마스크드 조건부 신경망을 이용한 환경음 인식
본 논문은 시간‑주파수 스펙트로그램을 효과적으로 활용하기 위해 조건부 신경망(CLNN)과 그 변형인 마스크드 조건부 신경망(MCLNN)을 제안한다. MCLNN은 가중치에 규칙적인 희소성을 부여해 주파수 대역 단위 학습을 가능하게 하며, 필터뱅크와 유사한 주파수 이동 불변성을 제공한다. ESC‑10·ESC‑50 데이터셋에서 12 % 파라미터만 사용해 데이터 증강 없이도 최신 CNN 대비 경쟁력 있는 정확도를 달성하였다.
저자: :
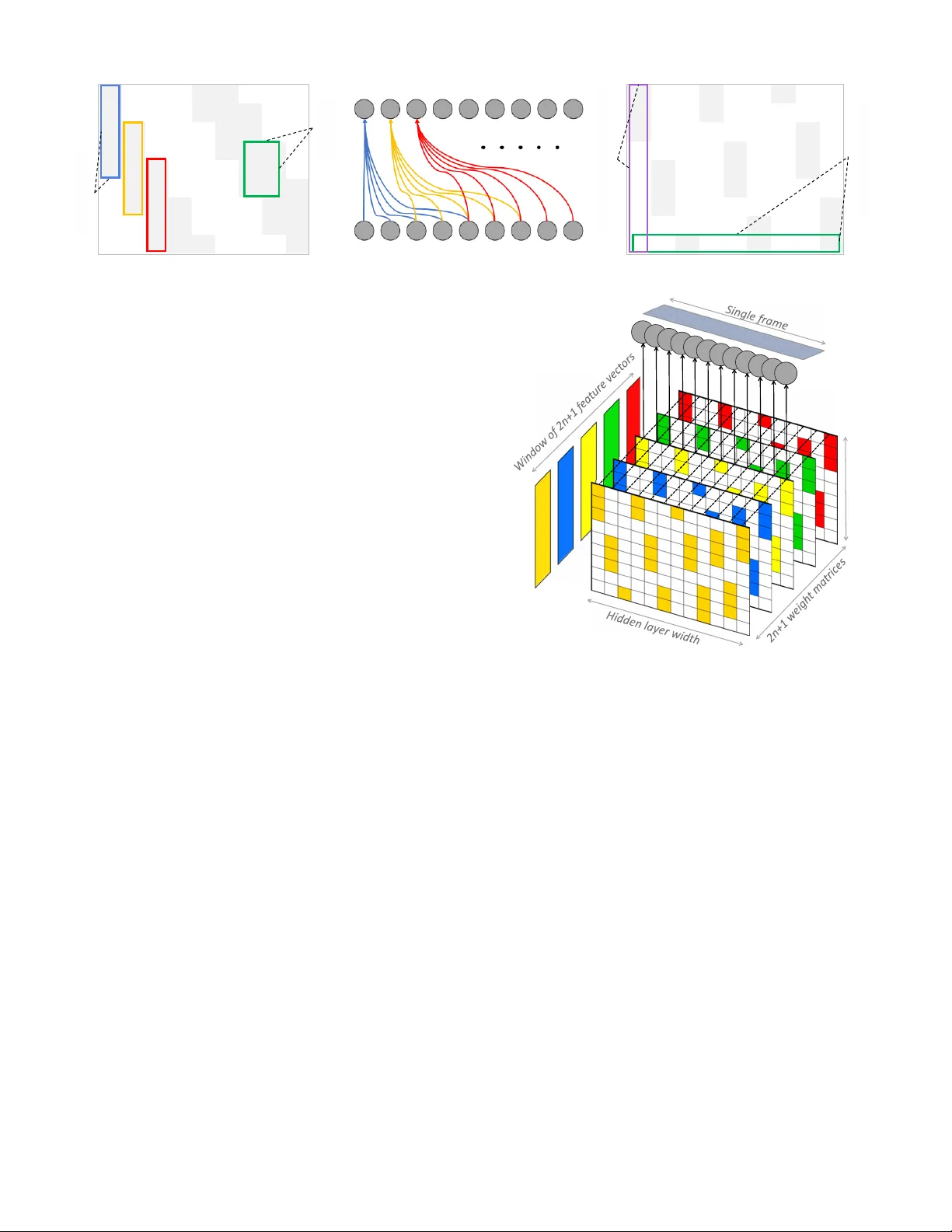
본 논문은 이미지 인식에 최적화된 딥러닝 구조를 그대로 사운드 인식에 적용할 경우, 시간‑주파수 스펙트로그램의 고유한 특성을 충분히 활용하지 못한다는 점을 지적한다. 이를 해결하기 위해 저자들은 조건부 신경망(Conditional Neural Network, CLNN)과 마스크드 조건부 신경망(Masked Conditional Neural Network, MCLNN)을 제안한다. CLNN은 기존 제한 볼츠만 머신(RBM)이나 컨디셔널 RBM(CRBM)에서 영감을 받아, 입력을 일정 길이의 프레임 윈도우(2n+1)로 나누고 각 프레임마다 별도의 가중치 행렬을 적용한다. 이렇게 하면 과거와 미래 프레임이 현재 프레임의 예측에 직접적인 영향을 미치게 되어, 시간적 연속성을 보존하면서도 다차원 신호를 효과적으로 처리할 수 있다. 수식적으로는 각 숨김 유닛 j에 대해 활성화 a_j = f( Σ_{t=-n}^{n} W_{t}^{(j)}·x_{u+t} + b_j ) 형태이며, 여기서 W_{t}^{(j)}는 윈도우 내 t번째 프레임에 대응하는 가중치 행렬이다. 이러한 구조는 윈도우 크기에 비례해 가중치 텐서의 깊이가 증가하지만, 파라미터 공유 없이 프레임별 특성을 학습할 수 있다는 장점이 있다.
MCLNN은 CLNN에 필터뱅크와 유사한 마스크를 도입한다. 마스크는 0과 1로 이루어진 이진 행렬이며, ‘밴드폭(bandwidth)’과 ‘오버랩(overlap)’이라는 두 하이퍼파라미터에 의해 정의된다. 밴드폭은 연속된 1이 차지하는 열 수를, 오버랩은 인접한 밴드 간의 겹침 정도를 조절한다. 마스크가 적용된 가중치 행렬은 element‑wise 곱을 통해 비활성화된 연결을 0으로 만들고, 활성화된 연결만 학습에 참여하게 된다. 결과적으로 네트워크는 개별 주파수 bin이 아니라 주파수 대역 단위로 특징을 학습하게 되며, 이는 주파수 이동에 대한 불변성을 제공한다. 또한, 여러 밴드 조합을 동시에 탐색함으로써 전통적인 수작업 피처 선택 과정을 자동화한다. 마스크 적용은 추가 파라미터를 요구하지 않으며, 학습 과정에서 기존 가중치와 동일하게 역전파된다.
실험 설정은 다음과 같다. ESC‑10과 ESC‑50 두 환경음 데이터셋을 사용했으며, 입력은 128‑차원 로그멜스펙트로그램을 0.5 s 길이의 프레임으로 나누어 윈도우에 넣었다. 모델은 3‑계층 CLNN 구조에 각 계층마다 서로 다른 밴드폭과 오버랩을 적용한 마스크를 부착하였다. 최종 출력은 소프트맥스 레이어를 거쳐 10 또는 50개의 클래스 중 하나를 예측한다. 파라미터 수는 약 0.5 M으로, 동일 조건의 CNN(예: VGG‑ish) 대비 12 % 수준이다. 데이터 증강 없이도 ESC‑10에서 81 %, ESC‑50에서 66 %의 정확도를 달성했으며, 이는 기존 최첨단 CNN(데이터 증강 포함)과 비교해 차이가 없거나 약간 우수한 수준이다. 특히, 파라미터 효율성 덕분에 학습 및 추론 시간이 크게 단축되었으며, 모바일 디바이스에서도 실시간 적용 가능성을 시사한다.
논문은 또한 MCLNN이 필터뱅크와 유사한 동작을 수행함을 시각화 실험을 통해 확인한다. 마스크가 적용된 가중치 행렬을 주파수 축에 따라 시각화했을 때, 각 숨김 유닛이 특정 주파수 대역에 집중하는 패턴이 관찰되었다. 이는 인간 청각 시스템이 멜 스케일 필터뱅크를 이용해 음성을 처리하는 방식과 유사하며, 네트워크가 스스로 주파수 이동 불변성을 학습했음을 의미한다.
결론적으로, 저자들은 CLNN과 MCLNN이 시간‑주파수 특성을 동시에 고려하면서도 파라미터 효율성을 크게 개선할 수 있음을 입증하였다. 향후 연구에서는 마스크 설계 자동화, 더 깊은 계층 구조 적용, 그리고 다른 음성·음악 도메인으로의 확장을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기