Hierarchical Cooperative Multi-Agent Reinforcement Learning with Skill Discovery
Human players in professional team sports achieve high level coordination by dynamically choosing complementary skills and executing primitive actions to perform these skills. As a step toward creating intelligent agents with this capability for full…
Authors: Jiachen Yang, Igor Borovikov, Hongyuan Zha
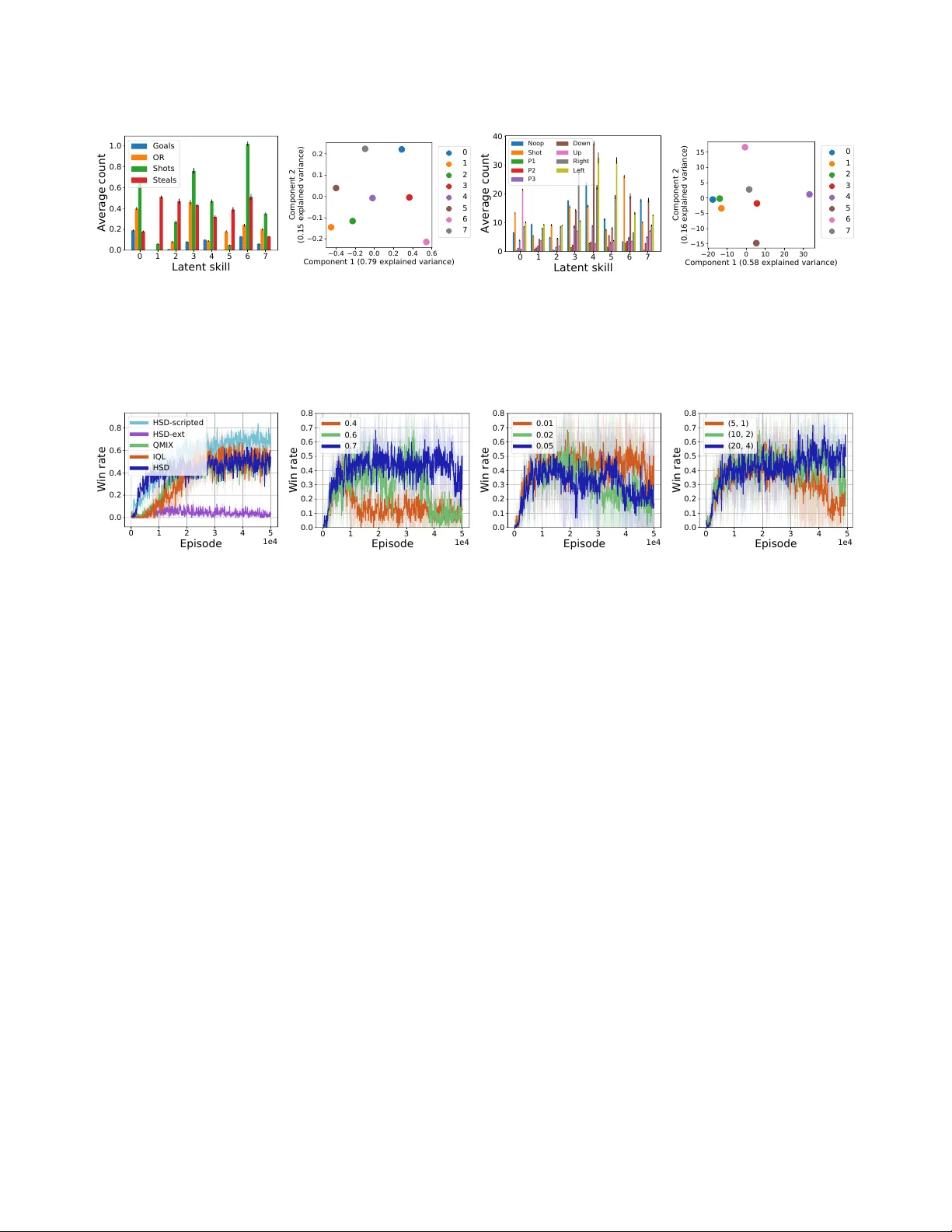
Hierarchical Cooperative Multi- Agent Reinforcement Learning with Skill Discov er y Jiachen Y ang ∗ Georgia Institute of T echnology Atlanta, Georgia jiachen.yang@gatech.edu Igor Boroviko v Electronic Arts Redwood City, California iborovikov@ea.com Hongyuan Zha Georgia Institute of T echnology Atlanta, Georgia zha@cc.gatech.edu ABSTRA CT Human players in professional team sports achieve high le vel coor- dination by dynamically choosing complementary skills and exe- cuting primitive actions to perform these skills. As a step toward creating intelligent agents with this capability for fully cooperative multi-agent settings, we propose a two-lev el hierarchical multi- agent reinforcement learning (MARL) algorithm with unsup ervised skill discovery . Agents learn useful and distinct skills at the low level via independent Q-learning, while the y learn to select comple- mentary latent skill variables at the high lev el via centralized multi- agent training with an extrinsic team reward. The set of low-lev el skills emerges from an intrinsic reward that solely promotes the de- codability of latent skill variables from the trajectory of a low-level skill, without the need for hand-crafted rewards for each skill. For scalable de centralized execution, each agent independently chooses latent skill variables and primitive actions based on local observa- tions. Our overall method enables the use of general cooperative MARL algorithms for training high level policies and single-agent RL for training low le vel skills. Experiments on a stochastic high dimensional team game show the emergence of useful skills and cooperative team play . The interpretability of the learned skills show the promise of the proposed method for achieving human- AI cooperation in team sports games. KEY W ORDS multi-agent learning; hierarchical learning; option discovery A CM Reference Format: Jiachen Y ang, Igor Borovikov, and Hongyuan Zha. 2020. Hierarchical Coop- erative Multi- Agent Reinforcement Learning with Skill Discov ery. In Pr oc. of the 19th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2020), Auckland, New Zealand, May 9–13, 2020, IF AAMAS, 9 pages. 1 IN TRODUCTION Fully coop erative multi-agent reinforcement learning (MARL) is an active area of r esearch [ 14 , 25 ] with a diverse set of r eal-world application, which include autonomous navigation [ 6 ], game AI micromanagement [ 10 , 27 ], and trac network optimization [ 45 ]. A unique challenge is the need for centralized training for agents to nd global optimal cooperative policies, while ensuring scalable ∗ W ork done at EA Digital Platform, Data & AI, Ele ctronic Arts. Proc. of the 19th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2020), B. A n, N. Y orke-Smith, A. El Fallah Seghrouchni, G. Sukthankar ( eds.), May 9–13, 2020, Auckland, New Zealand . © 2020 International Foundation for Autonomous Agents and Multiagent Systems (www .ifaamas.org). All rights reserved. decentralized execution whereby agents choose actions indepen- dently . In this paradigm of centralized training with decentralize d execution [ 5 ], a common approach [ 10 , 27 , 32 , 36 , 44 ] is to conduct centralized training at the level of primitive actions, which are the actions use d in the transition function of the Markov game [ 20 ]. Howev er , the design of hierarchical agents who can coop erate at a higher le vel of abstraction using temporally-extended skills in high- dimensional multi-agent environments is still an open question. A skill is a policy that is conditioned on a latent variable, execute d for an extended duration, and generates behavior from which the latent variable can be deco ded [ 1 , 9 ]. It is also not clear how multiple agents can discover skills without hand-crafted reward functions for each skill, and how to construct such hierarchical policies to allow human interpretation of skills for potential human-AI cooperation. In this paper , we take a hierarchical approach to fully cooperative MARL and address these questions by drawing inspiration from team sports games. At the team level, coaches train human players to execute complementary skills in parallel, such as moving to dif- ferent eld positions in a formation, as well as eective sequences of skills over time, such as switching between oensive and defen- sive maneuvers when ball p ossession changes. At the individual level, each player learns a sequence of primitive actions to execute a chosen skill. Hierarchical approaches inspired from such real- world practices have se veral benets for fully cooperative MARL. From an algorithmic viewpoint, a hierarchical decomposition in two key dimensions—over agents, and across time—simultane ously addresses b oth the diculty of learning cooperation at the level of noisy low-level actions in stochastic environments and the di- culty of long-term credit assignment due to highly-delayed r ewards (e.g., scoring a goal in football) [ 12 , 41 ]. Hierarchical approaches may also reduce computational complexity [ 38 ] to address the ex- ponential increase in sample complexity with number of agents in MARL. From the viewpoint of human- AI coop eration, which has near-term application to video game AI to improve human players’ experiences [ 46 ], hierarchical policies trained with explicit skills is a key step toward interpretable and modular policies. In this work, we take interpretability to mean the decodability of a latent skill from an agent’s observed behavior—i.e., a policy is interpretable if it produces events and actions in a consistent or distinguishable manner . While a at policy is a black-b ox, since the action output is purely determine d by the agent’s observation input, the modularity of hierarchical mo dels also provides an entry point for external control over the skills executed by AI teammates (e.g., e xecute the oense skill when it observes a human teammate doing so). Howev er , decomposing a global team obje ctive such as “scoring a goal” into many sub-objectives for training a collection of skills is extremely dicult without expert knowledge, which may be hard to access for complex settings such as competitive team sports. Man- ually crafting reward functions for each skill in high-dimensional state spaces involving numerous agents is also prone to missp eci- cation and cause unintended behavior [ 3 ]. Instead, we investigate a metho d for hierarchical agents in MARL to discover and learn a set of high-level latent skills. Agents should learn to coop erate by choosing eective combinations of skills with their teammates, and also dynamically choose skills in r esponse to the state of the game. In contrast to prior work in single-agent settings, where motion skills were discover ed purely via an intrinsic reward [ 1 , 9 ], MARL poses signicant new challenges for skill discovery . Merely discovering distinguishable individual motion in an open-ended multi-agent environment may be useless for a team objective. While increasing the number of skills increases the chance that some are useful for a task [ 9 ], doing so in the hierarchical multi-agent setting means exponentially increasing the size of a joint high-level action space and will exacerbate the diculty of learning. W e present a method for training hierarchical policies with un- supervise d skill discovery in cooperative MARL, with the following key technical and experimental contributions. 1) W e construct a two-level hierarchical agent for MARL by dening a high-level action space as a set of latent variables. Each agent consists of a high-level policy that chooses and sustains a latent variable for many time steps, and a low-level p olicy that uses both its obser- vation and the selected latent variable to take primitive actions. 2) W e use an extrinsic team reward to conduct centralize d training of high-level policies for cooperation, while we use a combination of an intrinsic re ward and the team re ward to conduct decentral- ized training of low-level policies with independent reinforcement learning (RL). This allows the use of powerful and general algo- rithms for cooperative MARL and single-agent RL to train high- and low-level policies, respectively . 3) W e dene the intrinsic r eward as the performance of a de coder that predicts the ground truth latent variable from trajectories generated by low-level policies that were conditioned on the latent variables. By dynamically weighting the intrinsic versus e xtrinsic reward, each low-level policy is trained to reach a balance between deco dability and usefulness—it executes a skill, without the need for hand-designed skill-specic re ward func- tions. 4) W e applie d this algorithm to a highly stochastic continuous state simulation of team sports and performe d a detailed quantita- tive investigation of the learned behaviors. Agents discover useful skills, that aect game events and determine low-lev el actions in distinct and interpretable ways, such as grouping together to steal possession from an opponent. They learn to choose complementary skills among the team, such as when one agent camps near the opponent goal to get a rebound when its teammate makes a long- range shot attempt. 5) Our hierarchical agents perform higher than at methods in ad-hoc co operation when matched with teammates who follow policies that were not encountered in training. This is an encouraging result for the possibility of human-AI cooperation. 2 RELA TED WORKS Building on the framework of options, temporally-extended actions, and hierarchical single-agent RL [ 8 , 26 , 33 , 38 ], early work on hier- archical MARL in discrete state spaces with hand-crafted subtasks [ 12 , 22 ] showed that learning cooperation at the level of subtasks signicantly speeds up learning over at methods [ 20 , 35 , 39 ]. Re- cent work built on deep reinforcement learning [ 24 , 30 ] to demon- strate hierarchical single-agent RL in high-dimensional continuous state spaces, using predened subgoals [ 16 ], end-to-end learning of options [ 4 ], and latent directional subgoals [ 41 ] in a two-level hierarchy . In hierarchical MARL, dierent subtasks are chosen con- currently by all agents, whereas only a single subtask is chosen for each segment in single-agent hierarchical RL [4, 41]. Progress in hierarchical learning benets from a complementary line of work on automatic subgoal discovery [ 23 ]. Our work draws inspiration from variational option discovery [ 1 , 9 , 13 ], which— in formal analogy with variational auto-encoders [ 15 ]—trains a maximum-entropy policy encoder to map latent context vectors into trajectories from which the context can be recovered by a supervise d decoder . In contrast to prior work on single-agent skill discovery that focus on nding distinguishable behavior in simu- lated robotics environments, option discovery in co operative MARL poses signicant new demands: 1) individually distinguishable be- haviors must be useful for the team objective; 2) hoping to discover useful skills by increasing the number of latent skills is impractical for the exponentially larger action space of MARL; and 3) skills must be discovered in the actual multi-agent environment rather than in an isolated single-agent setting. The key dierences from recent work in hierarchical MARL [ 2 , 40 ] are that we discov er skills with an intrinsic reward instead of hand-crafting subtask-specic rewards [ 40 ], and our agents are on equal footing without a de dicated “Manager” [ 2 ]. A concurrent work on MARL with latent skills [ 19 ] require fully-centralize d execution using global state information, while our method enables decentralized execution with lo cal observations. A complementar y line of work learns role -sp ecic parameters and assignment of roles to agents with unique features, where each role is sustained for an entire episode [ 43 ], while our agents can dynamically cho ose skills multiple times in an episode. W e design our hierarchical agents using QMIX [ 27 ] and independent DQN [ 24 , 39 ]; other decentralize d cooperative MARL [ 14 ] and single-agent RL [ 37 ] algorithms are equally applicable. 3 METHODS W e present a method for fully-coop erative hierarchical MARL, whereby independently-acting agents learn to cooperate using la- tent skills that emerge from a combination of intrinsic and extrinsic rewards. Inspir ed by training practices of real world professional sports teams, we create our method within the paradigm of central- ized training with decentralized execution [ 5 ]. For ease of exposition and intuition, we assume all agents have the same observation space and action space; nevertheless the y take individual actions based on individual observations. In the r est of this section, we dene the objective of hierarchical MARL with skill discov er y , describe our method to solve the optimization problem, and discuss practical implementation techniques for eective learning. 3.1 Combining centralized and decentralized training in hierarchical MARL W e describ e a two-lev el hierarchical MARL setup for training N agents, labeled by n ∈ [ N ] , as follows. Let Z denote a set of latent 𝑄 "#" (𝑠, ' 𝑧) 𝑄 * (𝑜 * , 𝑧 * ) 𝑧 𝜏 𝑝(𝑧 |𝜏) 𝑄 * (𝑜 * , 𝑧 * , 𝑎) Skill predictor Low - level policy 𝑎𝑟𝑔𝑚𝑎𝑥 4 𝑄 * (𝑜 * , 𝑧) 𝐸 6 𝑝(𝑧 |𝜏) Cooperative multi - agent reinf orcement learning High - level dynamic skill selection Skill Tr a j e c t o r y Rewa rd for useful and distinguishable skills Figure 1: Hierarchical MARL with unsup ervised skill discovery . At the high level (left), the extrinsic team reward is use d to train a centralized action-value function Q tot ( s , z ) that decomposes into individual utility functions Q n ( o n , z n ) for decentralized selection of latent skill variables z . At the low level (right), skill-conditioned action-value functions Q n ( o n , z n , a n ) take primi- tive actions independently . Trajectories τ generated under each z are colle cted into a dataset D = { ( z , τ ) } , which is used to train a skill de co der p ( z | τ ) to predict z from τ . The probability of selected skills under p ( z | τ ) is the intrinsic reward for low-level Q n . variables z , each of which corresponds to a skill . In this work, we use a nite set of latent variables with one-hot encoding; it is possible to generalize Z to be a learne d continuous embedding space [ 1 ]. W e treat Z as the action space for high-level p olicies 1 µ n : O 7→ Z , ∀ n ∈ [ N ] , each of which maps from an agent’s observation o n ∈ O to a choice of skill z n ∈ Z . Each choice of z n is sustained for t seg time steps: letting T = K t seg denote the length of an episode, there ar e K time points at which a high-level skill selection is made (see Section 3.4). Conditioned on a chosen latent skill and given an agent’s observation, a low-level policy π n : O × Z 7→ A outputs a primitive action a n in a low-level action space A . Each z ∈ Z and the latent-conditioned policy π n (· ; z n ) is a skill, in accord with terminology in the literature [ 1 , 9 , 13 ]. Let boldface µ , π , and a denote the joint high-level policy , joint low-level policy , and joint action, respectively . Let (·) − n denote a joint quantity for all agents except agent n . At the high level, µ learns to select skills to optimize an extrinsic team reward function R : S × { A } N n = 1 7→ R that maps global state and joint action to a scalar reward. At the low level, { π n } N n = 1 learn to choose primitive actions to produce useful and decodable behavior by optimizing a low-level reward function R L . Combining the learning at both levels, we vie w hierarchical MARL as a bilevel optimization problem [7]: max µ , π E z ∼ µ , P " E s t , a t ∼ π , P " T Õ t = 1 γ t R ( s t , a t ) # # (1) π n ∈ argmax π E z ∼ µ , P " K Õ k = 1 E τ n k ∼ π , P R L ( z n k , τ n k ) # , ∀ n ∈ [ N ] (2) where τ n k is the k -th trajectory segment that consists of a se quence of observations by agent n , P denotes the environment transition probability P ( s t + 1 | s t , a ) , and R L ( z n , τ n ) : = Í ( s t , a t ) ∈ τ n R L ( z n , s t , a t ) denotes the sum of agent n ’s low-level rewards along trajectory τ n . This may also be viewed as a general-sum meta-game between a µ -player and another π -player . When R L is the extrinsic team reward, we have a fully-co operative meta-game, while the other 1 Without loss of generality , and for consistency with our algorithm implementation below , we use the notation for deterministic policies in this paper . extreme is wher e R L solely promotes decodability . Our approach, explained in Section 3.2, lies in between these extremes to strike a balance between usefulness and decodability . It is dicult to solve (1) - (2) exactly in high-dimensional con- tinuous state spaces. Furthermore, we adjust R L dynamically to promote skill predictability (see Section 3.2). Instead, we approach it using powerful algorithms for MARL and RL. First, we use central- ized MARL algorithms to train high-lev el policies µ for cooperative high-level skill selection. While cooperative behavior may emerge from at policies trained by a team reward [ 21 ], explicitly training high-level skill-selection policies allows external contr ol over the choice of skills performe d (by xing a latent variable), and sub- sequent analysis of the b ehavior for each skill. Second, we apply independent RL to train low-level policies { π n } N n = 1 , each condi- tioned on a skill selected by the agent’s corresponding high-level policy , to take primitive actions to optimize R L ( z n , τ n ) (dened below in Section 3.2). This reects the fact that human play ers in team sports can master skills individually outside of team practice. 3.2 Skill discovery via dynamically weighted decoder-based intrinsic rewar ds W e dene the low-level re ward by rst introducing a skill deco der p ψ ( z n | τ n ) that predicts the ground truth latent skill z n that was used in the low-lev el policy π ( · ; z n ) that generated the trajectory τ n . The deco der is trained using a dataset D = { ( z , τ ) } of skill- trajectory pairs, where each consists of the z chosen by a high level policy and the corresponding trajector y τ generated by the low level policy given z , over all agents. D is accumulated in an online manner during training. Hence , training p ψ alone can be view ed as a supervised learning problem where we have access to the ground truth “label” z asso ciated with each “ datapoint” τ . W e dene the intrinsic reward R I ( z n k , τ n k ) for agent n ’s k -th tra- jectory segment τ n k via the prediction p erformance of the skill decoder on the tuple ( z n k , τ n k ) . Agent n receives this scalar re ward upon generating the segment τ n k . The key intuition is that a skill in many complex fully-cooperative team games can be inferred from the trajectory of primitive actions that implement the skill [ 14 , 18 ]. For example, any agent who executes a defensive subtask in soccer will move toward opponents in a consistent way that mainly de- pends on its own observations, with only weak dependence on the behavior of other physically distant agents 2 . This intrinsic reward encourages the generation of distinguishable behavior for dierent skills, since only by doing so can the low-lev el policy produce su- ciently distinct “classes” in the dataset D for the decoder to achieve high prediction performance. Hence we dene the low-level reward R L as a combination of team reward R and intrinsic reward R I : R L ( z n , τ n ) : = α Õ s t , a t ∈ τ n γ t R ( s t , a t ) + ( 1 − α ) R I ( z n , τ n ) (3) where R I : = p ψ ( z n | τ n ) (4) α ∈ R is a dynamic weight (specied below) that determines the amount of intrinsic v ersus environment reward. In contrast to prior work on single-agent option discovery that do not use an extrinsic reward [ 1 , 9 , 13 ], we take advantage of the team r eward in MARL to guarantee that skills are useful for team performance, and r ely on the intrinsic reward only to promote the association of latent variables with predictable behavior . This ensures that low-level policies, when conditioned on dierent latent variables, produce trajectories that are 1) suciently dierent to allow decoding of the latent variable, and 2) useful for attaining the true game rewar d— e.g. “attack opponent net” and “defend own net” . W e decrease α from 1.0 to α end via an automatic curriculum in which α decreases by α step only when the performance (e .g., win rate) in evaluation episodes, conducted p eriodically during training, exceeds a thresh- old α threshold . At high α , low-level policies learn independently to maximize the team reward by taking useful actions, some of which can be composed into interpretable behavior . As α decreases and the skill decoder associates traje ctories with latent variables, the low-level policy is increasingly r ewarded for generating easily de- codable modes of b ehavior when conditioned on dierent z . A high α threshold can be mor e suitable for highly stochastic games ( see Sec- tion 5.2), so that the weight on the intrinsic reward increases later during training, after agents have learned to take useful actions. 3.3 Algorithm Algorithm 1 is our approach to the optimization pr oblem eqs. (1) and (2), with skill discovery based on e q. (3). W e initialize replay buers B H , B L for both levels of the hierarchy , for o-policy up- dates in similar style to DQN [ 24 ], and initialize a dataset D for the decoder ( line 2). At the k -th high-level step, which occurs once for every t seg primitive time steps (line 6), we compute the SMDP reward ˜ R t : = Í t seg − 1 i = 0 γ i R ( s t − i , a t − i ) for the high-level policy (line 8) [ 38 ]. Each agent computes its reward and independently selects a new skill to execute for the next high-level step (lines 12-13). W e periodically take gradient steps to optimize the high level coopera- tive skill-selection objective (1) (lines 15-17), using QMIX [ 27 ] to 2 As a rst step, we do not include higher-order skills that involve coordinated behavior of two or more agents. Our method can be extended to higher-order skills by associating multiple agents’ concurrent trajectories with a single skill. Algorithm 1 Hierarchical MARL with unsupervise d skill discovery 1: procedure Algorithm 2: Initialize high-level Q ϕ , low-level Q θ , decoder p ψ , high- level replay buer B H , low-level replay buer B L , and trajectory-skill dataset D 3: for each episode do 4: s t , o t = env .reset() 5: Initialize trajectory storage { τ n } N n = 1 of max length t seg 6: for each step t = 1 , . . . , T in episo de do 7: if t mod t seg = 0 then 8: if t > 1 then 9: Compute ˜ R t : = γ t seg ∗ Í t seg k = 0 R t − k 10: Store ( s t − t seg , o t − t seg , z , ˜ R t , s t , o t ) into B H 11: for each agent n do 12: Store ( z n , τ n ) into D 13: Compute intrinsic reward R n I using (4) 14: end for 15: end if 16: Select new z n by ϵ -greedy ( Q n ϕ ( o n , z )) , ∀ n ∈ [ N ] 17: if # ( high level steps) mod t train = 0 then 18: Update Q ϕ ( s , z ) using B H and (5) 19: end if 20: end if 21: Get a n t from ϵ -greedy ( Q ( o n t , z n t , a )) for each agent 22: s t + 1 , o t + 1 , R t = env .step( a t ) 23: Compute R n L : = α R t + ( 1 − α ) R n I for each agent 24: For all agents, store ( o n t , a n t , R n L , o n t + 1 , z n ) into low- level replay buer B L , and append o n t to trajectory τ n 25: if # ( low-lev el steps) mod t train = 0 then 26: Update Q θ ( o n , z n , a n ) using B L and (7) 27: end if 28: end for 29: if size of D ≥ N batch then 30: Update decoder p ψ ( z | τ ) using D , then empty D 31: end if 32: if evaluation win rate exceeds α threshold then 33: α ← max ( α end , α − α step ) 34: end if 35: end for 36: end procedure train a centralized Q-function Q tot ϕ ( s t , z ) via minimizing the loss: L ( ϕ ) : = E µ , π 1 2 y k − Q tot ϕ ( s k , z k ) 2 (5) y k : = ˜ R k + γ Q tot ϕ ( s k + 1 , z ′ ) | { z ′ n = argmax z n Q n ϕ ( o n k + 1 , z n ) } N n = 1 (6) Q tot ϕ is a non-linear function (e .g., neural network) that is mono- tonic in individual utility functions Q n ϕ , n ∈ [ N ] , and we denote µ as the collection of greedy policies induced by Q n ϕ . The hypernetwork of QMIX enforces ∂ Q tot ϕ / ∂ Q n ϕ > 0 , which is a sucient condition for a global argmax to be achieved via decentralize d argmax , i.e., argmax z Q tot ϕ (· , z ) = { argmax z n Q n ϕ (· , z n )} N n = 1 . This allows central- ized training with decentralize d skill selection. In general, one can choose from a diverse set of cooperative MARL algorithms with decentralized execution [10, 32, 36, 44]. Conditioned on the choices of skills, each agent independently executes primitive actions at every low-level time step (lines 19- 20), using the greedy policy π n induced by low-level Q-functions Q n θ ( o n t , z n t , a n ) . W e periodically take gradient steps to optimize the low level obje ctive (2) (lines 23-25), by using independent DQN [24, 39, 42] to optimize Q n θ via minimizing the loss: L ( θ ) : = E µ , π 1 2 y n t − Q n θ ( o n t , z n , a n t ) 2 (7) y n t : = R L ( z n , τ n ) + γ max a n ˆ Q n θ ( o n t + 1 , z n , a n ) , ∀ n ∈ [ N ] (8) π denotes the collection of greedy policies induce d by all Q n θ . The low level rewar d R L includes the contribution of the intrinsic reward R I only at the nal time step of each length- t seg trajectory segment, i.e., at every high-level step . ˆ Q is a target network [24]. Once N batch number of ( z n , τ n ) are collected into the dataset D (lines 11, 27-29), the skill decoder p ψ ( z | τ ) is trained to predict z given τ via supervise d learning on D by minimizing a standard cross-entropy loss. Each chosen z n acts as the class label for the corresponding trajectory τ n . Periodically , we evaluate the agents’ performance (e.g., win rate) in seperate evaluation episodes; if per- formance exceeds α threshold , we decrease the w eight α by α step with lower b ound α end (Section 3.2). While it is e xtremely challenging to provide theoretical guarantees for hierarchical methods, especially due to the nee d for nonlinear function approximation to tackle high- dimensional continuous state spaces, simultaneous optimization in hierarchical RL has shown promising practical r esults [4, 41]. 3.4 Trajectory segmentation and compression Hierarchical MARL requires agents to change their choice of skills dynamically at multiple times within an episode, such as in response to a change of ball possession in soccer . This means we use partial segments instead of full episode trajectories for skill discovery , in contrast to the single-agent case [ 1 , 9 , 13 ]. At rst glance, using a xed time discretization hyperparameter t seg for segmentation may pose diculties for the skill decoder , such as when a segment contains qualitatively dierent behavior that should correspond to dierent skills. W e address this issue by using the time p oints at which the high-level policy cho oses a new set of skill assign- ments as the segmentation. Hence, π learns to generate trajectory segments in between the time points, and p ψ learns to associate these segments with the chosen latent variables. W e synchr onize the time points of all agents’ high-lev el skill choice, and all skills are sustained for t seg low-level steps. This corresponds to a special case of the “any” termination scheme, which is dominant over other termination schemes considered in [ 28 ]. A practical approach is to dene a range of values based on domain knowledge (e.g., average duration of a player’s ball p ossession) and include it in hyperpa- rameter search. Agents can still learn skills that require more than t seg steps, by sustaining the same skill for multiple high-lev el steps. Building on [ 1 ], we preprocess each trajector y before using it as input to the decoder . W e downsample by retaining every k skip steps, which lters out low-le vel noise in stochastic envir onments. W e use the element-wise dierence b etween the downsampled obser vation vectors. This discourages the possibility that more than one skill exhibits stationary behavior (e.g., camping at dierent regions of a eld), as the dierence will b e indistinguishable for the de coder and result in low intrinsic reward. W e reduce the dimension of obser- vation vectors for the decoder by removing entries corresponding to all other agents, while retaining game-specic information (e .g., ball possession). Hence an agent’s own trajector y must contain enough information for decoding the latent skill variable. 4 EXPERIMEN T AL SET UP Our experiments demonstrate that the proposed method discovers interpretable skills that are useful for high-level strategies and has potential for human- AI cooperation in team sports games 3 . W e contribute evidence that hierarchical MARL with unsup ervised skill discovery can meet or excee d the performance of non-hierarchical methods in high-dimensional environments with only a global team reward. W e describ e the simulation setup in Se ction 4.1 and provide full implementation details of all methods in Section 4.2. 4.1 Simple T eam Sports Simulator The Simple T eam Sports Simulator (STS2) captures the high-level rules and physical dynamics of general N versus N team sports while abstracting away ne-grained details that do not signicantly impact strategic team play [ 31 , 47 ]. Stochasticity of ball p ossession and goals makes STS2 a challenging environment for MARL. Com- plementary to 3D simulations such as Kurach et al . [17] that require massively parallelized training, STS2 is a lightweight benchmark where MARL agents can outperform the scripted opponent team within hours on a single CP U. W e train in 3v3 mo de against the scripted opponent team for 50k episo des. Each episode terminates either upon a goal or a tie at 500 time steps. State. W e dene a state representation that is invariant under 180 degree rotation of the playing eld and switch of team perspec- tive. For one team, the state vector has the following components, making up total dimension 34: normalize d position of the player with possession relative to the goal, and its velocity; a 1-hot vector indicating which team or opp onent player has possession; for each team and opponent player , its normalized p osition and velocity . Observation. Each agent has its own egocentric observation vector with the following components, making up total dimension 31: normalized position and velocity of the player with possession relative to this agent; a binary indicator of whether this agent has possession; a binary indicator of whether its team has p ossession; its normalized position and its velocity; relative normalized position of each teammate, and their relative velocities; a binary indicator of whether the opponent team has p ossession; relativ e normalized position of each opponent player , and their relative velocities. Action. The low-level discrete set of actions consists of: do- nothing, shoot, pass-1, ... , pass-N, down, up, right, left. Movement and shoot dir ections are relative to the team’s eld side. If the agent does not have possession and attempts to shoot or pass, or if it has possession and passes to itself, it is forced to do nothing. Reward. The team receives r eward + 1 for scoring, − 1 when the opponent scor es, ± 0 . 1 on the single step when it regains possession from, or loses possession to, the opponent. W e include a reward of ± 1 /( 2 ∗ max steps per episo de ) for having or not having p ossession. 3 Code for experiments is available at https://github.com/011235813/hierarchical- marl Game events. W e dene a set of game events, which are fre- quently used for analyzing team sports [ 11 ], to quantify the eect of skills. Goals: agent scored a goal, upon which an episode ends. Oensive rebound: agent’s team made a shot attempt, which missed, and the agent retrieved possession. Shot attempts: agent attempted to score a goal. Made or received pass: agent made (received) a suc- cessful pass to (from) a teammate. Steals: agent retrieved possession from an opponent by direct physical contact. 4.2 Implementation and baselines W e use parameter-sharing among all agents, as is standard for ho- mogeneous agents in cooperative MARL [ 14 ]. For function approxi- mation, we use fully-connected neural networks without recurrent units since the game is fully observable. Each component is de- picted in Figure 1. The low-level Q-function has two hidden layers, each with 64 units, and one output no de per action. The high-level Q-function is a QMIX architecture: the individual utility function has two layers with 128 units per layer , and one output node per skill. Utility values of all agents ar e passed into a mixer network, whose non-negative weights in two hidden lay ers are generated by hypernetworks of output dimension 64, and whose nal output is a single global Q value (see [ 27 ]). The skill decoder is a bidirectional LSTM [ 29 ] with 128 hidden units in b oth forward and backward cells, whose outputs are mean-po oled over time and passed through a softmax output layer to produce probabilities over skills. W e use batch size N batch = 1000 to train the de coder; ϵ -greedy exploration at both high and low levels with ϵ decaying linearly from 0.5 to 0.05 in 1e3 episodes; replay buers B H and B L of size 1e5; learning rate 1e-4; and discount γ = 0 . 99 . High and low le vel action-value functions are trained using minibatches of 256 transitions every 10 steps at the high and low levels, respectively . T arget networks [ 24 ] are up dated after each training step with up date factor 0.01. W e conduct 20 episodes of e valuation once every 100 training episo des. W e experimented with 4 and 8 latent skills, t seg = 10 , and let α de- cay fr om 1.0 to a minimum of 0.6 by α step = 0 . 01 whenever average win rate during evaluation exceeds α threshold = 70% . W e process trajectory segments as describ ed in Section 3.4 with k skip = 2 . As we instantiate our general method using QMIX [ 27 ] at the high level and independent Q-learning (IQL) [ 24 , 39 ] at the low level, we compare performance with these two baselines to demon- strate that the new hierarchical architecture maintains performance while gaining interpretability . QMIX uses the same neural archi- tecture as our method, except that the individual utility function outputs action-values for primitive actions instead of action values for high-le vel skills. IQL uses a two-layer Q-netw ork with 128 units per layer . W e rst performed a coarse manual search for hyper- parameters of QMIX and IQL, and used the same same values for the corresponding subset of hyperparameters in our method. Ad- ditional hyperparameters ( α threshold , α step , and t seg ) in our method were chosen from a coarse manual search, and we show results on hyperparameter sensitivity . W e also compared with a variant of our method that uses two hand-scripted subtask rewar d functions with the same hierarchical architecture. An agent with subtask 1 gets reward +1 for making a goal when having possession; an agent with subtask 2 gets +1 for stealing possession from an opp onent. These individual rewards mitigate the dicult problem of multi-agent credit assignment, and so this variant gives a rough indication of maximum possible win rate against the scripted opponent team. 5 RESULTS Our method for Hierarchical learning with Skill Discovery , labele d “HSD” , learns interpretable skills that are useful for high-le vel co- operation. HSD meets the performance of QMIX and IQL, exceeds them in ad-hoc cooperation, and enables deep er policy analysis due to its hierarchical structur e. Section 5.1 provides a detailed quan- titative behavioral analysis of learned skills. Section 5.2 discusses performance, hyperparameters sensitivity , and ad-hoc coop eration. 5.1 Quantitative behavioral analysis W e conducted a quantitative analysis of the discovered skills by measuring the impact of skills on occurrence of game events and primitive actions, agents’ choices of skills over an episode, and the spatial occurrence of skills. Figure 2 shows results for the case of four latent skills, which we describe immediately below . W e describe the case of eight latent skills later in Figure 3. Analysis of game events. Figure 2a shows the counts of each game event under each skill, summed over any agent who was assigned to execute the skill, and averaged ov er 100 test episodes. Skill 1 makes the most shot attempts, Skill 2 provides defense by focusing on steals, while Skill 3 contributes to the most numb er of successful goals. This dierence in game impact, which emerged without any skill-specic reward functions, is also reected by the large separation of principal components in Figur e 2b that result from applying PCA to the vector of event counts of Figure 2a. Fig- ure 2b suggests that component 1 corr esponds to tendency to make oensive shots, while comp onent 2 corresponds to tendency to make steals. Figure 2c shows the distribution of primitive actions taken by the low-level policy when conditioned on each latent skill. Skill 0 predominantly moves up towards the opp onent net to begin oense, Skill 1 is more biased toward the left eld, while Skill 2 moves down to defend the home net more than other skills. Figure 2e shows the usage of each skill by the high-level policy , under the cases when agent team has possession and when the op- ponent team has possession. Skill 2 is strongly associated with lack of possession since it is a defensive skill for regaining possession. Time series of skill usage. Figure 2f shows a time series of skill usage over high-level steps by each agent during thr ee dier- ent episodes (from top to bottom). Importantly , agents learned to choose complementary skills, such as in Episode 3 when Agent 3 stays for defense while Agents 1 and 2 execute oense via Skills 1 and 3, at step 9. Each individual agent also dynamically switches between skills, such as in Episode 1 when Agents 1 and 3 switch from the defensiv e Skill 2 to the oensive Skill 3 at step 6. As shown by the extended periods in all episodes when all agents play the defensive Skill 2, agents are able to sustain the same skill over mul- tiple conse cutive high-level steps, which mitigates the concern over choosing a xed t seg . Note that at any given time in the game, the defensive Skill 2 is almost always used by some agent either to make steals or cover the home net. Spatial o ccurrence of skills. Figure 2g is a heatmap of skill usage over the playing eld. Consistent with the previous analysis, Skill 0 is use d for moving up for oense, Skills 1 and 3 tend to 0 1 2 3 Latent skill 0.00 0.25 0.50 0.75 1.00 1.25 1.50 Average count Goals OR Shots Steals (a) Event distribution −0.5 0.0 0.5 Component 1 (0.58 explained variance) −0.4 −0.2 0.0 0.2 0.4 0.6 0.8 Component 2 (0.40 explained variance) 0 1 2 3 (b) PCA of events 0 1 2 3 Latent skill 0 10 20 30 40 50 60 Average count Noop Shot P1 P2 P3 Down Up Right Left (c) Action distribution −20 0 20 40 Component 1 (0.56 explained variance) −20 −10 0 10 20 Component 2 (0.34 explained variance) 0 1 2 3 (d) PCA of actions 0 1 2 3 Latent skill 0 5 10 15 20 25 Average count With possession Without possession (e) Overall skill usage 0 3 6 9 0 1 2 0 3 6 9 12 15 18 0 1 2 0 3 6 9 0 1 2 0.0 0.2 0.4 0.6 0.8 1.0 High level step 0.0 0.2 0.4 0.6 0.8 1.0 Latent skill Agent 1 Agent 2 Agent 3 (f ) Time series of latent skill usage 0 10 0 10 20 30 0 10 0 10 20 30 0 10 0 10 20 30 0 10 0 10 20 30 1 0 0 1 0 1 1 0 2 (g) Latent skill usage (skills 0-3, left to right) over the spatial playing eld Figure 2: (a-c): Behavioral investigation of one HSD p olicy , showing average and standard error over 100 test episodes. (a) Dis- tribution of spe cial game events for each latent skill. ( b) Projection of each skill’s event distribution via PCA. (c) Distribution of primitive actions for each latent skill, where “Px” denotes “pass to teammate x” . (d) Projection of each skill’s action distri- bution via PCA. (e) Count of overall skill usage, when agent team has or does not have p ossession. (f ) Time series of skills selected high-level steps, each consisting of t seg = 10 primitive steps; each subplot shows one independent test episode; (g) Count of skill usage over the full continuous playing eld, discretized to a 36x18 grid. camp near the opponent net (top) to attempt shots, while Skill 2 is concentrated near the home net ( bottom) to make defensive steals. Increasing numb er of skills. The number of latent skills is also a key design choice to make base d on domain knowledge. Figure 3 analyzes HSD when traine d with eight skills. Skills 0, 3, and 6 focus on shot attempts and oensive rebounds (Figure 3a), and they have high values of the rst principal component (Figure 3b). Skills 1 and 2 focus on defensive steals. Figure 3c shows that Skill 0 moves up for oense the most, while Skill 4 moves down to play defense. This is reected by their large separation in the rst principal component (Figure 3d). 5.2 Performance and parameter sensitivity Figure 4 shows win rate against the scripted opponent team over training episodes for HSD and baselines, each with 5 independent runs, and for varying hyperparameter settings of HSD, each with 3 independent runs. HSD agents learn faster than QMIX and IQL, consistent with ndings on hierarchical versus non-hierarchical methods in early work [ 12 ], while their nal performance are within the margin of error (Figure 4a). HSD-ext do es not have access to extrinsic rewards and underperforms the rest. This supports our hypothesis that the extrinsic team reward is needed in combination with the intrinsic r eward to pr omote useful behavior . HSD-scripted outperformed other methods, showing that using co operative learn- ing at the high-level and independent learning at the low level is a strong approach, and impro vement to skill discovery is possible. W e investigated the eect of varying the key hyperparameters of HSD. Figure 4b sho ws that larger values of α threshold gives higher performance and lower variance. A small α threshold increases the likelihood that a spuriously high evaluation performance crosses α threshold , which would cause a r e-weighting of the extrinsic versus intrinsic reward even when the agents have not yet adapted to the current reward. This e xplains the instability of α threshold = 0 . 4 in Figure 4b. Likewise, Figure 4c shows that a smaller value of α step performs better , because each adjustment of the low-level reward is smaller and hence the automatic curriculum is easier for learning. Figure 4d shows that agents who sustain high-level skills for 10 or 20 time steps perform better than agents who sustain only for 5 steps. A smaller t seg means that agents make more frequent decisions to sustain or switch their choice of skill, which allows for more exible policies but increases the diculty of learning. T able 1: Win/lose percentage of nal policies over 100 test episodes and 5 seeds, matched with dierent teammates. HSD QMIX IQL T eammate Win Lose Win Lose Win Lose Training 46 (4) 39 (4) 55 (3) 23 (3) 36 (7) 46 (4) 1 scripted 49 (4) 45 (3) 48 (4) 44 (4) 32 (3) 54 (4) 2 scripted 52 (3) 45 (1) 45 (2) 51 (2) 37 (2) 58 (1) 1 defensive 43 (5) 42 (4) - - - - 1 oensive 45 (2) 41 (1) - - - - 0 1 2 3 4 5 6 7 Latent skill 0.0 0.2 0.4 0.6 0.8 1.0 Average count Goals OR Shots Steals (a) Event distribution −0.4 −0.2 0.0 0.2 0.4 0.6 Component 1 (0.79 explained variance) −0.2 −0.1 0.0 0.1 0.2 Component 2 (0.15 explained variance) 0 1 2 3 4 5 6 7 (b) PCA of events 0 1 2 3 4 5 6 7 Latent skill 0 10 20 30 40 Average count Noop Shot P1 P2 P3 Down Up Right Left (c) Action distribution −20 −10 0 10 20 30 Component 1 (0.58 explained variance) −15 −10 −5 0 5 10 15 Component 2 (0.16 explained variance) 0 1 2 3 4 5 6 7 (d) PCA of actions Figure 3: Behavioral analysis of HSD policies with 8 latent skills. (a) Skill 0 makes the most goals, skill 1 focuses on defensive steals, skill 6 makes the most shot attempts. (b) Dierences b etween skills, especially skills 0, 1 and 6, are reecte d by the PCA reduction of events. (c) Skill 0 predominantly moves up, which explains its high goal rate, while skill 4 moves down the most (d) These distinguishable characteristics of skills are reecte d by their large separation after PCA reduction. 0 1 2 3 4 5 Episode 1e4 0.0 0.2 0.4 0.6 0.8 Win rate HSD-scripted HSD-ext QMIX IQL HSD (a) Win rate against scripted b ots 0 1 2 3 4 5 Episode 1e4 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Win rate 0.4 0.6 0.7 (b) V arying α threshold 0 1 2 3 4 5 Episode 1e4 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Win rate 0.01 0.02 0.05 (c) V arying α step 0 1 2 3 4 5 Episode 1e4 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Win rate (5, 1) (10, 2) (20, 4) (d) V arying t seg and k skip Figure 4: Win rate against scripted opponent team over training episodes. Each curve is the mean over random se eds (5 for (a) and 3 for (b-d)) with shade d region representing 95% condence inter val. (a) HSD is within margin of error with QMIX and IQL. HSD-scripte d has the same hierarchical architecture as HSD but is trained with hand-scripted subtask rewards. HSD-ext does not use extrinsic rewards. (b-d) Learning is more stable with high α threshold , small α step , and longer t seg . Ad Hoc coop eration. W e investigated the test performance of agents in ad-hoc cooperation, by giving them teammate(s) with whom they never pre viously trained [34]. This mimics the setting where AI agents must co operate with a human player in team sports games. T able 1 shows the win and lose percentage of HSD , QMIX, and IQL ( draws are possible). HSD agents perform as well or better when one or two of their teammates ar e replaced by scripted bots, possibly due to indep endently-trained low-level policies in HSD . However , QMIX agents performed signicantly worse when paired with scripted bots, likely because the out-of-training be- havior of bots p ose diculties for QMIX agents who under went fully-centralized training. IQL agents also lost signicantly mor e often with scripted teammates. For HSD, we can also x one agent to always play a defensive or oensive skill. Based on Figure 2a, we chose Skill 1 for oense and Skill 2 for defense. HSD agents are able to maintain their performance within the margin of error . 6 CONCLUSION AND DISCUSSION W e presented a method for hierarchical multi-agent reinforcement learning that discovers useful skills for strategic teamwork. W e train coop erative decentralized p olicies for high-level skill selec- tion and train independent low-level p olicies to execute chosen skills, which emerge from a dynamically weighted combination of intrinsic and extrinsic r ewards. W e demonstrated the emergence of quantiable, distinct and useful skills in stochastic team sports simulations without assigning a reward to each skill. These nd- ings are a step to ward multi-agent game AI that execute realistic high-level strategies and can cooperate with human players. There are many inter esting avenues for future work. One may condition high-level policies on unique agent features, such that agents play dierent roles [ 43 ] that aect their choice of skills. Asynchronous termination [ 4 ] of subtasks allows learning a larger space of policies. Optimizing the number of skills is also a natural generalization. One may apply curriculum-learning approaches that initialize skill-conditioned low-lev el policies from pretraining in an induced single-agent setting [ 44 ] or using expert data, analogous to professional players practicing skills outside of team matches. This may speed up training since low-level policies can already generate useful trajectories that can be segmented into distinguishable skills. A CKNO WLEDGMEN TS W e are grateful to Ahmad Beirami (Facebook AI) for signicant contributions to extensive and insightful discussions throughout the course of this work, and for detaile d feedback that helped to improve the clarity and precision of the paper . W e also thank indi- viduals from Electronic Arts: Maziar Sanjabi and Y unqi Zhao for discussions; Caedmon Somers, Jason Rupert and Yunqi Zhao for STS2 development; Mohsen Sardari and K azi Zaman for support. REFERENCES [1] Joshua Achiam, Harrison Edwards, Dario Amodei, and Pieter Abbe el. 2018. Vari- ational option discovery algorithms. arXiv preprint arXiv:1807.10299 (2018). [2] Sanjeevan Ahilan and Peter Dayan. 2019. Feudal multi-agent hierarchies for cooperative reinforcement learning. arXiv preprint arXiv:1901.08492 (2019). [3] Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. 2016. Concrete problems in AI safety . arXiv preprint (2016). [4] Pierre-Luc Bacon, Jean Harb, and Doina Precup. 2017. The option-critic architec- ture. In Thirty-First AAAI Conference on A rticial Intelligence . [5] Daniel S Bernstein, Robert Givan, Neil Immerman, and Shlomo Zilberstein. 2002. The complexity of decentralized control of Marko v decision processes. Mathe- matics of operations research 27, 4 (2002), 819–840. [6] Y ongcan Cao, W enwu Yu, W ei Ren, and Guanrong Chen. 2013. An overview of recent progress in the study of distributed multi-agent co ordination. IEEE Transactions on Industrial informatics 9, 1 (2013), 427–438. [7] Benoît Colson, Patrice Marcotte, and Gilles Savard. 2007. An overview of bilevel optimization. A nnals of operations research 153, 1 (2007), 235–256. [8] Peter Dayan and Georey E Hinton. 1993. Feudal reinforcement learning. In Advances in neural information processing systems . 271–278. [9] Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, and Sergey Levine. 2019. Di- versity is all you need: Learning skills without a reward function. In International Conference on Learning Representations . [10] Jakob N Foerster , Gregory Farquhar , Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. 2018. Counterfactual multi-agent policy gradients. In Thirty- Second AAAI Conference on Articial Intelligence . [11] Alexander Franks, Andrew Miller, Luke Bornn, Kirk Goldsberr y , et al . 2015. Characterizing the spatial structure of defensive skill in professional basketball. The A nnals of Applied Statistics 9, 1 (2015), 94–121. [12] Mohammad Ghavamzadeh, Sridhar Mahadevan, and Rajbala Makar. 2006. Hierar- chical multi-agent reinforcement learning. Autonomous Agents and Multi-A gent Systems 13, 2 (2006), 197–229. [13] Karol Gregor , Danilo Jimenez Rezende, and Daan Wierstra. 2016. V ariational intrinsic control. arXiv preprint arXiv:1611.07507 (2016). [14] Pablo Hernandez-Leal, Bilal Kartal, and Matthew E Taylor . 2018. Is multiagent deep reinforcement learning the answer or the question? A brief sur vey . arXiv preprint arXiv:1810.05587 (2018). [15] Diederik P Kingma and Max W elling. 2014. Auto-encoding variational bayes. In International Conference on Learning Representations . [16] T ejas D Kulkarni, Karthik Narasimhan, Ardavan Saeedi, and Josh T enenbaum. 2016. Hierarchical deep reinforcement learning: Integrating temp oral abstraction and intrinsic motivation. In Advances in neural information processing systems . 3675–3683. [17] Karol Kurach, Anton Raichuk, Piotr Stańczyk, Michał Zaj a ¸ c, Olivier Bachem, Lasse Espeholt, Carlos Riquelme, Damien Vincent, Marcin Michalski, Olivier Bousquet, et al . 2019. Google Research Football: A Novel Reinforcement Learning Environment. arXiv preprint arXiv:1907.11180 (2019). [18] Hoang M Le, Yisong Yue, Peter Carr, and Patrick Lucey . 2017. Coordinated multi- agent imitation learning. In Proceedings of the 34th International Conference on Machine Learning- V olume 70 . JMLR. org, 1995–2003. [19] Y oungwoon Le e, Jingyun Y ang, and Joseph J. Lim. 2020. Learning to Coordinate Manipulation Skills via Skill Behavior Diversication. In International Conference on Learning Representations . https://openreview .net/forum?id=r yxB2lBtvH [20] Michael L Littman. 1994. Markov games as a framework for multi-agent rein- forcement learning. In Machine Learning Proceedings 1994 . Elsevier , 157–163. [21] Siqi Liu, Guy Lever , Josh Merel, Saran Tunyasuvunakool, Nicolas Heess, and Thore Graepel. 2019. Emergent coordination through competition. In Interna- tional Conference on Learning Representations . [22] Rajbala Makar , Sridhar Mahadevan, and Mohammad Ghavamzadeh. 2001. Hierar- chical multi-agent reinforcement learning. In Proceedings of the fth international conference on Autonomous agents . ACM, 246–253. [23] Amy McGovern and Andrew G Barto. 2001. Automatic Discovery of Subgoals in Reinforcement Learning using Diverse Density . In Procee dings of the Eighteenth International Conference on Machine Learning . Morgan K aufmann Publishers Inc., 361–368. [24] V olodymyr Mnih, Koray Kavukcuoglu, David Silver , Andrei A Rusu, Joel V eness, Marc G Bellemare, Alex Grav es, Martin Riedmiller , Andreas K Fidjeland, Georg Ostrovski, et al . 2015. Human-level control through deep r einforcement learning. Nature 518, 7540 (2015), 529. [25] Liviu Panait and Sean Luke . 2005. Coop erative multi-agent learning: The state of the art. A utonomous agents and multi-agent systems 11, 3 (2005), 387–434. [26] Doina Precup. 2000. T emporal Abstraction in Reinforcement Learning. Ph. D. thesis, University of Massachusetts (2000). [27] T abish Rashid, Mikayel Samvelyan, Christian Schr oeder, Gregory Farquhar , Jakob Foerster , and Shimon Whiteson. 2018. QMIX: Monotonic Value Function Factori- sation for Deep Multi-A gent Reinforcement Learning. In Proceedings of the 35th International Conference on Machine Learning . 4295–4304. [28] Khashayar Rohanimanesh and Sridhar Mahadevan. 2003. Learning to take con- current actions. In Advances in neural information processing systems . 1651–1658. [29] Mike Schuster and Kuldip K Paliwal. 1997. Bidirectional recurrent neural net- works. IEEE Transactions on Signal Processing 45, 11 (1997), 2673–2681. [30] David Silver , Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George V an Den Driessche, Julian Schrittwieser , Ioannis Antonoglou, V e da Panneershel- vam, Marc Lanctot, et al . 2016. Mastering the game of Go with deep neural networks and tree search. nature 529, 7587 (2016), 484. [31] Caedmon Somers, Jason Rupert, Yunqi Zhao, Igor Bor ovikov , and Jiachen Y ang. 2020. Simple T eam Sports Simulator (STS2). (Feb. 2020). https://github.com/ electronicarts/Simple T eamSportsSimulator [32] K yunghwan Son, Daewoo Kim, W an Ju Kang, David Hostallero, and Y ung Yi. 2019. QTRAN: Learning to Factorize with T ransformation for Cooperative Multi- Agent Reinforcement learning. In International Conference on Machine Learning . [33] Martin Stolle and Doina Pr ecup. 2002. Learning options in reinforcement learning. In International Symposium on abstraction, reformulation, and approximation . Springer , 212–223. [34] Peter Stone, Gal A K aminka, Sarit Kraus, and Jerey S Rosenschein. 2010. Ad hoc autonomous agent teams: Collaboration without pre-coordination. In T wenty- Fourth AAAI Conference on A rticial Intelligence . [35] Peter Stone and Manuela V eloso. 2000. Multiagent systems: A sur vey from a machine learning perspective. A utonomous Robots 8, 3 (2000), 345–383. [36] Peter Sunehag, Guy Lever , Audrunas Gruslys, W ojciech Marian Czarne cki, Vini- cius Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z Leibo, Karl T uyls, et al . 2018. Value-decomposition networks for cooperative multi-agent learning based on team reward. In Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems . International Foundation for Autonomous A gents and Multiagent Systems, 2085–2087. [37] Richard S Sutton and Andre w G Barto. 2018. Reinforcement learning: An intro- duction . MIT press. [38] Richard S Sutton, Doina Precup, and Satinder Singh. 1999. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. A rticial intelligence 112, 1-2 (1999), 181–211. [39] Ming Tan. 1993. Multi-agent reinforcement learning: Independent vs. coop erative agents. In Proceedings of the tenth international conference on machine learning . 330–337. [40] Hongyao T ang, Jianye Hao , T angjie Lv , Yingfeng Chen, Zongzhang Zhang, Hang- tian Jia, Chunxu Ren, Y an Zheng, Changjie Fan, and Li W ang. 2018. Hierarchical deep multiagent reinforcement learning. arXiv preprint arXiv:1809.09332 (2018). [41] Alexander Sasha V ezhnevets, Simon Osindero, T om Schaul, Nicolas Heess, Max Jaderberg, David Silver , and Koray Kavukcuoglu. 2017. Feudal networks for hierar- chical reinforcement learning. In Proceedings of the 34th International Conference on Machine Learning- V olume 70 . JMLR. org, 3540–3549. [42] Christopher JCH W atkins and Peter Dayan. 1992. Q-learning. Machine learning 8, 3-4 (1992), 279–292. [43] Aaron Wilson, Alan Fern, and Prasad T adepalli. 2010. Bayesian p olicy search for multi-agent role discovery . In Tw enty-Fourth AAAI Conference on A rticial Intelligence . [44] Jiachen Y ang, Alireza Nakhaei, David Isele, Hongyuan Zha, and Kikuo Fujimura. 2018. CM3: Cooperative Multi-goal Multi-stage Multi-agent Reinforcement Learning. arXiv preprint arXiv:1809.05188 (2018). [45] Zhi Zhang, Jiachen Y ang, and Hongyuan Zha. 2019. Integrating indep endent and centralize d multi-agent reinforcement learning for trac signal network optimization. arXiv preprint arXiv:1909.10651 (2019). [46] Y unqi Zhao, Igor Borovikov , Ahmad Beirami, Jason Rupert, Caedmon Somers, Jesse Harder, Fernando de Mesentier Silva, John Kolen, Jervis Pinto, Reza Pourabolghasem, et al . 2019. Winning Isn’t Everything: Training Human-Like Agents for Playtesting and Game AI. arXiv preprint arXiv:1903.10545 (2019). [47] Y unqi Zhao, Igor Borovikov , Jason Rup ert, Caedmon Somers, and Ahmad Beirami. 2019. On Multi-Agent Learning in T eam Sports Games. arXiv preprint arXiv:1906.10124 (2019).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment