코드검색넷 챌린지 의미 기반 코드 검색 현황 평가
코드검색넷 챌린지는 6개 언어(Go, Java, JavaScript, PHP, Python, Ruby)로 구성된 600만 개 함수와 2백만 개의 자동 생성 주석을 포함한 대규모 코드‑자연어 쌍 데이터셋을 공개한다. 99개의 실제 검색 질의를 선정하고, 각 언어별로 4천 건 이상의 전문가 레이블을 수집해 평가용 베이스라인을 제공한다. 논문은 데이터 구축 과정, 라벨링 절차, 기본 신경망·ElasticSearch 모델들을 소개하고, NDCG 기반 …
저자: Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit
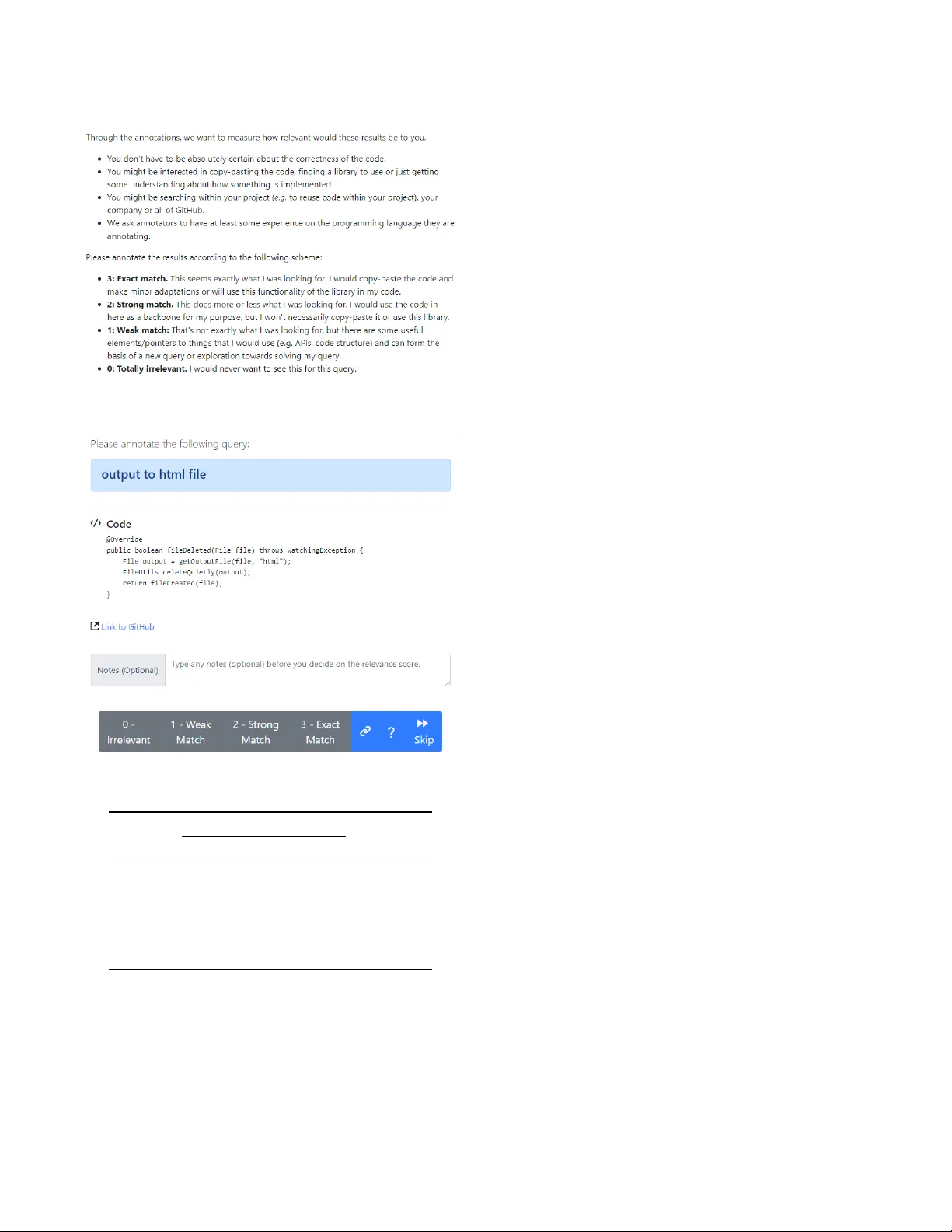
코드검색넷 챌린지는 의미 기반 코드 검색을 체계적으로 연구하기 위한 데이터와 평가 프레임워크를 제공한다. 서론에서는 딥러닝이 이미지·음성 등 비정형 데이터에 성공을 거두었지만, 구조화된 코드와 같은 고도로 규칙적인 데이터에서는 아직 한계가 있음을 지적한다. 특히 코드 검색은 자연어 질의와 코드 토큰 사이의 어휘·구조 차이, 그리고 평가용 라벨이 부족한 점이 큰 장애물이다. 이를 해결하고자 저자들은 두 단계의 접근법을 제시한다. 첫 번째는 대규모 자동 생성 데이터셋인 CodeSearchNet Corpus를 구축하는 것이고, 두 번째는 99개의 실제 검색 질의와 전문가가 매긴 4,000여 개의 관련도 라벨을 포함한 CodeSearchNet Challenge를 설계하는 것이다.
데이터 구축 단계에서는 GitHub의 비포크 공개 저장소를 라이선스와 인기(스타·포크) 기준으로 선별한다. TreeSitter 파서를 이용해 Go, Java, JavaScript, PHP, Python, Ruby의 함수·메서드를 추출하고, 정규식 기반으로 문서화된 주석을 수집한다. 이후 주석을 첫 문단으로 제한하고, 토큰 수가 3 미만인 주석·코드, 테스트 함수·생성자·특수 메서드 등을 제거한다. 중복 함수는 Allamanis와 Lopes의 중복 탐지 기법으로 필터링한다. 최종적으로 약 2백만 개의 (코드, 주석) 쌍과 4백만 개의 주석 없는 함수가 확보되었으며, 80‑10‑10 비율로 학습·검증·테스트 셋을 나눈다. 저자들은 자동 생성 데이터가 실제 검색 질의와 어휘·형식이 다르며, 오래된 주석·다국어 주석 등 노이즈가 존재한다는 한계를 솔직히 인정한다.
챌린지 데이터는 실제 개발자가 검색할 가능성이 높은 질의를 확보하기 위해 Bing에서 클릭‑스루가 높은 코드 관련 검색어를 추출하고, StaQC의 의도 재작성 문장을 결합해 99개의 자연어 질의를 만든다. 각 질의에 대해 6개 언어별로 10개의 후보 코드를 신경망 앙상블(모든 신경망 모델 + ElasticSearch)으로 사전 선정한다. 이후 전문가(소프트웨어 엔지니어·데이터 사이언티스트·연구자)에게 웹 인터페이스를 제공해 질의‑코드 쌍마다 0(전혀 관련 없음)부터 3(매우 관련 있음)까지 점수를 매기게 한다. 총 4,026개의 라벨이 수집됐으며, 언어별 라벨 분포는 다소 편향된다(예: Python은 고르게, JavaScript는 낮은 점수 편중). 동일 쌍에 대해 두 명 이상이 라벨링한 경우 Cohen’s κ=0.47로 중간 수준의 일관성을 보였다.
베이스라인 모델은 코드와 질의를 각각 인코딩해 공동 임베딩 공간에 매핑하는 구조를 따른다. 입력 전처리에서는 코드 토큰을 서브토큰으로 분리하고, 자연어는 BPE를 적용한다. 인코더는 (1) Bag‑of‑Words, (2) 양방향 GRU, (3) 1‑D CNN, (4) 멀티‑헤드 Self‑Attention 네 가지를 실험했으며, 풀링은 평균·최대·가중합 방식을 사용한다. 임베딩 차원은 128로 고정하고, 손실은 소프트맥스 기반 내적 최대화(음성 샘플링) 방식이다. 검색 단계에서는 Annoy를 이용해 전체 6백만 함수에 대한 근사 최근접 이웃 인덱스를 구축한다. ElasticSearch는 함수명 서브토큰과 전체 코드 텍스트를 인덱싱하는 전통적 IR baseline로 제공된다.
성능 평가에서는 학습용 테스트 셋에서 Mean Reciprocal Rank(MRR)를 측정했으며, Self‑Attention 모델이 가장 높은 MRR을 기록했다. 그러나 실제 챌린지 평가에서는 정규화된 Discounted Cumulative Gain(NDCG) 기준으로 Bag‑of‑Words 모델이 가장 높은 점수를 얻었다. 이는 학습 목표와 실제 검색 질의 사이의 도메인 차이, 후보 생성 단계에서의 편향, 그리고 복잡한 모델이 과적합될 가능성을 시사한다. 저자들은 또한 코드 품질(가독성·보안·성능), 질의 모호성, 라이브러리·프로젝트 특이성, 컨텍스트 의존성, 방향성(예: int→string vs string→int) 등 실제 검색에서 마주치는 다양한 문제점을 정성적으로 논의한다.
마지막으로 논문은 Weights & Biases 기반 리더보드를 공개해 연구자들이 NDCG(Within, All) 점수를 제출하고 비교할 수 있게 한다. 향후 작업으로는 질의 수와 언어 종류 확대, 라벨링 품질 향상, 더 정교한 신경망‑검색 결합 모델 개발 등을 제시한다. 전체적으로 CodeSearchNet 챌린지는 대규모 자동 생성 데이터와 고품질 소규모 평가 데이터를 동시에 제공함으로써 의미 기반 코드 검색 연구의 기반 인프라를 구축하고, 커뮤니티 주도의 지속적인 성능 향상을 촉진한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기