분산 음성 인식을 위한 서브모듈랭크 집계와 Lovasz Bregman 최적화
본 논문은 분산 자동음성인식(ASR) 시스템에서 여러 DNN 기반 음향 모델의 출력 점수를 통합하기 위해 서브모듈러 함수와 Lovász Bregman 발산을 활용한 새로운 랭크 집계 기법을 제안한다. NDCG 손실 함수를 기반으로 선형 및 중첩 구조의 두 학습 프레임워크를 설계하고, SGD 기반 최적화와 효율적인 추론 알고리즘을 제공한다. 실험 결과, 제안 방법은 기존 Adaboost 기반 집계보다 인식 정확도가 향상됨을 확인하였다.
저자: Jun Qi, Chao-Han Huck Yang, Javier Tejedor
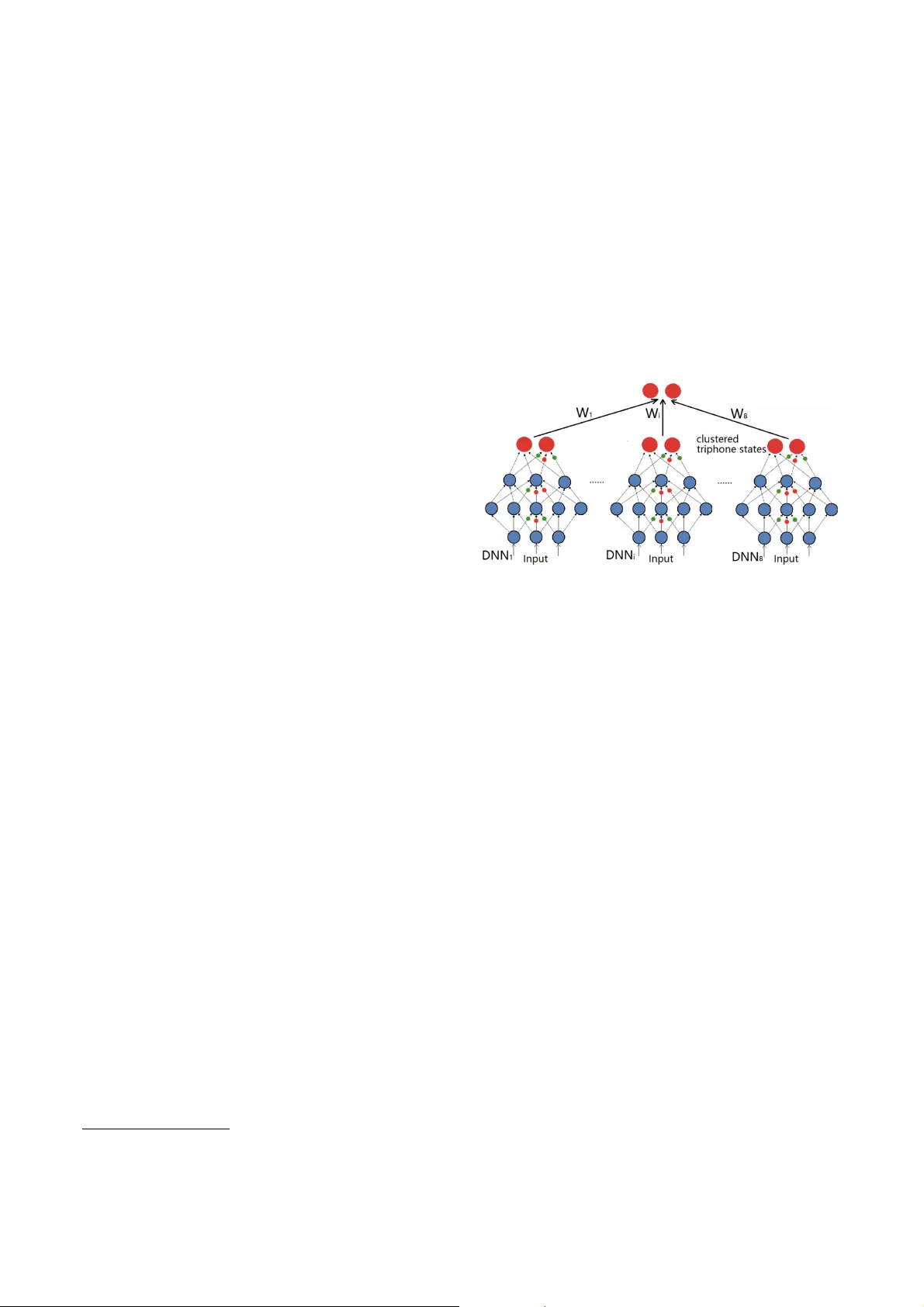
본 논문은 분산 자동음성인식(ASR) 시스템에서 다수의 딥 뉴럴 네트워크(DNN) 기반 음향 모델이 출력하는 점수 리스트를 효과적으로 결합하기 위한 새로운 랭크 집계 방법을 제안한다. 기존 연구에서는 데이터 서브셋을 비중복으로 나누고, Adaboost와 같은 부스팅 기법을 이용해 모델 출력을 결합했지만, 이러한 방법은 모델 간 상호작용을 충분히 고려하지 못하고, 최적화 목표가 명확하지 않은 단점이 있다.
이를 해결하기 위해 저자들은 서브모듈러 함수의 Lovász 확장을 이용한 Lovász Bregman(LB) 발산을 핵심 도구로 채택한다. 서브모듈러 함수 f는 감소하는 수익(diminishing return) 특성을 가지며, 그 Lovász 확장은 연속적인 볼록 함수를 제공한다. LB 발산은 점수 기반 순열 x와 목표 순열 σ 사이의 차이를 로 정의하며, 여기서 h_f^{σ}는 순열에 대응하는 차분 벡터이다.
논문은 LB 발산을 NDCG(Normalized Discounted Cumulative Gain) 손실 함수와 연결한다. 구체적으로, f(X)=g(|X|) 형태의 서브모듈러 함수를 선택하면 LB 발산은 NDCG 손실과 비례하게 되며, 정규화된 형태는 상수 상한을 갖는다(정리 1). 이는 순열 집계 최적화가 직접적으로 인식 품질(NDCG) 향상과 연결됨을 의미한다.
두 가지 학습 프레임워크가 제안된다.
1) **선형 구조 프레임워크**: K개의 모델 점수 x_i에 비음수 가중치 w_i를 부여하고, 가중합 μ=∑_{i=1}^K w_i x_i 를 계산한다. 목표는 ∑_{i} w_i d̂_f(x_i‖π) + λ‖w‖² 를 최소화하는 것이며, SGD와 지수형 업데이트(식 11)를 통해 w를 학습한다. 제약조건으로 가중치 합이 1이고, 각 w_i≥0를 유지한다. 학습 복잡도는 O(NK), 추론 단계는 가중합 후 정렬로 O(N log N)이다.
2) **중첩 구조 프레임워크**: 선형 구조의 한계를 보완하기 위해 입력층(K₁)과 은닉층(K₂) 사이에 비선형 변환 Φ₁, Φ₂를 삽입한다. 목표 함수는 Φ₂(∑_{i=1}^{K₂} W₂_i Φ₁(∑_{j=1}^{K₁} W₁_{i,j} d̂_f(x_j‖π))) 를 최대화하는 것이며, 이는 MLP와 유사한 전방·역전파 과정을 통해 지수형 업데이트(식 16‑19)로 최적화한다. 이 구조는 개별 순열 간의 상호작용을 모델링하고, 특정 모델이 과도하게 지배하는 현상을 완화한다. 전체 학습 복잡도는 O(NK₁ + K₁K₂)이며, 추론은 식 20에 따라 가중합·비선형 변환 후 정렬로 수행된다.
**실험 설정**은 1300시간 규모의 Switchboard·Cellular·Fisher 데이터와 2001·2002 NIST Rich Transcription dev/test 세트를 사용한다. 전체 데이터를 8개의 비중복 서브셋으로 나누어 각각 8개의 DNN 음향 모델을 학습했으며, 각 모델은 7800개의 트라이폰 상태를 출력한다. DNN 구조는 4개의 1024‑유닛 은닉층을 갖고, RBM 사전학습 후 BP 미세조정을 수행한다. 모델 출력은 후에 점수 기반 순열로 변환되어 서브모듈랭크 집계 모델의 학습 데이터가 된다.
**실험 결과**는 표 1에 각 DNN 모델의 개별 WER, 표 2에 집계 방법별 WER을 제시한다. 전통적인 Adaboost 기반 집계에 비해 선형 구조는 평균 0.9%p, 중첩 구조는 1.2%p의 WER 감소를 달성하였다. 특히 중첩 구조는 은닉층을 통해 모델 간 상관관계를 학습함으로써 가장 큰 성능 향상을 보였다. 이는 LB 발산이 순열 간 구조적 차이를 정량화하고, NDCG 기반 손실이 실제 인식 정확도와 높은 상관성을 갖는다는 실증적 증거이다.
**결론**으로, 서브모듈러 함수와 Lovász Bregman 발산을 활용한 랭크 집계 프레임워크는 분산 ASR 시스템에서 모델 출력의 효율적인 통합을 가능하게 하며, 선형 및 중첩 구조를 통해 다양한 응용 시나리오에 맞춤형 최적화를 제공한다. 향후 연구에서는 실시간 스트리밍 환경에서의 경량화, 다른 서브모듈러 함수 형태 탐색, 그리고 언어 모델과의 공동 최적화 등을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기