Refined WaveNet Vocoder for Variational Autoencoder Based Voice Conversion
This paper presents a refinement framework of WaveNet vocoders for variational autoencoder (VAE) based voice conversion (VC), which reduces the quality distortion caused by the mismatch between the training data and testing data. Conventional WaveNet…
Authors: Wen-Chin Huang, Yi-Chiao Wu, Hsin-Te Hwang
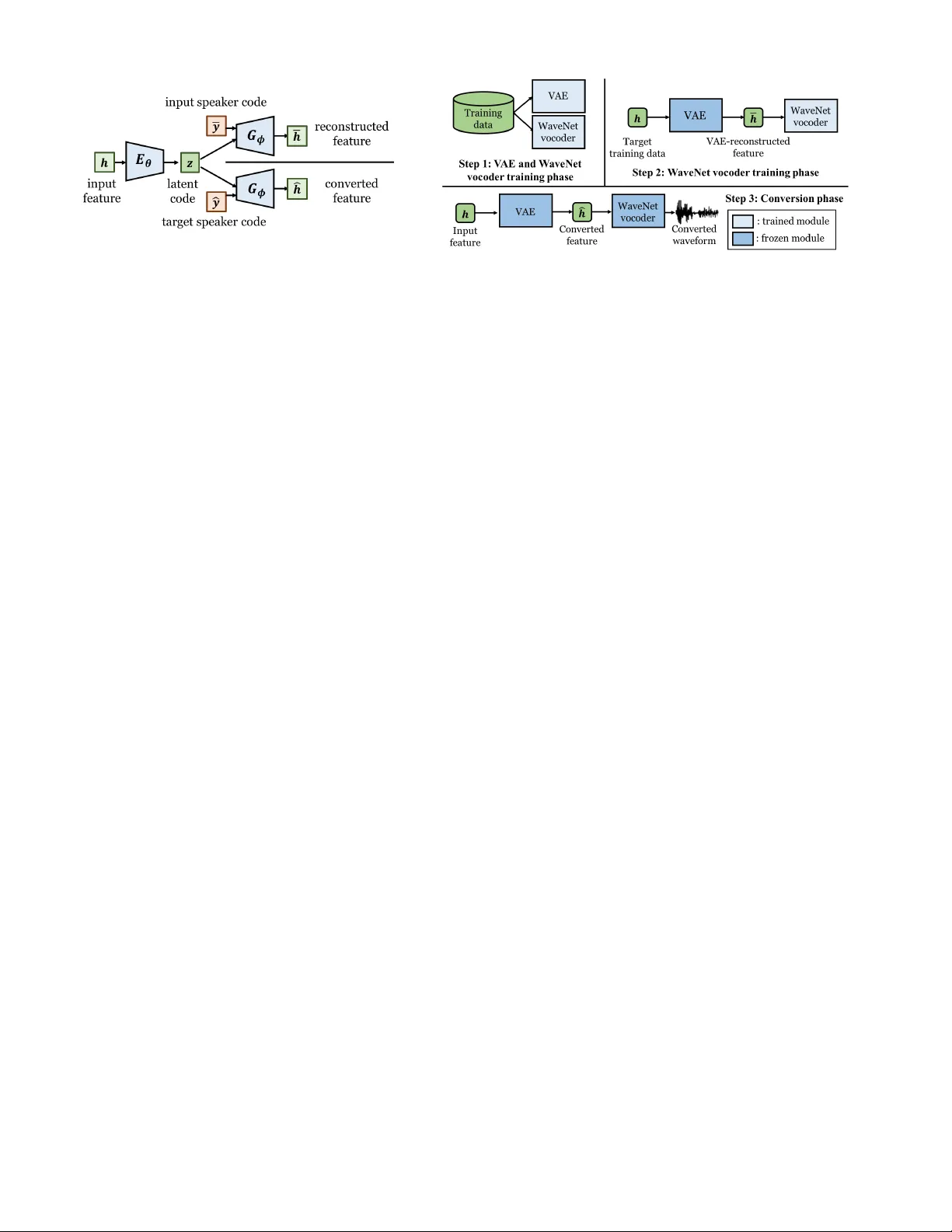
Refined W a v eNet V ocoder for V ariational Autoencoder Based V oice Con v ersion W en-Chin Huang ∗ , Y i-Chiao W u † , Hsin-T e Hwang ∗ , P atrick Lumban T obing † , T omoki Hayashi † , Kazuhiro K obayashi † , T omoki T oda † , Y u Tsao ∗ , Hsin-Min W ang ∗ ∗ Academia Sinica, T aiwan † Nagoya Uni versity , Japan Abstract —This paper presents a r efinement framework of W aveNet vocoders for variational autoencoder (V AE) based voice con version (VC), which reduces the quality distortion caused by the mismatch between the training data and testing data. Conv entional W a veNet vocoders are trained with natural acoustic features but conditioned on the con verted features in the con version stage for VC, and such a mismatch often causes significant quality and similarity degradation. In this work, we take advantage of the particular structure of V AEs to refine W aveNet vocoders with the self-reconstructed features generated by V AE, which are of similar characteristics with the conv erted features while having the same temporal structure with the target natural features. W e analyze these features and show that the self-reconstructed features ar e similar to the converted featur es. Objective and subjecti ve experimental results demonstrate the effectiveness of our proposed framework. Index T erms —voice con version, variational autoencoder , W aveNet vocoder , speaker adaptation I . I N T RO D U C T I O N V oice con version (VC) aims to con vert the speech from a source to that of a target without changing the linguistic content. While numerous approaches have been proposed [1]–[7], in this work we study variational autoencoder [8] based VC (V AE-VC) [9], where the conv ersion framework consists of an encoder-decoder pair . First, the source features are encoded into a latent content code by the encoder , and the decoder generates the con verted features by conditioning on the latent code and the target speak er code. The whole network is trained in an unsupervised manner , minimizing the reconstruction error and a Kullback-Leibler (KL)-div ergence loss, which regularizes the distribution of the latent variable. Because of the unsupervised learning nature of V AE, V AE-VC does not need parallel training data. The wav eform generation process plays an important role in a VC system. Conv entional VC frameworks employ para- metric vocoders as their synthesis module, which impose many overly simplified assumptions that discard the phase information and result in unnatural excitation signals, and thus cause a significant degradation in the quality of the con verted speech [10]–[12]. In recent years, the W av eNet vocoder [13], [14], built upon one of the most promising neural speech generation models, W av eNet [15], has been proposed. It is capable of reconstructing the phase and excitation information, and thus generates more natural sounding speech. In [14], it was confirmed that compared with the speaker independent (SI) W aveNet v ocoder, which is trained with a Fig. 1: A general mismatch between the training and con version features of the W aveNet vocoder , which is highlighted in the orange box. multi-speaker speech corpus, the speaker dependent (SD) vari- ant [13] is superior in terms of speech quality . Howe ver , it is impractical to collect a sufficient amount of data (usually more than 1 hour) required to build a target-dependent W aveNet vocoder in a VC framework. T o alleviate this problem, many researchers have applied a fine-tuning technique [16]–[21] and its effecti veness has been confirmed in [18]. Howe ver , the above mentioned fine-tuning technique suffers from the mismatch between the training and testing input features of the W av eNet vocoder , as shown in Fig. 1. The features used to train the W aveNet vocoder are extracted from either the source’ s or the target’ s natural speech, which we will refer to as the natural features, and are dif ferent from the con verted features generated by the con version model. One way to reduce this mismatch is to use the conv erted features to fine-tune the W aveNet vocoder , similar to [22]. Howe ver , this cannot be used directly in VC, since the time alignment between the con verted features and the tar get speech wa veform will be required, and an imperfect alignment will introduce an additional mismatch. T o generate alignment-free data, [23] first used intra-speaker con version, but the performance was limited since there was a gap between such intra-con verted features and the actual con verted features. Furthermore, [21] used a cyclic conv ersion model to ensure the self-predicted features were indeed similar to the con verted features. Although these methods seem to be promising in parallel VC, the use of such techniques in non- parallel VC has not been properly inv estigated. For instance, it remains unknown how to effecti vely apply such techniques Fig. 2: Illustration of the two types of spectral frames generated by feeding different speaker codes in the forward process of V AE-VC. Fig. 3: The proposed W av eNet vocoder fine-tuning framework using V AE-reconstructed features. The analysis module is omitted. to V AE-VC. In light of this, in this work, we propose a nov el W aveNet vocoder fine-tuning framew ork for V AE-VC. Specifically , the self-reconstructed features of the trained V AE network are used to fine-tune the W aveNet vocoder . Our contributions are: • The self-reconstructed features of V AE are suitable for fine-tuning. Since the forward processes of the V AE- VC are almost identical except that they are condi- tioned on different speaker codes, we hypothesize that the characteristics of the self-reconstructed features are similar to that of the con verted features. W e analyzed the properties of these features and verified this hypothesis with objectiv e measures. T o our knowledge, this is the first attempt to examine the ”suitableness” of the features used for fine-tuning. • The self-reconstructed features of V AE are innately time- alignment free, since the temporal structure of self- reconstructed and natural target features is identical. Therefore, we don’t need to add additional networks or losses to solve the alignment issue, as in [21], [23]. I I . R E L A T E D T E C H N I QU E S A. V AE-VC In V AE-VC [9], the conv ersion function is formulated as an encoder-decoder network. Specifically , giv en an observed (source or target) spectral frame h , a speaker -independent encoder E θ with parameter set θ encodes h into a latent code: z = E θ ( h ) . The (target) speaker code ˆ y is then concatenated with the latent code, and passed to a conditional decoder G φ with parameter set φ to generate the con verted features. Thus, the conv ersion function f of V AE-VC can be expressed as: ˆ h = f ( h ) = G φ ( z , ˆ y ) . Fig. 2 shows the two types of spectral frames used in training and con version. In the training phase, the forward pass is done by encoding h of an arbitrary speaker into a latent code z , and feeding it into the decoder along with the speaker code ¯ y to generate the reconstructed frame ¯ h , which we will refer to as the V AE-reconstructed feature. During training, there is no need for parallel training data. The model parameters can be obtained by maximizing the variational lower bound, L : L ( θ , φ ; h , y ) = L recon ( h , y ) + L lat ( h ) , (1) L recon ( h , y ) = E q θ ( z | h ) log p φ ( h | z , y ) , (2) L lat ( h ) = − D K L ( q θ ( z | h ) k p ( z )) , (3) where q θ ( z | h ) is the approximate posterior , p φ ( h | z , y ) is the data likelihood, and p ( z ) is the prior distribution of the latent space. L recon is simply a reconstruction term as in any vanilla autoencoder , whereas L lat regularizes the encoder to align the approximate posterior with the prior distribution. B. W aveNet vocoder W av eNet [15] is a deep autoregressi ve network, which generates high-fidelity speech waveforms sample-by-sample, using the following conditional probability equation: P ( X | h ) = N Y n =1 P ( x n | x n − r , . . . , x n − 1 , h ) , (4) where x n is the current sample point, r is the size of the recep- tiv e field, and h is the auxiliary feature vector . The W av eNet vocoder [13], [14] reconstructs time-domain wav eforms by conditioning on acoustic features, including spectral features, fundamental frequencies ( f 0 ) and aperiodicity signals (APs). A W aveNet vocoder is composed of several stacked residual blocks skip-connected to the final output, with each residual block containing a 2 × 1 dilated causal con volution layer , a gated activ ation function, and two 1 × 1 con volution layers. In short, giv en a data sequence pair ( h , x ) , the W aveNet vocoder is trained in a supervised fashion, learning to map the acoustic features h to the time-domain signals x . In recent years, fine-tuning a W aveNet vocoder to the target speaker has become a popular technique to improve speech quality when applying the W aveNet vocoder to VC [16]–[21]. Specifically , an initial SI W av eNet vocoder is first trained with a multi-speaker dataset. Then, the tar get speaker’ s data is used to fine-tune all or partial model parameters. Therefore, suitable fine-tuning data that matches the con verted features is the key to better speech quality . C. V AE-VC with W aveNet vocoder A combination of V AE-VC and W av eNet vocoder has been proposed in [19]. First, a V AE con version model is trained. A W av eNet vocoder is then constructed by training with natural features of a multi-speaker dataset first, followed by fine- tuning using the natural features of the target speaker . In the conv ersion phase, the V AE model first performs spectral Fig. 4: An illustration of the distances between the three types of features. Fig. 5: Density plot of the mel-cepstral distortion of the three distances. Fig. 6: Global variance values of the three types of features from speaker TF1. feature con version, and by conditioning on the con verted spectral features, source APs and transformed f 0 , the W aveNet vocoder generates the con verted speech wav eform. Here we once again point out that the W av eNet vocoder conditions on features of different characteristics in the training and con version phases, i.e. there is a mismatch between the input features in the training and con version phases. In the following section, we will introduce our proposed method for reducing this mismatch. I I I . P RO P O S E D M E T H O D F O R W A V E N E T VO C O D E R FI N E - T U N I N G I N V A E - V C Using the conv erted features to fine-tune the W aveNet vocoder is an effecti ve approach to reduce the mismatch between training and con version in VC. Ho wev er, this is only possible when a parallel corpus is av ailable, which conflicts with the capability of V AE-VC under non-parallel conditions. Even with parallel data, since con ventional VC models per- form conv ersion frame-by-frame, the con verted feature and the source speech have the same temporal structure, which is different from that of the target. As a result, we need an elegant fine-tuning method for a non-parallel VC method like V AE-VC that solves both the time-alignment and mismatch issues. W e propose to fine-tune W aveNet vocoders with V AE- reconstructed features by taking advantage of the particular network structure of V AEs, as depicted in Fig. 3. Specifically , a V AE model is first trained with the whole training corpus. Then, the V AE-reconstructed features ¯ h could be obtained from the target speaker’ s training data through the reconstruc- tion process described in Section II-A. W e can thereafter use data pairs ( ¯ h , x ) to fine-tune the SI W av eNet v ocoder instead of using the original ( h , x ) as described in Section II-B, where h and x denote the natural target feature and the target wa veform, respectiv ely . There are two main adv antages of using the V AE- reconstructed features to fine-tune the SI W aveNet vocoder . First, since h and ¯ h have the same temporal structure, time-alignment is no longer required. More importantly , the mismatch between the V AE-reconstructed features and the con verted features ˆ h is small. Recall that in V AE-VC, ¯ h and ˆ h can be obtained by feeding the input speaker code ¯ y and the target speaker code ˆ y , respecti vely . Since ¯ h and ˆ h only differ in speaker codes, we hypothesize that they share similar properties. Experimental results confirm the abov e hypothesis, as we will show in Section IV -B. I V . E X P E R I M E N T A L E V A L U A T I O N S A. Experimental settings All experiments were conducted using the V oice Con ver - sion Challenge 2018 (VCC2018) corpus [24], which included recordings of 12 professional US English speakers with a sampling rate of 22050 Hz and a sample resolution of 16 bits. The training set consisted of 81 utterances and the testing set consisted of 35 utterances of each speaker . The total number of training utterances was 972 and the training data length was roughly 54 minutes. The WORLD vocoder [12] was adopted to extract acoustic features including 513-dimensional spectral en velopes (SPs), 513-dimensional APs and f 0 . The SPs were normalized to unit-sum, and the normalizing factor was taken out and thus not modified. 35-dimensional mel- cepstral coefficients (MCCs) were extracted from the SPs. For the spectral con version model, we used the CD V AE variant [25] as it was capable of modeling MCCs while the original V AE [9] failed to do so [25]. The CD V AE model was trained with the whole training data of the 12 speakers from VCC2018, with the detailed network architecture and training hyper-parameters consistent with [25]. For the W aveNet vocoder , we followed the of ficial im- plementation 1 with the default settings, including the noise shaping technique [26]. All training data of VCC2018 were used to train the multi-speaker W av eNet vocoder . Although some works used discriminate speaker embeddings for train- ing, we did not adopt such technique since simply mixing all speakers ga ve better performance as reported in [14]. The default 200000 iterations of model training led to approximate 2.0 training loss (in terms of negati ve log-likelihood). Fine- tuning of the W av eNet vocoder was performed by updating the whole network until the training loss reached around 1.0. At con version, the input features included the conv erted MCCs from the V AE con version model followed by energy compensation, the linear mean-variance transformed log- f 0 as well as the unmodified source APs. 1 https://github .com/kan-bayashi/PytorchW av eNetV ocoder T ABLE I: The compared methods. GV stands for the global variance postfilter [27]. Name V ocoder GV T raining feature Adapting feature Baseline 1 WORLD No None None Baseline 2 WORLD Y es None None Baseline 3 W aveNet No Natural Natural Baseline 4 W aveNet Y es Natural Natural Proposed 1 W aveNet No Natural V AE-r econstructed Proposed 2 W aveNet Y es Natural V AE-r econstructed +GV Upper bound W av eNet – Natural Natural B. Analysis of Mismatch In order to prov e that the V AE-reconstructed features are more similar to the con verted features than the natural target features, we analyzed their spectral properties based on the mean mel-cepstral distortion (MCD) and global variance (GV) measurements on the training set. First, we trained a V AE and obtained the three types of features using the training data of the VCC2018 corpus. Then, we calculated the distances (Dist. 1-3) by calculating the mean MCD of each sentence and then comparing the distributions, as illustrated in Fig. 4. Fig. 5 shows the three distances calculated from con version pairs of a subset of speakers (SF1, SM1 to TF1, TF2, TM1, TM2). First, we observe that Dist. 2 is rather large, showing that the natural features are somehow distorted through the imperfect reconstruction process of V AE. W e further observe that Dist. 3 is smaller than Dist. 1, demonstrating that con- ventional approaches suf fer from the mismatch gi ven by Dist. 1, and our proposed method can alleviate the issue because Dist. 3 is small. Note that Dist. 1 and Dist. 3 are affected by time alignment while Dist. 2 is not, so the former have lar ger variation than the latter . Fig. 6 illustrates the GVs of the three types of features. The GVs of the natural features are higher than that of the other two types of features, since the natural features contain the most spectral details and structures while the V AE-reconstructed and con verted features suffer from the ov er-smoothing effect. These results imply that the V AE-reconstructed features are more suitable to fine-tune the W av eNet vocoder as they well simulate the properties of the con verted features. C. Evaluation of the pr oposed methods W e conducted objective and subjecti ve e valuations of se ven methods, as sho wn in T able I. The baseline methods (Baseline 1-4) are the V AE-VC systems with the WORLD and the fine-tuned W av eNet vocoders using the natural features [19], [25]. The proposed methods (Proposed 1-2) are the V AE- VC systems with the W aveNet vocoder fine-tuned with the V AE-reconstructed and GV post-filtered V AE-reconstructed features, respectively . The upper bound system is the W aveNet vocoder fine-tuned with the target natural features, i.e. without the con version process. Note that the GV column indicates whether the GV post-filter is applied to the con verted spectral features before sending them into the W av eNet vocoder . (a) Global v ariance values of mel-cepstrum coef ficients extracted from speech conv erted to speaker TF1 and the natural TF1 speech. (b) Mean opinion score on naturalness over all speaker pairs. Error bars indicate the 95% confidence interv als. (c) Result of speaker similarity scores, which were aggregated from “same sure” and “same not-sure” decisions. Error bars indicate the 95% confidence interv als. Fig. 7: Results of objectiv e and and subjectiv e ev aluations. Fig. 7(a) sho ws the GV over the MCCs extracted from the con verted voices of the compared methods. In the VC litera- ture, the GV v alues reflect perceptual quality and intelligibility , and we generally seek for a GV curve close to that of the target. In light of this, the following are some observations from the graph: • Baselines 2 and 4 had GV very close to that of the natural target, compared to Baselines 1 and 3, which is consistent with the results of combining the GV post- filtering method with the W av eNet vocoder as in [23]. • The GV of Baseline 3 was far from that of the natural tar- get compared to that of Baseline 4, possibly because the post-filtered con verted features are closer to the natural features used to train/fine-tune the W av eNet vocoder . • Proposed 1 had higher GV values than Baseline 3. This indicates that the W aveNet vocoder acts like a post-filter that compensates the over -smoothed con verted features in our proposed framew ork. • Nonetheless, the GV values of Proposed 1 and Proposed 2 were nearly identical and still lower than that of the nat- ural tar get. W e speculate that since we penalize W aveNet by training it using distorted features, degradation in speech quality might still be introduced. Subjectiv e tests were conducted to ev aluate the naturalness and similarity . A 5-scaled mean opinion score (MOS) test was performed to assess the naturalness. For the speaker similarity , each listener was giv en a pair of audio stimuli, consisting of a natural speech of a target speaker and a con verted speech, and asked to judge whether they were produced by the same speaker , with a confidence decision, i.e., sure and not sure. A subset of speakers (SF1, SM1, SF3, SM3, TF1, TM1, TF2, TM2) were chosen. T en subjects were recruited. Fig. 7(b) shows that our proposed methods outperformed all baseline systems, e ven though the proposed methods had smaller GV values compared with Baselines 2 and 4. It could be inferred that the proposed methods not only alleviated the ov er-smoothing problem of the con verted features but also improv ed other aspects of the generated speech, which might correspond to the naturalness of speech. Furthermore, Fig. 7(c) indicates that our proposed methods also improved the speaker similarity of the generated speech. V . C O N C L U S I O N In this work, we hav e proposed a refinement framework of V AE-VC with the W av eNet vocoder . W e utilize the self- reconstruction procedure in the V AE-VC framew ork to fine- tune the W aveNet vocoder to alleviate the performance degra- dation issue caused by the mismatch between the training phase and con version phase of the W aveNet vocoder . Eval- uation results sho w the effecti veness of the proposed method in terms of naturalness and speaker similarity . In the future, we plan to inv estigate the use of V AE-reconstructed features in the multi-speaker training stage of the W aveNet v ocoder to further improve the robustness. Speech samples are av ailable at https://unilight.github .io/V AE-WNV -VC-Demo/ V I . A C K N O W L E D G E M E N T This work was partly supported by JST , PRESTO Grant Number JPMJPR1657 and JSPS KAKENHI Grant Number JP17H06101, as well as the MOST -T aiwan Grants 105-2221- E001-012-MY3 and 107-2221-E-001-008-MY3. R E F E R E N C E S [1] Y . Stylianou, O. Cappe, and E. Moulines, “Continuous probabilistic transform for voice conversion, ” IEEE Tr ansactions on Speech and Audio Pr ocessing , vol. 6, no. 2, pp. 131–142, Mar 1998. [2] T . T oda, A. W . Black, and K. T okuda, “V oice conv ersion based on maximum-likelihood estimation of spectral parameter trajectory , ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 15, no. 8, pp. 2222–2235, Nov 2007. [3] S. Desai, A. W . Black, B. Y egnanarayana, and K. Prahallad, “Spectral mapping using artificial neural networks for voice con version, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 18, no. 5, pp. 954–964, July 2010. [4] L. H. Chen, Z. H. Ling, L. J. Liu, and L. R. Dai, “V oice con version using deep neural networks with layer -wise generativ e training, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 22, no. 12, pp. 1859–1872, Dec 2014. [5] R. T akashima, T . T akiguchi, and Y . Ariki, “Exemplar -based v oice con version in noisy en vironment, ” in Proc. SLT , 2012, pp. 313–317. [6] Z. W u, T . V irtanen, E. S. Chng, and H. Li, “Exemplar-based sparse representation with residual compensation for voice con version, ” IEEE/ACM T ransactions on A udio, Speech, and Languag e Pr ocessing , vol. 22, no. 10, pp. 1506–1521, Oct 2014. [7] Y .-C. W u, H.-T . Hwang, C.-C. Hsu, Y . Tsao, and H.-M. W ang, “Locally linear embedding for exemplar -based spectral con version, ” in Proc. Interspeech , 2016, pp. 1652–1656. [8] D. P . Kingma and Max W ., “ Auto-encoding variational bayes., ” CoRR , vol. abs/1312.6114, 2013. [9] C.-C. Hsu, H.-T . Hwang, Y .-C. W u, Y . Tsao, and H.-M. W ang, “V oice con version from non-parallel corpora using variational auto-encoder, ” in Pr oc. APISP A ASC , 2016, pp. 1–6. [10] B. S. Atal and Suzanne L. Hanauer , “Speech analysis and synthesis by linear prediction of the speech wav e, ” The Journal of the Acoustical Society of America , vol. 50, no. 2B, pp. 637–655, 1971. [11] H. Kawahara, I. Masuda-Katsuse, and A. de Cheveign, “Restructuring speech representations using a pitch-adapti ve time-frequency smoothing and an instantaneous-frequency-based f0 extraction: Possible role of a repetitiv e structure in sounds, ” Speech Communication , vol. 27, no. 3, pp. 187–207, 1999. [12] M. Morise, F . Y okomori, and K. Ozawa, “WORLD: A V ocoder-Based High-Quality Speech Synthesis System for Real-Time Applications, ” IEICE T ransactions on Information and Systems , vol. 99, pp. 1877– 1884, 2016. [13] A. T amamori, T . Hayashi, K. K obayashi, K. T akeda, and T . T oda, “Speaker-dependent W av eNet vocoder , ” in Pr oc. Interspeech , 2017, pp. 1118–1122. [14] T . Hayashi, A. T amamori, K. K obayashi, K. T akeda, and T . T oda, “ An in vestigation of multi-speaker training for W av eNet vocoder , ” in IEEE Automatic Speech Recognition and Understanding W orkshop (ASR U) , Dec 2017, pp. 712–718. [15] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. V inyals, A. Graves, N. Kalchbrenner , A. Senior, and K. Kavukcuoglu, “W aveNet: A generativ e model for raw audio, ” arXiv pr eprint arXiv:1609.03499 , 2016. [16] P . L. T obing, Y . W u, T . Hayashi, K. Kobayashi, and T . T oda, “NU voice con version system for the voice con version challenge 2018, ” in Pr oc. Odyssey , 2018, pp. 219–226. [17] Y . Wu, P . L. T obing, T . Hayashi, K. K obayashi, and T . T oda, “The NU non-parallel voice conversion system for the voice conversion challenge 2018, ” in Proc. Odysse y , 2018, pp. 211–218. [18] B. Sisman, M. Zhang, and H. Li, “ A voice con version framework with tandem feature sparse representation and speaker-adapted W av eNet vocoder , ” in Proc. Interspeech , 2018, pp. 1978–1982. [19] W .-C. Huang, C.-C. Lo, H.-T . Hwang, Y . Tsao, and H.-M. W ang, “W aveNet v ocoder and its applications in voice con version, ” in Pr oc. The 30th ROCLING Confer ence on Computational Linguistics and Speech Pr ocessing (ROCLING) , Oct 2018. [20] L.-J. Liu, Z.-H. Ling, Y . Jiang, M. Zhou, and L.-R. Dai, “W aveNet vocoder with limited training data for voice conv ersion, ” in Proc. Interspeech , 2018, pp. 1983–1987. [21] P . L. T obing, Y . W u, T . Hayashi, K. Kobayashi, and T . T oda, “V oice con version with cyclic recurrent neural network and fine-tuned W av eNet vocoder , ” in ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , May 2019, pp. 6815–6819. [22] J. Shen, R. Pang, R. J. W eiss, M Schuster, N. Jaitly , Z. Y ang, Z. Chen, Y . Zhang, Y . W ang, Rj Skerrv-Ryan, et al., “Natural TTS synthesis by conditioning W av eNet on mel spectrogram predictions, ” in 2018 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 4779–4783. [23] K. Kobayashi, T . Hayashi, A. T amamori, and T . T oda, “Statistical voice conversion with W aveNet-based wa veform generation, ” in Pr oc. Interspeech , 2017, pp. 1138–1142. [24] J. Lorenzo-Trueba, J. Y amagishi, T . T oda, D. Saito, F . V illavicencio, T . Kinnunen, and Z. Ling, “The voice conversion challenge 2018: Promoting de velopment of parallel and nonparallel methods, ” in Pr oc. Odyssey , 2018, pp. 195–202. [25] W .-C. Huang, H.-T . Hwang, Y .-H. Peng, Y . Tsao, and H.-M. W ang, “V oice conversion based on cross-domain features using variational auto encoders, ” in Proc. ISCSLP , 2018. [26] K. T achibana, T . T oda, Y . Shiga, and H. Kawai, “ An inv estigation of noise shaping with perceptual weighting for W aveNet-based speech generation, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , April 2018, pp. 5664–5668. [27] H. Sil ´ en, E. Helander , J. Nurminen, and M. Gabbouj, “W ays to implement global variance in statistical speech synthesis, ” in Pr oc. Interspeech , 2012, pp. 1436–1439.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment