집단 학습 프레임워크
본 논문은 분산 반지도 학습 환경에서 각 에이전트가 자체 라벨 데이터로 사전 학습한 뒤, 공유된 비라벨 데이터를 이용해 합의 기반 프록시 라벨을 생성·교환함으로써 전체 시스템의 성능을 향상시키는 ‘집단 학습(Collective Learning, CL)’ 방식을 제안한다. 이 과정은 자기‑학습 단계와 집단‑학습 단계로 구분되며, 이질적인 모델 구조와 계산 자원을 가진 에이전트들이 프라이버시를 유지하면서 협업할 수 있음을 실험을 통해 입증한다.
저자: Francesco Farina
본 논문은 분산 반지도 학습 환경에서 에이전트들이 서로 협력하여 학습 성능을 향상시키는 새로운 프레임워크인 집단 학습(Collective Learning, CL)을 제안한다. 서론에서는 인간의 협업·대립·지식 교환 과정을 모방해, 기계 학습에서도 유사한 두 단계(자기‑학습, 집단‑학습)를 적용할 수 있음을 강조한다. 관련 연구 섹션에서는 분산 최적화, 합의 프로토콜, 연합 학습, Co‑training, Self‑training 등 기존 접근법을 정리하고, 이들 대부분이 중앙 서버 의존 혹은 파라미터 공유에 초점을 맞추는 반면, CL은 예측값 기반 합의를 통해 파라미터를 비공개로 유지하면서 협업한다는 차별점을 제시한다.
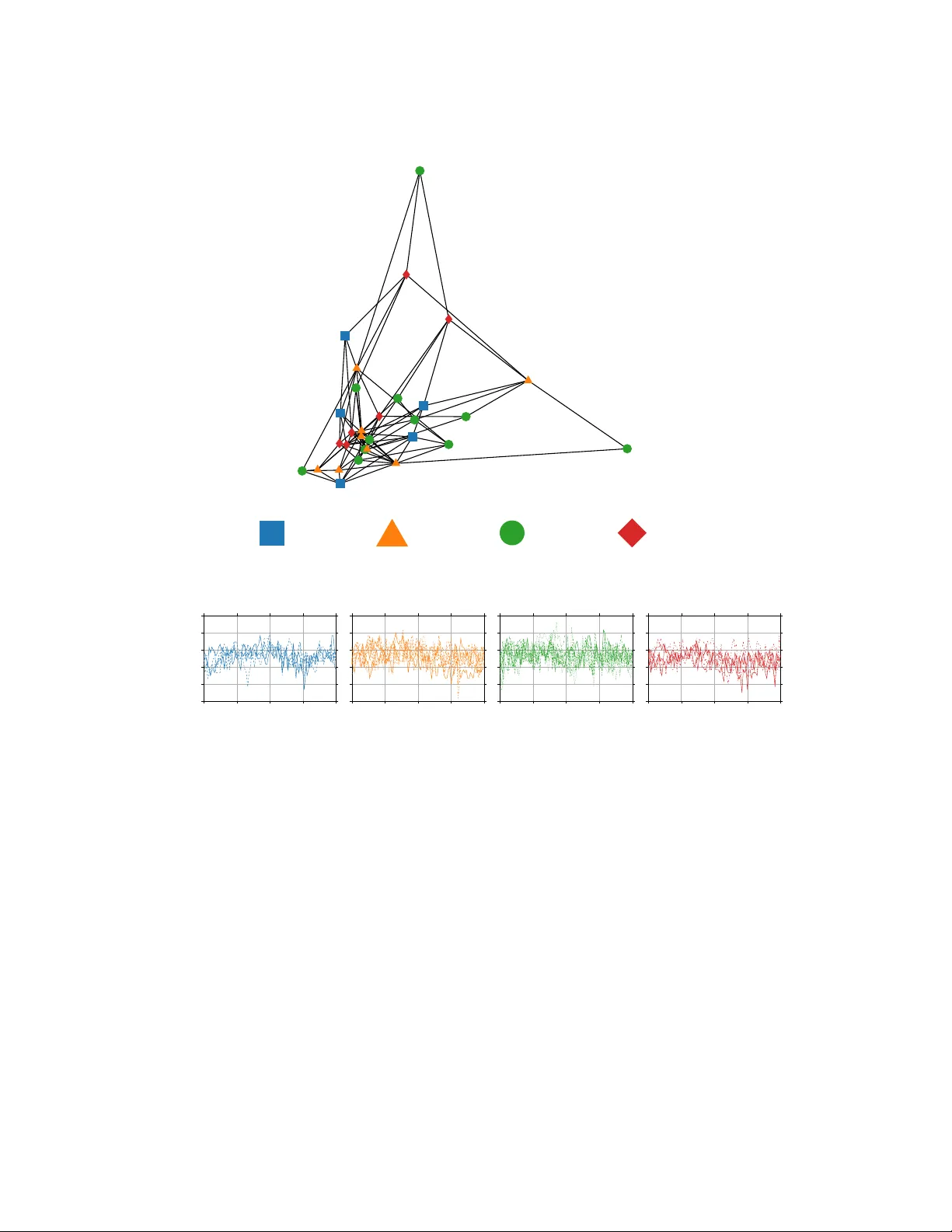
문제 설정에서는 N개의 에이전트가 시간 가변적인 방향성 그래프 Gₖ에 의해 연결된다고 가정한다. 각 에이전트 i는 d 차원의 입력 공간에 대해 자체 라벨이 부착된 데이터 Dᵢ (훈련 Dᵢ,ₜ와 검증 Dᵢ,ᵥ)와, 전체 에이전트가 공동으로 접근 가능한 비라벨 데이터 집합 Dₛ를 보유한다. 목표는 각 에이전트가 로컬 모델 fᵢ(θᵢ;·)를 학습해, 공유 테스트 세트 Dₜₑₛₜ에 대한 정확도를 최대화하는 것이다. 모델 구조와 파라미터 차원 nᵢ는 에이전트마다 다를 수 있어, 이질적인 시스템을 자연스럽게 포괄한다.
알고리즘은 두 단계로 구성된다. 1) 자기‑학습 단계에서는 각 에이전트가 자신의 라벨 데이터 Dᵢ,ₜ만을 이용해 손실 Ψᵢ(θᵢ)=∑_{(x,y)∈Dᵢ,ₜ}Φᵢ(fᵢ(θᵢ;x),y)를 최소화한다. 업데이트 규칙 Uᵢ는 SGD, Adam 등 기존 최적화 기법을 그대로 적용할 수 있다. 이 단계는 통신이 필요 없으며, 로컬 데이터가 제한적이므로 얻어지는 성능은 제한적이다.
2) 집단‑학습 단계에서는 공유 비라벨 데이터 Dₛ에서 하나씩 샘플 xₖˢ를 추출한다. 각 에이전트 i는 현재 파라미터 θₖᵢ를 사용해 예측값 zₖᵢ=fᵢ(θₖᵢ;xₖˢ)를 계산하고, 이를 자신의 출력 이웃에게 전송한다. 수신된 예측값들을 가중 평균 ∑_{j∈Nₖᵢ,인} wₖᵢⱼ zₖⱼ 로 결합하고, 라벨 변환 연산자 lbl
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기