Interpreting DNN output layer activations: A strategy to cope with unseen data in speech recognition
Unseen data can degrade performance of deep neural net acoustic models. To cope with unseen data, adaptation techniques are deployed. For unlabeled unseen data, one must generate some hypothesis given an existing model, which is used as the label for…
Authors: : John Smith, Jane Doe, Michael Johnson
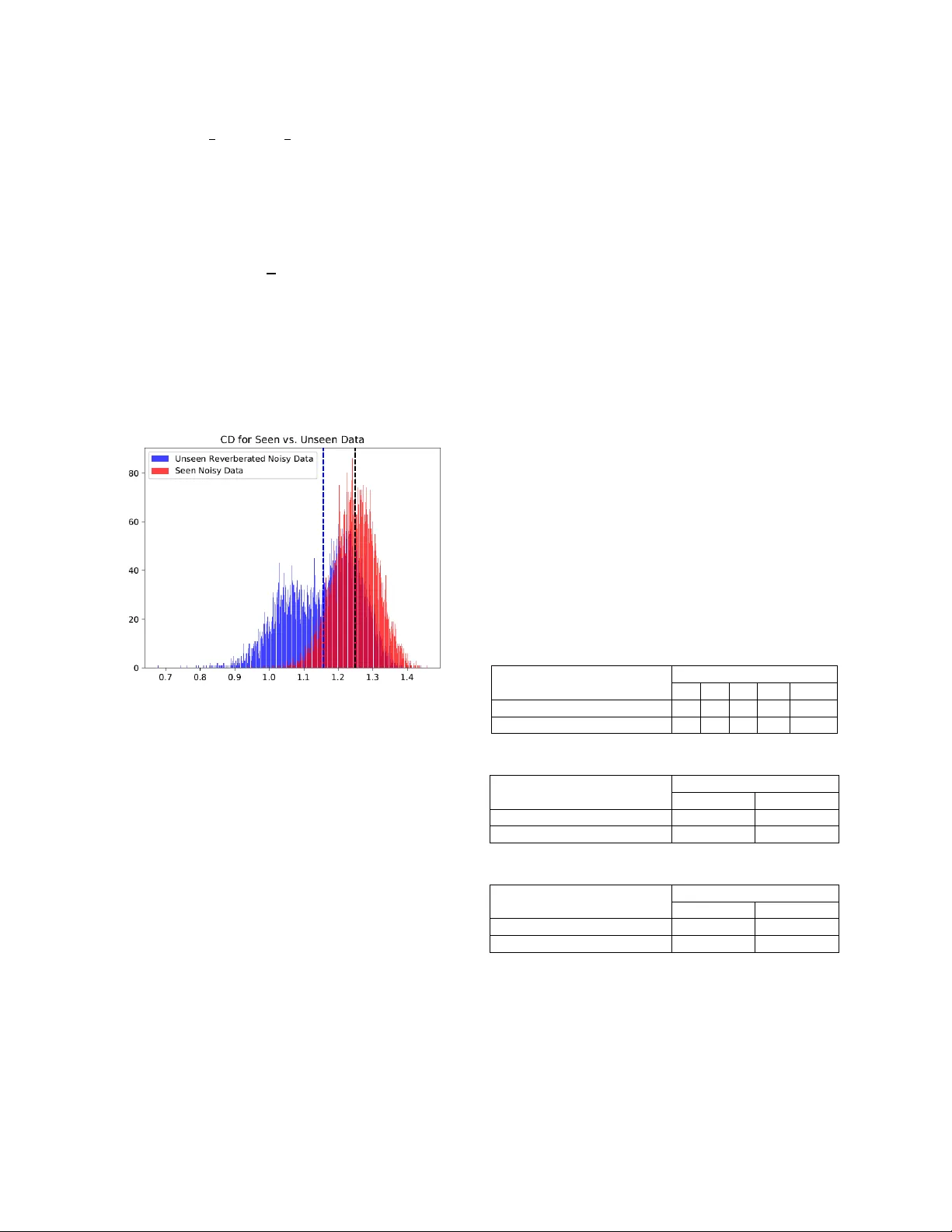
INTERPRETING DNN OUTPUT LAYER ACTIVATIONS: A STRATEGY TO COPE WITH UNSEEN DATA IN SPEECH RECOGNITI ON Vikramjit Mitra * , Horacio Franco University of M aryland, Co llege Park, MD, U SA Speech Technolog y and Research Lab oratory , SRI Internation al, Menlo Park , CA, USA vmitra @ umd . edu, horacio.franco@sri.com ABSTRACT Unseen data can degrade performance o f d eep neural net (DNN) acoustic models. To cope with unseen data, adaptation techniques are deployed. For un labeled uns een data, on e must generate s ome hypothesis given an existing model, which is used as the label f or model adaptation. However, assessing th e goodness of the h y pothesis can b e difficult, and an erroneous h ypothesis can lead to poorl y trained models. In such cases, a strategy to select data having reliable hypothesis can ensure better model adaptation. This work proposes a data-selection strategy for DNN model adaptation, where DNN output la yer activations are used to ascer tain the goodness of a generated hypothesis. In a DNN acoustic model, the output layer activations are used to generate target class probabilities. Under unseen data conditions, the difference b etween th e most probable target and the next mos t probable target is decreased compared to th e same fo r seen data, indicating that the model may be uncertain while generating its hypothesis. T his work proposes a strategy to assess a model’s perf ormance by analyzing the output la yer activations b y using a distance measure between the most likely tar get and th e next most likel y target, which is u sed for data selection fo r performing unsupervised adaptation. Index Ter m s — automatic speech rec o gnition, r obust speech recognition, unsupervised adaptation, output layer activatio ns, deep neural networks, confidence measures. 1. INTRODUCTION Deep learning technologies have revolutio nized automatic speech r ecognition ( ASR) s y s tems [ 1, 2 ], demonstrating impressive performance for almos t all tried languages. Interestingly, deep neural network (DNN) -based s ystems are both data hungry and data s ensitive [3], wh ere the performance of a model i s found to improve with additional diverse training data. Unf ortunately, annotated training data can be expensive. Althou gh large volumes of d ata are becoming available ever y da y, not all of it is properly transcribed or reflective o f the varying acou stic conditions that sy stems are expected to tackle. In limited d ata conditions, DNN acoustic models can be quite sensitive to acoustic-condition mismatches, wh ere sub tle variation in the background acoustic conditions can significantly degrade recognition performance. To co pe with the prob lem of unseen data, multi - condition traini n g accompanied by data augmentation is _____________________ ________________________ ______________ *The author perf o rmed this work while at SRI I nternational and is currently worki n g at Apple Inc. generally used to ex pose t he DN N acoustic model to a wider range of background acoustic variations [4] . Data augmentation may expo se the mod el to th e anticip ated acoustic variations; but in reality, acous tic variations ar e difficult to anticipate. Real-world ASR applications encounter diverse acou stic conditions, which are m o stly unique an d hence difficult to anticipate. Systems that are trained with several thousands of hours of data collected from different realistic con ditions typically are fou nd to be quite robust to background conditions, as they are expected to contain many variations; however, such data may not contain all the possible variations found in the world . Recently, several o pen s peech recognition evaluati ons [5-8] have shown h ow vuln erable DNN acoustic models are to realistic, varying, and unseen acoustic conditions. One of the most celebrated and least resource -constrained approaches to coping with unseen data conditions is performing unsupervised adaptation, where th e onl y necessity is having raw data. A more reliable ad aptation technique is supervised adaptation, which assumes h aving annotated target-domain d ata; however, annotated d ata is often un available in real-world scenarios. This constraint often makes unsup ervised adaptation more practical. Unsupervised speaker adaptation of DNNs has been explored in [8 – 11], with adaptation based on maximum likelihood linear regression (MLLR) transforms [10] , i- vectors [ 11], etc. showing impressive perfo rmanc e gains over un -adapted models. In [12] Kullback-Leibler divergence (KLD) based regul arization was proposed for DNN model parameter adap tation . F eatu re-space MLLR (fMLLR) transfo rm was found to improve DNN acoustic model p erformance for mismatched cases in [13] . Confidence score based unsupervised adaptation demonstrated improvem ents in r ecognition per f ormance for Wall Street Journal (WSJ) [ 14 ] an d VERBMOBIL [15 ] speech recognition tasks. A s emi-su pervised DNN acoustic model training was investigated in [16 ], where a DNN trained with a small dataset was adapted to a larger d ata set, leveraging data selection usin g a confidence measure. In this work, we focus o n understandin g how acoustic - condition mismatch b etween the trainin g and the testin g data impacts the DNN output decision. Similar efforts have been p ursued b y researchers in [ 17 , 18]. Earlier [ 19 ], we investigated an entropy measure to ascertain the level of uncertainty in a DNN and to translate th at measure to quantify DN N decision reliabilit y. This pape r focuses on how data mismatch impacts th e output layer activation s of a DNN, and proposes a measure that predicts when a DNN’s decision ma y be less accurate. The pro posed approach relies on the fact that under seen conditions, the most likel y target’s pro bability is s ubstantially hig her than the next most lik ely target’s p robability, wh ereas for un seen conditions, the difference betwe en those target p robabilities may no t be as large, which happens as a consequence o f the DNN being more uncertain while making a d ecision in the unseen condition. A similar observation about the impact of unseen data on th e winning neuron’s activation with respect to th e next best activation was cited in [ 20 ]. I n this work, we use the o utput layer neural activations (befo re non linear transform) to compu te a distance measure between the most likely target and the 2 nd and 3 rd most likel y targets, respectively. We n ame this mea sure the confusion distance ( CD ) and show that the CD is higher for seen data as compared to unseen data. We compute an averaged distance measure o ver an u tterance and use that to select data for unsupervised adap tation. Note that the proposed strategy is not onl y restricted to speech recognitio n but can be used in other applications that involve probabilistic processing. 2. DATA The acoustic models in this work were trained by using the multi-conditioned, noise- and chann el-degraded training data f rom the 16 kHz Aurora - 4 [ 21] no isy WSJ0 corpu s. Aurora-4 contains a total of six additive noise types (car; babble; restaurant; street; airport; and train station), with channel-matched and mismatched conditions. It was created from th e standard 5K WSJ0 datab ase and contains 7 K training utterances of approximatel y 15 -ho urs duration and 330 test utterances. The test d ata includ es 14 test sets from two d ifferent channel conditions and six different added noises. T h e signal - to -noise r atio (SNR) for the test sets varied between 0- 15 dB. Au dio d ata for test sets 1 – 7 was recorded with a Sen nheiser microphone, while test sets 8 – 14 wer e recorded using a second microphone randomly selected from a se t of 1 8 different microphones. Resu lts from the test sets are presented as follows: Set A: clean, matched-channel (test set 1); Set B: nois y , matched -channel (test sets 2 – 7); Set C : clean, var ying-channels (test set 8); and Set D: nois y , varying-channels (test sets 9 – 14). We treat ed reverberation as the unseen data condition i n our experiments, where we trained the models using the Aurora-4 corpus and evaluated their p erformance on real - world reverberated data. For adapta tion , op timization , and evaluation purposes, we used the training, d evelopment , and evaluation se ts distributed with the REVERB-2014 challenge. The REVERB -2014 dataset [ 8] contain s single- speaker utterances, where only the single -microphone part of the dataset was used in the experiments rep orted in this paper. The REVE RB-2014 training set consists of the clean WSJCAM0 [22] data, which was con volved with room impulse responses (with reverberation times from 0.1 sec to 0.8 sec) and then corrupted with b ackground no ise. No te that as the REVERB-2 104 training set was used as the unsupervised adaptation set, its t ranscrip tions wer e not used in any of our ex p eriments. The evaluatio n and d evelopment data contain both real recordings (real data) and simulated data (sim data). The real data is borrowed f rom the MC - WSJ-AV corpus [23], wh ich consists o f utterances recorded in a noisy and reverberant room. The simulated evaluation set contains 1088 utterances in each of the f ar- an d n ear- microphone conditions, and the real evaluation set con tains 372 utterances sp lit equall y between far - and n ear- microphone conditions. We used gammatone f ilterbank energies (G FBs) as the acoustic feat u res for our experiments. G FBs were g enerated using a bank of 40 gammatone filters equally spaced on the equivalent rectangular bandwidth scale. The analysis window was 2 6 ms with a frame rate of 10 ms. The gammatone subband powers were dynamic -range compressed using 15 th roo t. G FBs were used in o ur experiment because of their robustness against b ackground distortions compared to mel-sca le features [ 27 ]. 3 . THE CONFUSION D ISTANCE ( CD) M EASURE In th e case of unknown acoustic variations, DNN -based acoustic models fail to generalize well and, as a consequence, propagate any dis tortion in the input f eature space, resulting in distorted outputs that do not represent relevant aspects of the input [ 17 , 18 ] . In grossly mismatched situations, detecting th e cases th at cause the system to completely fail versus th ose that generate a reaso nable output is qu ite u seful. One way to generate such detection is through a co nfidence measure, which is generall y indicative of how trustworth y the ASR h ypothesis is for each of the test files. A fully conn ected network can b e interpreted as a cascade of several feature -transformation steps, where the goal is making each target class as discriminative as pos sible with respect to each other. H ence, for cases where the model fails to generate reasonable performance, such transformations fail to generate reliable features, and therefore the model decision is impacted . It can be expected that when th e mod el decision is impaired, that is when th e model is uncertain abou t its d ecision, and thus multiple output activations may be generating similar posterior p robabilities. A n atural indicator of this is ho w close the neural net activation producing th e maximum value is with respect t o the activ atio ns producing the s econd or third maxima, respectively. I n the case when t he distance between the most likel y target (i.e., the activation producing the maximum value) an d the next most likel y target (the activation p roducing the second-highest m axi mum value) is less, then th e model can be expected to be uncertain while making a decision r elative to a model with a greater distance between these values. N ote that this distance measure is not an absolu te measure, and in this work, we pose it as a relative measure, based on the distances obtain ed from th e training set. We n ame this distance measure th e confusion distance ( CD ), where f igure 1 shows its d istribution from a training set and an unseen dataset. Let us assume that a DNN has N target classes, indicating N n eurons in the output lay er each generating activation s x t , i at a giv en instant o f time t , f or i th neuron in the output layer. Let X t be the vector of x t , i at time ins tant t . Let us define Y t to be the vector obtained after sorting (in descending order) X t . Let the elements of Y t be y t,i , where Where (1) Let us define the frame level CD measure as (2) where the first term deter mines the average o f the top α hypothesis and t he seco nd ter m deter mines the a verage of the top β co mpeting h ypothesis at ti me instant t . For an utterance consisting o f m fra mes, the overall avera ged CD measure ( CD avg ) is co mputed by ta king the mean of the CD i estimated fro m all the m f rames. (3) In th is work, the CD avg is estimated fo r each f ile f or b oth the training set and the unseen dataset (in this case the unsupervised adap tation set) . Let th e CD avg computed from the trainin g and the un supervised adaptation set b e denoted as: and respectively. The data selection from the unsupervised adaptation set is performed b y thresholding the of that set, where the thres h old is determined b y th e . Figure 1. Distribution of CD e stimated f ro m th e output layer of a DNN acoustic m odel. Green: CD estim ated from the training data (seen no isy). Blue: CD estimated from th e u nseen d ata (unseen reverberated + noisy ). The vertical dotted lines indicate the respective CD means. 4 . ACOUSTIC M ODEL In this work, we used time-frequency CNN (TFCNN) acoustic mod els based on their reliable performance [25 , 26 ] on th e Aurora-4 speech recognition task . To generate the alignments necessar y for train ing the acoustic model , a Gaussian mixture model (GMM )-HMM model was used to produce se n one labels. Altogether, the GMM -HMM sy stem produced 3125 context-dep endent states for the Aurora - 4 training data. The in put featu res to the acoustic models were formed by using a context window of 17 frames (8 f rames on either side of the current frame). The acoustic mod els were trained by usin g c ross-entrop y on the alignments f rom the GMM-HMM system. A 5 -layered DNN with 2048 neurons in each layer was train ed b y using the alignments from th e GMM-HMM s ystem, which in turn was used to generate ali gnments fo r training th e subsequent TF CNN acoustic model used in this paper. For the TFCNN acoustic models, the input acoustic features were f ormed b y us ing a context win dow of 17 frames. The TFCNNs had 75 f ilters to perform time con volution and 200 filters to perform frequency convolution . For time and frequency convolution, eight b ands were used, f ollowed b y a max - pooling over f ive and three s amples, respectively . Feature maps after bo th the convolution operations were concatenated and fed to a fu lly connected 4-hidden layer neural net, contain ing 2048 neurons. 5 . RESULTS The baseline acou stic model (TFCNN BASELINE ) was trained with th e Aurora-4 multi -condition training dataset, where a held-out, cross-validation set was used to train the TFCNN acoustic models. The reverberated acoustic condition was treated as the unseen data condition in our experiments, where the experimental analysis was performed by using the development and test d ata from the REVERB -2014 challenge dataset. As a baseline uns upervised adapted system ( TFCNN UV ) ( where the subscript UV stand s f or un supervised adaptation ), we used the hypothesis from the whole adaptation set to adapt the TFCNN BASELINE model. Note that during adaptatio n, the unsupervised adaptatio n dataset was used in addition to the original Au rora- 4 training dataset to up date the acoustic model parameters. During adaptation, all model parameters were updated with an L 2 no rm of 0.001 a nd an initial learning rate o f 0.004, with the learnin g rate halved at ever y it eration over the adaptation set. Early stopping was p erformed based on the cross-validation error. Tables 1-3 sh ow the word error rate (WER) obtained from the baseline model (TFCNN BASELINE ) and unsupervised adapted baseline model (TFCNN UV ). Table 1. WERs from the baseline acoustic models when evaluated on the Aurora-4 test set. System Aurora-4 A B C D Avg. TFCNN BASELINE 2.9 5. 7 5.6 14. 3 9. 2 TFCNN UV 3.2 5.9 6.2 14.7 9.5 Table 2. WERs from the baseline acoustic models when evaluated on the REVERB-2014 dev set. System REVERB 2014 dev Avg. Sim Avg. Real TFCNN BASELINE 39.3 42.4 TFCNN UV 24.4 33.7 Table 3. WERs from the baseline acoustic models when evaluated on the REVERB-2014 test set. System REVERB 2014 test Avg. Sim Avg. Real TFCNN BASELINE 37.8 46.9 TFCNN UV 22.7 37.4 Table 1 show that while some p erformance d egradation occurred u nder th e nois y con dition with which the model was initiall y trained , but th e degradation is not substantial , which is a consequence of a dd ing the orig in al trainin g set as part of the adaptation set. Tables 2 -3 show that using the entire adaptatio n set improved the model’s performance o n the unseen reverberation condition for both the dev and test sets of REVERB -2014, reducing the WER b y more than 20%. At this point, the question remains if the adaptation 1.25 1.16 step h as suffered from any inaccurate hypothesis generated from the adaptation data. Such inaccurate hy po thesis can be filtered o ut by performin g data selection b y u sing . As an initial ex p eriment to asse ss the values of and (refer to equation 2), we rank-sorted th e values estimated for the adaptatio n set and selected the top 4K files for performing adaptation, results shown in table 4 . The adapted model after data selection is represented as TFCNN UV_DS , where the subscript DS stan d s for data selection. Table 4. WERs from the adapted acoustic models , ( where the adaptation set was selected based on diff er ent values of and ) when tested on the REVERB-2014 dev set. System REVERB-2014 dev Avg. Sim Avg. Real TFCNN UV_DS 1 1 28.4 35.1 TFCNN UV_DS 1 2 22.3 31.5 TFCNN UV_DS 1 3 22.6 32.7 TFCNN UV_DS 1 4 22.5 32.5 TFCNN UV_DS 1 5 22.5 32.9 TFCNN UV_DS 2 3 22.5 32.4 TFCNN UV_DS 3 3 28.5 36.5 Table 4 shows that selecting = 1 an d = 2 gave the best adaptation performance, at which point th e TF C NN UV_DS acoustic model outperforms the TFCNN UV model. Finally, we explored data selection by u sing a CD threshold learned from the training list. Let train_CD and 2 train_CD be the mean and variance computed from the data. We can select data using a threshold , where the data h aving will be selected fo r performing the unsupervised model adaptation. Table 5 pres ents th e WER results af ter adaptation, using the data selected with different thresholds, when evaluated on t h e REVERB-2014 dev set. Table 5 in dicates that the optimal thresho ld was train_CD -2 tra in _CD . Tables 6 -7 present the WERs fro m the baseline models and the adapted models (using = 1, = 2 and train_CD -2 tra in _CD ) f or th e Au rora-4 an d REVERB 2014 eval. sets. Table 5. WERs from the adapted acoustic models, w ith data selection using differe nt values of (using = 1 and = 2), when evaluated on the REVERB-2014 dev set. System REVERB-2014 dev Avg. Sim Avg. Real TFCNN UV_DS tra in _CD 25.3 34.0 TFCNN UV_DS tra in _CD- tra in _CD 23.1 32.6 TFCNN UV_DS tra in _CD -2 tra in _CD 22.3 31.2 TFCNN UV_DS tra in _CD -3 tra in _CD 23.3 32.4 TFCNN UV_DS tra in _CD -4 tra in _CD 23.6 33.8 Table 6. WERs from the baseline systems and TFCNN UV (after data selection) acoustic models when eva luated on the Aurora-4 test set. System Aurora-4 A B C D Avg. TFCNN BASELINE 2.9 5.7 5.6 14.3 9.2 TFCNN UV 3.2 5.9 6.2 14.7 9.5 TFCNN UV_DS 3.3 6.0 6.1 14.7 9.5 Table 6 shows no substantial change in performance on th e seen data (Aurora -4 test set) from the adapted models compared to the TFCNN BASELINE system. Table 7. WERs from the baseline systems and TFCNN ADAPTED (after data selection) acoustic models when evaluated on the REVERB-2014 test set. System REVERB 2014 test Avg. Sim Avg. Real TFCNN BASELINE 37.8 46.9 TFCNN UV 22.7 37.4 TFCNN UV_DS 21.1 35.0 Table 7 shows that data selectio n followed by model adaptation result ed in better performance than using the entire adaptation data, where a 7% and 6% relative reduction in WER was respectively obtained f rom data selection compared to using the who le data . This indicates that the data -selection process h elps to f ilter out some bad hypotheses from bein g used during adaptation . Table 7 shows that the unsupervised adaptation using data selection helped to reduce the WER, where the relative WER improvement w ere 44 % and 25% for simulated and real test data., respectively. The s ubstantial improvement o n th e simulated reverberation condition is to some extent expected, as the ad aptation set us ed in this case was the REVERB-2014 training set, which consists of simulated reverberation onl y; hen ce, it helped the model to learn that condition more than the real reverberation cond ition. 6 . CONCLUSION In this work, we in vestigated using ou tput layer activations to predict the reliability of a n eural n et’s decision and th en using that information to perfo rm data selection f or unsupervised model adaptation. We prop osed a metric, the confusion distance ( CD ), and used it to perform data selection for performing unsupervised adap tation. A lower CD reflects more confu sion in a neural net hypothesis stemming f rom the reduced d istance between the winning target and th e next most p robable target. We u sed data th at resulted in higher CD values f or d oing model adaptation and demonstrated that filtering out data with bad h y potheses resulted in relative WER improvement of 6 to 7%. In th is work, we u sed a summary CD measure ( CD avg ) for each utterance; however, the measure can also be obtained at the individual frame level, providing f rame- level conf usion information. Future studies should explore us ing a frame - level confidence measure while selecting data segments for performing unsupervised adaptation. 7. ACKNOWLED GEMENTS This material is b ased u pon work p artly suppo rted b y the Defense Advanced Research Proj ects Ag en cy (DARPA) under Contract No . HR0011- 15 -C-0037. The views, opinions, and/or findin gs co ntained in this article are those of the au thors and should not be interpreted as representing the official views o r policies of the Department of Defense or the U.S. Government. 8. REFERENCES [1] A. Mohamed, G.E. Dahl, and G. Hinton, “Acoustic modeling using deep belief networks,” IEEE Trans. on ASLP , vol. 20, no. 1, pp. 14 – 22, 2012. [2] F. Seide, G. Li, and D. Yu, “Conversational speech transcription using context- dependent deep n eural n etworks,” Proc. of Interspeech , pp. 437-440, 2011. [3 ] F. Grézl, E. Egorova, and M. Karafiát , “Furth er investigation into multilin gual training and adaptation of stacked bo ttle- neck n eural network stru cture,” Proc. o f SLT , pp. 48 – 53, 2014. [4 ] M. Karafiát, F. Grézl, L. Burget, I. S zöke, and J. Cernocký “Three ways to adapt a CTS reco gnizer to uns een reverberated speech in BUT syste m for th e ASpIRE ch allenge,” Pro c. of Interspeech , pp. 2454 – 2458, 2015. [5 ] P . Bell, M.J.F. Gales , T . Hain, J. Kilgour, P. Lanchantin, X. Liu, A. McP arland, S. Renals, O. Saz, M. Wester, and P .C. Woodland, “The M GB chall enge: Evaluating multi-genre broadcast media recognition,” Proc. of ASRU , p p. 687-693 , 2015. [6 ] J. Barker, R. Marxer, E. Vincent, and S. Watanabe, “The third ‘CHiME’ speech separation an d recognition challenge: Dataset, task and baselines,” Pr o c. of ASRU , pp. 504-511, 2015. [7 ] M. Harper, “The automatic speech recognition in reverberant environments (A SpIRE) challenge,” Proc. of ASRU , pp. 547-554, 2015. [8] K. Kinoshita, M. Delcroix, T. Yoshioka, T. Nakatani, E. Habets, R. Haeb-U mbach, V . Leutnant, A. Sehr, W. Kellermann, R. Maas, S. Gannot, and B. Raj, “The REVERB Challenge: A comm o n evaluation framework for dereverberation and recognition of reverberant speech,” Pro c. of IEEE Workshop on App lications of S ignal Processing to Audio and Acoustics (WASPAA) , pp. 1-4, 2013. [8] T. Yoshioka, A. Ragni, and M.J.F. Gales, “Inve stigation of unsupervised adaptation of DNN acoustic models with filterbank input,” Proc. of ICASSP , pp. 6344 – 6348, 2014. [9] G. Saon, H. S oltau, D. Nahamoo, a nd M. Pich eny, “Speaker adaptation of neural network acoustic models using i- vectors,” Proc. of ASRU , pp. 55 – 59, 2013. [10] S.H.K. Parthasarathi, B. Hoffmeister, S. Matsoukas, A. Mandal, N. Strom, and S. Garimella, “fMLLR based feature - space speaker adaptation of DNN acoustic models,” Pr oc. of Interspeech , 2015. [11] V. Gupta, P. Kenn y and P Ouellet, “I -vector-based speaker adaptation of d eep neural networks for french broad cast audio transcription,” proc. of ICASSP, pp. 6334 -6338, 2014. [12] D. Yu, K. Yao, H. Su, G. Li, a n d F. Seide, “KL -divergence regularized deep neural network a daptation for improved large vocabulary speech recognition,” Proc. of ICASSP , 2013. [1 3] F. Seide, G. L i, X. Chen and D. Yu, "Feature Engineering in Co ntext-Dependent Deep Neural Ne t works for Conversational Speech Transcription", in p roc of A S RU, 20 11. [1 4 ] T. Anastasakos and S.V. Balakrishnan, “The Use of Confidence Measures in Unsupervised Adaptation of S peech Recognizers,” in Proc. Int. Conf. on Spoken Language Processing, pp. 2303-2306, Sydney, Australia, 199 8. [15 ] M. Pit z, F. W essel, and H. Ney, “Improved MLLR speaker adaptation using con fidence measures for con versational speech recognitio n,” in Proc. Int. Conf. on Spoken Language Processing, pp. 548-551, Beijing, China, 2000. [1 6] K. V eselý, M. Hannemann and L. Burget, "Se mi- supervised training of Deep Neural Netw o rks," 2013 IEEE Workshop o n Automatic S peech Recognition and Understanding, pp. 267-272, 2013. [17] H. Hermansky, L. Burget, J. Cohen, E. Dupoux, N. Feldman, J. Godfrey, S. Khudanpur, M. Maciejewski, S.H. Mallidi, A. Menon, T. Ogawa, V. P eddinti, R. Rose, R. Stern, M. Wiesner, and K. V eselý, “Towards machines that know when they do not know: Summary o f work done at 2014 Frederick Jelinek Me morial Workshop,” Proc. of ICASSP , pp. 5009 – 5013, 2015. [18] H. Zaragoza , and d’A - B. Fl orence, “Confidence measures for neural network classifiers,” Proc. of the 7 th Int. Conf. Information Processing and Management of Uncertainty in Knowledge Based Systems , 1998. [19] V. Mitra and H. F ranco, “Leveraging De ep Neural Network Activation Entropy to cope with Unseen Data in Speech [2 0 ] V. Moosavi, “ Computing With Contextual Numbers ,” [21] G. Hirsch, “Experimental framework for the perform ance evaluation of speech recognition front-ends on a large vocabulary task,” 2001. [22] T. Robinson, J. Fransen, D. P ye, J. Foote, and S . Renals, “WSJCAM0: A British English speech corpus for large vocabulary contin uous sp eech recognition,” Proc. ICASSP , pp. 81 – 84, 1995. [23] M. Lincoln, I. McCowan, J. Vep a, and H.K. Maganti, “The multi-channel Wall Street Journal audio visual corpus (M C- WSJ- AV): Specif ication and initial experime n ts,” Proc. of IEEE Workshop on Automatic Speech Recognition and Understanding , 2005. [25] V. Mitra, and H. Franco, “T ime - frequency convolution networks f o r robust sp eech recognition,” Proc. of ASRU , 2 015. [26] V. Mitra, and H. Franco, “Coping w ith Unseen Data Conditions: Investigating Neural Net Architectures, Robust Features, and Information Fusion for Robust Sp eech Recognition,” Proc. of Interspeech 2016, pp. 3783-3787. [27] V. Mitra, W. Wang, H. Franco, Y. Le i, C. Bartels, and M. Graciarena . “ Evaluatin g robu st features o n deep n eural networks for speech recognitio n in noisy and channel mismatched conditions ,” Proc. of Interspeech 2014, pp. 895- 899.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment