A Limited-Capacity Minimax Theorem for Non-Convex Games or: How I Learned to Stop Worrying about Mixed-Nash and Love Neural Nets
Adversarial training, a special case of multi-objective optimization, is an increasingly prevalent machine learning technique: some of its most notable applications include GAN-based generative modeling and self-play techniques in reinforcement learn…
Authors: Gauthier Gidel, David Balduzzi, Wojciech Marian Czarnecki
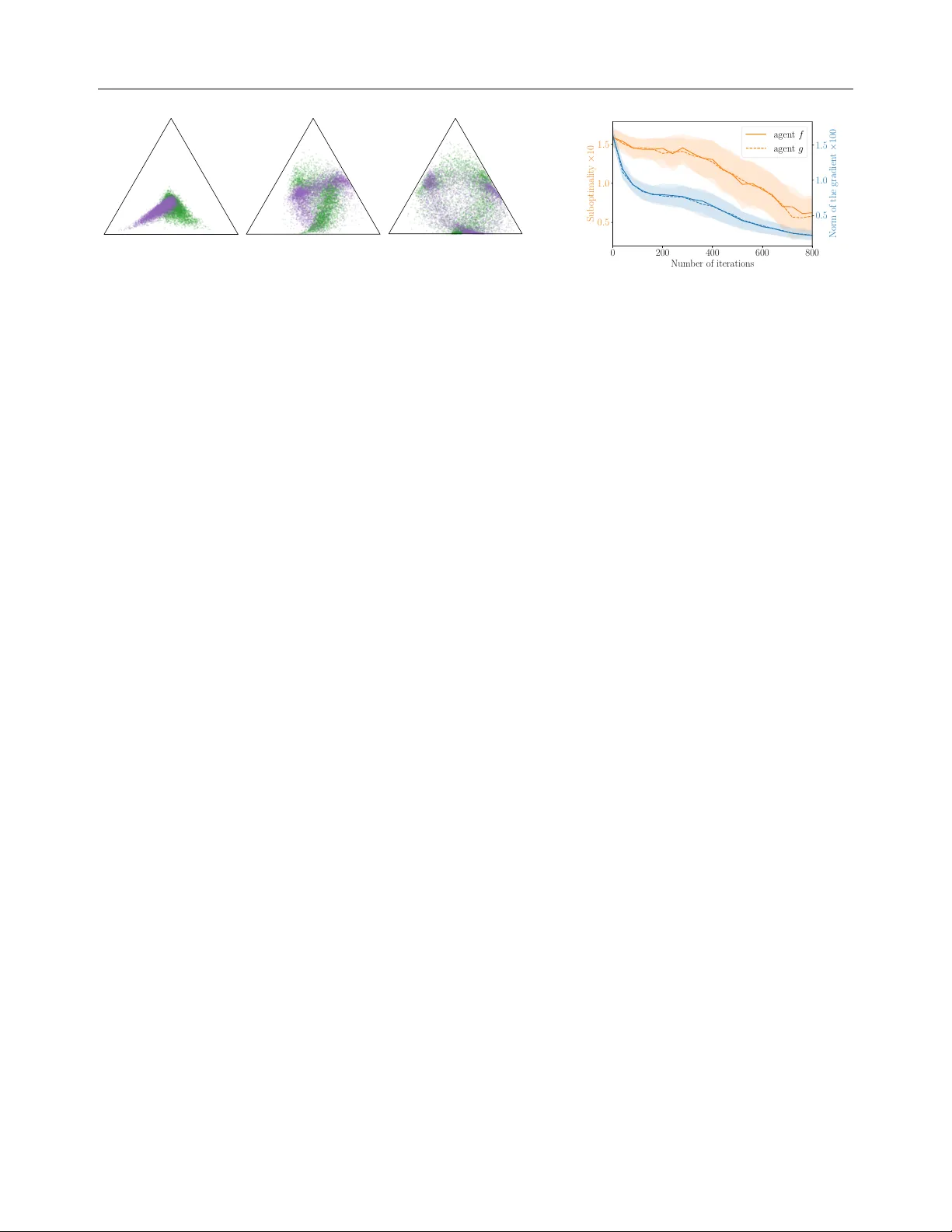
A Limited-Capacit y Minimax Theorem for Non-Con v ex Games or: Ho w I Learned to Stop W orrying ab out Mixed-Nash and Lo ve Neural Nets Gauthier Gidel † , ♠ Da vid Balduzzi ♠ Mila, Univ ersité de Montréal XTX Mark ets W o jciech Marian Czarnec ki Marta Garnelo Y oram Bachrac h DeepMind DeepMind DeepMind Abstract A dversarial training, a sp ecial case of multi- ob jectiv e optimization, is an increasingly prev alen t machine learning technique: some of its most notable applications include GAN- based generative mo deling and self-play tec h- niques in reinforcement learning which hav e b een applied to complex games such as Go or P oker. In practice, a single pair of netw orks is t ypically trained to find an approximate equilibrium of a highly nonconca ve-noncon v ex adv ersarial problem. Ho w ever, while a classic result in game theory states such an equilib- rium exists in conca v e-conv ex games, there is no analogous guarantee if the pay off is nonconca ve-noncon vex. Our main con tribu- tion is to provide an appro ximate minimax theorem for a large class of games where the play ers pic k neural netw orks including W GAN, StarCraft I I and Blotto Game. Our findings rely on the fact that despite b eing nonconca ve-noncon vex with respect to the neural netw orks parameters, these games are conca ve-con vex with respect to the actual mo dels (e.g., functions or distributions) rep- resen ted by these neural netw orks. 1 INTR ODUCTION Real-w orld games hav e b een used as b enc hmarks in ar- tificial in telligence for decades [ Samuel , 1959 , T esauro , 1995 ], with recent progress on increasingly complex † Canada CIF AR AI Chair. ♠ W ork done at DeepMind. Corresp ondence: gauthier.gidel@mila.quebec Pro ceedings of the 24 th In ternational Conference on Artifi- cial Intelligence and Statistics (AIST A TS) 2021, San Diego, California, USA. PMLR: V olume 130. Cop yright 2021 b y the author(s). domains suc h as p oker [ Bro wn and Sandholm , 2017 , 2019 ], chess, Go [ Silver et al. , 2017 ], and StarCraft I I [ Vin yals et al. , 2019 ]. Sim ultaneously , remark able adv ances in generative mo deling of images [ W u et al. , 2019 ] and sp eech syn thesis [ Bińko wski et al. , 2020 ] hav e resulted from tw o-play er games explicitly designed to facilitate via carefully constructed arms races [ Goo d- fello w et al. , 2014 ]. T wo-pla yer zero-sum games also pla y a fundamental role in building classifiers that are robust to adv ersarial attacks [ Madry et al. , 2017 ]. The goal of the pap er is to put learning—by neural nets—in tw o-play er zero-sum games on a firm theoret- ical foundation to answ er the question: What do es it me an to solve a game with neur al nets? In single-ob jectiv e optimization, p erformance is well- defined via a fixed ob jective. How ev er, it is not obvious what counts as “optimal" in a tw o-play er zero-sum nonconca ve-noncon vex setting. Since eac h pla yer’s goal is to maximize its pay off, it is natural to ask whether a play er can maximize its utility indep endently of how the other play er b ehav es. v on Neumann et al. [ 1944 ] laid the foundation of game theory with the Minimax theorem, which provides a meaningful notion of op- timal b ehavior against an unkno wn adversary . F or a tw o-pla yer zero-sum game, suc h a solution concept incorp orates t wo notions: (i) a value V , (ii) a str at- e gy for e ach player such that their av erage gain is at least V (resp. - V ) no matter what the other do es. The existence of suc h a v alue and optimal strategies in conca ve-con v ex games is guaran teed in Sion et al. [ 1958 ], an extension of v on Neumann’s result. F rom a game-theoretic p ersp ective, minimax may not exist in nonconcav e-nonconv ex (NC-NC) games. Never- theless, mac hine learning (ML) practitioners typically train a single pair of neural netw orks to solv e min θ ∈ Θ max w ∈ Ω ϕ ( w , θ ) where ϕ ( ⋅ , ⋅ ) is NC-NC . (1) Previous w ork [ Arora et al. , 2017 , Hsieh et al. , 2019 , Domingo-Enrich et al. , 2020 ] coped with this A Limited-Capacity Minimax Theorem for Noncon v ex-Nonconcav e Games nonconca ve-noncon vexit y issue by transforming Eq. 1 in to a bilinear minimax problem ov er the Borel distri- butions on Θ and Ω (a.k.a. lifting trick), min µ ∈ P ( Θ ) max ν ∈ P ( Ω ) µ, Aν ∶ = E θ ∼ µ w ∼ ν [ ϕ ( w , θ )] (2) Ho wev er, working on the space of distributions (a.k.a, mixed strategies) ov er the weigh ts of a neural netw ork is not practical and do es not exactly corresp ond to the initial problem ( 1 ) . That is why we do not conside r ( 2 ) and fo cus instead on minimax theorems for ( 1 ). Our main con tribution is Theorem 1 , an approximate limited-capacit y minimax theorem for NC-NC games. This result con trasts with the negative result of Jin et al. [ 2019 ] who construct a NC-NC game where pure global minimax do es not exist. The insights provided b y our main theorem are three-fold; first, it provides a principled explanation of why practitioners hav e suc- cessfully trained a single pair of neural nets in games lik e GANs. Secondly , the equilibrium achiev ed in the theorem has a meaningful in terpretation as the solu- tion of a game where the play ers hav e limite d-c ap acity . Finally , it shed light on some geometric prop erties of the space of neural netw orks (roughly , it is ’almost con vex’), that could be lev eraged in diverse contexts of deep learning theory . All the pro ofs can b e found in the app endix. 2 RELA TED WORK Minimax theorems in GANs. Man y pap ers ha v e adopted a game-theoretic persp ective on GANs, mo- tiv ating the computation of distributions of genera- tors (in practice, finite collections) [ Arora et al. , 2017 , Olieho ek et al. , 2018 , Hsieh et al. , 2019 , Grnarov a et al. , 2018 , Domingo-Enrich et al. , 2020 ] or an a verage of discriminators F arnia and T se [ 2018 ]. How ever, these pap ers fail to explain wh y , in practice, it suffices to train only a single generator and discriminator (instead of col- lections) to achiev e state-of-the-art p erformance [ Bro c k et al. , 2019 ]. Ov erall, even if we share motiv ations with the related work mentioned ab ov e (pro viding principled results), our results and conclusion are fundamen tally differen t: we explain why using a single generator and discriminator—not a distribution ov er them—mak es sense. W e do so by proving that one can ac hieve a notion of nonconcav e-noncon vex minimax equilibrium in GANs parametrized with neural nets. Stac kelberg games and lo cal optimality . The lit- erature has considered other notions of equilibrium. Recen tly , Fiez et al. [ 2020 ] prov ed results on games where the goal is to find a (local) Stack elb erg equi- librium. Using that persp ective, Zhang et al. [ 2020 ] and Jin et al. [ 2019 ] studied lo cal-optimality in the con text of nonconcav e-noncon vex games. Alternativ e notions of lo cal equilibria ha ve b een proposed and studied by Berard et al. [ 2020 ], F arnia and Ozdaglar [ 2020 ], Schaefer et al. [ 2020 ] who argued that lo cal Nash equilibria ma y not b e the right notion of lo cal optimal- it y . Our work provides a complementary p ersp ective b y providing a glob al minimax optimality theorem in a restricted—though realistic—nonconcav e-noncon vex setting. Stac kelberg equilibria ma y b e meaningful in some con texts, such as adv ersarial training, but we argue in § B that the minimax theorem is fundamental for defining a v alid notion of solution for many mac hine learning applications. P arametrized strategies in games. The notion of laten t matrix games mentioned in this pap er is similar to the pushforward technique prop osed by Dou et al. [ 2019 ]. It can also b e related to the latent p olicies used in some multi-agen t reinforcement learning (RL) appli- cations. F or instance the agen t trained b y Vin yals et al. [ 2019 ] to play the game of StarCraft I I had p olicies of form π ( a s, z ) where z b elongs to structured space that corresp onds to a particular w ay to start the game or to actions it should complete during the game (e.g., first constructed buildings). Moreov er, using parametrized function to estimate strategies in games has b een at the heart of multi-agen t RL [ Baxter et al. , 2000 , F rançois- La vet et al. , 2018 , Mnih et al. , 2015 ]. The idea of using a laten t space to parametrize distributions has also b een widely used in the ML comm unit y [ Goo dfellow et al. , 2014 ]. Our contribution regarding latent matrix games (and more broadly latent RL p olicies) is the- oretical: we provide a framew ork to study equilibria in parametrized NC-NC games as well as an existence result for an equilibrium (Thm. 1 ). Bounded rationality . In his seminal w ork, Simon [ 1969 ] introduced the principled of b ounded rationalit y . Generally speaking, it aims to capture the idea that rational agen ts are actually incapable of dealing with the full complexity of a realistic environmen t, and thus b y these limitations, achiev e a sub-optimal solution. Neyman [ 1985 ], P apadimitriou and Y annak akis [ 1994 ], Rubinstein and Dalgaard [ 1998 ] mo deled these limita- tions by constraining the computational resources of the pla y ers. Similarly , Quan tal response equilibrium (QRE) [ McKelvey and Palfrey , 1995 ] is a wa y to mo del b ounded rationality: the play ers do not choose the b est action, but assign higher probabilities to actions with higher reward. Overall, QRE, b ounded rational- it y/computation ha v e a similar goal as our notion of limited capacity equilibrium: to mo del play ers that are limited b y computation/memory/reasoning. How ev er, the wa y the limits are mo deled differs since, in this w ork, the limitations of the play ers are embedded in the Gauthier Gidel, Da vid Balduzzi, W o jciech Marian Czarnec ki, Marta Garnelo, Y oram Bac hrac h represen tative p ow er of the class of function considered. Finding a Nash equilibrium of Colonel Blotto. After its introduction by Borel [ 1921 ], finding a Nash equilibrium of the Colonel Blotto game has b een an op en question for 85 years. Rob erson [ 2006 ] found an equilibrium solution for the contin uous v ersion of the game, later extended to the discrete symmetric case by Hart [ 2008 ]. The equilibrium computation in the general case remains open. Recen tly , Blotto has b een used as a challenging use-case for equilibrium computation [ Ahmadinejad et al. , 2019 ]. Similarly , w e consider a v ariant of Blotto to v alidate that w e can practically find approximate equilibrium in games with a single pair of neural net works. 3 MOTIV A TION: MINIMAX IN MA CHINE LEARNING A two-player zer o-sum game is a p ayoff function ϕ ∶ Ω × Θ → R , that ev aluates pairs of strategies ( w , θ ) . The goal of the game is to find an e quilibrium , i.e., a pair of strategies ( ω ∗ , θ ∗ ) suc h that, ϕ ( w , θ ∗ ) ≤ ϕ ( w ∗ , θ ∗ ) ≤ ϕ ( w ∗ , θ ) , ∀ w ∈ Ω , θ ∈ Θ . Ha ving such an equilibrium ensures that the order in whic h the pla y ers choose their resp ective strategy do es not matter and that there is a non-exploitable strategy , min θ ∈ Θ max w ∈ Ω ϕ ( w , θ ) = max w ∈ Ω min θ ∈ Θ ϕ ( w , θ ) = ϕ ( w ∗ , θ ∗ ) . If the function ϕ is concav e-conv ex and if the sets Θ and Ω are con vex and compact then Sion et al. [ 1958 ]’s Minimax theorem guarantees a Nash equilibrium exists. Previous theoretical work in the con text of machine learning [ Arora et al. , 2017 , Oliehoek et al. , 2018 , Grnaro v a et al. , 2018 , Hsieh et al. , 2019 ] considered the mo del p ar ameters w and θ as the strategies of the game. Arguably , the most well-kno wn example of suc h a game is GANs. Example 1. [ Go o dfel low et al. , 2014 ] A GAN is a game wher e the first player picks a binary classifier D w p ar ametrize d by w ∈ R p 1 c al le d discriminator , and the se c ond player picks a generator G θ that is a p ar ametrize d mapping fr om a latent sp ac e to an out- put sp ac e. The p ayoff ϕ is then the ability of the first player to discriminate a r e al data distribution p d fr om the gener ate d distribution, ϕ ( w , θ ) ∶ = E x ∼ p d log D w ( x ) + E z ∼ N ( 0 ,I d ) log 1 − D w ( G θ ( z )) . (3) Unfortunately , Example 1 do es not satisfy Sion Mini- max theorem’s assumptions for the following reasons: (i) The parameter sets are not compact. (ii) The func- tion ϕ is not concav e-conv ex b ecause of the non-con- v exity induced by the neural netw orks parametrization. While one can easily cop e with the first issue—by for instance restricting ourselves to b ounded weigh ts or by lev eraging F an’s Theorem [ F an , 1953 ]—the second issue (ii) is an in trinsic part of learning by neural netw orks. On the one hand, one cannot exp ect ( 3 ) to b e v alid for general nonconcav e-nonconv ex (NC-NC) games [ Jin et al. , 2019 ]. On the other hand, man y games in the con text of machine learning ha ve a particular structure since, as we will see in the next section, their NC-NC asp ect comes from the neural netw ork parametrization. T wo complementary p ersp ectiv es on a game. Example 1 can b e interpreted as a game b etw een tw o pla yers, one play er, the gener ator , prop oses a sample that the other play er, the discriminator tries to distin- guish from a real data distribution p data . In that game, the parameters w and θ of the pa yoff function ( 3 ) , do not explicitly corresp ond to any meaningful strategy– i.e., generating a sample or distinguishing data from generated samples–but they resp ectively parametrize mo dels (a discriminator and a distribution) that hav e an in tuitive interpretation in the GAN game. Considering q θ the generated distribution in ( 3 ) , we then ha ve a duality b etw een parameters and mo dels ˜ ϕ ( D w , q θ models ) ∶ = E p d [ log D w ( x )] + E q θ [ log 1 − D w ( x ′ )] = ϕ ( w , θ params ) . (4) A comp e lling asp ect of this dual p ersp ective is that ev en though, one c annot exp ect ϕ , the pay off function of the parameters w and θ , to b e conca ve-con vex, the pay off of the mo dels ˜ ϕ is c onc ave-c onvex . F ormally , for w i ∈ Ω , θ i ∈ Θ , and λ i ∈ [ 0 , 1 ] , i = 1 . . . K , λ 1 + . . . + λ K = 1 w e hav e (by concavit y of log and linearity of q ↦ E q ), ˜ ϕ ( ∑ K i = 1 λ i D w i , q θ ) ≥ ∑ K i = 1 λ i ˜ ϕ ( D w i , q θ ) , ∀ θ ∈ Θ , ˜ ϕ ( D w , ∑ K i = 1 λ i q θ i ) = ∑ K i = 1 λ i ˜ ϕ ( D w , q θ i ) , ∀ w ∈ Ω . Note that the notion of con vex com bination for the mo dels is quite subtle here: λD w + ( 1 − λ ) D w ′ cor- resp onds to a conv ex combination of functions while λq θ + ( 1 − λ ) q θ ′ corresp onds to a conv ex combination (a.k.a, mixture) of distributions. Ev en if the pa yoff ( 4 ) is concav e-conv ex with respect to ( D , p ) , one c annot apply (yet) any standard minimax theorem for the follo wing reason: given w 1 , w 2 ∈ Ω and λ ∈ [ 0 , 1 ] we may hav e ∄ w ∈ Ω , s.t. λD w 1 + ( 1 − λ ) D w 2 = D ω , (5) meaning that the set of functions F Ω ∶ = { D w w ∈ Ω } ma y not b e con v ex. Ho w ever, for the particular case A Limited-Capacity Minimax Theorem for Noncon v ex-Nonconcav e Games of parametrized neural netw orks we will show that the set F is “almost conv ex” (see Prop. 2 and 3 ). It is one of the core results used in Thm. 1 ’s pro of. 4 AN ASSUMPTION FOR NC-NC GAMES The games arising in machine learning are not classical normal- or extensive-form games. Rather, they often use neural nets mo dels to approximate complex func- tions and high dimensional distributions [ Bro ck et al. , 2019 , Razavi et al. , 2019 ]. That is why they are of- ten considered gener al nonc onc ave-nonc onvex (NC-NC) games ( 1 ) . How ev er, as illustrated in ( 4 ) , in the ma- c hine learning context, many games hav e a particular structure where the mo dels’ pa yoff is concav e-conv ex. Assumption 1. The NC-NC game ( 1 ) is assume d to have a concav e-conv ex mo dels’ p ayoff, i.e., w and θ r esp e ctively p ar ametrize f w and q θ such that, ϕ ( w , θ params ) = ˜ ϕ ( f w , q θ models ) (6) wher e ( f , q ) ↦ ˜ ϕ ( f , q ) is c onc ave-c onvex. W e c al l f w and q θ the mo dels picke d by the players , they c an either b e a p ar ametrize d function or distribution. The intuition b ehind this assumption is that the noncon vex-nonconca vity of the problem comes from the (neural net work) parametrization of the mo dels. One example of such a game has b een developed in ( 4 ) where the first play er picks a function D w and the sec- ond one a distribution ov er images q θ . Another closely related example is the W asserstein GAN (WGAN). Example 2. [ Arjovsky et al. , 2017 ] The WGAN for- mulation is a minimax game with a p ayoff ϕ s.t., ϕ ( w , θ ) = ˜ ϕ ( D w , q θ ) ∶ = E x ∼ p data D w ( x ) − E x ′ ∼ q θ D w ( x ′ ) wher e the discriminator D w has to b e 1-Lipschitz, i.e., D w L ≤ 1 . By biline arity of the function ( D , p ) ↦ E p [ D ( x )] we have that ˜ ϕ is biline ar and thus satisfies Assumption 1 . Finally , w e present how Assumption 1 holds when trying to solv e a matrix game with a v ery large (or ev en infinite) num b er of strategies b y parametrizing mixed strategies. 1 1 Note that here we do not claim the nov elt y of parametrizing p olicies/strategies, suc h idea has b een used in many games and RL applications (see related w ork sec- tion). W e instead fo cus on illustrating how a particular wa y of parametrizing leads to game that satisfies Assump. 1 . Using function approximation to solve matrix games In the case of matrix games, the pay off func- tion ϕ ∶ A × B → R has no conca v e-conv ex struc- ture, and the sets A and B are often even discrete. v on Neumann et al. [ 1944 ] introduced mixed strategies p ∈ ∆ ( A ) , where ∆ ( A ) is the set of probabilit y distri- butions o ver A , in order to guarantee the existence of an equilibrium. In game-theory , a well-kno wn example of a challenging matrix game is the Colonel Blotto game. Example 3 (Colonel Blotto Game) . Consider two players who contr ol armies of S 1 and S 2 soldiers r e- sp e ctively. Each c olonel al lo c ates their soldiers on K b attlefields. A str ate gy for player- i is an al lo c ation a i ∈ A i and the p ayoff of the first player is the numb er of b attlefields won ϕ ( a 1 , a 2 ) ∶ = 1 K ∑ K k = 1 1 {[ a 1 ] k > [ a 2 ] k } (7) wher e A i ∶ = a ∈ N K ∶ ∑ K k = 1 [ a ] k ≤ S i , 1 ≤ k ≤ K and [ a ] k c orr esp ond to the k th c o or dinate of a . In Example 3 , the num b er of strategies gro ws exp o- nential ly fast as K gro ws. Consequently , one cannot afford to w ork with an explicit distribution o ver the strategies. A tractable wa y to compute an equilibrium of the Colonel Blotto Game has b een an op en question for decades. The GANs examples (Example 1 & 2 ) sug- gest to consider distributions implicitly defined with a generator. Given a laten t space Z , a laten t distribution π on Z and a mapping g θ ∶ Z → A , w e can define the distribution q θ ∈ ∆ ( A ) as a ∼ q θ ∶ a = g θ ( z ) , z ∼ π . (8) Definition 1 (Laten t Matrix Game) . A latent matrix game ( ϕ, F , G ) is a two-player zer o-sum game wher e the players pick f w ∈ F and g θ ∈ G and, given π and π ′ two fixe d distributions, obtain p ayoffs ϕ ( w , θ ) ∶ = E z ∼ π , z ′ ∼ π ′ ϕ f w ( z ) , g θ ( z ′ ) . The reformulation of any matrix game as a latent game satisfies Assumption 1 . Example 3 (Laten t Blotto) . Consider the functions f w ∶ R p → A 1 and g θ ∶ R p → A 2 . The p ayoff is ϕ ( w , θ ) ∶ = 1 K ∑ K k = 1 P [ f w ( Z 1 )] k > [ g θ ( Z 2 )] k (9) wher e Z 1 , Z 2 ∼ N ( 0 , I p ) ar e indep endent Gaussians and A i is define d in ( 7 ) . Laten t matrix games encompass multi-agen t RL games pla yed with RL p olicies such as the setting used b y Viny als et al. [ 2019 ] to play StarCraft I I. The agen t, called AlphaStar, has a latent-conditioned p olicy Gauthier Gidel, Da vid Balduzzi, W o jciech Marian Czarnec ki, Marta Garnelo, Y oram Bac hrac h π ( a s, z ) where z b elongs to a structured space that represen ts information ab out how to start constructing units and buildings, and that is sampled from an ex- p ert human play er distribution: z ∼ p human ( z ) . Giv en t wo agents π 1 ( a s, z ) and π 2 ( a s, z ) , the pay off in the laten t game is ϕ ( π 1 , π 2 ) = P ( π 1 b eats π 2 ) . The classes F and G corresp ond to the neural architectures used to parametrize the p olicies; the priors π and π ′ are the h uman exp ert distribution p human . In that example, and more generally in m ulti-agent RL zero-sum games play ed with p olicies parametrized by neural net works, the pay off ϕ ( w , θ ) = P ( π w b eats π θ ) is a p otentially nonconcav e-noncon vex function of the parameters but satisfies Assumption 1 . 5 A MINIMAX THEOREM W e w ant to prov e a minimax theorem for some NC-NC games ( 1 ) that satisfy Assumption 1 . W e start with an informal statemen t of our result. Theorem 1. [Informal] L et ϕ b e a nonc onc ave- nonc onvex p ayoff that satisfies Assump. 1 with ˜ ϕ bilin- e ar and wher e the players pick ( w , θ ) , the p ar ameters of two neur al networks. F or any > 0 ther e exists ( w , θ ) achieving an appr oximate limited-capacity equilibrium . The notion of approximate limited-capacit y equilibrium men tioned in that informal statement is detailed in the complete statemen t of Theorem 1 . When pla yed with neural netw orks Example 2 and 3 satisfy the hypoth- esis of this theorem. The pro of of this Theorem is split in to 3 main steps: (i) in § 5.1 by using the fact that ϕ ( w , θ ) = ˜ ϕ ( f w , q θ ) w e provide the existence of a limited-capacit y equilibrium in the con vex hull of the models’ space of f w and q θ . Note that, since w e are w orking in the conv ex hull, one can only exp ect (in general) to ac hieve this equilibrium with a collec- tion of parameters ( w i , θ i ) i ∈ I . (ii) in § 5.2 we sho w that appro ximate equilibrium can b e ac hieved with a rela- tiv ely small conv ex combination. (iii) in § 5.3 we show that when using neural netw orks, such small conv ex com bination of mo dels can b e achiev ed b y a single larger neural net work. A formal definition of con vex com bination of mo dels is provided in § 5.1 . 5.1 Limited Capacit y Equilibrium in the Mo dels’ Space Recall that by Assump. 1 , the NC-NC pay off ϕ can b e written as, ϕ ( w , θ ) = ˜ ϕ ( f w , q θ ) (10) where ( f , q ) ↦ ˜ ϕ ( f , q ) is conca ve-con vex. The mo de ls f w and q θ are either functions or distributions resp ec- tiv ely parametrized b y w and θ . F or instance, in the con text of WGAN (Example 2 ), f w w ould b e the dis- criminator and q θ w ould b e the generated probability distribution. In that example, notice that ˜ ϕ ( f w , ⋅ ) is not con vex with resp ect to the generator function but only with resp ect to the generated distribution. Simi- larly , if w e computed con v ex combinations generator’s parameters, the pay off ϕ w ould not b e conv ex in gen- eral. Moreov er, the Lip chitz constraint in Example 2 is a natural constraint in the function space , but it is c hallenging to translate it into a constrain t in the pa- rameter space . 2 Ov erall, using ( 10 ) one can rewrite ( 1 ) as follo ws, min f ∈ F Ω max g ∈ G Θ ˜ ϕ ( f , g ) (11) where F Ω and G Θ are function or distribution spaces (dep ending on the application) incorp orating the lim- ited capacity constraints of the problem, e.g., Lipschitz constrain t. In the follo wing , for simplicit y of the discussion, w e discuss what the formal definitions of a con vex combination are when F Ω is a function space and G Θ is a distribution space when we hav e no addi- tional constraint aside from the parametrization, i.e., F Ω ∶ = { f w w ∈ Ω } and G Θ ∶ = { q θ θ ∈ Θ } . How ever, these notions and our results extend if w e consider that b oth mo dels are distributions (e.g., in Example 3 ), or if w e add any con vex constraint on the functions or the distributions, see Example 2 . Con vex combination of functions. Let us con- sider w 1 and w 2 ∈ Ω , the conv ex com bination of the mo dels f w 1 and f w 2 is their p oint-wise av eraging. The con vex hull of F Ω can b e defined as, h ull ( F Ω ) ∶ = { A verages from F Ω } (12) = K i = 1 λ i f w i w i ∈ Ω , λ ∈ ∆ K , K ≥ 0 . where ∆ K is the K -dimen tional simplex, i.e., { λ ∈ R K , λ i ≥ 0 , ∑ K i = 1 λ i = 1 } . Con vex com bination of distributions. Consider laten t mappings θ 1 and θ 2 ∈ Θ that parametrize prob- abilit y distribution q θ 1 and q θ 2 o ver a set X . The c onvex c ombination q λ of q θ 1 and q θ 2 with λ ∈ [ 0 , 1 ] is the mixture of these t wo probability distributions, q λ ∶ = λq θ 1 + ( 1 − λ ) q θ 2 . T o sample from q λ , flip a biased coin with P ( heads ) = λ . If the result is heads then sample a strategy from q θ 1 and if the result is tails then sample from q θ 2 . The 2 In practice, parameters are clipp ed [ Arjovsky et al. , 2017 ] or the Lip chitz constan t of the netw ork is approxi- mated [ Miyato et al. , 2018 ]. These approximations can b e arbitrarily far from the original constraint. A Limited-Capacity Minimax Theorem for Noncon v ex-Nonconcav e Games con vex hull of G Θ is, h ull ( G Θ ) ∶ = { Mixtures from G Θ } (13) = K i = 1 λ i q θ i θ i ∈ Θ , K i = 1 λ ∈ ∆ K , K ≥ 0 . The set h ull ( G Θ ) is a subset of P ( X ) , the set of prob- abilit y distributions on X . This set is differen t from the set of distributions supp orted on G Θ considered b y Arora et al. [ 2017 ], Hsieh et al. [ 2019 ]. It contains ‘smaller’ mixtures b ecause there ma y b e many distri- butions supp orted on G Θ that corresp ond to the same p ∈ hull ( G Θ ) . Moreo ver these works did not take adv an- tage of the conv exity with respect to the discriminator function (see Example 1 and 2 ) b y considering ( 12 ). Existence of an equilibrium by pla ying in the con vex hulls. Our first result is that there exists an equilibrium by allowing functions or distributions to b e pic ked from their conv ex hulls. Prop osition 1. L et ϕ b e a game that fol lows Assump- tion 1 . If G Θ and F Ω ar e c omp act, then ther e exist a v alue for the game such that, V ( Ω , Θ ) ∶ = sup f ∈ hull ( F Ω ) inf q ∈ hull ( G Θ ) ˜ ϕ ( f , q ) = inf q ∈ hull ( G Θ ) sup f ∈ hull ( F Ω ) ˜ ϕ ( f , q ) , (14) wher e h ull ( G Θ ) and h ull ( F Ω ) ar e either define d in ( 12 ) or in ( 13 ) , dep ending on the typ e mo del. After showing that the closure of h ull ( G Θ ) and h ull ( F Ω ) are compact, this prop osition is a corollary of Sion et al. [ 1958 ]’s minimax theorem (see § C ). Note that Ω and Θ are arbitrary and that this equilibrium differs from the infinite-capacit y equilibrium of the game ( 11 ) where we w ould allow f and g to b e any function or distribution (i.e. with no parametrization restriction). Because w e consider the conv ex hull of F Ω and G Θ , this equilibrium is achiev ed with c onvex c ombinations (Eq. 12 & 13 ) of q θ i , i ≥ 0 (resp. f w i ) and th us there is no reason to exp ect to ac hiev e this equilibrium with a single pair of weigh ts ( w , θ ) in general. Ho wev er in § 5.2 , we show that one can appro ximate suc h an equilibrium with relativ ely small conv ex combinations. 5.2 Appro ximate minimax equilibrium Appro ximate equilibria for ( 14 ) are the pairs of mo dels -close to ac hieving the v alue of the game. Definition 2 ( -equilibrium) . A p air ( f ∗ , q ∗ ) ∈ h ull ( F ) × hull ( G ) is an -e quilibrium if, min q ∈ hull ( G Θ ) ˜ ϕ ( f ∗ , q ) ≥ V ( Ω , Θ ) − and max f ∈ hull ( F Ω ) ˜ ϕ ( f , q ∗ ) ≤ V ( Ω , Θ ) + . (15) Note that f ∗ do es not dep end on p ∗ and vice-versa. W e will sho w that suc h appro ximate equilibria are ac hieved with finite conv ex combinations. Considering f k ∈ F Ω and q ′ k ∈ G Θ (that can either b e functions or distributions) w e aim at finding the smallest conv ex com bination that is an -equilibrium. ( K Ω , K Θ ) ∶ = Smallest K and K ′ ∈ N s.t. ( K k = 1 λ k f k , K ′ k = 1 λ ′ k q k ) is an -equilibrium . (16) Our goal is to provide a b ound that dep ends on and on some prop erties of the classes F Ω and G Θ . Theorem 2. L et ϕ a game that satisfies Assumption 1 . If ˜ ϕ is biline ar, θ ≤ R , w ≤ R , ∀ w , θ ∈ Ω × Θ ⊂ R d × R p and ϕ is L -Lipschitz then, K Ω ≤ 4 D 2 w p 2 ln ( 6 RL 2 ) and K Θ ≤ 4 D 2 θ d 2 ln ( 6 RL 2 ) (17) wher e D w ∶ = max w,w ′ ,θ ϕ ( w , θ ) − ϕ ( w ′ , θ ) and D θ ∶ = max w,θ ,θ ′ ϕ ( w , θ ) − ϕ ( w , θ ′ ) . Roughly , the num ber K Θ expresses to what exten t the set of distributions induced b y the mappings in G Θ has to be ‘con v exifed’ to achiev e an appro ximate equilibrium. Note that in practice we expect this quan tity to b e small. F or instance, in the context of GANs, if the class of discriminators F Ω con tains the constan t function D ( ⋅ ) = . 5 then K Ω = 1 since ϕ ( D , G ) = 0 , ∀ G ∈ G . T w o close related results are [ F arnia and T se , 2018 , Theorem 4] and [ Arora et al. , 2017 , Theorem 4.2]. In the former, the authors p oint out that the functional space of neural netw orks is not conv ex and prov e that an y function in the con v ex hull of neural netw orks can be approximated by a finite av erage of function. In the latter, the authors show that by considering uniform mixtures of generators and disciminators one can approximate the equilibrium of a GAN. Our results generalize these tw o ideas by sho wing that for an y pa yoff functon ϕ that satisfy Assumption 1 one can find an approximate equilibrium with a finite con vex com bination of function or distributions (dep ending on the con text). W e th us simultaneously handle the case of conv ex combinations of functions or distributions and consider a more general class of pa yoff functions. 5.3 A chieving a Mixture or an A verage with a Single Neural Net W e sho wed ab ov e that under the assumption of The- orem 2 , approximate equilibria can b e achiev ed with finite conv ex combinations. In this section, w e inv es- tigate how it is p ossible to achiev e such approximate Gauthier Gidel, Da vid Balduzzi, W o jciech Marian Czarnec ki, Marta Garnelo, Y oram Bac hrac h equilibria with a single neural net work. F ormally , a neural net work g ∶ R d in → R d can b e written as, g θ ( x ) = b l + W l σ ( b l − 1 + W l − 1 . . . σ ( b 1 + W 1 x )) , (18) where W 1 , . . . , W l are the w eight matrices, b l , . . . , b 1 the biases and σ is a given non-linearit y . W e note θ the concatenation of all the parameters of this neural net work. W e present tw o results on the geometry of the space of neural netw orks. The first one concerns mix- tur es of distributions represen ted by latent neural nets with ReLU non-linearity , and the second one concerns c onvex c ombinations of neural nets as functions. Neural Nets Represent Mixtures of Sub-Nets. First, w e get interested in the probability distributions q θ induced b y g θ , θ ∈ Θ , defined as a ∼ q θ ∶ a = g θ ( z ) where z ∼ U ([ 0 , 1 ]) . (19) One of the motiv ations of this work is to represent distribution ov er im ages usually represented by a high dimensional v ector in [ 0 , 1 ] d . That is why we will assume that our generator function tak e its v alue in [ 0 , 1 ] d . Moreo ver, for this prop osition, we only consider the ReLU non-linearity σ ( x ) = ReLU ( x ) ∶ = max ( 0 , x ) . Prop osition 2. L et θ k ∈ [ − R, R ] p , k = 1 . . . K, b e the p ar ameters of k R eLU nets with p p ar ameters. If the input latent variable is of dimension d in = 1 and if for al l k = 1 . . . K , z ∈ [ 0 , 1 ] , g θ k ( z ) ∈ [ 0 , 1 ] d and g θ k is c onstant outside of [ 0 , 1 ] , then ther e exists a R eLU net with K ( p + 6 ) non-line arities θ ∈ [ − K R, K R ] K ( p + 6 ) such that d T V ( 1 n ∑ K k = 1 q θ k , q θ ) ≤ 1 / R wher e d T V is the total variation distanc e. Fig. 2b (in § C ) illustrates how g θ is constructed. Unlike the universal approximation theorem, Prop. 2 sho ws that a single neur al network can r epr esent mixtures. On the one hand, when one wan ts to approximate an arbitrary contin uous function, the num b er of required hidden units ma y be prohibitively large [ Lu et al. , 2017 ] as the error v anishes. On the other hand, the dimension of θ in Prop. 2 does not dep end on an y v anishing quan tity . The high-lev el insight is that a large enough ReLU net can represent mixtures of distributions induced by smaller ReLU nets, with a width that grows linearly with the size of the mixture. Neural Nets can represent an a verage of Sub- Nets. If we consider av erages of functions as de- scrib ed in ( 12 ) , we can show that p oint-wise av erages of neural net works can b e represented by a wider neural net work. This result is v alid for an y non-linearity . Prop osition 3. L et w k ∈ [ − R, R ] p , k = 1 . . . K b e the p ar ameters of k neur al nets with p p ar ameters, ther e exists au neur al net p ar ametrize d by w ∈ [ − R , R ] K p , such that 1 n ∑ K k = 1 f w k = f w . Figure 2a sho ws how f w is constructed. Similarly as the Prop. 2 , Prop. 3 is a representation theorem that sho ws that the space or neural netw orks with a fixed n umber of parameters is ‘almost’ conv ex. 5.4 A Minimax Theorem for NC-NC Games Pla yed with Neural Nets Prop. 2 and 3 giv e insights ab out the represen tative p o wer of neural nets: as their num b er of parameters gro ws, neural nets can express larger mixtures/av erages of sub-nets. Combining these prop erties with Thm. 2 , w e show that appro ximate equilibria can b e achiev ed for suc h nonconcav e-nonconv ex (NC-NC) pay off. Theorem 1. L et ϕ b e a NC-NC game that fol lows Assumption 1 . W e assume that the mo dels’ p ayoff ˜ ϕ is biline ar and c onsider two c ases wher e the mo dels have p p ar ameters b ounde d by R , i.e., ( w , θ ) ∈ [ − R, R ] 2 p : 1. [F unction vs. distribution] : ϕ ( w , θ ) = ˜ ϕ ( f w , q θ ) wher e q θ is a distribution p ar ametrize d by a R eLU net with d in = 1 (se e Eq. 19 ), and f w is a neur al network with any non-line arity. Applies to Ex. 2 . 2. [Distribution vs. distribution] : ϕ ( w , θ ) = ˜ ϕ ( q w , q θ ) wher e q θ and q w ar e distributions p ar ametrize d by a R eLU net with d in = 1 . Ap- plies to Example 3 . If ˜ ϕ is ˜ L -Lipschitz, and if ϕ is L -Lipschitz, then for any > 0 , ther e exists ( w ∗ , θ ∗ ) ∈ [ − R, R ] 2 p , such that, min θ ∈ [ − R,R ] p ϕ ( w ∗ , θ ) + + 2 ˜ L R ≥ max w ∈ [ − R,R ] p ϕ ( w , θ ∗ ) , wher e p ≥ C p log ( R p / ) , R ≥ R p p , and the subnet- works gener ating the distributions (se e Eq. 19 ) takes their values in [ 0 , 1 ] d and ar e c onstant outside of [ 0 , 1 ] . An explicit formula for C is provided in § C.5 as well as v ariants of this theorem when b oth play ers pic k a mo del that is a function. Theorem 1 sho ws the existence of a notion of weak er-capacity- e quilibrium for a nonconcav e- noncon vex game where the mo dels use a standar d ful ly c onne cte d ar chite ctur e . This result differs from Arora et al. [ 2017 , Theorem 4.3] who, only in the context of GANs, design a sp e cific ar chite ctur e to achiev e a differen t notion of approximate equilibrium. The notion of weak er-capacity is encompassed within the fact that w and θ are of dimension p ≤ p and are b ounded by R ≤ R . Roughly , this theorem can b e in terpreted as follows: if one considers a minimax game where the pla yers pick neural netw orks and where the pa yoff is bilinear with resp ect to the mo dels (functions on distributions) represented by these neural netw orks, A Limited-Capacity Minimax Theorem for Noncon v ex-Nonconcav e Games then there exist a combination of parameters that can ac hieve an -appro ximate minimax against subnetw orks with p parameters, i.e., the first (resp. second) play er cannot b e beaten by more than b y any sub-netw ork of the second (resp. first) play er. Regarding the num b er of parameters p of these sub- net works, on the one hand, if p < 1 , then the low er- b ound on p is v acuous, on the other, the num b er of parameters of the higher-capacit y netw orks p only needs to (roughly) grow quadr atic al ly with to achiev e a non-v acuous bound. Hence, a consequence of The- orem 1 is that, for the NC-NC games that follo w the assumptions of Theorem 1 , highly over p ar ametrize d networks can prov ably achiev e a non-v acuous notion of appro ximate equilibrium. It is worth discussing what happ ens when some assump- tions fail to hold. W e think the Lipschitz assumptions are quite standard. W e fo cus on the case of distribu- tions parametrized b y a ReLU net with d in = 1 . W e think the assumptions that the non-linearities must b e ReLU is an artefact form the pro of technique and we b eliev e that with a bit more work a similar version of Theorem 1 would hold with any non-linearities with whic h one can arbitrarily approximate indicator func- tions. Extending theorem to d in > 1 seems p ossible though very c hallenging. The difficulty relies on ex- tending Proposition 2 to d in ≥ 2 . One idea, may b e to consider deep er net works to represent a mixture of smaller nets. W e leav e this question op en. 6 APPLICA TION: SOL VING COLONEL BLOTTO GAME Finally , we present some exp eriments with d in ≥ 2 on the Colonel Blotto Game to illustrate the soundness of Theorem 1 and explore whether equilibria can b e ac hieved with larger input spaces. W e apply the latent game approac h dev elop ed in Definition 2 to solv e a differen tiable version of Example 3 . W e consider a con tinuous relaxation of the strategy space where S 1 = S 2 . After renormalization we hav e that A 1 = A 2 = ∆ K , where ∆ K is the K -dimensional simplex. It is imp ortan t to notice that in that case an al lo c ation corresp onds to a p oint on the simplex and a mixtur e of alloc ation corresp onds to a distribution over the simplex . W e replace the pay off ( 9 ) of Latent Blotto by a differen tiable one, ϕ ( w , θ ) ∶ = E z ∼ π z ′ ∼ π ′ 1 K K k = 1 σ ([ f w ( z ) − g θ ( z ′ )] k ) (20) where σ is a sigmoid minus 1 / 2 and f w , g θ ∶ R p → ∆ K . This game has b een theoretically analyzed b y F erdowsi et al. [ 2018 ] when S 1 > S 2 . The generativ e functions f w and g θ are dense ReLU nets with 4 hidden la yers, 16 hidden units per lay er, and a K -dimensional softmax output with a Gaussian laten t v ariable ( d in = 16 ). W e trained the mo dels using gradien t descent ascent on the parameters of f and g with the Adam optimizer [ Kingma and Ba , 2015 ] with β 1 = . 5 and β 2 = . 99 . In Fig. 1b , we presen t the performance of the agents against a b est response. T o compute it, we sampled 5000 strategies and computed the b est resp onse against this mixed strategy using gradient ascen t on the sim- plex. W e also compute d the norm of the (sto c hastic) gradien t used to up date f . In Fig. 1a , we plotted samples from f at differen t training times. As we get closer to conv ergence to a non-exploitable strategy , we can see that this distribution av oids the center of the simplex (putting tro ops evenly on the battlefields) and the corners (fo cusing on a single battlefield) that are strategies easily exploitable by fo cusing on tw o battle- fields, this correlates with the decrease of the gradient and of the sub optimalit y indicating that the agen ts learned ho w to play Blotto. 7 DISCUSSION Nonconca ve-noncon vex games radically differ from min- imization problems since equilibria ma y not exist in general. Ho w, then, can neural nets regularly find meaningful solutions to games lik e GANs? In this work, w e partially answ er this question b y lever- aging the structure of GANs to show that a single pair of ReLU nets can achiev e a notion of limited-capacity- equilibrium. The in tuition underlying our theorem is as follows: neural nets ha v e a particular structure that in terleav es matrix multiplications and simple non- linearities. The matrix multiplications in one lay er of a neural net compute linear combinations of functions enco ded b y the other lay ers. In other words, neural nets are (non-)linear mixtures of their sub-net works. Our main result can b e related to games with b ounded rationalit y [ Simon , 1969 ]: when the play ers pic k parametrized mo dels, they are limited b y the represen- tational p ow er of the class of mo dels accessible (e.g., a fixed arc hitecture). It is instructive to discuss the relativ e merits of that limited-capacity asp ect occur- ing. On the one hand, if one had access to an y func- tion/distribution an infinite-capacity equilibrium would exist (b ecause the whole function/distribution space is con vex). Ho wev er, this quan tity may not b e realistic, e.g., in GANs, the optimal infinite-capacity generator m ust represent the distribution of ‘real-world’ images. If suc h a concept is not tractable, it seems unrealistic to exp ect limited capacity agents, such as humans or computers, to find it [ Papadimitriou , 2007 ]. On the Gauthier Gidel, Da vid Balduzzi, W o jciech Marian Czarnec ki, Marta Garnelo, Y oram Bac hrac h 0 iterations 400 iterations 800 iterations (a) 5000 samples using the latent mapping f and g after 0 , 400 , and 800 training steps. Their respective sub optimalit y along training has a v alue of 1 . 5 , 1 . 2 , and . 5 . 0 200 400 600 800 Num b er of iterations 0 . 5 1 . 0 1 . 5 Sub optimalit y × 10 agen t f agen t g 0 . 5 1 . 0 1 . 5 Norm of the gradien t × 100 (b) P erformance and conv ergence of the agen ts. Figure 1: T raining of latent agents to play differentiable Blotto with K = 3 . Righ t: The sub optimality corresp onds to the pay off of the agent against a b est resp onse. The curves corresp ond to av erages ov er 40 random seeds with standard deviation. other hand, our w ork sho ws that one can efficien tly appro ximate some equilibria when working with neural net works. In a similar vein as the games with b ounded rationalit y , these equilibria capture the notion that agen ts–and humans–that play complex games hav e a limited capacity . It seems to b e a more reasonable concept to consider the optimal w ay to play complex games suc h as Pok er of StarCraft I I that are m ulti-step with imp erfect information. A ckno wledgmen ts Gauthier Gidel would like to thank Ian Gemp for the helpful discussions. References A. Ahmadinejad, S. Dehghani, M. Ha jiaghayi, B. Lucier, H. Mahini, and S. Seddighin. F rom duels to battlefields: Computing equilibria of Blotto and other games. Mathematics of Op er ations R ese ar ch , 2019. C. D. Aliprantis and K. C. Border. Infinite Dimensional A nalysis A Hitchhiker’s Guide . Springer, 2006. M. Arjo vsky , S. Chintala, and L. Bottou. W asserstein generativ e adversarial netw orks. In ICML , 2017. S. Arora, R. Ge, Y. Liang, T. Ma, and Y. Zhang. Gen- eralization and equilibrium in generativ e adv ersarial nets (GANs). In ICML , 2017. J. Baxter, A. T ridgell, and L. W eav er. Learning to play c hess using temp oral differences. Machine L e arning , 2000. H. Berard, G. Gidel, A. Almahairi, P . Vincen t, and S. Lacoste-Julien. A closer lo ok at the optimization landscap es of generative adversarial net w orks. In ICLR , 2020. M. Bińko wski, J. Donah ue, S. Dieleman, A. Clark, E. Elsen, N. Casagrande, L. C. Cob o, and K. Si- mon yan. High fidelity sp eech synthesis with adver- sarial net works. In ICLR , 2020. E. Borel. La théorie du jeu et les équations intégrales a no yau symétrique. Comptes r endus de l ' A c adémie des Scienc es , 1921. A. Brock, J. Donahue, and K. Simony an. Large scale GAN training for high fidelit y natural image synthe- sis. In ICLR , 2019. N. Brown and T. Sandholm. Safe and nested subgame solving for imp erfect-information games. In A dvanc es in neur al information pr o c essing systems , 2017. N. Bro wn and T. Sandholm. Sup erhuman AI for mul- tipla yer p oker. Scienc e , 2019. V. Conitzer and T. Sandholm. Computing the optimal strategy to commit to. In Pr o c e e dings of the 7th A CM c onfer enc e on Ele ctr onic c ommer c e , 2006. C. Domingo-Enrich, S. Jelassi, A. Mensc h, G. Rotskoff, and J. Bruna. A mean-field analysis of tw o-play er zero-sum games. arXiv pr eprint arXiv:2002.06277 , 2020. Z. Dou, X. Y an, D. W ang, and X. Deng. Find- ing mixed strategy nash equilibrium for contin u- ous games through deep learning. arXiv pr eprint arXiv:1910.12075 , 2019. K. F an. Minimax theorems. Pr o c e e dings of the National A c ademy of Scienc es of the Unite d States of Americ a , 1953. F. F arnia and A. Ozdaglar. Do GANs alwa ys ha ve Nash equilibria? In ICML , 2020. F. F arnia and D. T se. A conv ex dualit y framework for GANs. In NeurIPS , 2018. A. F erdowsi, A. Sanjab, W. Saad, and T. Basar. Gener- alized colonel Blotto game. In 2018 A nnual Americ an Contr ol Confer enc e (A CC) , 2018. A Limited-Capacity Minimax Theorem for Noncon v ex-Nonconcav e Games T. Fiez, B. Chasnov, and L. J. Ratliff. Implicit learning dynamics in stac kelberg games: Equilibria character- ization, con vergence analysis, and empirical study . In ICML , 2020. V. F rançois-Lav et, P . Henderson, R. Islam, M. G. Belle- mare, and J. Pineau. An in tro duction to deep rein- forcemen t learning. arXiv pr eprint arXiv:1811.12560 , 2018. I. Goo dfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde-F arley , S. Ozair, A. Courville, and Y. Ben- gio. Generativ e adversarial nets. In A dvanc es in neur al information pr o c essing systems , 2014. P . Grnaro v a, K. Y. Levy , A. Lucchi, T. Hofmann, and A. Krause. An online learning approach to generative adv ersarial netw orks. In ICLR , 2018. J. Y. Halp ern and R. P ass. Algorithmic rationality: Game theory with costly computation. Journal of Ec onomic The ory , 2015. S. Hart. Discrete colonel Blotto and general lotto games. International Journal of Game The ory , 2008. Y.-P . Hsieh, C. Liu, and V. Cevher. Finding mixed nash equilibria of generative adversarial net works. In ICML , 2019. G. Huang, H. Berard, A. T ouati, G. Gidel, P . Vincent, and S. Lacoste-Julien. Parametric adversarial diver- gences are goo d task losses for generative mo deling. arXiv pr eprint arXiv:1708.02511 , 2017. C. Jin, P . Netrapalli, and M. I. Jordan. What is lo cal optimalit y in nonconv ex-nonconca ve minimax opti- mization? arXiv pr eprint arXiv:1902.00618 , 2019. E. Kalai. Bounded rationality and strategic complexity in rep eated games. In Game the ory and applic ations . Elsevier, 1990. D. P . Kingma and J. Ba. Adam: A metho d for stochas- tic optimization. In ICLR , 2015. R. J. Lipton and N. E. Y oung. Simple strategies for large zero-sum games with applications to complexity theory . In Pr o c e e dings of the twenty-sixth annual A CM symp osium on The ory of c omputing , pages 734– 740, 1994. Z. Lu, H. Pu, F. W ang, Z. Hu, and L. W ang. The expressiv e pow er of neural net works: A view from the width. In NeurIPS , 2017. A. Madry , A. Makelo v, L. Schmidt, D. T sipras, and A. Vladu. T ow ards deep learning mo dels resistant to adv ersarial attacks. arXiv pr eprint arXiv:1706.06083 , 2017. R. D. McKelv ey and T. R. Palfrey . Quantal resp onse equilibria for normal form games. Games and e c o- nomic b ehavior , 1995. T. Miyato, T. Kataok a, M. Ko yama, and Y. Y oshida. Sp ectral normalization for generative adv ersarial net- w orks. In ICLR , 2018. V. Mnih, K. Kavuk cuoglu, D. Silver, A. A. Rusu, J. V e- ness, M. G. Bellemare, A. Gra ves, M. Riedmiller, A. K. Fidjeland, G. Ostro vski, et al. Human-level con trol through deep reinforcement learning. natur e , 2015. M. Mohri, A. Rostamizadeh, and A. T alwalk ar. F oun- dations of machine le arning . MIT press, 2012. A. Neyman. Bounded complexity justifies co op eration in the finitely repeated prisoners’ dilemma. Ec o- nomics letters , 1985. F. A. Olieho ek, R. Sav ani, J. Gallego, E. v an der Pol, and R. Groß. Beyond local nash equilibria for ad- v ersarial netw orks. arXiv pr eprint arXiv:1806.07268 , 2018. C. H. Papadimitriou. The complexity of finding nash equilibria. Algorithmic game the ory , 2007. C. H. P apadimitriou and M. Y annak akis. On com- plexit y as bounded rationality . In Pr o c e e dings of the twenty-sixth annual A CM symp osium on The ory of c omputing , 1994. A. Razavi, A. v an den Oord, and O. Vin y als. Generat- ing div erse high-fidelity images with VQ-V AE-2. In A dvanc es in Neur al Information Pr o c essing Systems , 2019. B. Rob erson. The colonel Blotto game. Ec onomic The ory , 2006. A. Rubinstein and C.-j. Dalgaard. Mo deling b ounde d r ationality . MIT press, 1998. A. L. Samuel. Some studies in machine learning using the game of c heck ers. IBM Journal of r ese ar ch and development , 1959. F. Schaefer, H. Zheng, and A. Anandkumar. Implicit comp etitiv e regularization in gans. In ICML , 2020. S. Shalev-Sh wartz and S. Ben-David. Understanding machine le arning: F r om the ory to algorithms . Cam- bridge univ ersity press, 2014. D. Silv er, J. Sc hrittwieser, K. Simony an, I. An tonoglou, A. Huang, A. Guez, T. Hub ert, L. Baker, M. Lai, A. Bolton, et al. Mastering the game of go without h uman knowledge. natur e , 2017. H. A. Simon. The scienc es of the artificial . MIT press, 1969. M. Sion et al. On general minimax theorems. Pacific Journal of mathematics , 1958. G. T esauro. T emporal difference learning and td- gammon. Communic ations of the A CM , 1995. Gauthier Gidel, Da vid Balduzzi, W o jciech Marian Czarnec ki, Marta Garnelo, Y oram Bac hrac h O. Vin yals, I. Babuschkin, W. M. Czarnecki, M. Math- ieu, A. Dudzik, J. Chung, D. H. Choi, R. Po well, T. Ew alds, P . Georgiev, et al. Grandmaster level in starcraft ii using multi-agen t reinforcement learning. Natur e , 2019. J. v on Neumann, O. Morgenstern, and H. W. Kuhn. The ory of games and e c onomic b ehavior (c ommemo- r ative e dition) . Princeton univ ersity press, 1944. Y. W u, J. Donahue, D. B alduzzi, K. Simony an, and T. Lillicrap. LOGAN: Laten t optimisation for generativ e adversarial netw orks. arXiv pr eprint arXiv:1912.00953 , 2019. G. Zhang, P . Poupart, and Y. Y u. Optimality and stabilit y in non-conv ex-non-concav e min-max opti- mization. arXiv pr eprint arXiv:2002.11875 , 2020. A Limited-Capacity Minimax Theorem for Noncon v ex-Nonconcav e Games A Minimax Theorem for Nonconca v e-Noncon v ex Games: Supplemen tary Materials A In terpretation of Equilibria in Laten t Games In latent games, pla yers em b ed in mapping spaces in order to solve the game. When we consider a standard normal form game ϕ that we try to solve using mappings to appro ximate mixtures of strategies, we are actually pla ying a limited capacity version of the game that heavily dep ends on the expressivity of the mappings in the classes F and G . Suc h a limitation ma y b e interpreted as limitations on the skills of the play ers. It intuitiv ely makes sense that suc h limitations w ould change the optimal wa y to pla y the game: the optimal w ay to play StarCraft I I is different for pla yers that can p erform 10 versus 100 actions p er second. Thus, if the goal is to train agents to comp ete with humans, one needs to set a class G that (roughly) corresp onds to human skills. Setting “fair” constraints on the RL agents trained to pla y the game of StarCraft I I has b een an imp ortant issue Viny als et al. [ 2019 ] and can b e understo o d as setting the right class G in a latent game. Similarly a play er would not pla y p oker the same w a y if they had no memory of their opponents’ b ehavior in previous games. Similarly , in the context of Generative Adv ersarial Netw orks, it has b een argued that setting a restricted function class for the discriminator pro vides a more meaningful loss and describes an ac hiev able learning task for the generator Arora et al. [ 2017 ], Huang et al. [ 2017 ]. The final task is to generate pictures that are realistic according to the human metric. Such task is w a y lo oser – and thus easier to ac hiev e – than for instance minimizing the KL div ergence or the W asserstein distance b etw een the real data distribution and the generated distribution. T o sum-up, the equilibrium of a latent game provides a notion of limited-capacity-equilibrium that can define a target that corresp ond to agents with expressive and realistic b ehavior. In many tasks, our goal is to train agents that outperform human using human realistic limitations: it is imp ortant to constrain the agen t in order to prev ent it to play 10 5 actions p er minute but it is also imp ortant to constrain its opp onent b ecause we would like opp onen t to try to exploit the main agent in a semantically meaningful w ay and not by designing very sp ecific ’adv ersarial example’ strategies –e.g., v ery precise p ositions of units that breaks the vision system of the main agen t – that a human play er could not p erform. This idea of mo deling the limitations of realistic pla y ers play sub optimally is related to the notion of games with b ounded rationalit y [ Simon , 1969 , Rubinstein and Dalgaard , 1998 , Papadimitriou and Y annak akis , 1994 , Kalai , 1990 ] or b ounded computation [ Halp ern and P ass , 2015 ]. How ev er, b ounded rationality mo dels play ers that do not optimize their reward function [ Rubinstein and Dalgaard , 1998 ], the corresp onding literature aims to mo del a pro cess a choice for play ers not alwa ys maximizing their reward. Bounded computation refers to studies of games where play ers pay for the (time) complexity of the strategy they use. The notion of limited-capacity in latent games is a limitation on the represen tativ e p ow er of the function (or distribution) spaces. The literature has not thoroughly considered limitations on r epr esentational p ower – a gap that is critical to address, giv en that neural nets are no w a ma jor workhorse in AI and ML. Gauthier Gidel, Da vid Balduzzi, W o jciech Marian Czarnec ki, Marta Garnelo, Y oram Bac hrac h B Relev ance of the Minimax theorem in the Con text of Mac hine Learning A notorious ML application which has a minimax formulation is adversarial tr aining where a classifier is trained to b e robust against adversarial attac k. F rom a game-theoretic p ersp ective, the adversarial attack is pick ed after the classifier f is set and thus it corresp onds to a best resp onse. F rom a learning persp ective, the goal is to learn to be robust to adversarial attacks sp e cific al ly designe d against the curren t classifier. Such an equilibrium is called a Stac kelberg Equilibrium [ Conitzer and Sandholm , 2006 ]. In games with imperfect information such as Colonel Blotto, P ok er, or StarCraft I I the play ers m ust commit to a strategy without the knowledge of the strategy pick ed b y their opp onent. In that case, the agents cannot design attac ks sp ecific to their opp onent, b ecause such attacks may b e exploitable strategies. It is thus strictly equiv alent to consider that the play ers simultaneously pick their resp ective strategies and then reveal them. Thus, a meaningful notion of pla ying the game must hav e a v alue and an equilibrium. In machine learning applications, each pla yer is trained using lo cal information (though gradien t or RL based metho ds). Because the behavior of the pla yers changes slo wly , they cannot ha ve access to the best response against their opp onent. In order to illustrate that p oint, let us consider the example of Generative Adv ersarial Net works. The tw o agents (the generator and the discriminator) are usually sequentially updated using a gradient metho d with similar step-si zes. During training, one cannot exp ect an agent to find a b est resp onse in a single (or few) gradient steps. T o sum-up, since local up dates are p erformed one must exp ect to reac h a p oint (if it exists) that is lo cally stable. In this work, we show that there actually exists a glob al approximate equilibrium for a large class of parametrized games. C Pro of of results from Section 5 C.1 Pro of of Prop osition 1 Before pro ving this prop osition let us state Sion’s minimax theorem. Theorem 3 (Minimax theorem [ Sion et al. , 1958 ]) . If U and V ar e c onvex and c omp act sets and if the sublevel sets of ϕ ( ⋅ , v ) and − ϕ ( u, ⋅ ) ar e c onvex then, max u ∈ U min v ∈ V ϕ ( u, v ) = min u ∈ U max v ∈ V ϕ ( u, v ) (21) Let us no w state our prop osition. Prop osition 1. L et ϕ b e a game that fol lows Assumption 1 . If G Θ and F Ω ar e c omp act, then ther e exist a v alue for the game such that, V ( Ω , Θ ) ∶ = sup f ∈ hull ( F Ω ) inf q ∈ hull ( G Θ ) ˜ ϕ ( f , q ) = inf q ∈ hull ( G Θ ) sup f ∈ hull ( F Ω ) ˜ ϕ ( f , q ) , (14) wher e hull ( G Θ ) and h ull ( F Ω ) ar e either define d in ( 12 ) or in ( 13 ) , dep ending on the typ e mo del. Pr o of. F or simplicit y and conciseness w e note, F = F Ω and G = G Θ . The sets h ull ( F ) and h ull ( G ) are conv ex b y construction. How ev er, they are not compact in general. How ever, since G is assumed to b e a compact set we then ha ve that under mild assumptions (namely , that F and G b elong to a completely metrizable lo cally conv ex space) that the closure of h ull ( G ) is compact [ Alipran tis and Border , 2006 , Theorem 5.20]. Thus, we can apply Sion’s theorem to get, min p ∈⁐ ( hull ( G )) max f ∈⁐ ( hull ( F )) ˜ ϕ ( f , p ) = max f ∈⁐ ( hull ( F )) min p ∈⁐ ( hull ( G )) ˜ ϕ ( f , p ) (22) Moreo ver there exists ( w i ) i ≥ 0 , ( θ i ) i ≥ 0 , λ i ≥ 0 , ∑ i ≥ 0 λ i = 1 and ρ i ≥ 0 , ∑ i ≥ 0 ρ i = 1 such that, V ( Ω , Θ ) = ˜ ϕ i ≥ 0 λ i f w i , i ≥ 0 ρ i p θ i . (23) A Limited-Capacity Minimax Theorem for Noncon v ex-Nonconcav e Games 0 x 1 , 2 x 1 , 1 x 2 , 2 x 2 , 1 1 f 1 f 2 f 3 Input space: x ∈ [ 0 , 1 ] Output space: y = f ( x ) (a) ReLU netw orks of width p can represent any p -piecewise linear function. The point-wise a verage f 3 of tw o ReLU neural net works f 1 and f 2 is a piecewise linear function that can b e represented by a wider ReLU neural netw ork. 0 λ 1 I 2 I 1 g 1 g 2 g 3 Laten t space: z ∼ U ([ 0 , 1 ]) Output space: x ∼ g ( z ) (b) Laten t mixture of g 1 and g 2 : F or k ∈ { 1 , 2 , 3 } the transformation g k maps the uniform distribution on [ 0 , 1 ] in to a distribution on the output space: x ∼ p g i iff x = g i ( z ) , z ∼ U ([ 0 , 1 ]) . In that case, p g 1 and p g 2 are resp ectiv ely the uniform distribution ov er I 1 and I 2 . The function g 3 represen ts a distribution that puts half of its mass uniformly on I 1 and the other half on I 2 . Figure 2: Difference b etw een p oint wise a veraging of function and latent mixture of mapping. This comes from the fact that an y element in ⁐ ( h ull ( F )) can b e written as ∑ i ≥ 0 λ i f w i : Lemma 1. L et U b e a c omp act set that b elongs to a c ompletely metrizable lo c al ly c onvex sp ac e. Then the closur e of the c onvex hul l of U is c omp act and we have that ⁐ ( hull ( U )) = { ∑ i ≥ 0 λ i u i , λ i ≥ 0 , ∑ i ≥ 0 λ i = 1 , u i ∈ U } . Pr o of. Let us consider a sequence ( u n ) ∈ conv ( U ) N , we hav e u n = ∑ K n i = 0 λ i,n u i,n where u i,n ∈ U , ∀ i, n ∈ N . Since λ i,n ∈ [ 0 , 1 ] and u i,n ∈ U that are compact sets these sequences hav e a conv ergent subsequence. By Cantor diagonalization pro cess, ( x n ) has a con vergen t subsequence. C.2 Pro of of Theorem 2 W e will prov e a result a bit more general that the result stated in the main pap er, Theorem 4. L et ϕ a game that satisfies the assumptions of Pr op osition 1 . If ˜ ϕ is biline ar and ϕ is L -Lipschitz then, K Ω ≤ 4 D w 2 ln ( N ( Θ , 2 L )) and K Θ ≤ 4 D θ 2 ln ( N ( Ω , 2 L )) (24) wher e N ( H , ′ ) is the numb er of ′ -b al ls ne c essary to c over the set A and the quantities D w and D θ ar e define d as D w ∶ = max w,w ′ ,θ ϕ ( w , θ ) − ϕ ( w ′ , θ ) and D θ ∶ = max w,θ ,θ ′ ϕ ( w , θ ) − ϕ ( w , θ ′ ) . In the literature,the quantit y N ( H , ′ ) is called cov ering num b er of the set H . By definition of compactness, it is finite when H is compact. It is a complexity measure of the set H that has b een extensively studied in the con text of generalization b ounds [ Mohri et al. , 2012 , Shalev-Shw artz and Ben-David , 2014 ]. Pr o of. This pro of is largely inspired from the proof of [ Lipton and Y oung , 1994 , Theorem 2] and [ Arora et al. , 2017 , Theorem B.3]. The difference with [ Arora et al. , 2017 , Theorem B.3] is that w e make app ear a notion of condition num b er and we pro vide this pro of in a context more general than [ Arora et al. , 2017 , Theorem B.3] who w as fo cusing on GANs. One wa y to insure that D w amd D θ ha ve b ounded v alue is by assuming that Θ and Ω hav e a finite diameter, w e then ha ve that the v alues of D w and D θ are respectively b ounded by L diam ( Θ ) and L diam ( Ω ) . Note that is practice one also ma y hav e that the pay off is bounded betw een − 1 (losing) and 1 (winning). Gauthier Gidel, Da vid Balduzzi, W o jciech Marian Czarnec ki, Marta Garnelo, Y oram Bac hrac h By Prop osition 1 w e hav e that there exists f ∗ and p ∗ suc h V ( Ω , Θ ) = ˜ ϕ f ∗ , p ∗ , (25) where, f ∗ ∶ = ∞ k = 1 λ k f w k and p ∗ ∶ = ∞ k = 1 ρ k p θ k (26) where w k , θ k ∈ Ω × Θ , ρ k , λ k > 0 , ∑ ∞ k = 1 λ k = ∑ ∞ k = 1 ρ k = 1 . No w let us consider the mixture f ∗ n ∶ = 1 n n k = 1 f w k (27) where w k , 1 ≤ k ≤ n are defined in ( 26 ) and are drawn indep endently from the m ultinomial of weigh ts ( λ k ) k = 1 ... ∞ . Let assume that Θ has a finite cov ering num b er N ( Θ , /( 2 L )) (in the following we will show that if Ω is compact then, its co vering num ber is finite and we will giv e an explicit b ound on it when Ω ⊂ R p ). Let us recall that cov ering n umber of Θ is the smallest num b er of balls needed to cov er Θ . Let us consider θ i , 1 ≤ i ≤ N ( Θ , 2 L ) the center of these balls where L is the Lipsc hitz constant of ϕ . Using Ho effding’s inequality , for any θ i , 1 ≤ i ≤ N ( Θ , 2 L ) w e hav e that, P ( ˜ ϕ ( f ∗ n , p θ i ) − ˜ ϕ ( f ∗ , p θ i ) < / 2 ) ≤ e − n 2 2 D 2 w (28) where D w is a b ound on the v ariations of ϕ defined as D w ∶ = max w,w ′ ,θ ϕ ( w , θ ) − ϕ ( w ′ , θ ) . (29) Note that b ecause we assumed that ˜ ϕ is bilinear, the b ound on the v ariations of ϕ is also v alid for the v ariations of ˜ ϕ . More precisely , we hav e ˜ ϕ ( i λ i f w i , p θ ) − ˜ ϕ ( i λ ′ i f w ′ i , p θ ) = i λ i ( ϕ ( w i , θ ) − ϕ ( w ′ i , θ )) (30) ≤ i λ i D w = D w . (31) Th us, using standard union b ounds, P ˜ ϕ ( f ∗ n , p θ i ) − ˜ ϕ ( f ∗ , p θ i ) < / 2 , ∀ 1 ≤ i ≤ N ( G , 2 ˜ L ) ≤ N ( G , 2 ˜ L ) e − n 2 2 D 2 w (32) Let us no w consider ˆ p n ∈ arg min p ∈⁐ ( hull ( G )) ˜ ϕ ( f ∗ n , p ) = arg min θ ∈ Θ ˜ ϕ ( f ∗ n , p θ ) (33) Note that this minim um is achiev ed with q ∈ G b ecause w e assumed that the function ˜ ϕ is bilinear (and th us a minim um with resp ect to a conv ex h ull is alw ays achiev ed at an atom). 3 Th us there exists ˆ θ n ∈ Θ such that ˆ p n = p ˆ θ n . Since ϕ is L -Lipsc hitz and since we hav e that ( θ i ) is an 2 L -co vering there exists a θ i that is 2 L -close to ˆ θ n and th us, ˜ ϕ ( f ∗ n , p θ i ) − min p ∈⁐ ( hull ( G )) ˜ ϕ ( f ∗ n , p ) = n k = 1 1 n ( ϕ ( w k , θ i ) − ϕ ( w k , ˆ θ n )) ≤ / 2 . (34) 3 Note that we could get rid of the bilinear assumption b y replacing the cov ering num ber of Θ by the cov ering num b er of h ull ( G ) . Ho wev er the asymptotic b ehavior of the latter (when → 0 ) may be c hallenging to b ound. W e thus decided to fo cus on bilinear examples since the cov ering num b er for finite dimensional compact sets is a well studied quantit y . A Limited-Capacity Minimax Theorem for Noncon v ex-Nonconcav e Games When w e hav e that ˜ ϕ ( f ∗ , p θ i ) − ˜ ϕ ( f ∗ n , p θ i ) < / 2 (which is true with high probability) we hav e, min p ∈⁐ ( hull ( G )) ϕ ( f ∗ n , p ) ≥ ˜ ϕ ( f ∗ n , p θ i ) − / 2 (35) > ˜ ϕ ( f ∗ , p θ i ) − (36) = V ( Ω , Θ ) − (37) Th us for n > 4 D 2 w 2 ln ( N ( Θ , 2 L )) w e hav e, P min p ∈⁐ ( hull ( G )) ϕ ( f ∗ n , p ) > V ( Ω , Θ ) − < 1 (38) Since this probability is strictly smaller than one, for any ′ > 0 , among all the possible sampled f ∗ n there exist at least one suc h that min p ∈⁐ ( hull ( G )) ϕ ( f ∗ n , p ) > V L − . (39) Th us, K Ω ≤ 4 D 2 w 2 ln ( Θ , 2 L ) . (40) A similarly w e can prov e a b ound on K Θ . Then, w e will use a simple bound for the co vering num b er Θ ⊂ R d that can b e found in Shalev-Sh wartz and Ben-Da vid [ 2014 ], log N ( Θ , 2 L ) ≤ d log ( 4 LR d ) . (41) that leads to K Ω ≤ 4 D 2 w d 2 log ( 4 LR d ) (42) C.3 Pro of of Prop osition 3 Prop osition 3. L et w k ∈ [ − R , R ] p , k = 1 . . . K b e the p ar ameters of k neur al nets with p p ar ameters, ther e exists au neur al net p ar ametrize d by w ∈ [ − R, R ] K p , such that 1 n ∑ K k = 1 f w k = f w . Pr o of. W e will prov e this result for an arbitrary conv ex combination. Let us start with the pro of for a tw o-la yers neural net work of width W . It can b e written as g ( x ) = W i = 1 a i σ ( c ⊤ i x + d i ) + b i (43) where a i , b i ∈ R d out , c i ∈ R d , and d i ∈ R and σ is an y given non-linearity . Then, let us consider K suc h functions with p parameters, then an y conv ex combination of these K functions can b e written as, f ( x ) = K k = 1 W k i = 1 λ k ( a i,k σ ( c ⊤ i,k x + d i,k ) + b i,k ) (44) where λ k ≥ 0 , 1 ≤ k ≤ K and ∑ K k = 1 λ k = 1 . Setting ˜ a i,k ∶ = λ k a i,k and ˜ b i,k ∶ = λ k b i,k , w e hav e that f ( x ) = ( i,k ) ˜ a i,k σ ( c ⊤ i,k x + d i,k ) + ˜ b i,k (45) whic h is a neural netw ork using the non-linearity σ with K ⋅ p parameters. Gauthier Gidel, Da vid Balduzzi, W o jciech Marian Czarnec ki, Marta Garnelo, Y oram Bac hrac h Let us now consider K neural netw orks ( f w k ) k ∈ 1 ...K with p parameters w k ∈ [ − R, R ] p and the same architecture, and λ k ≥ 0 , 1 ≤ k ≤ K suc h taht ∑ K k = 1 λ k = 1 . By m ulti plying the last lay er of f k b y λ k and concatenating each la yer to get w ∈ [ − R , R ] p ⋅ K w e hav e that K k = 1 λ k f w k = f w (46) is a neural net work with K ⋅ p parameters. C.4 Pro of of Prop osition 2 Prop osition 2. L et θ k ∈ [ − R, R ] p , k = 1 . . . K, b e the p ar ameters of k R eLU nets with p p ar ameters. If the input latent variable is of dimension d in = 1 and if for al l k = 1 . . . K , z ∈ [ 0 , 1 ] , g θ k ( z ) ∈ [ 0 , 1 ] d and g θ k is c onstant outside of [ 0 , 1 ] , then ther e exists a R eLU net with K ( p + 6 ) non-line arities θ ∈ [ − K R , K R ] K ( p + 6 ) such that d T V ( 1 n ∑ K k = 1 q θ k , q θ ) ≤ 1 / R wher e d T V is the total variation distanc e. Pr o of. W e will prov e the first part of this theorem for an arbitrary num b er K of mappings. Let g b e a t wo-la yers ReLU net work of width p , the probability distribution π g induced b y g verifies, π g ( S ) = ` ( g − 1 ( S )) , ∀ S measurable in [ 0 , 1 ] d out . (47) where ` is the Lesb egues measure on [ 0 , 1 ] d . The conv ex combination π of π g 1 , . . . , π g K v erifies, π ( S ) ∶ = K k = 1 λ k π g k ( S ) = 1 ≤ k ≤ K λ k ` ( g − 1 k ( S )) Using the prop erties of the Lesb egues measure we hav e that ∀ λ > 0 , b ∈ R λ` ( U ) = ` ( λU + b ) , (48) where λU is the dilation of the set U and U + b its translation by b . thus, we hav e that for any b k ∈ R , k = 1 . . . K , π ( S ) = 1 ≤ k ≤ K ` ( λ k g − 1 k ( S ) + b k ) No w notice that, λ k g − 1 k ( S ) + b k = { λ k x + b k ∶ x ∈ [ 0 , 1 ] , g k ( x ) ∈ S } (49) = { x ∶ x ∈ [ b k , λ k + b k ] , g k ( x / λ k + b k ) ∈ S } (50) Then, setting b k ∶ = ∑ k − 1 i = 0 λ k ∈ [ 0 , 1 ] , w e get b y construction that b k + 1 = b k + λ k and thus that the sets S k ∶ = [ b k , λ k + b k ] are a partition of [ 0 , 1 ] . Finally , if we note ˜ g the function, ˜ g ( x ) = g k ( x / λ k + b k ) if x ∈ [ b k , b k + 1 ] (51) W e hav e by construction (and by the fact that S k are disjoin ts) π ˜ g ( S ) = 1 ≤ k ≤ K ` ( λ k g − 1 k ( S ) + b k ) = K k = 1 λ k π g k ( S ) (52) Ho wev er, the proof is not ov er because ˜ g ma y not be con tinuous it cannot correspond in general to a neural net work. W e will no w construct a neural netw ork that approximate the distribution induced b y ˜ g . Let us in tro duce the approximated "step" function h δ that is a ReLU net with 3 parameters and h δ ( x ) ∶ = 1 δ x + − 1 δ x − δ + = 0 if x < 0 1 if x > δ x / δ otherwise. (53) A Limited-Capacity Minimax Theorem for Noncon v ex-Nonconcav e Games Th us we can introduce the ReLU net ˜ g k defined as ˜ g k ( x ) ∶ = g k ( x / λ k + b k ) − g k ( 0 ) h δ ( − x + b k ) − g k ( 1 ) h δ ( x + b k + 1 ) (54) = 0 if x < b k or x > b k + 1 g k ( x / λ k + b k ) if b k + δ < x < b k + 1 − δ (55) The second line is due to the fact that w e assumed that g k ( x ) = g k ( 0 ) , ∀ x < 0 and g k ( x ) = g k ( 1 ) , ∀ x > 1 . Finally we hav e that the sum of ˜ g k for k = 1 , . . . K is a ReLU neural netw ork with K ( p + 6 ) parameters such that T V ( π , π ∑ k ˜ g k ) = sup S π ( S ) − π ∑ k ˜ g k ( S ) ≤ K δ Moreo ver, since g k has p parameters in [ − R, R ] w e hav e that ˜ g k has p + 6 parameters that are in [ − R / λ k , R / λ k ] . Since we assumed that the parameters of the ReLU net work should b e b ounded by K R w e hav e that we cannot pic k the parameters g k ( 0 )/ δ and g k ( 1 )/ δ larger than K R . Th us by setting λ k = 1 / K , there exists a ReLU netw ork with K ( p + 6 ) parameters in [ − K R , K R ] such that, T V ( π , π ∑ k ˜ g k ) = sup S π ( S ) − π ∑ k ˜ g k ( S ) ≤ 1 R C.5 Pro of of Theorem 1 Theorem 1. L et ϕ b e a L -Lipschitz nonc onc ave-nonc onvex game with values b ounde d by D that fol lows Assump- tion 1 for which the p ayoff ˜ ϕ is biline ar and ˜ L Lipschiz. The players ar e assume d to b e p ar ametrize d neur al networks g ∶ R d → R d out with p p ar ameters smal ler than R , and satisfies one of the thr e e fol lowing c ases: • Both players pick functions. F or any > 0 ther e exists ( w ∗ , θ ∗ ) ∈ [ − R, R ] 2 p s.t., min θ ∈ R p θ ≤ R ϕ ( w ∗ , θ ) + ≥ max w ∈ R p w ≤ R ϕ ( w , θ ∗ ) . (56) wher e p ≥ 2 D p log ( 4 L p / ) . • The first player picks distributions whose gener ating function is a R eLU nets with d in = 1 . The se c ond player picks functions. This is for instanc e the setting of W GAN (Example 2 ). F or any > 0 ther e exists ( w ∗ , θ ∗ ) ∈ [ − R, R ] 2 p s.t., min θ ∈ R p θ ≤ R ϕ ( w ∗ , θ ) + + ˜ L R ≥ max w ∈ R p w ≤ R ϕ ( w , θ ∗ ) . (57) wher e p ≥ 2 D p log ( 4 L p / ) − 6 , R ≥ R p p , and the subnetworks gener ating the distributions (se e Eq. 19 ) takes their values in [ 0 , 1 ] d and ar e c onstant outside of [ 0 , 1 ] . • Both players pick distributions whose gener ating function is a R eLU nets with d in = 1 . This is for instanc e the setting of the Blotto game (Examples 3 ). F or any > 0 ther e exists ( w ∗ , θ ∗ ) ∈ [ − R, R ] 2 p s.t., min θ ∈ R p θ ≤ R ϕ ( w ∗ , θ ) + + 2 ˜ L R ≥ max w ∈ R p w ≤ R ϕ ( w , θ ∗ ) . (58) wher e p ≥ 2 D p log ( 4 L p / ) − 6 , R ≥ R p p and the subnetworks gener ating the distributions (se e Eq. 19 ) takes their values in [ 0 , 1 ] d and ar e c onstant outside of [ 0 , 1 ] . Gauthier Gidel, Da vid Balduzzi, W o jciech Marian Czarnec ki, Marta Garnelo, Y oram Bac hrac h Pr o of. Let > 0 and let us consider ReLU netw orks with p parameters in [ − R , R ] (w e will set those quantities later). F or simplicity here Ω = Θ = [ − R , R ] p . Theorem 2 says that an -equilibrium can b e achiev ed with a uniform con vex combination of K net works. Let us consider the case where the first play er is a function and the second play er is a distribution. F or the first play er, one can apply Prop osition 3 to say that such a conv ex combination of K functions can b e expressed with a larger net work that has K ⋅ p parameters in [ − R , R ] . F or the second pla yer, once can apply Prop osition 2 to get that that such a uniform con v ex combination of K functions can b e expressed up to precision 1 / K R with a larger net work that has K ⋅ p parameters in [ − K R , K R ] . Th us we get that a sufficient condition for -appro ximate equilibrium of the game ϕ to be achiev ed by a ReLU net work with p parameters in [ − R , R ] is that, p ≥ ( p + 6 ) K and R ≥ K R (59) Let us set, p ∶ = 2 D p ln ( 4 LR p / ) − 6 and R ∶ = R p p (60) Using the fact that in Theorem 2 , K ≤ 4 D 2 2 p log 4 LR p w e hav e that ( p + 6 ) K ≤ 2 4 D 2 p ln ( 4 LR p / ) 4 D 2 2 log 4 LR p ≤ p (61) where w e used the fact that p ≤ p and R ≤ R . Moreo ver, since p ≥ ( p + 6 ) K w e hav e that, K R ≤ p p + 6 R ≤ R . (62) Finally , since in Prop osition 2 we approximate such uniform conv ex com bination up to a TV distance 1 / R and since w e assumed that ϕ w as ˜ L -Lipsc hitz (with resp ect to the TV distance) we hav e the additional ˜ L R term.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment