CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Semantic code search is the task of retrieving relevant code given a natural language query. While related to other information retrieval tasks, it requires bridging the gap between the language used in code (often abbreviated and highly technical) a…
Authors: Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit
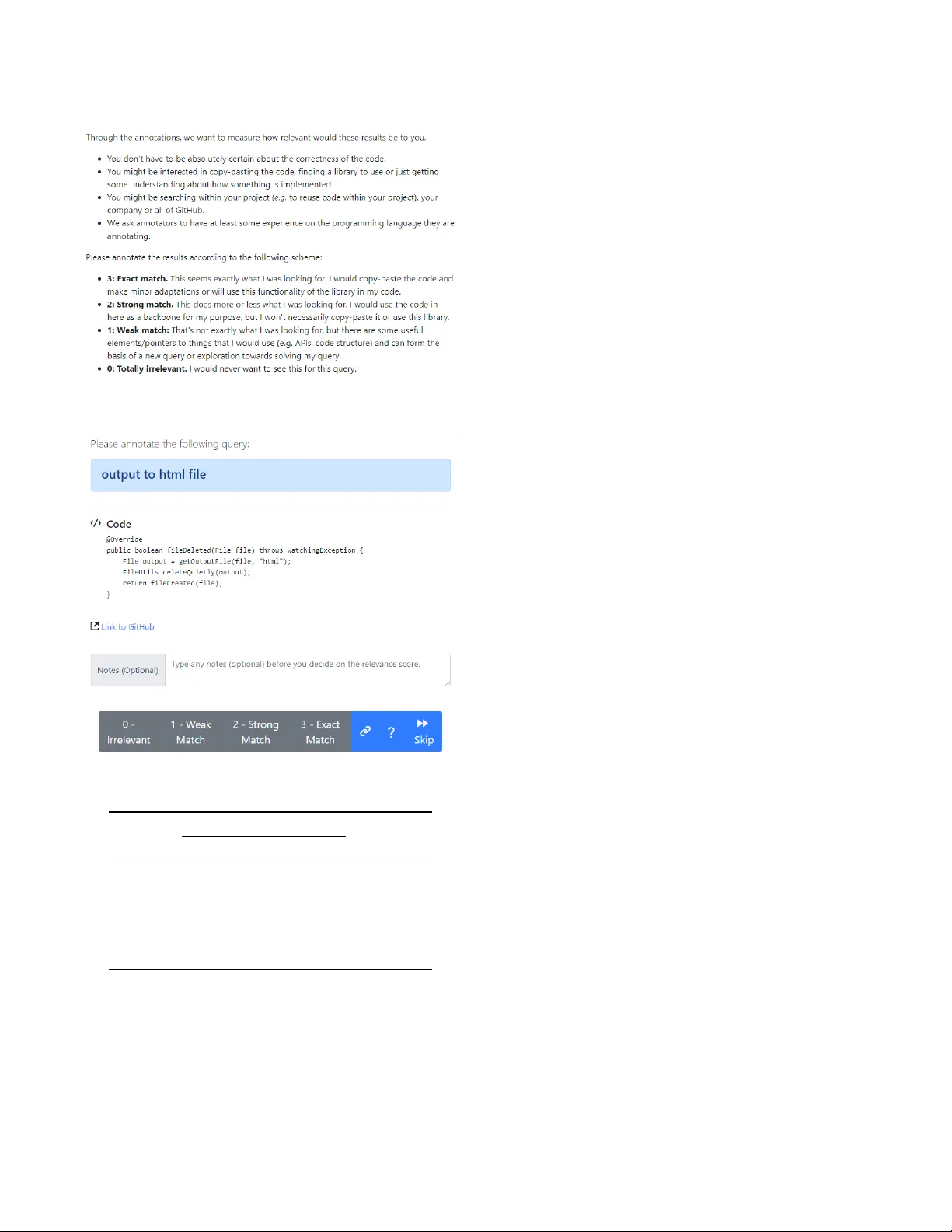
CodeSearchNet Challenge Evaluating the State of Semantic Code Search Hamel Husain Ho-Hsiang W u Tiferet Gazit {hamelsmu, hohsiangwu, tiferet}@github .com GitHub Miltiadis Allamanis Marc Brockschmidt {miallama, mabrocks}@microsoft.com Microsoft Research ABSTRA CT Semantic code search is the task of retrieving relevant code given a natural language query . While related to other information retrieval tasks, it requires bridging the gap between the language used in code (often abbreviated and highly technical) and natural language more suitable to describe vague concepts and ideas. T o enable evaluation of progress on code sear ch, we are releasing the CodeSearchNet Corpus and are presenting the CodeSearch- Net Challenge , which consists of 99 natural language queries with about 4k expert relevance annotations of likely results from Code- SearchNet Corpus . The corpus contains about 6 million functions from open-source code spanning six programming languages (Go , Java, JavaScript, PHP, Python, and Ruby). The CodeSearchNet Corpus also contains automatically generated query-like natural language for 2 million functions, obtaine d from mechanically scrap- ing and preprocessing associated function documentation. In this article, we describe the methodology used to obtain the corpus and expert labels, as well as a number of simple baseline solutions for the task. W e hope that CodeSearchNet Challenge encourages researchers and practitioners to study this interesting task further and will host a competition and leaderb oar d to track the progress on the chal- lenge. W e ar e also keen on extending CodeSearchNet Challenge to more queries and programming languages in the future . 1 IN TRODUCTION The deep learning revolution has fundamentally changed how we approach perceptive tasks such as image and spee ch r ecognition and has shown substantial successes in working with natural lan- guage data. These have be en driven by the co-evolution of large (labelle d) datasets, substantial computational capacity , and a num- ber of advances in machine learning models. Howev er , deep learning models still struggle on highly structured data. One example is semantic code search : while search on natural language documents and even images has made great progress, searching code is often still unsatisfying. Standard information re- trieval methods do not work well in the co de search domain, as there is often little shared vocabulary between search terms and results ( e.g. consider a method calle d deserialize_JSON_obj_from_stream that may be a correct result for the query “read JSON data”). Even more problematic is that evaluating methods for this task is ex- tremely hard, as there are no substantial datasets that were created for this task; instead, the community tries to make do with small datasets from related conte xts ( e.g. pairing questions on web forums to code chunks found in answers). T o tackle this problem, we have dened the CodeSearchNet Challenge on top of a new CodeSearchNet Corpus . The Code- SearchNet Corpus was programmatically obtained by scraping open-source repositories and pairing individual functions with their (processed) do cumentation as natural language annotation. It is large enough (2 million datapoints) to enable training of high- capacity deep neural models on the task. W e discuss this process in detail in section 2 and also release the data preprocessing pipeline to encourage further research in this area. The CodeSearchNet Challenge is dened on top of this, pro- viding realistic queries and expert annotations for likely results. Concretely , in v ersion 1.0, it consists of 99 natural languages queries paired with likely results for each of six considered programming languages (Go, Java, JavaScript, PHP, Python, and Ruby). Each query/result pair was labeled by a human expert, indicating the relevance of the result for the query . W e discuss the methodology in detail in section 3 . Finally , we create a number of baseline methods using a range of state-of-the-art neural sequence processing techniques (bag of words, RNNs, CNNs, attentional models) and evaluate them on our datasets. W e discuss these models in section 4 and present some preliminary results. 2 THE CODE SEARCH CORP US As it is economically infeasible to create a dataset large enough for training high-capacity models using expert annotations, we instead create a proxy dataset of lo wer quality . For this, we follow other attempts in the literature [ 5 , 6 , 9 , 11 ] and pair functions in open-source software with the natural language present in their respective do cumentation. However , to do so requires a number of preprocessing steps and heuristics. In the following, we discuss some general principles and decisions driven by in-depth analysis of common error cases. CodeSearchNet Corpus Collection. W e collect the corpus from publicly available open-source non-fork GitHub repositories, using libraries.io to identify all projects which are used by at least one other project, and sort them by “popularity” as indicated by the number of stars and forks. Then, we remove any projects that do not have a license or whose license does not explicitly permit the re-distribution of parts of the project. W e then tokenize all Go, Java, JavaScript, Python, PHP and Ruby functions (or methods) using Tr eeSitter — GitHub ’s univ ersal parser — and, wher e available, their respective documentation text using a heuristic regular expression. Filtering. T o generate training data for the CodeSearchNet Challenge , we rst consider only those functions in the corpus CodeSearchNet Number of Functions w/ documentation All Go 347 789 726 768 Java 542 991 1 569 889 JavaScript 157 988 1 857 835 PHP 717 313 977 821 Python 503 502 1 156 085 Ruby 57 393 164 048 All 2 326 976 6 452 446 T able 1: Dataset Size Statistics that have do cumentation associated with them. This yields a set of pairs ( c i , d i ) where c i is some function do cumented by d i . T o make the data more realistic pr oxy for code search tasks, we then implement a number of preprocessing steps: • Documentation d i is truncated to the rst full paragraph, to make the length more comparable to search queries and re- move in-depth discussion of function arguments and return values. • Pairs in which d i is shorter than three tokens are remo ved, since we do not expect such comments to be informative. • Functions c i whose implementation is shorter than three lines are r emoved, these often include unimplemented meth- ods, getters, setters, etc. • Functions whose name contains the substring “test” are r e- moved. Similarly , we remo ve constructors and standard e x- tension methods such as __str__ in Python or toString in Java. • W e remo ve duplicates from the dataset by identifying (near) duplicate functions and only keeping one copy of them (we use the methods describ ed in Allamanis [ 1 ] , Lopes et al . [ 18 ] ). This removes multiple v ersions of auto-generated code and cases of copy & pasting. The ltered corpus and the data extraction code are released at https://github.com/github/CodeSearchNet . Dataset Statistics. The resulting dataset contains about 2 million pairs of function-documentation pairs and about another 4 million functions without an associated do cumentation ( T able 1 ). W e split the dataset in 80-10-10 train/valid/test proportions. W e suggest that users of the dataset employ the same split. Limitations. Unsurpsingly , the scraped dataset is quite noisy . First, documentation is fundamentally dierent from queries, and hence uses other forms of language. It is often written at the same time and by the same author as the documented code, and hence tends to use the same vocabulary , unlike search queries. Second, despite our data cleaning eorts we are unable to know the extent to which each documentation d i accurately describes its associated code snippet c i . For example, a number of comments are outdated with regard to the code that they describe. Finally , we know that some documentation is written in other languages, whereas our CodeSearchNet Challenge evaluation dataset focuses on English queries. 3 THE CODE SEARCH CHALLENGE T o evaluate on the CodeSearchNet Challenge , a method has to return a set of relevant r esults from CodeSearchNet Corpus for each of 99 pre-dened natural language queries. Note that the task is somewhat simplied from a general co de search task by only allowing full functions/methods as results, and not arbitrary chunks of code. 1 The CodeSearchNet Challenge evaluation dataset con- sists of the 99 queries with relevance annotations for a small number of functions from our corpus likely to be returned. These annota- tions were collected from a small set of expert programmers, but we are looking forward to widening the annotation set going for ward. Query Collection. T o ensure that our quer y set is repr esentative, we obtained common search queries from Bing that had high click- through rates to co de and combined these with intent rewrites in StaQC [ 24 ]. W e then manually ltered out queries that were clearly technical keywords ( e.g. the exact name of a function such as tf.gather_nd ) to obtain a set of 99 natural language queries. While most of the collected queries are generic, some of them are language-specic. Expert A nnotations. Obviously , we cannot annotate all quer y/- function pairs. T o lter this down to a more realistically-sized set, we used our implementations of baseline methods and ensembled them (see section 4 ) to generate 10 candidate results per query and programming language. Concretely , we used ensembles of all neural models and ElasticSearch to generate candidate results, merge the suggestions and pick the top 10. W e used a simple web interface for the annotation process. The web interface rsts shows instructions (see Figure 1 ) and then allows the annotator to pick a program- ming language. Then, one query/function pair is shown at a time, as shown in Figure 2 . A link to the origin of the shown function is included, as initial experiments showed that some annotators found inspecting the context of the code snippet helpful to judge relevance. The or der of query/code pairs shown to the user is ran- domized but weakly ordered by the number of expert annotations already collected. Annotators are unlikely to se e sev eral results for the same quer y unless they handle many examples. By randomizing the order , we aim to allow users to score the relevance of each pair individually without encouraging comparisons of dierent results for the same query . A nnotation Statistics. W e colle cted 4 026 annotations acr oss six programming languages and prioritized coverage over multiple annotations per query-snipp et pair . Our annotators are volunteers with software engine ering, data science and research roles and were asked to only annotate examples for languages they had signicant experience with. This led to a skewed distribution of annotations w .r .t. the considered programming languages. W e observed that the obtained relevance scores ar e distributed dierently for each language ( T able 2 ). For example, the relevance scores for Python are evenly distributed across the four categories while for JavaScript the annotations are skewed towards lower relevance scores. There is a number of potential reasons for this, such as the quality of the used corpus, language-sp ecic interactions 1 Note that on a suciently large dataset, this is not a signicant restriction: more com- monly implemented functionality almost always appears factored out into a function somewhere. CodeSearchNet Challenge Figure 1: Instructions provided to annotators. Figure 2: Interface used for relevance annotation. Count by Relevance Score T otal 0 1 2 3 Annotations Go 62 64 29 11 166 Java 383 178 125 137 823 JavaScript 153 52 56 58 319 PHP 103 77 68 66 314 Python 498 511 537 543 2 089 Ruby 123 105 53 34 315 T able 2: Annotation Dataset Statistics with our pre-ltering strategy , the queries we collected, higher expected relevance standards in the JavaScript community , etc. For the 891 query-co de pairs where we have more than one annotation, we compute the squared Cohen’s kappa interannotator agreement to estimate the quality of the task. The agreement is moderate with Cohen κ = 0 . 47 . This is somewhat e xpected given that this task was relatively open-ended, as we will discuss next. Qualitative Observations. During the annotation process we made some observations in discussions with the annotators and through the notes they provided in the web interface ( see Fig. 2 ). These com- ments point to some general issues in implementing code search: Code Quality A subset of the results being returned are func- tionally correct code, but of lo w quality , even though the y originated in reasonably popular projects. In this context, low quality refers to unsatisfactor y readability , bad secu- rity practices, known antipatterns and potentially slow code. Some annotators felt the need to give low er rele vance scores to low-quality co de as they would prefer not to see such results. Query Ambiguity Queries are often ambiguous without addi- tional context. For example, the query “how to determine if a string is a valid word” can have dier ent correct interpre- tations depending on the domain-sp ecic meaning of “valid word” . Library vs. Project Specic Often a search yields code that is very specic to a given project ( e.g. using internal utility functions), whereas other times the code is ver y general and verbose ( e.g. containing code that could be factored out). Which of these is preferable depends on the context of the query , which we did not explicitly specify when asking for annotations. Context Some results wer e semantically correct, but not relying on related help er functions and thus not self-contained. Some annotators were uncertain if such r esults should be consid- ered relevant. Directionality A common problem in results w ere functions im- plementing the inverse functionality of the quer y , e.g. “con- vert int to string” w ould be answered by stringToInt . This suggests that the baseline models used for pre-ltering have trouble with understanding such semantic aspects. 3.1 Evaluation of Ranking Models T o track the progress on the CodeSearchNet Challenge we hav e deployed a W eights & Biases leaderb oar d at https://app.wandb .ai/ github/codesearchnet/benchmark . W e hope that this leaderboard will allow the community to better compare solutions to the code search task. Metrics. W e use d normalized discounted cumulative gain (NDCG) to evaluate each competing method. NDCG is a commonly used metric [ 19 ] in information retrie val. W e compute two variants of NDCG: (a) NDCG computed over the subset of functions with human annotations (“Within”) ( b) NDCG over the whole Code- SearchNet Corpus (“ All”). W e make this distinction as the NDCG score computed over the whole corpus may not necessarily repr e- sent the quality of a search tool, as a ne w tool may yield relevant but not-annotated functions. CodeSearchNet Figure 3: Model Architecture Overview . 4 BASELINE CODESEARCH MODELS W e implemented a range of baseline models for the co de search task, using standard techniques from neural sequence pr ocessing and web search. 4.1 Joint V e ctor Representations for Code Search Following earlier work [ 11 , 20 ], we use joint emb eddings of code and queries to implement a neural search system. Our architecture employs one encoder per input (natural or programming) language and trains them to map inputs into a single, joint vector space. Our training objective is to map code and the corresponding language onto vectors that are near to each other , as we can then implement a search method by embedding the query and then r eturning the set of code snippets that are “near” in emb edding space. Although more complex models considering more interactions between queries and co de can perform better [ 20 ], generating a single vector per query/snippet allows for ecient indexing and search. T o learn these embe dding functions, we combine standard se- quence encoder mo dels in the architecture shown in Figure 3 . First, we preprocess the input sequences according to their seman- tics: identiers appearing in code tokens are split into subtokens ( i.e. a variable camelCase yields two subtokens camel and case ), and natural language tokens are split using byte-pair encoding (BPE) [ 10 , 21 ]. Then, the token sequences are processed to obtain (conte xtual- ized) token embeddings, using one of the following architectures. Neural Bag of W ords where each (sub)token is embedded to a learnable embedding (vector representation). Bidirectional RNN models where we employ the GRU cell [ 7 ] to summarize the input sequence. 1D Convolutional Neural Network over the input sequence of tokens [ 15 ]. Self- Attention where multi-head attention [ 22 ] is used to com- pute representations of each token in the sequence. The token embeddings are then combined into a sequence embed- ding using a pooling function, for which we have implemented mean/max-pooling and an attention-like weighted sum mechanism. For all models, we set the dimensionality of the embedding space to 128. During training we are given a set of N pairs ( c i , d i ) of code and natural language descriptions and have instantiated a code encoder E c and a query encoder E q . W e train by minimizing the loss − 1 N Õ i log exp ( E c ( c i ) ⊤ E q ( d i )) Í j exp ( E c ( c j ) ⊤ E q ( d i )) ! , i.e. maximize the inner product of the code and quer y encodings of the pair , while minimizing the inner product between each c i and the distractor snippets c j ( i , j ). Note that we have e xperimented with other similar objectives ( e.g. considering cosine similarity and max-margin approaches) without signicant changes in results on our validation dataset. The code for the baselines can be found at https://github.com/github/CodeSearchNet . At test time, we index all functions in CodeSearchNet Cor- pus using Annoy . Annoy oers fast, approximate nearest neighbor indexing and search. The index includes all functions in the Code- SearchNet Corpus , including those that do not have an associated documentation comment. W e observed that carefully constructing this index is crucial to achieving good performance. Sp ecically , our baseline models were underperforming when w e had a small number of trees in Annoy (trees can be thought as approximate indexes of the multidimensional space). 4.2 ElasticSearch Baseline In our experiments, we additionally include d ElasticSearch , a widely used search engine with the default parameters. W e congured it with an index using two elds for every function in our dataset: the function name, split into subtokens; and the text of the entire function. W e use the default ElasticSearch tokenizer . 4.3 Evaluation Following the training/validation/testing data split, we train our baseline models using our objective from above. While it does not directly correspond to the real target task of code search, it has been widely used as a proxy for training similar models [ 6 , 23 ]. For testing purposes on CodeSearchNet Corpus , we x a set of 999 distractor snipp ets c j for each test pair ( c i , d i ) and test all trained models. T able 3 presents the Mean Reciprocal Rank results on this task. Overall, we see that the models achieve relatively good performance on this task, with the self-attention-based model performing best. This is not unexpe cted, as the self-attention mo del has the highest capacity of all considered models. W e have also run our baselines on CodeSearchNet Challenge and show the results in T able 4 . Here, the neural bag of words model performs very well, whereas the stronger neural models on the training task do less well. W e note that the bag of words model is particularly go od at keyword matching, which seems to be a crucial facility in implementing search methods. This hypothesis is further validated by the fact that the non-neural ElasticSearch- based baseline performs competitively among all models we have tested. The NBo W model is the b est performing model among the baselines models, despite being the simplest. As noted by Cam- bronero et al . [ 6 ] , this can be attributed to the fact that the training CodeSearchNet Challenge Encoder CodeSearchNet Corpus (MRR) T ext Co de Go Java JS PHP Python Ruby A vg NBo W NBo W 0.6409 0.5140 0.4607 0.4835 0.5809 0.4285 0.6167 1D-CNN 1D-CNN 0.6274 0.5270 0.3523 0.5294 0.5708 0.2450 0.6206 biRNN biRNN 0.4524 0.2865 0.1530 0.2512 0.3213 0.0835 0.4262 SelfAtt SelfAtt 0.6809 0.5866 0.4506 0.6011 0.6922 0.3651 0.7011 SelfAtt NBo W 0.6631 0.5618 0.4920 0.5083 0.6113 0.4574 0.6505 T able 3: Mean Reciprocal Rank (MRR) on T est Set of CodeSearchNet Corpus . This evaluates for our training task, where given the documentation comment as a query , the models tr y to rank the correct code snippet highly among 999 distractor snippets. data constructed from code do cumentation is not a good match for the code search task. 5 RELA TED W ORK Applying machine learning to code has been widely considered [ 2 ]. A few academic works have looked into related tasks. First, seman- tic parsing has received a lot of attention in the NLP community . Although most approaches are usually aimed towar ds creating an executable representation of a natural language utterance with a domain-specic language, general-purpose languages have been recently considered by Hashimoto et al . [ 13 ] , Lin et al . [ 16 ] , Ling et al. [ 17 ], Yin and Neubig [ 25 ]. Iyer et al . [ 14 ] generate code from natural language within the context of existing methods, whereas Allamanis et al . [ 3 ] , Alon et al . [ 4 ] consider the task of summarizing functions to their names. Finally , Fernandes et al . [ 9 ] consider the task of predicting the documentation text from source code. More related to CodeSearchNet is prior work in code search with deep learning. In the last few years there has be en resear ch in this area (Cambroner o et al . [ 6 ] , Gu et al . [ 11 , 12 ] , Y ao et al . [ 23 ] ), and architectures similar to those discussed pre viously have been shown to work to some extent. Recently , Cambronero et al . [ 6 ] looked into the same problem that CodeSearchNet is concerned with and reached conclusions similar to those discussed here. In contrast to the aforementioned works, her e we pro vide a human- annotated dataset of relevance scores and test a few mor e neural search architectures along with a standard information retrieval baseline. 6 CONCLUSIONS & OPEN CHALLENGES W e hope that CodeSearchNet is a goo d step towards engaging with the machine learning, IR and NLP communities towards dev el- oping new machine learning models that understand sour ce code and natural language. Despite the fact this report gives emphasis on semantic code search we look forward to other uses of the pre- sented datasets. There are still plenty of open challenges in this area. • Our ElasticSearch baseline, that performs traditional keyword- based search, performs quite well. It has the advantage of being able to eciently use rare terms, which often appear in code. Researching neural methods that can eciently and accurately represent rare terms will impr ove performance. • Code semantics such as control and data ow are not ex- ploited explicitly by existing methods, and instead search methods seem to be mainly operate on identiers (such as variable and function) names. How to leverage semantics to improve r esults remains an open problem. • Recently , in NLP, pretraining methods such as BERT [ 8 ] have found great success. Can similar methods be useful for the encoders considered in this work? • Our data covers a wide range of general-purpose code queries. Howev er , anecdotal evidence indicates that queries in spe- cic projects are usually more specialized. Adapting search methods to such use cases could yield substantial perfor- mance improvements. • Code quality of the searched snipp ets was a recurrent issue with our expert annotators. Despite its subjective nature, there seems to be agreement on what constitutes very bad code. Using code quality as an additional signal that allows for ltering of bad results (at least when better results are available) could substantially improve satisfaction of search users. A CKNO WLEDGMEN TS W e thank Rok Nov osel for participating in the CodeSearchNet chal- lenge and pinpointing a bug with the indexing that was signicantly impacting our evaluation results. REFERENCES [1] Miltiadis Allamanis. 2018. The Adverse Eects of Code Duplication in Machine Learning Models of Code. arXiv preprint arXiv:1812.06469 (2018). [2] Miltiadis Allamanis, Earl T Barr , Premkumar Devanbu, and Charles Sutton. 2018. A sur v ey of machine learning for big code and naturalness. ACM Computing Surveys (CSUR) 51, 4 (2018), 81. [3] Miltiadis Allamanis, Hao Peng, and Charles Sutton. 2016. A Convolutional Attention Network for Extreme Summarization of Sour ce Code. In Proceedings of the International Conference on Machine Learning (ICML) . [4] Uri Alon, Omer Levy , and Eran Y ahav . 2018. code2seq: Generating sequences from structured representations of code. arXiv preprint arXiv:1808.01400 (2018). [5] Antonio Valerio Miceli Barone and Rico Sennrich. 2017. A parallel corpus of Python functions and documentation strings for automated code documentation and code generation. arXiv preprint arXiv:1707.02275 (2017). [6] Jose Cambronero, Hongyu Li, Seohyun Kim, Koushik Sen, and Satish Chandra. 2019. When Deep Learning Met Code Search. arXiv pr eprint (2019). [7] K yunghyun Cho, Bart van Merriënboer , Dzmitry Bahdanau, and Y oshua Ben- gio. 2014. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. Syntax, Semantics and Structure in Statistical Translation (2014). [8] Jacob Devlin, Ming- W ei Chang, Kenton Lee, and Kristina T outanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv CodeSearchNet Encoder CodeSearchNet Challenge – NDCG Within CodeSearchNet Challenge – NDCG All T ext Code Go Java JS PHP Python Ruby A vg Go Java JS PHP Python Ruby A vg ElasticSearch 0.307 0.257 0.318 0.338 0.406 0.395 0.337 0.186 0.190 0.204 0.199 0.256 0.197 0.205 NBo W NBo W 0.591 0.500 0.556 0.536 0.582 0.680 0.574 0.278 0.355 0.311 0.291 0.448 0.360 0.340 1D-CNN 1D-CNN 0.379 0.407 0.269 0.474 0.473 0.420 0.404 0.120 0.189 0.099 0.176 0.242 0.162 0.165 biRNN biRNN 0.112 0.165 0.066 0.148 0.193 0.185 0.145 0.030 0.056 0.017 0.042 0.070 0.060 0.046 SelfAtt SelfAtt 0.484 0.431 0.446 0.522 0.560 0.515 0.493 0.211 0.233 0.175 0.232 0.367 0.219 0.240 SelfAtt NBo W 0.550 0.514 0.545 0.557 0.583 0.650 0.566 0.284 0.340 0.299 0.291 0.422 0.360 0.333 T able 4: NDCG Baseline Results on CodeSearchNet Challenge . “Within” computes the NDCG only on the functions within the human-annotated examples. “ All” computes NDCG over all functions in the CodeSearchNet Corpus . preprint arXiv:1810.04805 (2018). [9] Patrick Fernandes, Miltiadis Allamanis, and Marc Brockschmidt. 2018. Structur ed Neural Summarization. arXiv preprint arXiv:1811.01824 (2018). [10] Philip Gage. 1994. A new algorithm for data compression. The C Users Journal 12, 2 (1994), 23–38. [11] Xiaodong Gu, Hongyu Zhang, and Sunghun Kim. 2018. Deep code search. In 2018 IEEE/ACM 40th International Conference on Software Engine ering (ICSE) . IEEE, 933–944. [12] Xiaodong Gu, Hongyu Zhang, Dongmei Zhang, and Sunghun Kim. 2016. De ep API Learning. In Proceedings of the International Symposium on Foundations of Software Engine ering (FSE) . [13] T atsunori B Hashimoto, Kelvin Guu, Y onatan Oren, and Percy S Liang. 2018. A retrieve-and-edit framew ork for predicting structured outputs. In Advances in Neural Information Processing Systems . 10073–10083. [14] Srinivasan Iyer , Ioannis K onstas, Alvin Cheung, and Luke Zettlemoyer . 2018. Map- ping language to code in programmatic context. arXiv preprint (2018). [15] Y oon Kim. 2014. Convolutional neural networks for sentence classication. arXiv preprint arXiv:1408.5882 (2014). [16] Xi Victoria Lin, Chenglong W ang, Luke Zettlemoyer , and Michael D. Ernst. 2018. NL2Bash: A Corpus and Semantic Parser for Natural Language Interface to the Linux Operating System. In International Conference on Language Resources and Evaluation . [17] W ang Ling, Edward Grefenstette, K arl Moritz Hermann, T omas Kocisky , Andrew Senior , Fumin W ang, and Phil Blunsom. 2016. Latent Predictor Networks for Code Generation. In Proceedings of the A nnual Meeting of the Association for Computational Linguistics (ACL) . [18] Cristina V Lopes, Petr Maj, Pedro Martins, V aibhav Saini, Di Yang, Jakub Zitny , Hitesh Sajnani, and Jan Vitek. 2017. DéjàVu: a map of code duplicates on GitHub. Proceedings of the ACM on Programming Languages 1, OOPSLA (2017), 84. [19] Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze. 2008. Intro- duction to Information Retrieval . Cambridge University Press. [20] Bhaskar Mitra, Nick Craswell, et al . 2018. An introduction to neural information retrieval. Foundations and Trends ® in Information Retrieval 13, 1 (2018), 1–126. [21] Rico Sennrich, Barry Haddow , and Alexandra Birch. 2016. Neural machine translation of rare words with subword units. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (A CL) . [22] Ashish V aswani, Noam Shazeer , Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser , and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems . 5998–6008. [23] Ziyu Y ao, Jayavardhan Re ddy Peddamail, and Huan Sun. 2019. CoaCor: Co de Annotation for Code Retrieval with Reinforcement Learning. (2019). [24] Ziyu Y ao, Daniel S W eld, W ei-Peng Chen, and Huan Sun. 2018. StaQC: A Sys- tematically Mined Question-Code Dataset from Stack Overow . In Proceedings of the 2018 W orld Wide W eb Conference on W orld Wide W eb . International W orld Wide W eb Conferences Steering Committee, 1693–1703. [25] Pengcheng Yin and Graham Neubig. 2017. A Syntactic Neural Model for General- Purpose Code Generation. Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL) .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment