PI(D) tuning for Flight Control Systems via Incremental Nonlinear Dynamic Inversion
Previous results reported in the robotics literature show the relationship between time-delay control (TDC) and proportional-integral-derivative control (PID). In this paper, we show that incremental nonlinear dynamic inversion (INDI) - more familiar…
Authors: Paul Acquatella B., Wim van Ekeren, Qi Ping Chu
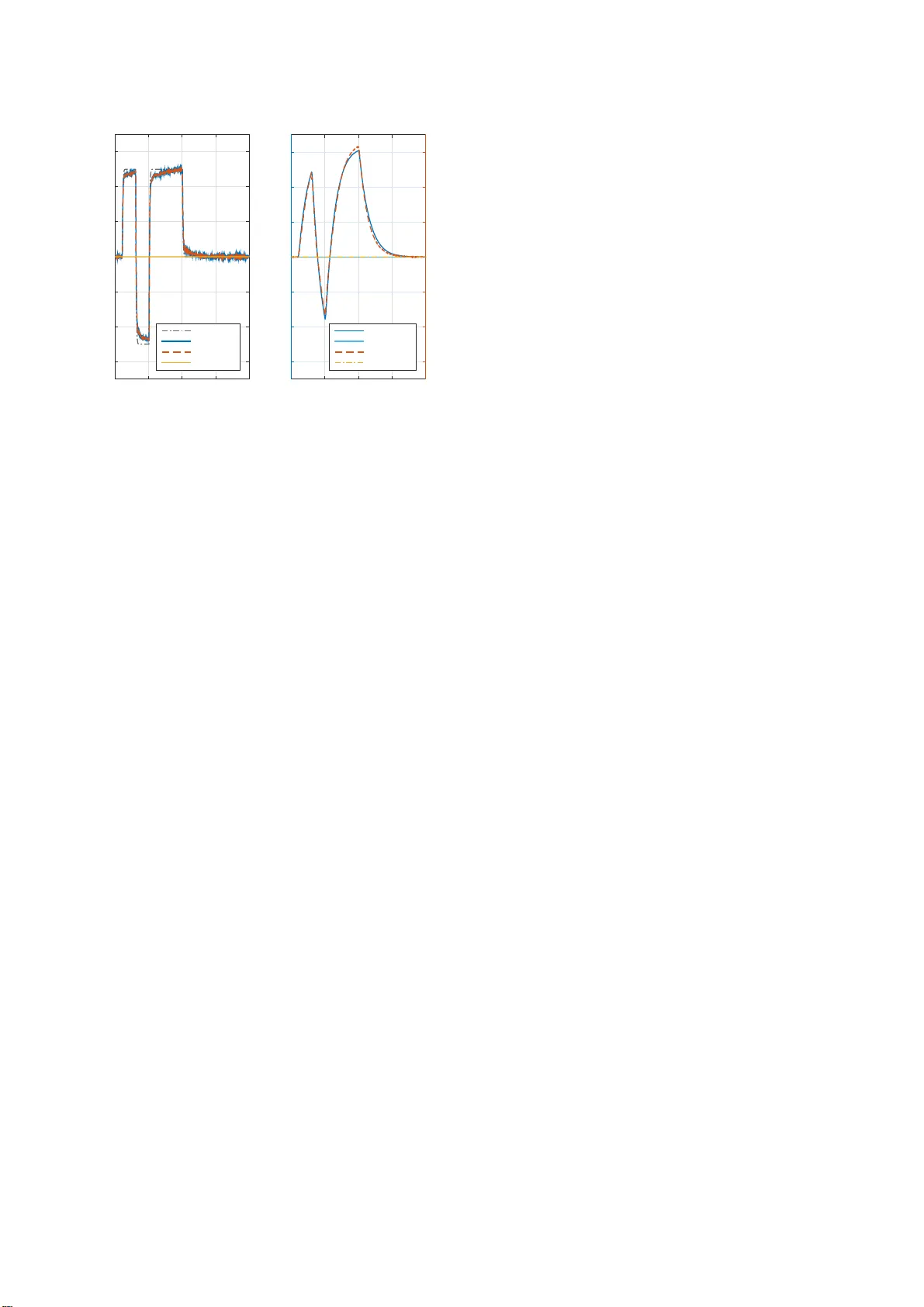
PI(D) tuning for Fligh t Con trol Systems via Incremen tal Nonlinear Dynamic In v ersion P aul Acquatella B. ∗ , 1 Wim v an Ek eren ∗ , ∗∗ , 2 Qi Ping Ch u ∗∗ , 3 ∗ DLR, German A er osp ac e Center Institute of System Dynamics and Contr ol D-82234 Ob erpfaffenho fen, Germany ∗∗ Delft University of T e chnolo gy, F aculty of A er osp ac e Engine ering 2629HS Delft, The Netherlands Abstract: Previous r esults rep orted in the rob otics literature show the rela tio nship betw een time-delay c ontr ol (TDC) and pr op ortional-inte gr al-derivative c ont r ol (PID). In this pap er, we show that incremental no nlinear dynamic inv ersion (INDI) — more familiar in the aero s pace communit y — are in fact equiv alent to TDC. This leads to a meaning ful and systematic metho d for PI(D)-co n trol tuning of robust nonlinea r flight co n trol sy stems via INDI. W e considered a reformulation of the plant dyna mics inv ersion which r e mov es effector ble nding mo dels from the resulting control law, resulting in robust mo del-free control laws like PI(D)-control. Keywor ds: ae rospace, tracking, application of nonlinear analysis and design 1. INTRODUCTION Ensuring stabilit y and p erformance in betw een op era tio nal po int s of widely-used gain-scheduled linear PID controllers motiv ates the use o f nonlinear dynamic in version (NDI) for flight con trol systems. NDI cancels o ut nonlinearities in the mo de l via state feedba ck, and then linea r control can be subse q uent ly designed to c lo se the sys tems’ outer -lo op, hence eliminating the need o f linear izing a nd desig ning different controllers for sev era l op erational p oints as in gain-scheduling. In this pap er w e consider nonlinear fligh t con trol str ategies based on incremen tal nonlinear dyna mic inv ersion (INDI). Using sensor a nd actuator measurements for feedback al- lows the design of an incremental control action which, in combination with nonlinear dyna mic in version, stabilizes the p artly -linearized nonlinear system incr emental ly . With this result, dep endency on exact knowledge o f the s ystem dynamics is grea tly reduced, ov ercoming this ma jor ro- bustness is sue from conv ent iona l nonlinea r dynamic in ver- sion. INDI has been considered a sensor-bas ed approach bec ause senso r measurements w ere meant to replac e a large part o f the vehicle mo del. Theoretical dev elopment of incremen ts of nonlinear con- trol action date back from the late nineties and started with activities concerning ‘implicit dynamic inv ersion’ for inv ersion-based flig ht control (Smith (1 9 98); B acon and Ostroff (2000 )), where the a rchitectures consider ed in this pap er were fir stly descr ib ed. Other designatio ns for these developmen ts fo und in the literature are ‘modified NDI’ 1 Researc h Engineer, Spa ce Systems Dynamics Departmen t. paul.acq uatella@dlr.d e . 2 Graduate Studen t, Control & Operations Department. w.vaneke ren@student.t udelft.nl . 3 Asso ciate Professor, Cont rol & Op erations D epartmen t. q.p.chu@ tudelft.nl . and ‘simplified NDI’, but the designation ‘incremental NDI’, in tro duced in (Chen and Zha ng (2008 )), is con- sidered to describ e the metho dolog y a nd nature of these t yp e of co n trol laws b etter (Chen and Zhang (2 008); Chu (2010); Siebe r ling et al. (20 10)). INDI has be en elab ora ted and applied theo retically in the past decade for adv anced flight cont ro l and space applications (Sieber ling e t a l. (2010); Smith (1998); Bacon and Ostro ff (2000 ); B acon et al. (2 000, 2001 ); Acquatella B. et al. (2012); Simpl ´ ıcio et a l. (201 3)). Mor e recently , this technique has b een ap- plied also in practice for quadroto rs and ada ptive co n trol (Smeur et a l. (2016a ,b)). In this pa per , we pr esent thre e main contributions in the context of nonlinear flight control system design. 1) W e revisit the NDI/INDI control laws and we establish the equiv a lence betw een INDI and time-delay con trol (TDC). 2) Ba sed on previous r esults rep or ted in the rob otics liter- ature showing the relationship b etw een discr ete formula- tions o f TDC and prop or tional-integral-deriv ative control (PID), we show that a n equiv alent PI(D) controller with gains < K , T i , ( T d ) > tuned via INDI/TDC is more mean- ingful and sys tematic than heuristic metho ds , since o ne considers desired erro r dynamics g iven by Hurwitz g ains < k P , ( k D ) > . Subsequently , tuning the remaining effector blending gain is muc h less cum b ersome than designing a whole set of g ains iteratively . 3) W e a ls o consider a r eformulation of the plant dyna mics inv ersion as it is done in TDC which re mov es the effector blending model (control deriv atives) fro m the resulting control law. This has not be en the case so far in the rep orted INDI co nt ro llers, ca using r obustness pr oblems bec ause of their uncertainties. Moreover, this a llows to consider the intro duced term as a scheduling v ariable which is only dire c tly related to the prop ortiona l g a in K . 2. FLIGHT VEHICLE MODELING W e are interested in E uler’s equation of motion r epresent- ing flight vehicles’ angular velocity dynamics I ˙ ω + ω × I ω = M B (1) where M B ∈ R 3 is the external mo ment vector in bo dy axes, ω ∈ R 3 is the ang ula r velocity vector, and I ∈ R 3 × 3 the iner tia matrix o f the rigid bo dy a ssuming symmetry ab out the plane x − z of the b o dy . F urthermore, we will be interested in the time history o f the angula r velo city v ector , hence the dy na mics of the rotational motion of a vehicle (1) can b e rewr itten as the following set of differential equations ˙ ω = I − 1 M B − ω × I ω (2) where ω = " p q r # , M B = " L M N # = S Q " b C l c C m b C n # , I = " I xx 0 I xz 0 I y y 0 I xz 0 I z z # , with p , q , r , the b o dy roll, pitch, and yaw rates, resp ec- tively; L , M , N , the roll, pitch, a nd ya w moments, resp ec- tively; S the wing surface ar ea, Q the dynamic pre ssure, b the wing spa n, c the mean aer o dynamic chord, and C l , C m , C n the moment co efficients for roll, pitch, and yaw, resp ectively . F urthermore, let M B be the s um of mo men ts partially generated b y the aer o dynamics o f the air frame M a and mo men ts generated by control surface deflections M c , and we describe M B linearly in the deflection angles δ assuming the co nt ro l deriv atives to b e linea r a s in Sieb er- ling et a l. (2010 ) with ( M c ) δ = ∂ ∂ δ M c ; therefore M B = M a + M c = M a + ( M c ) δ δ (3) where M a = " L a M a N a # , M c = " L c M c N c # , δ = " δ a δ e δ r # and δ c orresp onding to the control inputs: a ileron, elev a - tor, a nd rudder deflection angles, r esp ectively . Hence the dynamics (2) can be rewritten as ˙ ω = f ( ω ) + G ( ω ) δ (4) with f ( ω ) = I − 1 M a − ω × I ω , G ( ω ) = I − 1 ( M c ) δ . F or pra ctical implementations, we consider first-order ac- tuator dynamics represented by the follo wing tra nsfer function δ δ c = G a ( s ) = K a τ a s + 1 , (5) and furthermore, we do not consider these actuator dy- namics in the control design pro ce s s as it is usually the case for dynamic inversion-based control. F or that reason, we a s sume that these actuator s are sufficiently fast in the control-bandwidth sense, meaning that 1 /τ a is higher than the control system closed-lo op bandwidth. 3. FLIGHT CO NTR OL LA W DESIGN 3.1 Nonline ar Dynamic Inversion Let us define the control par ameter to b e the angular velocities, hence the o utput is simply y = ω . W e then consider an error vector defined as e = y d − y where y d denotes the smo oth des ired output vector (at least o ne time differentiable). Nonlinear dynamic in version (NDI) is desig ned to linearize and decouple the rotational dynamics in order to o btain an explicit desired closed lo o p dynamics to b e follow ed. Int ro ducing the vir tual control input ν = ˙ ω des , if the matrix G ( ω ) is non-singular (i.e., invertible) in the domain of interest for a ll ω , the no nlinear dynamic in version control co nsists in the follo wing input transformatio n (Slotine and L i (1990); C hu (2010)) δ = G ( ω ) − 1 ν − f ( ω ) (6) which cancels all the nonlinearities, a nd a simple input- output linear relationship between the output y and the new input ν is o bta ined as ˙ y = ν (7) Apart fro m b eing linear, an in teresting result fro m this relationship is that it is als o decoupled since the input ν i only affects the output y i . F r om this fact, the input trans- formation (6 ) is called a de c oupling c ontr ol law , and the resulting linear system (7) is called the single-inte gra tor form. This single-integrator form (7) can b e render ed ex- po nent ially stable with ν = ˙ y d + k P e (8) where ˙ y d is the feedforward term for tra cking tasks, a nd k P ∈ R 3 × 3 a constan t dia gonal matr ix, whos e i − th diagonal element s k P i are chosen so tha t the po lynomials s + k P i ( i = p, q , r ) (9 ) may beco me Hur witz, i.e., k P i < 0 . T his r e s ults in the exp onentially stable and decoupled desir e d error dynamics ˙ e + k P e = 0 (10) which implies that e ( t ) → 0. F rom this t ypical tracking problem it can b e seen that the entire control s y stem will hav e tw o control lo o ps (Ch u (2 010); Sieb erling et al. (2010)): the inner linea rization lo op (6), and the outer control lo op (8). This resulting NDI control law dep ends o n accurate knowledge of the aer o dynamic momen ts, hence it is susceptible to model uncertainties contained in b oth M a and M c . In NDI c o nt ro l design, we consider outputs with relative degrees of o ne (rates), mea ning a first-o rder system to be con trolled, see Fig. 1. Ex tensions of input-output lin- earization for systems inv olving higher r e lative degrees are done via fe e db ack line arization (Slotine and Li (1990 ); Chu (2010)). 3.2 Incr emental Nonline ar Dynamic Inversion The concept of incr ement al nonlinear dynamic in version (INDI) amounts to the applicatio n of NDI to a s ystem expressed in an incremental form. This improves the ro- bustness of the closed-lo o p system a s co mpared with con- ven tional ND I since dependency on the accurate knowl- edge of the plant dynamics is reduced. Unlik e NDI, this P S f r a g r e p la c e m e n t s Reference T ra jectory Po sition Con trol Flight Path Angle and Airsp eed Control Attitude Con trol Rate Control X, Y , Z V , ψ , γ µ, α, β p, q , r Fig. 1. F our lo op nonlinear fligh t cont ro l design. W e are fo cused o n nonlinear dynamic inv ersio n of the ra te co n trol loo p (grey b ox) in the following. Image credits: Sonneveldt (201 0 ). control design technique is implicit in the sense that de- sired clo sed-lo op dynamics do not reside in some explicit mo del to b e follow ed but result when the feedback lo o ps are closed (Bacon and O stroff (2000); Bacon et a l. (2000)). T o o btain a n incremental form of system dynamics, we consider a first-o rder T aylor se ries e x pansion of ˙ ω (Smith (1998); Ba con and Ostroff (200 0); Bacon et al. (2000, 2001); Sieb erling et a l. (2010); Acquatella B. et al. (2012, 2013)), not in the geometric s ense, but with res pec t to a suffiently smal l time-delay λ a s ˙ ω = ˙ ω 0 + ∂ ∂ ω f ( ω ) + G ( ω ) δ ω = ω 0 δ = δ 0 ( ω − ω 0 ) + ∂ ∂ δ G ( ω ) δ ω = ω 0 δ = δ 0 ( δ − δ 0 ) + O (∆ ω 2 , ∆ δ 2 ) ∼ = ˙ ω 0 + f 0 ( ω − ω 0 ) + G 0 ( δ − δ 0 ) with ˙ ω 0 ≡ f ( ω 0 ) + G ( ω 0 ) δ 0 = ˙ ω ( t − λ ) (11a) where ω 0 = ω ( t − λ ) and δ 0 = δ ( t − λ ) are the time- delay ed s ignals of the curr e n t state ω and control δ , re- sp ectively . This means an approximate linear ization abo ut the λ − delay ed s ig nals is p er formed incr emental ly . F or such sufficiently small time-delay λ so that f ( ω ) do es not v ary significant ly during λ , w e a ssume the following approximation to hold ǫ I N D I ( t ) ≡ f ( ω ( t − λ )) − f ( ω ( t )) ∼ = 0 (12) which leads to ∆ ˙ ω ∼ = G 0 · ∆ δ (13) Here, ∆ ˙ ω = ˙ ω − ˙ ω 0 = ˙ ω − ˙ ω ( t − λ ) re presents the incremental accele ration, and ∆ δ = δ − δ 0 represents the so-called incremental c o nt ro l input. F or the obtained approximation ˙ ω ∼ = ˙ ω 0 + G 0 ( δ − δ 0 ), NDI is a pplied to obtain a relation b etw een the incr emental con trol input and the output of the system δ = δ 0 + G − 1 0 ν − ˙ ω 0 (14) Note that the deflection angle δ 0 that corr esp onds to ˙ ω 0 is taken fr om the output of the actuators, and it has bee n assumed that a commanded control is achieved s u f- ficiently fast according to the assumptions of the a ctuator dynamics in (5). The tota l control command a lo ng with the obtained linearizing control ∆ δ can b e rewr itten a s δ ( t ) = δ ( t − λ ) + G − 1 0 h ν − ˙ ω ( t − λ ) i . (15) The dep endency of the closed-lo op sys tem o n accur ate knowledge of the a irframe mo del in f ( ω ) is largely de- creased, improving ro bustness agains t mo del uncertain- ties contained therein. Therefor e, this implicit control law design is more depe nden t on a ccurate measurements or accurate estimates of ˙ ω 0 , the a ngular acceleratio n, and δ 0 , the deflection a ngles, resp ectively . Remark 1 : By using the mea sured ˙ ω ( t − λ ) and δ ( t − λ ) incrementally we practically obtain a robust, mo del-free controller with the self-scheduling prop erties of NDI. Notice, how ever, that typical INDI control la ws ar e nev - ertheless also dep ending on effector blending mo dels r e- flected in G 0 , which makes this implicit controller suscep- tible to uncertainties in these terms. Instead, consider the following transformation as in (Chang and Jung (2009)) ˙ ω = H + ¯ g · δ (16) with H ( t ) = f ( ω ) + ( G ( ω ) − ¯ g ) δ, and with the following (but not limited) options for ¯ g (Chang and J ung (2009)), whe r e n = 3 in our case ¯ g 1 = k G ·I n = k G 1 0 · · · 0 0 1 . . . . . . 0 1 , ¯ g 2 = k G 1 0 · · · 0 0 k G 2 . . . . . . 0 k G n . Applying nonlinear dynamic in version (NDI) to (16) re- sults in a n e xpression for the co nt rol input of the vehicle as δ ( t ) = ¯ g − 1 ν ( t ) − H ( t ) . (1 7 ) Considering H 0 = ˙ ω 0 − ¯ g · δ 0 , the incr emental c o unt erpa rt of (17) results in a control law that is neither dep ending on the a irframe mo del nor the effector blending moments δ ( t ) = δ ( t − λ ) + ¯ g − 1 h ν − ˙ ω ( t − λ ) i . (18) Remark 2 : The self-scheduling pro p e rties of INDI in (15) due to the ter m G 0 are now lo s t, suggesting that ¯ g should be an scheduling v aria ble . 3.3 Time Delay Contr ol and Pr op ortional Inte gr al c ontr ol Time delay c ontr ol (TDC) (Chang and Jung (200 9)) de- parts fro m the usua l dynamic inv ersion input tra nsforma- tion o f (16) δ ( t ) = ¯ g − 1 ν ( t ) − ¯ H ( t ) (19) where ¯ H denotes an estimation of H , b eing the nominal case when ¯ H = H which res ults in p erfect inv ersion. Instead o f ha ving an e stimate, the TDC takes the following assumption (Chang and Jung (2009)) analogo us to (12) ǫ T D C ( t ) ≡ H ( t − λ ) − H ( t ) ∼ = 0 . (20) This relationship is used together with (16 ) to obtain wha t is ca lled time-delay estimation (TDE) as the following ¯ H = H ( t − λ ) = ˙ ω ( t − λ ) − ¯ g · δ ( t − λ ) (21) In addition, ǫ ( t ) is called TDE err or at time t . Com bining the equations we obtain the following TDC law δ ( t ) = δ ( t − λ ) + ¯ g − 1 ν − ˙ ω ( t − λ ) (22) which is in fact e quivalent to the INDI con trol law obtained in (18). Appropr iate selection of ¯ g must e nsure stabilit y according to (Chang and Jung (20 09)), and ideally , this term should be tuned accor ding to the b est estimate of the true effector blending moment ˆ g ( ˜ ω ) for measured angular velocities ˜ ω . So far we hav e consider ed deriv ations in co nt inuous-time. F or pra ctical implementations of these controllers and for the matters of up coming discussions, sa mpled-time formulations inv olving c ontin uous and discrete qua n tities as in (Chang and Jung (2009 )) are mor e co nv enien t and restated here. F or that, consider ing that the s ma llest λ one can consider is the eq uiv alent of the sampling p erio d t s of the o n-b oard co mputer. The sampled fo r mulation of (22) may be expressed as δ ( k ) = δ ( k − 1) + ¯ g − 1 ν ( k − 1 ) − ˙ ω ( k − 1) (23) where it has been neces sary to consider ν at s ample k − 1 for causality reas ons. Replacing the s ampled virtual cont ro l ν according to (8 ) we hav e δ ( k ) = δ ( k − 1 ) + ¯ g − 1 ˙ e ( k − 1) + k P e ( k − 1) (24) and we can co nsider the following finite difference appr ox- imation of the er ror deriv a tives as angular accele rations are not dir ectly measured ˙ e ( k ) = [ e ( k ) − e ( k − 1)] /t s . (25) Consider now the standar d pr op ortional-inte gr al (PI) con- trol δ ( t ) = K e ( t ) + T − 1 I Z t 0 e ( σ )d σ + δ DC , (26) where K ∈ R 3 × 3 denotes a diagona l pr op ortional ga in matrix, T I ∈ R 3 × 3 a co nstant diagona l matrix repres e nt- ing a reset or integral time, a nd δ DC ∈ R 3 denotes a constant vector represe nting a tr im-bias, which acts as a trim setting and is computed by ev aluating the initial conditions. The discrete form of the PI is given b y δ ( k ) = K e ( k − 1) + T − 1 I k − 1 X i =0 t s e ( i ) + δ DC (27) When substracting tw o co nsecutive terms of this discr e te formulation, we can remov e the integral sum and achieve the so-called PI c ontroller in incremental form δ ( k ) = δ ( k − 1 ) + K · t s ˙ e ( k − 1) + T − 1 I · e ( k − 1) (28) F ollowing the same steps , and for co mpleteness, w e a lso present the PID extension by simply consider ing the extra deriv a tive term ¨ e δ ( k ) = δ ( k − 1) + K · t s T D ¨ e ( k − 1 ) + ˙ e ( k − 1) + T − 1 I · e ( k − 1) , where T D ∈ R 3 × 3 denotes a c onstant diago nal matr ix representing deriv ative time. 3.4 Equivalenc e of IND I/TDC/PI(D) Having in mind the found the equiv a lence b etw een INDI and TDC, a nd comparing ter ms from (24) with (28), we hav e the following relationships as o riginally found in (Chang and Jung (2 009)) w hich are the rela tio nship betw een the discrete form ulations o f TDC and PI in incremental form K = ( ¯ g · t s ) − 1 , T I = k − 1 P (29) Whenever the system under co nsideration is of second- order controller canonica l form, we will hav e error dynam- ics of the form ¨ e + k D ˙ e + k P e = 0, and considering the newly intro duced deriv ative g ain k D related to ¨ e we hav e K = k D · ( ¯ g · t s ) − 1 , T I = k D · k − 1 P , T D = k − 1 D (30) This s uggests not only that an equiv alent discr ete P I(D) controller with gains < K , T i , ( T d ) > can b e obtained via INDI/TDC, but doing so is more meaningful a nd systematic than heuristic methods. This is beca us e we beg in the design fr om desir ed erro r dynamics given by Hurwitz gains < k P , ( k D ) > a nd what follows is finding the remaining effector blending ga in ¯ g either analytically whenever G is w ell kno wn, with a pro per estimate ˆ G , or b y tuning acco r ding to closed-lo op requirements. As alrea dy men tioned, details on a sufficient condition for closed- lo op stability under discrete TDC, and therefore applicable to its equiv alen t INDI, can b e found in (Chang and J ung (2009)) a nd the references therein. In essence, this pro cedure is more efficient a nd muc h less cum b erso me tha n des igning a whole set of ga ins iteratively . Moreov er, for flight control s ystems, the se lf-s cheduling prop erties of inv ersion-ba sed controllers have suggested su- per ior a dv antages with r esp ect to PID controls since these m ust be gain- s cheduled acco rding to the flight en velope v ar iations. The r elationships here outlined sugg ests that PID-scheduling sha ll b e done at the pro p o rtional gain K via the effector blending ga in ¯ g , and not ov er the who le set o f gains < K , T i , ( T d ) > . 4. LO NGITUDINAL FLIGHT CONTROL SIMULA TIO N In this s ection, robust PI tuning via INDI is demonstra ted with a simple y et s ignificant example co nsisting of the tracking control des ign fo r a long itudinal launcher vehicle mo del. The second-order no nlinear model is obtained fro m (Sonneveldt (2010 ); Kim e t al. (2004 )), and it cons ists on longitudinal dynamic equa tions r epresentativ e of a v ehicle trav eling a t an altitude of appr oximately 60 0 0 meter s , with aero dynamic coefficients represented as third order po lynomials in a ngle of attack α and Mach num ber M . The nonlinear equatio ns of motion in the pitch plane are given by ˙ α = q + ¯ qS mV T C z ( α, M ) + b z ( M ) δ , (31a) ˙ q = ¯ q S d I y y C m ( α, M ) + b m ( M ) δ , (31b) where C z ( α, M ) = ϕ z 1 ( α ) + ϕ z 2 ( α ) M , C m ( α, M ) = ϕ m 1 ( α ) + ϕ m 2 ( α ) M , b z ( M ) = 1 . 6238 M − 6 . 7 240 , b m ( M ) = 12 . 039 3 M − 4 8 . 2246 , and ϕ z 1 ( α ) = − 288 . 7 α 3 + 50 . 32 α | α | − 23 . 89 α, ϕ z 2 ( α ) = − 13 . 53 α | α | + 4 . 185 α, ϕ m 1 ( α ) = 3 03 . 1 α 3 − 246 . 3 α | α | − 3 7 . 56 α, ϕ m 2 ( α ) = 7 1 . 51 α | α | + 10 . 01 α. These approximations a re v alid for the flight env elop e of − 10 ◦ ≤ α ≤ 10 ◦ and 1 . 8 ≤ M ≤ 2 . 6. T o facilitate the control desig n, the no nlinear longitudinal mo del is rewritten in the more general state-space form as ˙ x 1 = x 2 + f 1 ( x 1 ) + g 1 u (32a) ˙ x 2 = f 2 ( x 1 ) + g 2 u (32b) where: x 1 = α, x 2 = q g 1 = C 1 b z , g 2 = C 2 b m and f 1 ( x 1 ) = C 1 ϕ z 1 ( x 1 ) + ϕ z 2 ( x 1 ) M , C 1 = ¯ q S mV T , f 2 ( x 1 ) = C 2 ϕ m 1 ( x 1 ) + ϕ m 2 ( x 1 ) M , C 2 = ¯ q S d I y y . The control ob jective considere d her e is to desig n a P I autopilot via INDI that tracks a smo oth command refer- ence y r with the pitch rate x 2 . It is a ssummed tha t the aero dynamic force and mo ment functions are accurately known and the Mach num ber M is treated as a parameter av ailable fo r measurement. Moreover, for this second- o rder system in non-low er triangular for m due to g 1 u and f 2 ( x 1 ), pitc h rate c o ntrol using INDI is p ossible due to the time- scale separa tion principle (Chu (201 0); Sieber ling et al. (2010)). With r esp ect to actua tor dynamics mo deled as in (5), we consider K a = 1, and τ a = 1 e − 2 . 4.1 Pitch r ate c ontr ol design First, introduce the rate-tr acking er ror z 2 = x 2 − x 2 ref (33) the z 2 − dynamics satisfy the following error ˙ z 2 = ˙ x 2 − ˙ x 2 ref (34) for which we design the fo llowing exp onentially stable desir e d err or dynamics ˙ z 2 + k P 2 z 2 = 0 , k P 2 = 50 rad/s . (35) According to the results previo usly outlined, the incremen- tal nonlinear dyna mic inv ersion control law design follows from consider ing the a ppr oximate dynamics ar ound the current refere nce state fo r the dy namic equation of the pitc h ra te as in (13 ) ˙ q ∼ = ˙ q 0 + ¯ g · ∆ δ (36) assuming that pitch ac c e leration is av a ilable fo r measure- men t and the s c a lar ¯ g to b e a factor of the accurately known estimate of g 2 ¯ g = k G · ˆ g 2 , k G = 1 . This is rewritten in our formulation as ˙ x 2 ∼ = ˙ x 2 0 + ¯ g · ∆ u (37) where recalling that ˙ x 2 0 is an incremental instance b efore ˙ x 2 , and therefor e the incremental nonlinea r dynamic in- version law is hence obtained as u = u 0 + ¯ g − 1 ν − ˙ x 2 0 , (38) with ν = − k P 2 z 2 + ˙ x 2 ref , (39) or more co mpactly u = u 0 + ¯ g − 1 − k P 2 z 2 − ˙ x 2 0 + ˙ x 2 ref (40) This r esults a s des ired, in the following z 2 − dynamics ˙ z 2 = ˙ x 2 0 + ¯ g · ∆ u − ˙ x 2 ref . (41) Notice that we a re replacing the a ccurate knowledge of f 2 by a measurement (or an estimate) a s f 2 ∼ = ˙ x 2 0 , which will result in a co ntrol law which is no t entirely dep endent on a mo de l, hence mor e r obust. W e now conside r these contin uous-time formulations in sampled-time. T o that end, we re place the small λ with the sampling p erio d t s so that t k = k · t s is the k − th sampling instant at time k , and therefore u ( k ) = u ( k − 1 )+ ¯ g − 1 − k P 2 z 2 ( k − 1) − ˙ x 2 ( k − 1) + ˙ x 2 ref ( k − 1) , (42) where due to caus ality relationships we need to consider the independent v ariables at the s ame sampling time k − 1. Referring back to the derived relationship b etw een INDI and PI control, the equiv ale nt PI control in incremen tal form is u ( k ) = u ( k − 1) + K · t s ˙ z 2 ( k − 1) + T − 1 I z 2 ( k − 1) , (43) with K = ( ¯ g · t s ) − 1 , T I = k − 1 P 2 (44) The na ture of the des ired er r or dynamics (prop ortional) gain k P 2 is therefore of an in tegral control actio n, whereas the effector blending gain ¯ g act as pro p o rtional cont ro l. Having designed for desired err or dyna mics, and for a given sampling time t s , tuning a pitch rate co ntroller is only a matter of selecting a prop er effecto r blending ga in ¯ g a ccording to p erfor mance requirements. Remark 3 : Notice at this point that having the PI control in incremental form intro duces a finite difference of the error state, which is the equiv a lent co un terpar t of what has be e n cons ide r ed the ac celeration or s tate deriv ative ˙ x 2 0 in INDI c ontrollers. Remark 4 : Notice also that desig ning the PI control gains via INDI is hig hly b eneficial, s inc e only the effector blending ga in is the tuning v aria ble . T his strong ly suggests that r obust a daptive cont ro l can be achiev ed by scheduling this v ariable online dur ing flight and not over the whole set o f gains. Sim ulation results for the INDI/PI control are presented in Figure 2, considering s mo oth rate doublets for a nominal longitudinal dynamics mo del a t Mach 2. F or b oth con- trollers, the same zero-mea n Gaussian white-noise with standard dev iation s d q = 1 e − 3 rad/s is added to the rates to simulate no is y measure ments. The designed INDI gains of k P 2 = 50 rad/s and k G = 1 are mapped to PI gains resulting in K = 100 ˆ g − 1 2 and T I = 0 . 02 s, b oth controllers showing iden tical clo sed-lo op r esp onse as exp ected. With this example, it is demonstrated ho w a self-sc heduled PI can b e tuned via INDI by departing from desired er ror dynamics with the g ain k P 2 , and consider ing an accura te effector blending mo del e stimate ¯ g = ˆ g 2 . q RE F q I N D I q P I q I N D I − q P I α I N D I α I N D I − α P I δ I N D I δ I N D I − δ P I P S f r a g r e p la c e m e n t s δ (deg) time (s) time (s) q (deg/s) α (deg) 0 5 1 0 1 5 2 0 0 5 10 15 20 0 5 10 15 20 − 6 − 4 − 2 0 2 4 6 − 6 − 4 − 2 0 2 4 6 − 6 − 4 − 2 0 2 4 6 Fig. 2. INDI/PI nominal tra cking control simulation o f the flight mo del (31) for k P 2 = 50 rad/s and k G = 1 5. CO NCLUSIONS This paper presented a meaningful and sys tema tic metho d for PI(D) tuning of r obust nonlinear flig ht control systems based o n results previously r ep orted in the ro b o tics lit- erature (Chang and Jung (2009)) re garding the relation- ship b etw een time-delay c ontr ol (TDC) and pr op ortional- inte gr al-derivative c ontr ol (PID). The method was demon- strated in the context of an example for the pitch rate tracking of a conv entional longitudinal nonlinear flig ht mo del, sho wing the same trac king perfor mance under nominal conditions. Being incremental nonlinear dynamic inversion (INDI) equiv a lent to TDC clearly suggests that impo sing de- sir e d err or dynamics , as usual f or INDI control laws, and then mapping these in to an equiv alent incremental PI(D)-controller tog ether with control deriv atives lea ds to a meaningful and sy s tematic PI(D) gain tuning method, which is very difficult to do heuristically . W e co nsidered a refor mulation o f the plan t dynamics in- version which reduces knowledge of the effector blending mo del (cont ro l deriv atives) from the resulting cont ro l law, reducing feedback co nt ro l dependency o n accura te knowl- edge o f b oth the aircraft a nd effector blending mo dels, hence re s ulting in ro bust and mo del-free co nt ro l laws like the PI(D) control. Since usual flight co n trol systems in- volv es gain scheduling over the flight env elop e, a nother key benefit of this r esult is that scheduling only the ef- fector blending gain seems promising for adaptive co n trol systems. A CKNOWLEDGEMENTS M. Ruf, N. T ekles, and G. Lo oye are acknowledged for discussions leading to improv ements of this pape r. REFERENCES Acquatella B., P ., F alkena, W., v an Ka mpen, E., and Ch u, Q.P . (2012). Robust Nonlinea r Spacecra ft Attitude Con- trol using Incre men tal Nonlinear Dynamic In version. In AIAA Guidanc e, Navigation, and Contr ol Confer enc e . American Ins titute o f Aeronautics a nd Astrona utics, Inc. (AIAA-2012-4 623). Acquatella B., P ., v a n Kamp en, E., and Chu, Q.P . (2013). Incremental Backstepping for Robus t Nonlinear Flight Control. In Eur oGNC 2013, 2nd CEAS Sp e cialist Con- fer enc e on Guidanc e, N avigation, and Contr ol . Bacon, B.J . and Ostroff, A.J. (200 0). Reco nfigurable Flight Co ntrol using Nonlinea r Dynamic Inv ersio n with a Sp ecial Accelero meter Implementation. In AIAA Guidanc e, Navigation, and Contr ol Confer enc e and Ex- hibit . (AIAA-2000-4 565). Bacon, B.J., Ostro ff, A.J., and Joshi, S.M. (2000 ). Nonlin- ear Dynamic Inv ersion Reconfigurable Controller utiliz- ing a Fault-tolerant Accelerometer Approach. T echnical rep ort, NASA La ngley Research Center. Bacon, B.J., O stroff, A.J., and J oshi, S.M. (2001). Reco n- figurable NDI Controller using Inertial Sensor F ailure Detection & Isolation. IEEE T r ansactions on A ero sp ac e and Ele ctr onic Systems , 37, 1373– 1383 . Chang, P .H. and Jung, J.H. (200 9). A Systematic Metho d for Gain Selec tion of Ro bust PID Con trol for Nonlin- ear Plants of Second-O rder Controller Canonical Form. IEEE T r ansactions on Contro l Systems T e chnolo gy , 17(2), 473– 4 83. Chen, H.B. and Zhang , S.G. (200 8). Robust Dynamic Inv ersion Fligh t Control Law Design. In ISSCAA 2008, 2nd International Symp osium on Systems and Contr ol in Aer osp ac e and Astr onautics . Chu , Q.P . (2010 ). Advanc e d Flight Contr ol . Lecture notes, Delft Universit y of T echnology , F aculty of Aeros pace Engineering . Kim, S.H., Kim, Y.S., a nd Song, C. (2004 ). A Robust Adaptive Nonlinear Co nt ro l Approa ch to Missile Au- topilot Design. Contr ol Engine ering Pr actic e , 33(6), 1732– 1742 . Siebe r ling, S., Ch u, Q.P ., and Mulder, J.A. (2010). Robust Flight Control Using Incr e mental Nonlinear Dynamic Inv ersion and Angular Accele r ation Pr ediction. Journal of Guidanc e, Contr ol and Dynamics , 33 (6 ), 17 32–17 42. Simpl ´ ıcio, P ., Pav el, M., v an Kamp en, E., and Chu, Q .P . (2013). An Accelera tio n Mea surements-based Approach for Helicopter Nonlinea r Flight C o ntrol us ing Incremen- tal No nlinear Dyna mic Inversion. Contr ol Engine ering Pr actic e , 21(8), 106 5 –107 7. Slotine, J.J. and Li, W. (19 9 0). A pplie d Nonline ar Contr ol . Prentice Hall Inc. Smeur, E.J., Chu, Q.P ., and de Cro on, G.C. (2016a ). Adaptive Incremental Nonlinear Dynamic Inv ersion for Attitude Control of Micro Air Vehicles. Journal of Guidanc e, Contr ol and D yn amics , 39(3), 450– 461. Smeur, E.J., de Cro on, G.C., a nd Ch u, Q.P . (2016b). Gust Disturbance Alleviation with Incremental Non- linear Dynamic Inversion. In IEEE/RSJ Intern ational Confer enc e on Intel ligent Ro b ots and Syst ems (IROS) . Smith, P .R. (1998). A Simplified Approach to Non- linear Dynamic Inv ersion Bas ed Flight Control. In AIAA Atmosph eric Flight Me chanics Confer enc e , 762– 770. American Institute of Aeronautics a nd Astronau- tics, Inc. (AIAA-98 -4461 ). Sonneveldt, L. (20 10). A daptiv e Backsteppi ng Flight Con- tr ol for Mo dern Fighter Air cr aft . PhD thesis, Delft Uni- versit y of T echnology , F aculty of Aerospa ce Engineering.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment