IdBench: Evaluating Semantic Representations of Identifier Names in Source Code
Identifier names convey useful information about the intended semantics of code. Name-based program analyses use this information, e.g., to detect bugs, to predict types, and to improve the readability of code. At the core of name-based analyses are …
Authors: Yaza Wainakh, Moiz Rauf, Michael Pradel
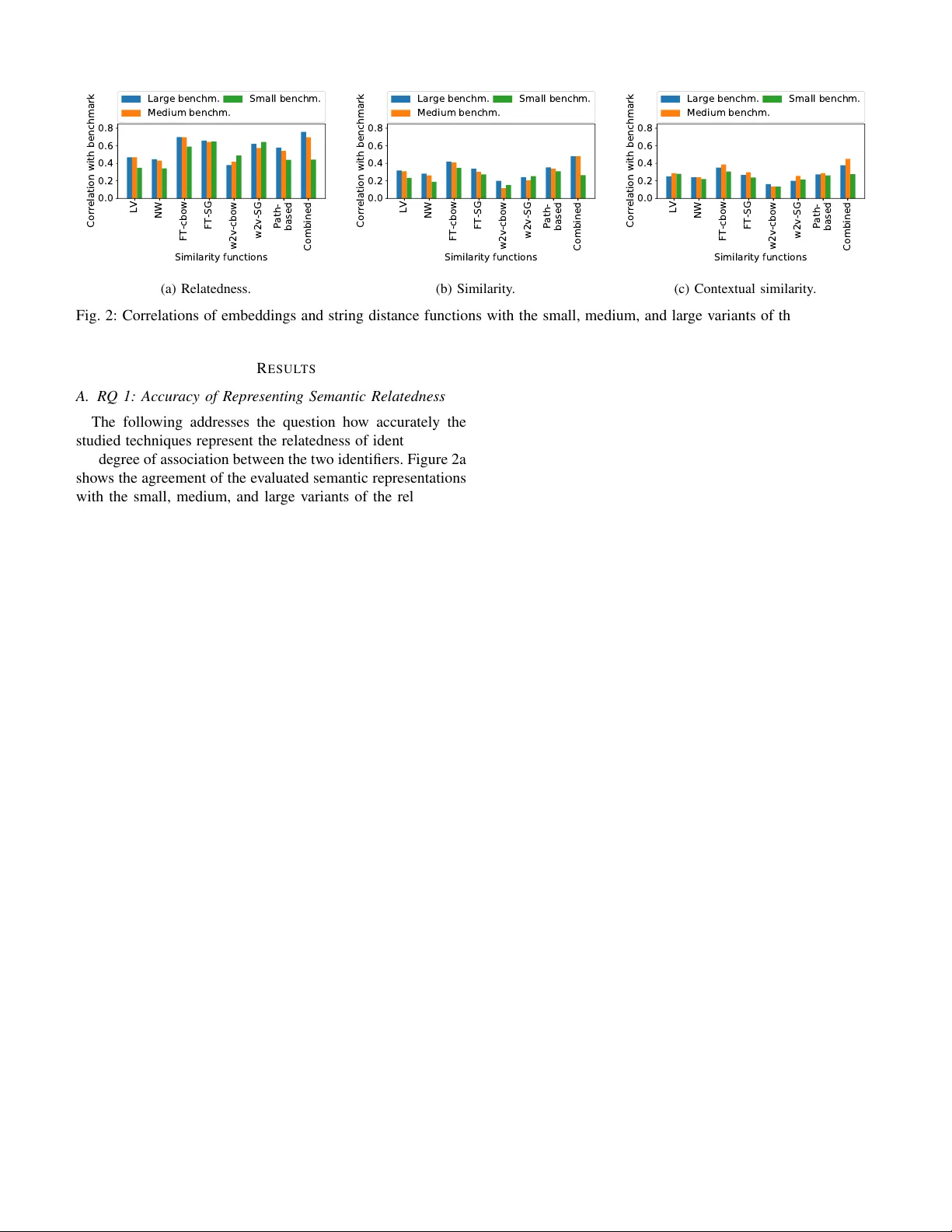
IdBench: Ev aluating Semantic Representations of Identifier Names in Source Code Y aza W ainakh Department of Computer Science TU Darmstadt Darmstadt, Germany yaza.wainakh@gmail.com Moiz Rauf Department of Computer Science University of Stuttgart Stuttgart, Germany moiz.rauf@iste.uni-stuttgart.de Michael Pradel Department of Computer Science University of Stuttgart Stuttgart, Germany michael@binaervarianz.de Abstract —Identifier names con vey useful information about the intended semantics of code. Name-based program analyses use this information, e.g ., to detect bugs, to predict types, and to improve the readability of code. At the core of name- based analyses are semantic representations of identifiers, e.g., in the form of learned embeddings. The high-level goal of such a repr esentation is to encode whether two identifiers, e.g., len and size , are semantically similar . Unfortunately , it is currently unclear to what extent semantic representations match the semantic r elatedness and similarity perceived by developers. This paper presents IdBench, the first benchmark for evaluating semantic repr esentations against a ground truth created from thousands of ratings by 500 software de velopers. W e use IdBench to study state-of-the-art embedding techniques proposed for natural language, an embedding technique specifically designed for source code, and lexical string distance functions. Our results show that the effectiveness of semantic representations varies significantly and that the best available embeddings successfully repr esent semantic relatedness. On the downside, no existing technique provides a satisfactory repr esentation of semantic similarities, among other reasons because identifiers with opposing meanings are incorrectly considered to be similar , which may lead to fatal mistakes, e.g., in a refactoring tool. Studying the strengths and weaknesses of the different techniques shows that they complement each other . As a first step toward exploiting this complementarity , we present an ensemble model that combines existing techniques and that clearly outperforms the best available semantic representation. Index T erms —sour ce code, neural networks, embeddings, iden- tifiers, benchmark I . I N T R O D U C T I O N Identifier names play an important role in writing, under - standing, and maintaining high-quality source code [1]. Be- cause they con ve y information about the meaning of variables, functions, classes, and other program elements, dev elopers of- ten rely on identifiers to understand code written by themselves and others. Be yond de velopers, v arious automated techniques analyze, use, and improve identifier names. For example, identifiers ha ve been used to find programming errors [2]– [5], to mine specifications [6], to infer types [7], [8], to predict the name of a method [9], or to complete partial code using a learned language model [10]. T echniques for This work was supported by the European Research Council (ERC, grant agreement 851895), and by the German Research Foundation within the ConcSys and Perf4JS projects. improving identifier names pinpoint inappropriate names [11] and suggest more suitable names [12]. The basic idea of all these approaches is to infer the intended meaning of a piece of code from the natural language information in identifiers, possibly along with other information, such as the structure of code, data flow , and control flo w . W e here refer to program analyses that rely on identifier names as a primary source of information as name-based analyses . Most name-based analyses reason about names in one of two ways. First, some approaches build upon string distance functions , such as the Le venshtein distance, sometimes in combination with algorithms for tokenizing names, e.g., based on underscore or camel-case notation [13]. Giv en a pair of identifiers, e.g. len and length , a string distance function yields a real-valued number that indicates to what extent the character sequences in the identifiers resemble each other . String distance functions are at the core of name-based anal- yses to detect name-related bugs [2], [3], to predict types [7], to impro ve identifier names [14], or to suggest appropriate names [15]. Second, another approach, which has become popular more recently , are neural network-learned embeddings of identifiers . An embedding maps each identifier into a continuous vector representation, so that similar identifiers are mapped to similar vectors. Embeddings implicitly define a similarity function via the cosine similarity of embedding vectors. For example, embeddings of identifiers are at the core of neural program analyses [16] to predict types [8], to detect bugs [4], to de-obfuscate code [17], to complete partial code [10], and to map API elements across programming languages [18]. The common aim of both string distance functions and embeddings of identifiers is to reason about the semantics of identifiers, and we hence call both of them semantic repr esen- tations of identifiers , or short semantic repr esentations . The ov erall effecti veness of a name-based analysis relies on the as- sumption that the underlying semantic representation encodes some kind of semantic relationship between identifiers. For example, two semantically similar identifiers, such as len and length , should be closer to each other than two unrelated identifiers, such as length and click . Despite the importance of semantic representations for name-based analyses, it is currently unclear how well e xisting approaches actually represent semantic relationships. Specifi- cally , we are interested in the follo wing questions: a) RQ 1: How accurately do state-of-the-art semantic r epresentations matc h the semantic relatedness of identifiers as per ceived by softwar e developers?: “Relatedness” here means the degree of association between tw o identifiers, which co vers various possible relations between them, e.g., being used in the same application domain or being opposites of each other . For example, top and bottom are related because they are opposites, click and dblclick are related because they belong to the same general concept, and getBorderWidth and getPadding are related because they belong to the same application domain. The relatedness of identifiers is relev ant for tools that reason about the broad meaning of code elements, e.g., to predict the types of functions [8], [19]. b) RQ 2: How accurately do state-of-the-art semantic r epresentations match the semantic similarity of identifier s as per ceived by softwar e developer s?: “Similarity” here means the degree to which two identifiers hav e the same meaning, in the sense that one could substitute the other without changing the overall meaning [20]. For example, length and size , as well as username and userid , are similar to each other . The similarity of identifiers is, e.g., relev ant for name-based bug detection tools [4], [21]. c) RQ 3: What are the str engths and weaknesses of the existing semantic r epr esentations?: Better understanding why particular techniques sometimes succeed or fail to accurately represent identifiers will enable improving the current seman- tic representations. d) RQ 4: Do the existing semantic r epresentations com- plement eac h other?: If current techniques are complementary , it may be possible to combine them in a way that outperforms the individual techniques. Addressing these questions relies on a way to measure and compare the effecti veness of semantic representations of identifiers in source code. This paper presents IdBench, the first benchmark for this task, which is based on a dataset of dev eloper assessments about the relatedness and similarity of pairs of identifiers. W e gather this dataset through surveys that show real-world identifiers and code snippets to hundreds of dev elopers, asking them to rate their semantic relationship. T aking the dev eloper assessments as a gold standard, IdBench allows for ev aluating semantic representations in a systematic way by measuring to what extent a semantic representation agrees with ratings gi ven by developers. Moreov er, inspecting pairs of identifiers for which a representation strongly agrees or disagrees with the benchmark helps understand the strengths and weaknesses of the representation. Applying our methodology to se ven widely used semantic representations leads to various nov el insights. W e find that different techniques differ heavily in their ability to accurately represent identifier relatedness and similarity . The best among the studied techniques, the CBO W variant of FastT ext [22], accurately represents the relatedness of identifiers (RQ 1), but none of the av ailable techniques accurately represents the similarity of identifiers (RQ 2). Studying the strengths and weaknesses of each technique (RQ 3) shows that some embeddings are confused about identifiers with opposite mean- ing, e.g., rows and cols , about identifiers that belong to the same application domain but are not similar, and about synonyms, e.g., file and record . Furthermore, practically all techniques struggle with identifiers that use abbre viations, which are v ery common in software. W e also find that simple string distance functions, which measure the similarity of identifiers without any learning, are surprisingly effecti ve, and ev en outperform some learned embeddings for the similarity task. A close inspection of the results sho ws that dif ferent tech- niques complement each other (RQ 4). T o benefit from the strengths of multiple techniques, we present a new semantic representation that combines the av ailable techniques into an ensemble model based on features of identifiers, such as the number of characters or whether an identifier contains non- dictionary words. The ensemble model clearly outperforms each of the e xisting semantic representations, impro ving agree- ment with dev elopers by 6% and 19% for relatedness and similarity , respecti vely . In summary , this paper makes the follo wing contributions. • A r eusable benchmark . W e make a vailable a benchmark of hundreds of pairs of identifiers, providing a way to systematically e valuate existing and future embeddings. 1 T o the best of our kno wledge, this is the first benchmark to systematically ev aluate semantic representations of identifiers. • Novel insights . Our study reveals both strengths and limitations of current semantic representations, along with concrete e xamples to illustrate them. These insights provide a basis for future w ork on better semantic repre- sentations. • A technique that outperforms the state-of-the-art . Com- bining the currently available techniques based on a few simple features yields a semantic representation that clearly outperforms all individual techniques. I I . M E T H O D O L O G Y T o measure and compare the accuracy of semantic represen- tations, we gather thousands of ratings from 500 de velopers (Section II-A). Cleaning and compiling this raw dataset into a benchmark yields se veral hundreds of pairs of identifiers with gold standard similarities (Section II-B). W e then measure the agreement between the gold standard and state-of-the- art semantic representations (Section II-C), where we study two string distance functions and fi ve learned embeddings (Section II-D). W e apply our methodology to Jav aScript code, because recent work on identifier names and code embeddings focuses on this language [4], [8], [17], [23], but our method- ology can also be applied to other languages. A. Developer Surve ys IdBench includes three benchmark tasks: A r elatedness task and two tasks to measure ho w well an embedding 1 https://github .com/sola- st/IdBench Identifiers: radians , angle 1) How r elated are the identifiers? Unrelated Related 2) Could one substitute the other? Not substitutable Substitutable (a) Direct surv ey . Which identifier fits best into the blanks? positions indices O p e n t i p . _ _ _ _ = [ " t o p " , " t o p R i g h t " , " r i g h t " , " b o t t o m R i g h t " , " b o t t o m " , " b o t t o m L e f t " , " l e f t " , " t o p L e f t " ] ; O p e n t i p . p o s i t i o n = { } ; _ r e f = O p e n t i p . _ _ _ _ ; (b) Indirect surv ey . Fig. 1: Examples of the dev eloper surveys. reflects the similarity of identifiers: a similarity task and a contextual similarity task . The follo wing describes how we gather dev eloper assessments that provide data for these tasks. The supplementary material provides additional examples and details of the surve y setup. a) Dir ect Survey of De veloper Assessments: This surve y shows two identifiers to a developer and then directly asks how related and ho w similar the identifiers are. Figure 1a shows an example question from the survey . The developer is sho wn pairs of identifiers and is then asked to rate on a fi ve-point Likert scale how related and how similar these identifiers are to each other . In total, each dev eloper is shown 18 pairs of identifiers, which we randomly sample from a larger pool of pairs. Before sho wing the questions, we provide a brief description of what the de velopers are supposed to do, including an explanation of the terms “related” and “substitutable”. The ratings gathered in the direct survey are the basis for the relatedness task and the similarity task of IdBench. b) Indir ect Survey of De veloper Assessments: This sur- ve y asks de velopers to pick an identifier that best fits a given code context, which indirectly asks about the similarity of identifiers. The motiv ation is that identifier names alone may not pro vide enough information to fully judge ho w similar the y are [20]. For example, without any context, identifiers idx and hl may cause confusion for de velopers who are trying to judge their similarity . The survey addresses this challenge by showing the code context in which an identifier occurs, and by asking the dev elopers to decide which of two giv en identifiers best fits this context. If, for a specific pair of identifiers, the developers choose both identifiers equally often, then the identifiers are likely to be similar to each other , since one can substitute the other . Figure 1b shows a question ask ed during T ABLE I: Occurrences of IdBench identifiers in code corpora of different languages. T otal occurrences Occurrences of individual identifiers Language Number Perc. Min Mean Max Jav aScript 3,697,498 12.5% 62 7,639 629,413 Python 2,279,866 14.8% 0 4,710 1,367,832 Jav a 757,064 6.3% 0 1,564 119424 the indirect surv ey . As sho wn in the e xample, for code conte xts where the identifier occurs multiple times, we show multiple blanks that all refer to the same identifier . In total, we sho w 15 such questions to each participant of the survey , where the 15 identifier pairs are randomly selected from the set of all studied pairs. The ratings gathered in the indirect survey are the basis for the contextual similarity tasks of IdBench. c) Selection of Identifiers and Code Examples: W e se- lect identifiers and code contexts from a corpus of 50,000 Jav aScript files [24]. W e select 300 pairs, made out of 488 identifiers, through a combination of automated and manual selection, aimed at a di verse set that cov ers different degrees of similarity and relatedness. At first, we extract from the code corpus all identifier names that appear more than 50 times, including method names, variable names, property names, and other types of identifiers. A nai ve approach would be to randomly sample pairs among those identifiers. Howe ver , this naive approach would result almost only in unrelated and dissimilar identifier pairs. Instead, we follow a methodology proposed for natural language [25], which ranks all pairs based on the cosine similarity according to a giv en embedding, and then selects pairs from different ranges in the ranking. W e select pairs using two embeddings [17], [26]. The fact that these embeddings are later also ev aluated with the benchmark does not introduce bias because the ground truth of the benchmark is constructed only from the human ratings, not from the embeddings. In addition to pairs selected as suggested in [25], we manually select some synonym pairs, which we observed to lack otherwise, and add randomly selected pairs, which are likely to be unrelated. The manual selection was done before ev aluating any semantic representations to a void biasing the benchmark. T o gather the code contexts for the indirect surve y , we search the code corpus for occurrences of the selected identi- fiers. As the size of the context, we choose fi ve lines, aiming to provide sufficient context to pick the best identifier without ov erwhelming the study participants with large amounts of code. F or each identifier , we randomly select fiv e different contexts. When showing a specific pair of identifiers to a dev eloper, we randomly select one of the gathered contexts for one of the two identifiers. T able I shows how often the selected identifiers occur in the Jav aScript corpus. Overall, the identifiers in IdBench occur 3.7 million times, which covers 12.5% of all identifier occur- rences. Ev en though this was not a criterion when selecting the identifiers, the benchmarks cov ers a non-negligible portion of real-world code. The table also shows how often individual identifiers occur , which is 7,639 times, on average. T o assess whether IdBench could also be used for other languages, we also measure the occurrences in Python [27] and Jav a code corpora [28] with 50,000 files each. As sho wn in T able I, the identifiers are also frequent in code beyond Ja vaScript, with an a verage number of occurrences of 4,710 and 1,564 in the Python and Jav a corpora, respectiv ely . A manual analysis shows that identifiers that occur across languages co ver general programming terminology , whereas identifiers that appears in Jav aScript only are mostly specific to the web domain, e.g., tag_h4 or DomRange . T o better understand whether IdBench co vers identifiers that appear in different syntactic roles, we measure for each identifier how often it used as a function name, v ariable name, or property name. W e then assign each identifier to one of these roles based on whether the majority of its occurrences is in a specific role. The measurements show that 17% of the identifiers are primarily function names, 18% are primarily variables names, 34% are primarily property names, and the rest is commonly used in multiple roles. d) P articipants: W e recruit dev elopers to participate in the surve y in se veral ways. About half of the participants are volunteers recruited via personal contacts, posts in public de- veloper forums, and a post in an internal forum within a major software company . The other half of the participants were recruited via Amazon Mechanical T urk, where we offered a compensation of one US dollar for completing both surve ys. On av erage, participants took around 15 minutes to complete both surveys. That is, the of fered compensation matches the av erage salary of software dev elopers in some countries of the world. 2 In total, 500 developers participate in the survey . Most participants li ve in North America and in India, and they hav e at least fiv e years of experience in software de velopment. B. Data Cleaning Crowd-sourced surveys may contain noise, e.g., due to lack of expertise or in volv ement by the participants [29]. T o address this challenge, we gather at least ten ratings per pair of identifiers and then clean the data based on the inter-rater agreement, which has been found ef fecti ve in other crowd- sourced surve ys [30]. a) Removing Outlier P articipants: As a first filter , we remov e outlier participants based on the inter-rater agreement, which measures the degree of agreement between participants. W e use Krippendorf ’ s alpha coefficient, because it handles unequal sample sizes, which fits our data, as not all participants rate the same pairs and not all pairs have the same number of ratings. The coef ficient ranges between zero and one, where zero represents complete disagreement and one represents perfect agreement. For each participant, we calculate the difference between her rating and the av erage of all the other ratings for each pair . Then, we average these differences for each rater , and discard participants with a difference above 2 https://www .payscale.com/research/IN/Job=Software Developer/Salary T ABLE II: Benchmark sizes and inter -rater agreement (IRA). Size Thresholds T ask τ θ Relatedness Similarity Contextual simil. Pairs IRA Pairs IRA P airs Small 0.215 0.4 167 0.67 167 0.62 115 Medium 0.23 0.5 247 0.61 247 0.57 145 Large 0.25 0.6 291 0.56 291 0.51 176 T ABLE III: Pairs of identifiers with their gold standard simi- larities. Score Identifier 1 Identifier 2 Related- Similar- Conte xtual ness ity similarity substr substring 0.94 1.00 0.89 setMinutes setSeconds 0.91 0.22 0.06 reset clear 0.90 0.89 0.94 rows columns 0.88 0.08 0.22 setInterval clearInterval 0.86 0.09 0.34 count total 0.83 0.81 0.79 item entry 0.78 0.77 0.92 miny ypos 0.68 0.37 0.02 events rchecked 0.16 0.14 0.18 re destruct 0.06 0.02 0.02 a threshold τ (values giv en in T able II). W e perform this computation both for the relatedness and similarity ratings from the direct surv ey , and then remove outliers based on the av erage difference across both ratings. b) Removing Downer P articipants: As a second filter , we eliminate participants that decrease the overall inter-rater agreement (IRA). W e call such participants downers [31], because they bring the agreement le vel between all participants down. For each participant p , we compute IRA sim and IRA rel before and after removing p from the data. If IRA sim or IRA rel increases by at least 10%, then we discard that participant’ s ratings. c) Removing Outlier P air s: As a third filter , we eliminate some pairs of identifiers used in the indirect survey . Since our random selection of code contexts may include contexts that are not helpful in deciding about the most suitable identifier , the ratings for some pairs may be misleading. For example, this is the case for code contexts that contain short and meaningless identifiers or that mostly consist of comments unrelated to the missing identifier . T o mitigate this problem, we remove a pair if the difference in similarity as rated in the direct and indirect surve ys exceeds some threshold θ (values giv en in T able II). T able II shows the number of identifier pairs that remain in the benchmark after data cleaning. For each of the three tasks, we provide a small , medium , and lar ge benchmark, which differ in the thresholds used during data cleaning. The smaller benchmarks use stricter thresholds and hence pro vide higher agreements between the participants, whereas the larger benchmarks offer more pairs. The thresholds are selected to strike a balance between increasing the o verall inter-rater agreement while keeping enough pairs and ratings to form a representativ e benchmark. C. Measuring Agr eement with the Benchmark Giv en the ground truth similarities and a semantic repre- sentation technique, we want to measure to what extent both agree with each other . a) Con verting Ratings to Scor es: As a first step of measuring the agreement with the benchmark, we con vert the ratings gathered for a specific pair during the dev eloper surve ys into a similarity score in the [0 , 1] range. For the direct surve y , we scale the 5-point Likert-scale ratings into the [0 , 1] range and a verage all ratings for a specific pair of identifiers. For the indirect survey , we use a signal detection theory-based approach for con verting the collected ratings into numeric values, which has been pre viously used to create a similarity benchmark for natural languages [20]. This con version yields an unbounded distance measure d for each pair , which we con vert into a similarity score s by normalizing and in verting the distance: s = 1 − d − min d max d − min d where min d and max d are the minimum and maximum distances across all pairs. b) Examples: T able III sho ws representative examples of identifier pairs and their scores for the three benchmark tasks. 3 The examples illustrate that the scores match human intuition and that the gold standard clearly distinguishes relatedness from similarity . Some of the highly related and highly similar pairs, e.g., substr and substring , are le xically similar , while others are synonyms, e.g., count and total . The identifiers rows and columns are strongly related, but one cannot substitute the other, and they hence hav e low similarity . Similarly miny , ypos represent distinct properties of the variable y , which is why they are related but not similar . Finally , some pairs are either weakly or not at all related, e.g., re and destruct . c) Corr elation with benchmark: W e measure the magni- tude of agreement of a semantic representation with IdBench by computing Spearman’ s rank correlation between the simi- larities of pairs of identifier vectors according to the semantic representation and our gold standard of similarity scores. Definition 1 (Correlation with benchmark): Given n pairs ( s i , g i ) of similarity scores, where s i is computed by a se- mantic representation and g i is the gold standard, let r ank ( s i ) and r ank ( g i ) be the ranks of s i and g i , respectiv ely . The cor- relation of the semantic representation with the benchmark is r = cov ( rank ( s i ) , rank ( g i )) σ rank ( s i ) σ rank ( g i ) where cov and σ are cov ariance and standard deviation of the rank variables, respecti vely . The correlation ranges between 1 (perfect agreement) and -1 (complete disagreement). For string distance functions, we compute the similarity score s i = 1 − d norm for each pair based on a normalized version d norm of the distance returned by the string distance function. W e use Spearman’ s rank corre- lation because directly comparing absolute similarities across different embeddings may be misleading [32]. The reason is 3 The full list of identifiers pairs is av ailable for do wnload as part of our benchmark. that, depending on ho w “wide” or “narro w” an embedding space is, a cosine similarity of 0.3 may mean a rather high or a rather lo w similarity . A rank-based comparison, as pro vided by Spearman’ s rank correlation, is more rob ust to dif ferent ways of populating the embedding space with identifiers than computing the correlation of absolute similarities. D. Embeddings and String Distance Functions T o assess ho w accurately existing semantic representations encode the relatedness and similarity of identifiers, we e v aluate sev en semantic representations against IdBench: T wo string distance functions and fiv e learned embeddings. String distance functions use lexical similarity as a proxy for the semantic relatedness of identifiers. W e consider these functions because the y are used in name-based b ug detec- tion tools [2], including a bug detection tool deployed at Google [3], to improv e identifier names [14], and to suggest appropriate names [15]. The two string distance functions we ev aluate are: • “L V”: Levenshtein’ s edit distance, which is the number of character insertions, deletions, and substitutions required to transform one identifier into another . • “NW”: Needleman-W unsch distance [33], which gen- eralizes the Lev enshtein distance by computing global alignments of two strings. Learned embeddings are popular in recent name-based analyses, e.g., for bug detection [4], type prediction [8], and for predicting names and types of program elements [17]. The fiv e learned embeddings we ev aluate are: • “w2v-cbow”: The continuous bag of words variant of W ord2vec [26], [34]. • “w2v-sg”: The skip-gram variant of W ord2vec . • “FT -cbo w”: The continuous bag of words v ariant of F astT ext [22], a sub-word extension of W ord2vec that represents words as character n-grams. • “FT -sg”: The skip-gram v ariant of F astT ext . • “path-based”: An embedding technique specifically de- signed for code, which learns from paths through a structural, tree-based representation of code [17]. W e train all embeddings on the same code corpus of 50,000 Jav aScript files [24]. For each embedding, we experiment with v arious hyper-parameters (e.g., dimension, number of context words) and report results only for the best performing models. 4 W e provide all identifiers as they are to the semantic representations, without pre-processing or tokenizing identi- fiers. The rationale is that such pre-processing should be part of the semantic representation. For example, the NW string distance function aligns the characters of identifiers, and the FastT ext embeddings split identifiers into character n-grams, which may enable these techniques to reason about subtokens of an identifier . LV NW FT-cbow FT-SG w2v-cbow w2v-SG Path- based Combined Similarity functions 0.0 0.2 0.4 0.6 0.8 Correlation with benchmark Large benchm. Medium benchm. Small benchm. (a) Relatedness. LV NW FT-cbow FT-SG w2v-cbow w2v-SG Path- based Combined Similarity functions 0.0 0.2 0.4 0.6 0.8 Correlation with benchmark Large benchm. Medium benchm. Small benchm. (b) Similarity . LV NW FT-cbow FT-SG w2v-cbow w2v-SG Path- based Combined Similarity functions 0.0 0.2 0.4 0.6 0.8 Correlation with benchmark Large benchm. Medium benchm. Small benchm. (c) Contextual similarity . Fig. 2: Correlations of embeddings and string distance functions with the small, medium, and large variants of the benchmark. I I I . R E S U LT S A. RQ 1: Accuracy of Repr esenting Semantic Relatedness The following addresses the question ho w accurately the studied techniques represent the relatedness of identifiers, i.e., the degree of association between the two identifiers. Figure 2a shows the agreement of the ev aluated semantic representations with the small, medium, and large variants of the relatedness benchmark in IdBench. All techniques achiev e relati vely high lev els of agreement, with correlations between 41% and 74%. The neurally learned embeddings clearly outperform the string distance-based similarity functions (41-74% vs. 46-49%), showing that the ef fort of learning a semantic representation is worthwhile. In particular , the learned embeddings match or ev en slightly exceed the inter-rater agreement, which is considered an upper bound of ho w strongly an embedding may correlate with a similarity-based benchmark [31]. Comparing different embedding techniques with each other , we find that both FastT e xt variants achie ve higher scores than all other embeddings. In contrast, despite using additional structural information of source code, path-based embeddings score only comparably to W ord2v ec. A likely reason for the effecti veness of FastT ext is that it generalizes across lexically similar names by computing embeddings based on character n-grams of an identifier . E.g., giv en the identifier getIndex , FastT ext computes its embed- ding based on embeddings for its various characters n-grams, such as Index and Ind , allowing the approach to generalize across le xically similar identifiers, such as setIndex or ind . B. RQ 2: Accuracy of Repr esenting Semantic Similarity This research question is about the semantic similarity , i.e., the degree to which two identifiers have the same meaning. Figure 2b shows how much the studied semantic representa- tions agree with the similarity benchmark in IdBench. Overall, the figure sho ws a much lower agreement with the gold standard than for relatedness. One explanation is that encoding semantic similarity is a harder task than encoding the less strict 4 Details on the hyperparameters and ho w we tuned them are a vailable in the supplementary material. concept of relatedness. Similar to relatedness, FT -cbow shows the strongest agreement, ranging between 35% and 38%. The results of the contextual similarity task (Figure 2c) confirm the findings from the similarity task. All studied techniques are less effecti ve than for relatedness, and FT -cbo w achiev es the highest agreement with IdBench. A perhaps surprising result is that string distance functions are roughly as ef fectiv e as some of the learned embeddings and sometimes even outperform them. The reason is that some semantically similar identifiers are also le xically similar , e.g., len and length . One do wnside of string distance functions is that they miss synonymous identifiers, e.g., count and total . C. RQ 3: Str engths and W eaknesses of Existing T ec hniques T o better understand the strengths and weaknesses of the studied semantic representations, we inspect v arious examples (Section III-C1) and study interesting subsets of all identifier pairs in isolation (Section III-C2). 1) Examples: T o better understand why current embeddings sometimes fail to accurately represent similarities, T able IV shows the most similar identifiers of selected identifiers ac- cording to the FT -cbow and path-based embeddings. The examples illustrate two observations. First, FastT ext, due to its use of n-grams [22], tends to cluster identifiers based on lexical commonalities. While many lexically similar identifiers are also semantically similar, e.g., substr and substring , this approach misses other synonyms, e.g., item and entry . Another downside is that lexical similarity may also es- tablish wrong relationships. For example, substring and substrCount represent dif ferent concepts, but FastT ext finds them to be highly similar . Second, in contrast to FastT e xt, path-based embeddings tend to cluster words based on the structural and syntactical contexts they occur in. This approach helps the embeddings to identify synonyms despite their lexical dif ferences, e.g., count and total , or files and records . The do wn- side is that it also clusters various related but not similar identifiers, e.g., minText and maxText , or substr and getPadding . Some of these identifiers even ha ve opposing T ABLE IV: T op-5 most similar identifiers by the FT -cbow and path-based models. Identifier Embedding Nearest neighbors substr FT -cbow substring substrs subst substring1 substrCount Path-based substring getInstanceProp getPadding getMinutes floor item FT -cbo w itemNr itemJ itemL itemI itemAt Path-based entry child record targ ne xtElement count FT -cbo w countTbl countInt countR TO countsAsNum countOne Path-based total limit minV al e xponent rate rows FT -cbow ro wOrRows ro wXs rows l rowsAr rowIDs Path-based cols cells columns tiles items setInterval FT -cbo w resetInterv al setT imeoutInterval clearInterval getInterval retInterval Path-based clearInterval assume alert ne xtTick ReactT extComponent minT ext FT -cbo w maxT ext minLengthT ext microsecT ext maxLengthT ext minuteT ext Path-based maxT ext displayMsg blankT ext disableT ext emptyT ext files FT -cbow filesObjs filesGen fileSets extFiles libFiles Path-based records tasks names tiles todos miny FT -cbo w min y minBy minx minPt min z Path-based minx ymin dataMax dataMin ymax meanings, e.g., rows and cols , which can mislead code analysis tools when reasoning about the semantics of code. 2) Inter esting Subsets of All Identifier P airs: T o better understand the strengths and weaknesses of semantic repre- sentations for specific kinds of identifiers, we analyze some interesting subsets of all identifier pairs in more detail. W e focus on four subsets: • Abbre viations . Pairs where at least one identifier is an abbreviation and where both identifiers refer to the same concept, e.g., substr and substring , or cfg and conf . Since abbre viations are commonly used for con- cise source code, accurately reasoning about them is important. • Opposites . Pairs where one identifier is the oppo- site of the other identifier , e.g., xMin and xMax , or setInstanceProp and getInstanceProp . Since opposite identifiers often occur in similar contexts, they may be difficult to distinguish. • Synonyms . Pairs that refer to the same concepts, e.g., reset and clear , or emptyText and blankText . These identifiers often are lexically different but should be represented in a similar way . • Added subtoken . Pairs where both identifiers are identical, except that one adds a subtoken to the other , e.g., id and sessionid , or maxLine and maxLineLength . • T rick y tokenization . Pairs where at least one of the identifiers is composed of multiple subtokens b ut uses neither camel case nor snail case to combine subtokens, e.g., touchmove and touchend , or newtext and content . This and the above subset are interesting be- cause some semantic representations reason about subto- kens of identifiers. T o e xtract pairs into these subsets, we inspect all 167 pairs from the small benchmark, which yields between 7 and 22 pairs per set. 0.5 0.0 0.5 Abbrevia- tions Relatedness Similarity Contextual similarity 0.5 0.0 0.5 Opposites 0.5 0.0 0.5 Synonyms 0.5 0.0 0.5 Added subtoken LV NW FT-cbow FT-SG w2v-cbow w2v-SG Path-based 0.5 0.0 0.5 Tricky tokenization LV NW FT-cbow FT-SG w2v-cbow w2v-SG Path-based LV NW FT-cbow FT-SG w2v-cbow w2v-SG Path-based Fig. 3: Agreement and disagreement with the benchmark for different kinds of identifiers. Figure 3 shows how much the different techniques agree or disagree with the benchmark for selected subsets. As in Figure 2, each bar shows the Spearman rank correlation between the predicted similarities and the ground truth. That is, higher v alues are better and negati ve values indicate a clear disagreement with the ground truth. The results sho ws that all techniques are challenged by abbreviations, with more than half of the correlations being negati ve. The poor performance for abbre viations can be at- tributed to the f act that fewer characters provide less informa- tion and that there may be many v ariants of the same name. F or opposites and synonyms, we find that most techniques, and in particular the learned embeddings, successfully represent the relatedness of these identifiers. Howe ver , almost all techniques clearly fail to capture that opposite identifiers are not similar , as one cannot replace the other , and to capture that synon yms are similar . For the subtoken-related subsets, we find that most tech- niques are challenged by pairs where one identifier adds a subtoken to the other , in particular , when reasoning about similarity . One explanation is that identifiers with an added subtoken tend to be rather specialized, and hence, occur less frequent, which giv es less training data to the learning-based techniques. When being faced with identifiers that use non- obvious tokenization, most techniques, with the exception of Needleman-W unsch, perform relatively well. W e attribute this result to the fact that techniques that reason about substrings of an identifier , such as FastT ext [22], do not rely on a specific tokenization approach, such as camel case or snail case, but instead consider character n-grams of the giv en identifier . D. RQ 4: Complementarity of Existing T echniques Our inspection of examples and of specific subsets of identifier pairs shows that different semantic representation techniques work well for different kinds of identifiers. F or example, some techniques work better for abbreviations than others. Based on this observation, we hypothesize that the existing semantic representations complement each other . If this hypothesis is correct, combining techniques in such a way that the most suitable set of techniques is used for a giv en pair of identifiers could represent similarities more accurately than any of the indi vidual techniques. T o v alidate this hypothesis, we present an ensemble model that combines e xisting semantic representations. The key idea is to train a model that predicts the similarity of two identifiers based on the similarity scores provided by the existing seman- tic representations. T o this end, the approach queries each of the sev en techniques studied in this paper for a similarity score and provides these scores to the model. T o help the model decide what representations to fa vor for a gi ven pair of identifiers, we also pro vide to the model a set of features that describe some properties of identifiers. Given two identifiers, the features we consider are: • The length of these identifiers. • The number of subtokens in each of the identifiers, based on snail case and camel case con ventions. • The number of words among the subtokens that are not in an English dictionary . The rationale for this feature is to identify abbreviations, which usually are not dictionary words. Giv en the seven similarity scores and the features, we train a model that takes the scores and features of a pair as an input, and then that predicts a similarity score for the pair . W e train the model in a supervised way , using the ground truth provided in IdBench as the labels for learning. W e use an off-the-shelf support vector machine model with the default hyperparameters provided by the underlying library 5 . In practice, one would train the model with all pairs in our benchmark and then apply the trained model to new pairs. T o enable us to measure the effecti veness of the model, we here train it with all but one pair , and then apply the trained model to the left-out pair . W e repeat this step for each pair and use the score predicted by the model as the score of the combined technique. Figure 2 shows the results of the combined approach. Com- bining different semantic representations clearly outperforms all existing techniques. For example, for the large benchmark, the combined approach increases the relatedness, similarity , and contextual similarity of the best individual technique by 6%, 19%, and 5%, respectiv ely . This result confirms our hypothesis that the existing techniques complement each other and shows the benefits of combining them. I V . D I S C U S S I O N This section discusses some lessons learned from our study of semantic representations, along with ideas for addressing the current limitations in future work. a) Neurally learned embeddings accurately repr esent the r elatedness of identifiers: Overall, all neural embeddings con- sidered in our ev aluation pro vide a high agreement with the ground truth pro vided by the relatedness scores in IdBench. This result sho ws that embeddings are ef fectiv e at assigning similar vector representations to identifiers that occur in the same application domain or that are associated in some other way . b) No e xisting technique accurately repr esents the sim- ilarity of identifiers: While the best available embeddings are highly ef fectiv e at representing relatedness, none of the studied techniques reaches the same level of agreement for similarity . In fact, e ven the best results in Figures 2b and 2c (38%) clearly stay beyond the inter -rater agreement of our benchmark (62%), showing a huge potential for improvement. For many applications of embeddings of identifiers, semantic similarity is crucial. For example, techniques that suggest suitable v ariable or method names [9], [17] aim for the name that is most similar, not only most related, to the concept represented by the v ariable or method. Like wise, name-based analyses for finding programming errors [4] or variable mis- uses [21] aim at identifying situations where the de veloper uses a wrong b ut perhaps related variable. Improving the ability of 5 Class sklearn.svm.SVR from scikit-learn. semantic representations to accurately represent the similarity of identifiers will benefit these name-based analysis. c) Neural embeddings g enerally outperform string dis- tance functions: Our results for both relatedness and similarity show that the best av ailable neural embeddings outperform classical string distance functions. For example, for the re- latedness benchmark, the string distance functions achie ve up to 49% correlation, whereas embeddings achie ve up to 74% correlation. For the similarity and contextual similarity benchmarks, the differences are smaller (32% vs. 38% for similarity , and 29% vs. 36% for contextual similarity), but still clearly visible. These results suggest that name-based analyses are likely to benefit from using embeddings instead of string distance functions. d) Opposite ar e challenging: Inspecting examples of (in)accurately represented pairs of identifiers sho ws that identi- fiers that describe opposing concepts are particularly challeng- ing for current semantic representations. For example, both the FT -cbow and path-based embeddings assign similar vectors to minText and maxText , even though these identifiers are clearly not similar but only related. Another example are the setInterval and clearInterval function names. T able IV shows these and other examples of this phenomenon. Improving semantic representations to better distinguish iden- tifiers with opposing meaning will benefit name-based anal- yses that, e.g., suggest method names [9] or refactorings of identifiers [12]. e) Distinguishing singular and plural identifiers is par - ticularly challenging: Another challenge we observe while inspecting pairs of inaccurately represented pairs of identifiers is to distinguish identifiers of individual items from identifiers of collections of items. For example, FT -cbo w assigns very similar vectors to substr and substrs (T able IV). Such a conflation of singular and plural concepts may be misleading, e.g., for name-based analyses that predicts types [7], [8], [19]. f) Shar ed subwor d information may be misleading: String distance functions and, to some e xtent, also subword- based embeddings, such as FastT e xt, rely on the assumption that substrings shared by two identifiers increase the chance that the identifiers are semantically similar . While a subword- based approach helps deal with the out-of-vocab ulary prob- lem [35], it may also mislead the semantic representation. For example, the FT -cbow embedding assigns similar vectors to minText and minuteText , as well as to setInterval and clearInterval , as these identifiers share subwords, ev en though the identifiers refer to clearly different concepts. g) Expanding abbre viations may impr ove semantic r ep- r esentations: The finding that practically all existing seman- tic representations have dif ficulties with abbreviations raises the question how to address this limitation. One promising direction is to expand abbreviations into longer identifiers before querying for their relatedness or similarity to another identifier . Sev eral techniques for expanding identifiers hav e been proposed [36]–[40], which could possibly be used as a preprocessing step within semantic representations. h) Differ ent semantic r epr esentations complement each other: The a vailability of dif ferent techniques for reason- ing about the similarity of identifiers can be exploited by combining multiple such techniques. Our ensemble model (Section III-D) shows the potential of combined approaches. V . T H R E A T S T O V A L I D I T Y A. Thr eats to Internal V alidity Threats to internal validity are about factors that may influence our results. The identifiers and the code examples associated with them may not be representative of other code. T o mitigate this threat, we gather data from a large and diverse code corpus, and we select identifiers that cover semantically similar and dissimilar pairs of identifiers (Section II-A0c). The decision to perform our work with code written in a dynamically typed programming language, Ja vaScript, biases our results toward such languages. The reason for focusing on a dynamically typed language is that such languages are the target of v arious name-based analyses [4], [7], [8], [19], [41], [42] and embedding techniques [17], [23]. Some ratings gathered our surv eys may be inaccurate, e.g., because participants may hav e misunderstood the instructions. T o mitigate this threat, we gather at least ten ratings per pair of identifiers and then carefully clean the ratings gathered by dev elopers to remove noise and outliers (Section II-B). B. Thr eats to External V alidity Threats to external v alidity are about factors that may influence the generalizability of our results. One limitation is that IdBench focuses on indi vidual identifiers only . As a result, it is not clear to what extent our ev aluation of semantic representations of identifiers allows for conclusions about representations at a larger granularity , e.g., of complex expressions, statements, or sequences of statements. W e focus on individual identifiers as they are the basic building blocks of code. Recent work on improving name-based and learning- based b ug detection [4] by aggregating identifiers in complex expressions suggests that improving embeddings for indi vidual identifiers also benefits larger -scale code representations [41]. Another limitation is that other string distance functions or other embeddings may perform better or worse than those studied here. W e select semantic representations that ha ve been used in past name-based analyses, as well as some recent em- bedding techniques that are state of the art in natural language processing (NLP). By making IdBench publicly av ailable, we enable others to ev aluate future semantic representations. As any benchmark, IdBench consists of a finite set of subjects, which may not be representati ve for all others. The number of pairs of identifiers in the benchmark (T able II) is in the same order of magnitude as that of word similarity benchmarks used in NLP [20], [31], [43]–[45]. Finally , we focus on Ja vaScript code, i.e., our findings may not generalize to identifiers in other languages. Finally , dif ferent name-based analyses hav e different re- quirements on the semantic representations they build upon. The tasks we present to survey participants may not represent all these requirements, and hence, a semantic representation may perform better or worse in a specific name-based analysis than IdBench suggests. V I . R E L A T E D W O R K a) Name-based Pr ogram Analysis: V arious analyses ex- ploit the rich information pro vided by identifier names, e.g., to find bugs [2]–[5] and vulnerabilities [47], to mine specifica- tions [6], to infer types based on identifier names as implicit type hints [7], [8], to predict the name of a method [9], to complete partial code using a learned language model [10], to identify inappropriate names [11], to suggest more suitable names [12], to resolv e fully qualified type names of methods, variables, etc. in a gi ven code snippet [48], or to map APIs between programming languages based on an embedding of code tokens [18]. A systematic way of e valuating semantic representations of identifiers, as provided in this paper, helps in further exploiting the implicit kno wledge encoded in iden- tifiers, and hence will benefit name-based program analyses. b) Embeddings of Identifiers: Embeddings of identifiers are at the core of sev eral code analysis tools. A popular approach, e.g., for bug detection [4], type prediction [8], or vulnerability detection [47], is applying W ord2v ec [26], [34] to token sequences, which corresponds to the W ord2vec embedding ev aluated in Section III. [49] train an RNN- based language model and extract its final hidden layer as an embedding of identifiers. Chen et al. [50] provide a more comprehensiv e survey of embeddings for source code. Beyond learned embeddings, string distance functions are used in other name-based tools, e.g., for detecting bugs [2], [3] or for inferring specifications [6]. The quality of embeddings is crucial in these and other code analysis tools, and IdBench will help to improv e the state of the art. c) Embeddings of Pro grams: Beyond embeddings of identifiers, there is work on embedding larger parts of a program. One approach [9] uses a log-bilinear , neural language model [51] to predict the names of methods. Other work em- beds code based on graph neural networks [21] or sequence- based neural networks applied to paths through a graph representation of code [23], [52]–[56]. Code2seq embeds code and then generates sequences of NL words [57]. For a broader ov erview and a detailed survey of learning-based software analysis, we refer the reader to [16] and [58], respecti vely . T o ev aluate embeddings of programs, the COSET benchmark provides thousands of programs with semantic labels [59]. An- other study measures ho w effecti ve pre-trained code2vec [23] embeddings are for different do wnstream tasks [46]. One conclusion from Kang et al. ’ s work [46] is that e valuating embeddings on a specific downstream task is insufficient, a problem we here address with a task-independent benchmark. Both of the abov e [46], [59] complement IdBench because the existing work is about entire programs, whereas IdBench is about identifiers. Since identifiers are a basic building block of source code, a benchmark for improving embeddings of identifiers will eventually also benefit learning-based code analysis tools. d) Benchmarks of W ord Embeddings: The NLP commu- nity has a long tradition of reasoning about the semantics of words. In particular, that community has addressed the challenge of measuring how well a semantic representation of words matches actual relationships between words through a series of gold standards of words, focusing on either relat- edness [25], [43], [44] or similarity [20], [31], [45], [60] of words. These gold standards define how similar two words are based on ratings by human judges, enabling an ev aluation that measures how well an embedding reflects the human ratings. Unfortunately , simply reusing these existing gold standards for identifiers in source code would be misleading. One reason is that the vocab ularies of natural languages and source code ov erlap only partially , because source code contains various terms and abbreviations not found in natural language texts. Moreov er , source code has a constantly growing vocab ulary , as developers tend to quickly inv ent new identifiers, e.g., for newly emerging application domains [35]. Finally , e ven words present in both natural languages and source code may differ in their meaning due to computer science-specific terms, e.g., “float” or “string”. This work is the first to address the need for a gold standard for identifiers in code. e) Data Gathering: Asking human raters how related or similar two w ords are was first proposed by [45] and then adopted by others [20], [31], [43], [60]. Our direct surve y also follows this methodology . [20] propose to gather judgments about contextual similarity by asking participants to choose a word to fill in a blank, an idea we adopt in our indirect surve y . T o choose words and pairs of words, prior work relies on manual selection [45], pre-e xisting free association databases [31], [60], e.g., USF [61] or V erbNet [62], [63], or cosine similarities according to pre-existing models [25]. W e follow the latter approach, as it minimizes human bias while cov ering a wide range of degrees of relatedness and similarity . f) Inter-r ater Agr eement: V alidating and cleaning data gathered via cro wd-sourcing based on the inter -rater agreement has been found effecti ve in other cro wd-sourced surv eys [30]. Gold standards for natural language words reach an inter-rater agreement of 0.61 [43] and 0.67 [31]. Our “small” dataset reaches similar le vels of agreement, sho wing that the rates in IdBench represent a genuine human intuition. As noted by [31], the inter-rater agreement also giv es an upper bound of the expected correlation between the tested model and the gold standard. Our results show that current models still leave plenty of room for improv ement, especially w .r .t. similarity . V I I . C O N C L U S I O N This paper presents the first benchmark for ev aluating se- mantic representations of identifiers names, along with a study of current semantic representation techniques. W e compile thousands of ratings gathered from 500 dev elopers into a benchmark that provides gold standard similarity scores rep- resenting the relatedness, similarity , and contextual similarity of identifiers. Using IdBench to experimentally compare two string distance functions and five embedding techniques shows that these techniques dif fer significantly in their agreement with our gold standard. The best available embeddings are effecti ve at representing how related identifiers are. Howe ver , all studied techniques show huge room for improvement in their ability to represent ho w similar identifiers are. An in- depth study of dif ferent subsets of identifiers sho ws the specific strengths and weaknesses of current semantic representations, e.g., that most techniques are challenged by abbre viations, opposites, and the difference between singular and plural. T o exploit the complementarity of current techniques, we present an ensemble model that effecti vely combines them and clearly outperforms the best individual techniques. Our work will help addressing the limitations of current semantic representations of identifiers. Such progress will benefit downstream dev eloper tools, in particular , name-based program analyses. More broadly , impro ving semantic rep- resentations of identifiers will also contribute toward better learning-based program testing and analysis techniques. R E F E R E N C E S [1] S. Butler, M. W ermelinger , Y . Y u, and H. Sharp, “Exploring the influence of identifier names on code quality: An empirical study , ” in Eur opean Confer ence on Software Maintenance and Reengineering (CSMR) . IEEE, 2010, pp. 156–165. [2] M. Pradel and T . R. Gross, “Detecting anomalies in the order of equally- typed method arguments, ” in International Symposium on Software T esting and Analysis (ISSTA) , 2011, pp. 232–242. [3] A. Rice, E. Aftandilian, C. Jaspan, E. Johnston, M. Pradel, and Y . Arroyo-Paredes, “Detecting argument selection defects, ” in Con- fer ence on Object-Oriented Pro gramming, Systems, Languages, and Applications (OOPSLA) , 2017. [4] M. Pradel and K. Sen, “DeepBugs: A learning approach to name-based bug detection, ” P ACMPL , vol. 2, no. OOPSLA, pp. 147:1–147:25, 2018. [Online]. A vailable: https://doi.org/10.1145/3276517 [5] S. Kate, J. Ore, X. Zhang, S. G. Elbaum, and Z. Xu, “Phys: probabilistic physical unit assignment and inconsistency detection, ” in Pr oceedings of the 2018 ACM J oint Meeting on Eur opean Software Engineering Conference and Symposium on the F oundations of Software Engineering, ESEC/SIGSOFT FSE 2018, Lake Buena V ista, FL, USA, November 04-09, 2018 , 2018, pp. 563–573. [Online]. A vailable: https://doi.org/10.1145/3236024.3236035 [6] H. Zhong, L. Zhang, T . Xie, and H. Mei, “Inferring resource speci- fications from natural language API documentation, ” in International Confer ence on Automated Softwar e Engineering (ASE) , 2009, pp. 307– 318. [7] Z. Xu, X. Zhang, L. Chen, K. Pei, and B. Xu, “Python probabilistic type inference with natural language support, ” in Pr oceedings of the 24th A CM SIGSOFT International Symposium on F oundations of Software Engineering, FSE 2016, Seattle, W A, USA, November 13-18, 2016 , 2016, pp. 607–618. [Online]. A vailable: https://doi.org/10.1145/2950290.2950343 [8] R. S. Malik, J. Patra, and M. Pradel, “NL2T ype: Inferring Jav aScript function types from natural language information, ” in Proceedings of the 41st International Conference on Software Engineering, ICSE 2019, Montreal, QC, Canada, May 25-31, 2019 , 2019, pp. 304–315. [Online]. A vailable: https://doi.org/10.1109/ICSE.2019.00045 [9] M. Allamanis, E. T . Barr , C. Bird, and C. A. Sutton, “Suggesting accurate method and class names, ” in Pr oceedings of the 2015 10th Joint Meeting on F oundations of Softwar e Engineering, ESEC/FSE 2015, Ber gamo, Italy , August 30 - September 4, 2015 , 2015, pp. 38–49. [10] M. R. Parvez, S. Chakraborty , B. Ray , and K. Chang, “Building language models for text with named entities, ” in Pr oceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, July 15-20, 2018, V olume 1: Long P apers , 2018, pp. 2373–2383. [Online]. A vailable: https://www .aclweb .org/anthology/P18- 1221/ [11] E. W . Høst and B. M. Østv old, “Debugging method names, ” in Eur opean Confer ence on Object-Oriented Pr ogramming (ECOOP) . Springer , 2009, pp. 294–317. [12] K. Liu, D. Kim, T . F . Bissyand ´ e, T . Kim, K. Kim, A. Koyuncu, S. Kim, and Y . L. Traon, “Learning to spot and refactor inconsistent method names, ” in Proceedings of the 41st International Conference on Software Engineering, ICSE 2019, Montreal, QC, Canada, May 25-31, 2019 , 2019, pp. 1–12. [Online]. A vailable: https: //dl.acm.org/citation.cfm?id=3339507 [13] S. Butler , M. W ermelinger , Y . Y u, and H. Sharp, “Improving the tokenisation of identifier names, ” in European Confer ence on Object- Oriented Pr ogramming (ECOOP) . Springer , 2011, pp. 130–154. [14] Y . Jiang, H. Liu, J. Q. Zhu, and L. Zhang, “ Automatic and accurate ex- pansion of abbreviations in parameters, ” IEEE T ransactions on Softwar e Engineering , 2018. [15] H. Liu, Q. Liu, C.-A. Staicu, M. Pradel, and Y . Luo, “Nomen est omen: Exploring and exploiting similarities between argument and parameter names, ” in International Confer ence on Software Engineering (ICSE) , 2016, pp. 1063–1073. [16] M. Pradel and S. Chandra, “Neural software analysis, ” CoRR , vol. abs/2011.07986, 2020. [Online]. A vailable: https://arxiv .or g/abs/2011. 07986 [17] U. Alon, M. Zilberstein, O. Levy , and E. Y aha v , “ A general path-based representation for predicting program properties, ” in ACM SIGPLAN Notices , vol. 53, no. 4. ACM, 2018, pp. 404–419. [18] T . D. Nguyen, A. T . Nguyen, H. D. Phan, and T . N. Nguyen, “Exploring API embedding for API usages and applications, ” in Proceedings of the 39th International Confer ence on Softwar e Engineering, ICSE 2017, Buenos Aires, Ar gentina, May 20-28, 2017 , 2017, pp. 438–449. [19] V . Hellendoorn, C. Bird, E. T . Barr , and M. Allamanis, “Deep learning type inference, ” in FSE , 2018. [20] G. A. Miller and W . G. Charles, “Contextual correlates of semantic similarity , ” Language and cognitive pr ocesses , vol. 6, no. 1, pp. 1–28, 1991. [21] M. Allamanis, M. Brockschmidt, and M. Khademi, “Learning to represent programs with graphs, ” CoRR , vol. abs/1711.00740, 2017. [Online]. A vailable: http://arxiv .or g/abs/1711.00740 [22] P . Bojanowski, E. Grave, A. Joulin, and T . Mikolov , “Enriching word vectors with subword information, ” T ACL , v ol. 5, pp. 135–146, 2017. [Online]. A vailable: https://transacl.org/ojs/index.php/tacl/article/ view/999 [23] U. Alon, M. Zilberstein, O. Levy , and E. Y ahav , “code2v ec: Learning distributed representations of code, ” Pr oceedings of the A CM on Pro- gramming Languages , vol. 3, no. POPL, p. 40, 2019. [24] V . Raychev , P . Bielik, M. V eche v , and A. Krause, “Learning programs from noisy data, ” in ACM SIGPLAN Notices , vol. 51, no. 1. A CM, 2016, pp. 761–774. [25] E. Bruni, N.-K. Tran, and M. Baroni, “Multimodal distributional se- mantics, ” Journal of Artificial Intelligence Resear ch , vol. 49, pp. 1–47, 2014. [26] T . Mikolov , K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space, ” arXiv pr eprint arXiv:1301.3781 , 2013. [27] V . Rayche v , P . Bielik, and M. V eche v , “Probabilistic model for code with decision trees, ” in OOPSLA , 2016. [28] M. Allamanis and C. A. Sutton, “Mining source code repositories at massiv e scale using language modeling, ” in Pr oceedings of the 10th W orking Confer ence on Mining Softwar e Repositories, MSR ’13, San F rancisco, CA, USA, May 18-19, 2013 , 2013, pp. 207–216. [29] A. Kittur , E. H. Chi, and B. Suh, “Crowdsourcing user studies with mechanical turk, ” in Proceedings of the SIGCHI confer ence on human factors in computing systems , 2008, pp. 453–456. [30] S. Now ak and S. R ¨ uger , “Ho w reliable are annotations via crowdsourc- ing: a study about inter-annotator agreement for multi-label image an- notation, ” in Proceedings of the international conference on Multimedia information retrie val , 2010, pp. 557–566. [31] F . Hill, R. Reichart, and A. K orhonen, “Simlex-999: Evaluating semantic models with (genuine) similarity estimation, ” Computational Linguistics , vol. 41, no. 4, pp. 665–695, 2015. [32] V . Zhelezniak, A. Savko v , A. Shen, and N. Y . Hammerla, “Cor - relation coefficients and semantic textual similarity , ” arXiv preprint arXiv:1905.07790 , 2019. [33] S. B. Needleman and C. D. Wunsch, “ A general method applicable to the search for similarities in the amino acid sequence of two proteins, ” Journal of molecular biology , vol. 48, no. 3, pp. 443–453, 1970. [34] T . Mikolov , I. Sutskev er, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their composi- tionality , ” in Advances in neural information pr ocessing systems , 2013, pp. 3111–3119. [35] H. Babii, A. Janes, and R. Robbes, “Modeling vocab ulary for big code machine learning, ” CoRR , 2019. [Online]. A vailable: https://arxiv .or g/abs/1904.01873 [36] A. Corazza, S. D. Martino, and V . Maggio, “LINSEN: an efficient approach to split identifiers and expand abbreviations, ” in 28th IEEE International Conference on Software Maintenance, ICSM 2012, T rento, Italy , September 23-28, 2012 . IEEE Computer Society , 2012, pp. 233– 242. [Online]. A vailable: https://doi.org/10.1109/ICSM.2012.6405277 [37] Y . Jiang, H. Liu, and L. Zhang, “Semantic relation based expansion of abbre viations, ” in Proceedings of the ACM Joint Meeting on Eur opean Softwar e Engineering Conference and Symposium on the F oundations of Software Engineering, ESEC/SIGSOFT FSE 2019, T allinn, Estonia, August 26-30, 2019 , M. Dumas, D. Pfahl, S. Apel, and A. Russo, Eds. A CM, 2019, pp. 131–141. [Online]. A vailable: https://doi.org/10.1145/3338906.3338929 [38] C. D. Newman, M. J. Deck er , R. S. Alsuhaibani, A. Peruma, D. Kaushik, and E. Hill, “ An empirical study of abbre viations and e xpansions in software artifacts, ” in 2019 IEEE International Confer ence on Softwar e Maintenance and Evolution, ICSME 2019, Cle veland, OH, USA, September 29 - October 4, 2019 . IEEE, 2019, pp. 269–279. [Online]. A vailable: https://doi.org/10.1109/ICSME.2019.00040 [39] D. J. Lawrie and D. W . Binkley , “Expanding identifiers to normalize source code vocabulary , ” in IEEE 27th International Confer ence on Softwar e Maintenance, ICSM 2011, W illiamsbur g, V A, USA, September 25-30, 2011 . IEEE Computer Society , 2011, pp. 113–122. [Online]. A vailable: https://doi.org/10.1109/ICSM.2011.6080778 [40] D. Lawrie, H. Feild, and D. Binkley , “Extracting meaning from abbre- viated identifiers, ” in W orking Conference on Source Code Analysis and Manipulation (SCAM) . IEEE, 2007, pp. 213–222. [41] R.-M. Karampatsis and C. Sutton, “Scelmo: Source code embeddings from language models, ” 2020. [Online]. A v ailable: https://openrevie w . net/pdf?id=ryxnJlSKvr [42] M. Pradel, G. Gousios, J. Liu, and S. Chandra, “T ypewriter: Neural type prediction with search-based validation, ” in ESEC/FSE ’20: 28th A CM Joint European Software Engineering Confer ence and Symposium on the F oundations of Software Engineering, V irtual Event, USA, November 8-13, 2020 , 2020, pp. 209–220. [Online]. A vailable: https://doi.org/10.1145/3368089.3409715 [43] L. Finkelstein, E. Gabrilovich, Y . Matias, E. Rivlin, Z. Solan, G. W olf- man, and E. Ruppin, “Placing search in context: The concept revisited, ” ACM T ransactions on information systems , vol. 20, no. 1, pp. 116–131, 2002. [44] T . Schnabel, I. Labutov , D. M. Mimno, and T . Joachims, “Evaluation methods for unsupervised word embeddings, ” in Proceedings of the 2015 Confer ence on Empirical Methods in Natural Languag e Pr ocessing, EMNLP 2015, Lisbon, P ortugal, September 17-21, 2015 , 2015, pp. 298–307. [Online]. A vailable: http://aclweb.or g/anthology/D/ D15/D15- 1036.pdf [45] H. Rubenstein and J. B. Goodenough, “Contextual correlates of syn- onymy , ” Communications of the ACM , v ol. 8, no. 10, pp. 627–633, 1965. [46] H. J. Kang, T . F . Bissyand ´ e, and D. Lo, “ Assessing the generalizability of code2vec token embeddings, ” in ASE , 2019. [47] J. A. Harer , L. Y . Kim, R. L. Russell, O. Ozdemir, L. R. Kosta, A. Rangamani, L. H. Hamilton, G. I. Centeno, J. R. K ey , P . M. Ellingwood, M. W . McConley , J. M. Opper, S. P . Chin, and T . Lazovich, “ Automated software vulnerability detection with machine learning, ” CoRR , vol. abs/1803.04497, 2018. [Online]. A vailable: http://arxiv .or g/abs/1803.04497 [48] H. Phan, H. A. Nguyen, N. M. T ran, L. H. Truong, A. T . Nguyen, and T . N. Nguyen, “Statistical learning of API fully qualified names in code snippets of online forums, ” in Proceedings of the 40th International Confer ence on Software Engineering, ICSE 2018, Gothenbur g, Sweden, May 27 - J une 03, 2018 , 2018, pp. 632–642. [Online]. A vailable: http://doi.acm.org/10.1145/3180155.3180230 [49] M. White, M. T ufano, C. V endome, and D. Poshyvanyk, “Deep learning code fragments for code clone detection, ” in ASE , 2016, pp. 87–98. [50] Z. Chen and M. Monperrus, “ A literature study of embeddings on source code, ” arXiv preprint , 2019. [51] Y . Bengio, R. Ducharme, P . V incent, and C. Jauvin, “ A neural proba- bilistic language model, ” Journal of machine learning resear ch , vol. 3, no. Feb, pp. 1137–1155, 2003. [52] T . Ben-Nun, A. S. Jakobovits, and T . Hoefler, “Neural code comprehension: A learnable representation of code semantics, ” CoRR , vol. abs/1806.07336, 2018. [Online]. A vailable: http://arxi v .org/abs/ 1806.07336 [53] J. Devlin, J. Uesato, R. Singh, and P . Kohli, “Semantic code repair using neuro-symbolic transformation networks, ” CoRR , vol. abs/1710.11054, 2017. [Online]. A vailable: http://arxiv .org/abs/1710.11054 [54] J. Henkel, S. K. Lahiri, B. Liblit, and T . W . Reps, “Code vectors: understanding programs through embedded abstracted symbolic traces, ” in Pr oceedings of the 2018 ACM Joint Meeting on Eur opean Softwar e Engineering Conference and Symposium on the F oundations of Software Engineering, ESEC/SIGSOFT FSE 2018, Lake Buena V ista, FL, USA, November 04-09, 2018 , 2018, pp. 163–174. [55] D. DeFreez, A. V . Thakur, and C. Rubio-Gonz ´ alez, “Path-based function embedding and its application to specification mining, ” CoRR , vol. abs/1802.07779, 2018. [56] X. Xu, C. Liu, Q. Feng, H. Y in, L. Song, and D. Song, “Neural network- based graph embedding for cross-platform binary code similarity detec- tion, ” in CCS , 2017, pp. 363–376. [57] U. Alon, S. Brody , O. Levy , and E. Y aha v , “code2seq: Generating sequences from structured representations of code, ” in 7th International Confer ence on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019 , 2019. [Online]. A vailable: https://openrevie w . net/forum?id=H1gKY o09tX [58] M. Allamanis, E. T . Barr , P . Dev anbu, and C. Sutton, “ A survey of machine learning for big code and naturalness, ” ACM Computing Surveys (CSUR) , vol. 51, no. 4, p. 81, 2018. [59] K. W ang and M. Christodorescu, “Coset: A benchmark for ev aluating neural program embeddings, ” CoRR , 2019. [Online]. A vailable: https://arxiv .or g/abs/1905.11445 [60] D. Gerz, I. V uli ´ c, F . Hill, R. Reichart, and A. Korhonen, “Simverb- 3500: A large-scale e valuation set of verb similarity , ” arXiv pr eprint arXiv:1608.00869 , 2016. [61] D. L. Nelson, C. L. McEv oy , and T . A. Schreiber , “The univ ersity of south florida free association, rhyme, and word fragment norms, ” Behavior Resear ch Methods, Instruments, & Computers , vol. 36, no. 3, pp. 402–407, 2004. [62] K. Kipper, B. Snyder , and M. Palmer , “Extending a verb-lexicon using a semantically annotated corpus. ” in LREC , 2004. [63] K. Kipper, A. K orhonen, N. Ryant, and M. Palmer , “ A large-scale classification of english verbs, ” Language Resources and Evaluation , vol. 42, no. 1, pp. 21–40, 2008.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment