Masked Conditional Neural Networks for Automatic Sound Events Recognition
Deep neural network architectures designed for application domains other than sound, especially image recognition, may not optimally harness the time-frequency representation when adapted to the sound recognition problem. In this work, we explore the…
Authors: :
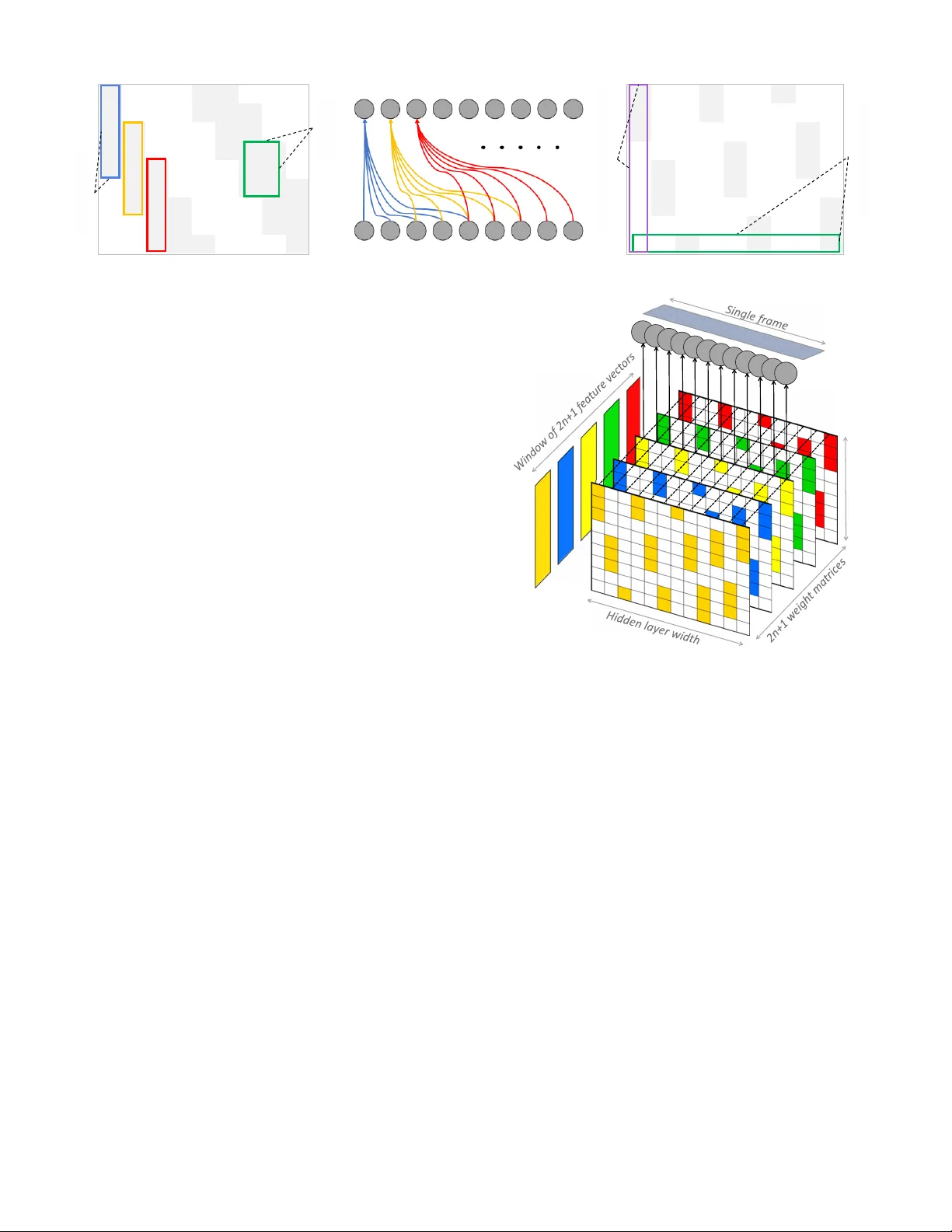
Masked Conditional Neural Networks for Automatic Sound Events Recognition Fady Medhat D avid Chesm ore John Rob inson Department of E lectronic Engineering University of York , York United Kingdom {f ad y. medhat, da vid . chesm ore , john.rob inson}@york.ac.uk Abstract — Deep ne ur al ne t w o r k architect ures desig ned for appli cati on do mai ns othe r tha n soun d, es pecially image recogniti on , may not o pti mall y har ness t he ti me - freq uency repr ese ntat io n when a dapt ed t o the s ound r eco g nit i on probl e m . In this w ork , w e ex pl ore the ConditionaL Neural Network ( CLNN ) and t he M as ked Co ndit i onaL Neu ral N etw or k (M CLNN ) 1 for mul t i - di mensi on al te mpo ral sig nal re cog nit ion. T he CL NN considers t he inter - f r a me rel ati ons hi p and the M CL NN enf orc e s a sy stematic s parseness o ver the netw ork’s lin ks to enable lear ning in fre que ncy ba nds rat her th an bi ns al low i ng the net w ork to be freq uency s hift inv aria nt m im ick in g a f ilterban k . T he mas k a lso allow s cons ideri ng se veral co mbinat ions of fe atur es c onc urre ntly , w hich is usua lly ha nd crafted t hr ough e x haust ive manual sear ch . We appli ed t he MCLNN t o t he environm ental so und re cogni ti on probl e m usi ng the ESC- 10 and ESC - 50 datasets . MCLNN achieved c ompetitiv e perfor mance, using 12 % of the parameters and w i thout aug me ntat io n, compar e d to state- of -the- art Convol utio nal N eural Ne t w o r ks . Keyword s — Restricte d Boltzmann M achine ; RBM ; Condition al RBM ; CRBM ; Deep Beli ef Net ; DBN ; C on diti onal Neural Netw ork ; CLNN ; Mas ked C ondit io n al N eural N etw ork; MCLNN; ES R; I. I NTRODUCTION Sound recog nition is a wide resea rch fiel d that combin es tw o broad area s of res earch ; signal processing and patt ern reco gnition. One of the very early attempts in so und recognitio n, especi ally s peech , w as in th e work of Davis et al. [1] in 1952. In their work, they devi sed an analog ci rcui try f or spoken digits’ reco gnition . Their attem pt marks a very early interest in the sound reco gnition pro blem . Ov er the y ears, th e methods ha ve evolved to involve not j ust speech, but music and environment al sound recognitio n as well. This int erest was b acked - up with the wid e spr ead of related applica tions. For exam ple, t he usa ge of music sharing pl atforms or applica tions of automatic environmenta l so und recogni tion for surveilla nce [ 2 , 3] especi ally w h en low lighting c onditions hinde rs the ability of the video cha nnel to capture useful i nformatio n. Hand crafting the f eatures ext ract ed from a sig nal, imag e or sound, has been widely investigat ed in rese arch . Th e effort s invested aim t o provide dist inctive feat ures that can enhance the reco gnition acc uracy of the pa ttern r ecognitio n mode l. Rece nt attempt s using deep neur al net work s have achieved brea kthroug h results [4] for image recognitio n . T hese d eep models m anag ed to abstr act t he featu res of a raw input signal over multiple neural network layers . The extrac ted featu res are further classified us ing a conventiona l classifier such as Random Fo res t [5] or Support Vector Ma chines (SV M) [6] . An attempt to use the deep neural n et wo r k archite ctures f or automatic fe ature extract ion for sound wa s i n t h e wo r k o f Ha me l et al. [7] . In the ir wo r k , they used thre e stac ked Restr icted Boltzm ann Machines (R BM) [8 ] to f or m a Deep B el ief Net (DB N) [9] arch ite cture. They used the DBN fo r fea ture extracti on from m usic clips . The extr acted featu res w ere fur ther class ified using a n SVM . They showed i n their work t he abstrac t represen tati ons ca pture d by the R BM at ea ch lay er whi c h conseq uently enhance s the classifica tion compared to using the raw tim e - frequen cy re presen tation . Deep ar chite ctures of C onvoluti onal Neura l N et wo r k s (CNN ) [ 10 ] achieved remarkab le results in image recogni tion [4] . Also, the y got adap ted to the sound recognition problem . For exam ple, CNN w as used in [ 11 ] for phoneme recognition in speech, w here the CNN w as used to ex tract t he fe atures , and the state s’ tran sition s wer e mode led using a Hidd en Markov Mode l ( HMM ) [ 12 ]. Hand cra fted feature s for sound are still supe rior in most context s compared to employing neur al networ k s as fea ture extract ors of im ages, bu t the a ccur acy ga p is getting na rrower. T he m otivation behind usi ng neural ne tworks aim s to elimin at e the effor ts invested i n ha ndcrafti ng the most eff icient fe atures for a sound si gnal. Several n eural bas ed archi tect ures h ave been prop osed for the so und rec ognition problem, b ut usua lly , t hey ge t adap ted to sound after they gain wide succe ss in other applica tions especi ally im age recog niti on. The ad apt atio n o f s uc h m od els to sound may not harness its related propert ies in a tim e - frequen cy re presentatio n. For e xample , an RBM tre ats th e tem poral s ignal fram es as stat ic , isol ated fram es, ig noring the inter - frame re lat ion . The CNN depends on w eight sha ring, which does not pre serv e the sp at ial locality of the learne d features. We discuss in this wor k , the Condi tionaL Neural Netw or k (CLNN) that is designed for m ultidimensional t emporal signa ls. T he Maske d Condition aL Neu ral Netw ork (MCLNN) e xtends upon the CLNN by em bed ding a filterb ank - like behavior w ithin the network through e nforcing a systemati c sp ars e ness over the network’s weights . T he filte rb ank - like pattern al lows t he 1 Cod e: https: //githu b.co m/fa dymedh at/ MCL NN This wo rk is f un ded by the Europe an Unio n’s Seven th Framew ork Programme for r esearc h, t echnologi cal develop ment and demons trati on under grant agreement n o. 6080 14 ( CAP AC IT IE ). network to e xp lo it per formance adv antag es of filterbanks used in signal analysis such as freque ncy shift - inva riance. Additionally , t he m ask ing opera tion allow s an automatic ex ploratio n of a r ange o f feature com binati on s concurrently analogo us to the man ual f eatur es s elect ion to be used for classif icat ion. T he mod el s we disc uss in this wor k have been cons idered in [ 13 ] for music gen re classif ication w ith more e mph a s is on t he influence of the data split (training set, validatio n set and testing set) o n the repor ted accur aci es in the lit era tur e . I n t h i s wo r k , we evaluat e the app licab il i ty of th e mod els to sou nds of a di ff er ent nature i.e. environmental so unds. II. R ELA TED W ORK The Restricted Boltzm ann Machine (RBM) [8] is a gener ati ve mod el t hat unde rgo es a n uns uper vise d tr aini ng. The RBM is fo r me d of two la yers o f neuro ns, a vi sibl e and a hid de n layer. The two layers are connected using bidirec tional connections across them with the absen ce of connections between neurons of the same later. An RBM is trained us ing contr asti ve diver ge nce [ 14 ] aiming to m inimize the error bet ween a n i nput feat ure vec tor intr oduc ed t o the net wor k at t he visible layer and the reconstructed versio n o f the gene rat ed vecto r fro m t he net wor k. We referred earlier that one of th e drawbacks of applying an RBM to a temporal signal i s ignoring the te mporal dependencies between the sign al’s frames. The C ondi tio nal Restricted Boltzmann Machine (CRBM) introduced by T a yl o r et al. [ 15 ] extended the RBM [8] for tem poral signal s by adapting conditio nal lin ks from the pr evious visible inp ut to consider their infl ue nce o n the net work ’s curr ent inp ut . Fig. 1 shows a CRBM with the RBM rep resented by the visible and h idden la yer s wit h bidirectio nal connec tio ns going acro ss them. The CRB M i nvo lves t he cond itio nal li nks fro m the pre vious vi sib le input states t o both the hidd en la yer a nd the curr ent visible inp ut . T he links be twee n the pre vio us i nput and the hiden layer are depicted by ( , , …, ). T he autor egr essi ve lin ks be twee n p revio us vi sib le inp ut and t he current one are depicted by ( , , …, ). T he CRBM was appl ied on a m ulti - channel temporal signal to model huma n motio n thro ug h the j oint s mo veme nts. M oha med e t al. [ 16 ] applied t he CRBM to th e phonem e recogn ition task and t he y extend ed the C RB M in t heir wo rk with the Int erp ola ting CRB M (ICRBM) that co nsiders the fu ture frames i n addition to the p ast ones. T hey sho wed in their work t he outpe rforman ce of apply ing th e ICRBM com pared to the CR BM for t he phon eme recognitio n tas k. The Conv olution al Neural Networks (CNN) [ 10 ] sho wn i n Fig 2 de pen ds on tw o mai n ope rati ons: C onvol uti on and Pooli ng. In the c onvolutio n, the 2 - dimensio nal inp ut (an image) is scanned w ith several small sized w eight matrices (fil ters), e .g. 5×5 in size. Eac h filter behaves as an edge detector on t he inp ut image. T he o ut put of the convolutional layer is a number o f feature map s matching t he number o f filters used . The pooling stage i nvolves decreasi ng the resol ution of the gener ated feature maps, where mean or max pooling are usua ll y u tiliz ed in this r egar d. Seve ral of thes e tw o lay ers are inte rleave d to f orm deep archite ctur es o f neural networks, wher e the output o f the final stage is flattened to a single feature ve ctor or globally pooled [ 17 ] to be f ed to a fully connected network for the cla ssificatio n decisi on. CNN ass um es that a f eatu re in a region of th e inp ut has a high probab ility of being lo cated in ot her locations acro ss the ima ge . Accor dingly, weight shar ing is the fund amental co nc ept of t he CN N, which pe rmitted app lying neural networ ks to images of large size s w itho ut having a dedicated weight for each pixel. The notio n of weight sharing worked well for imag es , but it doe s not pre serve the spa tia l loca lity of th e lear ned fe ature s. Spatial lo cal ity of the f eatures is an im portant consideration for sp ec tr o gr a ms o r t i me - frequ ency representat ions in ge neral . T he loca tio n of the le arned fe atur es sp ecifi es the sp ectr al compo nent , where the same en ergy va lue may re fer to di fferent freque ncies depen ding on the positi on at which it was detected . Thi s induced a ttempts [ 18 ],[ 19 ],[ 20 ], [ 21 ] , to ta ilo r the C NN filters to the nature o f the sound signa l in a time - f requency represen tation in sound reco gnition fo r speech, e nvironmental s o und s and music. III. C ONDITIONAL N EUR AL N E T WOR KS The Con diti onaL Neu ral N etw ork ( CLNN ) [ 13 ] i s a discriminative model desi gned for temporal si gnals. The CLNN extend s from the visible to hidden links proposed in the CRBM . Additionally , the C LNN considers the future fra mes in addition to the p ast ones as in the IC RBM. The CLNN tak es into co nsider atio n the co nditiona l influence, the frames in a window have o n the win d o w’ s m iddle fra me , where the pre dic tio n o f the central fr a me is c ondi ti on ed on near by fram es on either side o f it . The input o f a CL NN i s a w indow of d fram es, where d = 2 n + 1. The or der n specif ies the f rames to c onsi der on eith er side of the w indow ’s middl e f ram e ( t he 2 is to acco unt for a n equal numbe r of fra mes in the past an d t he fut ure and the 1 is f o r the w indow ’s m iddle f rame) . The hidden lay er of a CLNN is an Fig . 1. Co nditio nal Restr icte d Boltz m ann Ma chine Fig. 2. Convolut ional Neu ral Network e - dimensio nal vector o f neurons. Accordi ngly, a CLNN gener ates a single vector of e - dim ensions for each pr ocess ed win dow of f ram es . T he a ctivatio n of a singl e node of a CL NN is give n in ( 1) where , is the activati on of n ode j of th e hid den lay er and the index t refers t o po sition o f th e frame within a se gment ( a chunk of fram es w ith a m inimum size equ al t o the w indow disc ussed later in deta il) , is the transfer functio n and is the bias of the neuro n. , is the i th featu re o f the l dimens ional input feat ure vector at inde x u + t of th e w indow . The fram e’s in dex u in the window range s from -n up to n , whe r e t is the w indo w’s m iddle fram e and in the sam e time, th e index o f th e fram e in the segment. , , is the w eight betw een the i th featur e of th e inpu t feature vec tor at index u a nd j th hidden node. The vector form of the hidden layer activati on is formulate d in (2) where is activ ation of the hi dden layer for the frame at i nd ex t o f the input segment together w ith n frames on either of its sides . f is the transfer func tion and is the bias vector. is the inpu t featu re vector a t in dex u + t , w here u is t he index of the frame in the window and t is the in dex of the window’s middle fram e in the segment. is the weigh t matrix at in dex u wi thin t he windo w. Accordingl y, for a windo w of d frames a corres ponding num ber of w eight m atrices are present in the weight te nsor, where a vector - matrix m ultiplication operation is applied between the ve ctor at index u a nd its c orrespond ing weight m atrix a t index u in th e w eight t enso r. The si ze of each weight m atrix is [ feature vecto r length l , hidden layer width e ] and the count of matrices is equal to 2 n +1. The hidde n layer’s activ ation v ector using a logi stic transfer function is the conditional dist rib ution o f the predi ction for windo w’s middle frame cond itioned on the order n frames o n either side. The re lat ion is formulated as: ( | , … , , , , … , ) = ( … ) , wh ere is a sigmoid function or the output softmax lay er of th e discrimin ative m odel. Fig. 3 shows tw o stacked CL NN layers. Each C LNN l ayer possesses a weight tensor of size [ fea tu re ve cto r le ng th l, hidd en laye r wid th e, window size d ] scanni ng the multidimens ional i n the tempo ral dir ec tio n . T he dep th d o f the tensor matches th e window size. Acc ordingly, for order n= 1 , the de pth is 3, for n=2 the dept h is 5 and for orde r n the dept h is 2 n+1 as t he window size. At ea ch lay er , th e num b er of fram es dec reases by 2n fram es . T heref ore, the size of t he input segment f ollows ( 3) to account for t he numbe r of fr ames re quired a t the i nput o f a deep CLNN ar chitect ure . wher e t he q is the num ber of f ram es in a seg men t , m the number of layers an d k is the extra f ram es that should r emai n after the stacke d CLNN layers . These k fram es can be f latt ened t o a sin gle feature vector or pooled a cross b efore introd ucing t hem to a fully connect ed network as shown in Fig. 3. For exam ple, at n = 4, m = 3 (th ree CL NN layers ) and k =5, the in put at the fi rst layer is (2×4 ) × 3+5 = 29. Therefo re, th e outpu t size of the first layer is 29 – ( 2×4) = 21 frames. T he output at the seco nd layer is 21 – (2×4 ) = 13 frames. Finall y, the output at the third layer is 13 – (2×4 ) = 5 fr ames. Thes e remai ning 5 frames a re introd uced to the fully connect ed layer after pooling or flattening to a single vector . IV. M AS KED C OND ITIONAL N EUR AL N ETWORKS Raw tim e - freque ncy repr esentat ions s uch as s pectr ogram s are used widely for signals analysis. They pro vide an insi ght of the cha nges in the energy across differe nt frequenc y bins as the signal progr esses through time. Due to their sensitivity to frequen cy f luctuat ions, a small s hift in the e nergy of one frequenc y bin to a neighbori ng freq uency b in changes th e fi nal spect rogram represen tati ons. A filterbank i s a gr o up o f fi lte r s that allows subdi viding the freque ncy bins, meanwhile aggre gating the energy of each group of freque ncy bins into ener gy b ands. T hu s, suppr essing the effect of the energ y sm earing ac ross fre quency b ins in proximity to each other to prov ide a tra nsfo r matio n t hat is freque ncy shift - invar iant. For exam ple, th e Mel - scaled filt erbank is f or me d of a group of filt ers having their cent er freq ue ncies M el - spaced fro m each o ther to follow the human aud i tory s ys tem perce pti on of t ones. Mel - scaled filterbanks are us ed i n M el - scaled transformatio ns such as MFCC and M el -S pect rogr am both used w idely by recognition systems as inter m ediate signal representa tions , The Mask ed Con ditionaL Ne ural Netw ork (MCLNN) [ 13 ] extend s upon the CLNN a nd stems from the filterbank by enforci ng a systematic sparseness over the network’s weig hts that foll ows a ban d - like pa ttern using a co ll ect ion o f ones and zer o s a s i n F ig . 4 . T he m asking embeds a filter bank - like beha vior within t he network, which induc es the network to learn about freq uency band s rather than bi ns. Learning in band s , = + , , , (1 ) = + · (2 ) = ( 2 ) + , , 1 (3) Fig . 3. A tw o laye r CL NN mode l w ith n=1 CLNN of n = 1 CLNN of n = 1 Feature vectors with 2n fewer frames than the previous layer k central frames Result ant frame of the Mean/Max pooling or flattening operation over the central frames One or more Fully connect ed layer Output Softmax preve nts a hidde n node from being distracted by learning about the whole inp ut feature vector but instead allo ws a neuron to focu s on a spe cific regio n in its field of obser vation, which permits distinctive features to dom inate. The m ask design depen ds on tw o tun eabl e h yp er - param eters : the Ba ndwidth and the O verlap. T he Band width cont rols the numbe r of successive 1 ’s in a co l umn , and t he O verl ap con trol s t he super posi tion distan ce betw een o ne column and another . Fig. 4 .a. sho ws a mask having a ba ndwidth of 5 , wh ich ref ers t o the enabl ed featur es in a vect or and a n overlap of 3 . F i g. 4 .b shows the enabled network connec tions that ma p to the pattern in Fig. 4 .a. The overl ap can be assi gned negative values as in Fi g. 4 .c , wh e r e an ov erla p of -1 refers to the non - overlappi ng distance b etween succe ssive columns. The linear s pacing of th e binary pattern is formulated in (4 ) wher e t he line ar index lx is controlle d by the band width bw , the over lap ov a nd the feature vector length l . T he val ues of a are within [0, bw - 1] and g takes valu es in the int erval [1, ( × )/ ( + ( )) ]. T he handcraft ing o f the opt imum feature s com binat ion involve s a n e xhaustive mix - and - match process aiming to find the ri ght combi nati on o f f eatures that can i ncre ase t he recognit io n a ccuracy . Th e m ask autom ates thi s process b y embedd ing several shi fted version s o f t he filt erbank that allo ws combini ng dif feren t f eatures in the s ame in stan ce. Fo r exam p le, in Fig. 4 .c , ( the number o f col um ns represent s the hid den layer width) the fir st neuron in the hidd en layer fo cus es on lear ning about t he 1 st three fea tu res of the in p ut f ea ture ve ctor . Similar ly, the fourt h neuron (mapp ed to the 4 th c olumn in the mask) will learn abo ut the first two featu res , a nd the 7 th ne uron wi ll learn about one fea ture . The masking o peratio n is applied thro ugh an element - wi s e multip lication between t he mask and each weight mat r ix present in the weight tens or following ( 5 ). = (5) where is the matrix of si z e [ l, e ] at index u in a tenso r of d weight m atrices , is the masking pattern of size [ l, e ] and is the masked weight matrix to substi tute the in ( 2 ) Fig. 5 shows a single step of an M CLNN, where fo r a win dow of 2 n+ 1 frames a weight t ensor o f a matching de pth is processi ng the f rames in the w indow. F or each f eatur e vec tor (fram e) at a certain ind ex , a cor respondi ng matrix is processing it. T he output of a single step o f an MCLNN is a single represen tativ e ve ctor r epresen tation. The highlight ed cells i n e ach matrix represe nt the masking pattern desi gned using the B and wi dt h and t he Ove r lap . V. E XPER IMENTS We us ed t he ESC - 10 [ 22 ] and the E SC - 50 [ 22 ] datasets of environmenta l sou nds to eval uate the perform ance of the MCLNN. Bo th datasets are releas e d into 5- folds . The file s are of 5 seco nds each with files containing e vents shorter than 5 s econds padded with sile nce as descr i b ed i n [ 22 ] . As an init ial pre proc essi ng s te p, w e trimmed the silence and cloned each file several times. We extr acte d 5 seconds from each of the cl oned files. All files are res ampled at 22050 Hz, followed by a 60 bin logarithmic M el - scaled spectrogram tra nsformatio n using an FF T win dow of 10 24 an d a 50% over la p w ith the De lta ( 1 st deriva tive between frames acr oss the tem p oral dim ension). We con catenated the 60 bins and their de lta column - wise r esu lting in a feature vector of 120 bin. W e ex tract ed se gments of si ze q from each spectro gram following (3 ). All experiments follo wed the 5 - fold cr oss - val id atio n to unify r eporti ng the ac curacies b y elimi nating the influe nce of the da ta split. T he training fol ds wer e standardized to a zero mean and unit variance feat ure - wi s e , = + ( 1 ) ( + ( ) ) (4 ) Feature vector length 1 0 0 0 1 1 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 0 1 1 1 0 0 1 0 0 1 0 0 0 0 0 1 1 0 0 0 1 1 0 0 1 0 0 0 0 0 0 1 0 1 1 0 0 0 1 1 1 0 0 0 0 0 1 0 0 1 0 1 1 1 0 0 0 1 1 0 0 1 0 0 1 0 0 1 0 0 1 1 0 0 0 1 1 1 0 1 0 0 1 0 0 0 0 0 1 1 1 0 0 0 1 1 0 1 0 0 0 0 0 0 1 0 0 1 1 0 0 0 1 1 0 0 0 0 0 1 0 0 1 a. 0 0 1 1 1 0 0 0 1 b. c. 0 0 1 0 0 1 0 0 1 Fig . 4 . Ex am ple s of the M ask p atte rns. a) A bandw idth o f 5 wit h an o ve rl ap of 3 , b) The all ow ed co nnec tions matchi ng the m ask in a . across th e neurons of two laye rs, c) A bandw idth of 3 an d an o ve rl ap of -1 Bandwidth Overlap Feature vector leng th Hidden layer width and the training para meters wer e used to st andar dize t he testing and valid ation sets. We ad opted tw o MCLNN layers wit h hy perparam eters l isted in Tabl e I. The MCL NN lay ers a re foll ow ed by a g lobal pooli ng layer as studied in [ 17 ] , bu t for the so und , it is a s ingle dimensio nal mean global poo ling layer. The pooli ng across the tempor al dim ension beh aves a s an aggr egation oper ation , w hich enhances the accu racy as stu died by Be rgst ra in [ 23 ] . Following the MCL NN lay ers ar e tw o dense ly con necte d lay ers of 100 neuro ns each before the final softmax output layer. We used Parametric Re ctified L inear Units [ 24 ] f or the act ivat ion functio ns. Dropout [ 25 ] as a regula riz er. T he mod el was t rain ed to minim ize the catego rical cross - entropy betw een the predict ed and th e act ual l abel of each s egm ent of f ram es usi ng ADAM [ 26 ] . Probabil ity voting across the clip’s fra mes was used for the catego ry de cision. We used FFmpeg [ 27 ] for the file s cloning and LibRO SA [ 28 ] for the signal transfor mation. For the model implem entation , we used T heano [ 29 ] and Keras [ 30 ] A. ESC - 10 The d ataset is com pose d of 400 files for 10 e nvironmenta l sound categ o ries: D og B ark , R a in , S ea W av es , B ab y C ry , C l ock T ick , P erson Sneeze , H elicopte r , C hai nsaw , R o os ter a nd F ir e C racki ng . The 400 sound files are equ al ly d is trib ut ed among the 10 clas ses w ith 40 cli ps per cat egory . For t he ESC - 10, We used k = 1, which le aves the windo w’s middle fram e rem ainin g afte r the MCL NN lay ers to be fed t o two fu lly connected layers . The human reco gnition accur acy for the dataset is 95.7% , and a baselin e accu racy of 72.7% w as achie ved using Rando m Forest to classify MFCC fr ames in [ 22 ] . Table I I list s the m ean accu raci es ac ross a 5 - fo ld cros s va lida ti on on t he E SC - 10 datas et . The work of Piczak [ 31 ] achieved 8 0% us ing a deep CNN archite ctur e. The Piczak - CNN i s for me d of tw o convolu t ion al and two pooling layers fo llowed by two fully connect layers of 5000 ne uro n s ea ch resulting in a mod el containing o ver 25 million parameter s . Piczak u sed 10 augmentat ion variants for ea ch sound clip in the ESC - 10 dataset . Augmenta tion invo lves introducing deformations to the s ound files such as tim e delay s and p itch s hifting. Aug mentation increases the datas et si ze, which conse quently increase s the gen e rali zation of the m odel and e ventua lly the accu r acy as stud ied by Sal amon in [ 21 ] . W e did not co nsider augmentat ion as it is not re levant in benc hmarking the M CLNN performance agai nst other models. On the other ha nd, the MCLNN outper formed Picza k - CNN accuracy using 3 million param eter s achie ving 83% without augmentati on. T o furt her e nsure that MC LNN accura cy is not influ enced by the int ermedi ate rep resent ation , we adopted the spect rogram trans formati o n u sed fo r the Piczak - CNN (60 bin M el - spec . and delta). T o evaluate the influenc e o f t he mask abs ence in the CLNN, w e used the exact archi tectu re of the MC LNN. T he CLN N achieve d an accu racy of 73.3% compare d to the 8 3% achie ved by th e MCL NN of the s ame a rchitecture , w hich sh ows the eff ect of the maski ng operat ion due to the pr operties discu ssed earl ier . Fig. 6 s ho ws the conf usio n across t he ES C - 10 dataset using the MCL NN. Clock Ticks is confus ed with Fire Cracki ng and Rain, which co uld be due to the short event dura tion. T here is also apparent confusio n between the Helicopter sound and the rain, which is ac coun ted to th e c omm on low tona l com pone nt s across the two categ ories. B. ESC - 50 The dataset is fo r me d of 2000 e nvi ronmen tal sou nds cli ps evenl y dis trib ute d ac ro ss the 50 classes of t he fol lo win g five broad categories : A nimal s ounds : Hen, Cat, Frog, Cow, Pig , Rooster, Dog , Sheep , …etc. N atur al soundscapes and w ater s ounds e.g. Sea waves, Rain, Thunder storm, Cric kets, Chirping bir ds, …etc. Human (non - speec h) sounds e.g. Sno ring, T oo th br ushing, Laug hing, Foo tst eps, Coughing , Breath ing, …etc. Domest ic sounds e .g. Glass breaking , C lo ck Tic king , C lock Alar m , Vacuum cleaner , Wa shing ma chi ne , …etc. Urban nois e e.g. Airplane , T ra in, E ngine , Car ho rn, Sire n, … etc. The m odel we a dopted for t he ESC - 50 is the sa me o ne we used for the ES C - 10 dataset except for the order n = 14 and k = 6. T he spectrogram transform ation followed the same transfor mation em ploy ed by P icz ak i n [ 31 ] as d escribed earlier. TA B LE II P ERFORMANCE ON ESC - 10 DATASET USING M C LNN COMP ARED WITH OTHER ATTEMPTS IN THE LITERATURE Cla ssi fier and Featu res Acc . % MCLNN + Mel - Spec. with out Augmentatio n (this work) 83.0 Piczak - CNN + Mel - Spec. with Augm enta tion [ 31 ] 80.0 CLNN + Mel - Spec. with out Augm ent a ti on (this wo rk) 73.3 Random F orest + MFCC withou t Augme ntatio n [ 22 ] 72.7 TA B LE I MC LN N H YPER - P ARAMETERS La y er Typ e Nodes Ma sk Bandw idth Ma sk Overl ap Order n 1 M C LNN 300 20 -5 15 2 M C LNN 200 5 3 15 Dog Bark(DB ), Rain (Ra), Sea Waves (SW), Baby Cry(BC), Clock Tick(CT), Per son Sneez e(PS) , Helico pter(H e), Chains aw(Ch) , Rooster (Ro) and Fire Crackin g (FC) Fig . 6 . Conf usio n matrix for the ESC - 10 datase t. Table III lists the mean accuracies of a 5 - fold cros s - validati on achieved on the ESC - 50 dataset . MCLNN ach ieved 61.75% with out augme ntation and using 12% of th e 25 mil lion parameters e mp l o y ed in th e Piczak - CNN. The CNN m odel used by Picza k in [ 31 ] is th e same mode l applied to the ESC - 10 dataset . Additionally, P iczak applied 4 a ugmenta tio n varia nts for each sound clip in t he E SC - 50 dataset , which in creases the accuracy as discus sed earlier. T he CLNN achieved 51 .8 % com pared to th e 61.75% ac h ieved us ing a n MC LN N, whi c h supp ort s simi lar fi ndi ngs r ega rdi ng the maskin g in flue nce on the results repo rted for the ESC - 10 . VI. C ONCLUS ION AND F UTUR E W ORK We have explored the po ssibility of a pp lying t he Condi tion aL Neural N etwork ( CLNN ) designed f or temporal signals, and it s varian t t he Mas ked Cond itio na L Ne ural Network (MCLNN) for environm ental soun d recogn ition. T he CLNN is train ed over a window of frames to preserve the inter - frames relatio n, and the MCL NN exte nds th e CLNN th rough the use of a masking operation. The mask enforces a s ystematic spar senes s o ver the net wor k li nks, i nduc ing t he ne two rk to lea rn about freq uenc y band s ra the r t han bi ns. Le ar ning i n ba nd s mimic s the beha vio r o f a filter bank a l lo wing t he ne two rk to be freq uenc y shi ft - invaria nt . Additionall y, the mask design allows the co nc urre nt e xplo rati on o f se vera l f eat ures combinations anal ogous t o ha ndc rafti ng the op timum combinat ion of features for a classif ication problem. We evaluated th e MCLNN on the ESC - 10 and th e ESC -5 0 dataset s of envi ronment al soun ds. The MCLNN achieved competitive accuracies compared to state - of - the - art Co nvo lutio na l Ne ur al Ne twor ks . MCLNN used 12% of the parameters used by CNN architectures of a similar depth. Addit ionally , MCLNN did not us e augmen tation a dopted by the CNN attempts f or the referenced datasets . Fut ure wor k will consider deeper MCLNN architectures an d different masking patterns. We will also consider applying the MCLNN to other multi - cha nne l te mpora l si gnal s o ther t han sp ect ro gra ms. R EFERENCES [1] K. H. Dav is, R. Biddulp h, an d S. Bal ashek, " Autom atic Reco g ni tion of Spoke n Dig its," Jou rnal of the A cous tic al Soc iet y of Amer ica, vol. 2 4, pp. 6 37 - 642, 1952 . [2] M . Cowlin g, "Non - Spee ch E nviro nm ental Sou nd Cl ass ific ati on Sy stem for Aut onomou s Surveillan ce," Ph. D., Facu lty of Engi neerin g and Informat ion Tech nolog y, U nive rsity of G riffith, 20 04. [3] M. Crista ni, M. Biceg o, and V. Muri no, " Audio - Visual Event Reco gnit ion in Sur ve ill ance Vide o S eque nce s," I EEE Tra nsac tions on Multi media , vol. 9, p p. 2 57 - 267, 2007. [4] A. Kriz hevsky , I. Sutske ve r, and G . E. Hi nton, "I m ageNe t Clas sifica tion wit h Dee p Convol utio nal N eura l Ne tw orks," i n Ne ural I nformat ion Processing Systems, NIPS , 2012. [5] T. K. Ho, "The Ran dom Subs pace Meth od for Con structin g Deci sion Forests," IEEE Tra ns acti ons on Pa tte rn A nal ysis and M achine Intell ige n ce, vol. 20, pp. 83 2 - 844, 1 998. [6] V. Vap nik a nd A . L erne r, "Patte rn re cog nitio n us ing gene ralize d por trai t met hod," Automat ion and Remot e Contro l, vol. 24 , pp . 774 – 7 80, 1963. [7] P. Ham el and D. Eck , "Lear ni ng Fea tu res From M u sic Au di o With Deep Beli ef N etwor ks," i n I ntern atio nal So ciety for Mus ic I nform ation Retrie val Confer ence, I SMIR , 2010. [8] S. E. Fahl man, G . E. H inton, a nd T . J. Se jnow ski, "Mass ively Parallel Ar chitecture s for Al: NETL, T h istle, an d Bol tzmann Mach ines," in Natio nal Confe rence on A r tific ial I nte llig ence, AAAI , 1983 . [9] G. E. Hinton an d R. R. Sa lakhutdin ov, "Redu cing th e Dimensiona lity of Data w ith Neur al Ne two rks," Scien ce, vol. 313 , pp . 504 - 7, Jul 28 2006. [10] Y. L eCun, L. Bo ttou, Y. Beng io, and P. Haf fner, " Gradie nt - based learni ng appli ed to docu ment recogn ition ," Proce edings of the IEEE, vol. 8 6, pp . 22 78 - 2324, 1998. [11] O . Abde l - Ha mi d , A. - R. Mohamed , H. Jia ng, L . De ng, G. P enn, an d D. Yu, " Conv ol utio nal N eur al Networks for Speech Recogn ition, " IEEE /ACM Tra nsa cti ons o n Au dio , S peec h an d Lan gua ge Pr oce ssi ng, vol. 2 2, pp . 15 33 - 1545, Oct 20 14. [12] L . Rabiner and B. Ju ang, "An I ntro ductio n To Hid den Mar kov M ode ls ," IEEE ASSP Magazine , vol. 3 , pp. 4 - 16, 1986. [13] F . Me dhat, D. Chesm ore , and J. Rob inso n, " Maske d Co nditio nal N eura l Netw orks for A udio Classif icatio n," in Internationa l Conf erence on Art ificia l Neu ral Netw orks (ICANN ) , 2017 . [14] G . E. Hinton, "Traini ng Produc ts of Experts b y Minimi zing Cont rasti ve Div erg enc e," Neural C omp utat ion, vol. 14, pp. 1 771 - 800, Aug 2002. [15] G . W. Ta ylor, G. E . Hint on, and S. Roweis , "Mod eling Hum an Moti on Using Bi nary Lat ent V aria bles," in Ad vanc es i n Ne ural Inf orm atio n Processing Systems, NIPS , 2006, pp. 1345 - 13 52. [16] A. -R . M ohamed and G. Hinton, "Phone Rec ogniti on Using R estricted Boltzm ann Machin es " in IEEE Inte rnationa l Conf erence on Acoustic s Speec h and Signa l Process ing, ICASSP , 2010 . [17] M. L in, Q. Chen , an d S. Yan, "Ne tw ork I n Netwo rk," in Interna tiona l Con feren ce on Lear ni ng Re pres ent ati ons, I CL R , 2014 . [18] C. K erel iuk, B. L . Sturm, and J. L arsen, "De ep L earning and M usic Adversaries, " IEEE Tr ansacti ons on Mult imed ia, vol. 17, pp. 2059 - 2071, 2015. [19] J. Po ns, T . L idy, and X . Ser ra, "Expe rime nting w i th Mu sically Motiv ate d Co nvo luti onal Neur al N et w orks," in Internationa l Wor kshop on Cont ent - base d Mult ime dia I ndexi ng, CB MI , 2016. [20] P. B arro s, C. W eber , and S. W ermte r, "L earning Audito ry Neural Represen tati ons for E motion Rec ognition, " in IEEE Interna tion al Join t Conf ere nce on N eural Net wor ks (I JC NN/W CCI) , 2016 . [21] J. Salamon an d J. P. Bello, "D eep Con voluti onal Neura l Networks an d Data Augmentati on for Envi ronment al Sound C lassifi cation ," IEEE Signal Processing Letters, 2016. [22] K . J. Picz ak, "ES C: Dat aset fo r Env ironment al So un d Cl assif ica tio n," i n ACM Inte rnation al confe rence on Mult imedia 201 5, p p. 1015 - 1018. [23] J. Berg str a, N. Casa grand e, D. Erhan , D. E ck, an d B. Kégl , " Aggrega te Feature s A nd AdaBoo st F or Musi c Class ifica tion," M achi ne L ear ning , vol. 65 , pp. 47 3 - 484, 2 006. [24] K . He, X . Zhang, S . Ren , and J . Sun , "D elving D eep in to Rect ifiers : Surpa ssi ng H uman - Le vel Pe rform ance o n Imag eNet Cl assificat ion," in IEEE Inte rnational Conf erence on Comp uter Vision , ICCV , 2015. [25] N. S rivast ava, G . Hinto n, A. K rizhevsky , I. Sutske ver , and R. Sal akhu tdino v, "D ro pout: A Simpl e W a y to Pre vent Neur al N etw orks from Overfitt ing," Jour nal of Machine Lear ning R esea rch, JM LR, vol. 15, p p. 1 929 - 1958 , 2014. [26] D. King ma an d J. B a, "A DA M: A Method Fo r Sto chastic Optim izat ion," in Internat ional Con ference for Learni ng Repre sentatio ns, ICLR , 2015 . [27] FF mpeg De vel oper s. (20 16) . FFmp eg . Availab le: ht tp:// ffmpeg. org/ [28] M. McV icar, C. Raff el, D. L iang, O. N ieto, E. Batte nberg , J. Moore , et al. (2016). LibRO SA . Available: https://git hub.co m/li bros a/li brosa [29] R. Al - Rfou, G . Alain, A . Almahairi, and e . al., " The ano: A Python frame work for fast comput ation of mat hemati cal expressi ons, " arXiv e- prints , vol. abs/1605 .0268 8, May 2016 . [30] F . Cho lle t. (20 15) . Kera s . Availa ble: h ttps ://gi thub. com/ fchollet /k eras [31] K . J. Piczak , "Envi ronmenta l Sound Classi ficati on with Con voluti onal Neural Networ k s," i n IEEE interna tional wor ksho p on Mac hin e Learn ing fo r Signa l Pr ocessing (MLSP ) , 2015. TA B LE III P ERFORM ANCE ON ESC - 50 DATASET USING MC LN N COMPARED WITH OTHER ATTEMPTS IN THE LITE RATURE Cla ssi fier and Feat ur es Acc . % Piczak - CNN + Mel - Spec. with Augme ntation [ 31 ] 64.50 MCLNN + Mel - Spec. with out Au gmentati on (T h i s W or k) 61.75 CLNN + Mel - Spec. with out Au gmentati on (T h i s W or k) 51. 80 Random F orest + MFCC withou t Augme ntatio n [ 22 ] 44.00
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment