Polyphonic audio tagging with sequentially labelled data using CRNN with learnable gated linear units
Audio tagging aims to detect the types of sound events occurring in an audio recording. To tag the polyphonic audio recordings, we propose to use Connectionist Temporal Classification (CTC) loss function on the top of Convolutional Recurrent Neural N…
Authors: : John Doe, Jane Smith, Michael Johnson
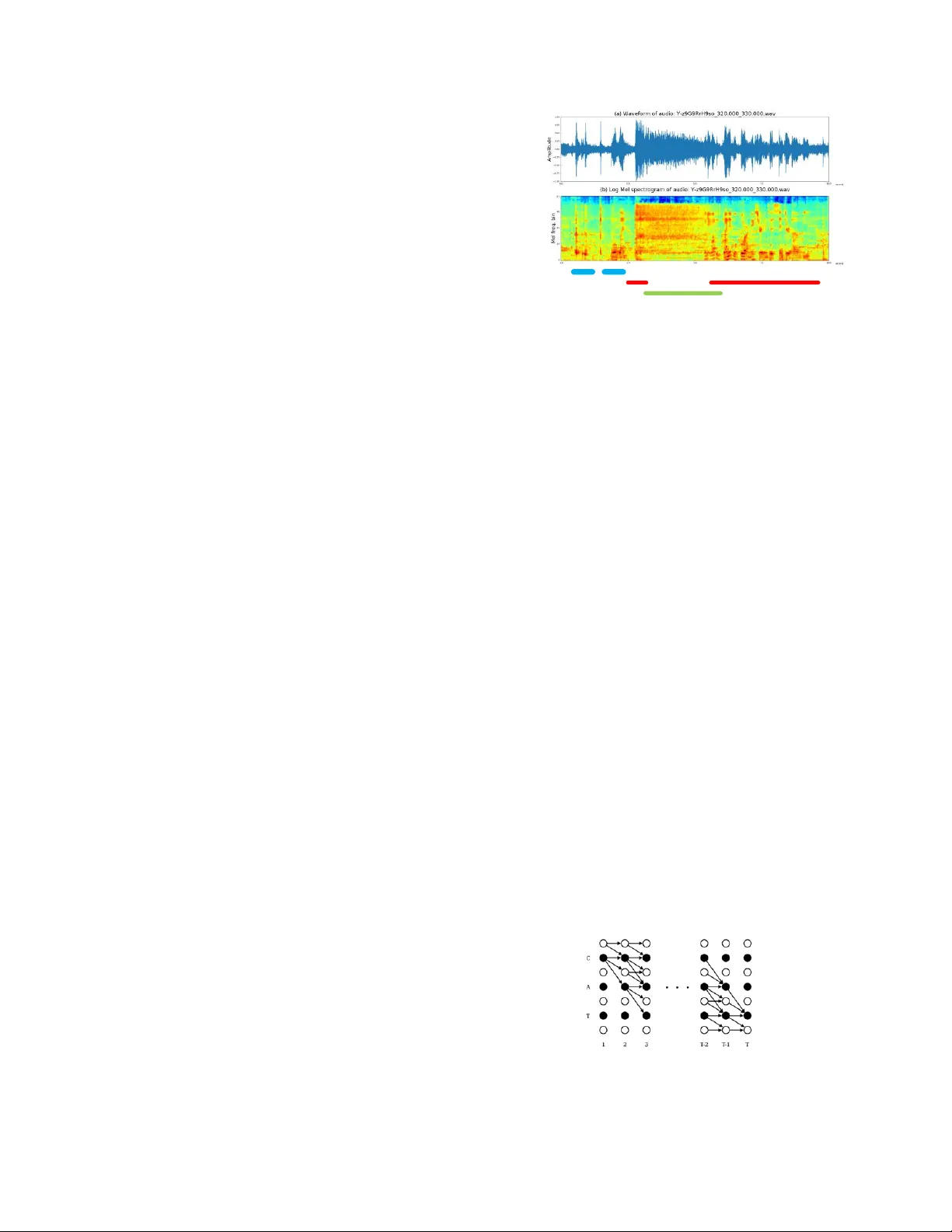
Detection and Classification of Acoustic Scenes and Events 201 8 19 -20 November 2018, Surrey , UK Polyphonic audio tagging with sequ entially labelled data using CRNN with learnable gated linear units Yuanbo Hou 1 , Qiuqiang Kong 2 , Jun W ang 1 , Shengchen Li 1 1 Beijing University of Posts and Telecommunications, Beijing, P.R.China {hy b, shengchen.li, wangjun19930314}@bupt.edu.cn 2 Centre for Vision, Speech a nd Signal Processing , University of Surrey , UK q.kong@surrey .ac.uk ABSTRACT Audio tagging aims to detect the types of sou nd events occurrin g in an audio recording. To tag th e polyphonic au dio recordings , we p ropose to use Connectionist Tem poral Classification (CTC) loss function on the top o f Convolution al Recurrent Neural Network (CRNN) with learnable Gated Linear Units (GLU- CTC), based on a n ew ty pe of audio label data : Sequentially Labelled Da ta (SLD) . In G LU-CTC, CT C o bjective function maps the frame-lev el probabil ity o f labels to clip-level p robabil- ity of labels. To compare the mapping abil ity o f GL U-CTC for sound events, we train a CRNN with GLU based on Global Max Poo ling (GLU-G MP) and a CRNN with GLU b ased on Global Averag e Pooling (GLU-G A P) . And we a lso compare the p ro- posed GLU-CT C system with the baseline system , which is a CRNN train ed using CTC loss function without GLU. The ex- periments show that the GL U-CTC achieves an A rea Und er Curve (AUC) score o f 0. 882 in audio tagging, outp erforming the GLU-G MP of 0. 803 , GLU-G AP of 0.766 and baseline system of 0.837 . That means based on th e same CRNN model with GLU, the performance of CTC mapping is b etter than the GMP and GA P mapping. Given bo th based on the CTC mapping, the CRNN with GL U outperforms the CRNN without GLU. Index Terms — Audio tagging, Con volutional Recurrent Neural Network (CRNN), Gated Linear Units (GL U), Connec- tionist Tem poral Classif ication (CT C) , Sequ entially Labelled Data (SLD) 1. INTRODUCTION Audio tagging aims to detect the types o f sound events occurring in an audio recording. Audio record ings are typically short seg- ments such as the audio recordings in IEEE AA SP DCASE 201 8 Challenge Task 4 [1] . Audio tagging has many application s in information retrieval [ 2] , aud io classification [ 3] , acoustic scene recognition [ 4] and indu stry sound recognition [ 5 ]. Most previous works of aud io tagging relies on strongly la- belled d ata or weakly labelled da ta. In strongly labelled d ata [4] , each audio clip is labelled with both the tags and th e onset and offset times of sound events. However, labelling strong label is time consuming and lab or expensive, resulting strongly labelled data is scarce an d its size is often limited to minutes or a few hours [ 6 ]. Thus the audio research community have turned to large-scale datasets without th e o nset and offse t times of so und events, which is referre d to as Weakly Labelled Data (WLD) [7] . WLD is also called clip level labelled data. In WLD, only the presence o r absence of sound events are known, but the occur- rence sequence of sound events are not known. I n th is paper, we explore th e p ossibility of Sequentially La- belled Data (SLD) in real-life polyphonic audio tagging. SLD is a type o f audio label newly prop osed in [ 8] . In SLD, both the tags of audio clip and the sequence of tags are known, without the onset and the o ffse t of tags. SLD reduces th e workload o f data anno tation and avoid s the problem of in accurate on set and offset ann otation of tags in strongly labelled data. In additio n, SLD co ntains the sequen tial information of tags which is n ot provided by WLD [8 ]. However, in the p revious work [ 8], the SLD was the synthesized monophon ic aud io based on IEEE DCASE 2 013 d evelopment d ataset, there is no overlap between sound events. To explore the possibility of S LD in real-life au- dio recordings, w e manually label 1578 polyphonic audio s of DCASE 201 8 Task 4 with sequ ential labels and release it here 1 . The details of sequential labelling of polyphon ic audio record- ings will be introduced in Section 3. T o predict the sequential labels of SLD in polyphonic audio recordings, we propose to use CTC loss function o n the to p of CRNN with learnable Gated L inear Units (GLU-CT C) . This id ea is insp ired b y the great performance of CTC in Automatic Speech Recognition [ 9]. CTC is a learning techn ique for se- quence labellin g with RNN, which allo ws RNN to be trained for sequence- to -sequence tasks withou t requiring any p rior align- ment between the input and target sequences. In GLU-CTC, CTC objective function maps the frame-level probability of so und eve nts to the target sequ ential labels of sound events , similar to th e poolin g layer in neural n etworks. So we explore the performance of this three p ooling function : CTC, G lo bal Max Pooling (GMP) and Global Average P ooling (GA P) in polyphonic au dio ta gging, based on th e same CRNN with GL U. This three models are abbreviated as GLU-CTC, GLU-G MP and GLU -GAP, respectively . In th is paper, the b aseline system is a CRNN without GLU train with CTC loss function. There are two con tribution s in this paper. First , in poly- phonic audio tagging we explore the possibil ity of a new label type: Sequentially Labelled Data , which no t only reduces the workload o f data an notation in strong labels, but also indicates the sequential information of tags in weak labels. We release the SLD o f DCASE 2018 Task 4 in here 1 . Second, to predict the sequential labels of S LD in polyphonic audio recordings, we 1 https://githu b.com/moses1994/DCASE2018 -Task4 Detection and Classification of Acoustic Scenes and Events 201 8 19 -20 November 2018, Surrey , UK propose to use CTC learning technique to train a CRNN model with learnable GLU. And we co mpare th e performance of GLU- CTC, GLU-G MP, GLU- GAP and th e baseline system , which is a CRNN train with CTC loss function . There is n o GLU in base- line system . This p aper is organized as follows, Section 2 intr oduces re- lated works. Section 3 describes the anno tation method of SLD in po lyphonic audio recordings. Section 4 describes how th e CTC uses SLD in polyphonic audio tagging and the model struc- ture. Section 5 describes th e dataset, experimental setup an d results. Section 6 gives conclu sions. 2. RELATED WORK Audio classif icatio n and d etection h ave obtained increasing attention in recent years. There are many challenges for audio detection and tagging su ch as IEEE AASP challenge on DCASE 2013 [ 4], DCASE 2016 [ 10 ] and DCASE 2 017 [ 6 ]. Many conventional works of audio classification and audio clip tagging u sed Mel Frequency Cepstrum Coefficie nt (MFCC) and Gaussian Mixture Mod el (GMM) as baseline system [ 4]. Recent audio classifica tion me thods including Deep Ne ural Networks (DNNs) [6 ], Convolution Neural Networks (CNNs) [1 1] and Recurrent Ne ural Networks (RNN) [ 3], with inputs vary ing from Short-Time Fourier Transform (STFT), Mel energy, spectrogram, MFCC to Constant Q Transform (CQT ) [1 2] . T he bag of frames (BOF) model was used in [1 3], where an audio clip is cu t in to segm ents and each segment inherits the labels of the audio clip. BOF is b ased on an assumption that tags occur in all frame s, which is ho weve r not th e case in practice. Some sound events such as “gunshot” on ly hap pen a sho rt time in an audio clip. S tate- of -the-art audio tagging methods [1 4 ] transform wavef orm to the Time-Frequency (T-F) representation. Then, th e T-F representation is treated as an image which is fed into CNNs. However, unlike image where th e ob jects usual ly occupy a dominant part of an image, in an au dio clip events o nly occur a sho rt time. To solve this problem, attentio n models [1 5 ] for aud io tagging and classification are applied to attend to the audio events and igno re the back ground sounds. 3. SEQUENTIALLY LABELLED DATA The polyphonic aud io data used in this paper is the weak annota- tions trainin g set o f DCASE 2018 Task 4 , a subset of Google Audio S et [ 16]. Audio S et consists of an ontolo gy o f 632 so und event classes and a collection of 2 million human-labeled 1 0- second audio clips drawn from YouTub e [ 16]. In the trainin g set, the polyphon y makes it hard to define ordered sequences of soun d events. To tackle this prob lem, we use the order of bound aries o f each sound event, th e order of onset and offset, but not the time stamps as the sequential labels. For example , we could use the sequential labels dishes_start, dishes_end, dishes_start, dishes_end, speech_start, blend- er_start, speech_end, speech_start, blend_ end, speech_end as the sequ ential label for the audio clip in Fig. 1 . Anoth er example is if th e content of an aud io clip cou ld be described by a d og barks while a car rings , we used the sequ ential labels ring_ start, dog_sta rt, dog_end , ring_end as the sequential lab el. In th e ground tru th label sequence, the tags of the audio clip and th e W eak lab e ls: (dis hes , sp ee c h , ble nder ) or (sp ee ch , d i s hes , bl ende r ) o r (bl ender , d is hes , sp eec h ) Sequ e ntia l label s: ( d i s hes_st art, dis hes_e nd, d ishes _sta rt, d ishes_ en d, spe ech_st art , blen d er_start, spe ech_e n d, spe ech_st art, b lend _en d , sp eech_ en d ) Str ong labels: dis hes sp eech ble nder Figure 1 : From top to bottom: (a) wavef orm of an aud io clip containing three sound events: “ dishes, speech, blender ”; (b) log Mel spectrogram of (a); S trong labels, sequenti al labels and weak labels of the audio clip. se quence o f tags are known, without knowing their occurrence time. We refer to the aud io clip labelled by label sequence as Sequentially Labelled Data (SLD ). Fig. 1 sho ws an audio clip with strong, sequential and weak tags. In this paper, we manually labelled the weak anno tations training set of DCASE 2018 Task 4 with sequential labels and release it after verification . S ee here 1 for more d etails abo ut S LD. 4. METHOD In this section , we will explain how to use CTC in po lyphonic audio tagging based on SLD. Then, we will describe the model structure used in th is paper. 4.1. CTC in Polyphonic Audio Tagging using SLD CTC is a learning technique for sequen ce labelling, it sho ws a new way for train ing RNN with unsegment sequen ces. In fact, CTC redefines the loss function of RNN [ 17 ] and allows RNN to b e trained for sequ ence- to -sequence tasks, without requ iring any prior alignment ( i.e. starting and endin g time of sound events) b etween the inpu t and target sequences [ 9 ]. In audio tagging, we are only in terested in the lab el sequence of corre- spondin g audio clip, not the groun d tru th alignment of events in the audio clip . Thus, we wa nt to marginalize ou t the alignment. To marg inalize out th e alignment, first, CTC adds an extra “blank” label (denoted by “ - ”) to original label set L [9] . Then, it defines a many- to -one mapping β that transforms the alignment ( i.e. the sequence of outp ut labels at each time step, also called a Figure 2: Trellis for computing CTC loss function [ 17] applied to labelling ‘CAT’. Black circles represent labels, white circles represent blanks. Arrows signify allowed transition s. Detection and Classification of Acoustic Scenes and Events 201 8 19 -20 November 2018, Surrey , UK path [17 ]) to label sequ ence. The mapping β removes repeated labels from the path to a single one, then removes the “blank” labels. For exam ple, β (C - AT - )= β (- CC -- ATT)=CA T, that is, path 'C - AT -' and '- CC -- ATT' both map to the label sequence 'CAT '. The CTC obj ective function is defined as the negative loga- rithm o f th e to tal p robability o f all p aths [ 9] that map to th e ground truth label sequence. The total probability can b e found using dynamic p rogramm in g algorithm [ 17] on the trelli s sho wn in Fig. 2. On the x-axis is ti me steps, on the y- axis is “modified label sequen ce”, that is target lab el sequence with blank labels added to th e beginnin g and the end and inserted between every pair of labels. When we u se the sim ple best path decoding to decode the output of CTC, the outp ut of CTC is directly the label sequence. By this means no thresho ld is needed to d etermine whether there are correspon ding events in th e audio clip . This will reduce the risk of over-fitting due to specific th resholds, which is an ad- vantage of usin g CTC loss functio n in audio tagging. More de- tails about CTC can be seen [ 17 ]. 4.2. M odel Structur e Inspired by the good performance of CRNN in audio tagging [1 5], CRNN is used in this paper shown in Fig. 3 . First, the wave forms of audio clips are transformed to T-F representation s such as Mel spectrograms. And convolutional layers are applied on th e T-F representation s to extract h igh level features. Next , Bidirectional Gated Recurrent Units (BGRU) are adopted to capture the temporal context information. Finally, the output layer is a dense layer with sigm oid activation function since au- dio tagging is a multi-class classification problem [3 , 6 ]. In the CRNN, the o utput activation from the CNN layers are padded with zeros to keep the d imension of the ou tput th e same as input. And th e max-pooling is applied in the frequency 0 64 240 Block Conv o lut ion la yer w i th GLU : 128 f il ters , kernel (3× 3) Conv o lut ion la yer w i th GLU : 128 f il ters , kernel (3× 3) Max-p o oli ng layer : kernel (1 × 4) + D ropout : 0.2 Block Block BGRU layer : 128 unit s (concat) N Timedistribute d Dense layer : N units Clip level probability of tags Pooling layer : CTC/G MP/GAP Frame level probability of tags Figure 3: M odel Structure. Due to th e acoustic event classes number is 10 in DCASE 201 8 Task 4, thus, f or model with GMP and G AP layer, N= 10 . For m o del with CTC layer , N= 21 (10 *2+1), the extra ‘1’ indicates the blan k label. t f linear sigmoid ⊙ GLU Mel feature Figure 4: The Structu re of GLU . axis only to preserve th e time resolu tion of the in put. Clip le vel probability of tags can be obtain ed from the last lay er. To co m- pare th e performance o f different p ooling functio n, there are three poo ling operation s in Fig. 3, CTC, Global Max P oolin g (GMP) and Global Average Pooling (GAP). 4.3. Gated Linear Un its A s shown in Fig. 3 , a CRNN model with 13 laye rs is applied for audio tagging. In ord er to reduce the gradient vanishin g pro blem in deep networks, the Gated Linear Units (GLU) [ 18 ] is used as the activation function to replace th e ReLU [ 19 ] activation func- tion in the CRNN model. The stru cture of GLU is shown in Fig. 4 . By providin g a linear p ath for the gradients propagation while keeping nonlinear capabilities through th e sigm oid operation , GLU can reduce the gradient vanishin g problem for deep net- works [ 18 ] . Similar to th e gating mechanism s in long sho rt-term mem o ries [ 20 ] o r gated recurrent un its [ 21] , GL U can control th e amount of information of a T-F unit flow to the next layer. GLU are defined as: * * Y W X b V X c where σ is sigmoid function, th e sym b ol is the element-wise product and ∗ is the convolu tion operator. W and V are con vo- lutional filters, b and c are biases. X denotes the in put T-F repre- sentation in the first layer or the feature maps of th e in terval lay- ers in model. The value of sigmoid function ranges from 0 to 1, so i f a GLU gate value is close to 1 , then the correspon ding T -F un it is attended. If a GLU gate value is near to 0 , then the correspond- ing T-F unit is ignored. By this means the network can learn to attend to so und events and igno re the unrelated soun ds. 5. EXPERIMENTS AND RESU LTS 5.1. Dataset, Ex perim ents Setup an d Evalu ation Metrics In th is paper, the training set is 1578 clips (2244 class occurrenc- es) of Task 4 from domestic environments, which consists o f 10 classes of so und events. We manually lab el the 1578 audio clips with sequential labels and release it after verifica tion, th e an nota- tion method is described in Section 3 . The test set is 288 poly- phonic aud io clips (9 06 events) of Task 4 [1] . For all the models described in this paper, i n train ing, log Mel band energy is extrac ted in Hamming window of length 64 ms with 64 Mel frequency b ins [ 22 ]. Fo r a given audio clip of 10 -second in Task 4, this feature extraction block results in a (240× 64) output as sho wn in Fig. 3 . 2 40 is the n umber of fra mes (1) Detection and Classification of Acoustic Scenes and Events 201 8 19 -20 November 2018, Surrey , UK Table 1: Averag ed Stats of Audio Tagging Metric A UC of each event class avg. Event Speech Dog Cat Bell Dishes Frying Blender Water cleaner Shaver A UC Precision Recall F-score GLU-G AP 0.895 0.946 0.875 0.820 0.583 0.602 0.641 0.773 0.771 0.758 0.766 0.960 0.588 0.730 GLU-G MP 0.909 0.946 0.921 0.873 0.669 0.643 0.691 0.813 0.785 0.778 0.803 0.957 0.645 0.771 GLU-CTC 0. 9 41 0.969 0.9 94 0.942 0.762 0.905 0.753 0.860 0. 850 0.835 0.882 0.816 0.816 0.816 Baseline 0.912 0.953 0.957 0.836 0.684 0.776 0.795 0.839 0.808 0.808 0.837 0.706 0.763 0.734 and 64 is the number of Mel frequency b ins. T he b inary cross- entropy lo ss [ 23 ] is applied b etween th e predicted probability of each tag and the correspond ing grou nd truth tag. Drop out and early stopping criteria are used in training p hase to prevent over- fitting. The model is trained for max imum 200 epochs with Ad- am optimize r with a learning rate of 0.00 1. To evaluate the results of audio tagging in clip level in this paper, we follo w the metrics proposed in [ 22 ]. The results are evaluated by Precision ( P ), Recall ( R ) and F-score [2 4 ] and Area Und er Curve ( AUC ) [ 25]. Larger P , R , F-score and AUC indicates better performance. 5.2. Results In this paper, the GLU-CTC , GLU-G MP and GL U-GA P all contain th e learnable GLU , w hich intro duces the attention mechanism in the convolu tional layers in CRNN. However, there is n o GLU in the baseline model, which is a CRNN train with CTC objective function. To evaluate th e performance of th e models in this paper , we calculate the AUC score of aud io tag- ging results in clip level of these models. As shown in Table 1 , GLU-CT C achieves an averaged AUC of 0 . 882 outperforming the GLU-G AP and GLU-G MP , and also better th an the baseline system . Table 1 also sh ows the averaged statistic including Pre- cision , Recall , F-score and AUC over 1 0 kinds of soun d events, respectively . GLU-CTC m apping performs better th an GLU- GA P and GLU-GMP, too. That is, based on the same CRNN model with GLU, the performa nce of CTC ma pping function is better than the GA P and GMP mapping function in polyphonic audio tagging. The averaged stats of audio tagging is evaluated in clip lev- el o f audio clips , the frame level p redictions of models o n exam - ple audio clip was sh own in Fig. 5 . In Fig. 5 , the prediction s of GLU- GA P in fram e level is always 1, which means the predic- tions of GL U- GA P in frame level overestim ates the occurrence probability of correspo nding event. While GLU- GM P , in con- trast, underestimates it. GLU-G M P produces wide peaks, indi- cating the onset and offset times o f event. That sh ows max po ol- ing has ability to locate event, while average poo ling seems to fail. The reason m ay be m ax poo ling encourages the respo nse for a single location to be high [ 26] , for similar aud io events which can obtain similar features. While averag e p oolin g encourages all response to be high [ 26], differe nce features of each event mak e it difficult to locate event. In Fig. 5, the GLU-CT C could p redict the o nset (start) and offset (end) tag sequ ence of correspond in g audio record ing , typically as a series of spikes [ 17] . Althou gh the spikes align well with the actual p osition of the bou ndaries of sound events in aud io recording, th ere is no ti me span information abo ut th ese events. The sp ikes ou tputted b y GLU-CTC co uld locate corre- spondin g events in the audio clip, while baseline system seem s to fail, which m eans the attention mechanism in troduced by GL U is helpful for aud io tagging. The reason ma y be th e atten- tion introduced by GLU focuses on the local in formation within each feature map, which could help GLU-CTC better learn the high-level representations of correspond ing audio events. Figure 5: F rame level predictions of GLU-GA P (b ), GL U-GMP (c), GLU-CTC (d), and Baseline (e). In GLU-CTC and Baseline , blue peaks denote the starting and red peaks denote th e endin g of corresponding sound events. 6. CONCLUSION In th is paper, we explore the possib ility of a n ew type of aud io label data called SLD in p olyphonic audio tagging. To uti lize SLD in audio tagging, we p ropose a GLU-CTC model. In GLU- CTC, CTC layer maps frame level tags to clip level tags, similar to the pooling op erations . Experiments show GLU-CT C outper- forms GLU-G AP and GLU-G MP . Finally, we released the se- quential labels o f DCASE 20 18 Task 4 after verification. In th e future, we will explore th e possibilit y o f SLD in soun d event detecti on with po lyphonic audio recordings and try to expand the size of SLD . 7. ACKNOWLEDGMENT Qiuqiang Kong was supported by EPSRC grant EP /N014 111/1 ``Mak ing Sense o f Sound s'' and a Research Scholarship from th e China Scholarship Council (CSC) No . 2014 06150 082." Detection and Classification of Acoustic Scenes and Events 201 8 19 -20 November 2018, Surrey , UK 8. REFERENCES [1] http://dcase.community/challenge 2018/task -large-scale- weak ly-labeled-sem i- supervised-sound -event-detection. [2] G. Guo and Stan Z Li, “Content -based audio classification and retrieval by support vector machines,” IEEE T ransac- tions on Neural Networks , vol. 1 4, no. 1, pp. 2 09 – 215, 2003 [3] Y. Xu, Q. Kong and W. Wang, et al. “ Large-scale weak ly supervised audio classifica tion using gated convolution al neural network,” arXiv preprint arXiv: 171 0.003 43, 201 7. [4] D. S towell, D. Giannoulis and E. Benetos, et al. “Detecti on and classification of acoustic scenes and events,” IEEE Transactions o n Multimedia , vol. 17, no. 10, pp. 17 33 – 174 6, 2015 [5] S. Dimitrov, J. Britz, B. Brandherm, and J. Frey, “Analyz ing sounds of home environment for device recognitio n ,” in AmI. Spring er , 2 014, p p. 1 – 16. [6] A. Mesaros, T. Heittola, A. Diment and B. Elizalde, et al. “DCASE 2017 challenge setup: Tasks, datasets and baseline system ,” in Proceedings of DCASE2017 Workshop . [7] A. Kumar and B. Raj, “Audio event detection using weakly labell ed data,” in Proceeding s of the 201 6 ACM on Multi- media Conference . ACM , 201 6, pp. 1038 – 1047 [8] https://www.re searchgate.net/publication/32 65882 86_Audio _Tagging_With_Connectionist_Temporal_Classification_M odel_Using_Sequ entially_Labelled_Data [9] A. Graves and N. Jaitly, “Towa rds end- to -end speech recog- nition with recurrent n eural networks”, in Proc. of ICML , 2014. [10] M. Valenti , A . Diment and G. Parascandolo, et al., “DCASE 2016 acoustic scene classification u sing convolutional neu- ral networks,” Workshop on Detection and Classification of Acoustic S cenes and Events (DCASE 20 16) , Budapest, Hungary, 2016 [11] Y. Han and K. Lee, “Acoustic sce ne clas sification using co nvolutio nal neural network and multiple-width frequency- delta data augmentation,” arXiv p reprint arX iv: 1607.0 2383, 2016. [12] T. Lidy an d A. Schindler, “CQT -based convolutio nal neural networks for audio scene clas sification,” in Workshop on Detection and Classificatio n of Acoustic Scenes and Events (DCASE 2016) , Budapest, Hungary, 2016 [13] J. Ye, T. Kob aya shi, M. Murakaw a, and T. Higuchi, “ Acoustic scene classification based on sou nd textures and events,” in Proceedings of ACM on Multimedia Co nference. ACM , 2015, pp. 12 91 – 1294. [14] K. Choi, G. Fazekas, and M. Sandler, “Automatic tagging using deep con volutional neural n etworks,” arX iv preprint arXiv: 1606 .00298 , 2016 . [15] Y. Xu , Q. Kon g, Q. Huang, W. Wang, and M. D. Plu mbley , “Attention and lo calization based on a deep con volutional recurrent model f or weakly supervised audio tagging,” in INTERSPEECH. IEEE, 2017 , pp. 3083 – 3087. [16] Gem meke, Jort F., et al. "Audio S et: An on tology and hu- man-labeled dataset for audio events." IEEE Internation al Conference on Acou stics, Speech and Sig nal Processing IEEE , 201 7:776 - 780. [17] Graves A, Gomez F. Connectio nist temporal classification: labelling unsegmented sequ ence data with recurrent n eural networks[C]. Internati onal Conference o n Mach ine Learn- ing. ACM , 2 006:36 9- 376. [18] Y. N. Dauph in, A. Fan, M. Auli, and D. Grangier, “Lan- guage modelling wi th gated convoluti onal networks,” arXiv preprint arXiv: 1 612.08 083, 2 016. [19] V . Nair and G. E. Hinto n, “Rectified lin ear units improve restricted boltzmann machines,” in ICML, 2010, pp. 807 – 814. [20] S . Hochreiter an d J. Schmidhub er, “Long short -term mem o ry,” Neural Computation, vol. 9 , n o. 8, pp. 17 35 – 1780, 1997. [21] J. Chung, C. Gulcehre, K. Cho, and Y. Ben gio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,” arXiv preprint arXiv: 1412 .3555 , 2014 . [22] Ko ng Q, Xu Y, So bieraj I, et al. S ound Event Detection and Time -Frequency S egm entation from Weakly Labelled Data , arXiv preprint arX iv: 1804.0 4715, 2018. [23] F . Ghazani, and M. S. Baghshah. "Mult i-label classification with feature-aware implicit enco ding and generalized cross - entropy loss." Electrical Engin eering IEEE, 2016 :1574- 1579. [24] A. Mesaros, T. Heittola, and T. Virtanen, “Metrics for poly- phonic sou nd event detection,” Ap plied Sciences , vol. 6, no. 6, p. 16 2, 201 6. [25] J. A . Hanley and B. J. McNeil, “The meaning and u se of the area un der a receiver o perating characteristic (roc) curve.” Radiolo gy , vol. 14 3, no. 1 , pp. 29 – 36, 19 82. [26] Ko lesnikov, Alex ander, and C. H. Lampert. "Seed, Expan d and Constrain: Three P rinciples for Weakly-Supervised Im- age Segmentation." Eu ropean Conference on Computer Vi- sion Sprin ger Internation al Publi shing, 2016 :69 5- 711.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment