깊은 강화학습 기반 저 저크 고속 온램프 병합 제어
본 논문은 고속 고속도로 온램프 병합을 위한 탈중앙화 의사결정 및 종방향 제어에 Deep Deterministic Policy Gradient(DDPG) 기반 연속 가속 제어를 적용한다. 충돌 회피와 승차감(저 jerk) 사이의 다목적 보상 함수를 설계하고, 가중치를 변화시켜 파레토 전선을 구함으로써 작은 저 jerk 페널티만으로도 충돌률을 0% 유지하면서 차량 jerk를 73% 감소시킬 수 있음을 입증한다.
저자: Yuan Lin, John McPhee, Nasser L. Azad
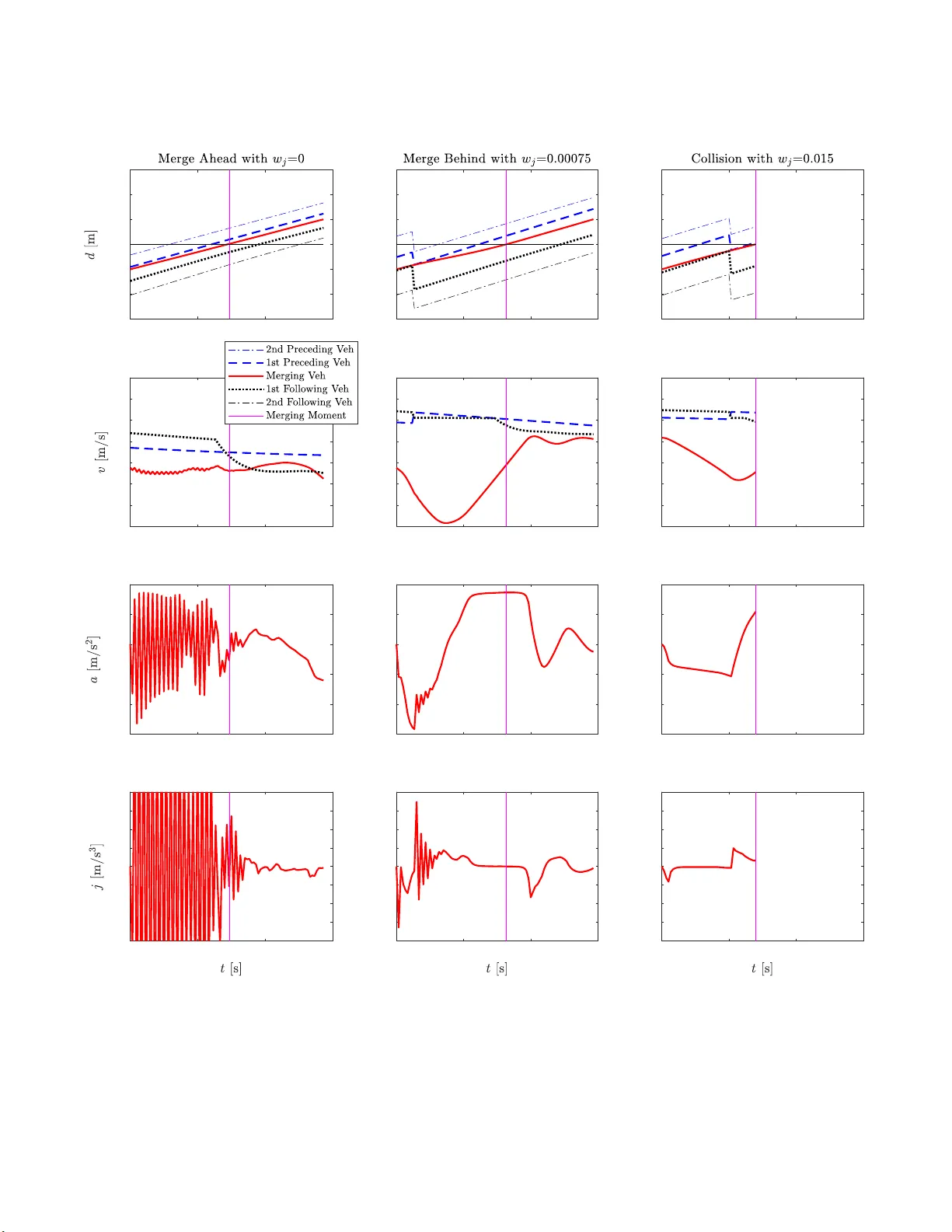
본 논문은 고속도로 온램프 병합을 위한 탈중앙화 의사결정 및 종방향 제어 문제를 Deep Reinforcement Learning(DRL)으로 해결하고자 한다. 연구 배경으로는 기존의 규칙 기반·최적화 기반 병합 방법이 실시간 계산 부담이 크고, 최근 DRL을 활용한 연구가 안전성(충돌 회피)에는 집중했지만 승차감(jerk) 최소화는 거의 다루지 않았다는 점을 들었다. 따라서 저 jerk와 충돌 회피라는 두 가지 상충 목표를 동시에 고려한 다목적 보상 함수를 설계하고, 그 파레토 전선을 정량적으로 분석한다.
1. **문제 정의 및 환경 설계**
- 병합 차량(m)과 앞·뒤 각각 두 대의 차량(p₁, p₂, f₁, f₂)으로 구성된 5대 차량 상태를 관측한다. 각 차량은 메인 로드에 투사된 경우와 온램프에 있는 경우 모두 동일한 거리·속도 정보를 제공한다.
- 상태 벡터 s =
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기