Collective Learning
In this paper, we introduce the concept of collective learning (CL) which exploits the notion of collective intelligence in the field of distributed semi-supervised learning. The proposed framework draws inspiration from the learning behavior of huma…
Authors: Francesco Farina
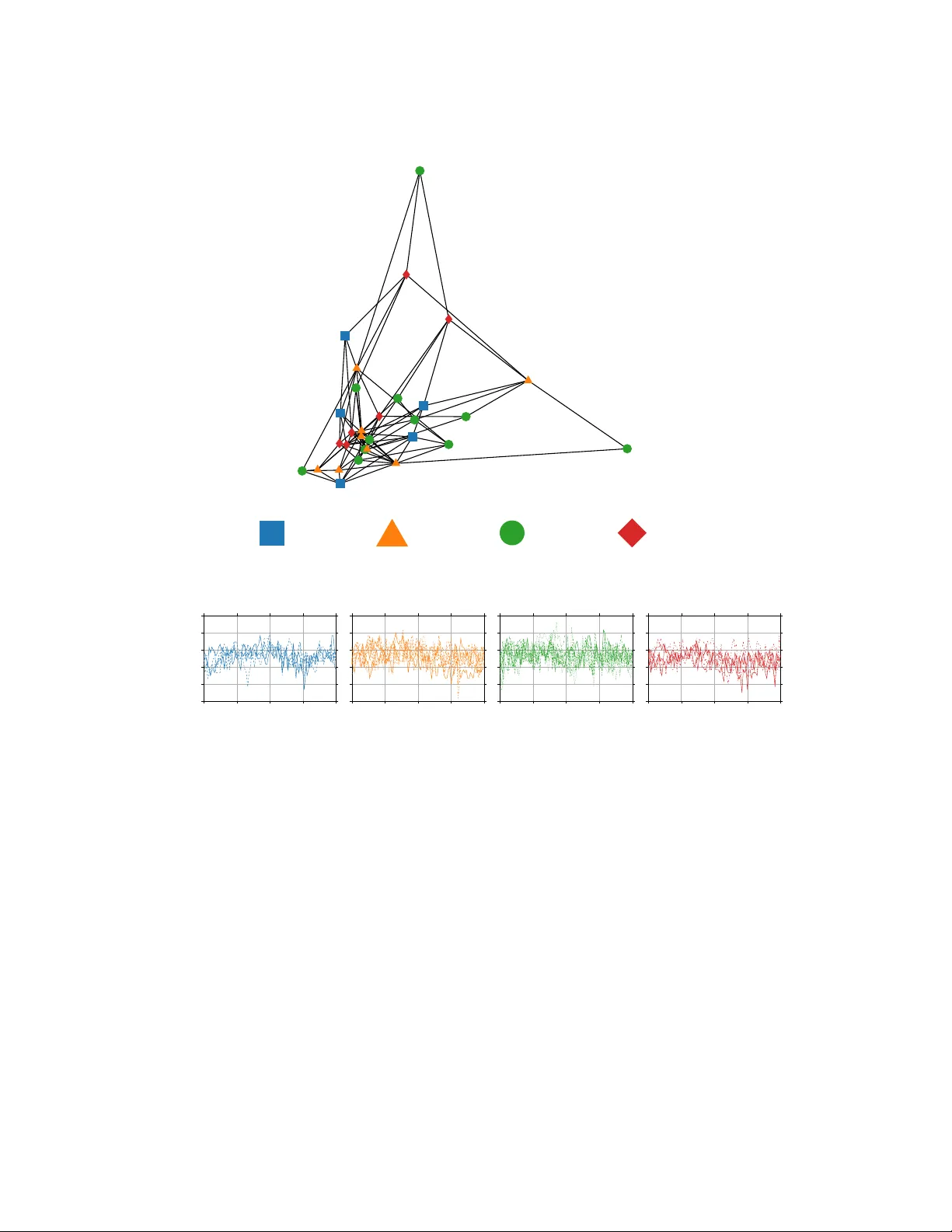
Collectiv e Learning F rancesco F arina franc.farina@unibo.it Departmen t of Electrical, Electronic and Information Engineering Alma Mater Studiorum - Univ ersit` a di Bologna Bologna, Italy Abstract In this pap er, we in tro duce the concept of collective learning (CL) whic h exploits the notion of collectiv e intelligence in the field of distributed semi-supervised learning. The prop osed framew ork dra ws inspiration from the learning behavior of h uman beings, who alternate phases in v olving collab oration, confrontation and exc hange of views with other consisting of studying and learning on their o wn. On this regard, CL comprises t wo main phases: a self-training phase in whic h learning is performed on lo cal priv ate (lab eled) data only and a collective training phase in which proxy-labels are assigned to shared (unlab eled) data by means of a consensus-based algorithm. In the considered framew ork, heterogeneous systems can be connected o ver the same netw ork, eac h with differen t computational capabilities and resources and ev eryone in the netw ork ma y tak e adv an tage of the coop eration and will ev en tually reach higher performance with resp ect to those it can reach on its own. An extensiv e exp erimental campaign on an image classification problem emphasizes the prop erties of CL by analyzing the p erformance ac hieved by the co operating agents. 1 In tro duction The notion of c ol le ctive intel ligenc e has b een firstly in tro duced in [Engelbart, 1962] and widespread in the sociological field by Pierre L ´ evy in [L ´ evy and Bononno, 1997]. By borrow- ing the words of L ´ evy , collective intelligence “ is a form of universal ly distribute d intel ligenc e, c onstantly enhanc e d, c o or dinate d in r e al time, and r esulting in the effe ctive mobilization of skil ls ”. Moreo ver, “ the b asis and go al of c ol le ctive intel ligenc e is mutual r e c o gnition and enrichment of individuals r ather than the cult of fetishize d or hyp ostatize d c ommunities ”. In this pap er, we aim to exploit some concepts b orro w ed from the notion of collective in telligence in a distributed machine learning scenario. In fact, b y coop erating with each other, machines may exhibit p erformance higher than those they can obtain by learning on their own. W e call this framework c ol le ctive le arning (CL) . Distributed systems 1 ha ve receiv ed a steadily gro wing attention in the last years and 1 When talking about distributed systems, the word distribute d can b e used with different meanings. Here, w e refer to those netw orks composed by peer agents, without an y cen tral co ordinator. 1 they still deserve a great consideration. In fact, now adays the organization of computa- tional p o wer and data naturally calls for the distributed systems. It is extremely common to ha ve heterogeneous computing units connected together in p ossibly time-v arying netw orks. Both computational p ow er and data can be shared or kept priv ate. Moreo ver, there can b e additional globally a v ailable resources (suc h as cloud -stored data). Last but not least, preserving the priv acy of the lo cal data of the netw orked systems must be a key requiremen t. This net work structure requires the design of tailored distributed algorithms that ma y let agen ts b enefit from the comm unication capabilities at disposal, exploit the av ailable com- putational p ow er and take adv antage b oth of shared and priv ate resources without affecting priv acy preserv ation. The learning framework w e wan t to address in CL is the one of semi-sup ervised learning. In particular, we consider problems in which priv ate data at eac h no de are lab eled, while shared (and cloud) data are unlab eled. This captures a key c hallenge in today’s learning problems. In fact, while unlab eled data can b e easy to retrieve, lab eled data are often exp ensiv e to obtain (b oth in terms of time and money) and can b e unshareable (due, e.g. , to priv acy restrictions or trade secrets). Th us, one t ypically has few lo cal lab eled samples and a huge n umber of (globally av ailable) unlabeled ones. Hybrid problems in which also shared lab eled and priv ate unlabeled data are av ailable can b e easily included in the prop osed framew ork. In order to p erform CL in the ab o ve set-up, w e prop ose an algorithmic idea that is now briefly describ ed. First of all, in order to take adv antage of the possible p eculiarities and heterogeneit y of all the agents in the netw ork, each agent can use a custom architecture for its learning function. The algorithm starts with an initial preliminary phase, c alled self- training, in whic h agen ts indep enden tly train their lo cal learning functions on their priv ate lab eled data. Then, the algorithm pro ceeds with the collective training phase, b y iterating through the shared (unlab eled) set. F or each unlab eled data, each agen t makes a prediction of the corresp onding lab el. Then, by using a weigh ted av erage of the predictions of its neigh b ors (as in consensus-based algorithms), it pro duces a lo cal pro xy-lab el for the current data and uses such a lab el to train the local learning function. W eights for the predictions coming from the neighbors are assigned by ev aluating the p erformance on lo cal v alidation sets. During the collective training phase, the lo cal lab eled dataset are review ed from time to time in order to give more imp ortance to the lo cal c orr e ctly lab ele d data. W e w ant to emphasize righ t no w that addressing the theoretical prop erties of the pro- p osed algorithm is b eyond the scop e of this paper and will b e sub ject to future inv estigation. Rather, in this work, we present the CL framew ork for distributed semi-sup ervised learn- ing, and w e pro vide some exp erimental results in order to emphasize the features and the p oten tial of the prop osed algorithm. The pap er is organized as follows. The relev ant literature for CL is rep orted in the next section. Then, the problem set-up is formalized and the prop osed CL algorithm is presented in details. Finally , an extensive numerical analysis is p erformed on an image classification problem to ev aluate the p erformance of CL. 2 Related w ork The literature related to this pap er can b e divided in t wo main groups: w orks addressing distributed systems and those inv olving widely known machine learning techniques that are 2 strictly related to CL. A v ast literature has been pro duced for dealing with distributed systems in differen t fields, including computer science, control, estimation, co op erative robotics and learning. Man y problems arising in these fields can b e cast as optimization problems and need to b e solv ed in a distributed fashion via tailored algorithms. Many of them are based on consensus protocols, whic h allows to reach agreement in m ulti-agent systems [Olfati-Sab er et al., 2007] and hav e b een widely studied under v arious netw ork structures and communication proto cols [Bullo et al., 2009, Kar and Moura, 2009, Garin and Schenato, 2010, Liu et al., 2011, Kia et al., 2015]. On the optimization side, dep ending on the nature of the optimization problem to b e solved, v arious distributed algorithms hav e b een developed. Conv ex problems hav e b een studied within a very large num b er of frameworks [Boyd et al., 2006, Nedic and Ozdaglar, 2009, Zhu and Mart ´ ınez, 2012, Ram et al., 2010, Ne dic et al., 2010, W ei and Ozdaglar, 2012, F arina and Notarstefano, 2020], while noncon vex problems hav e b een originally addressed via the distributed sto chastic gradient descent [Tsitsiklis et al., 1986] and hav e receiv ed recen t attention in [Bianchi and Jakubowicz, 2013, Di Lorenzo and Scutari, 2016, T atarenk o and T ouri, 2017, Notarnicola et al., 2018, F arina et al., 2019a]. In this pap er, we consider a differen t set-up with resp ect to the one usually found in the ab ov e distributed optimization algorithms. In fact, each agen t has its own learning function, and hence a lo cal optimization v ariable that is not related with the ones of other agents. Th us, there is no explicit coupling in the optimization problem. As it will b e sho wn in the next sections, the collective training phase of CL is heavily based on consensus algorithms, but agreemen t is sough t on data and not on decision v ariables. Other relev ant algorithms and frameworks sp ecifically designed for learning with non-centralized systems include the recen t w orks on distributed learning from constrain ts [F arina et al., 2019b], federated learning [Koneˇ cn` y et al., 2015, McMahan et al., 2016, Kone ˇ cn` y et al., 2016, Smith et al., 2017] and man y other frameworks [Dean et al., 2012, Lo w et al., 2012, Krask a et al., 2013, Li et al., 2014, Chen et al., 2015, Meng et al., 2016, Chen et al., 2016]. Except [F arina et al., 2019b] and some papers on federated learning, most of these works, ho wev er, lo ok for data/mo del distribution and parallel computation. They usually do not deal with fully distributed systems, b ecause a central server is required to collect and compute the required parameters. Mac hine learning tec hniques related to CL are, mainly , those inv olving proxy lab eling op erations on unsup ervised data (in semi-sup ervised learning scenarios). In fact, there exist man y techniques in which fictitious lab els are asso ciated to unsup ervised data, based on the output of one (or more) mo dels that ha ve b een previously trained on sup ervised data only . Co-training [Blum and Mitchell, 1998, Nigam and Ghani, 2000, Chen et al., 2011] exploit tw o (or more) views of the data, i.e. , different feature sets represen ting the same data in order to let mo dels pro duce labeled data for each other. Similarly , in demo cratic co-learning [Zhou and Goldman, 2004] different training algorithms on the same views are exploited, b y lever- aging off the fact that differen t learning algorithms ha ve different inductive biases. Lab els on unsup ervised data are assigned b y using the voted ma jorit y . T ri-training [Zhou and Li, 2005] is similar to demo cratic co-learning, but only three indep endently trained mo dels are used. In self-training [McClosky et al., 2006, Rosenberg et al., 2005] and pseudo-lab eling [W u and Y ap, 2006, Lee, 2013] a single mo del is first trained on sup ervised data, then it assigns lab els to unsup ervised data and uses them for training. Moreov er, strictly related to this work are the concepts of ensemble learning [T umer and Ghosh, 1996, Dietteric h, 2000, W ang et al., 2003, Rok ach, 2010, Deng and Platt, 2014] in which an ensemble of mo dels is used to mak e 3 b etter predictions, transfer learning [Bengio, 2012, W eiss et al., 2016] and distillation [Hin- ton et al., 2015] in whic h mo dels are trained by using other mo dels, and learning with ladder net works [Rasmus et al., 2015] and noisy lab els [Natara jan et al., 2013, Liu and T ao, 2016, Han et al., 2018]. T o sum up, w e p oint out that this pap er utilizes some of the ab ov e concepts b oth from distributed optimization and mac hine learning. In particular, w e exploit consensus proto cols and proxy lab eling tec hniques in order to pro duce collective in telligence from net work ed mac hines. 3 Problem setup In this section the considered problem setup is presented. First, we describ e the structure of the netw ork o v er whic h agen ts in the net work comm unicate. Then, the addressed distributed learning setup is describ ed. 3.1 Comm unication net w ork structure W e consider a netw ork comp osed by N agents, which is mo deled as a time-v arying directed graph G k = ( V , E k , W k ), where V = { 1 , . . . , N } is the set of agen ts, E k ⊆ V × V is the set of directed edges connecting the agents at time k and W k = [ w k ij ] is the weigh ted adjacency matrix asso ciated to E k . the elements of which satisfy (i) w k ii > 0 for all i ∈ V , (ii) w k ij ≥ 0 if and only if ( j, i ) ∈ E k , (iii) P N j =1 w k ij = 1 ( i.e. , W k is row sto chastic), for all k = 0 , 1 , . . . . W e assume the time-v arying graph G k is jointly strongly connected, i.e. , there exists K > 0 suc h that the graph G k ∪ G k +1 ∪ · · · ∪ G k + K is strongly connected for all k (see Figure 1 for a graphical representation). W e denote b y N k i,in the set of in-neighbors of no de i at iteration k (including no de i itself ), i.e. , N k i = { j | ( j, i ) ∈ E k } ∪ { i } . Similarly we define the set of out-neighbors of no de i at time k as N k i,out . The join t-strong connectivity of the graph sequence is a t ypical assumption and it is needed to guarantee the spread of information among all the agents. G k G k +1 G k +2 Figure 1: Graphical representation of a time v arying graph for which the joint graph G k ∪ G k +1 ∪ G k +2 is strongly connected. 4 3.2 Learning setup W e consider a semi-sup ervised learning scenario. Each agent i is equipp ed with a set of M i priv ate labeled data p oin ts D i = { ( x r i , y r i ) } M i r =1 , where x r i ∈ R d is the r -th data of no de i (with d b eing the dimension of the input space), and y r i the corresponding lab el. The set D i is divided in a training set and a v alidation set. The training set consists of the first m i < M i samples and is defined as D i,T = { ( x r i , y r i ) } m i r =1 , while the v alidation set is defined as D i,V = { ( x r i , y r i ) } M i r = m i +1 . Besides, all agents ha ve access to a shared dataset consisting of m s unlab eled data, D s = { x r s } m s r =1 , with x r s ∈ R d . The goal of eac h agent is to learn a certain lo cal function f i ( θ i ; x ) (represen ting a local classifier, regressor, etc.), where we denote b y θ i ∈ R n i the learnable parameters of f i and by x a generic input data. Notice that w e are not making any assumption on the lo cal functions f i . In fact, in general, n i 6 = n j for any i and j . A graphical representation of the considered learning setup is given in Figure 2. In the exp eriments, w e will consider as a metric to ev aluate the actual p erformance of the agents the accuracy computed on a s hared test set D test . Such a dataset is intended for test purp oses only and cannot b e used to train the lo cal classifiers. D s = { x r s } m s r =1 i f i , θ i , D i = { ( x r i , y r i ) } M i r =1 Figure 2: Graphical representation of the considered distributed semi-sup ervised learning set-up. 4 Collectiv e Learning In this section, we present in details our algorithmic idea for CL. F or the sake of exp osition, let us consider a problem in which all agents w ant to learn the same task through their lo cal functions f i . Multi-task problems can b e directly addressed in the same wa y , at the price of a more inv olved notation. Eac h agen t in the netw ork is equipped with a lo cal priv ate learning function f i . The structure of eac h f i can b e arbitrary and different from one agen t to the other. F or example, f 1 can b e a shallow neural net work with d input units, f 2 a deep one with man y hidden 5 la yers, f 3 a CNN and so on. As said, the functions f i are priv ate for each agent, and, consequen tly , their learnable parameters θ i should not b e shared. Collectiv e learning consists of t wo main phases: 1. a preliminary phase (referred to as self-tr aining ), in which eac h agent trains its lo cal learning function b y using only its priv ate (labeled) data contained in the local training set D i,T ; 2. a c ol le ctive tr aining phase, in whic h agents collab orate in order for collectiv e in telli- gence to emerge. 4.1 Self-training This first preliminary phase do es not require any communication in the netw ork since each agen t tries to learn f i from its priv ate lab eled training set D t,T . It allows agents to p e rform the successive collective training phase after exploiting their priv ate sup ervised data. Define Φ i ( f i ( θ i ; x ) , y ) as the loss function asso ciated by agen t i to a generic datum ( x, y ). Then, the optimization problem to b e addressed by age n t i in this phase is minimize θ i Ψ i ( θ i ; D i,T ) = X ( x,y ) ∈D i,T Φ i ( f i ( θ i ; x ) , y ) . (1) Usually , such a problem is solved (meaning that a stationary p oin t is found) by iteratively up dating θ i . Rules for up dating θ i usually dep ends on (sub)gradients of Ψ i or, in sto chastic metho ds, on the ones computed on batches of data from D i,T . Consider for simplicit y the particular case in which a batc h consisting of only one da- tum is used at each iteration. Most of the curren t state-of-art algorithms usable in this set-up, starting from the classical SGD [Bottou, 2010] to Adagrad [Duchi et al., 2011], Adadelta [Zeiler, 2012] and Adam [Kingma and Ba, 2014], can b e implicitly written as algorithms in which θ i is up dated by computing θ h +1 i = U i ( θ h i ; x h i , y h i ) , for h = 1 , . . . , m i , (2) where θ 0 i is some initial condition and U i ( θ h i ; x h i , y h i ) denotes the implicit up date rule giv en the current estimate of the parameter θ h i and the data ( x h i , y h i ) ∈ D i,T c hosen at iteration h . W e leav e the up date rule implicit, since, dep ending on the architecture of its own classifier, the av ailable computational p ow er and other factors, each agen t can choose the more appro- priate wa y to p erform a training step on the curren t data. As an example, in the classical SGD, the update rule reads θ h +1 i = θ h i − α h ∇ Φ i ( f i ( θ h i ; x h i ) , y h i ) where α h is a stepsize and ∇ denotes the gradient op erator. In order to approach a stationary p oint of problem (1), the pro cedure in (2) t ypically needs to b e rep eated m ultiple times, i.e. , one needs to iterate o ver the set D i,T m ultiple times. W e call (2) an ep o ch of the training pro cedure. Moreov er, we denote by ST i,e ( ˆ θ i ) the v alue of θ i obtained after a self-training phase started from ˆ θ i and carried out for e ep o chs. W e assume that the lo cally av ailable data at each node are relatively few, so that the p erformance that can b e reached on the test set D test b y solving (1) are intrinsically low er than the ones that can b e reached by training on a larger and more representativ e dataset. 6 4.2 Collectiv e training This is the main phase of collectiv e learning. It resembles the typical human co op erative b eha vior that is at the heart of collective intelligence. Algorithmically sp eaking, this phase exploits the communication among the agents in the netw ork and uses the shared (unlab eled) data D s . 4.2.1 Learning from shared data In order to learn from shared (unlabeled) data, agents are ask ed to pro duce at each iteration pro xy-lab els for eac h point in D s . In general, at eac h iteration, a batch from the set D s is dra wn and processed. T o fix the ideas, consider the case in which,, at each iteration k , a single sample x k s is dra wn from the set D s . Eac h no de pro duces a prediction z k i for the sample x k s , by computing z k i = f i ( θ k i ; x k s ), and broadcasts it to its out-neighbors j ∈ N k i,out . With the receiv ed predictions, each no de i pro duces a pro xy-lab el ˆ y k s,i (whic h w e call lo c al c ol le ctive lab el ) for the data x k s , b y conv erting the weigh ted a verage of its o wn predictions and the ones of its in-neighbors in to a lab el. Finally , it uses ˆ y k s,i as the lab el associated to x k s to up date θ k i . Summarizing, for all k = 1 , 2 , . . . , each no de i draws x k s from D s and then it computes z k i = f i ( θ k i ; x k s ) (3) ˆ y k s,i = lbl X j ∈N k i,in w k ij z k j (4) θ k +1 i = U i ( θ k i ; x k s , ˆ y k s,i ) (5) where we denoted by lbl [ · ] the op erator conv erting its argument into a lab el. F or example, in a binary classification problem the lbl op erator could b e a simple thresholding one, i.e. , lbl [ x ] = 0 if x < 0 . 5 and lbl [ x ] = 1 if x ≥ 0 . 5. Note that the lab eling pro cedure adopted in this phase highly resembles the human b eha vior. When unlab eled data are seen, their lab els are guessed by resorting to the opinion of neighboring agents. 4.2.2 W eigh ts computation Let us no w elaborate on the c hoice of the weigh ts w k ij . Clearly , they must account for the exp ertise and quality of prediction of eac h agen t with respect to the others. In particular, w e use as p erformance index the ac cur acy computed on the lo cal v alidation sets D i,V . Let us call a k i the accuracy obtained at iteration t by agent i , and, in order to p ossibly accentuate the differences b etw een the no des, let us define ˜ a k i = exp( γ a k i ) (6) with γ ≥ 0. Then, the weigh ts of the weigh ted adjacency matrix W k are computed as w k ij = ( ˜ a k j d k i , if j ∈ N k i,in , 0 , otherwise , (7) 7 where d k i = P m ∈N k i,in ˜ a k m . By doing so, w e guarantee that P N j =1 w k ij = 1 and w eights are assigned prop ortionally to the p erformance of each neighboring agent. Moreo ver, agents are capable to locally compute the w eights to assign to their neigh b ors, since only lo cally a v ailable information is required. The v alue of ˜ a k i ma y not b e computed at every iteration k . In fact, it is v ery unlikely that it changes to o m uch from one iteration to another. Thus, w e let agents up date their lo cal p erformance indexes every T i,E > 0 iterations. In the iterations in which the scores are not up dated, they are assumed to b e the same as in the previous iteration. Notice that one can think to different rules for the computation of the w eights in the adjacency matrix. F or example one can use the F1 score or some other metric in place of the accuracy or assign weigh ts with a different criterion. As a guideline, how ever, we p oin t out that the weigh ts should alwa ys dep end on p erformance of the agents on some (p ossibly common) task. Moreov er, the lo cal v alidation sets should b e sufficiently equally informative in order to ev aluate agents on an fairly equally difficult task. F or example, when a v ailable, a common v alidation set could b e used. 4.2.3 Review step By taking again inspiration from the human b ehavior, the collective training phase also includes a review step which is to be performed occasionally b y each no de (sa y ev ery T i,R > 0 iterations for each i ). Similarly to humans that o ccasionally review what they hav e already learned from reliable sources ( e.g. , b o oks, articles,. . . ), agents in the netw ork will review the data in the lo cal set D i,T (whic h are correctly lab eled). F ormally , every T i,R iterations, no de i p erforms a training ep o c h on the lo cal data set D i , i.e. , it mo difies step (5) as ˆ θ k +1 i = U i ( θ k i ; x k s , ˆ y k s,i ) (8) θ k +1 i = ST i, 1 ( ˆ θ k +1 i ) . (9) As it will b e shown next, the frequency of the review step plays a crucial role in the learning pro cedure. A too high frequency tends to produce a sort of ov erfitting b ehavior, while too lo w one makes agent for get their reliable data. 4.3 Remarks Before pro ceeding with the exp erimental results, a couple of remarks should b e done. The framew ork prese n ted so far is quite general and can b e easily implemented o ver net works consisting of v arious heterogeneous systems. In fact, each agen t is allow ed to use a custom structure for the lo cal function f i . This accounts for, e.g. , differen t systems with different computational capabilities. More p ow erful units can use more complex mo dels, while those with low er p otential will use simpler ones. Clearly , there will b e units that will intrinsically p erform better with respect to the others, but, at the same time agents starting with lo w p erformance ( e.g. , due to low representativ e lo cal lab eled datasets) will even tually reach higher p erformance by collab orating with more accurate units. Finally , CL is intrinsically priv acy-preserving since each agent shares with its neighbors only predictions on shared data. Thus, it is not p ossible to infer an ything ab out the in ternal architecture or priv ate data of each no de, since they are never exp osed. 8 5 Exp erimen tal results Consider an image classification problem in which each agent has a certain n umber of priv ate lab eled images and a huge amount of unlab eled ones is av ailable from some common source (for example the internet). In this setup, we select the F ashion-MNIST dataset [Xiao et al., 2017] to p erform an extensive n umerical analysis, and CL is implemented in Python by com bining T ensorFlow [Abadi et al., 2016] with the distributed optimization features pro- vided b y DISR OPT [F arina et al., 2020]. The F ashion-MNIST dataset, consists of 70 , 000 28x28 greyscale images of clothes. Each image is asso ciated with a lab el from 1 to 10, which corresp onds to the type of clothes depicted in the image. The dataset is divided in a training set D with 60 , 000 samples and a test set D test with 10 , 000 samples. Next, we first consider a simple communication net work and p erform a Montecarlo anal- ysis to show the influence of some of the algorithmic and problem-dep endent parameters in volv ed in CL. Then, we compare CL with other non-distributed metho ds and, finally , an example with a bigger and time-v arying netw ork is provided. The accuracy computed on D test is pick ed as p erformance metric and the samples in D are used to build the lo cal sets D i and the shared set D s in CL. 5.1 Mon tecarlo analysis Consider a simple scenario in which 4 agents co op erates ov er a fixed netw ork (represen ted as a complete graph, depicted in Figure 3) to learn to correctly classify clothes’ images. T o mimic heterogeneous agents, the lo cal learning functions f i of the 4 agen ts are as follows. 1. f 1 is represented as conv olutional neural netw orks (CNN) consisting of (i) a conv olu- tional la yer with 32 filters, kernel size of 3x3 and ReLU activ ation combined with a maxp o ol la y er with po ol size of 2x2; (ii) a conv olutional la y er with 64 filters, kernel size of 3x3 and ReLU activ ation combined with a maxp o ol lay er with p o ol size of 2x2; (iii) a conv olutional lay er with 32 filters, kernel size of 3x3, ReLU activ ation and flattened output; (iv) a dense lay er with 64 units and ReLU activ ation; (v) an output lay er with 10 output units and softmax activ ation. 2. f 2 is represen ted as a neural netw ork with 2 hidden la yers (HL2) consisting of 500 and 300 units resp ectively , with ReLU activ ation, and an output lay er with 10 output units and softmax activ ation. 3. f 3 is represen ted as a neural net work with 1 hidden lay er (HL1) of 300 units, with ReLU activ ation, and an output lay er with 10 output units and softmax activ ation. 4. f 4 is a shallow net work (SHL) with 10 output units with softmax activ ation. Next, the role of the algorithmic and problem-dep endent parameters in volv ed in CL is studied. In particular, w e study the p erformance of the algorithm in terms of the accuracy on the test set b y v arying: (i) the size of the local training sets, (ii) the review step frequency , and (iii) the parameter γ in the w eights’ computation. In all the next sim ulations, w e use |D i,V | = 100 with the samples comp osing such set randomly pic ked at eac h run from the set D . Moreov er, we use the Adam up date rule in (2) and (5), and a batch size equal to 10 b oth in the self-training and in the collective training phases. 9 1 2 3 4 Figure 3: Communication netw ork. 5.1.1 Influence of the lo cal training set size The num b er of priv ate lab eled samples lo cally av ailable at each agent is clearly exp ected to pla y a crucial role in the performance ac hieved b y eac h agen t. In order to show this, w e consider |D i,T | ∈ { 100 , 300 , 500 , 2000 } . F or each v alue we p erform a Mon tecarlo simulation consisting of 20 runs. In eac h run, we randomly pic k the samples in each D i,T from D (along with those in each D i,V ). The remaining samples of D are then unlab eled and put in the set D s . Then, the algorithm is ran for 3 ep o c hs ov er D s with the weigh ts computation and the review step p erformed every T i,E = 100 and T i,R = 300 iterations resp ectively and γ = 100 in (6). The results are depicted in Figure 4, and tw o things stand out. First, a higher n umber of priv ate lab eled samples leads to an higher accuracy on the test set D test . Second, as the num b er of lo cal samples increases, the v ariance of the p erformance tends to decrease. Moreo ver, it can b e seen that all the netw ork architectures reach almost the same accuracy for |D i,T | ∈ { 100 , 300 } , while for |D i,T | ∈ { 1000 , 2000 } , the shallow netw ork is ov ercome by the other three. Agent 1 CNN Agent 2 HL2 Agent 3 HL1 Agent 4 SHL 0 . 6 0 . 7 0 . 8 0 . 9 1 Accuracy ov er D test |D i,T | =100 |D i,T | =300 |D i,T | =1000 |D i,T | =2000 0 . 6 0 . 7 0 . 8 0 . 9 1 Accuracy ov er D test 0 . 6 0 . 7 0 . 8 0 . 9 1 Accuracy ov er D test 0 0 . 5 1 1 . 5 2 2 . 5 3 0 . 6 0 . 7 0 . 8 0 . 9 1 Epo chs over D s Accuracy ov er D test 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs over D s 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs over D s 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs over D s Figure 4: Influence of the lo cal training set size: evolution of the accuracy o ver D test along the algorithm evolution for the 4 agents, for D i,T ∈ { 100 , 300 , 1000 , 2000 } . The solid line represen ts the av erage accuracy ov er 20 simulations, while the shaded region denotes the a verage + / − tw o times the the standard deviation. 10 5.1.2 Influence of the review step frequency Also the frequency with which the review step is p erformed (which is inv ersely prop ortional to the magnitude of T i,R ) influences the p erformance of the agen ts. In fact, as h umans need to review things from time to time (but not to rarely), also here a to o high v alue for T i,R leads to a p erformance decay . W e p erform a Montecarlo simulation for T i,R ∈ { 50 , 200 , 2000 , 5000 } . F or each v alue we run 20 instances of the algorithm in whic h we build eac h set D i,T with 300 random samples from D (along with those in each D i,V ). The remaining samples of D are then unlab eled and put in the set D s . Then, the algorithm is ran for 3 ep o chs ov er D s with |D i,T | = 1000 for all i and the weigh ts computation p erformed ev ery T i,E = 100 with γ = 100 in (6). The results are reported in Figure 5. A higher time in terv al betw een t wo review steps, produce a higher v ariance and also leads to a lo wer accuracy . This is due to the fact that if the review step is p erformed to o rarely , agen ts tends to forget their knowledge on lab eled data and start to learn from wrongly labeled samples. Then, when the review o ccurs they seems to increase again their accuracy . On the con trary , a to o high frequency of review step pro duces a sligh tly o verfitting b ehavior o ver the priv ate lab eled data. This can b e appreciated by comparing in Figure 5 the cases for T i,R = 50 and T i,R = 200. It can b e seen that the accuracy on the test set for T i,R = 200 is higher with resp ect to the one for T i,R = 50. A more ov erfitting b ehavior can b e seen by further reducing T i,R . Agent 1 CNN Agent 2 HL2 Agent 3 HL1 Agent 4 SHL 0 . 6 0 . 7 0 . 8 0 . 9 1 Accuracy ov er D test T i,R =50 T i,R =200 T i,R =2000 T i,R =5000 0 . 6 0 . 7 0 . 8 0 . 9 1 Accuracy ov er D test 0 . 6 0 . 7 0 . 8 0 . 9 1 Accuracy ov er D test 0 0 . 5 1 1 . 5 2 2 . 5 3 0 . 6 0 . 7 0 . 8 0 . 9 1 Epo chs over D s Accuracy ov er D test 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs over D s 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs over D s 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs over D s Figure 5: Influence of the review step frequency: ev olution of the accuracy computed ov er D test along the collective training phase for the 4 agents, for T i,R ∈ { 50 , 200 , 2000 , 5000 } . The solid line represents the av erage accuracy ov er 20 simulations, while the shaded region denotes the av erage + / − t wo times the the standard deviation. 5.1.3 Influence of γ The last parameter w e study is γ in (6). A small v alue of γ means that small differences in the lo cal p erformances results in small differences in the weigh ts. On the contrary , a 11 high v alue pro duce a weigh t near to 1 for the b est agen t in the neighborho o d. In the extreme case when γ = 0 all agents hav e in the neighborho o d are assigned the same weigh t, indep enden tly of their p erformance. In Figure 6 the results for a Montecarlo simulation for γ ∈ { 0 , 1 , 10 , 100 , 1000 } are rep orted, where we use |D i,T | = 500, T i,R = 500 and T i,E = 100. In this setup, the b est accuracy is obtained with γ ∈ { 1 , 10 , 100 } with a slightly higher standard deviation for γ = 100. When γ = 0 ( i.e. , when employing a uniform weighing), the accuracies tend to reach a satisfactory v alue and, then, start to decrease. This is probably due to the fact that all agents has the same imp ortance and hence, in this case, all of them seems to obtain the p erformance of the w orst of them. Finally , when γ = 1000 there is a substan tial p erformance degradation. This should b e caused by the fact that, in the first iterations, there is an agent which is slightly b etter than the others and leads all the others to wards its (wrong) solution. It is worth mentioning that the influence of γ on the p erformance may v ary , dep ending on the considered setup. F or example, if w e consider D i,T = 300 for all i , the results are depicted in Figure 7. A c hoice of γ in the range [1 , 100] seems to still w ork well, while for γ = 1000 a steady state is reached. Moreo ver, for bigger generic comm unication graphs a c hoice of γ to o small may not w ork at all, due to, e.g. , having a lot of intrinsically lo w- p erforman t neighbors whose weigh t in the creation of the proxy lab el tends to pro duce a lot of wrong lab els. Agent 1 CNN Agent 2 HL2 Agent 3 HL1 Agent 4 SHL 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 Accuracy ov er D test γ =0 γ =1 γ =10 γ =100 γ =1000 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 Accuracy ov er D test 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 Accuracy ov er D test 0 0 . 5 1 1 . 5 2 2 . 5 3 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 Epo chs ov er D s Accuracy ov er D test 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs ov er D s 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs ov er D s 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs ov er D s 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs ov er D s Figure 6: Influence of γ (for |D i,T | = 500): ev olution of the accuracy computed o ver D test along the collective training phase for the 4 agen ts, for γ ∈ { 0 , 1 , 10 , 100 , 1000 } . The solid line represents the a verage accuracy o ver 20 sim ulations, while the shaded region denotes the av erage + / − tw o times the the standard deviation. 12 Agent 1 CNN Agent 2 HL2 Agent 3 HL1 Agent 4 SHL 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 Accuracy ov er D test γ =0 γ =1 γ =10 γ =100 γ =1000 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 Accuracy ov er D test 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 Accuracy ov er D test 0 0 . 5 1 1 . 5 2 2 . 5 3 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 Epo chs ov er D s Accuracy ov er D test 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs ov er D s 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs ov er D s 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs ov er D s 0 0 . 5 1 1 . 5 2 2 . 5 3 Epo chs ov er D s Figure 7: Influence of γ (for |D i,T | = 300): ev olution of the accuracy computed o ver D test along the collective training phase for the 4 agen ts, for γ ∈ { 0 , 1 , 10 , 100 , 1000 } . The solid line represents the a verage accuracy o ver 20 sim ulations, while the shaded region denotes the av erage + / − tw o times the the standard deviation. 5.2 Comparison with non-co op erativ e metho ds In this section we compare the results obtained by CL in the presen ted setup when |D i,T | = 500, γ = 100, T i,E = 100 and T i,R = 300 for all i with those obtained b y using other (non-co op erative) metho ds. In particular, we consider the following tw o approac hes. (ST) Indep endently train each learning function ov er a dataset with the same size of the lo cal priv ate training dataset used in CL, i.e. , with 500 samples. (FS) Assume that the entire training dataset of F ashion-MNIST is a v ailable, and indep en- den tly train each learning function ov er the entire dataset D . These approac hes gives t wo b enchmarks. On one side, the p erformance obtained b y the four learning function with ST coincides with those that can b e ac hieved by the agents by p erforming the self-training phase only and without coop erating. On the other side, the p er- formance obtained with FS, i.e. , in a fully sup ervised case, represents the b est p erformance that can b e achiev ed by the selected learning arc hitectures. In order for CL to b e worth for the agents it should lead to b etter performance with respect to ST and approac h as m uch as p ossible those obtained by FS. T o compare CL, ST and FS we p erform a Mon tecarlo simulation consisting of 100 runs of each of the three approac hes. In each run, the sets D i and D s for CL hav e b een created randomly as in the previous sections, and CL is run for 3 ep o chs o ver D s . Similarly , the 500 samples for training eac h function of ST are randomly dra wn from D at each run. The 13 three approaches are compared in terms of the obtained accuracy on the test set D test and the results are rep orted in T able 1. CL ST FS Arc hitecture/agent Mean Std Mean Std Mean Std CNN 0.8149 0.0060 0.7663 0.0127 0.9021 0.0043 HL2 0.8144 0.0051 0.7670 0.0171 0.8476 0.0058 HL1 0.8153 0.0049 0.7728 0.0112 0.8465 0.0062 SHL 0.8065 0.0050 0.7498 0.0077 0.8406 0.0028 T able 1: Comparison with non-co op erative metho ds: mean and standard deviation of the accuracy on the test set for CL, ST and FS. It can b e seen that CL reac hes an higher accuracy (with a lo wer standard deviation) with resp ect to ST, th us confirming the b enefits obtained through co op eration. The target p erformance of FS, how ever are not reac hed. On this regard we w ant to point out that the comparison with FS is a bit unfair, since the amoun t of usable information (in terms of lab eled samples) is extremely different. How ever, it can b e shown that with an higher n umber of samples in D i,T an accuracy near to FS can b e reached. F or example, from Figure 4, it is clear that with D i,T = 2000, the learning functions HL2 and HL1 already matc hes (via CL) the accuracy of FS. 5.3 Example with a larger, time-v arying comm unication net work In this section w e p erform an exp eriment with a larger netw ork consisting of 30 agen ts. Eac h agen t is equipp ed with a learning function randomly chosen from those in tro duced in the previous section (CNN, HL2, HL1, SHL). In particular, there are 5 CNNs, 8 HL2s, 11 HL1s and 6 SHLs. Agents in the net work communicate across a time-v arying (random) graph that c hanges every 10 iterations. Each graph is generated according to an Erd˝ os-R` enyi random mo del with connectivity parameter p = 0 . 1 (see Figure 8 for an illustrative example). Each agen t is equipp ed with |D i,T | = 300 training samples randomly pick ed from the F ashion- MNIST training set. Moreov er, w e select T i,R = 200, T i,E = 100 and γ = 10. W e run a sim ulation in this setup for 3 ep o chs o ver the shared set D s and the results at the end of the simulation are rep orted in Figure 9 in terms of the accuracy on the test set D test . It can b e seen that all the agen ts reac h an accuracy betw een 0 . 8 and 0 . 86. Moreo ver, in the last iterations, some of them also outp erform the target accuracy of FS obtained in the previous section (for HL2, HL1 and SHL). Agents equipp ed with the CNN, on the other side seems to b e unable to reach the accuracy of FS in this setup. 6 Conclusions In this pap er we presented the collective learning framework to deal with s emi-sup ervised learning problems in a distributed set-up. The prop osed algorithm allows heterogeneous in terconnected agen ts to coop erate for the purp ose of collectiv ely training their lo cal learning functions. The algorithmic idea dra ws inspiration from the notion of collective in telligence and the related human b ehavior. The obtained exp erimental results sho w the p otential of 14 CNNs HL2s HL1s SHLs Figure 8: Example with a larger, time-v arying communication netw ork: graph example. 2 . 8 2 . 85 2 . 9 2 . 95 3 0 . 78 0 . 8 0 . 82 0 . 84 0 . 86 0 . 88 Epochs on D s Accuracy on D test Agents with CNN 2 . 8 2 . 85 2 . 9 2 . 95 3 Epochs on D s Agents with HL2 2 . 8 2 . 85 2 . 9 2 . 95 3 Epochs on D s Agents with HL1 2 . 8 2 . 85 2 . 9 2 . 95 3 Epochs on D s Agents with SHL Figure 9: Example with a larger, time-v arying comm unication netw ork: evolution of the accuracy obtained b y the v arious agents ov er D test (in the last part of the third ep o ch). Eac h subplot groups together agen ts equipp ed with the same learning function. the proposed sc heme and call for a thorough theoretical analysis of the collective learning framew ork. References Mart ´ ın Abadi, P aul Barham, Jianmin Chen, Zhifeng Chen, Andy Da vis, Jeffrey Dean, Matthieu Devin, Sanjay Ghema wat, Geoffrey Irving, Michael Isard, et al. T ensorflow: A system for large-scale mac hine learning. In 12th { USENIX } Symp osium on Op er ating Systems Design and Implementation ( { OSDI } 16) , pages 265–283, 2016. 15 Y oshua Bengio. Deep learning of representations for unsupervised and transfer learning. In Pr o c e e dings of ICML Workshop on Unsup ervise d and T r ansfer L e arning , pages 17–36, 2012. P ascal Bianchi and J´ er´ emie Jakub owicz. Conv ergence of a multi-agen t pro jected sto c has- tic gradient algorithm for non-conv ex optimization. IEEE T r ansactions on Automatic Contr ol , 58(2):391–405, 2013. Avrim Blum and T om Mitc hell. Com bining labeled and unlab eled data with co-training. In Pr o c e e dings of the eleventh annual c onfer enc e on Computational le arning the ory , pages 92–100. ACM, 1998. L ´ eon Bottou. Large-scale machine learning with sto chastic gradient descent. In Pr o c e e dings of COMPST A T’2010 , pages 177–186. Springer, 2010. Stephen Boyd, Arpita Ghosh, Bala ji Prabhak ar, and Dev avrat Shah. Randomized gossip algorithms. IEEE/ACM T r ansactions on Networking (TON) , 14(SI):2508–2530, 2006. F rancesco Bullo, Jorge Cortes, and Sonia Martinez. Distribute d c ontr ol of r ob otic networks: a mathematic al appr o ach to motion c o or dination algorithms , volume 27. Princeton Uni- v ersity Press, 2009. Jianmin Chen, Xinghao Pan, Ra jat Monga, Samy Bengio, and Rafal Jozefowicz. Revisiting distributed synchronous sgd. arXiv pr eprint arXiv:1604.00981 , 2016. Minmin Chen, Kilian Q W einberger, and John Blitzer. Co-training for domain adaptation. In A dvanc es in neur al information pr o c essing systems , pages 2456–2464, 2011. Tianqi Chen, Mu Li, Y utian Li, Min Lin, Naiyan W ang, Minjie W ang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv pr eprint arXiv:1512.01274 , 2015. Jeffrey Dean, Greg Corrado, Ra jat Monga, Kai Chen, Matthieu Devin, Mark Mao, Andrew Senior, Paul T uc ker, Ke Y ang, Quoc V Le, et al. Large scale distributed deep net works. In A dvanc es in neur al information pr o c essing systems , pages 1223–1231, 2012. Li Deng and John C Platt. Ensemble deep learning for speech recognition. In Fifte enth Annual Confer enc e of the International Sp e e ch Communic ation Asso ciation , 2014. P aolo Di Lorenzo and Gesualdo Scutari. Next: In-netw ork nonconv ex optimization. IEEE T r ansactions on Signal and Information Pr o c essing over Networks , 2(2):120–136, 2016. Thomas G Dietterich. Ensemble metho ds in mac hine learning. In International workshop on multiple classifier systems , pages 1–15. Springer, 2000. John Duchi, Elad Hazan, and Y oram Singer. Adaptiv e subgradient metho ds for online learning and sto chastic optimization. Journal of Machine L e arning R ese ar ch , 12(Jul): 2121–2159, 2011. Douglas C Engelbart. Augmenting human intellect: A conceptual framework. Menlo Park, CA , 1962. 16 F rancesco F arina and Giusepp e Notarstefano. Randomized block proximal metho ds for distributed sto chastic big-data optimization. IEEE T r ansactions on Automatic Contr ol , 2020. doi: 10.1109/T AC.2020.3027647. F rancesco F arina, Andrea Garulli, Antonio Giannitrapani, and Giusepp e Notarstefano. A distributed asynchronous metho d of m ultipliers for constrained nonconv ex optimization. Au tomatic a , 103:243–253, 2019a. F rancesco F arina, Stefano Melacci, Andrea Garulli, and An tonio Giannitrapani. Asyn- c hronous distributed learning from constraints. IEEE tr ansactions on neur al networks and le arning systems , 31(10):4367–4373, 2019b. F rancesco F arina, Andrea Camisa, Andrea T esta, Iv ano Notarnicola, and Giusepp e Notarste- fano. Disropt: a python framework for distributed optimization. IF AC-Pap ersOnLine , 53 (2):2666–2671, 2020. F ederica Garin and Luca Schenato. A survey on distributed estimation and con trol appli- cations using linear consensus algorithms. In Networke d c ontr ol systems , pages 75–107. Springer, 2010. Bo Han, Quanming Y ao, Xingrui Y u, Gang Niu, Miao Xu, W eihua Hu, Ivor Tsang, and Masashi Sugiyama. Co-teaching: Robust training of deep neural netw orks with extremely noisy lab els. In A dvanc es in Neur al Information Pr o c essing Systems , pages 8527–8537, 2018. Geoffrey Hinton, Oriol Vin yals, and Jeff Dean. Distilling the knowledge in a neural netw ork. arXiv pr eprint arXiv:1503.02531 , 2015. Soumm ya Kar and Jos´ e MF Moura. Distributed consensus algorithms in sensor netw orks with imperfect communication: Link failures and c hannel noise. IEEE T r ansactions on Signal Pr o c essing , 57(1):355–369, 2009. Solmaz S Kia, Jorge Cort ´ es, and Sonia Martinez. Dynamic av erage consensus under lim- ited control authority and priv acy requiremen ts. International Journal of R obust and Nonline ar Contr ol , 25(13):1941–1966, 2015. Diederik P Kingma and Jimm y Ba. Adam: A metho d for sto chastic optimization. arXiv pr eprint arXiv:1412.6980 , 2014. Jakub Koneˇ cn` y, Brendan McMahan, and Daniel Ramage. F ederated optimization: Dis- tributed optimization b eyond the datacenter. arXiv pr eprint arXiv:1511.03575 , 2015. Jakub Koneˇ cn` y, H Brendan McMahan, F elix X Y u, Peter Rich t´ arik, Ananda Theertha Suresh, and Da ve Bacon. F ederated learning: Strategies for impro ving communication efficiency . arXiv pr eprint arXiv:1610.05492 , 2016. Tim Krask a, Ameet T alwalk ar, John C Duchi, Rean Griffith, Michael J F ranklin, and Mic hael I Jordan. Mlbase: A distributed mac hine-learning system. In Cidr , volume 1, pages 2–1, 2013. 17 Dong-Hyun Lee. Pseudo-lab el: The simple and efficient semi-supervised learning metho d for deep neural netw orks. In Workshop on Chal lenges in R epr esentation L e arning, ICML , v olume 3, page 2, 2013. Pierre L ´ evy and Rob ert Bononno. Col le ctive intel ligenc e: Mankind’s emer ging world in cyb ersp ac e . Perseus b o oks, 1997. Mu Li, Da vid G Andersen, Jun W o o Park, Alexander J Smola, Amr Ahmed, V anja Josi- fo vski, James Long, Eugene J Shekita, and Bor-Yiing Su. Scaling distributed machine learning with the parameter server. In 11th { USENIX } Symp osium on Op er ating Systems Design and Implementation ( { OSDI } 14) , pages 583–598, 2014. Bo Liu, W enlian Lu, and Tianping Chen. Consensus in net works of multiagen ts with switc h- ing top ologies mo deled as adapted sto c hastic processes. SIAM Journal on Contr ol and Optimization , 49(1):227–253, 2011. T ongliang Liu and Dacheng T ao. Classification with noisy labels by importance reweigh ting. IEEE T r ansactions on p attern analysis and machine intel ligenc e , 38(3):447–461, 2016. Y ucheng Low, Danny Bickson, Joseph Gonzalez, Carlos Guestrin, Aap o Kyrola, and Joseph M Hellerstein. Distributed graphlab: a framework for machine learning and data mining in the cloud. Pr o c e e dings of the VLDB Endowment , 5(8):716–727, 2012. Da vid McClosky , Eugene Charniak, and Mark Johnson. Effective self-training for parsing. In Pr o c e e dings of the main c onfer enc e on human language te chnolo gy c onfer enc e of the North Americ an Chapter of the Asso ciation of Computational Linguistics , pages 152–159. Asso ciation for Computational Linguistics, 2006. H Brendan McMahan, Eider Mo ore, Daniel Ramage, Seth Hampson, et al. Comm unication- efficien t learning of deep netw orks from decen tralized data. arXiv pr eprint arXiv:1602.05629 , 2016. Xiangrui Meng, Joseph Bradley , Burak Y avuz, Ev an Sparks, Shiv aram V enk ataraman, Da vies Liu, Jeremy F reeman, DB Tsai, Manish Amde, Sean Owen, et al. Mllib: Machine learning in apache spark. The Journal of Machine L e arning R ese ar ch , 17(1):1235–1241, 2016. Nagara jan Natara jan, Inderjit S Dhillon, Pradeep K Ravikumar, and Am buj T ewari. Learn- ing with noisy lab els. In A dvanc es in neur al information pr o c essing systems , pages 1196– 1204, 2013. A Nedic and A Ozdaglar. Distributed subgradien t metho ds for m ulti-agent optimization. IEEE T r ansactions on Automatic Contr ol , 54(1):48–61, 2009. Angelia Nedic, Asuman Ozdaglar, and Pablo A Parrilo. Constrained consensus and op- timization in m ulti-agent netw orks. IEEE T r ansactions on Automatic Contr ol , 55(4): 922–938, 2010. Kamal Nigam and Ra yid Ghani. Analyzing the effectiv eness and applicabilit y of co-training. In Cikm , volume 5, page 3, 2000. 18 Iv ano Notarnicola, Ying Sun, Gesualdo Scutari, and Giusepp e Notarstefano. Distributed big- data optimization via blo ck-iterativ e gradien t tracking. arXiv pr eprint arXiv:1808.07252 , 2018. Reza Olfati-Sab er, J Alex F ax, and Richard M Murra y . Consensus and co op eration in net work ed multi-agen t systems. Pr o c e e dings of the IEEE , 95(1):215–233, 2007. S Sundhar Ram, Angelia Nedi´ c, and V enugopal V V eerav alli. Distributed sto chastic subgra- dien t pro jection algorithms for con vex optimization. Journal of optimization the ory and applic ations , 147(3):516–545, 2010. An tti Rasmus, Mathias Berglund, Mikko Honk ala, Harri V alp ola, and T apani Raiko. Semi- sup ervised learning with ladder net works. In A dvanc es in neur al information pr o c essing systems , pages 3546–3554, 2015. Lior Rok ac h. Ensem ble-based classifiers. Artificial Intel ligenc e R eview , 33(1-2):1–39, 2010. Ch uck Rosenberg, Martial Heb ert, and Henry Schneiderman. Semi-sup ervised self-training of ob ject detection mo dels. In 2005 Seventh IEEE Workshops on Applic ations of Computer Vision (W ACV/MOT ION’05)-V olume 1 , volu me 1, pages 29–36. IEEE, 2005. Virginia Smith, Chao-Kai Chiang, Maziar Sanjabi, and Ameet S T alwalk ar. F ederated m ulti- task learning. In A dvanc es in Neur al Information Pr o c essing Systems , pages 4424–4434, 2017. T atiana T atarenko and Behrouz T ouri. Non-conv ex distributed optimization. IEEE T r ans- actions on Automatic Contr ol , 62(8):3744–3757, 2017. John Tsitsiklis, Dimitri Bertsek as, and Mic hael A thans. Distributed async hronous determin- istic and sto chastic gradient optimization algorithms. IEEE tr ansactions on automatic c ontr ol , 31(9):803–812, 1986. Kagan T umer and Joydeep Ghosh. Error correlation and error reduction in ense m ble clas- sifiers. Conne ction scienc e , 8(3-4):385–404, 1996. Haixun W ang, W ei F an, Philip S Y u, and Jiaw ei Han. Mining concept-drifting data streams using ensem ble classifiers. In Pr o c e e dings of the ninth A CM SIGKDD international c on- fer enc e on Know le dge disc overy and data mining , pages 226–235. AcM, 2003. Ermin W ei and Asuman Ozdaglar. Distributed alternating direction metho d of multipliers. In 2012 IEEE 51st IEEE Confer enc e on De cision and Contr ol (CDC) , pages 5445–5450. IEEE, 2012. Karl W eiss, T aghi M Khoshgoftaar, and DingDing W ang. A surv ey of transfer learning. Journal of Big data , 3(1):9, 2016. Kui W u and Kim-Hui Y ap. F uzzy svm for conten t-based image retriev al: a pseudo-lab el supp ort v ector machine framework. IEEE Computational Intel ligenc e Magazine , 1(2): 10–16, 2006. Han Xiao, Kashif Rasul, and Roland V ollgraf. F ashion-mnist: a no vel image dataset for b enc hmarking mac hine learning algorithms, 2017. 19 Matthew D Zeiler. Adadelta: an adaptive learning rate metho d. arXiv pr eprint arXiv:1212.5701 , 2012. Y an Zhou and Sally Goldman. Demo cratic co-learning. In 16th IEEE International Confer- enc e on T o ols with Artificial Intel ligenc e , pages 594–602. IEEE, 2004. Zhi-Hua Zhou and Ming Li. T ri-training: Exploiting unlab eled data using three classifiers. IEEE T r ansactions on Know le dge & Data Engine ering , (11):1529–1541, 2005. Mingh ui Zhu and Sonia Mart ´ ınez. On distributed conv ex optimization under inequality and equalit y constrain ts. IEEE T r ansactions on Automatic Contr ol , 57(1):151–164, 2012. 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment