Analysis of a Modern Voice Morphing Approach using Gaussian Mixture Models for Laryngectomees
This paper proposes a voice morphing system for people suffering from Laryngectomy, which is the surgical removal of all or part of the larynx or the voice box, particularly performed in cases of laryngeal cancer. A primitive method of achieving voic…
Authors: Aman Chadha, Bharatraaj Savardekar, Jay Padhya
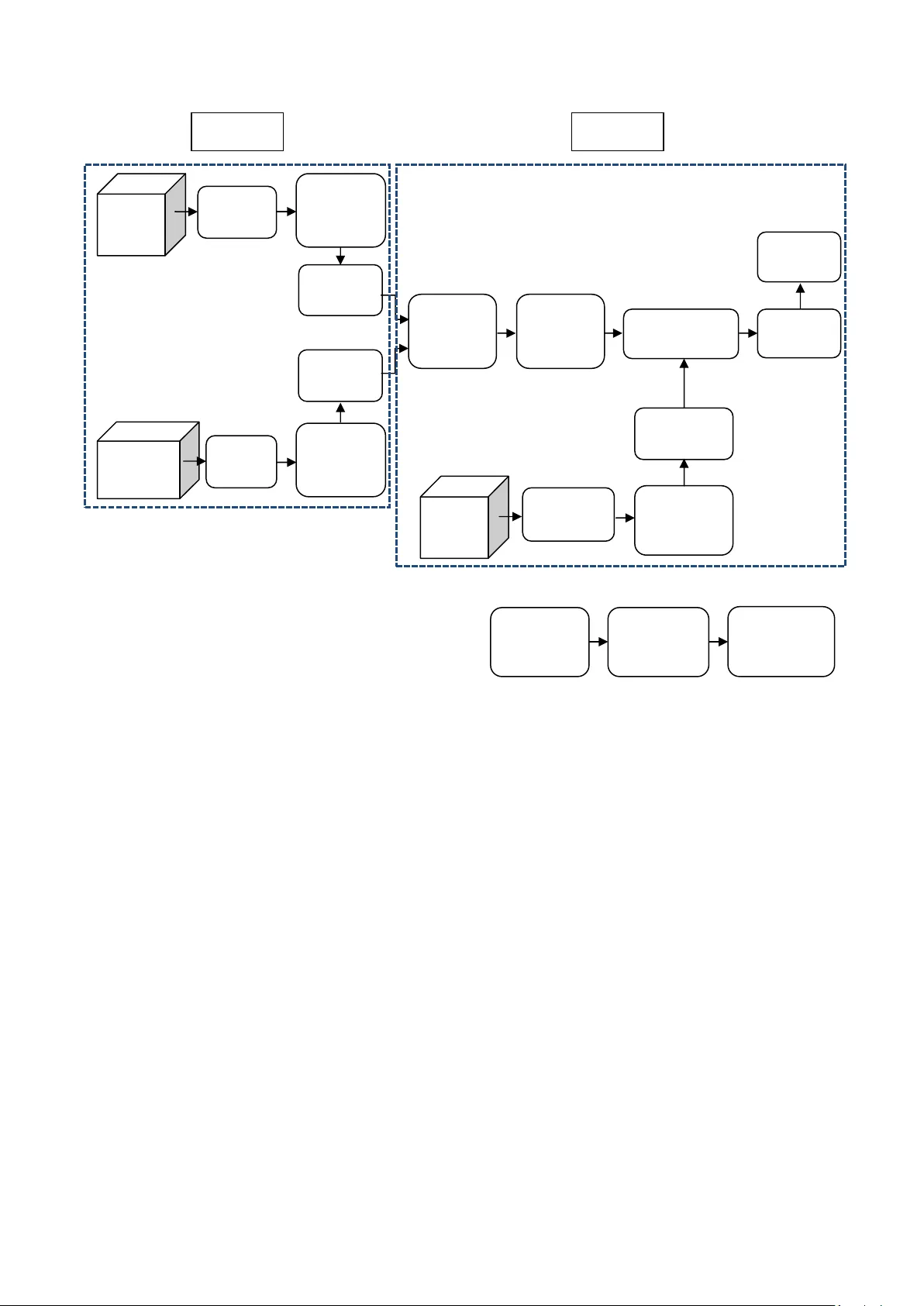
Internationa l Journal of Computer Ap plications (0975 – 8887) Volume 49– No.21, July 2012 25 Analysis o f a Mod ern Vo ice Morph ing A pp roach usi ng Gaussian Mixture M odels f or Laryngecto mees Aman C had ha Depa rtmen t of Elec tri cal and Compu te r Engin eerin g Uni versi ty o f W isco nsi n- Madi son Bhar atr aaj Sav ard ekar Depa rtmen t of Elec tron ics Eng ineeri ng K. J. S omaiy a Coll ege of Eng ineeri ng Jay Pa dhy a Depa rtmen t of Elec tron ics Eng ineeri ng K. J. S omaiy a Coll ege of Eng ineeri ng ABSTRACT This paper pro poses a voicemo rphing system for peop le suffering from Laryngectomy, which is the surgical rem oval of all or part of the larynx o r th e voice box, particu larly performed i n cases of lar yngeal can cer. A p rimitive method of achieving v oice morphing is by extracting the so urce's vocal coefficients and then con verting them into the target speaker 's vocal parameters. In thi s paper, we deplo y Gaussian Mixture Models (GMM) for mapping the coefficien ts from so urce to destination. However, the use of th e tradition al/conventional GMM-based mapping approach resu lts in th e pr oblem of over-smooth ening of the conver ted voice. Thus, we hereby propose a uniqu e method to perform e fficient voice morphin g and conversion based on G MM, which overcomes the traditional-method effects of o ver-smooth ening. It uses a technique of glottal w avefor m separation and pre diction of excitations and hence the result shows that not only over- smoothen ing is eliminated b ut also the transformed vocal tract parameters match with the target . Moreover, the synthesized speech thus obtained is found to be of a sufficientl y high quality. Thus, voice morphing based o n a unique GMM approach has been proposed and also critically evaluated based on various subjective and objective evaluation parameters. Furt her, an applicatio n of voice morphing for Laryngectomees which deploys t his unique ap proach h as been recommended b y this paper. General Terms Audio and S peech Processing Keywords Voice Morph ing, Laryngectomy, Gaussian Mixtu re Models 1. INT RODUCTION Voice morph ing is essentially a technique of trans forming a source speaker’s speech in to target speaker's sp eech. In general, the voice m orph ing systems con sist of two stages: training and transforming. Out o f the t wo, the main process is the t ransformation of the sp ectral e nvelope of the source speaker to match to that of the targ et s peaker. In order to implement th e perso nality trans formatio n, t here are two issues that need to b e tackled: firstl y, con verting the vocal tract feature para meters as well as tr ansformation o f excitation parameters. Till recentl y, sever al p ublished works [1] -[5] in the domain of voice c onversion have been f ocusing on the vocal tract mapp ing whose feat ures are parameterized by respective Linear Predictive Coding (LPC) parameters. However it has known that some kind s of transfor mation are needed to be applied to excitation signals in order to achieve transformations of high quality. Furthermore, the converted speech o ften suffers from the degrad ed qu ality due t o over- smoothen ing effects caused b y the trad itional GMM-based mapping method. In o rder to achieve a high quali ty co nverted speech, th ese main problems have to be tackled. A method o f d eploying LPC in voice conversio n, extracting LPC Coefficients and LP C filter transfer functio n an alysis has been discussed in [6]. Along with LPC an alysis/encoding, which involves d etermining th e vo iced/unvoiced i nput speech, estimation of pitch period, filtering and transmitting the relevant parameters has been demonstrated by Bradbury in [7]. Also, th e LPC source-filter model represent ation and LPC synthesis/decod ing has been elaborated in [ 7].A basic understanding of incorporating GMM f or voice transformation while still uti lizing t he LPC tech nique for extraction of coe fficients has been illustrated by Gundersen in [8]. In [9]-[11], the GMM pro cess has been elucidated with an approach that utili zes the con cept of Dynamic Time Warping (DTW) and Expectation Maximizatio n. Ho wever, the GMM approach d eployed in [9]-[11] is based on a trad itional approach that frequ ently results in over-smoothening of the source’s speech. A modern app roach to GMM which overcomes the over-smooth ening drawback has been explained in [12]. We follo w a similar app roach and the correspondi ng execution is found to fetch goo d results and conclusion s. In [ 13], a speaking-aid model for lar yngectomees has been suggested. This paper p roposes and an alyses a system which d eploys th e model pro posed in [13] with a modern GMM-based app roach, thu s not o nly overcoming th e drawbacks of t he tradi tional GMM-based app roach for voi ce conversion but al so i mproving the usability o f the system for Laryngectomees. 2. IDE A OF THE PRO POSED SOLUT ION 2.1 Phase 1 The source and d estination voice will undergo LP C analysis, followed b y the s eparation of glott al waveform. The vocal tract parameters will b e subjected to GMM prediction. 2.2 Phase 2 The GMM b ased predictio n is followed by th e conversion rule based o n GMM. The con version ru le has an in put from the test speaker’s voice, after b eing su bjected to LP C analysis and separation o f glot tal waveform. The con version rule will generate the output as the converted speech after LPC synthesis. Internationa l Journal of Computer Ap plications (0975 – 8887) Volume 49– No.21, July 2012 26 Fig 1: Overview of the proposed system We hereb y present voice morphing which in volves separati ng out the excitation signal from the speech w aveform of the speaker in order to co nvert vocal tract parameters in a precise manner. The remaind er of this paper is organized as follo ws. Firstly, a review of voice conversion mechanism is given in this section, followed by t he detailed descrip tion of techni que proposed. Later on, there is an evaluati on o f the perfor mance of the proposed system with the n ew tech nique. Finally, t he overall application s, conclusions and results are presented at the end. 3. O VERVIEW O F THE SYST EM The overview of ou r proposed voice con version system is as shown in figure 1. The entire system co mprises of two stages. 3.1.1 Training Stage This inclu des segmentatio n of the source an d target speaker voices i n into eq ual frames o f t wo p itch p eriod lengths and then analyzing it is based upon a Linear Predictive Coding model. This is d one in o rder to extract vocal features to b e transformed [ 6][7]. 3.1.2 Transforming Stage This in volves features tran sformatio n from source t o targ et. In order to have a better alignment between source and the target features, there is an appli cation of Dynamic Ti me Warping (DTW) in th e preprocessing step. 3.2 Glottal w avefor m separation al gorithm According to the Linear P rediction algorithm, an effective speech production m odel f or voiced speech is as sho wn in figure 2. Fig 2: Speech productio n model The terminolo gies used have been d efined as follows: S (z) is th e acoustic speech waveform, G (z) is the glottal waveform shapin g, V (z) is the models the vocal tract con figuration and R (z) is the radiation at the lips which can be modeled as an effect of the di fferential operator . Now, G’ ( z) which is the glott al derivative, can be derived as the product o f G(z) and R(z). Hence, ( ) ( ) ( ) ( ) ( ) ( ) ' S z G z V z G z V z R z = ⋅ = ⋅ ⋅ (1) Given this assumption of the model, it was obviou s that we can directly obtain the expl icit representatio n of vocal tr act b y inverse filtering S (z) with G’ (z). Unfortunately, the premise does n ot h old valid as sh own in [14]. Accurate and precise vocal tract parameters can o nly be obtained if and only if the glot tal d erivative e ffect is eliminated. Figure 3 shows the glottal d erivative as well as the ideal glottal waveform in a pitch period. G lottal Waveform G(z) Radiation at lips R(z) Vocal Tract H(z) Destination Vocal tract parameter Source LPC Analysis Separation of glottal waveform Vocal tract parameter LPC Analysis Separation of glottal waveform PHASE 1 GMM based prediction LPC Analysis Separation of glottal waveform Vocal tract parameter Conversion rule based on GMM LPC Synthesis Converted Speech Source GMM based conversion PHASE 2 Internationa l Journal of Computer Ap plications (0975 – 8887) Volume 49– No.21, July 2012 27 Fig 3: Glottal derivativ e and glottal w aveform It can be seen that the amplitu de of the glottal waveform starting fro m th e Glott al Closur e Instants (GCI) to the end o f the pitch period is d ecreasing monotonically, i.e., d uring the closing ph ase and the closed phase of the glott al waveform, the interaction with the vocal tract is d ecreased monoton ically, where linear predict ion coding (LPC) analysis can be performed in order to model the vocal tract almost exclusively since glot tal contribution is minimum [1]. In order to achieve an effective perso nality change it is n eeded to change th e glottal excitation characteristics of the source speaker to match exactly as that of th e target, so a prediction rule has b een trained on the aspects of the excitation signals of the target speaker. In the transforming st age, the source vocal tract features were extracted and mod ified b ased on the conversion r ule from th e training stage, meanwhile, converted excitation signals were obtain ed by p redicting from the transformed vocal tract features based on the prediction rule [15][16]. F inally, a continuous waveform was o btained in the LPC synthesis model b y synthesizing all these parameters. 4. IMPLEME NTATION STE PS Transformation stag e per formance in vo ice conversion systems is generall y ev aluated u sing both obj ective and subjective measures. Both objective and subjective evaluations are essential to assess the performance of such systems. Objective evaluation s are indicati ve of conversion performance and cou ld be useful to compare different algorithms within a particular frame work. However, objective measures o n their own are n ot reliable, sin ce they may n ot be directly co rrelated with human percepti on. As a r esult, a meaningful evalu ation of voice conversion sy stems requ ires the use o f sub jective measures to perceptually evaluate their conversion ou tputs. 4.1 Da tabase for Sy stem Implementation A parallel d atabase is so ught wherein the sou rce and th e target speakers re cord a matching set o f utteran ces. We narrowed down on th e CMU ARCTIC datab ases [17], constru cted at the Language Technol ogies In stitute at Carnegie Mellon University, which consists of phon etically b alanced, US English single speaker databases d esigned for unit selection speech synthesis research. Utterances record ed by six speakers are included in the database which is d eployed for system evalu ation. Each speaker has record ed a set of 11 32 phonetically balanced utt erances. The ARCTIC datab ase includes u tterances of SLT (US F emale), CLB (US Female), RMS (US Male), JMK (Canadian Male), AWB (Scott ish Male), KSP (Indian Male). 5. APPLICAT ION OF THE MODERN VOICE MORPHIN G APPROACH FOR LARYNGECTOMEE S Laryngectomy is a pro cedure of surgical remo val of th e larynx which is usu ally condu cted on patients with laryngeal cancer or a si milar probl em. When the p atient loses his larynx, he/she is called a laryngecto mee, he/she would lose th eir original voice, and they will face d ifficulty interacting with other persons. An electrolarynx is an electronic speech aid that enables the user to comm unicate with other people as quickly as possibl e after the succ essful re moval o f t he lar ynx. This device pro duces a to ne th at is transmitted over a membrane thr ough the soft p arts o n the bo ttom of the ch in into the mouth and throat cavity. In combinati on with clear articulation the tone is formed into speech. An electrolarynx is a popular method for enabling laryngectomees t o speak without th e vibration of the vocal cord due to the fact that it has several advantages as follows: • S peaking with an electrolar ynx can be learned quickly, which makes co mmunication possible shortly after surger y. • The el ectrolarynx can be u sed with an intraoral device while post-operative radi ation therap y an d if radiation treatment causes te mporary lo ss of the esophageal voice. • Usi ng an electro larynx is stressless, and not physically exhaustin g. • An electrolarynx enables louder, faster and f luent speech right from the st art. • The device can be used in almost all situations, including during meals an d w hen ever esop hageal speech ceas es or is n ot possible to use (i.e. in situations of stress, inflammatio n, rad iation therapy, poor anato mical conditions etc.) • The pitch of th e electro larynx c an be individually adjusted. Despite the distinct advantages of an electrolarynx, several disadvantages of an E lectrolarynx exist: • No t natural. The electrolarynx is a tech nical device. It can b e d efective, misplaced or can be rendered unusable b y a dead battery. • The sound of an electrolarynx is m ore noticeabl e than esoph ageal speech. A ‘ro botic voi ce’ effect clearly persist s in th e so und of an electrolarynx. This results in unnaturalness of the arti ficial speech. • The electrolarynx is a visual prosthesis. • On e hand is always occup ied by the electro larynx. • V ery clear articulation is requested. • Accen tuated speech can't b e learned by all patien ts (dependin g on their motor skills and musicality). • Leaka ge of sound source signals. In ord er to make artifici al speech su fficiently aud ible an electrolarynx n eeds to generate su fficiently loud sound source signals. Thus, the sound source signals th emselves are noi sy for other people around the laryngectomees es pecially in a quiet surrounding. Also, electri cal imitation of any vo cal fold vibration will cause a degradation of the sp eech quality. A nu mber o f oth er altern atives to the electrolarynx ha ve also been d eveloped, ho wever each was found to have its o wn set of d isadvantages. An ‘Arti ficial Larynx’ ap paratus p roposed in [18], h as i ndeed put an end to th e search for a more lifelike and individualized voice by do ing away with t he robo tic voice provided by a mechan ical laryn x, however it suffers from a 0.3-second delay bet ween when the tongue and mouth move, and when the computer calculates th e right word. This leaves Internationa l Journal of Computer Ap plications (0975 – 8887) Volume 49– No.21, July 2012 28 the mouth and the voice ou t of sync, giving the user th e appearance o f b eing du bbed. An ‘Electronic skin’ proposed by Dae-Hyeong K. et al.in [1 9] is a wearab le senso r that cou ld help monitor h ealth, amplify speech or control p rosthetics, but suffers from the drawback of bein g expensive to manufacture. Another major downside o f t his system i s that the continu al shedding of skin cells means that th e patch falls off a fter a few days. A major poi nt of concern i s t hat th e imitational speech c annot completely i mitate the arti ficial sp eech uttered by laryngectomees. Thus, i t is impo rtant to investigate ho w effective the s ystem is, b y using d ata obtain ed from laryngectomees. Although it is good for th e user t o get the auditory feedback from the cu rrent con verted speech but higher quality voi ce morphing t echniques that can work in real-time h ave not yet been devised . Thu s, we p ropose a novel method to p rovide the sign als detected by NAM micropho ne straight to t he speaker as expl icit aud itory feedback. We hereby re commend a speaking- aid sy stem using a modern voice con version technique for laryngectomees to provide much natural sp eech communication [2]. 5.1 S tructure of the Proposed Sy stem Fig 4: Structure of the Pr oposed Syste m As p roposed in [ 13], figure 3 shows the speaking-aid s ystem with a voice conversio n technique for laryngecto mees. First, a user attaches a so und so urce un it und er th e l ower ja w and articulates sound source signals. A disti nct feature of the sound source signals is that the power is extremely small so that people around t he user cannot hear it. To capt ure the small arti ficial speech, we u se a N on-Audible Murmur (NAM) microph one p owered with a high dynamic gain and a large ran ge o f operati on. As the artificial speech detected with NAM microphon e is still not the sa me as the n atural speech, the captu red data is converted i nto natu ral speech u sing our proposed voice conversion technique. Our system thus uses the m odern GMM-b ased ap proach discussed in the earlier sections o f this p aper for acco mplishin g the voi ce conversion section dep icted in th e figure. Finally, th e converted speech is presented as t he voice of user [13] . 6. PER FORMANCE AN ALYSIS AND RESULT S 6.1 S ubjective Evalu ation The u ltimate objective of the voice con version system is to transform an utteran ce of a spea ker to sound as if spoken b y the target spea ker while maintaining the n aturalness in speech. Hence, in order to evaluate the proposed system on these two scales, th ree t ypes o f su bjective measures are generally used , as mentioned below: • ABX Test • M OS Test • Similarity Test 6.1.1 ABX Test In o rder to check i f the con verted speech is perceived as the target speaker, ABX tests are most commonly used where participan ts l isten to so urce (A), target (B) and tran sformed (X) utterances and are asked t o determine whether A or B is closer to X in terms of speake r identity. A score of 100% indicates that all listeners find the transfor med speech closer to the target. 6.1.2 Mean Opinion Score and Similarity Test The transformed speech is also generall y evaluated in terms of naturaln ess and intell igibility b y M ean Opin ion Score (MOS) tests. In this test, the part icipants are asked to ran k t he transformed speech in ter ms o f its q uality and/o r intelligibi lity. Listeners evaluate th e speech qu ality of the converted voi ces using a 5-point scale, where: • 5: excellent • 4: good • 3: fair • 2: poor • 1: bad This is similar to the si milarity test, bu t the major difference lies in the fact th at we concentrate on the speaker characteristics in th e similarity test and in telligibility in the MOS test. The MOS test is generally p referred over t he Si milarity test as we are more interested in the intelli gibility, hen ce the MOS test h as b een formed and the results have been t abulated in Table 1. Table 1. M OS Training Table No. of Gaussians No. of test speaker sa mple for training Quality 1 2 2.9 5 2 3 10 2 3.5 1 8 3 5 8 4 10 8 4.3 Here the traini ng is done with two cases: • Usi ng two samples each o f source and target • Using eight sa mples each of source and target After train ing we have introd uced a test spea ker which will be an inp ut to th e training an d will exactl y reprodu ce the voice o f the target speaker. Hereaft er we have don e three tests: • S ignal to noise d istortion • Avera ge spectral disto rtion • Varying number of Gaussians The implementatio n thus follows. Upon varying the number o f Gaussians as (1, 5 , 10 ) and number of t est spea ker samples as (2, 8), we have assigned a rating as per t he observations. Internationa l Journal of Computer Ap plications (0975 – 8887) Volume 49– No.21, July 2012 29 6.2 O bjective Evaluati on Objective ev aluation s are indicative of conversion performance and cou ld be useful to compare different algorithms within a p articular framework. We ha ve calculated the signal to noise ratio of the tran sformed speech and also the average spe ctral d istortion. We h ave tested with t wo test speaker s ample traini ng and eight test speaker sa mple tr aining and compared t he results. Table 2. Average dist ortion for each sa mple Test speaker sa mple number Average spectral distorti on 1 2.940637 2 1.359387 4 3.050596 5 1.370122 6 1.836406 1 2.940637 6.2.1 Signal to Noise Ratio A Signal to Noise Ratio (S NR) of less than 1.1 suggests a very poor qu ality o f signal. Usin g the proposed method, we are gettin g a good quality signal havin g an SNR within the range o f 2.5 to 3 .6.We have p icked the test speaker samples from t est folder 1-6 and calculated the signal t o noi se rati o for both 2 test speaker sa mples and 8 t est speaker sa mples training. Table 3. SNR for 2 and 8 test speaker s amples Test speaker sample number 2 test speaker training sample SNR (dB) 8 test speaker training sample SNR (dB) 1 3.65 3.6505 2 2.5578 2.5608 4 3.0162 3.0100 5 3.4803 3.4867 6 3.2115 3.2100 1 3.5851 3.5851 6.2.2 Average spectral distortion Average sp ectral distort ion is th e objective evaluation o f differences b etween two speech signals. We h ave taken 6 test speakers and individually found out the difference between the test signal an d th e target sign al for 8 sample train ing (source + target). Table 4. Total objective e valuation No. of test speaker sample for training No. of Gaussians Time for execution (seconds) SNR (dB) Average spectral distortion 2 1 10 3.6550 2.946 2 3 20 3.6585 2.936 2 5 40 3.6582 2.943 2 10 180 3.6539 2.936 8 1 30 3.6591 2.946 8 3 45 3.6563 2.944 8 5 70 3.6567 2.943 8 10 300 3.6512 2.945 Thus, we o bserve that for 2 test speak er samples used for training, the signal to noise ratio was maximu m for number of Gaussians lying bet ween 3 t o 5 whereas in th e case of 8 samples being u sed for train ing, the si gnal to no ise was maximum when th e nu mber of Gaussians was 1. For traditional systems t he si gnal to noise ratio was around about 2.1 to 2.6 whereas for this method i t is well abo ve 3 as depicted by the tab le above. 7. CO NCLUSION AND FUTURE S COPE This pro ject present s a novel metho d which is based on t he technique of th e separatio n of glottal wavefor ms and the prediction o f th e tran sformed residu als for p recise voice conversion. P erformance analysis and results show th at not only are the transformed vocal tract para meters matching the target one better, bu t also are th e target perso nalities preserved. Although the enh ancements described in this paper give a substanti al improvement, there is st ill disto rtion remained which makes the aud io quality depressive and th e future work will therefore focus o n it. During the practical implementatio n of the system, in certain cases, so me critical problems may arise. The d ifficulty o f acquirin g the auditory feedback would cause a negative spir al of instabil ity o f the articulati on, t he degradatio n of the converted speech q uality and more instabi lity of the articulation. This would thus resul t in a repeti tive degrad ation and instability p rocess. Steps to overcome th is i ssue n eed to be worked up on in future course of time. 8. ACKNOW LEDGMEN TS Our sin cere thanks to P rof. Rakesh Ch adha, Biology Department, S t. Xavier’s College, for co ntributin g towards the development of the propo sed sy stem by providi ng us with information regarding Laryngectomy and th e n ewer solutions being dep loyed (apart from an el ectrolarynx) to enable s mooth communication for laryngectomees. The authors would also like to thank Prof. J. H. Nirmal, Department of Electro nics Engineering, K. J. Somaiya College o f Engineerin g, for his prompt guidance regarding the project. 9. RE FERENCES [1] Abe M., Nakamura S., Shikano K. and Kuwabara H., “Voice con version th rough vector quanti zation,” International Conference on Acoustics, Speech, and Signal Pro cessing (ICASSP), 1988, 65 5-658. [2] Baud oin G. and Stylianou Y., “On the t ransformation of the speech spectrum for voice co nversion,” International Conference on Spo ken Language (I CSLP), Philadephia, October 1996, Vol. 3, 1405-1408 . [3] Kain A. and M acon M., “Sp ectral vo ice conversion for text to speech synthesis,” Pr oceedings of the IEEE International Conference on Acoustics, S peech and Signal Pro cessing (ICASSP), 1998, Vo l. 1, 285-288. [4] Stylianou Y. and C appe O., “A syste m for voice conversion based on probabilistic classification and a harmonic p lus noise model, ” Intern ational C onference on Acoustics, Speech, and Signal P rocessing (ICASSP ), 1998, Seattle, 281-284. [5] Ye H. and Youn g S., “High quality voice morphing”, International Conference on Acoustics, Speech, and Signal Processing (ICASSP ), 2004, Mo ntreal, Vol. 1, 9 - 12. Internationa l Journal of Computer Ap plications (0975 – 8887) Volume 49– No.21, July 2012 30 [6] Upp erman, G., “Linear Predictive Coding In Voice Conversion ”, December 21, 2004. [7] Bradb ury J., “Linear P redictive Coding” Dece mber 5, 2000. [8] Gundersen , T., “Voice Transformation b ased on Gaussian mixture models,” Master o f Science in Communication Technology Thesis, Norwegian University of Science and Technology, Department of Electronics and Telecommunication s, 2010, 55. [9] Cliff M. , “GMM and M INZ Program Libraries for Matlab,” Krann ert Graduate Schoo l o f Management, Purdue Un iversity, March 2, 2003. [10] Scherrer B., “Gaussian Mixtur e Model Classifiers,” February 5, 2 007. [11] Resch B., “M ixtures of Gaussians-A Tut orial for th e Course Computati onal Intelligence,” Signal Pro cessing and Sp eech Communication Laboratory Inffeldgasse 1 6c, http://www.igi.tugraz.at/l ehre/CI, Jun e 2012. [12] Xu N. and Yang Z., “A P recise Estimatio n of Vo cal Tract Parameters for Hi gh Quali ty V oice Mo rphing”, 9th International Conference on Signal Processing (ICSP), October 2008, 684-687. [13] Nakamura K., Tod a T., Nakaji ma Y., Saruwatari H. an d Shikano K., “Evaluation of S peaking-Aid System with Voice Con version for Laryngectomees to ward I ts U se in Practical Environments,” INTERSP EECH (ISCA), 2008, Brisbane. [14] Huang X., Acero A . and Hon H. “Spoken Language Processing: A Guid e to Theory, Algor ithm and System Development”, P rentice Hall, 2001 . [15] Reynolds D., “Gaussian Mixtu re Mod els,” Encyclopedi a of Biometrics, 200 9, 659-663. [16] Mesbahi L., Barreaud V , and Boeffard O., “GMM-B ased Speech Transformation Systems under Data R eduction,” Sixth ISCA Worksho p on Speech Synthesis, 200 7, 119- 124. [17] CMU_ARCTIC Speech S ynthesis Databases, Carnegie Mellon University, ht tp://festvox.o rg/cmu_arctic, March 2012. [18] Russell M., “Towards S peech Recognition u sing P alato- Lingual Contact P atterns for Voice Restor ation,” PhD Thesis, Facult y of Engineerin g, University o f the Witwatersrand, Ju ne 2011. [19] Dae-Hyeong K. et al., “Epidermal E lectronics,” S cience, Vol. 333, No. 6044, 12 August 2011 , 838-843. AUTHOR BIOG RAPHIES Aman Chadha (M’2008) was b orn in Mumbai (M.H. ) in India on November 22, 1990. He is currently pursui ng his graduate studies in Electrical and Computer Engineering at the University of Wisconsin-Madison, USA. He completed his B.E. in Electron ics and Telecommunication Engineering from the Un iversity of M umbai in 2012. His special fields o f interest include Signal and Image Pro cessing, C omputer Vision (p articularly, Pattern Recogn ition) and P rocessor Microarchit ecture. He has 9 papers in International Conferences and Jou rnals to his credit. He is a member of the IETE, IACSIT and ISTE. Bharatraaj S avardekar (M ’2008) was b orn in Mu mbai (M.H.) in India on Jan uary 24, 1990. He completed his B.E. in Electronics Engineering f rom the University of Mumbai in 2012. His fields of interest include Audio Processing and Human-Comput er Interaction. Jay P adhya (M’20 08) was b orn in Mu mbai (M.H.) in In dia on May 16, 1990. He completed his B. E. in E lectronics Engineering from the University o f Mu mbai in 2012 . His fields o f int erest in clude Audio P rocessing and Human- Computer Int eraction.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment