The Airbus Air Traffic Control speech recognition 2018 challenge: towards ATC automatic transcription and call sign detection
In this paper, we describe the outcomes of the challenge organized and run by Airbus and partners in 2018. The challenge consisted of two tasks applied to Air Traffic Control (ATC) speech in English: 1) automatic speech-to-text transcription, 2) call…
Authors: Thomas Pellegrini, Jer^ome Farinas, Estelle Delpech
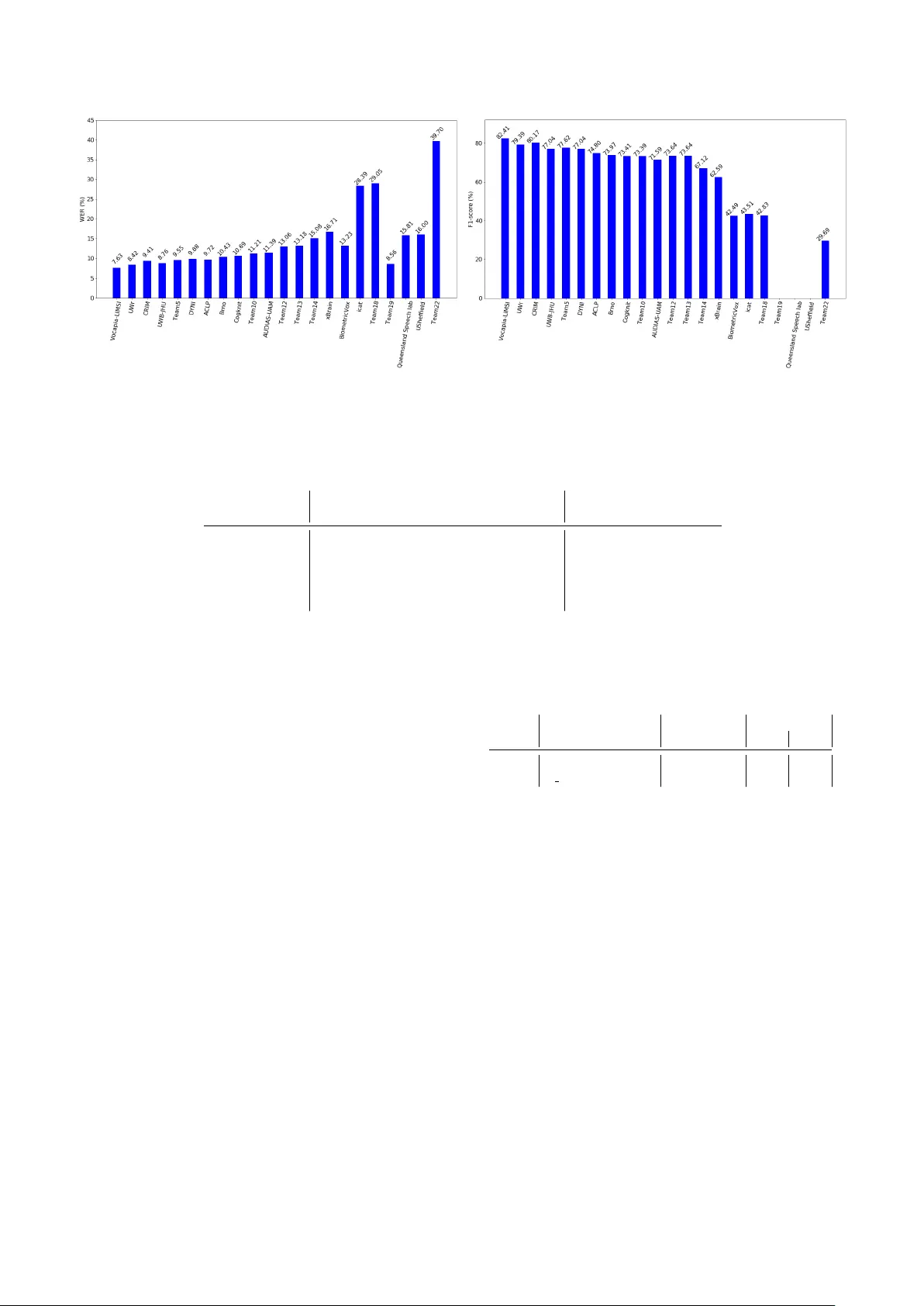
The Airb us Air T raffic Contr ol speech recognition 2018 challenge: towards A TC automatic transcription and call sign detection Thomas P elle grini 1 , J ´ er ˆ ome F arinas 1 , Estelle Delpech 2 , F ranc ¸ ois Lancelot 2 1 IRIT , Univ ersit ´ e Paul Sabatier , CNRS, T oulouse, France 2 Airbus, T oulouse, France { thomas.pellegrini,jerome.farinas } @irit.fr { estelle.e.delpech,francois.lancelot } @airbus.com Abstract In this paper , we describe the outcomes of the challenge orga- nized and run by Airbus and partners in 2018 on Air T raffic Control (A TC) speech recognition. The challenge consisted of two tasks applied to English A TC speech: 1) automatic speech- to-text transcription, 2) call sign detection (CSD). The regis- tered participants were pro vided with 40 hours of speech along with manual transcriptions. T wenty-two teams submitted pre- dictions on a fi ve hour e valuation set. A TC speech processing is challenging for several reasons: high speech rate, foreign- accented speech with a great diversity of accents, noisy com- munication channels. The best ranked team achieved a 7.62% W ord Error Rate and a 82.41% CSD F1-score. T ranscribing pilots’ speech was found to be twice as harder as controllers’ speech. Remaining issues towards solving A TC ASR are also discussed in the paper . Index T erms : speech recognition, air traffic control, special- ized language 1. Introduction The recent adv ances in Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU) technologies hav e opened the way to potential applications in the field of Air T raf- fic Control (A TC). On the controllers’ side, it is e xpected that these technolo- gies will provide an alternative modality for controllers. As a matter of fact, controllers have to keep track of all the clear- ances they emit, this is now adays made either by mouse input or by hand – which generates a high workload for controllers. The ongoing research project MALORCA 1 , for instance, aims at improving ASR models for providing assistance at dif ferent controller working positions. On the pilots’ side, ASR of A TC messages could also help decreasing pilots’ cognitiv e workload. Indeed, pilots have to perform se v eral cogniti ve tasks to handle spoken communica- tions with the air traffic controllers: • constantly listening to the VHF (V ery High Frequency) radio in case their call sign (i.e. their aircraft’ s identifier) is called; • understanding the controller message, even if pro- nounced with non-nativ e accent and/or in noisy condi- tions; • remembering complex and lengthy messages. In short, industrial stakeholders consider today that ASR and NLU technologies could help decrease operators’ work- 1 http://www.malorca- project.de/ load, both on pilots and on controllers’ sides. A first step to- wards cogniti ve assistance in A TC-related tasks could be a sys- tem able to (1) provide a reliable transcription of an A TC mes- sage; and (2) identify automatically the call sign of the recipient aircraft. Although significant progress has been made recently in the field of ASR — see, for example, the work of [1] and [2] who have both claimed to ha ve reached human parity in the switchboard corpus [3] — A TC communications still of fer chal- lenges to the ASR community; in particular because it combines sev eral issues in speech recognition: accented speech, code- switching, bad audio quality , noisy en vironment, high speech rate and domain-specific language associated with a lack of vo- luminous datasets [4]. The Airb us Air T raffic Control Speech Recognition 2018 challenge was intended to provide the re- search community with an opportunity to address the specific issues of A TC speech recognition. This paper is an attempt to pro vide an overview on the challenge outcomes. Section 2 presents the specificity of A TC speech as well as existing A TC speech corpora; section 3 de- scribes the tasks, dataset and e valuation metrics used in the challenge; section 4 briefly describes the best performing sys- tems and analyses the results of the challenge. Perspectiv es are discussed in section 5. 2. Specificity of A TC speech and existing A TC speech corpora A TC communications being very specific, voluminous generic datasets like the SWITCHBO ARD corpus [3] cannot be used to build an A TC speech recognition system. T able 1 provides a comparison of A TC speech vs. SWITCHBOARD speech. A TC speech provides man y challenges to automatic speech recogni- tion: audio quality is bad (VHF), the language is English b ut pronounced by non-nativ e speakers, speech rate is higher than in CTS [5] and there is also a lot of code switching. The only advantage of A TC compared to CTS is that the v ocabulary is limited to the International Civil A viation Organisation (ICA O) phraseology [6]. Sev eral A TC datasets ha ve been collected in the past. Un- fortunately most of them are either una v ailable, lack challeng- ing features of A TC or lack proper annotation. On top of this, it was required that at least a small portion of the dataset had nev er been disclosed so that it could be used for e valuation. The HIWIRE database [7] contains military A TC-related voice commands uttered by non-nativ e speakers and recorded in artificial conditions. The nnMT A C corpus [8] contains 24h of real-life, non-nativ e military A TC messages. Unfortunately , it is T able 1: CTS speech (SWITCHBO ARD) vs. A TC speech. SWITCHBO ARD speech A TC speech intelligibility good (phone quality) bad (VHF quality + noise) accents US English div erse & non-nati ve lexicon & syntax oral syntax, ev eryday topics limited to ICA O phraseology and related speech rate standard high other - code switching, possible Lombard effect not a vailable outside of N A TO 2 groups and af filiates. Similarly , the V OCALISE dataset [9] and the corpus of [10] (respectiv ely 150h and 22h of real-life French-accented ci vil A TC communi- cations) are not publicly av ailable. A TCOSIM [11] is a freely av ailable resource composed of realistic simulated A TC com- munications. Its limitations are its size (11h) and the fact that it lacks real-life features. The NIST Air Traf fic Control Corpus [12] is composed of 70h of real-life A TC from 3 different US airports and it is commercially available through the Linguistic Data Consortium (LDC). Unfortunately , it is mainly composed of native English and the call signs hav e not been annotated. The corpus collected by [13] is freely av ailable and contains real-life non-nati ve A TC speech. It is though quite small (20h) and does not contain call sign annotations. 3. Challenge description 3.1. T wo tasks: ASR and call sign detection (CSD) The Airbus A TC challenge consisted in tackling two tasks: 1) automatic speech-to-text transcription from authentic record- ings in accented English, 2) call sign detection (CSD). A viation call signs (CS) are communication call signs as- signed as unique identifiers to aircraft. They are expected to adhere to the follo wing pre-defined format: an airline code fol- lowed by three to fiv e numbers and zero to two letters. For instance, ”ENA C School six seven no vember” is a call sign in which EN A C school is a company name follo wed by two num- bers (six and seven) and ”nov ember” stands for the ’n’ character in the aviation alphabet. One dif ficulty lies in the use of short- ened spoken CS when there is no ambiguity . 3.2. Speech material The dataset used for running the challenge is a subset of the transcribed A TC speech corpus collected by Airbus [4]. This corpus contains speech signals at 16 kHz sampling rate and 16 bits per sample. All the specific features of A TC mentioned abov e are included in the corpus: non-nati ve speech, bad au- dio quality , code-switching, high speech rate, etc. On top of this, call signs contained in the audio hav e been tagged, which 2 North Atlantic T reaty Organization T able 2: Number of speech utterances and average duration within par entheses accor ding to the speech pr ogram (A T : ATIS, AP: Appr oac h, TO: T ower). A TIS AP TO train 843 (27.6 s) 20227 (4.5 s) 6975 (4.3 s) dev 102 (31.1 s) 2484 (4.3 s) 920 (4.2 s) test 102 (30.4 s) 2600 (4.5 s) 893 (4.4 s) allowed the challenge organizers to propose a ”call sign detec- tion” task. Although the corpus is not publicly av ailable, a sub- set of it was made av ailable to the challengers, for challenge use only . Half of the whole corpus, totalling 50 hours of manually transcribed speech, was used. Utterances were isolated, ran- domly selected and shuffled. All the meta-information (speaker accent, role, timestamps, category of control) were removed. The corpus was then split into three dif ferent subsets: 40h of speech together with transcriptions and call sign tags for train- ing, 5h of speech recordings for de velopment (leaderboard) and 5h for final e valuation, were provided to the participants at dif- ferent moments during the challenge. The participants did not hav e access to the ground-truth of the development and ev al subsets. They could make submissions to a leaderboard to get their scores on the dev subset. Several criteria were consid- ered to split the data into subsets that share similar character - istics (percentages given in speech duration): 1) speaker sex (female: 25%, male: 75%), 2) speaker job — A TIS (Airline T rav el Information System, mostly weather forecasts, 3%), pi- lots (54%) and controllers (43%) —, the ”program” — A TIS (3%), approach (72%), to wer (25%). T able 2 sho ws the number of utterances according to the program and the a verage mean duration of the utterances. A TIS is characterized by utterances of about 30 s in av erage longer than AP and TO with 4.5 second utterances in av erage. Links to the other av ailable A TC datasets ([11, 12, 13]) were given to the challengers so that they could use them as additional training data. Some participants did try to use exter- nal data with no gains or e ven with performance drops. 3.3. Evaluation metrics Evaluation was performed on both the ASR and CSD tasks. ASR was e valuated with W ord Error Rate (WER). Before com- parison, hypothesis and reference texts were set to lo wer case. These are compared through dynamic programming with equal weights for deletions, insertions and substitutions. For CSD, F- measure ( F 1 or F1-score) was used. A score S i of a submission i was defined to combine WER and F1 as the harmonic mean of the normalized pseudo-accuracy ( pAC C i norm ) and the nor- malized F 1 score ( F 1 i norm ): S i = 2 × pAC C i norm × F 1 i norm pAC C i norm + F 1 i norm where pAC C i = 1 − min (1 , WER i ) v : submissions’ scores vector v i norm = v i − min ( v ) max ( v ) − min ( v ) The harmonic mean was chosen since it penalizes more strongly than the arithmetic mean situations where one of the two scores is low . Submissions were sorted by decreasing S score values to get the final participant ranking. (a) ASR performance in W ord Error Rates on Ev al (%) (b) CSD Performance in F1-score on Eval (%). Figure 1: P erformance of the 22 systems on the Eval subset. T able 3: Results for the ASR and CSD tasks for the five best ranked teams. ASR CSD T eam WER (%) ins (%) del (%) sub (%) F1 (%) p (%) r (%) V ocapia-LIMSI 7.62 1.29 3.14 3.19 82.41 81.99 82.82 UWr 8.42 1.52 3.03 3.87 79.39 81.00 77.84 CRIM 9.41 1.21 4.51 3.69 80.17 84.94 75.91 UWB-JHU 8.76 1.55 3.42 3.80 77.04 84.05 71.11 T eam5 9.55 1.80 3.97 3.79 77.62 84.27 71.94 4. Result analysis and system over view In this section, we report detailed results for the two tasks ASR and CSD. W e also gi ve a bird’ s e ye vie w on the approaches of the best ranked predictions on the Ev al subset. 4.1. Results Figures 1a and 1b show the W ord Error Rates (WER) for the ASR task and the F1-scores for CSD, obtained by the 22 teams ordered by their final ranking. Only the names of the entities that gav e a disclosure agreement are displayed. V OCAPIA-LIMSI achieved the best results in both tasks with a 7.62% WER and a 82.41% CSD F1-score. Globally speaking, the best teams obtained impressive results with WERs below 10% and below 8% for the winner . T able 3 gives more details to analyze these results. One can see that almost all the ASR systems produced twice as many deletions and substitu- tions (around 3%) than insertions (around 1.5%). Regarding CSD, the best systems yielded F1-score abov e 80%. Except for the two best systems with similar precision and recall values (respectively 81.99% and 82.82% for V OCAPIA- LIMSI), precision was larger than recall by a significant mar - gin. This means that the number of missed CS is larger than false alarms for these systems. This lack of robustness may be explained by the variability with which call signs are employed: sometimes in their full form, sometimes in partial forms. Three teams including Queensland Speech Lab and U. Sheffield did not submit CS predictions resulting in a zero score in CSD (no visible bar in fig. 1b), and a final ranking that does not reflect their good performance in ASR. T able 4: Best ASR and CSD r esults accor ding to the speech pr ogr am (A T : A TIS, AP: Approac h, TO: T ower), the speaker job (C: contr ollers, P: Pilots) and se x (F: female, M: male). Program Speaker Sex A T AP TO C P F M WER 5.1 8.1 7.8 5.5 10.5 5.5 8.2 F1 82.8 81.4 86.8 79.0 88.6 80.9 T o get more insights in these results, T able 4 shows the highest ranked team WER and CSD F1-score according to the program, speaker job, and speaker sex. As expected, A TIS speech (mostly weather forecasts with limited vocab ulary) is easier to transcribe than Approach (AP) and T ower (TO), for which similar WERs were obtained: 8.1% and 7.8%, respec- tiv ely . An interesting finding is that pilots’ speech (P) was much more difficult to transcribe than controllers’ speech (C), with al- most a factor two in WER, and 8% absolute difference in CSD F1-score. This may be e xplained by the greater di versity of ac- cents and speakers among pilots compared to controllers. Most of the controllers are French nativ e speakers contrarily to the pilots. This could explain the better performance for controllers since French-accented English is the most represented accent in the corpus. Better performance was obtained for female speak- ers compared to male speakers probably because 78% of the female utterances are controller utterances. This is also inline with results from the literature, where lo wer WERs on female speech ranging from 0.7 to 7% were achie ved depending on speech type condition [14]. T able 5: Characteristics of the five best r anked teams’ ASR systems. Acoustic frontend Acoustic Modeling Language Modeling T eam Features Data augmentation Modeling Context Complexity Lex. size LM Decoding Ensemble V ocapia-LIMSI PLP-RAST A No HMM-MLP triphones 6M 2.2k 4-gram Consensus No UWr-T oopLoox Mel F-BANK freq. shifting, noise CTC Conv-BiLSTM diphones 50M 2.2k 4-gram Lattice Y es CRIM MFCC, iv ectors noise BiLSTM-TDNN triphones 17M 190k RNNLM N-best Y es UWB-JHU MFCC, iv ectors v olume, speed TDNN-F triphones 20M 2.2k 3-gram Lattice No T eam5 MFCC, i vectors rev erb, speed, volume TDNN triphones 6M 2.7k 4-gram Lattice No 4.2. ASR system characteristics T able 5 giv es an ov erview of the ASR modules used by the fiv e best rank ed teams. Regarding acoustic front-end, V ocapia- LIMSI used Perceptual Linear Predictive (PLP) features with RAST A-filtering [15, 16]. Except UWr-T oopLoox that used Mel F-B ANK coef ficients, all the other participants used high- resolution MFCC (40 to 80 coefficients) and 100-d i-vectors. According to their findings, i-vectors bring very small gains. For acoustic modeling, V ocapia-LIMSI used a hybrid HMM- MLP model (Hidden Marko v Models - Multi-Layer Percep- tron). UWr-T oopLoox used an ensemble of six large mod- els (50M parameters each), each comprised of two con v olution layers, fi ve bidirectional Long Short-T erm Memory layers (Bi- LSTM) trained with the CTC (Connectionist T emporal Clas- sification, [17]) objectiv e function. CRIM also combined six different models, three Bi-LSTM and three T ime-Delay Neural Networks (TDNN [18] using Kaldi [19]) [20]. UWB-JHU used factorized TDNNs (TDNN-F , [21]), which are TDNNs whose layers are compressed via Singular V alue Decomposition. Regarding developments specific to A TC speech, we no- ticed the use of specific pronunciations for certain w ords: words that correspond to letters (Alfa for A, Quebec for Q, using the N A TO phonetic alphabet), and other cases such as niner for nine, and tree for three, for instance. Non-English word se- quences, mostly French words, were denoted ’@’ in the manual annotations. Some systems used a special token for non-English words such as ’ < foreign > ’ and others simply mapped them to an unknown tok en (’ < UNK > ’). Finally , almost all the teams used the 2.2k word-type vo- cabulary extracted from the challenge corpus. The participants reported no gains when using neural language models rather than n- gram models. 4.3. Call Sign Detection system characteristics For CSD, two main approaches were implemented: on the one hand grammar-based and regular expression (RE) methods, i.e . knowledge-based methods, on the other hand machine learning models. The first type of models requires adaptation to capture production v ariants that do not strictly respect CS rules (pilots and controllers often shorten CS for example). The second one, namely neural networks, Consensus Network Search (CNS), n- grams, perform better in this ev aluation but are not able to detect unseen CS. V ocapia-LIMSI combined both approaches (RE al- lowing full and partial CSD together with CNS) and achiev ed the highest scores. 5. Summary and discussion In this paper, we reported and analyzed the outcomes of the first edition of the Airbus and partners’ A TC ASR challenge. The best rank ed team achieved a 7.62% W ord Error Rate and a 82.41% callsign detection F1-score on a 5-hour e v aluation sub- set. A TIS speech, consisting of mostly weather forecasts with limited vocab ulary , was shown to be easier to transcribe than Approach and T ower speech interactions. T ranscribing pilots’ speech was found to be twice as harder as controllers’ speech. Some participants attempted to use external A TC speech data for semi-supervised acoustic model training, and it was re- vealed to be unsuccessful. This technique usually brings perfor- mance gains, such as in [22]. This may be due to the fact that the e val subset is very close to the trained one so that adding external data just adds noise. This outcome reveals a robustness issue that needs to be addressed. A large-scale speech data col- lection is very much needed to solve A TC ASR. Se veral criteria should be considered for this data collection: diversity in the airports where speech is collected, di versity in foreign accents, acoustic devices used for A TC, among others. Regarding organizing a future challenge, using speech from different airports for training and testing purposes should be considered. This also would require systems with more gen- eralization capabilities for the CSD task since most of the call signs would be unseen during training. Furthermore, to be successful, the major players in the field should join forces for data collection but also to share the large costs needed to manually transcribe the recordings. Finally , much attention should be paid to legal aspects on data protec- tion and priv acy (in Europe, the recent General Data Protection Regulation). 6. Acknowledgements The organizing team would like to thank all the participants. This work was partially funded by AIRB US 3 , ´ Ecole Nationale de l’A viation Civile (ENA C) 4 , Institut de Recherche en Infor- matique de T oulouse 5 and SAFETY D A T A-CFH 6 . 7. References [1] W . Xiong, J. Droppo, X. Huang, F . Seide, M. Seltzer , A. Stolcke, D. Y u, and G. Zweig, “ Achieving human parity in con versational speech recognition, ” CoRR , 2016. [2] G. Saonn, G. Kurata, T . Sercu, K. Audhkhasi, S. Thomas, D. Dim- itriadis, X. Cui, B. Ramabhadran, M. Picheny , L. Lim, B. Roomi, and P . Hall, “English con versational telephone speech recognition by humans and machines, ” CoRR , 2017. [3] J. Godfrey , E. Holliman, and J. McDaniel, “SWITCHBOARD: T elephone speech corpus for research and development, ” in Pr oc. ICASSP , vol. 1, 1992, pp. 517–520. [4] E. Delpech, M. Laignelet, C. Pimm, C. Raynal, M. Trzos, A. Arnold, and D. Pronto, “ A real-life, french-accented corpus of Air T raffic Control communications, ” in Pr oc. LREC , Miyazaki, 2018, pp. 2866–2870. [5] R. Cauldwell, “Speech in action: Fluency for Air Traf fic Control, ” PTLC , August 2007. 3 https://www.airbus.com/ 4 http://www.enac.fr/en 5 https://www.irit.fr/ 6 http://www.safety- data.com/en/ [6] Manual of Radiotelephony , 4th ed., ICA O, doc 9432-AN/925. [7] J. C. Segura, T . Ehrette, A. Potamianos, D. Fohr , I. Illina, P .- A. Breton, V . Clot, R. Gemello, M. M., and P . Maragos, “The HIWIRE database, a noisy and non-nati ve English speech cor - pus for cockpit communication, ” W eb Download, 2007, http: //catalog.elra.info/en- us/repository/browse/ELRA- S0293/. [8] S. Pigeon, W . Shen, and D. v an Leeuwen, “Design and charac- terization of the non-native military air traffic communications database (nnMA TC), ” in Proc. Interspeech , Antwerp, 2007, pp. 2417–2420. [9] L. Graglia, B. F av ennec, and A. Arnoux, “V ocalise: Assessing the impact of data link technology on the r/t channel, ” in The 24th Digital A vionics Systems Conference , vol. 1, 2005. [10] S. Lopez, A. Condamines, A. Josselin-Leray , M. ODonoghue, and R. Salmon, “Linguistic analysis of english phraseology and plain language in air -ground communication, ” J ournal of Air T ransport Studies , vol. 4, no. 1, pp. 44–60, 2013. [11] K. Hofbauer , S. Petrik, and H. Hering, “The A TCOSIM corpus of non-prompted clean Air T raffic Control speech, ” in Pr oc. LREC , Marrakech, 2008, pp. 2147–2152. [12] J. Godfrey , “ Air traf fic control complete LDC94S14A, ” W eb Download, Philadelphia: Linguistic Data Consortium, 1994, https://catalog.ldc.upenn.edu/LDC94S14A. [13] L. ˇ Sm ´ ıdl and P . Ircing, “Air Traf fic Control communica- tions (A TCC) speech corpus, ” W eb Download, Uni ver - sity of W est Bohemia, Department of Cybernetics, 2014, https://lindat.mff.cuni.cz/repository/xmlui/handle/11858/ 00- 097C- 0000- 0001- CCA1- 0. [14] M. Adda-Decker and L. Lamel, “Do speech recognizers prefer female speakers?” in Pr oc. Interspeech , Lisbon, 2005, pp. 2205– 2208. [15] H. Hermansky , “Perceptual linear predictive (PLP) analysis of speech, ” the Journal of the Acoustical Society of America , vol. 87, no. 4, pp. 1738–1752, 1990. [16] H. Hermansky and N. Morgan, “RAST A processing of speech, ” IEEE transactions on speech and audio pr ocessing , vol. 2, no. 4, pp. 578–589, 1994. [17] A. Grav es, S. Fern ´ andez, F . Gomez, and J. Schmidhuber, “Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks, ” in Pr oc. ICML . Pittsbur gh: ACM, 2006, pp. 369–376. [18] A. W aibel, T . Hanazawa, G. Hinton, K. Shikano, and K. J. Lang, “Phoneme recognition using time-delay neural networks, ” IEEE T ransactions on Acoustics, Speech, and Signal Processing , vol. 37, no. 3, pp. 328–339, 1989. [19] D. Pove y , A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P . Motlicek, Y . Qian, P . Schwarz et al. , “The kaldi speech recognition toolkit, ” in IEEE 2011 W orkshop on Automatic Speech Recognition and Understanding . IEEE Signal Processing Society , 2011. [20] V . Gupta and G. Boulianne, “CRIM’s system for the MGB-3 En- glish multi-genre broadcast media transcription, ” in Pr oc. Inter- speech , Hyderabad, 2018, pp. 2653–2657. [21] D. Pove y , G. Cheng, Y . W ang, K. Li, H. Xu, M. Y armo- hammadi, and S. Khudanpur , “Semi-orthogonal low-rank matrix factorization for deep neural networks, ” in Proc. Inter- speech , Hyderabad, 2018, pp. 3743–3747. [Online]. A vailable: http://dx.doi.org/10.21437/Interspeech.2018- 1417 [22] L. ˇ Sm ´ ıdl, J. ˇ Svec, A. Pra ˇ z ´ ak, and J. Trmal, “Semi-supervised training of DNN-based acoustic model for A TC speech recogni- tion, ” in Pr oc. SPECOM . Leipzig: Springer , 2018, pp. 646–655.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment