에어버스 ATC 음성인식 챌린지 2018 자동 전사와 호출부호 탐지
본 논문은 2018년 에어버스가 주관한 항공 교통 관제(ATC) 영어 음성 데이터에 대한 자동 전사(ASR)와 호출부호(Call Sign) 검출(CSD) 과제를 다룬 챌린지 결과를 보고한다. 40시간의 훈련 데이터와 5시간 평가 데이터를 제공했으며, 22개 팀이 참여했다. 최고 성적 팀은 7.62%의 단어 오류율(WER)과 82.41%의 F1 점수를 기록했다. 파일럿의 발화가 관제사의 발화보다 두 배 정도 어려웠으며, 데이터 다양성 및 외부 데…
저자: Thomas Pellegrini, Jer^ome Farinas, Estelle Delpech
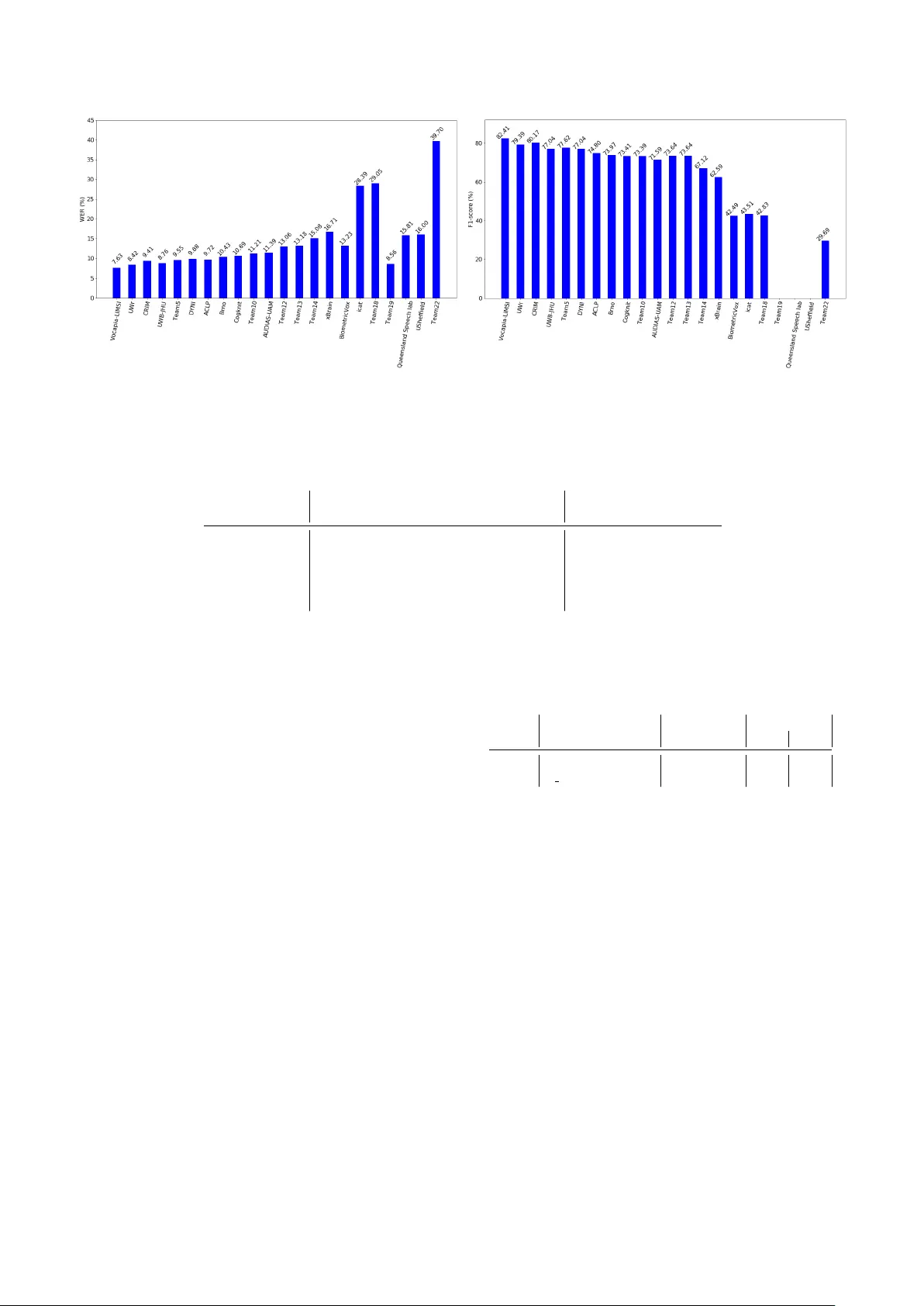
본 논문은 2018년 에어버스와 협력 기관이 주관한 ATC(항공 교통 관제) 음성 인식 챌린지의 전반적인 설계, 데이터 구성, 평가 방법 및 결과 분석을 제공한다. ATC 음성은 VHF 채널의 저품질, 높은 발화 속도, 다국적 비원어민 억양, 코드스위칭, ICAO 표준 어휘 등 특수한 어려움을 내포하고 있어 기존 대규모 일반 음성 코퍼스(SWITCHBOARD 등)와는 차별화된 접근이 필요하다. 이를 위해 조직위원회는 50시간 분량의 실제 ATC 녹음 중 40시간을 훈련용, 5시간을 개발용, 5시간을 최종 평가용으로 나누어 제공하였다. 데이터는 16 kHz, 16 bit PCM 형식이며, 스피커 성별(여성 25 %, 남성 75 %), 직업(파일럿 54 %, 관제사 43 %, ATIS 3 %) 및 프로그램(ATIS, Approach, Tower) 별로 균형 있게 배분하였다. 호출부호는 ICAO 알파벳과 숫자 조합으로 구성되며, 전체 발화에 태깅이 되어 있다.
평가 지표는 두 과제에 대해 각각 WER과 F1‑score를 사용했으며, 이를 정규화한 뒤 조화 평균을 최종 점수(S)로 정의하였다. 이는 한 과제에서 낮은 점수가 전체 순위에 큰 영향을 미치도록 설계된 것이다. 22개 팀이 최종 제출을 했으며, 최고 성적 팀은 7.62% WER과 82.41% F1을 기록했다. 전체 상위 팀들은 WER 10% 이하, CSD F1 80% 이상을 달성했으며, 평균적으로 삽입 오류는 1.5% 수준으로 낮았지만 삭제와 치환 오류가 각각 약 3%로 더 크게 나타났다.
기술적 분석에서는 상위 5팀의 시스템 구성을 상세히 살펴보았다. 특징 추출 단계에서는 PLP‑RASTA, 고해상도 MFCC, Mel‑Fbank 등 다양한 스펙트로그램 기반 특징이 사용되었고, 대부분 i‑vector를 추가했지만 성능 향상은 미미했다. 음향 모델은 HMM‑MLP 혼합, CTC 기반 Conv‑BiLSTM, TDNN‑F, BiLSTM‑TDNN 등 최신 딥러닝 구조가 적용되었으며, 파라미터 규모는 6 M에서 50 M까지 다양했다. 언어 모델은 2.2 k 어휘 기반 4‑gram이 기본이었고, 일부 팀이 신경망 LM을 시도했지만 큰 개선을 보이지 못했다. 이는 훈련 데이터가 제한적이고 도메인 어휘가 작아 n‑gram이 충분히 효과적이었기 때문이다.
CSD에서는 규칙 기반 정규표현식(RE)과 신경망 기반 컨센서스 네트워크 서치(CNS)를 결합한 하이브리드 접근이 최고 성능을 보였다. RE는 전체 및 축약 형태의 호출부호를 모두 포괄하도록 설계되었고, CNS는 데이터에 기반한 패턴 인식을 담당했다. 대부분의 팀이 정밀도는 높았지만 재현율이 낮아 호출부호 누락이 주요 오류 원인으로 드러났다.
분석 결과, 파일럿 발화가 관제사 발화보다 WER이 약 두 배 높았으며, 이는 파일럿의 억양 다양성, 비표준 약어 사용, 그리고 프랑스어 억양이 주를 이루는 관제사와 대비되는 특성 때문으로 해석된다. 여성 스피커가 남성보다 낮은 오류율을 보인 것은 여성 발화가 주로 관제사(프랑스어 억양)였기 때문이다. 외부 ATC 데이터(예: NIST, ATCOSIM)를 추가 학습에 활용한 팀은 성능이 향상되지 않았으며, 이는 데이터 도메인 불일치와 레이블 차이, 그리고 평가 데이터와의 높은 유사도가 외부 데이터의 일반화 효과를 억제했기 때문으로 판단된다.
결론적으로, 제한된 규모와 복합적인 음성 특성에도 불구하고 최신 딥러닝 기반 ASR과 CSD 기술이 충분히 적용 가능함을 입증했다. 그러나 데이터 규모 확대, 다양한 공항·장비·억양 확보, 호출부호의 미표시 상황에 대한 강건한 탐지 기법 개발이 향후 과제로 남는다. 또한, 향후 챌린지에서는 훈련과 평가 데이터를 서로 다른 공항에서 수집해 일반화 능력을 더욱 검증할 필요가 있다. 마지막으로, 대규모 데이터 수집과 라벨링에는 높은 비용과 법적·프라이버시 이슈가 수반되므로, 산업계와 학계가 협력해 지속 가능한 데이터 인프라를 구축하는 것이 중요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기