Optimal Controller and Quantizer Selection for Partially Observable Linear-Quadratic-Gaussian Systems
In networked control systems, often the sensory signals are quantized before being transmitted to the controller. Consequently, performance is affected by the coarseness of this quantization process. Modern communication technologies allow users to o…
Authors: Dipankar Maity, Panagiotis Tsiotras
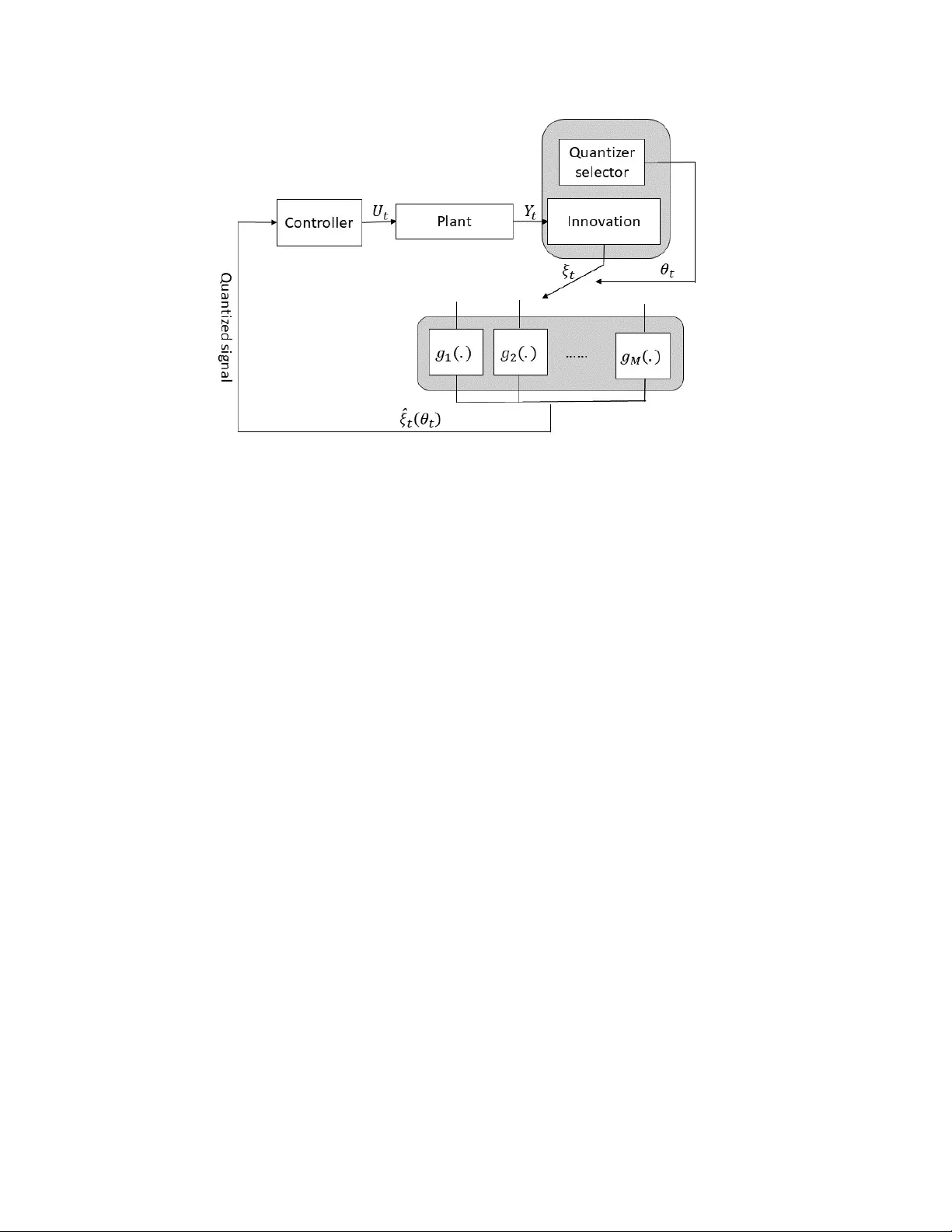
Optimal Quan tizer Sc heduling and Con troller Syn thesis for P artially Observ able Linear Systems ∗ Dipank ar Mait y † P anagiotis Tsiotras ‡ Abstract In net work ed con trol systems, often the sensory signals are quantized b efore b eing transmitted to the con troller. Consequen tly , p erformance is affected by the coarseness of this quantization pro cess. Mo dern comm unication tec hnologies allo w users to obtain resolution-v arying quantized measuremen ts based on the prices paid. In this paper, we consider joint optimal controller syn thesis and quan tizer sc heduling for a partially observ ed Quan tized-F eedback Linear-Quadratic-Gaussian (QF-LQG) system, where the measure- men ts are quantized before b eing sent to the controller. The system is presented with sev eral c hoices of quan tizers, along with the cost of using eac h quan tizer. The ob jective is to join tly select the quan tizers and syn thesize the con troller to strik e an optimal balance be- t ween con trol p erformance and quantization cost. When the innov ation signal is quantized instead of the measurement, the problem is decoupled into t wo optimization problems: one for optimal controller synthesis, and the other for optimal quantizer selection. The optimal con troller is found by solving a Riccati equation and the optimal quantizer selection p olicy is found by solving a linear program (LP)- b oth of which can b e solved offline. Keywor ds: Quantized optimal control, communication constrained control. 1 In tro duction Net work ed con trol systems op erating under finite data-rate constrain ts emplo y signal quanti- zation to reduce the amount of data for communication. System-sp ecific quan tizers (enco ders) and deco ders are designed to compress signals with a finite n umber of bits and to incur mini- mal signal reconstruction errors, resp ectively . The av ailable bit-rate to quan tize the signals, as w ell as the choice of the quan tizers and the deco ders, determine the error in the reconstructed signals, and consequen tly , they affect the p erformance of the con trol system [19, 27]. The quan tizers used for netw orked con trol systems with limited data-rates are designed to ensure that the least amount of information is lost due to the enco ding pro cess. T o ac hieve this goal, often these quantizers m ust be time-v arying and the dynamics of the time-v arying quantizer parameters are tied to the dynamics of the net work ed control systems for optimal p erformance [27]. ∗ This work has b een supp orted b y ARL under DCIST CRA W911NF-17-2-0181 and b y ONR aw ard N00014- 18-1-2375. † Departmen t of Electrical and Computer Engineering, Univ ersity of North Carolina at Charlotte, Charlotte, NC, 28223, USA, (dmaity@uncc.edu). ‡ Guggenheim School of Aerospace Engineering, Georgia Institute of T echnology , A tlanta, GA, 30332, USA, (tsiotras@gatec h.edu). 1 Time-v arying quan tizers pro vide the flexibilit y to send high resolution quantized signals when needed, and use a coarser resolution otherwise. T ypically , design of dynamic quantiz- ers requires solving a join t optimization problem for the quantizer and the con troller [37] to obtain optimal performance. Suc h co-design the easily becomes in tractable due to the non- linear/saturation b ehavior of the quantization pro cess. Ev en for the linear-quadratic optimal con trol problem – whic h is one of the simplest problems in optimal control for which an ana- lytical closed-form solution exists – b ecomes intractable when quantized measurements are fed bac k to the controller. In [14], the authors show the lack of a sep ar ation principle for an LQG system with quantized feedbac k. In [37], the authors demonstrated that a separation principle exists when pr e dictive quantizers are used. F urthermore, this work also demonstrated that the use of predictive quantizers can b e made without loss of generalit y . The principle b ehind predictiv e quantizers is not to quantize the state X t (whic h contains all the past control), but rather to quantize a signal that is obtained after removing all the past control history from X t . While these works provide some characterization on the optimal quantizer, how ev er, the exact solution of the optimal quan tizer is not a v ailabl. LQG con trol with quan tization has been studied for a long time [5, 22, 31, 32, 33, 34] and many others. Owing to the intractabilit y of the problem, these works do not readily pro vide the optimal quantizers. An exception is [3], where an iterativ e metho d is prop osed to find a quantizer and a con troller for LQG systems. In principle, the iterative metho d con verges in the case of op en-lo op enco der systems. How ever, as mentioned in that w ork, the prop osed iterative metho d do es not necessarily conv erge for the general case with partial side information. F or the sp ecial case of op en-lo op enco der systems, the pro cess is likely to conv erge to a lo cal optimum instead to the global one. T o circum ven t the in tractability asso ciated with finding the optimal qunatizers, we formu- late a problem to find the optimal quantizer from a given finite collection of quantizers for an LQG system. In this wa y , our form ulation b ecomes a quan tizer scheduling/selection problem where the b est quan tizer at each time instance is selected from a given finite set. W e assume a partially observed linear system that can c ho ose from a giv en set of quantizers to quantize its measuremen ts and transmit the resulting quantized signal to the controller. The system can use different quantizers at differen t time instances to meet the need for time-v arying quantizer resolution. W e further assume that these quantizers are costly to use and different quantizers ha ve p ossibly different costs of op eration. The performance of the system is thus measured b y an expected quadratic cost plus the total cost for using the quan tizers. Quantizers with higher resolution are generally more costly than ones with low er resolution. Therefore, b e tter con trol p erformance can b e achiev ed at the exp ense of a higher quan tization cost. This wa y , our framew ork provides a con trol-quantization trade-off. Some of the earlier works on quan tization and control can be traced bac k ed to [28, 8, 26, 10]. These works do not necessarily fo cus on finding the optimal quantizer, but rather inv estigate the effects of a giv en quan tizer in the system performance. While optimalit y (whic h is measured b y a weigh ted sum of a control and quantization costs) is the fo cus in the curren t pap er, the w orks in [11, 35, 36, 15, 20] consider stability of the system to b e their fo cus. In [35] and [36], the authors explicitly considered the issues of quan tization, co ding and dela y . The concept of c ontainability was used to study stability of linear systems. A quantization scheme with time- v arying quantization sensitivit y was studied in [6] proving asymptotic stabilit y of the system. In [21] the author deriv ed a relationship b etw een the norm of the transition matrix and the n umber of v alues tak en by the encoder to ensure global asymptotic stabilit y . Reference [27] addressed the problem of finding the smallest data-rate ab ov e whic h exp onen tial stabilit y can 2 b e ensured. In all ab o vemen tioned w orks, the role of quantization has b een prov en to b e crucial. How- ev er, for a given control ob jectiv e, ho w to sc hedule from a set of a v ailable quantizers, which ha ve a cost asso ciated with them, has not b een addressed. T o the b est of our knowledge, [25] is the first work where a joint optimization framework is considered to syn thesize an optimal con troller and schedule the optimal quan tizers from a giv en set of costly quantizers. This article extends the w ork of [25] b y considering a partially observ ed system with noisy sensors, and, more imp ortantly , it explicitly considers the nuisances of delay and out-of-order measuremen t a v ailabilit y . Con tributions The contributions of this w ork are as follo ws. W e show that quantizing the “inno v ation signal” separates the controller synthesis problem from the quan tizer selection problem. While the idea of innov ation–quantization was originally prop osed in [5] for a fully observ ed system with a deterministic initial state, in this work, we extend the innov ation- quan tization idea for partially observed systems with uncertain initial states. F urthermore, we explicitly consider delays in the arriv al of the measurements at the controller. W e study the optimal controller and show that the con troller is of a certain ty-equiv alence t yp e. The controller gains can b e computed offline and they do not dep end on the parameters of the quan tizers. The analysis of the quan tizer-selection problem reveals that the optimal strategy for the selection of the quan tizers can also b e computed offline by solving a simple linear programming problem. The rest of the pap er is organized as follows: in Section 2 we discuss some background on random v ariables; in Section 3 we formally define the problem addressed in this pap er; Section 4 pro vides the structure for the optimal controller and the quantizer selection scheme. Finally , w e conclude the pap er in Section 7. 