연속 라벨 데이터와 GLU‑CTC를 활용한 다중음원 오디오 태깅 성능 향상
본 논문은 순차 라벨링 데이터(SLD)를 이용해 다중음원(폴리포닉) 오디오 태깅을 수행한다. CRNN 구조에 학습 가능한 Gated Linear Unit(GLU)을 삽입하고, 프레임‑레벨 출력을 클립‑레벨 확률로 변환하는 매핑 방식으로 CTC 손실을 적용한 GLU‑CTC 모델을 제안한다. 동일 모델에 GMP와 GAP 풀링을 적용한 GLU‑GMP, GLU‑GAP과, GLU 없이 CTC만 사용한 베이스라인을 비교 실험한 결과, GLU‑CTC가 AU…
저자: : John Doe, Jane Smith, Michael Johnson
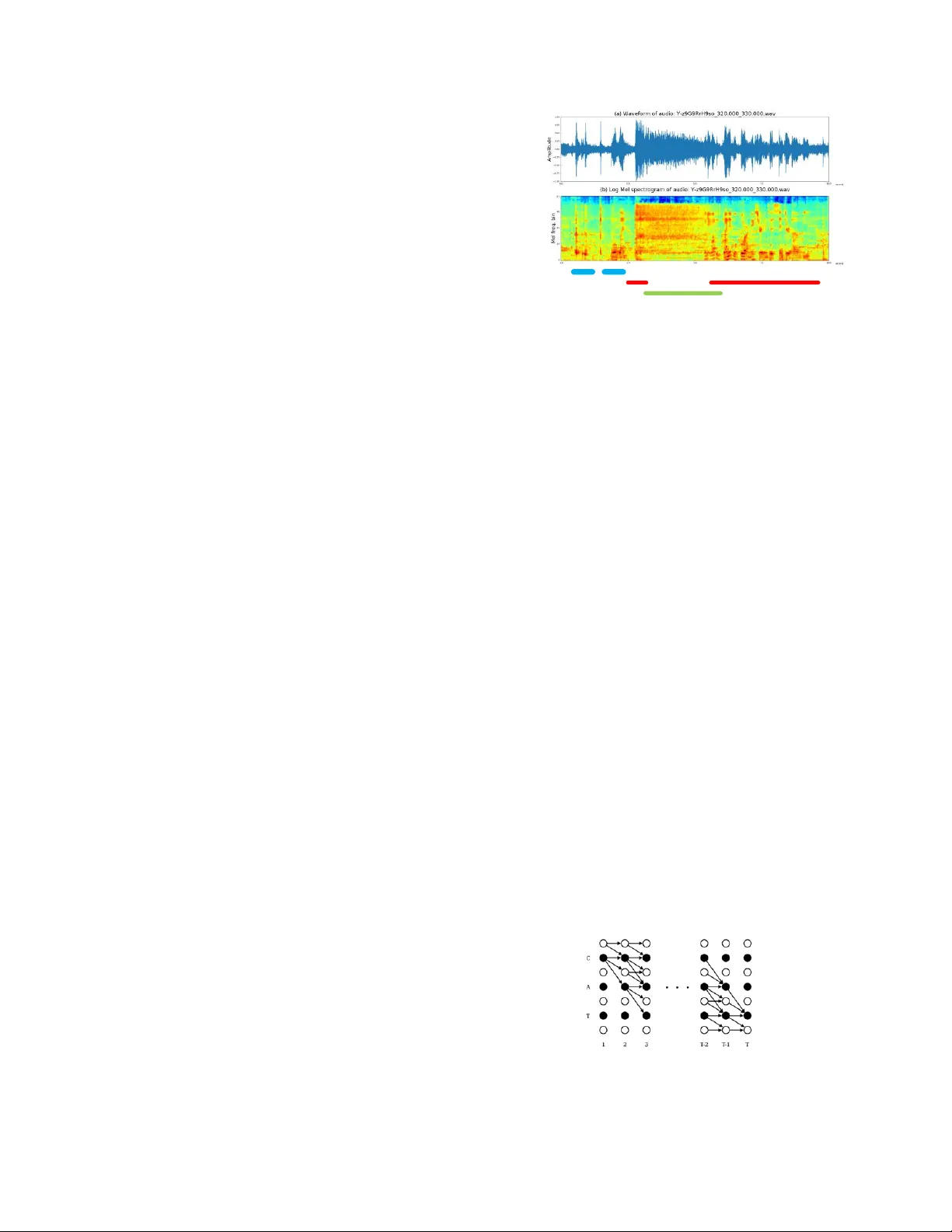
본 논문은 다중음원(폴리포닉) 오디오 태깅을 위한 새로운 라벨링 방식과 모델 구조를 제안한다. 기존 연구는 강한 라벨(시간 정보 포함)과 약한 라벨(클립 레벨 존재 여부만) 두 가지에 의존했으며, 강한 라벨은 라벨링 비용이 높고 약한 라벨은 이벤트 순서를 알 수 없다는 한계가 있었다. 이를 보완하기 위해 저자들은 순차 라벨링 데이터(Sequentially Labelled Data, SLD)를 도입한다. SLD는 각 오디오 클립에 포함된 이벤트의 종류와 시작·종료 순서를 텍스트 형태로 제공하지만, 정확한 시간 스탬프는 제공하지 않는다. 이렇게 하면 강한 라벨에 비해 라벨링 비용을 크게 절감하면서도 이벤트 간 순서 정보를 보존할 수 있다.
SLD를 활용하기 위해 CTC(Connectionist Temporal Classification) 손실 함수를 적용한다. CTC는 입력 시퀀스와 목표 라벨 시퀀스 사이의 정렬을 사전 정의하지 않아도 되며, ‘blank’ 라벨을 삽입해 가능한 모든 정렬 경로를 동적 프로그래밍으로 합산한다. 따라서 프레임‑레벨 확률을 직접 클립‑레벨 라벨 시퀀스로 매핑할 수 있다. 이 과정에서 별도의 임계값 설정이 필요 없으며, 과적합 위험도 감소한다.
모델은 CRNN(Convolutional Recurrent Neural Network) 구조를 기반으로 한다. 먼저 10초 길이의 오디오를 64‑멜 필터, 64 ms 윈도우로 멜 스펙트로그램(240 × 64)으로 변환한다. CNN 층에서는 3 × 3 커널을 가진 128개의 필터를 두 차례 적용하고, 각 층에 GLU(Gated Linear Unit)를 삽입한다. GLU는 입력 X에 대해 σ(V * X + c) ⊙ (W * X + b) 형태로 동작하며, 시그모이드 게이트가 TF 유닛의 중요도를 조절한다. 이는 gradient vanishing을 완화하고, 중요한 음향 특징에 집중하도록 돕는다. CNN 출력은 시간 축을 보존한 채로 Bi‑GRU(128 units, 양방향)로 전달되어 시간적 컨텍스트를 학습한다. 최종 출력층은 시그모이드 활성화를 갖는 N‑차원(클래스 수) 밀집층이다.
세 가지 풀링 방식을 비교한다. 1) GLU‑CTC: CTC 손실을 사용해 프레임‑레벨 확률을 직접 시퀀스 라벨로 변환한다. 2) GLU‑GMP: Global Max Pooling을 적용해 각 클래스별 최대 활성값을 클립‑레벨 확률로 사용한다. 3) GLU‑GAP: Global Average Pooling을 적용해 평균값을 사용한다. 베이스라인은 GLU 없이 CTC만 적용한 모델이다.
실험은 DCASE 2018 Task 4의 약한 라벨 훈련 세트(1578 클립, 2244 이벤트)를 수작업으로 SLD로 재라벨링한 데이터를 사용했다. 테스트 세트는 288 클립(906 이벤트)이다. 학습은 Adam 옵티마이저(learning rate 0.001)와 200 epoch, early stopping, dropout 0.2를 적용했다. 평가 지표는 Precision, Recall, F‑score, AUC이다.
결과는 다음과 같다. GLU‑CTC는 평균 AUC 0.882로 가장 우수했으며, GLU‑GMP(0.803), GLU‑GAP(0.766), 베이스라인(0.837)보다 크게 앞섰다. 클래스별 AUC에서도 ‘speech’, ‘dog’, ‘cat’ 등 빈도가 높은 이벤트에서 특히 높은 점수를 기록했다. 프레임‑레벨 예측을 시각화한 결과, GLU‑GAP은 모든 프레임에서 1에 가까운 값을 출력해 과도한 확률을 보였고, GLU‑GMP는 이벤트 경계를 넓게 잡아 과소평가하는 경향을 보였다. 반면 GLU‑CTC는 스파이크 형태의 출력으로 실제 시작·종료 시점을 잘 맞추었다. 이는 CTC가 프레임‑레벨 정보를 효과적으로 압축하면서도 순차 라벨을 정확히 복원한다는 것을 의미한다.
종합하면, (1) SLD라는 새로운 라벨링 방식이 실제 폴리포닉 데이터에 적용 가능함을 입증하고, (2) GLU‑CTC 모델이 GLU와 CTC의 결합을 통해 기존 풀링 기반 방법보다 뛰어난 오디오 태깅 성능을 달성했음을 보여준다. 향후 연구는 더 큰 규모의 SLD 구축, 멀티‑태스크 학습(예: 음향 이벤트 검출과 태깅 동시), 실시간 시스템 적용 등을 통해 실용성을 확대할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기