VAE 기반 음성 변환을 위한 WaveNet 보코더 정밀화
본 논문은 VAE 기반 비병렬 음성 변환 시스템에서 발생하는 학습‑추론 특징 불일치를 완화하기 위해, VAE가 자체 재구성한 스펙트럼 특성을 이용해 WaveNet 보코더를 미세조정하는 방법을 제안한다. 실험 결과, 제안 방식이 기존 WORLD 및 기존 WaveNet 기반 베이스라인보다 자연스러움과 화자 유사도에서 우수함을 확인하였다.
저자: Wen-Chin Huang, Yi-Chiao Wu, Hsin-Te Hwang
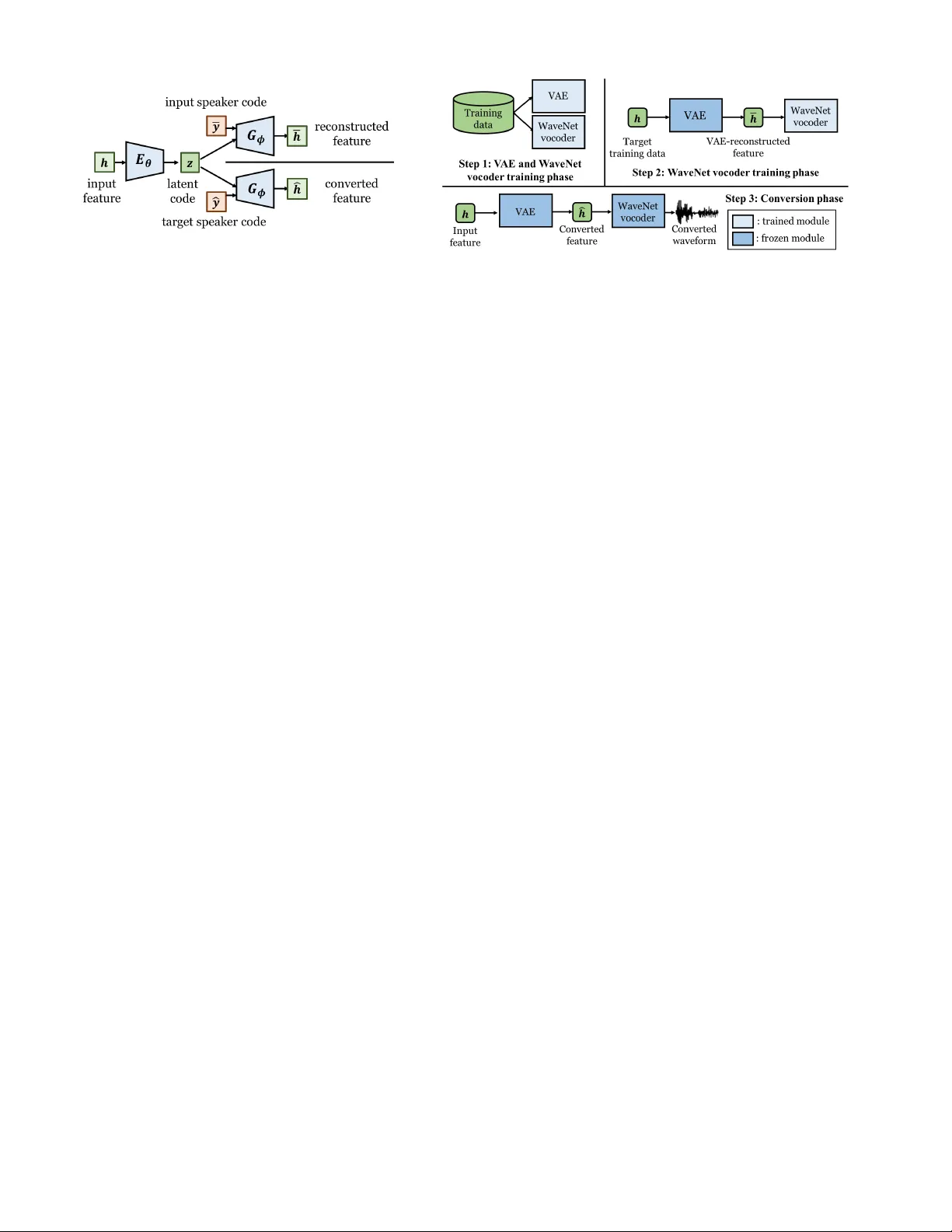
본 논문은 비병렬 음성 변환(Voice Conversion, VC) 시스템에서 널리 사용되는 VAE(Variational AutoEncoder) 기반 모델과 WaveNet 보코더 사이에 존재하는 특징 불일치 문제를 해결하기 위한 새로운 정밀화(framework) 방식을 제안한다. 기존의 WaveNet 보코더는 자연 음성에서 추출한 스펙트럼, 기본 주파수(F0), 비주기성(AP) 등과 같은 음향 특성을 입력으로 학습한다. 그러나 변환 단계에서는 VAE가 생성한 변환 스펙트럼을 입력으로 사용하게 되며, 이때 학습 시 사용된 자연 특성과 변환 시 사용되는 특성 사이에 통계적 차이와 시간 정렬 차이가 발생한다. 이러한 불일치는 변환된 음성의 자연스러움과 화자 유사도에 큰 악영향을 미친다.
저자들은 VAE의 구조적 특성을 활용해 이 문제를 근본적으로 해결하고자 한다. VAE는 인코더‑디코더 형태로, 입력 스펙트럼을 잠재 코드(z)로 압축한 뒤, 화자 코드를 결합해 디코더가 스펙트럼을 재구성한다. 동일한 입력에 대해 서로 다른 화자 코드를 사용하면 (1) 입력 화자 코드를 사용한 경우의 재구성 스펙트럼(¯h)과 (2) 목표 화자 코드를 사용한 경우의 변환 스펙트럼(ĥ)이 생성된다. 두 스펙트럼은 시간 축이 동일하고, 차이는 오직 화자 코드에만 존재한다는 점이 핵심이다.
이 가정을 검증하기 위해 저자들은 VCC2018 데이터셋(12명, 총 54분)에서 CD‑VAE 모델을 학습하고, 세 종류의 스펙트럼(자연 h, 재구성 ¯h, 변환 ĥ)을 추출하였다. 이후 MCD(Mean Mel‑Cepstral Distortion)와 GV(Global Variance) 지표를 이용해 거리(Dist. 1~3)를 계산하였다. 결과는 (i) 자연 특성과 변환 특성 사이의 거리(Dist. 1)가 가장 크고, (ii) 재구성 특성과 변환 특성 사이의 거리(Dist. 3)가 현저히 작으며, (iii) 재구성 특성은 시간 정렬이 필요 없고, 자연 특성보다 GV가 낮아 과‑스무딩 현상이 존재한다는 것을 보여준다. 즉, 재구성 특성은 변환 특성과 통계적으로 매우 유사하면서도 시간 구조는 목표 화자와 일치한다는 점에서 보코더 미세조정에 최적의 후보가 된다.
실험에서는 다중 화자 WaveNet 보코더를 사전 학습한 뒤, 두 가지 미세조정 방식을 비교하였다. Baseline 1‑4는 기존 WORLD 보코더와 자연 특성을 사용한 WaveNet 보코더(미세조정 여부 포함)이며, Proposed 1은 재구성 특성만을 사용해 전체 WaveNet을 미세조정한 경우, Proposed 2는 여기에 GV 포스트필터를 적용한 경우이다. Upper Bound는 목표 화자 자연 특성으로 직접 미세조정한 최상의 성능을 의미한다.
객관적 평가는 GV 곡선과 MCD를 통해 수행했으며, 주관적 평가는 5점 MOS와 화자 유사도 테스트(확신도 포함)로 진행되었다. 결과는 다음과 같다. (1) Proposed 1·2는 모든 Baseline보다 높은 MOS 점수를 기록했으며, 특히 자연스러움에서 Upper Bound에 근접했다. (2) 화자 유사도에서도 제안 방법이 가장 높은 점수를 얻었다. (3) GV 측면에서는 Baseline 2·4가 목표와 가장 가까웠지만, Proposed 1·2는 GV가 다소 낮음에도 불구하고 보코더 자체가 포스트필터 역할을 수행해 품질을 보완했다.
본 연구의 주요 기여는 세 가지이다. 첫째, VAE 재구성 특성이 변환 특성과 거의 동일한 통계적 특성을 가진다는 실증적 증명을 제공하였다. 둘째, 시간 정렬이 필요 없는 간단하고 효율적인 WaveNet 보코더 미세조정 프레임워크를 제시하였다. 셋째, 비병렬 VAE‑VC 환경에서도 보코더‑변환 모델 간 불일치를 효과적으로 감소시켜 음질과 화자 유사도를 동시에 향상시켰다.
향후 연구 방향으로는 재구성 특성의 품질을 더욱 향상시키기 위한 VAE 구조 개선(예: 더 깊은 네트워크, 정규화 기법)과, HiFi‑GAN, WaveGlow 등 다른 최신 신경 보코더와의 결합 가능성을 탐색하는 것이 제시된다. 또한, 다중 화자 상황에서 화자 임베딩을 활용한 보다 정교한 미세조정 전략도 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기