2 Preliminaries In this section we pro vide some background on random v ariables, the Hilb ert space of random v ariables, condition exp ectation, and the orthogonal pro jection of random v ariables defined on a Hilb ert space. Define the probability space (Ω , F , P ) where Ω is the sample space, F is the set of even ts, and the measure P : F → [0 , 1] defines the probability of o ccurring an even t. In this probability space, X : Ω → X is a random v ariable defined as a measurable function from the sample space Ω to a measurable space X , such that for any measurable set S ⊆ X , X − 1 ( S ) = { ω ∈ Ω : X ( ω ) ∈ S } ∈ F . E [ X ] denotes the exp ected v alue of X , with resp ect to P , defined as E [ X ] = R Ω X ( ω )d P ( ω ). Let us define the space H of real-v alued ( X = R ) random v ariables X : Ω → R such that H = { X | E [ X 2 ] < ∞} . F or X , Y ∈ H , αX + β Y ∈ H for all α, β ∈ R . The inner pro duct in H is defined by h X , Y i = E [ X Y ] . F act 1 [24, Section 4.2]: H is a Hilb ert space. 3 Let X 1 , . . . , X ` b e a collection of ` random v ariables b elonging to H . The σ -field generated b y th ese random v ariables is denoted as σ ( X 1 , . . . , X ` ), and the linear span of these random v ariables is denoted b y σ L ( X 1 , . . . , X ` ) = { Y | Y = P ` i =1 c i X i , c i ∈ R } . Clearly , we hav e that σ L ( X 1 , . . . , X ` ) ⊆ σ ( X 1 , . . . , , X ` ). The function g ( X 1 , . . . , X ` ) : R ` → R is a measurable function of the random v ariables X 1 , . . . , X ` if g − 1 ( S ) ∈ σ ( X 1 , . . . , X ` ) for all S ⊆ R . Let G denote the set of all measurable functions g ( X 1 , . . . , X ` ) of ` random v ariables X 1 , . . . , X ` . The conditional exp ectation of a random v ariable Y conditioned on the random v ariables X 1 , . . . , X ` , denoted as E [ Y | X 1 , . . . , X ` ] ∈ G , is defined as [4, Section 34] Z S E [ Y | X 1 , . . . , X ` ] d P = Z S Y d P , ∀ S ∈ σ ( X 1 , . . . , X ` ) . The follo wing Lemma is adapted from [29, Theorem 3.6]. Lemma 1 F or any r andom variable Y , the solution to the optimization pr oblem inf g ∈G E [( Y − g ) 2 ] is g ∗ ( X 1 , . . . , X ` ) = E [ Y | X 1 , . . . , X ` ] . That is, E [ Y | X 1 , . . . , X ` ] is the pro jection of the random v ariable Y onto the span of the σ -field G generated by X 1 , . . . , X ` . The pro jection error Y − E [ Y | X 1 , . . . , X ` ] is orthogonal to any measurable function g ( X 1 , . . . , X ` ) ∈ G (i.e., the error is orthogonal to the σ -field σ ( X 1 , . . . , X ` )), h Y − E [ Y | X 1 , . . . , X ` ] , g i = 0 , ∀ g ∈ G . The follo wing Lemma, presen ted without proof, states that in the case of Gaussian random v ariables the conditional exp ectation can be represen ted as an affine combination of X 1 , . . . , X ` . Lemma 2 [9, Chapter 11] L et Y , X 1 , . . . , X ` b e jointly Gaussian r andom variables. Then, ther e exists c 0 , . . . , c ` ∈ R such that E [ Y | X 1 , . . . , X ` ] = c 0 + ` X i =1 c i X i ∈ σ L (1 , X 1 , . . . , X ` ) . The study in [1] pro vides necessary and sufficien t conditions for the conditional expectation E [ Y | X 1 , . . . , X ` ] to b e a linear function of X 1 , . . . , X ` when the v ariables are not jointly Gaus- sian. The previous definitions and lemmas can be extended to multi-dimensional random v ariables [24, 4, 29, 9]. 3 Problem F orm ulation Let us consider a linear discrete-time sto c hastic system X t +1 = A t X t + B t U t + W t , (1) Y t = C t X t + ν t , (2) 4 where, for all t ∈ N 0 (= N ∪ { 0 } ), X t ∈ R n , U t ∈ R m and Y t ∈ R p , A t , B t and C t are matrices of compatible dimensions, { W t } t ∈ N 0 and { ν t } t ∈ N 0 are tw o i.i.d noise sequences in R n and R p with statistics W 0 ∼ N (0 , W ) and ν 0 ∼ N (0 , V ), resp ectiv ely , and W k , ν j are indep endent for all j , k ∈ N 0 . The initial state, X 0 , is also a Gaussian random v ariable distributed according to N ( µ 0 , Σ x ), and indep enden t of the noises W t and ν t for all t ∈ N 0 . F or notational con venience, w e will write X 0 = µ 0 + W − 1 where W − 1 ∼ N (0 , Σ x ). Thus, X 0 , W k , W ` , ν i and ν j are indep enden t random v ariables for all k , `, i, j = 0 , 1 , . . . , such that k 6 = ` , and i 6 = j . In what follo ws, w e will consider A t , B t and C t to be time inv ariant in order to main tain notational brevit y . How ev er, the extension of the results presented in the subsequen t sections to time v arying A t , B t and C t is straigh tforward and do es not require any further assumptions. In this work, we address the quantized output feedbac k LQG (QO-LQG) optimal control problem defined as follows. Referring to Figure 1, we assume that M quantizers are provided to quantize the measurement Y t and transmit the quantized output to the con troller. The range of the i -th quantizer is denoted by Q i = { q i 1 , q i 2 , · · · , q i ` i } . Thus, the i -th quantizer has ` i quan tization levels. Without any loss of generalit y , we assume that ` 1 ≤ . . . ≤ ` M . Asso ciated with the i -th quan tizer, let P i = {P i 1 , P i 2 , · · · , P i ` i } denote a partition of R p suc h that P i j gets mapp ed to q i j for each j ∈ { 1 , 2 , · · · , ` i } . Sp ecifically , one may think of the i -th quantizer as a mapping g i : R p → Q i suc h that g i ( y ) = q i j if and only if y ∈ P i j . The quan tized measurements are transmitted through a communication channel that has a finite data-rate. Consequently , some quantized measurements ma y need more than one time step to complete the sensor-to-con troller transmission and the decoding at the controller’s site [2], and hence, the av ailability of that measuremen t to the con troller will b e dela yed. F urthermore, quantized signals of different lengths may exp erience different amounts of dela y , and hence, out-of-order measuremen t a v ailabilit y is inevitable [17]. In this work, w e do not adhere to any particular mo del for c haracterizing this dela y , rather we simply consider the case where a quan tized signal with larger num b er of bits may exp erience a longer dela y b efore it is a v ailable to the controller. That is, the dela y d i asso ciated with the i -th quantizer is non- decreasing with i , i.e., d 1 ≤ d 2 ≤ . . . ≤ d M . The num b er of quan tization lev els ` i generally captures the resolution of the quantization, i.e., a higher ` i t ypically means a b etter resolution and lesser quantization error, but, at the same time, it induces longer delay d i . Therefore, this w ork will also reveal the trade-off b etw een choosing a coarser but faster quantization service v ersus a finer but dela yed service. In fact, we will see later on that, for a finite-horizon optimal con trol problem, different resolution-delay (finer-delay ed vs . coarser-faster) characteristics are preferred at different time instances. Asso ciated with each quantizer there is an op erating cost that m ust b e paid in order to use this quantizer. Let λ ( Q i ) = λ i ∈ R + denote the cost asso ciated with the i -th quantizer. F or example, λ i ∝ log 2 ` i represen ts the case where the cost is prop ortional to the co de-length used to enco de the output of the quan tizer. This c ost is also related to the delay asso ciated with the con troller. In this work, we do not adhere to any sp ecific structure for λ . W e just assume that the v alues of λ i ’s are given to us a priori. If there is a cost for op erating the communication c hannel, that cost can b e also incorp orated into λ i . Note that, in contrast to previous w orks [35, 13], w e do not aim at designing a quantization sc heme, rather a set of quantizers is already giv en by some service pro vider. Our ob jective is to optimally decide which quantizer is to b e requested for use at what time instances. Also, w e will assume that the costs λ i are determined by the service provider and presen ted to us a priori. Designing suc h costs in order to regulate the use of the quantizers is an equally in teresting 5 Figure 1: Sc hematic diagram of the system. The top-right gray blo c k contains the quan tizer selector that selects the optimal quan tizer at eac h time, and the inno v ation block that pro duces the inno v ation signals from the measurements. The down-righ t gra y blo ck contains the set of M quantizers whose outputs are sen t through the comm unication channel to the con troller. problem for the service pro vider that will b e addressed elsewhere. W e will further assume that the comm unication channel b et ween eac h quan tizer and the con troller alwa ys transmits the quan tized information without an y distortion. The ob jective is to minimize a p erformance index that takes into account the quan tization cost. Contrary to the existing literature on quantization-based LQG [5, 31, 32, 33, 34, 22], in our case there are tw o decision makers instead of a single one: One decision-mak er (the con troller) decides the input ( { U t } t ∈ N 0 ) to apply to the system, and the other decision-maker (the quan tizer-selector) decides the quality and dela y of the measurements (quan tized state v alues) which are transmitted to the con troller. W e in tro duce a new decision v ariable θ i t for the quantizer-selector in the following wa y: θ i t = ( 1 , i -th quan tizer is used at time t, 0 , otherwise. Let us denote the vector θ t , [ θ 1 t , θ 2 t , . . . , θ M t ] T ∈ { 0 , 1 } M , that characterizes the decision of the quan tizer-selector at time t . W e enforce the quantizer-selector to select only one quan tizer at an y time instance, and hence for all t ∈ N 0 , w e hav e M X i =1 θ i t = 1 . (3) The deco ded measuremen t(s) av ailable to the con troller at time t is denoted as ˆ O t . Note that ˆ O t ma y con tain delay ed quantized measurements; also, sev eral measurements may b e made a v ailable sim ultaneously at the con troller. F or example, as shown in Figure 2, if there are tw o quan tizers with d 1 = 1 and d 2 = 3, and if the second quantizer is selected at time 0 follow ed 6 b y the selection of the first quan tizer at times t = 1 , 2, then no deco ded measuremen ts are a v ailable at times t = 0 , 1, i.e., ˆ O 0 = ˆ O 1 = ∅ . The decoded information about Y 1 , denoted as ˆ Y 1 , is av ailable at time t = 2, i.e., ˆ O 2 = { ˆ Y 1 } , and the deco ded information ab out Y 0 and Y 2 are av ailable sim ultaneously at time t = 3, i.e., ˆ O 3 = { ˆ Y 0 , ˆ Y 2 } . Thus, ˆ O t is a function of { θ 0 , . . . , θ t } (to be precise, ˆ O t is only a function of { θ t − d i : i = 1 , . . . , M , t − d i ≥ 0 } ). A 0 1 2 3 4 5 6 7 ˆ O 0 = ∅ ˆ O 1 = ∅ ˆ O 2 = { ˆ Y 1 } ˆ O 3 = { ˆ Y 0 , ˆ Y 2 } ˆ O 4 = ∅ ˆ Y 0 ˆ Y 1 ˆ Y 2 Figure 2: Out-of-order measurement a v ailabilit y at the controller when the second quantizer (with delay 3) is selected at times t = 0 , 3 , 4 and the first quan tizer (with dela y 1) is selected at other time instances. The new deco ded measurements a v ailable at time t at the controller is ˆ O t , i.e., ˆ O 0 = ˆ O 1 = ∅ , ˆ O 2 = { ˆ Y 1 } , ˆ O 2 = { ˆ Y 0 , ˆ Y 2 } , and so on. In this example, ˆ Y 1 is av ailable b efore ˆ Y 0 and ˆ Y 5 is a v ailable b efore ˆ Y 4 . detailed description of ˆ O t will b e provided later on. Let us in tro duce the sets Y t , { Y 0 , Y 1 , · · · , Y t } , ˆ O t , { ˆ O 0 , ˆ O 1 , · · · , ˆ O t } U t , { U 0 , U 1 , · · · , U t } and Θ t , { θ 0 , θ 1 , · · · , θ t } to b e the measuremen t history , quantized measuremen t history at the con troller, con trol history , and quan tization-selection history , resp ectively . F or conv enience, we will use the notation U for U T − 1 , and likewise, we will use Θ for Θ T − 1 . The information av ailable to the con troller at time t is I c t = { ˆ O t , U t − 1 } = I c t − 1 ∪ { ˆ O t , U t − 1 } where I c 0 = { ˆ O 0 } . It should b e noted that I c t dep ends on Θ t through ˆ O t . In classical optimal LQG control, the information av ailable to the controller is not decided b y any activ e decision mak er, unlike the situation here. An admissible control strategy at time t is a measurable function from the Borel σ -field generated by I c t to R m . Let us denote such strategies by γ u t ( · ) and the space they b elong to by Γ u t . On the other hand, the information av ailable to the quan tizer-selector at time t is I q t = {Y t , ˆ O t − 1 , U t − 1 , Θ t − 1 } = I q t − 1 ∪ { Y t , ˆ O t − 1 , U t − 1 , θ t − 1 } where I q 0 = { Y 0 } . The information I q t will b e used to generate a signal ξ t = f ( I q t ) that will further b e quantized b efore b eing transmitted to the controller. If f ( I q t ) = Y t , then the output itself is quantized. The information ¯ I q t = { ˆ O t − 1 , Θ t − 1 } ⊂ I q t will b e used to decide the optimal quan tizer to quantize ξ t . Thus, the admissible strategies for the selection of the quantizers are measurable functions from the Borel σ -field generated by ¯ I q t to { 0 , 1 } M . Let us denote such strategies by γ θ t ( · ), and the space they b elong to by Γ θ t . Thus, the entire quantization pro cess is c haracterized by the follo wing tw o equations: ξ t = f ( I q t ) , (4a) θ t = γ θ t ( ¯ I q t ) . (4b) F or brevit y , we will often use γ u t instead of γ u t ( · ) or γ u t ( I c t ), and γ θ t in place of γ θ t ( · ) or γ θ t ( ¯ I q t ). Let γ Θ denote the en tire sequence { γ θ 0 , γ θ 1 , · · · , γ θ T − 1 } and let Γ Θ denote the space where γ Θ b elongs to. Lik ewise, γ U and Γ U are defined similarly . Let us also define I c = { I c t } T − 1 t =0 and I q = { I q t } T − 1 t =0 . The sequence of decision making within one time instance is then as follows: 7 I q t f ,γ θ t → { ξ t , θ t } → ˆ O t → I c t γ u t → U t → X t +1 → Y t +1 → I q t +1 . The cost function to b e minimized co op eratively by the quan tizer-selector and the controller is a finite horizon exp ected quadratic criterion, giv en as J ( U , Θ) = E " T − 1 X t =0 ( X T t Q 1 X t + U T t RU t + θ T t Λ) + X T T Q 2 X T # , (5) where Λ = [ λ 1 , λ 2 , . . . , λ M ] T is the cost for quan tization, Q 1 , Q 2 0, R 0, U = γ U ( I c ) = { γ u 0 ( I c 0 ) , γ u 1 ( I c 1 ) , . . . , γ u T − 1 ( I c T − 1 ) } and Θ = γ Θ ( ¯ I q ) = { γ θ 0 ( ¯ I q 0 ) , γ θ 1 ( ¯ I q 1 ) , . . . , γ θ T − 1 ( ¯ I q T − 1 ) } . W e seek to find the optimal strategies γ U ∗ = { γ u ∗ 0 , γ u ∗ 1 , . . . , γ u ∗ T − 1 } and γ Θ ∗ = { γ θ ∗ 0 , γ θ ∗ 1 , . . . , γ θ ∗ T − 1 } that minimize (5). W e will also rewrite (5) in terms of γ U and γ Θ as J ( γ U , γ Θ ) = E h T − 1 X t =0 ( X T t Q 1 X t + U T t RU t + θ T t Λ) + X T T Q 2 X T | U t = γ u t ( I c t ) , θ t = γ θ t ( ¯ I q t ) i . (6) The cost function (6) is affected by the choice of the function f ( I q t ). Solving an estimation problem is intractable even when ξ t = f ( I q t ) = Y t and there is only one quantizer, let alone the con trol problem with multiple quantizers; for example, confer [12, 7, 18, 30] and the references therein. Although a linear quadratic Gaussian system is considered here, the non-linearity asso ciated with the quantization pro cess makes the problem challenging, since quantization results in a nonlinear sto chastic optimal control problem. T o keep our analysis tractable, in this pap er, we will consider ξ t = f ( I q t ) = Y t − E [ Y t | Y 0 , . . . , Y t − 1 ] , that is, the innov ation signal. Quantizing the inno v ation signal not only mak es the problem tractable, but also allows us to sho w that a separation principle b etw een control and quan tizer- selection is retained. It is well kno wn [16] that the information con tained in the inno v ation signals { ξ 0 , . . . , ξ t } is the same as the information con tained in the observ ations { Y 0 , . . . , Y t } . Therefore, designing an output-feedback con troller is equiv alen t to designing an innov ation- feedbac k controller. Ho wev er, after quantization, the information contained in the quantized inno v ations is not necessarily the same as the information contained in the quantized out- puts. Therefore, in general, it cannot b e claimed that the p erformance of the optimal output- quan tized feedback controller will b e the same as that of the optimal innov ation-quantized feedbac k controller. In the following, the information I q t = {Y t , ˆ O t − 1 , U t − 1 , Θ t − 1 } will b e divided into t wo parts, namely , {Y t , U t − 1 } , whic h will b e used for generating the inno v ation signals ξ t , and ¯ I q t = { ˆ O t − 1 , Θ t − 1 } , whic h will b e used for selecting the quantizers. Therefore, (4) takes the form ξ t = Y t − E [ Y t |Y t − 1 , U t − 1 ] , (7a) θ t = γ θ t ( ¯ I q t ) = γ θ t ( { ˆ O t − 1 , Θ t − 1 } ) . (7b) A t this p oint, one may notice that the presence of U t − 1 is redundan t in (7a) since U t is a function of I c t whic h can b e written as some function (that dep ends on γ u t , γ θ t , and f ) of Y t . 8 4 Optimal Con trol and Quantization Selection In this section w e find the optimal γ U ∗ and γ Θ ∗ that minimize the cost function (6) amongst all admissible strategies, that is, ( γ U ∗ , γ Θ ∗ ) = arg min γ U ∈ Γ U ,γ Θ ∈ Γ Θ J ( γ U , γ Θ ) . (8) Before pro ceeding further to solv e (8), let us discuss, in some detail, the input for the quan tization pro cess since it will play a crucial role in the following analysis. Unlike other quan tized feedbac k-based con trol approac hes [34], [22], we will quantize an inno v ation signal ξ t instead of Y t at time t . The inno v ation signal ξ t can be readily computed from the mea- suremen t history Y t as follows. Let H b e the Hilb ert space of random v ariables in R p ha ving finite cov ariances. The observ ations Y 0 , Y 1 , . . . , Y t b elong to H , and the σ -field generated by these random v ariables is denoted b y σ ( Y t ) = σ ( Y 0 , . . . , Y t ). With a sligh t abuse of notation, w e will use Y t to denote b oth the σ -field σ ( Y t ) and the set of random v ariables { Y 0 , Y 1 , . . . , Y t } , whenev er the context is not ambiguous. These random v ariables ma y not necessarily b e or- thogonal, i.e., E [ Y i Y T j ] 6 = 0. Ho wev er, one can construct random v ariables ξ 0 , ξ 1 , . . . , ξ t whic h are orthogonal and σ ( ξ 0 , . . . , ξ t ) = σ ( Y t ). It can b e shown that the random v ariable ξ i is of the form ξ i = Y i − E [ Y i |Y i − 1 ]; see [16]. In order to prov e the orthogonality of ξ i , ξ j , let us consider i > j (hence Y i − 1 ⊇ Y j ), and observe that E [ ξ i ξ T j ] = E E [ ξ i ξ T j |Y j ] = E ( E [ ξ i |Y j ]) ξ T j = E ( E [ Y i − E [ Y i |Y i − 1 ] |Y j ]) ξ T j = E [0 ξ T j ] = 0 . 4.1 The Inno v ation Pro cess The con trol U t is a function of the quantized innov ations which are not Gaussian random v ari- ables. Therefore, the state X t and the measuremen t Y t are no-longer Gaussian random v ariables under quan tized inno v ation feedbac k. Although the inno v ation signal is a Gaussian random v ariable for partially observ ed classical linear-quadratic-Gaussian systems without quan tiza- tion, in our case, this may no longer b e true since the control is a function of quan tized signals (whic h are not Gaussian random v ariables). W e therefore need to indep enden tly v erify whether the distribution of the innov ation signal is Gaussian or not. It can be v erified that the innov ation ξ t is not affected b y the con trol strategy , although, Y t is affected. F urthermore, the innov ation ξ t retains its Gaussian distribution and the parameters of this distribution can b e computed offline. This observ ation is presented in the following prop osition. Prop osition 4.1 F or al l t , ξ t is a Gaussian r andom variable with zer o me an and c ovarianc e M t such that M t +1 = C Σ t +1 | t C T + V Σ t +1 | t = A Σ t A T + W , Σ 0 |− 1 = Σ x Σ t +1 = Σ t +1 | t − Σ t +1 | t C T M − 1 t +1 C Σ t +1 | t . 9 Mor e over, the se quenc e of r andom variables { ξ 0 , . . . , ξ t } is unc orr elate d for al l t . Pr o of: The pro of is presented in App endix A. Prop osition 4.1 is equiv alen t of the following facts: 1. The innov ation sequence { ξ t } t ∈ N 0 do es not dep end on the control history U t − 1 . 2. The innov ation sequence is a Gaussian uncorrelated noise sequence with zero mean and co v ariance M t . 3. Since the sequence of random v ariables { ξ t } t ∈ N 0 is uncorrelated and Gaussian, each ξ t and ξ k are indep enden t for all k 6 = t . 4.2 Implications of Delay Let g i ( ξ t ) ∈ Q i denote the quantized version of ξ t if the i -th quan tizer is selected. Therefore, the quan tized information sen t to the con troller is ˆ ξ t = M X i =1 g i ( ξ t ) θ i t , (9) and this information will b e deco ded and b e av ailable at the controller at time t + P M i =1 θ i t d i . Notice that g i ( ξ t ) ∈ Q i is a random v ariable, and hence ˆ ξ t is a random v ariable taking v alues in the discrete set ∪ M i =1 Q i with P ( ˆ ξ t = q i j ) = P ( ξ t ∈ P i j ). Since the dela ys may result in out-of-order a v ailabilit y of the deco ded signal to the con troller, it is imp ortant that every quantized signal is time-stamp ed, i.e., when the controller receives a deco ded measurement ˆ q at time t , it should b e able to uniquely determine whic h of the signals { ξ 0 , . . . , ξ t } was quantized to pro duce this measurement along with the quantizer that w as used. In order to uniquely deco de whic h of the signals { ξ 0 , . . . , ξ t } pro duced the data ˆ q , the pair ( ˆ ξ t , i ) will b e sent at each time t , where i is the index of the quantizer that w as used to quantize ξ t . Consequently , if the deco ded pair ( ˆ q , i ) is received by the controller at time t , then the controller can immediately infer that the i -th quan tizer w as used and that this signal is delay ed by d i units, and hence ˆ q corresp onds to ξ t − d i . Th us, ( ˆ q , i ) rev eals that θ i t − d i = 1, and ˆ q = g i ( ξ t − d i ). At any time t , there can b e at most M (delay ed) new simultaneously av ailable deco ded measuremen ts. Let us define the set of indexes that are present in ˆ O t b y idx t = { i : ∃ q ∈ R p s.t. ( q , i ) ∈ ˆ O t } ⊆ { 1 , . . . , M } . Therefore, θ i t − d i = 1 if i ∈ idx t , otherwise θ i t − d i = 0. It follows that the new deco ded measuremen ts av ailable to the con troller at time t can b e expressed as: { θ 1 t − d 1 , . . . , θ M t − d M } ∪ { ˆ ξ t − d i : i ∈ idx t } . With a slight abuse of notation, the ab ov e set is equiv alen t to: { θ 1 t − d 1 , . . . , θ M t − d M , θ 1 t − d 1 ˆ ξ t − d 1 , · · · , θ M t − d M ˆ ξ t − d M } . Ha ving characterized the effects of dela ys in the information av ailable to the controller, in the next section, we discuss the optimal controller that minimizes the cost function (6). 10 4.3 Optimal Con trol Policy Let us define the innov ation history by Ξ t , { ξ 0 , . . . , ξ t } . With a slight abuse of notation, we also denote Ξ t = σ ( ξ 0 , . . . , ξ t ) to b e the σ -field that generated these innov ation signals. Let us further define the state estimate by ¯ X t , E [ X t | I c t ] . (10) The quan tized information a v ailable to the con troller at time t is ˆ O t = { ϑ 0 ,t ˆ ξ 0 , ϑ 1 ,t ˆ ξ 1 , · · · , ϑ t,t ˆ ξ t }∪ t k =0 { θ i k − d i : i = 1 , . . . , M , k − d i ≥ 0 } , where ϑ k,t is an indicator of whether ˆ ξ k is av ailable at the con troller by time t or not. Note that ϑ k,t can b e expressed as ϑ k,t = M X i =0 θ i k 1 d i ≤ t − k . (11) Clearly , if t − k ≥ d M for some k , then the ab o ve expression for ϑ k,t b ecomes ϑ k,t = P M i =0 θ i k = 1 ensuring that the quantized version of ξ k is presen t at the con troller. Similarly to ˆ O t , let us define the set O t = { ϑ 0 ,t ξ 0 , ϑ 1 ,t ξ 1 , · · · , ϑ t,t ξ t } ∪ t k =0 { θ i k − d i : i = 1 , . . . , M , k ≥ d i } , which con tains the inno v ation signals that w ere quantized to pro duce ˆ O t along with the corresponding indexes of the quantizers that w ere used. Due to the construction of O t , ˆ O t do es not contain any new information when O t is giv en 1 . Therefore, we hav e ¯ X t = E [ X t | I c t ] = E [ X t | ˆ O t , U t − 1 ] = E [ E [ X t |O t , ˆ O t , U t − 1 ] | ˆ O t , U t − 1 ] = E [ E [ X t |O t , U t − 1 ] | ˆ O t , U t − 1 ] (12) In order to compute ¯ X t , w e compute E [ X t |O t , U t − 1 ] which is inside the outer exp ectation of the last equation. Lemma 3 F or any t , E [ X t |O t , U t − 1 ] = A t µ 0 + t X k =0 Ψ( t, k ) ϑ k,t ξ k + t − 1 X k =0 A t − 1 − k B U k , (13) and, for al l t ≥ k , the matric es Ψ( t, k ) ar e given by Ψ( t, k ) = A t − k Σ k | k − 1 C T M − 1 k . (14) Pr o of: The pro of is given in App endix B. Therefore, using Lemma 3 we obtain from (12) that ¯ X t = E [ E [ X t |O t , U t − 1 ] | ˆ O t , U t − 1 ] = A t µ 0 + t X k =0 Ψ( t, k ) ϑ k,t E [ ξ k | ˆ O t ] + t − 1 X k =0 A t − 1 − k B U k , (15) 1 O t con tains the innov ation signals that were quantized to pro duce ˆ O t as w ell as the corresp onding indices of the quantizers that were used for quantization. Therefore, each ˆ ξ k ∈ ˆ O t can b e computed from O t . 11 where, we hav e used the fact that U t is a measurable function of I c t = { ˆ O t , U t − 1 } for all t , and hence, given ˆ O t , the control history U t − 1 do es not provide any new information ab out ξ k , i.e., E [ ξ k | ˆ O t , U t − 1 ] = E [ ξ k | ˆ O t ]. Next, we fo cus on computing E [ ξ k | ˆ O t ]. T o that end, let us define ¯ ξ i t , E [ ξ t | ˆ ξ t , θ i t = 1]. Based on (3) and (9), we may write ¯ ξ i t = E [ ξ t | g i ( ξ t ) , θ i t = 1] = ` i X j =1 1 g i ( ξ t )= q i j E [ ξ t | g i ( ξ t ) = q i j , θ i t = 1] = ` i X j =1 1 g i ( ξ t )= q i j E [ ξ t | ξ t ∈ P i j ] = ` i X j =1 1 g i ( ξ t )= q i j Z P i j ξ P t (d ξ |P i j ) (16) where 1 a = b is an indicator function that is equal to 1 if and only if a = b , otherwise it equals 0. Therefore, ¯ ξ i t is a random v ariable taking v alues in the set { R P i j ξ P t (d ξ |P i j ) : j = 1 , . . . , ` i } and it dep ends on the realization of ξ t through 1 g i ( ξ t )= q i j . F rom Prop osition 4.1, one can easily compute the measure P t (d ξ |P i j ) as follows P t (d ξ |P i j ) = ( α t e − ξ T M − 1 t ξ / 2 d ξ , ξ ∈ P i j , 0 , otherwise , (17) ( α t ) − 1 = p (2 π ) p det( M t ) P ( ξ t ∈ P i j ) , = Z P i j e − ξ T M − 1 t ξ / 2 d ξ . (18) F urthermore, from Prop osition 4.1, we ha ve that ξ t ∼ N (0 , M t ). Since M t can b e computed offline, the prior distribution of ξ t is kno wn to the con troller. After receiving the quan tized v alue ˆ ξ t , the controller up dates the distribution of ξ t . If the quan tized v alue of ξ t , after b eing quan tized by the i -th quantizer, is ˆ ξ t = q i j , then the con troller can infer that ξ t ∈ P i j . This is illustrated in Figure 3. The entit y ¯ ξ i t computes the exp ected v alue of ξ t giv en that the i -th quantizer was used in the pro cess of quantization, and the quantized v alue is ˆ ξ t ∈ Q i . Now, let us further define ¯ ξ t , E [ ξ t | ˆ ξ t , θ t ] = M X i =1 θ i t ¯ ξ i t , (19) and ˜ ξ t , ξ t − ¯ ξ t . (20) F rom this definition of ¯ ξ t , along with the constraint P M i =1 θ i t = 1, w e ha ve that ¯ ξ t = ¯ ξ i t if and only if the i -th quantizer was selected at time t . The conditional cov ariance M t ( θ t ) , E [ ˜ ξ t ˜ ξ T t | θ t ] turns out to b e M t ( θ t ) = E ξ t ξ T t − ξ t ¯ ξ T t − ¯ ξ t ξ T t + ¯ ξ t ¯ ξ T t | θ t = E [ ξ t ξ T t | θ t ] − E [ ¯ ξ t ¯ ξ T t | θ t ] = E [ ξ t ξ T t | θ t ] − E [ ¯ ξ t ¯ ξ T t | θ t ] , (21) 12 | {z } P i 2 | {z } P i 3 | {z } P i 1 (a) (b) Figure 3: (a): The blue curve denotes the prior distribution P t (d ξ ). The partitions P i j for the i -th quan tizer is sho wn as w ell where P i 2 is highligh ted with the orange blo ck. (b) The p osterior distribution ( P t (d ξ |P i 2 )) of ξ t is shown here for the case when the receiv ed quantized measuremen t ˆ ξ t is q i 2 (or equiv alen tly , ξ t ∈ P i 2 ). where we ha ve used the fact that E [ ξ t ¯ ξ T t | θ t ] = E [ E [ ξ t ¯ ξ T t | ˆ ξ t , θ t ] | θ t ] = E [ E [ ξ t | ˆ ξ t , θ t ] ¯ ξ T t | θ t ] = E [ ¯ ξ t ¯ ξ T t | θ t ]. By defining F t ( θ t ) , E [ ¯ ξ t ¯ ξ T t | θ t ] and using the expression of ¯ ξ t from (19), we obtain F t ( θ t ) = E [ ¯ ξ t ¯ ξ T t | θ t ] = M X i =1 θ i t E [ ¯ ξ i t ¯ ξ i T t ] = M X i =1 θ i t F i t , (22) where F i t = E [ ¯ ξ i t ¯ ξ i T t ] = ` i X j =1 P ( ξ t ∈ P i j ) E [ ξ t | ξ t ∈ P i j ] E [ ξ t | ξ t ∈ P i j ] T . (23) Therefore, using the definition of F t ( θ t ), we may rewrite (21) as M t ( θ t ) = E [ ξ t ξ T t | θ t ] − F t ( θ t ), and furthermore, w e also obtain E [ M t ( θ t )] = M t − E [ F t ( θ t )]. The linear dep e ndence of F t ( θ t ) on θ t will b e useful in designing a linear-program for selecting the optimal quantizers, as shown later in the pap er. A t this point, recall from Prop osition 4.1 and the discussion thereafter that { ξ t } t ∈ N 0 is a sequence of uncorrelated zero-mean Gaussian noises (hence ξ k , ξ ` are indep endent for k 6 = ` ) and { ˆ ξ t } t ∈ N 0 is the corresp onding sequence of the quantized version of { ξ t } t ∈ N 0 . Therefore, ξ k and ˆ ξ ` are indep enden t for all k 6 = ` . Hence, E [ ξ k | ˆ O t ] = ( E [ ξ k | ˆ ξ k , θ k ] , if ˆ ξ k ∈ ˆ O t , E [ ξ k ] , otherwise . = ϑ k,t ¯ ξ k , (24) where we hav e used the definitions of ¯ ξ t and ϑ k,t to compactly write E [ ξ k | ˆ O t ] = ϑ k,t E [ ξ k | ˆ ξ k , θ k ] = ϑ k,t ¯ ξ k . F rom this observ ation, and using Lemma 3, the expression of ¯ X t is computed in the follo wing lemma. Lemma 4 F or any t , ¯ X t = E [ X t | I c t ] is given by, ¯ X t = A t µ 0 + t X k =0 Ψ( t, k ) ϑ k,t ¯ ξ k + t − 1 X k =0 A t − 1 − k B U k . (25) 13 Pr o of: Notice that, from (15) we hav e E [ X t | I c t ] = A t µ 0 + t X k =0 Ψ( t, k ) ϑ k,t E [ ξ k | ˆ O t ] + t − 1 X k =0 A t − 1 − k B U k . The lemma follows immediately after w e substitute the expression of E [ ξ k | ˆ O t ] from (24) into the last equation. Define the error e t , X t − ¯ X t . It follows from (25) that e t = A t X 0 + t − 1 X k =0 A t − k − 1 W k − A t µ 0 − t X k =0 Ψ( t, k ) ϑ k,t ¯ ξ k . Notice that e t do es not depend on the con trol strategy γ U . How ev er, it do es depend on the quan tizer selection strategy γ Θ through the last term in the ab ov e equation. F urthermore, for all t , E [ e t ] = 0 since E [ ¯ X t ] = E [ X t ] due to the law of total exp ectation. A t this p oint we are ready to return to the cost function (6) and find the optimal controller and the optimal quantizer selection p olicies. Asso ciated with the cost function (6), let us define the v alue function as follows: V k ( I k ) = min { γ u t } T − 1 t = k , { γ θ t } T − 1 t = k E γ h T − 1 X t = k ( X T t Q 1 X t + U T t RU t + θ T t Λ) + X T T Q 2 X T i , (26a) V T ( I t ) = E γ [ X T T Q 2 X T ] , (26b) where the information set I k = { I c k , ¯ I q k } and E γ [ · ] denotes the exp ectation under the strategy pair γ = ( γ U , γ Θ ). Using the dynamic programming principle, V k ( I k ) = min γ u k ∈ Γ u k ,γ θ k ∈ Γ θ k E γ h ( X T k Q 1 X k + U T k RU k + θ T k Λ) + V k +1 i . (27) If γ u ∗ k and γ θ ∗ k minimize the right-hand-side of (27), then the optimal strategies are U ∗ k = γ u ∗ k ( I c k ) and θ ∗ k = γ θ ∗ k ( ¯ I q k ). F rom (26), w e also hav e that min γ U ∈ Γ U ,γ Θ ∈ Γ Θ J ( γ U , γ Θ ) = E γ [ V 0 ] . (28) The follo wing theorem c haracterizes the optimal p olicy γ u ∗ k ( · ) for all k = 0 , 1 , . . . , T − 1. Theorem 4.2 (Optimal Control P olicy) Given the information I c k to the c ontr ol ler at time k , the optimal c ontr ol p olicy γ u ∗ k : I c k → R m that minimizes the right-hand-side of (27) has the fol lowing structur e U ∗ k = γ u ∗ k ( I c k ) = − L k ¯ X k , (29) wher e ¯ X k is c ompute d in L emma 4 for al l k = 0 , 1 , . . . , T − 1 , and the matric es L k and P k ar e obtaine d by L k = ( R + B T P k +1 B ) − 1 B T P k +1 A, (30a) P k = Q 1 + A T P k +1 A − L T k ( R + B T P k +1 B ) L k , (30b) P T = Q 2 . (30c) 14 Pr o of: The pro of of this theorem is based on the dynamic programming principle. Sp ecifi- cally , if there exist v alue functions V k for all k = 0 , 1 , . . . , T that satisfy (27), then the optimal con trol U ∗ k and the optimal quantizer selection θ ∗ k are obtained by the p olicies γ u ∗ k and γ θ ∗ k that minimize (27). Let us assume that the v alue function at time k = 0 , 1 , . . . , T − 1 is of the form: V k ( I k ) = E γ [ X T k P k X k ] + C k + r k , (31) where P k is as in (30b), and, for all k = 0 , 1 , . . . , T − 1, C k = min { γ θ t } T − 1 t = k E γ θ " T − 1 X t = k e T t N t e t + θ T t Λ # , (32) where N k ∈ R n × n and r k ∈ R are giv en by N k = L T k ( R + B T P k +1 B ) L k , (33a) r k = r k +1 + tr( P k +1 W ) , (33b) r T =0 . (33c) Equation (32) can b e re-written as C k = min γ θ k E γ θ [ e T k N k e k + θ T k Λ + C k +1 ] . W e first verify that V T − 1 is of the form (31). V T − 1 = min γ u T − 1 ,γ θ T − 1 E γ h X T T − 1 Q 1 X T − 1 + U T T − 1 RU T − 1 + θ T T − 1 Λ + X T T P T X T i . (34) Substituting the equation X T = AX T − 1 + B U T − 1 + W T − 1 , and after some simplifications, yields V T − 1 = min γ u T − 1 ,γ θ T − 1 E γ h k U T − 1 + L T − 1 X T − 1 k 2 ( R + B T P T B ) + X T T − 1 P T − 1 X T − 1 + θ T T − 1 Λ + tr( P T W ) i , where k L k 2 K , L T K L for any tw o matrices L and K of compatible dimensions. In the previous expression, k U T − 1 + L T − 1 X T − 1 k 2 ( R + B T P T B ) is the only term that dep ends on U T − 1 . Therefore, w e seek γ u T − 1 : I c T − 1 → R m that minimizes the mean-square error E h k U T − 1 + L T − 1 X T − 1 k 2 ( R + B T P T B ) i . Th us, the optimal U T − 1 is a minimum mean squared estimate of − L T − 1 X T − 1 based on the σ -field generated by I c T − 1 . Hence, from Lemma 1, U ∗ T − 1 = γ u ∗ T − 1 ( I c T − 1 ) = − L T − 1 E [ X T − 1 | I c T − 1 ] = − L T − 1 ¯ X T − 1 . (35) After substituting the optimal U ∗ T − 1 in (34), we obtain V T − 1 = min γ θ T − 1 E γ h k X T − 1 − ¯ X T − 1 k 2 N T − 1 + θ T T − 1 Λ + tr( P T W ) + X T T − 1 P T − 1 X T − 1 i . 15 The ab o ve expression of V T − 1 can b e rewritten as follows V T − 1 = min γ θ T − 1 E γ θ e T T − 1 N T − 1 e T − 1 + θ T T − 1 Λ + E [ X T T − 1 P T − 1 X T − 1 ] + tr( P T W ) . Therefore, using the definitions of C T − 1 and r T − 1 from (32) and (33b), we obtain V T − 1 = E [ X T T − 1 P T − 1 X T − 1 ] + C T − 1 + r T − 1 . Th us, V T − 1 is of the form (31). Next, we pro ve the hypothesis (31) using mathematical induc- tion. T o that end, w e now assume that (31) is true for some k + 1. Then, V k = min γ u k ,γ θ k E γ h ( X T k Q 1 X k + U T k RU k + θ T k Λ) + V k +1 = min γ u k ,γ θ k E γ h ( X T k Q 1 X k + U T k RU k + θ T k Λ) + X T k +1 P k +1 X k +1 + r k +1 + C k +1 . Using (1), and after some simplifications, it follows that V k = min γ u k ,γ θ k E γ h k U k + L k X k k 2 ( R + B T P k +1 B ) + X T k P k X k + θ T k Λ (36) + tr( P k +1 W ) + r k +1 + C k +1 i . One ma y notice from the definition of e k that it do es not dep end on the past con trol his- tory U k , but rather, it dep ends on the quan tizer selection history Θ k . Th us, C k do es not dep end on the control history U k . F urthermore, from (33a), (33b) and (30b), one notices that N k , r k and P k do not dep end on the past (or future) decisions on the con trol or quan tizer- selection. Therefore, k U k + L k X k k 2 ( R + B T P k +1 B ) is the only term in the ab ov e expression of V k that dep ends on U k . Using Lemma 1, the optimal I c k -measurable control U ∗ k that minimizes E h k U k + L k X k k 2 ( R + B T P k +1 B ) i is giv en by U ∗ k = γ u ∗ k ( I c k ) = − L k E [ X k | I c k ] = − L k ¯ X k . (37) After substituting the optimal control in (36), we obtain V k = E [ X T k P k X k ] + min γ θ k E γ h e T k ( L T k ( R + B T P k +1 B ) L k ) e k + θ T k Λ + C k +1 i + tr( P k +1 W ) + r k +1 = E [ X T k P k X k ] + min γ θ k E γ θ h e T k N k e k + θ T k Λ + C k +1 i + r k = E [ X T k P k X k ] + C k + r k . Th us, the v alue function is indeed of the form (31), and hence, the optimal con trol at time k = 0 , 1 , · · · , T − 1 is giv en by (37). This completes the pro of. Remark 4.3 F r om The or em 4.2, the optimal c ontr ol is line ar in ¯ X k . The optimal gain − L k c an b e c ompute d offline without know le dge of γ Θ ∗ . The effe ct of γ Θ ∗ on γ U ∗ is thr ough the term ¯ X k , which c an b e c ompute d online using (25) . 16 Ha ving computed the optimal con troller, we now fo cus on solving for the optimal selection of the quantizers. T o that end, from (31), we hav e V 0 = E [ X T 0 P 0 X 0 ] + C 0 + r 0 , and th us, min γ U ∈ Γ U ,γ Θ ∈ Γ Θ J ( γ U , γ Θ ) = E [ V 0 ] = µ T 0 P 0 µ 0 + tr( P 0 Σ x ) + r 0 + C 0 , where, from (32), C 0 can b e written as C 0 = min { γ θ t } T − 1 t =0 E γ θ " T − 1 X t =0 e T t N t e t + θ T t Λ # . (38) Notice that the effect of the quan tizer-selection policy γ Θ on the cost J ( γ U , γ Θ ) is reflected only through the term C 0 . The optimal quantizer selection p olicy can th us b e found by p erforming the minimization asso ciated with C 0 as represen ted in (38). 4.4 Optimal Quan tizer Selection P olicy In this section, we study the optimal quantizer-selection p olicy γ Θ ∗ , whic h can be found b y solving (38). W e may write E [ e T t N t e t ] = tr( N t E [ e t e T t ]), and the following Lemma computes E [ e t e T t ]. Lemma 5 F or al l t ∈ N 0 , E [ e t e T t ] = Σ t + t X k =0 Ψ( t, k )( M k − E [ ϑ k,t F k ( θ k )])Ψ( t, k ) T . Pr o of: The pro of is given in App endix C. Using Lemma 5, Therefore, the cost C 0 can b e simplified as C 0 = T − 1 X t =0 tr(Σ t N t ) + t X k =0 tr( ˜ N k,t M k ) ! + min { γ θ t } T − 1 t =0 E γ θ " T − 1 X t =0 tr (Π t (Θ) F t ( θ t )) + θ T t λ # , (39) where ˜ N k,t = Ψ( t, k ) T N t Ψ( t, k ) , (40a) Π t (Θ) = − T − 1 X ` = t ϑ t,` ˜ N t,` . (40b) The optimal quan tizer selection p olicy is found by solving the Mixed-In teger-Nonlinear Program (MINP) in (39). A t this p oint it ma y app ear that the expression P T − 1 t =0 tr(Π t (Θ) F t ( θ t )) in (39) is a nonlinear function of Θ. How ev er, we now show that after some simplifications, it can b e written as a 17 linear function of Θ. By expressing (39) as a linear function of Θ, we can recast (39) as a Mixed-In teger-Linear-Program (MILP), whic h further can b e solv ed efficiently using existing efficien t solvers [23]. T o express (39) as an MILP , we construct a matrix Φ ∈ R T × M as follo ws: for all i = 0 , . . . , T − 1 and j = 1 , . . . , M , let [Φ] ij = ( 1 , if i ≥ d j , 0 , otherwise , (41) where [Φ] ij is the ij -th comp onent of Φ matrix. It directly follows from the definition of Φ that 1 d j ≤ t − k = [Φ] t − k,j . Consequently , we can express (11) as ϑ k,t = M X i =1 θ i k [Φ] t − k,i . Th us, Π t (Θ) in (40b) can b e rewritten as Π t (Θ) = − P T − 1 ` = t P M i =1 θ i t [Φ] ` − t,i ˜ N t,` . Also, from (22), w e hav e that F t ( θ t ) = P M i =1 θ i t F i t . Thus, tr(Π t (Θ) F t ( θ t )) = − tr M X i =1 ( θ i t T − 1 X ` = t [Φ] ` − t,i ˜ N t,` ) F t ( θ t ) ! = − tr M X i =1 θ i t T − 1 X ` = t [Φ] ` − t,i ˜ N t,` ! M X j =1 θ j t F j t ( a ) = − tr M X i =1 θ i t T − 1 X ` = t [Φ] ` − t,i ˜ N t,` F i t ! = − M X i =1 θ i t β i t , where β i t = tr P T − 1 ` = t [Φ] ` − t,i ˜ N t,` F i t and ( a ) follows from the fact θ i t θ j t = 0 if i 6 = j . Note that the co efficients β i t can b e computed offline. F rom the previous deriv ation, C 0 in (39) b ecomes C 0 = c + min { γ θ t } T − 1 t =0 E γ θ " T − 1 X t =0 c T t θ t # , (42) where constant c = P T − 1 t =0 tr(Σ t N t ) + P t k =0 tr( ˜ N k,t M k ) and c t = [ c 1 t , . . . , c M t ] T with c i t = λ i − β i t . Notice that, in (42), the cost function is linear in θ and the co efficients c i t are deterministic (and can b e computed offline). Therefore, it is sufficien t to lo ok for a deterministic strategy to minimize the linear cost P T − 1 t =0 c T t θ t , as the class of deterministic strategies con tains an optimal solution for min { γ θ t } T − 1 t =0 E γ θ h P T − 1 t =0 c T t θ t i . The follo wing lemma presents an MILP formulation to obtain the optimal quantizer selection p olicy . Lemma 6 The optimal quantizer sele ction str ate gy is found by solving the fol lowing Mixe d- 18 Inte ger-Line ar-Pr o gr am min Θ T − 1 X t =0 c T t θ t , (43a) s . t . θ i t ∈ { 0 , 1 } , t = 0 , . . . , T − 1 , i = 1 , . . . , M , (43b) M X i =1 θ i t = 1 , t = 0 , . . . , T − 1 . (43c) Pr o of: The pro of follows directly from the deriv ation of (42) and the subsequen t discussion. Notice that in (43) there is no constrain t coupling θ k and θ ` , and the cost function in (43) is also decoupled in θ k and θ ` for all k 6 = ` ∈ { 0 , . . . , T − 1 } . Therefore, the optimal θ t at time t can b e found b y minimizing c T t θ t sub ject to the constraints P M i =1 θ i t = 1, θ i t ∈ { 0 , 1 } . Thus, the optimal quantizer selection strategy for this problem turns out to b e remark ably simple: if i ∗ =arg min i =1 ,...,M { c 1 t , . . . , c M t } , then the optimal strategy is to use the i ∗ -th quan tizer 2 suc h that γ θ ∗ t = θ ∗ t = [1 i ∗ =1 , . . . , 1 i ∗ = M ] T . This result is summarized in the following theorem. Theorem 4.4 (Optimal Quantizer Selection) A t time t , the j -th quantizer is optimal if and only if c j t = min { c 1 t , . . . , c M t } , wher e, for al l i = 1 , . . . , M , c i t = λ i − tr T − 1 X ` = t [Φ] ` − t,i ˜ N t,` ! F i t ! . and ˜ N t,` , [Φ] ` − t,i and F i t ar e define d in e quation (40a) , (41) and (23) r esp e ctively. The follo wing remark is immediate from Theorem 4.4. Remark 4.5 The optimal str ate gy for sele cting the quantizers c an b e c ompute d offline. This r e quir es an offline c omputation of ˜ N t,` and F i t , but it do es not r e quir e know le dge of the optimal c ontr ol str ate gy. 4.5 Discussion and Remarks W e delve into the cost c T t θ t in (43) to discuss how the three factors, namely , the cost of quan- tization, the quantization resolution, and the delay , affect the cost function. The co efficien ts c i t whic h determine the optimal quantizer selection strategy at time t ha v e t wo comp onen ts, 2 In case there exists multiple minimizers for arg min i =1 ,...,M { c 1 t , . . . , c M t } , one of these minimizers can b e chosen randomly without affecting the optimality . 19 namely , λ i , and β i t , where λ i is the cost for using the i -th quan tizer, and β i t captures the trade-off b et ween quantization qualit y and the asso ciated delays. Let us discuss eac h of these tw o terms in greater detail. First, c i t b eing prop ortional to the cost λ i , reflects the fact that low er quan- tization cost is desirable. The quantit y β i t is arguably more interesting. Note that β i t is of the form tr( G i t F i t ), where for all i , G i t is a p ositive (semi)-definite matrix whose expression can b e easily identified from the expression of β i t . Moreo v er, since 1 ≥ [Φ] i, 1 ≥ [Φ] i, 2 ≥ . . . ≥ [Φ] i,M ≥ 0 for all i = 0 , . . . , T − 1, w e ha ve G 1 t G 2 t . . . G M t . On the other hand, b y using the i -th quan tizer, the reduction in unc ertainty c ovarianc e is F i t . By unc ertainty c ovarianc e we mean the following: Before the arriv al of an y measurement ( ˆ ξ t ), ξ t is a Gaussian distributed random v ariable with cov ariance M t . Once a quantized version ( ˆ ξ t ) of ξ t arriv es at the con troller, the con troller receives information on the realization of the random v ariable ξ t . Sp ecifically , at this p oint, the con troller kno ws in whic h of the P i j ⊂ R p the random v ariable ξ t b elongs to. Therefore, the p osterior distribution of ξ t c hanges after receiving ˆ ξ t , and the difference b et ween the co v ariance of this posterior distribution and the prior distribution is F i t if the i -th quan tizer is used. Needless to say , had there b een a quantizer which could ensure ˆ ξ t = ξ t , i.e., no loss during quantization for every realization of ξ t , then the reduction in cov ariance is exactly M t and the p osterior distribution of ξ t at the controller is a Dirac measure around ˆ ξ t . Use of quan- tized measurements is similar as operating somewhere in betw een op en-lo op and closed-lo op con trol. In op en-lo op, no measurement is sen t, and in closed-lo op, the exact measurement is sen t without any distortion. By means of quantization, the controller receives something but not everything . F urthermore, since β i t ≥ 0 and since it appears with a negativ e sign in the cost function, it is clearly desirable to choose a quan tizer that would maximize β i t . The matrix F i t directly reflects how muc h reduction in co v ariance will o ccur if the i -th quantizer is used. The matrix G i t , on the other hand, incorp orates the delay asso ciated with the i -th quantizer. As i is increased from 1 to M , G i t decreases tr( G i t F i t ), reflecting the fact that smaller delay is preferable. Ho wev er, as i is v aried, F i t sho ws the v ariation in co v ariance reduction. F or example, if reduction in cov ariance increases with the increase in ` i , then F i t is attempting to increase tr( G i t F i t ) as i is v aried from 1 to M . Thus, there is a dual b eha vior b et ween F i t and G i t as i c hanges, and this duality is captured by the parameters of the channel and the quan tizers, namely , P i , ` i , and the delay d i . W e conclude this section with a few more remarks. Remark 4.6 The c ost function in (43) r esembles the c omp onent P T − 1 t =0 Λ T θ t in (6) , exc ept that al l the state and c ontr ol c osts ar e absorb e d in the c o efficients c i t . Her e c i t c an b e viewe d as the adjuste d c ost for op er ating the i -th quantizer at time t , and the adjustment factor is β i t which c an b e c ompute d offline. Remark 4.7 This appr o ach al lows for the c ase when the set of available quantizers c ontains a quantizer Q 0 with only one quantization level, i.e., ` 0 = 1 , P 0 = {P 0 1 = R p } , and quantization c ost λ 0 = 0 . This quantizer pr o duc es the same quantize d output for every input signal, henc e pr oviding the option to r emain op en-lo op. F or such a quantizer, it c an b e verifie d fr om (23) that F 0 t = 0 for al l t . Ther efor e, c 0 t = λ 0 − β 0 t = 0 for al l t , and sele ction of this quantizer at any time t r efle cts the fact that it is optimal not to send any information to the c ontr ol ler at that time. If the quantization c osts ar e very high 3 λ i 1 , the optimal choic e of the quantizers 3 Or, the quan tization cost is higher than the reward from using quan tization, i.e. λ i > β i t for all t . 20 would b e Q 0 , and henc e, the c ontr ol ler wil l not b e r e c eiving any information, which in principle, is e quivalent to op en-lo op c ontr ol. 5 Sp ecial Cases In this section we consider tw o sp ecial cases, namely: (i) constant-dela y case, and (ii) full observ ation case. 5.1 Constan t-Dela y In this section w e consider the case where d 1 = d 2 = . . . = d M = d , i.e., the dela y induced b y each quantizer is the same. Intuitiv ely , since the dela y is not affected b y the c hoice of the quan tizer, then the quantizer selection problem should reduce to a trade-off betw een the quan tization cost and the qualit y of quan tization. T o see this, let us first note that [Φ] i, 1 = . . . = [Φ] i,M = 1 i ≥ d for all i = 0 , . . . , T − 1. Therefore, β i t =tr T − 1 X ` = t [Φ] ` − t,i ˜ N t,` ! F i t ! =tr T − 1 X ` = t 1 ` − t ≥ d ˜ N t,` ! F i t ! = tr T − 1 X ` = t + d ˜ N t,` ! F i t ! =tr H ( t, d ) F i t , where H ( t, d ) = P T − 1 ` = t + d ˜ N t,` 0. Th us, for fixed t and d , whether the i -th quantizer is optimal at time t is en tirely determined by F i t where recall that F i t represen ts the unc ertainty c ovarianc e reductions. Also notice that H ( t, d ) = 0 for all t ≥ T − d , and hence β i t = 0. Therefore, the optimal selection for the quantizers for t ≥ T − d would b e the one with the lo west λ i . This is due to the fact that the quantized information ξ T − d , ξ T − d +1 , . . . will not b e av ailable at the controller b efore time T − 1, and hence these quan tized measuremen ts w ould b e of no use to the controller. Therefore, the quality of the quan tization for time T − d on ward is immaterial to the con troller, and hence, the low est cost quan tizer would b e the optimal. 5.2 F ull Observ ation F or the full observ ation case w e substitute V = 0 and C = I in the analysis presen ted abov e. As a direct consequence, one can verify that ξ t = W t − 1 for all t . Therefore, { ξ t ∼ N (0 , W ) } t ∈ N 0 are i.i.d signals, and consequen tly the matrices F i t giv en in (22) will b e time inv ariant, i.e., F i 1 = . . . = F i T , F i . F or all t ∈ N 0 , Σ t = 0, Σ t +1 | t = M t +1 = W . This also implies that, for all t ≥ k , Ψ( t, k ) = A t − k , and ˜ N k,t = A t − k T N t A t − k . 21 Therefore, the state estimate can b e written as ˜ X t = A t µ 0 + t X k =0 Ψ( t, k ) ϑ k,t ¯ ξ k + t − 1 X k =0 A t − 1 − k B U k = A t µ 0 + t X k =0 A t − k ϑ k,t ¯ ξ k + t − 1 X k =0 A t − 1 − k B U k = A ˜ X t − 1 + B U t − 1 + ϑ t,t ¯ ξ t + t − 1 X k =0 A t − k ( ϑ k,t − ϑ k,t − 1 ) ¯ ξ k . (44) The expression for β i t is no w given by: β i t =tr T − 1 X ` = t [Φ] ` − t,i ˜ N t,` ! F i t ! =tr T − 1 X ` = t + d i A ` − t T N ` A ` − t F i . Let us define a symmetric matrix Υ t as follo ws Υ t = A T Υ t +1 A + N t , Υ T =0 , whic h allows us to rewrite β i t = tr(Υ min { t + d i ,T } F i ).W e conclude this section by discussing the constan t delay case for fully observ ed systems. Under the assumption of constant delay , i.e., d 1 = . . . = d M = d , w e obtain β i t = tr(Υ min { t + d,T } F i ). F urthermore, ϑ k,t = 1 if and only if t − k ≥ d , otherwise ϑ k,t = 0. This implies from (44) that, for all t ∈ N 0 , ¯ X t = ( A ¯ X t − 1 + B U t − 1 + A d ¯ ξ t − d , if t ≥ d, A ¯ X t − 1 + B U t − 1 , otherwise . (45) 6 Numerical Examples In this section, we illustrate our theory on the follo wing system X t +1 = 1 . 01 0 . 5 0 1 . 1 X t + 0 . 1 0 0 0 . 15 U t + W t , (46a) Y t = 1 0 1 1 X t + ν t , (46b) where X 0 ∼ N (0 , I ), W t ∼ N (0 , 1 2 I ), and ν t ∼ N (0 , 1 4 I ). The con trol cost has parameters Q = Q f = R = 1 2 I , and the time horizon was set to T = 50. The simulation w as performed with three quan tizers ( Q 1 , Q 2 , Q 3 ) where Q i has 2 i n umber of quan tization levels. The partitions associated with the quantizers are P 1 = { R + × R , R < 0 × R } , 22 Figure 4: Optimal selection of the quantizers ov er time when d i = i for all i . Figure 5: Optimal selection of the quantizers ov er time when d i = 1 for all i . P 2 = { R + × R + , R + × R < 0 , R < 0 × R + , R < 0 × R < 0 } and P 3 = { [0 , 1) × R + , [1 , ∞ ) × R + , [0 , 1) × R < 0 , [1 , ∞ ) × R < 0 , [ − 1 , 0) × R + , ( −∞ , − 1) × R + , [ − 1 , 0) × R < 0 , ( −∞ , − 1) × R < 0 } . The costs asso ciated with the quantizers are Λ = [100 , 200 , 300] T . W e consider t wo scenarios where in the first scenario the dela ys asso ciated with the quan- tizers are d i = i for all i , and in the second scenario, d i = i for all i . Under these conditions the optimal selections for the quantizers are plotted in Figures 4 and 5 resp ectively . Although Figures 4 and 5 p ortray similar b ehavior, there are minor differences in the optimal selection of the quan tizers due to the dela ys. F or example, from Figures 4 and 5, one notices that at t = 37, Q 3 is optimal when d 3 = 1, whereas Q 2 is optimal when d 3 = 3. The reason b ehind this is the fact that the quantized output of b oth Q 3 and Q 2 will b e av ailable with same delay when d i = 1 for all i , whereas the quan tized output of Q 3 will reach later than that of Q 2 when d i = i , although the quantized output of Q 3 will less distorted than that of Q 2 . At this partic- ular instance, it turned out to ha ve coarser measuremen t faster than finer measurement with more dela yed. Th us, this simple example reflects the com bined (dual) effect of the quan tization resolution and the asso ciated delays in the optimal c hoice of the quan tizers. The same example is considered when ν t = 0 for all t , i.e., a p erfect state feedback scenario. The optimal selections for the quantizers are plotted in Figures 6 and 7 resp ectively . In this p erfect observ ation case, the system is not as keen in using the finest resolution quantization as it was for the noisy observ ation case; nonetheless, w e still observe the dual effect of the quan tization resolution and the asso ciated delays in the optimal choice of the quan tizers. 23 Figure 6: Optimal selection of the quantizers under p erfect observ ation when d i = i for all i . Figure 7: Optimal selection of the quantizers under p erfect observ ation when d i = 1 for all i . 7 Conclusions In this w ork, w e hav e considered a quantization-based partially observed LQG problem with a quantization cost. The problem is to c ho ose an optimal quan tizer among a set of av ailable quan tizers that minimizes the com bined cost of quan tization and con trol p erformance. The n umber of bits required to represen t the quan tized v alue increases as the quantization resolution gets b etter, and hence the dela y transmitting the measuremen t also increases. W e illustrate ho w the quality of quan tization and dela y together emerge in the cost function and w e demonstrate their dual role in the optimal solution. W e ha v e sho wn that the optimal con troller exhibits a separation principle and it has a linear relationship with the estimate of the state. The optimal gains for the con troller are found by solving the classical Riccati equation asso ciated with the LQG problem. W e hav e also sho wn that the optimal selection of the quantizers can b e found by solving a linear program that can b e solved offline indep enden tly . F urthermore, the sp ecial cases of full observ ation and constant dela y are also discussed. The p ossibilit y of the system to remain op en-lo op at time t by not sending an y quantized information, is discussed as well in Remark 4.7. The analysis of this pap er relies on the idea of quantization of the innov ation signal. As a future w ork it w ould b e interesting to extend the similar idea b eyond LQG systems. 24 A Pro of of Prop osition 4.1 Let us consider a state-pro cess X new t and an observ ation-process Y new t as follo ws X new t = X t − t − 1 X k =0 A t − 1 − k B U k − A t µ 0 , (47a) Y new t = C X new t + V t . (47b) It follo ws that X new t +1 = AX new t + W t , (48a) Y new t = C X new t + V t , (48b) X new 0 = X 0 − µ 0 = W − 1 ∼ N (0 , Σ x ) . (48c) Here X new t is the pro cess asso ciated with X t , whic h is indep endent of the con trol strategy . Using this definition of X new t and Y new t , we hav e X t = X new t + ϕ ( t, U t − 1 ) and Y t = Y new t + C ϕ ( t, U t − 1 ) where ϕ ( t, U t − 1 ) = P t − 1 k =0 A t − 1 − k B U k + A t µ 0 . Therefore, the information sets ( Y t − 1 , U t − 1 ) and ( Y new 0 , . . . , Y new t − 1 , U t − 1 ) are equiv alen t, i.e., one can b e constructed from the other. The inno v ation pro cess asso ciated with system (48) is given by ξ new t = Y new t − E [ Y new t | Y new 0 , . . . , Y new t − 1 ] . Since ξ t is the inno v ation process asso ciated with the system (1), it can be shown that ξ new t = ξ t for all t . In order to prov e this statement, notice that ξ t = Y t − E [ Y t |Y t − 1 , U t − 1 ] = Y new t + C ϕ ( t, U t − 1 ) − E [ Y new t |Y t − 1 , U t − 1 ] − E [ C ϕ ( t, U t − 1 ) |Y t − 1 , U t − 1 ] = Y new t − E [ Y new t | Y new 0 , . . . , Y new t − 1 , U t − 1 ] = Y new t − E [ Y new t | Y new 0 , . . . , Y new t − 1 ] = ξ new t . Th us, ξ t do es not dep end on the control history U t − 1 . The standard results of Kalman filtering hold for the pro cess X new t with observ ation Y new t . It follows that { ξ new t } t ∈ N 0 is a sequence of uncorrelated Gaussian noises. Thus, using standard Kalman filtering theory , we define e new t = X new t − E [ X new t | Y new 0 , . . . , Y new t − 1 ] , (49a) ∆ new t = X new t − E [ X new t | Y new 0 , . . . , Y new t ] , (49b) Σ t | t − 1 = E [ e new t e new t T ] , (49c) Σ t = E [∆ new t ∆ new t T ] . (49d) Moreo ver, E [ X new t | Y new 0 , . . . , Y new t ] = E [ X new t | Y new 0 , . . . , Y new t − 1 ] + K t ξ new t , where K t is the Kalman gain at time t . Thus, ∆ new t = e new t − K t ξ new t = ( I − K t C ) e new t − K t V t . The initial conditions are e new 0 = X new 0 ∼ N (0 , Σ x ) and Σ 0 |− 1 = Σ x . Therefore, E [ ξ new t ] = 0 25 and M t , Σ t | t − 1 and Σ t satisfy M t = E [( C e new t + V t )( C e new t + V t ) T ] = C Σ t | t − 1 C T + V , Σ t | t − 1 = E [ e new t e new t T ] = E [( A ∆ new t − 1 + W t − 1 )( A ∆ new t − 1 + W t − 1 ) T ] = A Σ t − 1 A T + W , Σ t = E [( I − K t C ) e new t e new t T ( I − K t C ) T ] + K t C V C T K T t =( I − K t C )Σ t | t − 1 ( I − K t C ) T + K t V K T t =Σ t | t − 1 − Σ t | t − 1 C T M − 1 t C Σ t | t − 1 , where K t = Σ t | t − 1 C T M − 1 t is the Kalman gain. This concludes the pro of. B Pro of of Lemma 3 Note that the information con tained in ( Y t , U t − 1 ) is the same as the information contained in (Ξ t , U t − 1 ), where Ξ t = { ξ 0 , . . . , ξ t } . Therefore, E [ X t |Y t , U t − 1 ] = E [ X t | Ξ t , U t − 1 ] = E [ X new t | Ξ t , U t − 1 ] + t − 1 X k =0 A t − 1 − k B U k + A t µ 0 = E [ X new t | Ξ new t ] + t − 1 X k =0 A t − 1 − k B U k + A t µ 0 , where Ξ new t = { ξ new t } t ∈ N 0 = { ξ t } t ∈ N 0 = Ξ t . F rom the theory of Kalman filtering, it follows that E [ X new t | Ξ new t ] = E [ X new t | Ξ new t − 1 ] + K t ξ new t = A E [ X new t − 1 | Ξ new t − 1 ] + K t ξ new t , since W t − 1 is indep enden t of Ξ new t − 1 . W e need to sho w that E [ X new t | Ξ new t ] = t X k =0 Ψ( t, k ) ξ new k , (50) for some Ψ( t, k ). W e show this by induction. T o this end, notice that (50) is true for t = 0 with Ψ(0 , 0) = Σ x C T ( C Σ x C T + V ) − 1 , where Σ x is the cov ariance of the initial state X 0 . Next, if (50) is true for t = τ , then we hav e that, for t = τ + 1, E [ X new τ +1 | Ξ new τ +1 ] = A E [ X new τ | Ξ new τ ] + K τ +1 ξ new τ +1 = A τ X k =0 Ψ( τ , k ) ξ new k + K τ +1 ξ new τ +1 = τ +1 X k =0 Ψ( τ + 1 , k ) ξ new k , 26 where K τ +1 is the Kalman gain at time τ + 1, Ψ( τ + 1 , k ) = A Ψ( τ , k ) for all k = 0 , . . . , τ , and Ψ( τ + 1 , τ + 1) = K τ +1 . Therefore, for all t ≥ k , Ψ( t, k ) = A t − k K k = A t − k Σ k | k − 1 C T M − 1 k , and E [ X t |Y t , U t − 1 ] = E [ X new t | Ξ new t ] + t − 1 X k =0 A t − 1 − k B U k + A t µ 0 = t X k =0 Ψ( t, k ) ξ new k + t − 1 X k =0 A t − 1 − k B U k + A t µ 0 = t X k =0 Ψ( t, k ) ξ k + t − 1 X k =0 A t − 1 − k B U k + A t µ 0 . (51) The set O t ma y not con tain all the elemen ts of Ξ t due to delays. In fact, for k ≤ t , w e hav e that ξ k ∈ O t if and only if ϑ k,t = 1. Since ξ k and ξ t are indep enden t for t 6 = k , we ha ve E [ ξ k |O t ] = ( ξ k , if ξ k ∈ O t , 0 , otherwise . Therefore, w e can write E [ ξ k |O t ] = ϑ k,t ξ k . Thus, E [ X t |O t , U t − 1 ] = E [ E [ X t | Ξ t , U t − 1 ] |O t , U t − 1 ] = E " t X k =0 Ψ( t, k ) ξ k |O t , U t − 1 # + t − 1 X k =0 A t − 1 − k B U k + A t µ 0 = t X k =0 Ψ( t, k ) ϑ k,t ξ k + t − 1 X k =0 A t − 1 − k B U k + A t µ 0 . This completes the pro of. C Pro of of Lemma 5 Let us define ∆ t = E [ e t | Y t , ˆ O t , U t − 1 ], and notice that, E [ e t e T t | Y t , ˆ O t , U t − 1 ] = E [( e t − ∆ t )( e t − ∆ t ) T | Y t , ˆ O t , U t − 1 ] + E [∆ t ∆ T t | Y t , ˆ O t , U t − 1 ] , since E [∆ t ( e t − ∆) T | Y t , ˆ O t , U t − 1 ] = ∆ t E [( e t − ∆) T | Y t , ˆ O t , U t − 1 ] = 0. T aking exp ectations on b oth sides of the last equation, w e obtain E [ e t e T t ] = E [( e t − ∆ t )( e t − ∆ t ) T ] + E [∆ t ∆ T t ] . (52) Substituting the expression of ¯ X t from (15) in e t = X t − ¯ X t , yields e t = X t − t − 1 X k =0 A t − 1 − k B U k − A t µ 0 − t X k =0 Ψ( t, k ) ϑ k,t ¯ ξ k . 27 Therefore, ∆ t = E [ e t | Y t , ˆ O t , U t − 1 ] = E [ X t | Y t , ˆ O t , U t − 1 ] − t − 1 X k =0 A t − 1 − k B U k − A t µ 0 − t X k =0 Ψ( t, k ) ϑ k,t ¯ ξ k = t X k =0 Ψ( t, k ) ξ k − t X k =0 Ψ( t, k ) ϑ k,t ¯ ξ k = t X k =0 Ψ( t, k )( ξ k − E [ ξ k | ˆ O t ]) (53) where w e hav e used E [ X t | Y t , ˆ O t , U t − 1 ] = E [ X t | Y t , U t − 1 ] since ˆ O t is a Y t -measurable function and w e hav e also used (24) to write ϑ k,t ¯ ξ k as E [ ξ k | ˆ O t ]. Using the expression of ∆ t from (53), w e obtain e t − ∆ t = X t − t − 1 X k =0 A t − 1 − k B U k − A t µ 0 − t X k =0 Ψ( t, k ) ξ k = X new t − E [ X new t | Ξ new t ] = ∆ new t , where X new t , E [ X new t | Ξ new t ], and ∆ new t are defined in equations (47) and (50), and (49), resp ectiv ely . Thus, we may rewrite (52) as follows E [ e t e T t ] = E [( e t − ∆ t )( e t − ∆ t ) T ] + E [∆ t ∆ T t ] = E [∆ new t ∆ new t T ] + t X k =0 t X ` =0 Ψ( t, k ) E [( ξ k − E [ ξ k | ˆ O t ])( ξ ` − E [ ξ ` | ˆ O t ]) T ]Ψ( t, ` ) T = Σ t + t X k =0 t X ` =0 Ψ( t, k ) E [( ξ k − E [ ξ k | ˆ O t ])( ξ ` − E [ ξ ` | ˆ O t ]) T ]Ψ( t, ` ) T (54) where w e used the definition Σ t = E [∆ new t ∆ new t T ] from (49). T o further simplify (54), we recall that ξ k and ξ ` are indep endent random v ariables when k 6 = ` and therefore, we obtain E [( ξ k − E [ ξ k | ˆ O t ])( ξ ` − E [ ξ ` | ˆ O t ]) T ] = E E [( ξ k − E [ ξ k | ˆ O t ])( ξ ` − E [ ξ ` | ˆ O t ]) T | ξ k , ˆ O t ] = E ( ξ k − E [ ξ k | ˆ O t ]) E [( ξ ` − E [ ξ ` | ˆ O t ]) T | ξ k , ˆ O t ] = E [( ξ k − E [ ξ k | ˆ O t ])( E [ ξ ` | ξ k , ˆ O t ] − E [ ξ ` | ˆ O t ]) T ] = E [( ξ k − E [ ξ k | ˆ O t ])( E [ ξ ` | ˆ O t ] − E [ ξ ` | ˆ O t ]) T ] = 0 for all k 6 = ` . On the other hand, for k = ` , we obtain E [( ξ k − E [ ξ k | ˆ O t ])( ξ k − E [ ξ k | ˆ O t ]) T ] = E [ ξ k ξ T k ] − E [ E [ ξ k | ˆ O t ] E [ ξ k | ˆ O t ] T ] ( a ) = M k − E [ ϑ k,t ¯ ξ k ¯ ξ T k ] = M k − E [ E [ ϑ k,t ¯ ξ k ¯ ξ T k | θ k ]] ( b ) = M k − E [ ϑ k,t E [ ¯ ξ k ¯ ξ T k | θ k ]] ( c ) = M k − E [ ϑ k,t F k ( θ k )] 28 where (a) follo ws from (24) and the fact that ϑ 2 k,t = ϑ k,t since ϑ k,t ∈ { 0 , 1 } , and (b) follows from the fact that ϑ k,t is a deterministic function of θ k due to (11), and finally , (c) follows from (22). Consequently , (54) reduces to the following equation E [ e t e T t ] = Σ t + t X k =0 Ψ( t, k )( M k − E [ ϑ k,t F k ( θ k )])Ψ( t, k ) T . References [1] E. Akyol, K. Visw ana tha, and K. Rose , On c onditions for line arity of optimal esti- mation , IEEE T ransactions on Information Theory , 58 (2012), pp. 3497–3508. [2] A. Araf a, K. Bana w an, K. G. Seddik, and H. V. Poor , Timely estimation using c o de d quantize d samples , in 2020 IEEE International Symp osium on Information Theory (ISIT), IEEE, 2020, pp. 1812–1817. [3] L. Bao, M. Skoglund, and K. H. Johansson , Iter ative enc o der-c ontr ol ler design for fe e db ack c ontr ol over noisy channels , IEEE T ransactions on Automatic Control, 56 (2010), pp. 265–278. [4] P. Billingsley , Pr ob ability and Me asur e , John Wiley & Sons, 2008. [5] V. S. Borkar and S. K. Mitter , LQG c ontr ol with c ommunic ation c onstr aints , in Comm unications, Computation, Con trol, and Signal Pro cessing, Springer, 1997, pp. 365– 373. [6] R. W. Brockett and D. Liberzon , Quantize d fe e db ack stabilization of line ar systems , IEEE T ransactions on Automatic Control, 45 (2000), pp. 1279–1289. [7] K. Clements and R. Haddad , Appr oximate estimation for systems with quantize d data , IEEE T ransactions on Automatic Control, 17 (1972), pp. 235–239. [8] R. E. Curr y , Estimation and Contr ol with Quantize d Me asur ements , MIT press Cam- bridge, MA, 1970. [9] W. B. Da venpor t, W. L. Root, et al. , An Intr o duction to the The ory of R andom Signals and Noise , vol. 159, McGraw-Hill New Y ork, 1958. [10] D. F. Delchamps , Extr acting state information fr om a quantize d output r e c or d , Systems & Con trol Letters, 13 (1989), pp. 365–372. [11] D. F. Delchamps , Stabilizing a line ar system with quantize d state fe e db ack , IEEE T rans- actions on Automatic Control, 35 (1990), pp. 916–924. [12] Z. Duan, V. P. Jilko v, and X. R. Li , State estimation with quantize d me asur ements: Appr oximate MMSE appr o ach , in 2008 11th International Conference on Information F u- sion, 2008, pp. 1–6, Cologne, Germany . [13] N. Elia and S. K. Mitter , Stabilization of line ar systems with limite d information , IEEE T ransactions on Automatic Control, 46 (2001), pp. 1384–1400. 29 [14] M. Fu , L ack of sep ar ation principle for quantize d line ar quadr atic Gaussian c ontr ol , IEEE T ransactions on Automatic Control, 57 (2012), pp. 2385–2390. [15] H. Ishi i and B. A. Francis , Quadr atic stabilization of sample d-data systems with quan- tization , Automatica, 39 (2003), pp. 1793–1800. [16] T. Kaila th , An innovations appr o ach to le ast-squar es estimation–p art I: Line ar filtering in additive white noise , IEEE T ransactions on Automatic Control, 13 (1968), pp. 646–655. [17] C. Kam, S. Kompella, and A. Ephremides , A ge of information under r andom up dates , in 2013 IEEE International Symp osium on Information Theory , IEEE, 2013, pp. 66–70. [18] R. Karlsson and F. Gust afsson , Filtering and Estimation for Quantize d Sensor In- formation , Link¨ oping Univ ersity Electronic Press, 2005. [19] V. K ostina and B. Hassibi , R ate-c ost tr ade offs in c ontr ol , IEEE T ransactions on Au- tomatic Con trol, 64 (2019), pp. 4525–4540. [20] K. Li and J. Baillieul , R obust quantization for digital finite c ommunic ation b andwidth (DF CB) c ontr ol , IEEE T ransactions on Automatic Control, 49 (2004), pp. 1573–1584. [21] D. Liberzon , On stabilization of line ar systems with limite d information , IEEE T ransac- tions on Automatic Control, 48 (2003), pp. 304–307. [22] K. Liu, R. E. Skel ton, and K. Grigoriadis , Optimal c ontr ol lers for finite wor d length implementation , IEEE T ransactions on Automatic Control, 37 (1992), pp. 1294–1304. [23] J. L ¨ ofberg , Y ALMIP: A to olb ox for mo deling and optimization in MA TLAB , in Pro- ceedings of the CACSD Conference, vol. 3, T aip ei, T aiwan, 2004. [24] D. G. Luenberger , Optimization by V e ctor Sp ac e Metho ds , John Wiley & Sons, 1969. [25] D. Maity and P. Tsiotras , Optimal c ontr ol ler synthesis and dynamic quantizer switch- ing for line ar-quadr atic-Gaussian systems , to app ear in IEEE T ransactions on Automatic Con trol, (2021). [26] P. Moroney , Issues in the Implementation of Digital Comp ensators , MIT Press, 1983. [27] G. N. Nair and R. J. Ev ans , Exp onential stabilisability of finite-dimensional line ar systems with limite d data r ates , Automatica, 39 (2003), pp. 585–593. [28] F. Schweppe , R e cursive state estimation: Unknown but b ounde d err ors and system in- puts , IEEE T ransactions on Automatic Control, 13 (1968), pp. 22–28. [29] J. L. Speyer and W. H. Chung , Sto chastic Pr o c esses, Estimation, and Contr ol , vol. 17, SIAM, 2008. [30] E. Sviestins and T. Wigren , Optimal r e cursive state estimation with quantize d me a- sur ements , IEEE T ransactions on Automatic Control, 45 (2000), pp. 762–767. [31] S. T a tikonda , Contr ol under c ommunic ation c onstr aints , PhD thesis, Massach usetts In- stitute of T echnology , 2000. 30 [32] S. T a tik onda, A. Sahai, and S. Mitter , Contr ol of LQG systems under c ommuni- c ation c onstr aints , in Pro ceedings of the 37th IEEE Conference on Decision and Con trol, 1998, pp. 1165–1170, T ampa, USA. [33] S. T a tikond a, A. Sahai, and S. Mitter , Sto chastic line ar c ontr ol over a c ommunic a- tion channel , IEEE T ransactions on Automatic Control, 49 (2004), pp. 1549–1561. [34] D. Williamson and K. Kadiman , Optimal finite wor d length line ar quadr atic r e gulation , IEEE T ransactions on Automatic Control, 34 (1989), pp. 1218–1228. [35] W. S. W ong and R. W. Brockett , Systems with finite c ommunic ation b andwidth c onstr aints. I. State estimation pr oblems , IEEE T ransactions on Automatic Con trol, 42 (1997), pp. 1294–1299. [36] W. S. W ong and R. W. Brockett , Systems with finite c ommunic ation b andwidth c onstr aints. II. Stabilization with limite d information fe e db ack , IEEE T ransactions on Au- tomatic Con trol, 44 (1999), pp. 1049–1053. [37] S. Y ¨ uksel , Jointly optimal LQG quantization and c ontr ol p olicies for multi-dimensional systems , IEEE T ransactions on Automatic Control, 59 (2013), pp. 1612–1617. 31
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment