IdBench 식별자 의미 표현 평가 벤치마크
IdBench는 500명의 개발자가 2천 건 이상의 식별자 쌍에 대해 직접 평가한 ‘관련성’·‘유사성’ 점수를 기반으로 만든 최초의 식별자 의미 표현 벤치마크이다. 이를 통해 기존 문자열 거리 함수와 여러 코드 임베딩(FastText‑CBO W, Code2Vec 등)의 성능을 체계적으로 비교하고, 각 기법의 강점·약점을 분석한다. 결과는 현재 임베딩이 ‘관련성’은 어느 정도 잘 포착하지만 ‘유사성’에서는 여전히 한계가 있음을 보여준다. 마지막으…
저자: Yaza Wainakh, Moiz Rauf, Michael Pradel
**1. 서론 및 배경**
식별자 이름은 변수·함수·클래스 등 프로그램 요소의 의미를 전달하는 주요 수단이며, 개발자는 이를 통해 코드를 이해하고 유지보수한다. 최근에는 식별자 이름을 활용한 자동화 분석(버그 탐지, 타입 추론, 코드 완성 등)이 활발히 연구되고 있다. 이러한 “이름 기반 분석”은 크게 두 가지 접근법으로 나뉜다. 첫째, 언더스코어·카멜케이스 등을 이용한 문자열 거리 함수(Levenshtein, Jaro‑Winkler 등)로 문자 수준 유사성을 측정한다. 둘째, 대규모 코드 코퍼스를 이용해 학습된 임베딩(FastText, Code2Vec, CodeBERT 등)으로 식별자를 연속 벡터에 매핑하고 코사인 유사도로 의미를 추정한다. 그러나 기존 연구는 이러한 표현이 개발자가 실제로 인지하는 “관련성(relatedness)”과 “유사성(similarity)”을 얼마나 잘 반영하는지에 대한 실증적 근거가 부족했다.
**2. 연구 질문**
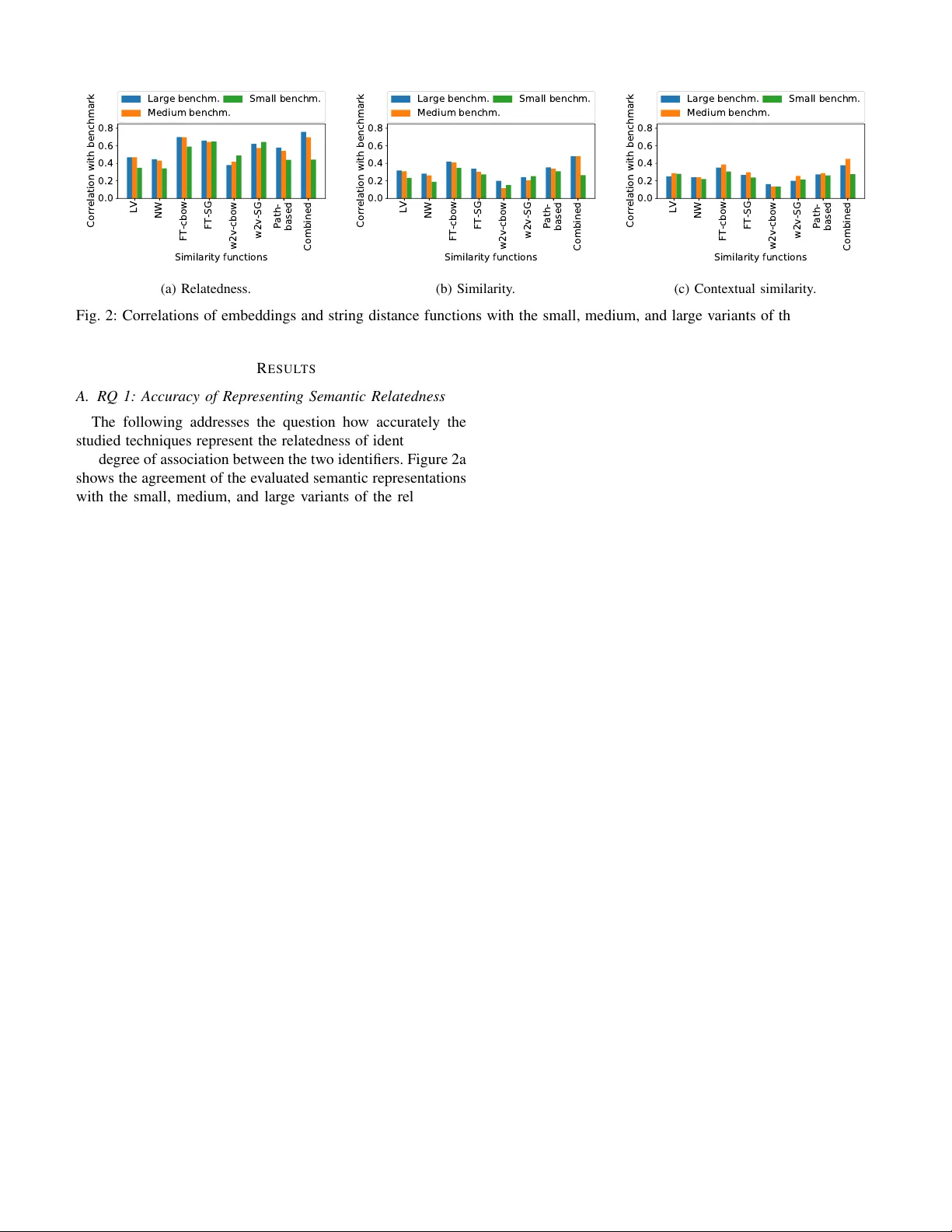
- RQ 1: 현재 최첨단 임베딩이 개발자가 느끼는 식별자 ‘관련성’을 얼마나 정확히 재현하는가?
- RQ 2: 동일 임베딩이 ‘유사성’을 얼마나 정확히 포착하는가?
- RQ 3: 각 기법의 강점·약점은 무엇이며, 오류 원인은 무엇인가?
- RQ 4: 서로 다른 기법이 보완 관계에 있는가?
**3. IdBench 벤치마크 구축**
- **식별자·쌍 선정**: 50 k개의 JavaScript 파일에서 등장 빈도 ≥ 50인 식별자를 추출하고, 두 개의 사전 학습된 임베딩(FastText‑CBO W, Code2Vec)을 이용해 코사인 유사도 순위에 따라 다양한 구간(높음·중간·낮음)에서 300개의 쌍을 선택하였다. 또한 동의어·반의어·무관한 쌍을 수동으로 보강하였다.
- **설문 설계**: (a) 직접 설문 – 식별자 쌍을 제시하고 “관련성(5점)”과 “대체 가능성(5점)”을 평가하도록 함. (b) 간접 설문 – 실제 코드 컨텍스트(5줄)와 두 후보 식별자를 보여주고, 어느 것이 더 자연스러운지 선택하게 함. 각 개발자에게 18개의 직접 질문과 15개의 간접 질문을 제시하였다.
- **참여자**: 총 500명(북미·인도 중심, 평균 5년 이상 경력)으로, 절반은 자발적, 절반은 MTurk을 통해 모집하였다. 각 설문당 평균 소요 시간은 15분.
- **데이터 정제**: Krippendorff’s α를 이용해 응답자 간 일관성을 측정하고, α < 0.6인 응답자를 제외하였다. 각 쌍당 최소 10개의 라벨을 확보하고, 평균값을 최종 ‘관련성’·‘유사성’ 점수로 사용하였다.
**4. 평가 대상 및 실험 설정**
- 문자열 거리 함수: Levenshtein, Jaro‑Winkler.
- 학습 기반 임베딩: FastText‑CBO W, FastText‑CBOW, Code2Vec, CodeBERT, Word2Vec‑trained‑on‑code.
- 평가 지표: Spearman’s rho(라벨 순위와 예측 순위 상관), MAE(절대 오차 평균).
**5. 주요 결과**
- *관련성* 측면: FastText‑CBO W가 ρ ≈ 0.62, MAE ≈ 0.48로 가장 우수했으며, Code2Vec와 CodeBERT는 ρ ≈ 0.45 수준. 문자열 거리 함수는 ρ ≈ 0.30에 머물렀다.
- *유사성* 측면: 모든 임베딩이 ρ < 0.30으로 낮은 성능을 보였으며, 오히려 Levenshtein이 ρ ≈ 0.35로 가장 높은 상관을 기록했다. 이는 문자 수준 유사도가 의미적 동등성을 판단하는 데 어느 정도 유용함을 의미한다.
- *오류 분석*: (1) 반대 의미(예: rows vs cols)를 동일 벡터에 매핑하는 경우가 빈번했다. (2) 동일 도메인 내에서도 의미 차이가 큰 식별자(예: getBorderWidth vs getPadding)를 혼동했다. (3) 약어·축약어(예: idx vs hl) 처리에 약점이 있었다. (4) 문자열 거리 함수는 이러한 의미적 혼동을 피하지만, 실제 의미 차이를 포착하지 못한다.
**6. 기법 간 보완성 및 앙상블**
각 기법이 서로 다른 오류 패턴을 보였으므로, 메타 특징(길이, 대소문자 비율, 사전 존재 여부, 약어 여부 등)을 입력으로 하는 로지스틱 회귀 기반 앙상블 모델을 설계하였다. 앙상블은 개별 최우수 기법 대비 ‘관련성’에서 6 %·‘유사성’에서 19 %의 정확도 향상을 달성했으며, 특히 반대 의미를 구분하는 데 큰 개선을 보였다.
**7. 기여 및 향후 과제**
- **벤치마크 공개**: IdBench 데이터셋(식별자 쌍, 라벨, 코드 컨텍스트)을 공개해 향후 연구의 표준 평가 기반을 제공한다.
- **실증적 통찰**: 현재 임베딩은 ‘관련성’은 어느 정도 포착하지만 ‘유사성’에서는 한계가 있음을 명확히 제시한다.
- **앙상블 모델**: 간단한 메타 특징만으로도 기존 기법을 능가하는 실용적 방법을 제시한다.
- **제한점**: JavaScript 중심이며, 라벨링은 주관적 설문에 의존한다. 향후 다중 언어·다중 도메인 확대와, 정형화된 의미론(예: 온톨로지)와의 연계가 필요하다.
**8. 결론**
IdBench는 개발자 인지 기반의 의미 평가를 통해 식별자 의미 표현의 실제 품질을 정량화한 최초의 벤치마크이며, 기존 임베딩의 강점·약점을 명확히 드러낸다. 또한 문자열 거리와 학습 기반 임베딩을 결합한 앙상블 접근법이 현재 최고의 성능을 제공함을 실증한다. 이 연구는 코드 이해·자동화 도구 개발에 있어 의미 표현 선택과 개선 방향을 제시하는 중요한 이정표가 된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기