Anti-Jerk On-Ramp Merging Using Deep Reinforcement Learning
Deep Reinforcement Learning (DRL) is used here for decentralized decision-making and longitudinal control for high-speed on-ramp merging. The DRL environment state includes the states of five vehicles: the merging vehicle, along with two preceding an…
Authors: Yuan Lin, John McPhee, Nasser L. Azad
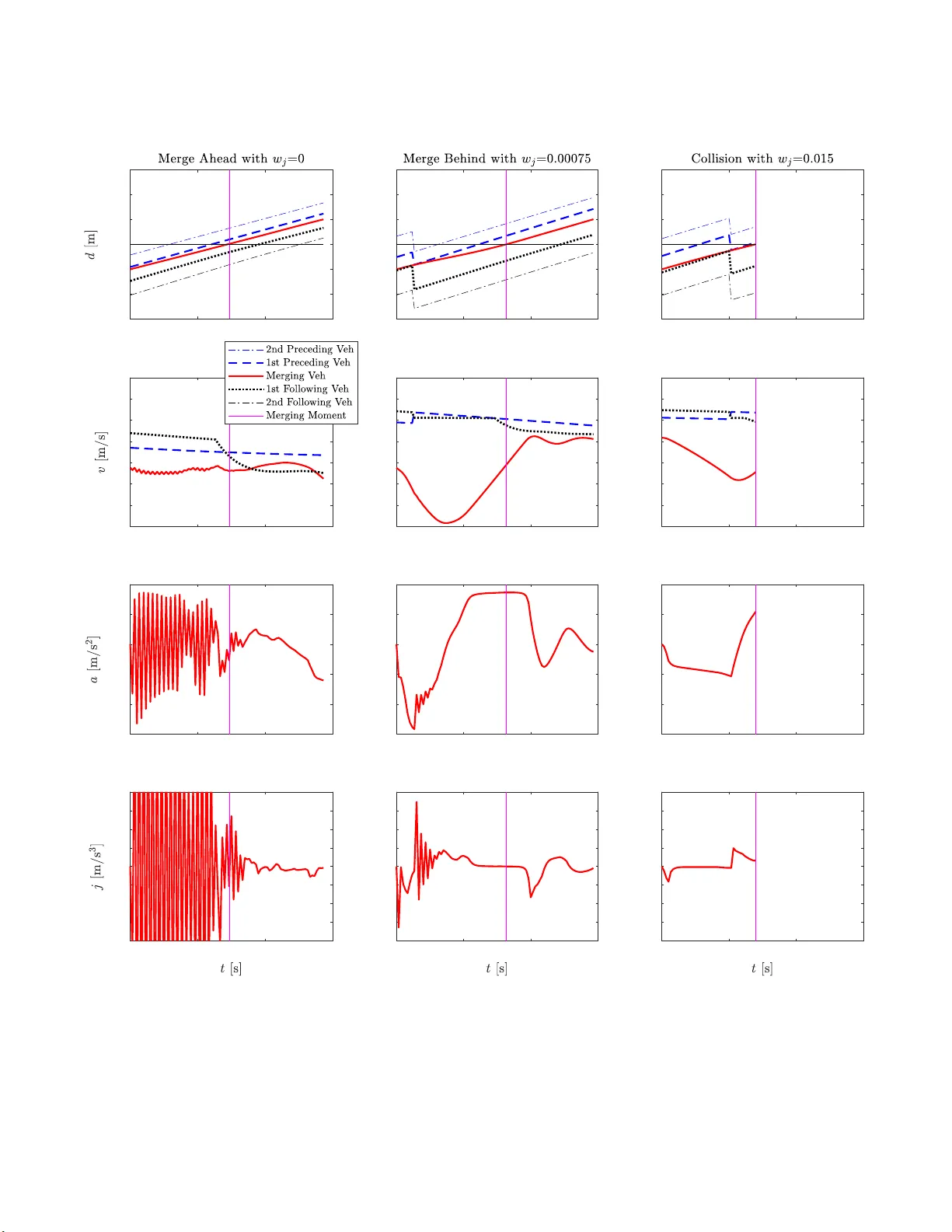
Anti-J erk On-Ramp Merg ing Using Deep Reinf or cement Lear ning Y uan Lin 1 , John McPhee 2 , and Nasser L. Azad 3 Abstract — Deep Reinfor cement Lear ning (DRL) is used here fo r decentralized decision-making and longitudinal control for high-speed on-ramp merging . The DRL en vironment state includes the states of five vehicles: the merging vehicle, along with two preceding and two fo llowing vehicles wh en the merging vehicle is or is projected on the main road. The control action is the acceleration of the merging vehicle. Deep Deterministic Policy Gra dient (DDPG) is the DRL algorithm fo r training to outpu t conti nuous control actions. W e i nves tigated the relationship between collisi on avo idance fo r safety and jerk min imization for p assenger comfo rt in th e multi-objective reward function by obtaini n g the Pareto front. W e fo und that, with a small jerk penalty in the multi-objectiv e reward function, the v ehicle jerk could be reduced by 73% compar ed with no jerk penalty while th e collisi on rate was maintained at zero. Regardless of the jerk penalty , the mer ging vehicle exhibited decision-making strategies such as merging ahead or behind a main-road vehicle. I . I N T RO D U C T I O N Automated vehicle de velopment is im p ortant work that could imp rove transpor ta tio n safety a n d mobility . Th ere are commercia lly av ailable Advanced Driver Assistance Systems such as Adaptive Cru ise Control, Lane Keeping Assistance, Blind Spot W arning, and Dr iv er Drowsiness Detection [1]. Some comp anies are workin g on highly automated vehicles that can p erform complex automated driving tasks such as merging, intersection tr aversing, and roun dabou t maneu vers. These intelligent d riving functions assist hu man d rivers but safety is yet to be guaranteed. V ehicle-to-everything (V2X) wireless comm u nications cou ld enhan ce safety and mobility [2], but 100 % pe netration of V2X commun ications for every vehicle a n d road n etwork in the world is still in the future . Merging is a challeng ing task for bo th human drivers and autom ated vehicles. Acco rding to the US Departmen t of T ransportatio n, nearly 300, 000 merging accidents happen e v- ery year with 50,000 being fatal [3]. The pilot vehicles of the leading self-driving car com pany , W aymo, were repor tedly unable to merge a utonom ously [ 4]. Merging scenario s hav e many variations: (1) There are low-speed merging in urban driving and h igh-speed fre eway on-r amp merging. In urban driving, the automated vehicle may stop before the main road while in freew ay merging, stoppin g is d angero u s. Intuitively , high-spee d merging seems to be riskier since there is less 1 Dr . Y uan Lin is a Postdoctoral Fel lo w in the Syste ms Desi gn Engin eering Departmen t at the Univ ersity of W ater loo, Ontario, Canada N2L 3G1. y428lin@uwate rloo.ca 2 Dr . John McPhee is a Professor and Canada Research Chair in the Systems Design Engineeri ng Department at the Univ ersity of W aterl oo, Ontario, Cana da N2L 3G1. mcphe e@uwaterloo.c a 3 Dr . Nasser L . Azad is an Associat e Professor in the Systems Design Engineeri ng Departme nt at the Uni v ersity of W aterloo, Ontario, Cana da N2L 3G1. nlashgar ianazad@uwate rloo.ca time for reaction given the limits of vehicle dyna mics. (2 ) For fre eway on -ramps, there are parallel-typ e ramps where in a part of the ramp is co n nected and parallel to the main road such that the merging vehicle could switch to the m ain ro ad at any point of the p arallel p ortion of the ramp. Ther e are also taper-type ramps wher e in the ramp is only con nected to the main ro ad at the ramp’ s end. Parallel-type ramps are preferr ed by the Federal High way Administratio n. Howe ver , there is still sign ificant pr e sence of taper-type ramps in th e world [5]. (3) Th e main road traffi c may be light or dense. In extremely den se traffic, the in teractions with m anually driven vehicles ma y be cr ucial for successful merging [6] . (4) Th e r e are also centralized and decentralized me rging. Centralized merging relies on road side centralized co ntrollers to coo r dinate the vehicles using V2X commun ications, while in dece n tralized merging, the merging vehicle merges com- pletely on its own. In th is work, we consider d ecentralized high-spee d non- sto p merging into freeways with mod e r ate traffic via taper-type r amps. In the curre nt literature, there are rule-based and optimization -based metho ds pro posed to tack le the auto- mated merging problem [7]. The rule-b a sed app roaches in- clude heuristics. The optimizatio n-based ap proach es requ ir e modeling merging in a multi-agent system fra mew ork. In [8], the author s used an op timal co n trol appr oach fo r centr a lized merging control with V2X commun ications. In [9], the authors used M odel Predictive Contro l ( MPC) to c ontrol an automated vehicle to merge via a parallel-type on-ram p in a d ecentralized fashion. In [10], the auth ors used the virtu al platoon method through ce ntralized control to allow vehicles to merge with a predeterm ined sequence. Optimization-ba sed methods requir e o nline optimization which could beco me an obstacle for realtime app lication if the number of vehicles in volved is large [11], [1 2]. In [ 1 3], the authors inv estigated merging decision -making using game theo r y . In rec e n t years, there are num erous studies th at inv estigate automated merging using DRL, which is a learning- based method. This is b ecause DRL has demon strated super-human perfor mance in playin g complex boar d games [14]. Addition- ally , DRL has been shown to achieve near-optimal con trol perfor mance when com pared to MPC [15]. DRL utilizes deep (multi-layer) n e ural n ets as the policy app r oximator s, which re quire very little computa tio n time during deploy- ment. In [1 6], the autho rs u sed reinfo rcement learn ing to train a continuo u s action contr oller fo r hig h-speed merging with a quad ratic func tio n with ne ural-net weig hts as the policy appro ximator; the o bjectives inc lu de maintain ing a safe distan c e with n eighbo r ing vehicles while minimizing control effort; howev er , the merging decision- making such as gap selection and the merging tra je c tories are not shown in the paper . In [1 7], th e a uthors u sed the passi ve acto r-critic algorithm f o r gap-selectio n and continuo us action control fo r merging into dense traffic; the rewards encourage merging midway between vehicles on the main road while keeping the same spee d as th e precedin g vehicle. In [18], the auth ors considered the coop eration levels of surro undin g vehicles and used Deep Q-Networks for discrete action con trol o f the merging vehicle; urban d r iving with dense traffic was considered and the vehicle speeds were ar ound 5 m/s. In [19], the a uthors also con sidered the coope ration le vels of vehicles and d ev eloped a m u lti-agent rein forceme nt learnin g algorithm for discrete a c tio n control; vehicle speeds of 15m/s and 20m /s were considered and th e algorithm achieved zero collision ra te in the simulation ; the au thors also ob served the trained decision- m aking strategies of mergin g ahead an d behind a main-roa d vehicle. Automotive veh icle control usually inv olves multiple o b- jectiv es, which m ay includ e safety , passeng er comf o rt, and energy efficiency [20]. T hese ob jectiv es may be presente d as penalizin g collision, jerk, an d con trol action, respectively , in the multi-objective rew ard or co st fu nction. Safety is the priority co n cern while the oth er objectives are also impo rtant. For examp le, p assenger com f ort is related to passenger s’ well-being and thus impacts th e public acceptance o f auto- mated vehicles. Howe ver , a large number of pub lished paper s on au tomated vehicle contro l usin g DRL focu s on safety an d neglect the other o bjectives . For exam p les, veh icle jerk and control action p e nalties are no t included in pap ers that use DRL for merging [1 8], [1 7], in tersection [21], [22], [23], [24], an d ro undab out [2 5] man e u vers. T here is also limited work that con siders anti- jerk co ntrol in the DRL objectives. In [1 9], the auth ors exclude action s that lead to high jerk values du ring training to obtain a merging po licy . T o our best knowledge, th ere is no work that sy stematically investigates the impact of jer k minimization on the safety comp romise of automa ted vehicle contro l u sing reinforcem ent learning . The systematic study of th e interactio n o f multiple ob je c ti ves in volves obtaining the Pareto fro nt, wherein n o solutio n can improve at least one o bjective with out degrading any other objective [2 6]. A typ ical way to o btain th e Pareto fron t is to vary the ratios of the weights for different objectives [27]. Our work here stud ies d e centralized de cision-makin g and longitud inal con trol for merging using DRL. The decision- making is defined as merging gap selectio n , which results from m erging ahead or b e hind. T he d ecision-mak ing o f merging ahead or behind is not a dire ct output from DRL; instead, it is an ou tcome of co ntrolling th e acceleration o f the merging vehicle via DRL. Th e m ain contributions of this work are two-fold. Firstly , we use DDPG to tr ain the mergin g policy . DDPG is based on a d eterministic policy and ou tputs continuo us action s fo r decision-m aking and c o ntrol [28]. There is no publishe d pap er that utilizes DDPG fo r merging . Secondly , we ob tain the Pareto front for the objectives of collision an d jerk m inimizations by varying the weight o f the jerk penalty . It allows us to inv estigate if jerk could be reduced while maintaining zero collisions. It also en ables us to study the trajectory smoothness an d decisio n -makin g strategies withou t a n d with jerk minimization. The rest of the p aper is organized as follows: in Section II, the preliminar ies o f reinf orcemen t learning and DDPG are introduced ; in Section I II, th e merging problem is f o r- mulated and cast into the reinf orcemen t learning framework; in Section IV , training an d testing simulation s are presented and results a re evaluated; in Sectio n V , we draw conclu sio n s and present possible future work. I I . R E I N F O R C E M E N T L E A R N I N G P R E L I M I NA R I E S In this sectio n, we intro duce the prelimina r ies of reinforc e- ment learning and DDPG. A. Rein for cement Learn ing Reinforceme nt learning is a learn ing-based meth od for decision-ma king and control. In reinforcem ent learning, an agent takes an action b a sed on th e environment state at the current time step, and the environment sub sequently m oves to a nother state at the next time step. Th e ag ent also receives a reward based on the action taken. The action and reward are based on pro babilities. Reinfor cement learning algo rithms seek to minimize the expected discounted cu mulative reward for each episode. Spec ifically , the discou nted cumu lativ e rew ard for a state-actio n p air is called the Q-value, i.e. Q ( s t , a t ) = E [ ∑ τ = T τ = t γ τ − t r ( s τ , a τ )] whe r e r ( s τ , a τ ) is the re- ward fo r the state s an d action a at time step τ , and γ ∈ [ 0 , 1 ] is the discount factor . The reinforc e ment learning pr oblem is solved via Bellman’ s princ ip le of op timality wh ich means that, if the o ptimal Q- value for the next step is kn own, then action for the cu rrent time step must be o ptimal. That is, Q ⋆ ( s t , a t ) = r ( s t , a t ) + γ Q ⋆ ( s t + 1 , a t + 1 ) for an optimal po licy , with ⋆ denoting the optimality . B. Deep Deterministic P olicy Gradient There are different DRL algor ithms av ailable, while we use DDPG for c ontinuo us control. There are two network s in D DPG: actor and cr itic n e twork s. The critic n e twork represents the Q-value which is the disco u nted cumulative re- ward. T h e critic network is iterativ ely updated based o n Bell- man’ s princip le of optimality b y minimizing the root- mean- squared lo ss L t = r ( s t , a t ) + ( 1 − I ) γ Q ( s t + 1 , µ ( s t + 1 | θ π )) − Q ( s t , a t | θ Q ) using grad ient descent where θ Q denotes the critic n eural n et we ig hts, and θ π denotes th e a c to r neu ral net weights. Th e I ∈{ 0,1 } is the indicator for episode terminatio n with I = 1 m e a ns termination a n d I = 0 means that the episode is not y et ter minated. The actor ne twork is th e policy network th at m aps the environment state to actio n. The actor network is learned b y performin g a g radient ascent on the Q-value Q ( s t , µ ( s t | θ π )) with respect to acto r network parameters θ π . Sev eral techn iques ar e n ecessary to facilitate training an d improve train ing stab ility . Tho se includ e target networks, mini-batch gra d ient descent, and experience replay . During training, Gaussian n oise is added to the action for exploration purpo se. T able I shows the D D PG parameter values that are used for the merging pro blem d escribed next. Th ese DDPG parameters are tuned throu gh tria l and erro r . Both the acto r and cr itic networks have 2 h idden layers w ith 64 neu r ons for each layer . T ABLE I D D P G PA R A M E T E R V A L U E S . T arget network update coef ficie nt 0.001 Re ward discount factor γ 0.99 Actor learn ing rate 0.0001 Critic learn ing rate 0.001 Experienc e replay memory size 1500000 Mini-bat ch size 128 Actor Gaussian noise mean 0 Actor Gaussian noise standa rd deviat ion 0.02 I I I . M E R G I N G P R O B L E M F O R M U L A T I O N A. Merging Envir on ment The merging environment is created in th e Simulation of Urban Mobility ( SUMO) driving simulator [ 29]. W e consider a vehicle seek ing to merge onto a freeway (main road ) via a taper-type on -ramp. The me rgin g vehicle is an auto mated vehicle equipp e d with a suite of per ception sensors such as lidar and radar . W e consider the ho r izontal sen sin g range of th e merging vehicle as a cir cle with a radiu s of 200 meters, which co uld be made possible by ad vanced sen sors [30], [31]. The automated vehicle is assumed to perceive the states of all the vehicles (including itself) within its sensing rang e and perf orm d ecentralized merging contro l. There is no centralized con trol f or the me rgin g an d main-ro ad vehicles via wireless commun ications. T he mergin g vehicle is consider ed as a po in t mass and u tilizes a kin ematic model for state upd ate. That is, the r e is no vehicle dynamics or delay considered for the merging vehicle. The m ain-roa d vehicles can pe r form car following and collision avoidance based on the I ntelligent Driver Model (IDM) [32]. They c an slow down when the merging vehicle enters the small junction area th at con n ects the on-r a m p and the main roa d , see Fig. 1. Main- road vehicles ha ve speeds that are nea r th e speed limit v l imit = 29 . 06 m / s (65 mph) . Particularly , each ma in -road vehicle has a desired spee d as v l imit ∗ γ where γ is con stant for a vehicle. T h e γ is a Gaussian distribution of mean 1 an d standa rd d eviation 0. 1 with values clipped within [0 .8, 1.2 ]. W e co n sider mod e rate traffic density such that a ma in-road vehicle is gen erated at th e far b ottom o f the main r oad with a probab ility of 0.5 at ev ery second. Due to the pro b abilistic traffi c generation , the sp e ed variation among vehicles, and IDM model par ameter variations (such as car-following head way difference), the main -road vehicles have very different inter- vehicular distance gaps near th e merging junction. All th e main-ro a d vehicles have n ormal acceleration values in [ -4.5, 2.6]m/s 2 . Whe n emergency situation s happe n , such as the merging veh icle m erges to o closely , the following vehicle can decelerate further to the minimu m -9 m/s 2 which is the emergency br aking d eceleration. These definition s for the main-ro a d vehicles remain the same for DRL train ing and testing. W e define a con trol zo ne for the merging vehicle that is 100m b ehind the m erging point o n the o n-ram p and 100m ahead of the m erging point on the main road , see Fig. 1. The DRL policy is fo r controlling th e m erging vehicles only in the co ntrol z one. W e assume that effective decisions could be made within 10 0m behin d the me rgin g point since the mergin g vehicle could co me to a comp lete stop within 100m given the speed limit in case tha t merging is not successful. Ad d itionally , the beginning po rtion of an on -ramp is designed for the merging vehicle to accelerate fro m low speeds and merging d e cisions may not b e made during the initial accelera tion phase in p ractice. The 100m ahead of the merging point is used to e valuate the merging success since collision could o ccur after merging if th e merging vehicle does not merge with appr opriate speed s and gaps betwee n vehicles. W e assum e th at there is n o other on-r amp merging vehicle in front of the contr olled merging vehicle within th e 100m behind the merging point. The main road is assumed to be single-lane such that ther e is no lane c hange behavior by the main-ro a d vehicles. Each simulation time step is 0 . 1 secon d s. For each merging episode, the merging veh ic le is initially positioned at 100m b ehind the mergin g point on the on- ramp. The in itial velocity of th e merging vehicle is rand omly distributed in [22 .35, 26.82 ]m/s (50-6 0mph) . This is based on the suggestion o f th e US Departme n t o f Transportation th at a merging vehicle reach es at least 50mph befor e m erging to a freeway with 6 5mph speed limit [5]. Th e initial accelera tio n of the m erging vehicle is zero. When stop s, collisions, or merging successes h appen, the corr e sp onding episodes are ter minated; the merging vehicle is then deleted an d regenerated with new initial cond itio ns. Merging success is defined as merging past the control zon e with no sto p or collision regardless of brak in g by the m a in-road veh icle s. Based on th e merging en vironm ent, we design th e follow- ing reinforce m ent learning framework for training a m erging policy . B. Envir o nment S tate The en vironm ent state o f the reinforceme n t learning framework includes the states of fi ve vehicles: th e merging vehicle ( m ), alo ng with its two prec e ding ( p 1, p 2) and two following ( f 1, f 2) vehicles when the m e rging vehicle is or is projected o n the m ain road, see Fig. 1. The merging vehicle’ s proje c tio n on the main road h a s the same distance to the merging p oint a s the merging vehicle on ramp . The state of the merging vehicle includes the distance to the merging p oint d m , velocity v m , and acceleratio n a m . The states of the pre c e ding and following vehicles includ e the distan c es to the merging point ( d p 2 , d p 1 , d f 1 , d f 2 ) and velocities ( v p 2 , v p 1 , v f 1 , v f 2 ). The acceleration values of the precedin g and fo llowing vehicles ar e not includ ed in the en vironm ent state sin c e the accelera tion measurem ents are usually noisy , especially wh e n the vehicles are f urther away . The distance to the merging poin t is po siti ve an d negati ve Fig. 1. Sc hematic for m ergi ng. before and after the merging point, respectively . The d istance to the merging poin t is measured fro m the fr ont bumper of the vehicle. Th e e n vironm ent state is de noted as s = [ d p 2 , v p 2 , d p 1 , v p 1 , d m , v m , a m , d f 1 , v f 1 , d f 2 , v f 2 ] (1) When there are fewer than two p receding o r two fo llow- ing vehicles detected , virtual veh ic le s ar e assumed at the intersections o f the sensing space and th e m ain road to deliberately construct the fi ve-vehicle state vector . This is a conservati ve appro ach f o r safety as there could be vehicles just outside the sensing space in real- world driving. T he virtual vehicles h ave velocity values as the main road speed limit. Note that a vehic le is determined to b e precedin g or following r elativ e to the m e rgin g vehicle or its pr o jection. A fo llowing vehicle may become a preced ing veh ic le if the merging vehicle slows down on ram p and its projec tion moves b ehind the main-ro ad vehicle. C. Co n tr ol Action The co ntrol a ction o f the rein forcemen t learning frame - work is th e acceleration to the merging vehicle a m . As we don’t con sider vehicle dynamics and delays, the acc e leration control in p ut is executed in stantaneously b y th e merging vehicle. The velocity a nd p osition u pdates o f the mergin g vehicle follow an Euler f o rward discretization with 0. 1 s as the time step. The acceleration con trol input for th e merging vehicle is within [ a min , a max ] = [-4.5,2.6 ]m/s 2 , which is the same n ormal acceleration ran ge of a main-road vehicle. There is no emergency braking acceler ation defined for the merging vehicle. D. Rewar d The rew ard at each time step inc lu des: 1) After the merging point and un til the end of the control zone (1 0 0m ah ead of the merging point), the merging vehicle should be m idway between the first pre c e ding and first following vehicles, with the a verage speed of the two vehicles. The corre sp onding pen alizing r ew ard is d efined as r m = − w m ∗ ( | w | + | ( v p 1 + v f 1 ) / 2 − v m | ∆ v max ) (2) where w m is the weig ht fo r mergin g midway an d w is the midway ra tio defined as the r atio between the difference and sum of the distance g aps among the merging, its first precedin g , and its first fo llowing vehicles. The ratio w has values in [0,1] where in 0 means th e distance gap between the merging and the first precedin g vehicles is th e sam e as the one between the m erging and the first following vehicles, and 1 m eans the mergin g vehicle has zero distance gap with either the first preced ing or first following vehicle. The ∆ v max =5m/s is the max imum allowed speed difference that we defined. w = | d p 1 − d m − l p 1 | − | d m − d f 1 − l m | | d p 1 − d f l − l p 1 − l m | (3) where l p 1 =5m, l m =5m, and l f 1 =5m are the vehicle lengths of the first preced ing, merging , and first following vehicles, respectively . 2) When th e first following vehicle perform s b raking a f 1 < 0m/s 2 in the contro l zon e , a penalizing rew ard is giv en as: r b = − w b ∗ | a f 1 | max ( | a min | , a max ) (4) where w b is the weight for penalizin g brakin g by the first following vehicle. 3) T o reduce the jerk of the merging vehicle for passenger comfor t, we define a penalizing rew ard as: r j = − w j ∗ | j m | j max = − w j ∗ | ˙ a m | j max (5) where w j is the weight fo r the jerk penalty . Th e j max =3m/s 3 is the maximu m allo wed jerk value for passenger co mfort [33]. The w j value is varied in this work to o btain the Pareto front for the collision and jerk minimization objectiv es. 4) When the merging vehicle stops, a pen alizing reward of -0.5 is giv en and the ep isode is terminated. 5) When the mergin g vehicle collides with any vehicle, a p enalizing rew ard o f -1 is given and the episode is terminated. A collision is registered whe n the in ter-vehicular distance gap is less than 2.5 m. No te th at a larger pe n alty is given for co llisions than for stops because collisions are considered more catastrophic. 6) When the me rgin g vehicle successfully p asses the control zo ne (1 00m ah e ad of the merging point) , a re ward of 1 is gi ven. W e don’t p enalize the time it takes the ag e nt to finish an episode since time minimization is in h erent in the r ein- forcemen t learnin g discount factor γ = 0 . 99 [18]. In additio n , penalizing stops d uring mergin g also c ontributes to tim e minimization . T ab le II shows the para m eter values of th e merging vehicle. T ABLE II P A R A M E T E R V A L U E S F O R T H E M E R G I N G V E H I C L E . Minimum accelerat ion a min -4.5m/s 2 Maximum accelerat ion a max 2.6m/s 2 W eight for m ergi ng midway w m 0.015 Maximum allowe d s peed dif feren ce ∆ v max 5m/s W eight for penalizi ng brakin g by first follo wing vehi cle w b 0.015 W eight for penalizing jerk w j 0 to 0.015 Maximum allowe d jerk value j max 3m/s 3 Fig. 2. Un discounte d episode rewa rd during training . I V . R E S U L T S In this section, we show and evaluate the training and testing simulatio n results fo r each weight for jerk penalty . Additionally , repr esentativ e episodes are p resented to show the merging vehicle’ s learne d beh aviors. A. T r aining For each weight f or jerk penalty , we train the merging vehicle f or 1 . 5 million simulation time steps, wherein we observe reasonable con vergence of the undiscou nted episod e rew ard. Note tha t, befo re each episode starts, there is a 10- second buf fer fo r in itialization of the main-ro ad traffic. Fig . 2 shows the u ndiscou n ted episod e rew ard when the weight for jerk penalty w j =0.015 , which is the largest amo ng the weights considered; the training co n vergence results fo r othe r weights loo k similar and are n ot plotted h ere. In general, at the initial ph ase of training , the DRL agent had episode rew ards less th an -0.5 very of ten, indicating many stops or collisions. As train ing prog resses, the episode r ewards less than - 0.5 hap pened less o ften. It took around 10 hours for either training or testing on a compu ter with a 16 -core (32- thread) AMD processor and a Nvidia GeForce R TX GPU. B. T esting For ea c h weight for jerk p enalty , the train ed p olicy is tested for anoth er 1.5 million simu lation time steps which rep r esent rough ly 19000 mergin g episodes. W e define the fo llowing metrics to ev aluate th e merging vehicle’ s p erform ance durin g testing. (1) A v erage collision rate: the number of collisions d ivided by the numbe r of episodes. (2) A verag e jer k: the me an of th e average jer k magnitu d e of each episode. (3) A verage acceleration: th e mean of the average accel- eration magnitu d e of each episode. (4) A verage velocity: the m e an of the a verage velocity o f each episode. (5) M e rge-behind rate: the numb er of times o f mergin g behind divided by the num b er of episod es. (6) Merge-a h ead rate: the num ber of times of merging ahead divided by the numbe r of episodes. Note that merging ah ead or behind is defined as merging ahead or behind the fir st following vehicle. Fig. 3 shows a summary o f th e metrics results for d ifferent weights fo r the jerk p e nalty . As DDPG is not robust an d may conv erge to different sub-op timal po licies each time, the plots in Fig. 3 do not show sm o oth monoto nic trends. The plo t o f the average collision rate shows that when w j ≤ 0.00 075, the r e a re zero collision s. When w j > 0.00 075, the average collision rate inc r eases with th e increa sin g weight for jerk p e nalty . In con trast, th e av erage jerk shows a decreasing trend with the incr easing weig ht fo r jerk p enalty . In p articular, the average jerk is 1.5 2m/s 3 when w j =0.000 75 and 5 .68m/s 3 when w j =0, wh ich in dicates 73% jerk re- duction ev en tho ugh both ca ses h av e z e ro collisions. The Pareto front for the objectives of collision avoidance an d jerk minimization is sho wn in the third plot o f the first row of Fig. 3. The av erage acceleration seems to decrease with the weight f o r jerk p enalty although the trend is not obviou s. Howe ver , a decreasing acceleration trend is usually expected as we penalize jerk, which ind icates b etter en e rgy efficiency [20], [33]. Th e average velocity f or smaller w j seems to be smaller than fo r larger w j . T h e merge-behind and merge- ahead rates do not chan g e significantly with the increasing weight fo r jerk penalty . Ad ditionally , the merge-ah ead rate is much larger tha n the m e rge-behind rate, indicatin g that th e merging vehicle pref erred to maintain the initial positioning sequence during merging. Note that there wer e a f ew sto ps for different we ights of jerk penalty durin g testing . For each case of jer k penalty , there were also a few occ asions w h erein th e m erging vehicle merged b ehind or a h ead twice in one e pisode. C. R epr esentative Ep isodes T o under stan d bo th the learned decision -making strategies and th e impac t of using different weights for jerk p enalty on the trajecto r y smoothne ss, we plot the vehicle states under d ifferent d e cision-makin g strategies an d for d ifferent weights fo r the jer k penalty , see Fig. 4. W e plotted 3 episodes: Episod e 1 , the merging vehicle merged ahead with w j =0; Episode 2 , the mergin g vehicle merged beh ind with w j =0.000 75, and Episode 3, the merging vehicle caused a collision with w j =0.015 . In Ep isode 1 , the merging vehicle’ s initial projection o n the main road was a little behin d the first preceding vehicle 0 0.00075 0.0015 0.005 0.0075 0.01 0.015 0 0.002 0.004 0.006 0.008 0.01 0 0.00075 0.0015 0.005 0.0075 0.01 0.015 0 1 2 3 4 5 6 0 1 2 3 4 5 6 0 0.002 0.004 0.006 0.008 0.01 0 0.00075 0.0015 0.005 0.0075 0.01 0.015 0.5 1 1.5 2 0 0.00075 0.0015 0.005 0.0075 0.01 0.015 24 24.5 25 25.5 26 26.5 0 0.00075 0.0015 0.005 0.0075 0.01 0.015 0 0.2 0.4 0.6 0.8 1 Fig. 3. Me rging performance for dif ferent weights for jerk penal ty w j during testi ng. and its speed was a little smaller than the first preced ing vehicle. The merging vehicle’ s velocity was fairly con stant during merging as the mergin g vehicle merged ahead the first following vehicle and rem ained behind the first preced ing vehicle. The a c celeration and jerk plots ar e very no isy because there is no penalty on the vehicle jerk. In Ep isode 2 , the merging vehicle’ s initial projection o n the main road was a little ahead the first fo llowing vehicle and its speed was a little smaller than the first fo llowing vehicle. Th e trained policy en a b led the merging vehicle to slow d own sig n ificantly to merge behind the fir st following vehicle. The acceleratio n and jerk plots are much less jerky as co mpared with Episod e 1, even with th e small weight on jerk penalty w j =0.000 75. Note that the first following vehicle became th e fir st preceding vehicle during m e rgin g due to the slowdo wn of the merging vehicle. In Episode 3, th e merging vehicle’ s in itial projec tion on the main road was a little ahea d the first fo llowing vehicle and its speed was a little smaller than the first following vehicle . The merging vehicle slowed d own but n o t significantly . The first following vehicle becam e the first preceding vehicle b efore the merging vehicle collided with it in th e fro n t. This is likely due to the heavy weigh t for jerk pen alty w j =0.015 , which leads to insufficient contro l action to av oid the collision. V . C O N C L U S I O N S In this work, we trained a freeway on-ram p merging po licy using DDPG. Th e Pareto fr ont for the me rging ob jectiv es of collision av oidance an d jerk redu ction (passeng er com- fort) was obtain ed. W e foun d that, with a relatively small jerk penalty with w j =0.000 75, the vehicle jerk could b e significantly reduce d by up to 7 3% while merging could be maintained collision -free. As the weig ht for jerk p enalty continues to increase, the g ain o f jerk reduction is no t significant. Repr esentativ e episod e s sho w that when jerk penalty was no t co nsidered, the DRL-trained solution exhib- ited highly jer ky jerk and acceleration pro files. Th e je r kiness may be in p art d ue to the pe n alty sp ikes when stops or collisions hap pened which caused sharp neural-n et weight updates du r ing b ackpro pagation . On the other h and, if the jerk penalty is too large, the merging vehicle could fail to execute sufficient contr ol action s to avoid collision s. At the dec ision-makin g le vel, the DRL-trained po licies mainly exhibited two merging strategies: merging ahead or be h ind a following vehicle on the main r oad. Merging ahead dominated merging behin d as it happ ened more than 80% of the time. Th e resulting d ecision-mak ing strategies are depen dent on the rewards that we designed ; mergin g ahead resulted in higher cu mulative discoun ted rew ards in the merging environment. W e ob ser ved that mergin g ahead resulted in lower jerk magn itu des in general, w h ich con - tributed to hig her rew ards. In addition, the time minimization due to the d isco unt factor an d the stop pen alty may motiv ate merging ahead since it may take sho rter time than m erging behind with slowdo wn. 0 3 6 9 -300 -200 -100 0 100 200 300 0 3 6 9 18 20 22 24 26 28 30 32 0 3 6 9 -4.5 -3 -1.5 0 1.5 3 0 3 6 9 -20 -15 -10 -5 0 5 10 15 20 0 3 6 9 -300 -200 -100 0 100 200 300 0 3 6 9 18 20 22 24 26 28 30 32 0 3 6 9 -4.5 -3 -1.5 0 1.5 3 0 3 6 9 -20 -15 -10 -5 0 5 10 15 20 0 3 6 9 -300 -200 -100 0 100 200 300 0 3 6 9 18 20 22 24 26 28 30 32 0 3 6 9 -4.5 -3 -1.5 0 1.5 3 0 3 6 9 -20 -15 -10 -5 0 5 10 15 20 Fig. 4. Thre e represe ntati v e episode s of mergi ng during testing. Episode 1 (first column): merge ahead the first follo wing vehic le with w j =0; Episode 2 (second column): merge behind the first followin g vehicle with w j =0.00075; and E pisode 3 (third column): collision with w j =0.015. In the second and third plots on the first row , the first followi ng vehicl e became the first precedin g vehicl e as the merging vehicle slowed down , which causes the sharp change s of the distance to merging point d value s for the related vehicles. In the first plot on the fourth ro w , the vehicle jerk va lues in the first 3 seconds are larger than 80m/s 3 . W hile the lengths of the three episode s are diffe rent and not equal to 9s, the x-axis limit is set to 9s for comparison purposes. Even though our simu lations showed zero collisions, guar- anteed safety fo r the neural-net policy ne e ds to be research ed in the future work [3 4]. Future work sho uld also include co n- sidering vehicle dy namics in trainin g since, in our previous work, we discovered that the kinematic-m odel-train ed po licy could cause significantly degraded pe r forman ce in realistic situations with vehicle dynam ics [3 5]. Ano ther research direction is to directly consider en e rgy e fficiency in the rew ard to train an economic merging policy [3 6]. AC K N O W L E D G M E N T The autho rs th ank T oyo ta, Ontario Centres of E xcellence, and th e Natura l Sciences and E n gineerin g Research Co u ncil of Canada fo r the suppo rt of this work. Th e authors apprec i- ate the constructive feedback from Prof. Krzyszto f Czarnecki and his research group at the Univ ersity of W aterloo. R E F E R E N C E S [1] A. E skandaria n, Handbook of Intellig ent V ehicle s . Springer London, 2012. [2] J. J. Blum, A. E skandaria n, and L. J. Hoffman, “Challenge s of interv ehicl e ad hoc networks, ” IEE E T ransa ctions on Intell igent T rans- portation Systems , vol. 5, no. 4, pp. 347–351, 2004. [3] “https://www .dulaneyla uerthomas.com/blog/merging-into-danger - risks-of-ent ering-hig hway-traf fic.cfm. ” [4] “https://www .thetruthaboutcars.com/20 18/05/thwarted-ramp-waymo- dri verl ess-car -doesnt-fee l-urge-merg e/. ” [5] A. Aashto, “Policy on geomet ric design of highways and streets, ” American Ass ociation of State Highway and T ransport ation Officia ls, W ashington, DC , vol. 1, no. 990, p. 158, 2001. [6] L . Sun, W . Zhan, Y . Hu, and M. T omiz uka, “Interpretabl e modell ing of dri ving behav iors in inte racti v e drivin g scenarios based on cumulati ve prospect theory , ” in 2019 IEEE Intellig ent T ransport ation Systems Confer enc e (ITSC) . IEEE, 2019, pp. 4329–4335. [7] J. Rios-T orres and A. A. Malikopoul os, “ A surve y on the coordi nation of connected and automated vehi cles at intersectio ns and merging at highwa y on-ramps, ” IEEE T ra nsactions on Intellig ent Tr ansportati on Systems , vol. 18, no. 5, pp. 1066–10 77, 2016. [8] ——, “ Automated and coopera ti ve vehi cle mergi ng at highw ay on- ramps, ” IEEE T ransa ctions on Intel lige nt T ranspo rtation Systems , vol. 18, no. 4, pp. 780–789, 2017. [9] W . Cao, M. Mukai, T . Kawabe , H. Nishira, and N. Fujiki, “Cooperati v e vehi cle path generation during m ergi ng using model predicti v e control with real-time optimizat ion, ” Contr ol Enginee ring Practice , vol . 34, pp. 98–105, 2015. [10] Z. W ang, B. Kim, H . Ko bayashi, G. W u, and M. J. Barth, “ Agent-based modeling and simulation of connecte d and automated vehicles using game engine: A coopera ti ve on-ramp merging study , ” arXiv pre print arXiv:1810.09952 , 2018. [11] A. Maitland and J. McPhee, “Quasi-transl ations for fast hybrid nonlin- ear model predic ti ve control, ” Contro l E ngineering Practice , vol. 97, p. 104352, 2020. [12] J. Ding, L. Li, H. Peng, and Y . Zhang, “ A rule-base d cooperati v e merg- ing strate gy for connecte d and automated vehicle s, ” IE EE T r ansactions on Intel lige nt T ra nsportation Systems , 2019. [13] K. Kang and H. A. Rakha, “Game theoretica l approach to model decisio n making for merging maneuvers at free way on-ramps, ” T rans- portation Resear ch Record , vol . 2623, no. 1, pp. 19–28, 2017. [14] D. Silver , A. Huang, C. J. Maddi son, A. Guez, L. Sifre, G. V an Den Driessche, J. Schrittwiese r , I. Antonoglou, V . Panneershel va m, M. Lanctot, et al. , “Mastering the game of go with deep neural netw orks and tree s earch, ” Natur e , vol. 529, no. 7587, p. 484, 2016. [15] Y . Lin, J . McPhee, and N. L . Azad, “Comparison of deep rein- forcement learn ing and model predicti v e contro l for adapti ve cruise control , ” arXiv preprint , 2019. [16] P . W ang and C.-Y . Chan, “ Autonomous ramp merge maneuve r based on reinforce ment learning with continu ous actio n space, ” arXiv pre print arXiv:1803.0920 3 , 2018. [17] T . Nishi, P . Doshi, and D. Prokhoro v , “Mergi ng in conge sted freew ay traf fic using multipoli cy decision making and passiv e actor-cr itic learni ng, ” IEEE T ransact ions on Intellig ent V ehi cles , vol. 4, no. 2, pp. 287–297, 2019. [18] M. Bouton, A. Nakhaei, K. Fujimura, and M. J. Koc henderfer , “Coopera tion-a ware reinforce ment lear ning for merging in dense traf- fic, ” arXiv pre print arXiv:1906.1102 1 , 2019. [19] Y . Hu, A. Nakhaei, M. T omiz uka, and K. Fujimura, “Intera ction-a war e decisio n m aking with adapti v e strategi es under merging scenarios, ” arXiv preprint arXiv:1904.06025 , 2019. [20] X. W ei and G. Rizzoni, “Object i ve metric s of fuel economy , perfor- mance and dri v eabili ty-a revie w , ” SAE T echnical Paper , T ech . Rep., 2004. [21] Z. Qiao, K. Muelling, J. M. Dolan, P . Palani samy , and P . Mudalige, “ Automatical ly genera ted curric ulum based reinforce ment learning for autonomous vehi cles in urban en vironment , ” in 2018 IEEE Intell igen t V ehicl es Symposium (IV) . IEEE, 2018, pp. 1233–1238. [22] Z. Qiao, K. Muellin g, J. Dolan, P . Palanisamy , and P . Mudalige , “POMDP and hierarchic al options MDP with continuous actio ns for auton omous dri ving at inte rsections, ” in 2018 21st International Confer enc e on Intell igent T ransporta tion Systems (ITSC) . IEEE, 2018, pp. 2377–2382. [23] D. Isele, R. Rahimi, A. Cosgun, K. Subramani an, and K. Fujimura, “Nav igating occlud ed intersectio ns with autonomous vehi cles using deep reinforce ment learning, ” in 2018 IEEE International Confer ence on Robotic s and Automat ion (ICRA) . IEEE, 2018, pp. 2034–2039. [24] C. Li and K. Czarnecki, “Urban driving with multi-obj ecti v e deep reinforc ement learning, ” in Proce edings of the 18th International Con- fer ence on Autonomous Agents and MultiAgent Systems . International Founda tion for Autonomous Agents and Multiage nt Systems, 2019, pp. 359–367. [25] K. Jang, E. V initsk y , B. Chalaki, B. Remer , L. Beaver , A. A. Ma- lik opoulos, and A. Bayen, “Simulati on to scale d city: zero-shot polic y transfer for traf fic control via autonomous vehicle s, ” in Pr oceed ings of the 10th AC M/IEEE Internatio nal Confer ence on Cyber -Physical Systems , 2019, pp. 291–300. [26] P . Ngatchou, A. Zarei, and A. El-Sharkawi , “Pareto multi object i ve optimiza tion, ” in Proce edings of the 13th International Confer ence on, Intellige nt Systems A pplicat ion to P ower Systems . IEEE, 2005, pp. 84–91. [27] K. V an Moff aert and A. Now ´ e, “Multi-obje cti ve reinforceme nt learn- ing using sets of pareto dominat ing polici es, ” The J ournal of Machi ne Learning R esear ch , vol. 15, no. 1, pp. 3483–3512, 2014. [28] T . P . Lillic rap, J. J. Hunt, A. Pritzel, N. Heess, T . Erez, Y . T a ssa, D. Silve r , and D. W ierstra, “Continu ous control with deep reinforce- ment learning, ” arXiv pr eprint arX iv:1509.0297 1 , 2015. [29] P . A. Lopez, M. Behrisch, L. Bieker -W a lz, J. Erdmann, Y .-P . Fl ¨ ot ter ¨ od, R. Hilbric h, L . L ¨ ucke n, J. Rummel, P . W agner , and E. W ieBn er , “Mi- croscopic traf fic simulation using SUMO, ” in 2018 21st Internatio nal Confer enc e on Intell igent T ransporta tion Systems (ITSC) . IEEE, 2018, pp. 2575–2582. [30] T . Fersch, R. W ei gel, and A. K oelpin, “Challenge s in miniaturize d automoti v e long-range lidar system design, ” in Three-Dime nsional Imagin g, V isuali zation, and Display 2017 , vol. 10219. Internatio nal Society for Optics and Photonics, 2017, p. 102190T . [31] J. Hecht, “Lidar for self-dri vi ng cars, ” Optics and Photonic s Ne ws , vol. 29, no. 1, pp. 26–33, 2018. [32] M. Trei ber , A. Hennecke , and D. Helbing, “Congested traf fic states in empirica l observ ations and microscopic simulations, ” Physical revi ew E , vol . 62, no. 2, p. 1805, 2000. [33] M. Batra, J . McPhee, and N. L. Azad, “Real-time model predicti ve control of connecte d electric vehicle s, ” V ehicle System Dynamics , vol. 57, no. 11, pp. 1720–1743, 2019. [34] J. Lee, A. Balakrishn an, A. Gaurav , K. Czarnec ki, and S. Sedwar ds, “W isemo ve: A framew ork to in vesti gate safe deep reinforcement learni ng for autonomous drivi ng, ” in Internat ional Confer ence on Quantita tive Evaluation of Systems . Springer , 2019, pp. 350–354. [35] Y . Lin, J. McPhee, and N. L. Azad, “Longit udinal dynamic versus kinemati c models for car -follo wing control using deep reinforcement learni ng, ” in 2019 IEE E Intell igen t T r ansportati on Systems Confere nce (ITSC) . IEEE, 2019, pp. 1504–1510. [36] M. V ajedi and N. L. Azad, “Ecolog ical adapti v e cruise controll er for plug-in hybrid electric vehicles using nonlinear model predicti ve control , ” IEEE T r ansactio ns on Intel lige nt T r ansportatio n Systems , vol. 17, no. 1, pp. 113–122, 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment