가우시안 혼합 모델 기반 현대 음성 변환 기법: 후두절제 환자를 위한 고품질 음성 합성
본 논문은 전통적인 GMM 기반 음성 변환에서 발생하는 과도한 평활화 문제를 해소하기 위해, 성대 파형 분리와 흥분 신호 예측을 결합한 새로운 GMM 매핑 방식을 제안한다. LPC와 DTW를 이용해 음성 특성을 추출·정렬하고, glottal 파형을 제거한 후 음성 기관 파라미터를 GMM으로 변환한다. 변환된 파라미터와 예측된 흥분 신호를 LPC 합성에 적용해 고품질 합성 음성을 생성한다. CMU‑ARCTIC 데이터베이스를 활용한 주관·객관 평가…
저자: Aman Chadha, Bharatraaj Savardekar, Jay Padhya
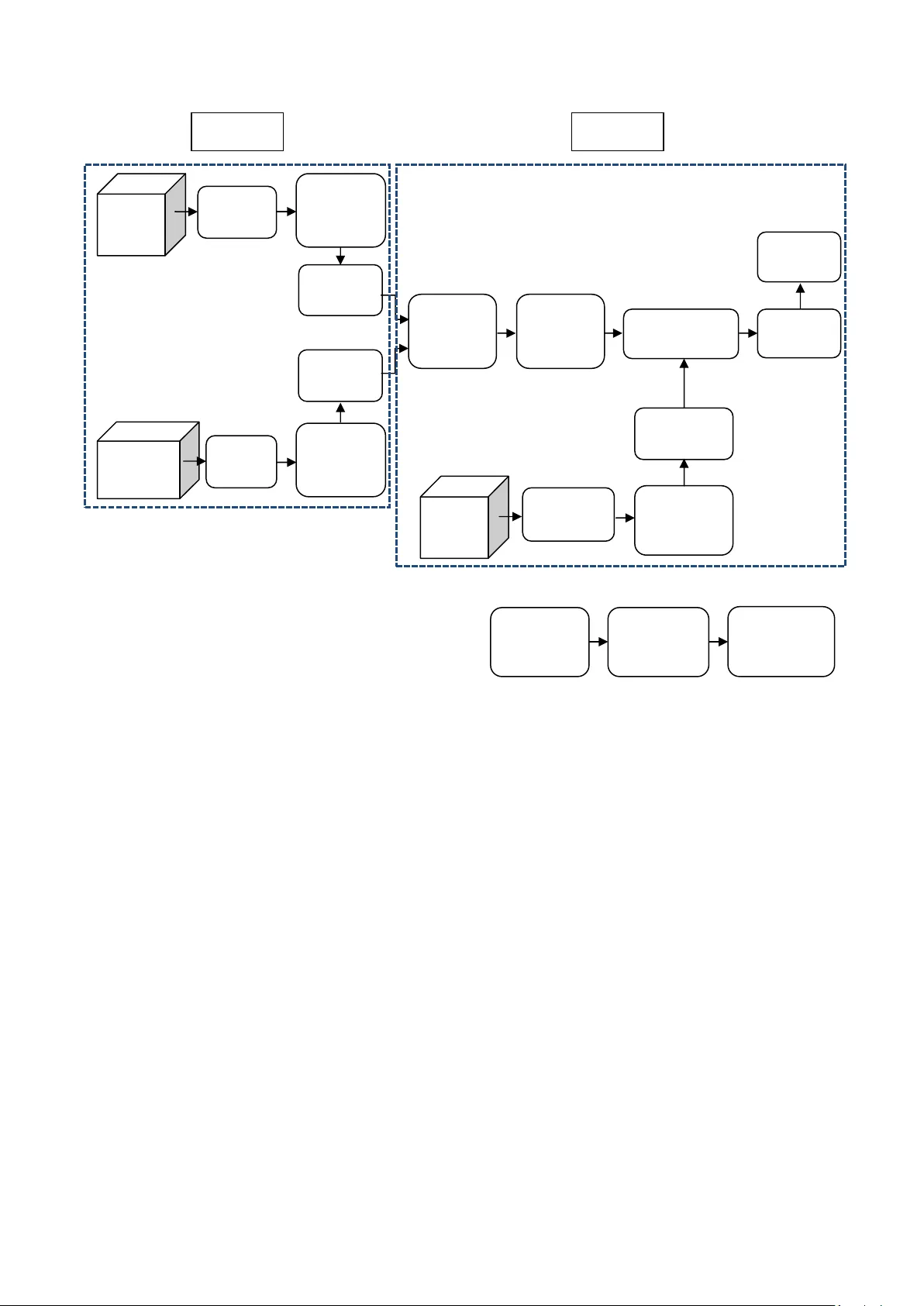
본 논문은 후두절제(laryngectomy) 환자를 위한 음성 보조 시스템 개발을 목표로, 기존 가우시안 혼합 모델(GMM) 기반 음성 변환에서 발생하는 과도한 평활화(over‑smoothening) 문제를 해결하는 새로운 방법론을 제시한다. 먼저 서론에서는 음성 변환의 기본 흐름을 소개하고, 기존 연구가 주로 음성 기관(vocal‑tract) 매핑에 집중했으며, excitation 신호에 대한 변환이 부족해 변환 음성의 품질이 저하된다는 점을 지적한다. 이를 보완하기 위해 LPC(Linear Predictive Coding)와 DTW(Dynamic Time Warping)를 활용한 프레임 정렬, glottal 파형 분리, 그리고 GMM 기반 매핑을 결합한 두 단계 프로세스를 설계한다.
**제안 시스템 구조**는 크게 두 단계(Phase 1, Phase 2)로 나뉜다. Phase 1에서는 source와 target 음성을 LPC 분석하고, glottal 파형을 분리한다. 이때 glottal derivative G′(z)를 역필터링함으로써 순수한 음성 기관 파라미터만을 추출한다. 추출된 파라미터는 GMM에 입력되어 source‑to‑target 매핑 모델을 학습한다. Phase 2에서는 학습된 GMM을 이용해 테스트 화자의 LPC 파라미터를 변환하고, 동시에 excitation 신호에 대한 예측 규칙을 적용해 새로운 excitation을 생성한다. 최종적으로 변환된 음성 기관 파라미터와 예측된 excitation을 LPC 합성기에 입력해 자연스러운 합성 음성을 만든다.
**구현 세부사항**으로는 CMU‑ARCTIC 데이터베이스를 사용해 6명의 화자(SLT, CLB, RMS, JMK, AWB, KSP)로부터 11~32개의 발음 균형 문장을 수집하였다. 학습 단계에서는 source와 target 음성을 동일한 프레임 길이(2 pitch period)로 나누고, DTW를 통해 시간 정렬을 수행한다. 이후 각 프레임에 대해 12차 LPC 계수를 추출하고, glottal 파형을 제거한다. GMM은 EM(Expectation‑Maximization) 알고리즘으로 학습되며, Gaussian 수는 1, 5, 10을 실험하였다.
**평가 방법**은 주관적 평가와 객관적 평가로 구분된다. 주관적 평가는 ABX 테스트, MOS(Mean Opinion Score) 테스트, 유사도 테스트를 통해 변환 음성의 화자 일치도와 자연스러움을 측정한다. MOS는 5점 척도로 평가했으며, 실험 결과 Gaussian 수가 10개이고 학습 샘플이 8개일 때 MOS 평균이 4.3에 달했다. 객관적 평가는 신호‑대‑잡음 비(SNR)와 평균 스펙트럼 왜곡(average spectral distortion)을 계산했으며, Gaussian 수와 학습 샘플 수가 증가할수록 왜곡이 감소하는 경향을 보였다.
**후두절제 환자 적용** 부분에서는 기존 전자 성대(electrolarynx)의 한계—소리의 로봇틱함, 배터리 의존성, 청자에게 불쾌감을 주는 높은 음량—를 논의하고, 비가청 마이크(NAM)와 결합한 새로운 보조 시스템을 제안한다. 사용자는 하악 아래에 소리 발생 장치를 부착하고, 매우 낮은 전력의 인공 음성을 NAM 마이크로 포착한다. 포착된 신호는 본 논문의 GMM 기반 변환 파이프라인을 거쳐 자연스러운 음성으로 재생된다. 이 방식은 기존 전자 성대보다 더 자연스러운 음성 피드백을 제공하고, 실시간 대화에 근접한 사용성을 기대한다.
**결론**에서는 제안된 glottal 파형 분리와 excitation 예측을 포함한 GMM 매핑이 전통적인 GMM 기반 변환의 평활화 문제를 효과적으로 완화함을 강조한다. 실험 결과는 주관적 MOS와 객관적 왜곡 지표 모두에서 기존 방법보다 우수함을 입증한다. 다만, 실시간 구현에 대한 상세한 연산 복잡도 분석이 부족하고, 실제 laryngectomee를 대상으로 한 현장 테스트가 이루어지지 않아 향후 연구 과제로 남는다. 전반적으로, 이 논문은 음성 변환 기술을 의료 보조 기기에 적용하는 데 있어 중요한 이론적·실험적 기반을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기