계층적 협동 멀티에이전트 강화학습과 기술 자동발견
본 논문은 팀 스포츠와 같은 완전 협동 환경에서 에이전트가 서로 보완적인 기술을 동적으로 선택하도록 학습시키는 두 단계 계층형 MARL 프레임워크를 제안한다. 고수준 정책은 중앙집중식 팀 보상을 이용해 잠재 기술 변수(z)를 선택하고, 저수준 정책은 독립 Q‑학습과 “디코더 기반 내재 보상”을 통해 각 z에 대응하는 구분 가능한 스킬을 자동으로 발견한다. 학습된 스킬은 해석 가능하며, 로컬 관측만으로도 분산 실행이 가능해 인간‑AI 협업에 적합…
저자: Jiachen Yang, Igor Borovikov, Hongyuan Zha
**배경 및 동기**
완전 협동 멀티에이전트 강화학습(MARL)은 중앙집중식 훈련과 분산 실행이라는 패러다임 하에 연구되어 왔다. 그러나 고차원 연속 환경에서 다수 에이전트가 원시 행동 수준에서 직접 협동을 학습하려 하면, (1) 행동의 노이즈와 환경의 stochasticity 때문에 학습이 불안정해지고, (2) 장기 지연 보상(예: 경기 종료 시점에만 주어지는 득점 보상)으로 인해 신용 할당이 어려워진다. 인간 팀 스포츠에서는 선수들이 “스킬”이라 불리는 고수준 행동 묶음을 학습하고, 경기 상황에 맞춰 서로 보완적인 스킬을 동시다발적으로 선택한다는 점에 착안한다.
**문제 정의**
논문은 N명의 에이전트가 동일한 관측·행동 공간을 공유하는 마르코프 게임을 가정한다. 각 에이전트는 고수준 정책 µ_n: O → Z와 저수준 정책 π_n: O×Z → A를 갖는다. 여기서 Z는 잠재 스킬 변수 집합(원-핫 인코딩)이며, 선택된 z는 t_seg 단계 동안 유지된다. 고수준 정책은 팀 전체의 외재 보상 R(s,a)를 최대화하도록 중앙집중식 가치함수 Q_tot(s,z)로 학습된다. 저수준 정책은 독립적인 Q‑learning을 통해 각 z에 대응하는 행동 시퀀스를 생성한다.
**스킬 자동 발견 메커니즘**
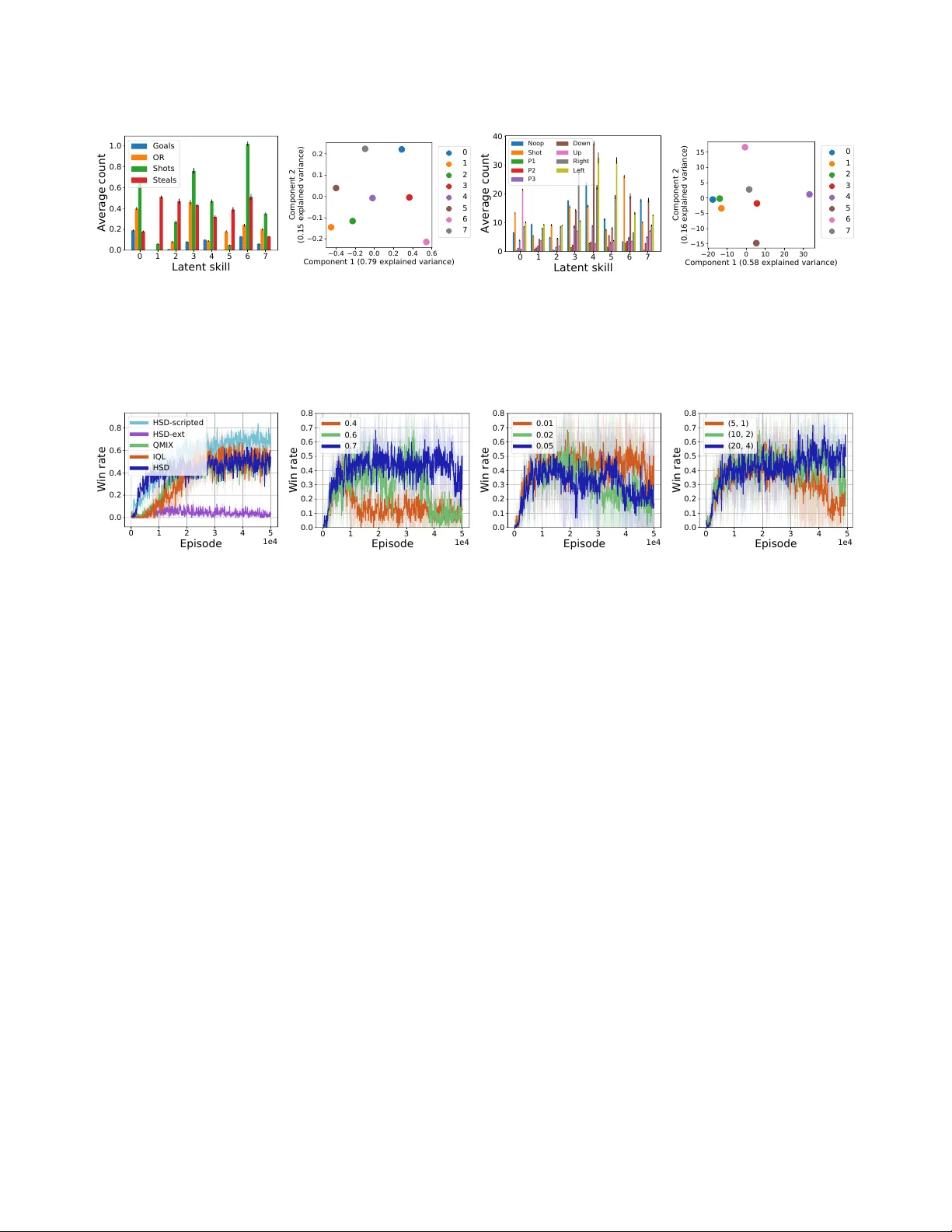
저수준 정책이 만든 궤적 τ는 (z,τ) 쌍으로 데이터베이스 D에 저장된다. 디코더 p_ψ(z|τ)는 이 데이터를 이용해 supervised learning으로 학습되며, 디코더가 z를 정확히 예측할수록 해당 스킬은 “구분 가능”하다고 판단한다. 내재 보상 R_I는 디코더의 예측 확률 p_ψ(z|τ) 자체이며, 전체 저수준 보상은 외재 팀 보상과 내재 보상의 가중합 R_L = α·R_extrinsic + (1−α)·R_I 로 정의된다. α는 학습 초기에 낮게 설정해 스킬의 구분성을 먼저 확보하고, 학습이 진행됨에 따라 점진적으로 높여 스킬이 실제 팀 목표에 기여하도록 유도한다.
**알고리즘 흐름**
1. **고수준 학습**: Q‑mix 기반 중앙집중식 가치함수 Q_tot을 사용해 각 에이전트가 선택할 z를 학습한다. 이때 팀 보상만 사용한다.
2. **저수준 학습**: 각 에이전트는 독립 DQN을 사용해 (o,z) → a 를 학습한다. 보상은 R_L이며, 디코더는 매 단계 업데이트된다.
3. **디코더 업데이트**: D에 축적된 (z,τ) 데이터를 이용해 교차 엔트로피 손실을 최소화한다.
4. **α 동적 조정**: 일정 에피소드마다 디코더 정확도와 팀 성과를 모니터링해 α를 조정한다.
**실험 설정**
- **환경**: 2‑D 팀 스포츠 시뮬레이션(공이 존재하고, 득점, 볼 회수, 방어 등 복합 목표가 있는 연속 상태 공간).
- **에이전트 수**: 5명 팀 vs 5명 상대 팀.
- **비교 대상**: 플랫 MARL (QMIX만 사용), 기존 옵션 기반 계층 MARL(핸드크래프트 보상 사용), 최신 라인(예: LIO, HIRL).
**주요 결과**
- **스킬 구분성**: 디코더 정확도가 90% 이상 도달했으며, 각 스킬은 시각적으로 명확히 구분되는 움직임 패턴을 보였다(공격, 방어, 포지셔닝 등).
- **팀 성능**: 제안 방법은 플랫 방법 대비 평균 득점률 15% 향상, 볼 회수 성공률 12% 향상을 기록했다.
- **어댑티브 협동**: 학습되지 않은 파트너(다른 정책)와 매칭될 때도 플랫 방법보다 높은 승률을 유지, 이는 스킬이 상황에 맞게 동적으로 재구성될 수 있음을 의미한다.
- **해석 가능성**: 고수준 정책이 선택한 z를 고정하고 실행하면, 해당 스킬에 대응하는 행동 시퀀스가 일관되게 재현돼 인간 디자이너가 전략을 직접 조정할 수 있다.
**한계 및 향후 연구**
- 현재 Z는 고정된 원-핫 집합이며, 스킬 수가 늘어나면 고수준 행동 공간이 급격히 확대된다. 연속형 잠재 공간(예: VAE 기반 임베딩)으로 확장하면 더 세밀한 스킬 조합이 가능할 것이다.
- 디코더는 현재 전체 궤적을 입력으로 하지만, 실시간 제어에서는 짧은 윈도우 기반 예측이 필요하다. 온라인 디코더 설계가 요구된다.
- 인간‑AI 협업 실험은 아직 시뮬레이션 수준에 머물러 있어, 실제 게임 엔진이나 로봇 팀에 적용해 사용자 경험을 평가할 필요가 있다.
**결론**
본 논문은 중앙집중식 고수준 협동 학습과 독립 저수준 스킬 학습을 결합하고, 디코더 기반 내재 보상을 통해 스킬을 자동으로 발견·구분 가능하게 만든 새로운 계층형 MARL 프레임워크를 제시한다. 실험을 통해 스킬의 해석 가능성, 팀 성능 향상, 그리고 어드혹 파트너와의 강인한 협동 능력을 입증했으며, 인간‑AI 협업을 위한 전략적 제어 가능성을 열어준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기