Submodular Rank Aggregation on Score-based Permutations for Distributed Automatic Speech Recognition
Distributed automatic speech recognition (ASR) requires to aggregate outputs of distributed deep neural network (DNN)-based models. This work studies the use of submodular functions to design a rank aggregation on score-based permutations, which can …
Authors: Jun Qi, Chao-Han Huck Yang, Javier Tejedor
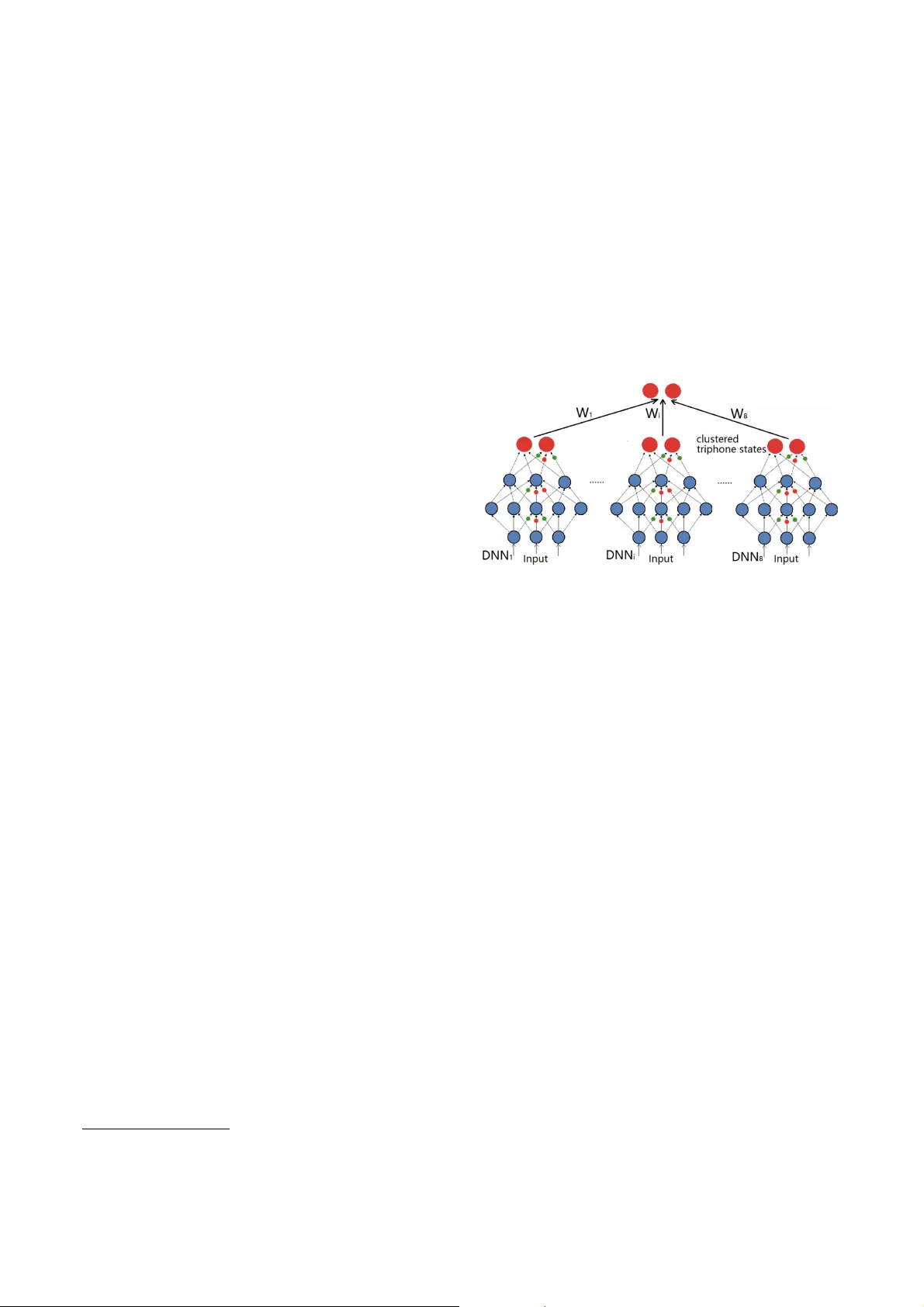
SUBMODULAR RANK A GGREGA TION ON SCORE-B ASED PERMUT A TIONS FOR DISTRIBUTED A UT OMA TIC SPEECH RECOGNITION J un Qi 1 , Chao-Han Huck Y ang 1 , J avier T ejedor 2 1 Electrical and Computer Engineering, Georgia Institute of T echnology , Atlanta, GA, USA 2 Escuela Politecnica Superior , Univ ersidad San Pablo-CEU, CEU Uni versities, Madrid, Spain ABSTRA CT Distributed automatic speech recognition (ASR) requires to aggre- gate outputs of distributed deep neural network (DNN)-based mod- els. This work studies the use of submodular functions to design a rank aggregation on score-based permutations, which can be used for distrib uted ASR systems in both supervised and unsupervised modes. Speci fi cally , we compose an aggregation rank function based on the Lov asz Bregman div ergence for setting up linear structured con ve x and nested structured concav e functions. The algorithm is based on stochastic gradient descent (SGD) and can obtain well- trained aggre gation models. Our experiments on the distributed ASR system show that the submodular rank aggre gation can obtain higher speech recognition accuracy than traditional aggregation methods like Adaboost. Code is available online 1 . Index T erms — Distributed automatic speech recognition, rank aggregation, submodular function, Lo vasz Bre gman div ergence. 1. INTR ODUCTION The recent development of computer architectures allows automatic speech recognition (ASR) to be set up in a distrib uted way [1, 2], where the outputs of different deep neural network (DNN)-based acoustic models are somehow combined to obtain higher ASR ac- curacy . Our previous work on distributed ASR [3] focused on how to set up a distributed ASR system based on sev eral non-overlapping data subsets, which are produced by applying the submodular data partitioning approach. Howe ver , the traditional Adaboost [4] was used in that work to combine the outputs of dif ferent subsystems from distrib uted acoustic models for a better ASR performance. This work proposes a novel method on submodular rank aggregation on score-based permutations for combining scores of acoustic models into a fi nal consistent list of scores. Rank aggregation is the task of combining a couple of differ - ent permutations on the same set of candidates into one ranking list with a better permutation on candidates. More speci fi cally , there are K permutations { x 1 , x 2 , ..., x K } in total, where the elements { X 1 j , X 2 j , ..., X N j } , which are in the ranking list x j , denote either relativ e orders or numeric values for the candidates. In the frame- work of rank aggregation on score-based permutations, the elements in the ranking lists represent numerical values and a combined list ˆ x with the aggregated scores is used to obtain the relative orders for candidates by sorting the values in ˆ x . The Lov asz Bregman (LB) diver gence for rank aggregation on the score-based permutations is initially introduced in [5]. The LB div ergence is deriv ed from the generalized Bregman diver gence parametrized by the Lovasz extension of a submodular function, 1 https://github .com/uwjunqi/Subrank Fig. 1 . An illustration of a distributed ASR system. where a submodular function can be de fi ned via the property of diminishing return [6]. The diminishing return suggests that a func- tion f : 2 V → R + is submodular if ∀ a ∈ V \ B and subsets A ⊆ B ⊆ V , f satis fi es the inequality f ( { a } ∪ A ) − f ( A ) ≥ f ( { a } ∪ B ) − f ( B ) . Although general discrete optimization prob- lems are NP-hard, the submodular function allows the discrete optimization problems to be ef fi ciently approximated by heuristic algorithms, e.g., an exact minimization and an approximated max- imization [7], in a polynomial time with a performance guarantee. Moreov er , the Lovasz extension of a submodular function ensures a con ve x function [8]. The LB div ergence to rank aggregation on score-based permu- tations is brie fl y discussed in [5, 9], where the LB div ergence is ca- pable of measuring the div ergence between a score-based permuta- tion and an order-based permutation. This work applies the LB di- ver gence to construct the Normalized Discounted Cumulative Gain (NDCG) [10] loss function for the rank aggregation with an appli- cation to the distributed ASR system. The NDCG is a measure of ranking quality to ev aluate the effectiv eness of ranking algorithms, and it can be taken as an objective function for the rank aggregation of the distributed ASR system. Figure 1 shows a distributed ASR system, where there are 8 well-trained DNN-based acoustic models and the outputs of all mod- els need to be aggre gated to enhance the ASR performance. Our previous work [3, 11] focused on how to use submodular data par- titioning and selecting algorithms to split the full dataset into 8 dif- ferent non-overlapping subsets, and made use of the subsets to train 8 different DNN-based acoustic models. Then, the scoring lists of 8 acoustic models are aggregated to generate a consensus scoring list based on submodular rank aggregation in this w ork. Our contrib ution in this work includes: (1) the NDCG loss func- tion is constructed based on the LB di vergence; (2) linear and Nested structured framew orks are formulated for constructing optimization problems of the submodular rank aggregation; (3) ef fi cient learning and inference algorithms are proposed; (4) the algorithms are applied to a distributed ASR system. The remainder of the paper is organized as follows: Section 2 introduces the submodular function based on the LB di ver gence and the related NDCG loss function, and then the linear and nested rank aggregation functions are discussed in Section 3. The experimental results of the submodular rank aggregation for the distributed ASR system are shown in Section 4 and the paper is concluded in Sec- tion 5. 2. LB DIVERGENCE AND THE NDCG LOSS FUNCTION The LB div ergence as a utility function was fi rstly proposed in [12], and the related de fi nitions for the LB diver gence are brie fl y summa- rized in De fi nitions 1, 2, 3. De fi nition 1. For a submodular function f and an order-based per- mutation σ , then there is a chain of sets φ = S σ 0 ⊆ S σ 1 ⊆ ... ⊆ S σ N = V , with which the vector h f σ is de fi ned as (1). h f σ ( σ ( i )) = f ( S σ i ) − f ( S σ i − 1 ) , ∀ i = 1 , 2 , ..., | V | (1) where V is the ground set with all elements, and | V | is the number of candidates. De fi nition 2. For a submodular function f and a score-based permu- tation x , we de fi ne a permutation σ x such that x [ σ x (1)] ≥ x [ σ x (2)] ≥ ... ≥ x [ σ x ( N )] , and a chain of sets φ = S σ x 0 ⊆ S σ x 1 ⊆ ... ⊆ S σ x N = V , with which the vector h f σ x is de fi ned as (2). h f σ x ( σ x ( i )) = f ( S σ x i ) − f ( S σ x i − 1 ) , ∀ i = 1 , 2 , ..., N (2) De fi nition 3. Given a submodular function f and its associated Lo- vasz extension ˆ f , we de fi ne the LB di vergence d ˆ f ( x || σ ) for measur- ing the diver gence of permutations between a score-based permu- tation x and an order-based permutation σ . The LB div ergence is de fi ned as (3). d ˆ f ( x || σ ) = < x , h f σ x − h f σ > (3) where both h f σ and h f σ x are de fi ned via de fi nitions 1 and 2 , respec- tiv ely . Next, we study ho w to apply the LB di ver gence to obtain the NDCG loss function, which is used in the rank aggreg ation on score- based permutations. De fi nition 4. Given an order-based permutation σ with candidates from a ground set V = { 1 , 2 , ..., N } , and a set of relev ance scores { r (1) , r (2) , ..., r ( N ) } associated with σ , the NDCG score for σ is de fi ned as (4), where D ( · ) denotes a discounted term and π denotes the ground truth. Accordingly , the NDCG loss function L ( σ ) is de- fi ned as (5). N DC G ( σ ) = 1 N i =1 r ( π ( i )) D ( i ) N i =1 r ( σ ( i )) D ( i ) (4) L ( σ ) = 1 − N DC G ( σ ) = N i =1 r ( π ( i )) D ( i ) − r ( σ ( i )) D ( i ) N i =1 r ( π ( i )) D ( i ) (5) Corollary 1. For a submodular function f ( X ) = g ( | X | ) , the LB div ergence d ˆ f ( x || σ ) associated with f is deriv ed as (6). d ˆ f ( x || σ ) = N i =1 x ( σ x ( i )) δ g ( i ) − N i =1 x ( σ ( i )) δ g ( i ) (6) where δ g ( i ) = g ( i ) − g ( i − 1) , g ( · ) is a concave function, | X | denotes the cardinality of the set X , and σ x and σ refer to the score- based and order-based permutations, respecti vely . It is found that d ˆ f ( x || σ ) ∝ L ( σ ) , and the normalized d ˆ f ( x || σ ) can be applied as a utility function for the NDCG loss measurement because the normalization term in (5) is constant. Besides, the LB div ergence guarantees an upper bound for the NDCG loss function as shown in Proposition 1 . Proposition 1. Given a score-based permutation x and a concave function g , the LB diver gence d ˆ f ( x || σ ) de fi ned as (6) provides a constant upper bound to the NDCG loss function. Speci fi cally , L ( σ ) ≤ n Z · ǫ · ( g (1) − g ( | V | ) + g ( | V | − 1)) ≤ ǫ · ( g (1) − g ( | V | ) + g ( | V | − 1)) min i x ( σ x ( i )) δ g ( i ) (7) where n is the number of permutation x , ǫ = max i,j | x ( i ) − x ( j ) | , Z = n i =1 x ( σ x ( i )) δ g ( i ) is a normalization term, and the upper bound for L ( σ ) is independent of the permutation variable σ . Pr oof. T o obtain (7), we fi rstly show that, gi ven a monotone sub- modular function f and any permutation σ , there is an inequality (8) for d ˆ f ( x || σ ) : d ˆ f ( x || σ ) ≤ ǫ n · (max j f ( j ) − min j f ( j | V \{ j } )) (8) where ǫ = max i,j | x ( i ) − x ( j ) | , and f ( j | V \{ j } ) = f ( V ) − f ( V \{ j } ) is a marginal gain. Furthermore, by setting f ( X ) = g ( | X | ) , we can obtain max j f ( j ) = g (1) , and by applying the submodular dimin- ishing return property min j f ( j | V \{ j } ) = f ( V ) − f ( V \{ j } ) = g ( | V | ) − g ( | V | − 1) . Thus, by setting L ( σ ) = 1 Z d ˆ f ( x || σ ) , and not- ing that Z ≥ n · min i σ x ( i ) δ g ( i ) , the proof for (7) is completed. 3. THE LEARNING FRAMEWORKS FOR SUBMODULAR RANK A GGREGA TION Section 3 discusses two learning framew orks based on the NDCG loss function as introduced in Section 2, and the associated algo- rithms are proposed accordingly . 3.1. The Linear Structured Framework The fi rst learning framework based on the LB div ergence is built upon a linear structure. Suppose that there are | Q | queries and K score-based permutations { x q 1 , x q 2 , ..., x q K } associated with the query q ∈ Q , ∀ q ∈ Q , and π q ∈ { 1 , 2 , ..., N } . The LB diver - gence d ˆ f ( x q i || π q ) computes the div ergence between x q i and π q . The problem focuses on ho w to assign the weight v ector w = ( w 1 , w 2 , ..., w K ) T to d ˆ f ( x || π q ) = ( d ˆ f ( x q 1 || π q ) , ..., d ˆ f ( x q K || π q )) T . The objectiv e function of the linear structure is formulated in (9), where λ denotes a regularization term. Algorithm 1 Inference Algorithm 1 1. Input: a test data { q , N , K, X } , and the trained weights w ∗ = { w ∗ 1 , w ∗ 2 , ..., w ∗ K } . 2. Compute R X = K i =1 w ∗ i x i . 3. Argsort R X in a decreasing order → ˆ σ . 4. Output: ˆ σ and the sorted scores R X ( ˆ σ ) . min w 1 | Q | q ∈ Q K i =1 w i d ˆ f ( x q i || π q ) + λ 2 K i =1 w 2 i s.t., K i =1 w i = 1 , w i ≥ 0 (9) The stochastic gradient descent (SGD) algorithm is applied to obtain ∇ sgd as (10), and update the parameter w based on (11) to satisfy the constraints in (9). ∇ i = 1 | Q | q ∈ Q d ˆ f ( x q i || π q ) + λ w i (10) w ( t +1) i = w ( t ) i exp( − µ ∇ sgd i ) K j =1 w ( t ) j exp( − µ ∇ sgd j ) (11) The update of (11) goes through all i = 1 , ..., K and each query q ∈ Q . Several iterations are repeated until w gets con vergence. Proposition 2. In the linear structured frame work, giv en the number of candidates N and the number of permutations K , the computa- tional complexity in the training stage is O ( N K ) . The inference process is formulated as follo ws: given a test data { q , N , K , X } , where q is a query , N and K hav e been de fi ned as abov e, and X = { x q 1 , ..., x q K } represents the score-based permuta- tion associated with the query q , we estimate an optimal order-based permutation ˆ σ as de fi ned in (12). ˆ σ = arg min π q K i =1 w ∗ i d ˆ f ( x q i || π q ) (12) where w ∗ refers to the weight vector trained in the training stage. Generally , the problem in (12) is an NP-hard combinatorial prob- lem, but the LB div ergence provides a close-form solution ˆ σ = σ µ , where µ = K i =1 w ∗ i x q i . The complete inference algorithm is shown in Algorithm 1. Note that the order -based permutation ˆ σ is fi nally obtained by sorting the numerical v alues in R X and the permutation associated with R X is returned in a decreasing order . 3.2. The Nested Structured Framework The linear structured frame work inv olves several potential problems: the fi rst problem is that the score-based permutations { x i } K i =1 may not interact with each other, since one permutation might be partially redundant with another; the second problem lies in the fact that a permutation x i tends to become dominant o ver the rest. T o ov ercome these problems, an additional hidden layer is utilized to construct a nested structured framew ork. The objective function for the nested structured framework is formulated as (13), where K 1 and K 2 separately represent the num- bers of units in the input and hidden layers, W 1 ∈ R K 2 × K 1 and W 2 ∈ R 1 × K 2 denote weights for the bottom and upper layers, re- spectiv ely , and λ 1 and λ 2 refer to regularization terms. By setting both Φ 1 and Φ 2 as increasing conca ve functions, the objecti ve func- tion becomes a concave function and thus it needs to be maximized with respect to W 1 and W 2 . max W 1 ,W 2 1 | Q | q ∈ Q Φ 2 ( K 2 i =1 W 2 ( i ) Φ 1 ( K 1 j =1 W 1 ( i, j ) d ˆ f ( x q j || π q ))) + λ 1 2 || W 1 || 2 F + λ 2 2 || W 2 || 2 F s.t., K 1 j =1 W 1 ( i, j ) = 1 , K 2 i =1 W 2 ( i ) = 1 , W 1 ( i, j ) ≥ 0 , W 2 ( i ) ≥ 0 , ∀ i, j (13) The update for weights W 1 and W 2 follows a feed-forw ard man- ner that is similar to that employed for a standard Multiple Layer Perceptron (MLP) training. As to the update for the weights of the bottom layer, the tempo- ral variables δ 1 ( i ) and ∇ 1 ( i, j ) need to be fi rstly computed by (14) and (15), and W 1 is updated by (16), where µ refers to the learning rate. δ 1 ( i ) = K 1 j =1 W ( t ) 1 ( i, j ) d ˆ f ( x q j || π q ) (14) ∇ 1 ( i, j ) = ( Φ 1 ( δ 1 ( i ))) ′ K 1 j =1 d ˆ f ( x q j || π q ) + λ 1 W ( t ) 1 ( i, j ) (15) W ( t +1) 1 ( i, j ) = W ( t ) 1 ( i, j ) exp( − µ ∇ 1 ( i, j )) K 1 j =1 W ( t ) 1 ( i, j ) exp( − µ ∇ 1 ( i, j )) (16) The procedure of updating W 2 starts as soon as the update of W 1 is done. The new δ 2 and ∇ 2 ( i ) are separately deriv ed by (17) and (18) based on the message propagation from the bottom layer . Finally , the update for W 2 is conducted by (19). δ 2 = K 2 i =1 W ( t ) 2 ( i ) Φ 1 ( δ i ( i )) (17) ∇ 2 ( i ) = ( Φ 2 ( δ 2 )) ′ Φ 1 ( δ 1 ( i )) + λ 2 W ( t ) 2 ( i ) (18) W ( t +1) 2 ( i ) = W ( t ) 2 ( i ) exp( − µ ∇ 2 ( i )) K 2 j =1 W ( t ) 2 ( j ) exp( − µ ∇ 2 ( j )) , ∀ i (19) Proposition 3. In the nested structured framework, giv en the num- bers K 1 and K 2 for the input and hidden layers, respectiv ely , and the number of candidates N , the computational complexity for the entire training process is O ( N K 1 + K 1 K 2 ) . The inference for the nested structured framew ork shares the same steps that the linear structured framework except that the step 2 in Algorithm 1 is replaced by (20). R X = Φ 2 ( K 2 i =1 W 2 ( i ) Φ 1 ( K 1 j =1 W 1 ( i, j ) x q j )) (20) 4. EXPERIMENTS This section presents the experimental setups and empirical results on the distributed ASR system. Our distributed ASR system is shown in Figure 1, where there are 8 DNN-based acoustic models and each DNN shares the same initial setup in terms of the model architectures and ReLU activ ation functions. A full training dataset is partitioned into 8 non-overlapping subsets by means of the ro- bust submodular data partitioning algorithm [3], and each subset is employed to train a particular DNN-based acoustic model, which results in 8 different DNN-based acoustic models. The 8 lists of acoustic scores from the acoustic models need to be aggregated into a fi nal list with a higher ASR accuracy . Instead of adopting the aggregation method based on Adaboost of our previous work [3], we apply the approach of submodular rank aggregation discussed in this work. 4.1. Experimental setup Follo wing the steps in [3], the submodular partitioning functions were composed based on the prior phonetic kno wledge that a tri- phone corresponds to 8 different biphones based on the phonetic knowledge including ‘Place of Articulation’, ‘Production Manner’, ‘V oicedness’ and ‘Miscellaneous’. For training each DNN-based acoustic model, the full dataset is split into 8 disjoint data subsets by formulating the problem as a robust submodular data partitioning algorithm in [3]. Our experiments were conducted on the 1300 hours of con versa- tional English telephone speech data from the Switchboard, Switch- board Cellular, and Fisher databases. The development and testing datasets were the 2001 and 2002 NIST Rich Transcription dev el- opment sets, with 2.2 hours and 6.3 hours of acoustic data, respec- tiv ely . Data preprocessing includes extracting 39 -dimensional Mel Frequency Cepstrum Coef fi cient (MFCC) features that correspond to 25 . 6 ms of speech signals. Besides, mean and v ariance speaker normalization were also applied. The acoustic models are initialized as clustered tri-phones mod- eled by 3 -state left-to-right hidden Marko v models (HMMs) [13]. The state emission probability in the HMMs was modeled from the Gaussian mixture model (GMM). The DNN targets consisted of ap- proximately 7800 clustered tri-phone states [14]. All sequential la- bels corresponding to the training data were generated by forced- alignment based on HMM-GMM. A 3-gram language model, built from the training materials, was used for the decoding. The units at the input layer of each of the 8 DNNs correspond to a long-context feature vector that was generated by concatenat- ing 11 consecutiv e frames of the primary MFCC feature followed by a discrete cosine transformation (DCT) [15, 16]. Thus, the di- mension of the initial long-context feature was 429 and the num- ber was reduced to 361 after DCT . There were 4 hidden layers in total with a setup of 1024 - 1024 - 1024 - 1024 for the DNN construc- tion [17]. The parameters of the hidden layers were initialized via Restricted Boltzman Machine pre-training [18], and the fi ne-tuned by the Multi-layer Perceptron Back-propag ation algorithm. Besides, the feature-based maximum lik elihood linear regression was applied to the DNN speaker adaption [19]. When the training process of all the DNN-based acoustic models was done, the fi nal posteriors of the clustered tri-phones associated with the training data should be separately obtained from each of the DNN-based acoustic models. Those posteriors were taken as per- mutation data for training the submodular rank aggregation models. In the testing stage, the posteriors collected from the 8 DNN-based acoustic models are combined to one permutation that is expected to be as close to the ground truth as possible. As for the con fi gura- tion of the submodular rank aggregation formulations, the number of permutations K is set to 8 , and the dimension of a permutation is con fi gured as 7800, which matches the number of clustered tri- phone states. Besides, the number of units of the hidden layer in the nested structured framework is set to 120, and there is only one output corresponding to the fi nal aggregation permutation. 4.2. Experimental results T able 1 shows the ASR decoding results from each of the DNN- based acoustic models, and T able 2 represents the combined ones based on the dif ferent aggregation methods. The results suggest that the submodular rank aggregation methods based on the linear and nested structured formulation obtain a better result than the base- line system based on the Adaboost approach and a simple a veraging method. The marginal gain obtained with the nested structured for- mulation with regards to the linear structured one arises from the potential bias caused by the forced-alignment of the clustered tri- phones. Model DNN1 DNN2 DNN3 DNN4 PER 28.3 28.7 29.3 28.6 Model DNN5 DNN6 DNN7 DNN8 PER 28.8 28.7 28.6 28.4 T able 1 . Phone Error Rate (PER) (%). Method PER A veraging 28.1 Adaboost 27.4 Linear-LBD 26.8 Nested-LBD 26.4 T able 2 . Phone Error Rate (PER) (%). ‘LBD’ stands for the Lovasz Bregman di ver gence. 5. CONCLUSIONS This work proposes a submodular rank aggregation on score-based permutations based on the LB diver gence in both linear and nested structured frame works for a distributed ASR system. Besides, the related learning algorithms based on SGD are used to ensure op- timal solutions to the submodular rank aggregation problem. Our experiments on the distrib uted ASR system sho w that the nested LB div ergence can obtain signi fi cantly more gains. Howev er , the gains obtained with respect to the other approaches are lower to v arying degrees. In addition, our methods can be scalable to large-scale datasets because of their low computational complexity in the in- ference procedure. Future work will study ho w to generalize the nested structure to a deeper one with more hidden layers. Although the conve x- ity/concavity of the objective function with a deep structure can be maintained, the use of the message-passing to deeper layers cannot obtain a satisfying result on the task of distributed ASR. Thus, an improv ed learning algorithm for training an LB-div ergence based objectiv e function with a deeper structure is necessary . 6. REFERENCES [1] Guangsen W ang and Khe Chai Sim, “Regression-based context-dependent modeling of deep neural networks for speech recognition, ” IEEE/A CM T ransactions on Audio, Speech and Langua ge Pr ocessing (T ASLP) , v ol. 22, no. 11, pp. 1660–1669, 2014. [2] Kadri Hacioglu and Bryan Pellom, “ A distributed architecture for robust automatic speech recognition, ” in 2003 IEEE In- ternational Conference on Acoustics, Speech, and Signal Pro- cessing (ICASSP). IEEE, 2003, vol. 1, pp. I–I. [3] Jun Qi and Javier T ejedor , “Robust submodular data partition- ing for distributed speech recognition, ” in 2016 IEEE Interna- tional Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2016, pp. 2254–2258. [4] Gunnar R ¨ atsch, T akashi Onoda, and K-R M ¨ uller , “Soft mar- gins for adaboost, ” Machine Learning , vol. 42, no. 3, pp. 287– 320, 2001. [5] Rishabh Iyer and Jeff Bilmes, “The lov ´ asz-bregman div ergence and connections to rank aggregation, clustering, and web rank- ing, ” arXiv preprint , 2013. [6] Jack Edmonds, “Submodular functions, matroids, and certain polyhedra, ” in Combinatorial Optimization—Eur eka , pp. 11– 26. Springer , 2003. [7] Satoru Fujishige, Submodular functions and optimization , vol. 58, Elsevier , 2005. [8] L ´ aszl ´ o Lov ´ asz, “Submodular functions and con ve xity , ” in Mathematical Pr ogramming The State of the Art , pp. 235–257. Springer , 1983. [9] Jun Qi, Xu Liu, Javier T ejedor , and Shunsuke Kamijo, “Unsu- pervised submodular rank aggregation on score-based permu- tations, ” arXiv preprint , 2017. [10] Kalervo J ¨ arvelin and Jaana K ek ¨ al ¨ ainen, “Cumulated gain- based ev aluation of ir techniques, ” ACM T ransactions on In- formation Systems (TOIS) , v ol. 20, no. 4, pp. 422–446, 2002. [11] Jun Qi, Xu Liu, Shunshuke Kamijo, and Javier T ejedor, “Dis- tributed submodular maximization for lar ge vocab ulary contin- uous speech recognition, ” in 2018 IEEE International Confer- ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 2501–2505. [12] Rishabh Iyer and Jeff Bilmes, “Submodular bregman di ver- gences with applications, ” Neural Information Processing So- ciety (NIPS) , pp. 2933–2941, 2012. [13] Sean R Eddy , “Hidden markov models, ” Current opinion in structural biology , v ol. 6, no. 3, pp. 361–365, 1996. [14] Ste ve J Y oung, Julian J Odell, and Philip C W oodland, “Tree- based state tying for high accuracy acoustic modelling, ” in Pr oceedings of the workshop on Human Languag e T echnology . Association for Computational Linguistics, 1994, pp. 307–312. [15] J. Qi, D. W ang, and J. T ejedor Noguerales, “Subspace models for bottleneck features, ” in Interspeech . ISCA, 2013, pp. 1746– 1750. [16] J. Qi, D. W ang, and and J. T ejedor Noguerales J. Xu, “Bottle- neck features based on gammatone frequency cepstral coef fi - cients, ” in Interspeech . ISCA, 2013, pp. 1751–1755. [17] J. Qi, J. Du, S.M. Siniscalchi, and C.-H. Lee, “ A theory on deep neural network based vector -to-vector regression with an illustration of its expressiv e power in speech enhancement, ” IEEE/A CM T ransactions on Audio, Speech, and Language Pr ocessing (TASLP) , v ol. 27, no. 12, pp. 1932–1943, 2019. [18] Geof frey E Hinton and Ruslan R Salakhutdinov , “Reducing the dimensionality of data with neural networks, ” science , vol. 313, no. 5786, pp. 504–507, 2006. [19] Mark JF Gales, “Maximum likelihood linear transformations for hmm-based speech recognition, ” Computer speech & lan- guage , v ol. 12, no. 2, pp. 75–98, 1998.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment