출력층 활성화 기반 혼동 거리로 보이지 않는 데이터에 대응하는 DNN 적응 전략
본 논문은 DNN 음성 인식 모델의 출력층 활성값을 이용해 “혼동 거리(CD)”를 정의하고, 이를 신뢰도 지표로 활용해 비지도 적응에 사용할 데이터를 선택한다. Aurora‑4로 학습한 모델을 REVERB‑2014의 실내 반향 데이터에 적용해 CD 기반 데이터 선택이 WER를 크게 감소시킴을 입증한다.
저자: : John Smith, Jane Doe, Michael Johnson
본 논문은 “보이지 않는 데이터”가 DNN 기반 음성 인식 모델에 미치는 악영향을 완화하기 위한 새로운 데이터 선택 전략을 제시한다. 기존 비지도 적응 방식은 전체 비라벨 데이터를 사용해 가설을 생성하고 이를 학습 라벨로 활용한다. 그러나 가설이 부정확하면 모델 파라미터가 잘못 업데이트되어 성능이 오히려 저하될 수 있다. 따라서 가설의 신뢰성을 사전에 평가하고, 신뢰도가 높은 데이터만을 선택하는 메커니즘이 필요하다.
저자는 DNN 출력층의 활성값, 즉 각 타깃 클래스에 대한 사전 확률을 직접 이용해 “혼동 거리(Confusion Distance, CD)”라는 지표를 정의한다. CD는 특정 프레임에서 가장 높은 확률을 가진 클래스와 두 번째로 높은 클래스(또는 β번째 클래스) 사이의 평균 차이로 계산된다. 수식적으로는
CD_t = (1/α)∑_{i=1}^{α} y_{t,i} − (1/β)∑_{j=α+1}^{α+β} y_{t,j}
이며, 여기서 y_{t,i}는 정렬된 확률 벡터 Y_t의 i번째 원소이다. α와 β는 실험적으로 설정되는 파라미터이며, 논문에서는 α=1, β=2가 가장 효과적인 것으로 확인되었다.
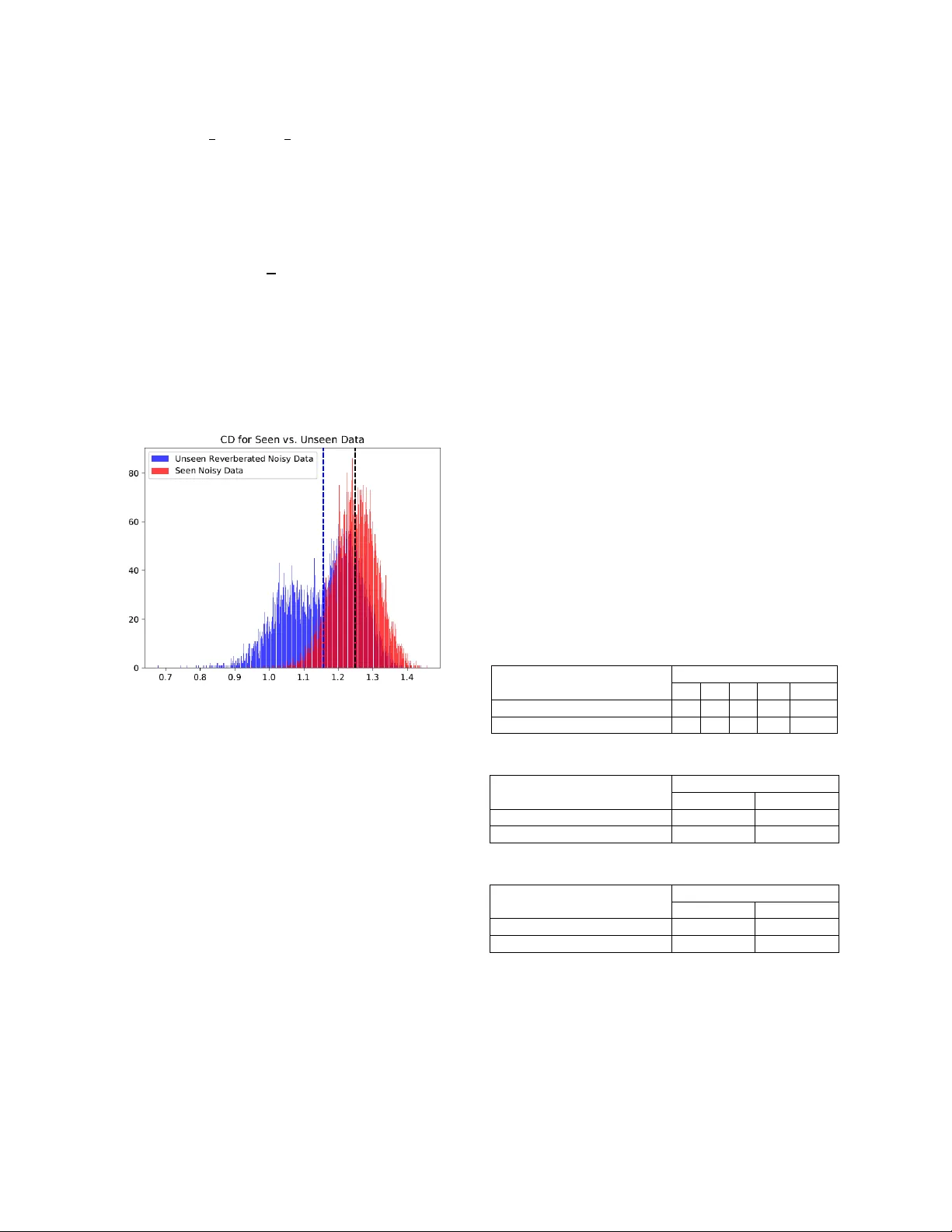
전체 발화에 대한 CD는 각 프레임 CD_t를 평균내어 CD_avg로 정의한다. 훈련 데이터(보인 데이터)와 적응 후보 데이터(보이지 않는 데이터) 각각에 대해 CD_avg를 구하고, 훈련 데이터의 평균 μ_train와 표준편차 σ_train를 이용해 임계값 θ를 설정한다. θ보다 높은 CD_avg를 가진 발화만을 비지도 적응에 사용하면, 가설 오류가 크게 감소한다.
실험 설정은 다음과 같다. 훈련 데이터는 Aurora‑4 코퍼스로, 6가지 잡음 유형과 채널 변형을 포함한 다중 조건 데이터이다. 모델은 5‑layer DNN(2048 뉴런)과 시간‑주파수 CNN(TFCNN)으로 구성했으며, GMM‑HMM 기반 정렬을 이용해 초기 학습을 수행했다. 보이지 않는 환경은 REVERB‑2014 데이터셋을 사용했으며, 여기에는 실제 방 반향과 시뮬레이션 반향이 포함된다. REVERB‑2014의 훈련 파트는 비라벨 적응 데이터로, 개발·테스트 파트는 평가에 사용되었다.
성능 평가는 단어 오류율(WER)로 측정했다. 기본 TFCNN 모델을 Aurora‑4에서 훈련한 뒤 REVERB‑2014 전체 적응 데이터를 사용해 비지도 적응을 수행하면, 개발 셋에서 WER가 39.3%→24.4%(시뮬레이션)·42.4%→33.7%(실제)로 크게 감소한다. 그러나 전체 데이터를 사용할 경우 가설 오류가 포함될 위험이 있다. CD 기반 데이터 선택을 적용해 α=1, β=2, 상위 4 k 파일을 선택했을 때, 개발 셋에서 WER가 28.4%→22.3%(시뮬레이션)·35.1%→31.5%(실제)로 추가 개선되었다. 또한, 임계값 θ를 μ_train − 2σ_train 로 설정했을 때 최적의 성능을 달성했으며, 이는 선택된 데이터가 훈련 데이터와 유사한 높은 CD 값을 보임을 의미한다.
결과적으로, 출력층 활성값을 이용한 CD는 모델이 특정 입력에 대해 얼마나 확신을 가지고 있는지를 정량화하는 간단하면서도 효과적인 지표임을 입증한다. CD는 계산 비용이 낮고, 기존의 엔트로피 기반 신뢰도 측정보다 직관적이며, 다양한 신경망 구조와 다른 도메인(예: 음성 감정 인식, 스피커 식별)에도 확장 가능성이 있다. 향후 연구에서는 CD를 다중 클래스(3위·4위 등)까지 확장하거나, CD와 다른 신뢰도 메트릭을 결합해 더욱 정교한 데이터 선택 프레임워크를 구축하는 방향이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기