AlignNet: A Unifying Approach to Audio-Visual Alignment
We present AlignNet, a model that synchronizes videos with reference audios under non-uniform and irregular misalignments. AlignNet learns the end-to-end dense correspondence between each frame of a video and an audio. Our method is designed accordin…
Authors: Jianren Wang, Zhaoyuan Fang, Hang Zhao
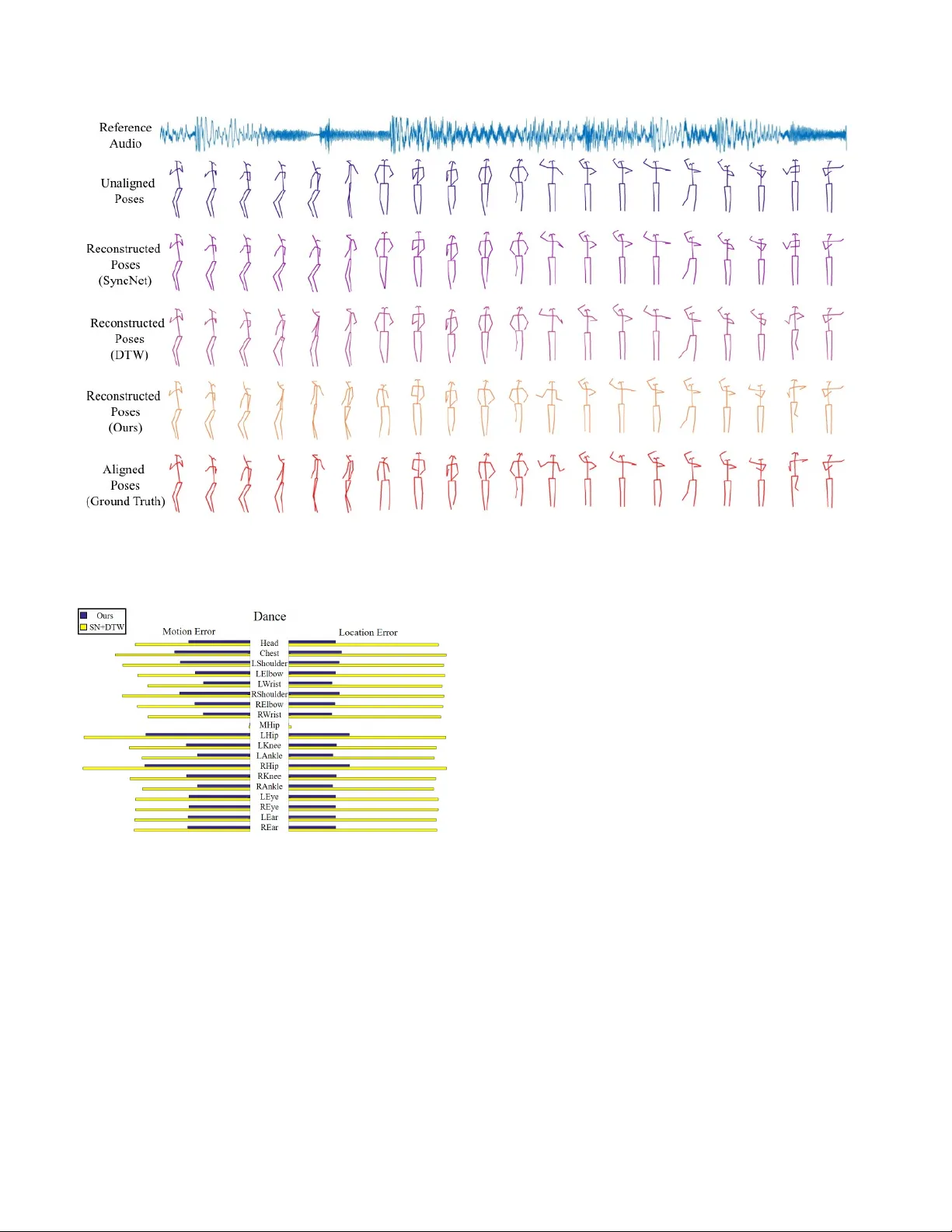
AlignNet: A Unifying A ppr oach to A udio-V isual Alignment Jianren W ang* CMU jianrenw@andrew.cmu.edu Zhaoyuan F ang* Uni versity of Notre Dame zfang@nd.edu Hang Zhao MIT hangzhao@csail.mit.edu Figure 1: Giv en a pair of unaligned audio and video, our model aligns the video to the audio according to the predicted dense correspondence. Abstract W e pr esent AlignNet, a model that sync hr onizes videos with r eference audios under non-uniform and irre gular mis- alignments. AlignNet learns the end-to-end dense corre- spondence between each frame of a video and an audio. Our method is designed accor ding to simple and well- established principles: attention, pyramidal pr ocessing, warping, and affinity function. T ogether with the model, we r elease a dancing dataset Dance50 for training and e val- uation. Qualitative, quantitative and subjective evaluation r esults on dance-music alignment and speech-lip alignment demonstrate that our method far outperforms the state-of- the-art methods. Code, dataset and sample videos are avail- able at our pr oject page 1 . * indicates equal contribution 1 https://jianrenw.github.io/AlignNet/ 1. Introduction Dancers move their bodies with music, speakers talk with lip motions and are often accompanied by hand and arm gestures. The synchrony between visual dynamics and audio rhythms poses perfect performances. How- ev er, recorded videos and audios are not always temporally aligned. e.g . dancers may not be experienced enough to follow the music beats precisely; “ Automated Dialogue Re- placement (ADR)” is used in film making instead of simul- taneous sounds for lip synchronization. It is not hard to imagine the humongous amount of ef forts and time required to temporally synchronize videos and audios by aligning vi- sual dynamics and audio rhythms. This alignment problem is especially dif ficult for humans since the misalignment is often non-uniform and irregular . There are se veral pre vious attempts to address this prob- lem. [8] extracted visual beats analogous to musical beats, and applied audio-video alignment to tasks such as video dancification and dance retargeting. Their method requires feature engineering on visual beats and only performs align- ment on beat-lev el, which makes the generated dances sometimes exaggerated. SyncNet [6] proposed to learn the alignment features with a contrastiv e loss that discriminates matching pairs from non-matching pairs. Howe ver , they as- sume a global temporal offset between the audio and video clips when performing alignment. [14] further le veraged the pre-trained visual-audio features of SyncNet [6] to find an optimal alignment using dynamic time warping (DTW) to assemble a ne w , temporally aligned speech video. Their method can therefore stretch and compress the signals dy- namically . Ho wever , the minimum temporal resolution of their method is limited (0.2 second). In a realistic setting, e.g . ADR or of f-beat dancing, misalignment between audio and video can happen at any moment on arbitrary temporal scale. Therefore, a crucial property for audio-visual align- ment solutions is the ability to deal with arbitrary tempo- ral distortions. Another nice property to hav e is end-to-end training, as it significantly simplifies the solution to such a hard task. In this work, we present AlignNet, an end-to-end train- able model that learns the mapping between visual dynam- ics and audio rhythms, without the need of any hand-crafted features or post-processing. Our method is designed ac- cording to simple and well-established principles: atten- tion, pyramidal processing, warping, and affinity function. First, attention modules highlight the important spatial and temporal regions in the input. Then, casting in two learn- able feature pyramids (one for video and one for audio), AlignNet uses the current level correspondence estimation to warp the features of the reference modality (video or au- dio). W arped features and reference signal features are used to construct an affinity map, which is further processed to estimate denser correspondence. T ogether with the model, we introduce a dancing dataset Dance50 for dance-music alignment. The dataset is cleaned and annotated with human keypoints using a fully automated pipeline. W e demonstrate the ef fectiv eness of AlignNet on both dance-music alignment and lip-speech alignment tasks, with qualitati ve and quantitati ve results. Finally we con- duct dance and speech retargeting experiments, and sho w the generalization capabilities of our approach with subjec- tiv e user studies. 2. Related W orks A udio-video alignment Audio-video alignment refers to the adjustment of the relative timing between audio and vi- sual tracks of a video. Automatic audio-video alignment has been studied over decades in computer vision. Early works like [2] and [23] used canonical correlation analy- sis (CCA) for synchronization prediction. Later methods tried to align video and audio based on handcrafted fea- tures. Lewis [16] proposed to detect phonemes (short units of speech) and subsequently associate them with mouth po- sitions to synchronize the two modalities. Con versely , [11] classified parameters on the face into visemes (short units of visual speech), and used a viseme-to-phoneme mapping to perform synchronization. [8] split videos according to vi- sual beats and applied video-audio alignment on beat-le vel. Learning multimodal features is a recent trend. Sync- Net [6] learned a joint embedding of visual face sequences and corresponding speech signals in a video by predicting whether a given pair of face sequence and speech track are synchronized. Similarly , [20] proposed a self-supervised method to predict the alignment of motion and sound within a certain time shift. These works attempted to detect and correct a global error , which is a common problem in TV broadcasting. Howe ver , they cannot address non-uniform misalignment, e .g. dancers do not only make mistakes at musical beats. In other words, misalignment in videos and audios is oftentimes completely unconscious and irregular . In these scenarios, the closest method to our work is pro- posed by [14], which can stretch and compress small units of unaligned video signal to match audio signal. Howe ver , their method can only adjust audio-video misalignment on a coarser granularity , since they assume the consistency of information within ev ery 0.2 second. Time W arping Given two time series, X = [ x 1 , x 2 , ..., x n x ] ∈ R d × n x and Y = [ y 1 , y 2 , ..., y n y ] ∈ R d × n y , dynamic time w arping (DTW) [22] is a tech- nique to optimally align the samples of X and Y such that the follo wing sum-of-squares cost is minimized: C ( P ) = P m t =1 k x p X t − y p y t k 2 , where m is the number of indices (or steps) needed to align both signals. Although the number of possible ways to align X and Y is e xponential in n x and n y , dynamic programming [1] offers an efficient way to minimize C using Bellmans equation. The main limitation of DTW lies in the inherent inability to handle sequences of varying feature dimensionality , which is essential in multimodal data, like video and audio. Further- more, DTW is prone to f ailure when one or more sequences are perturbed by arbitrary affine transformations. T o this end, the Canonical Time W arping (CTW) [31] is proposed, which elegantly combines the least-squares formulations of DTW and Canonical Correlation Analysis (CCA) [9], thus facilitating the utilization of sequences with v arying dimensionality , while simultaneously performing feature selection and temporal alignment. Deep Canonical T ime W arping (DCTW) [26] further e xtends CTW through the usage of deep features. These methods are widely used in audio-audio alignment [15, 18], video-audio alignment [14] and video-video alignment [25]. A udio-visual Datasets Most existing audio-visual datasets focus on speech and face motion. Some early datasets are obtained under controlled conditions: forensic data intercepted by police officials [27], speech recorded from mobile de vices [28], etc . In contrast, V oxCeleb [19, 5] and A VSpeech [10] collected a large amount of audio- visual data of human speeches in the wild. MUSIC [30, 29] and F AIR-Play [12] are datasets of music and instruments. In this work, we introduce a new dancing dataset to the community , focusing on the synchronization between music and body motions. 3. A pproach 3.1. F ormulation AlignNet is an end-to-end trainable model that learns the implicit mapping between visual dynamics and audio rhythms at multiple temporal scales, without the need of any post-processing. It takes in a video feature sequence F t v , t ∈ (1 , .., n ) and an audio feature sequence F t a , t ∈ (1 , .., m ) , to predict a dense correspondence d , which is the tempo- ral displacement for each video frame ( n, m might not be the same). T o generate unaligned training data, we apply random and non-uniform distortion temporally (speed-ups and slow-do wns) to the aligned audio-video data of differ - ent lengths. Different from previous methods [6, 7, 14] that use raw image frames as inputs, which are prone to large variations when there are changes in outfits, makeups, lighting, shad- ows, etc. , we instead use more rob ust pose/lip ke ypoint fea- tures pro vided by a keypoint detector OpenPose [3]. Fur- thermore, as suggested by [4], operating in the velocity space improves the results of human pose forecasting. For our task, at time t , we input v elocity v v ( t ) and the accel- eration a v ( t ) of the keypoints. For audio, we use normal- ized log-mel spectrogram as input. Note that the input video features and audio features do not have the same shape and granularity , b ut our proposed network learns to e xtract in- formation from dif ferent modalities and align them on the same scale. The full pipeline of AlignNet is shown in Figure 2. It is designed based on the following principles: (1) spatial and temporal attention modules highlight the important re gions; (2) learnable feature pyramids extract features from visual and audio inputs at multiple le vels (temporal scales); (3) inspired by [24], warping layers warp the lower -lev el refer- ence modality feature based on the correspondence estima- tion on the current le vel to better predict distortion on larger scales; (4) correlation layers models the affinity between video features with audio features; (5) final dense corre- spondence estimation is predicted from the affinity map. W e will explain each module in details in the following para- graphs. 3.2. Spatial and T emporal Attention Modules Intuitiv ely , certain ke ypoints are more reflective of the visual rhythms than others, so are certain sound fragments of the auditory beats. Hence, we use attention modules to highlight these important parts. Applying spatio-temporal attention jointly requires excessi ve parameters, so we pro- pose to decouple it, using a spatial attention module and a temporal attention module. For the spatial attention, we assign a weight to each k ey- point, indicating the importance of this spatial location. T o make the learning more effecti ve and meaningful, we force the attention of symmetric keypoints ( e.g. left and right el- bow) to be the same. Note that we assume keypoint at- tentions are the same over the whole dataset, so they are learned as model parameters (the number of parameters is the same as the number of keypoints). For the temporal attention, we train a self-attention mod- ule conditioned on the input audio, and re-weight audio fea- tures at each time step accordingly . Different from keypoint attention, temporal attention varies with the input data, so the attention weights are the intermediate outputs of the model. 3.3. Multimodal F eature Pyramid Extraction For each modality , we generate an N -le vel feature pyra- mid, with the 0-th lev el being the input features, i.e. , F 0 p = F t v /a , t ∈ (1 , .., n/m ) . Con volutional layers then extract the feature representation at the l -th le vel, F l p , from the fea- ture representation at the ( l − 1 )-th lev el, F l − 1 p . 3.4. Time W arping The concept of warping is common to flow-based meth- ods and goes back to [17]. W e introduce time w arping layer to warp the video features giv en the estimated correspon- dences. The warping operation assesses previous errors and computes an incremental update, helping the predic- tion module to focus on the residual misalignment between video and audio. Formally , at the l -th level, we warp refer- ence audio features toward video features using the upsam- pled prediction from the ( l + 1 )-th lev el, d l +1 : F l w ( x ) = F l a up γ d l +1 ( x ) (1) where x is the frame indices and up γ is the upsampling function with scale factor γ . 3.5. Affinity Function In order to better model the correspondence, we em- ploy an affinity function A at each feature pyramid lev el. A provides a measure of similarity between video features F l v t , t ∈ (1 , .., n l ) and audio feature F l a t , t ∈ (1 , .., m l ) , denoted as A F p l v , F p l a . The af finity is the dot product Figure 2: Our model consists of attention, pyramidal processing, time warping, af finity and correspondence prediction. between embeddings: for F l v i and F l a j , A ( j, i ) = F l a j > F l v i P j F l a j > F l v i (2) 3.6. Multimodal Dense Correspondence Estimation Correspondences are normalized to ( − 1 , 1) . For a video with N frames, we first include a correspondence loss, namely an L1 regression loss of the predicted correspon- dence at all pyramid le vels: L f s = N X l =0 λ l n l X i =0 d l ( i ) − ˜ d l ( i ) (3) where d l ( i ) is the ground truth correspondence and ˜ d l ( i ) is the predicted correspondence of frame i at le vel l , and λ l is the weighting factor of le vel l . T o force the network to predict realistic correspondence that are temporally monotonic, we further incorporate a monotonic loss: L mono = N X l =0 λ l n l − 2 X i =0 max 0 , 1 − ˜ d l ( i ) + ˜ d l ( i + 1) (4) W ith µ being a weighting hyperparameter , our full objective to minimize is therefore: loss = L f s + µL mono (5) 3.7. Model Architectur e Details AlignNet takes in normalized log-mel spectrograms with 128 frequency bins as audio input and pose/lip ke ypoints as visual input with shape (2 × #keypoints, #frames), where the 2 accounts for two dimensional (x,y) coordinates. Note that all conv olutional layers in our network are 1D conv o- lutions, which speed up the prediction at both training and testing time. W e use a 4-lev el feature pyramid, with chan- nels 128, 64, 32, 16 and the temporal do wnscale factors 1/3, 1/2, 1/2, 1/2, respectiv ely . The final output is obtained by upsampling the 1st-level correspondence to match with the input dimension. Note that our model can take in videos of arbitrary lengths. 4. Experiments W e ev aluate AlignNet on two tasks: dance-music align- ment, and lip-speech alignment. W e test our method, both quantitativ ely and qualitati vely on the these tasks, and com- pare our results with tw o benchmark methods. Finally , sub- jectiv e user studies are performed for dance and speech re- targeting. Baselines In order to compare our methods with other state-of-the-art audio-video synchronization techniques, we implemented two baselines: SyncNet [6] and Sync- Net+DTW [14]. F or SyncNet, we follo w the exact steps described in [6] except that we replace raw frame inputs with pose/lip ke ypoints and replace MFCC feature inputs with normalized log-mel spectrograms. Since (1) the rele- vant features to dancing and speaking are essentially body and lip motion and (2) MFCC features are handcrafted and low-dimensional ( i.e. contain less information than spectro- grams), these changes should reach similar performance of the original method, if not better . SyncNet+DTW uses the pre-trained SyncNet as their feature extractor , so we also replace the SyncNet here with our implementation. Then, DTW is applied on the extracted video and audio features. T raining During training, we use online sample genera- tion for both our method and the baselines. In our method, the video features are randomly distorted and scaled tempo- rally each time to prev ent the network from o verfitting finite misalignment patterns. T o better mimic real world situa- tions, the distortions are always temporally monotonic, and we linearly interpolate the keypoints from adjacent frames. For the baselines, SyncNet is trained with random pairs of matching / non-matching pairs with the same clip length and maximum temporal difference as the original paper [6]. W e Methods Performance AFE Accuracy SyncNet [6] 6.58 25.88 SyncNet+DTW [14] 4.27 38.29 AlignNet (Ours) 0.94 89.60 T able 1: Performance of music-dance alignment on Dance50 dataset. further augment the training data by horizontally flipping all poses in a video clip, which is a natural choice because visual dynamics is mirror-in v ariant. F or the audio inputs, we employ the time masking and frequenc y masking sug- gested by SpecAugment [21]. Adam is used to optimize the network parameters with a learning rate of 3 × 10 − 4 . Evaluation Quantitati ve ev aluation was performed using a human perception-inspired metric, based on the maximum acceptable audio-visual asynchrony used in the broadcast- ing industry . According to the International T elecommuni- cations Union (ITU), the auditory signal should not lag by more than 125 ms or lead by more than 45 ms. Therefore, the accurac y metric we use is the percentage of frames in the aligned signal which fall inside of the abov e acceptable (human undetectable) range, compared to the ground truth alignment. W e also defined A verage Frame Error (AFE) as the a ver- age difference between the reconstructed frame indices and the original undistorted frame indices. This gives a more direct measure of ho w close the reconstructed video is com- pared to the original video. 4.1. Dance-music Alignment Dance50 Dataset W e introduce Dance50 dataset for dance-music alignment. The dataset contains 50 hours of dancing clips from over 200 dancers. There are around 10,000 12-second videos in the training set, 2,000 in the validation set, and 2,000 in the testing set. Our training, validation, and testing sets contain disjoint videos, such that there is no overlap between the videos from any two sets. All dancing clips are collected from K-pop dance cover videos from Y ouT ube.com and Bilibili.com . Similar to [13], we represent our annotations of the poses with a temporal sequence of 2D skeleton keypoints, obtained using Open- Pose [3] BOD Y 25 model, discarding 6 noisy keypoints from the feet and k eeping the rest. W e refer the readers to supplementary material for more details. Settings W e use Dance50 to ev aluate the performance of method on dance synchronization. W e compare our method against the state-of-the-art baselines using the aforemen- tioned ev aluation metrics. Results T able 1 compares the performance of our method and the two baselines on Dance50 testing set. Our method significantly reduces the AFE, and achiev es a g ain of 51.31% in accuracy , which reaches 89.60%. Our network obtains a satisfactory performance e ven on video clips com- pletely unseen in training, and this shows that the pro- posed method effecti vely learns the implicit mapping be- tween video dynamics and audio features on multiple tem- poral scales. T o get a better idea of how well our method aligns the video to the audio compared to the baselines methods, we show some visualization of the skeletons reconstructed from the correspondence predictions in Figure 3. It can be seen that our method closely recovers the original aligned poses, while both SyncNet and DTW fails to align poses warped on dif ferent temporal scales. W e also show the mean motion error and location error of each human keypoint after alignment in Figure 4. The mo- tion error reflects visual rhythm dif ference between aligned video and original video (Figure 4 Left), while the loca- tion error reflects the objective difference between aligned video and original video (Figure 4 Right). For motion error , we normalize the keypoint velocity in pixel space of both x and y coordinates to (-1,1). Similarly , we normalize the location of each keypoint for calculating location error . As shown in the figure, for both motion and location, our pro- posed method outperforms the baseline method consistently by a large mar gin under all human keypoints. It’ s worth noticing that mid-hip locations are always subtracted dur - ing preprocessing. Thus, the mid-hip error of both motion and location is significantly smaller than other keypoints. Furthermore, we plot e xamples of the ground truth dis- tortion compared to the distortion predicted by SyncNet- DTW and our method in Figure 6 (left). It can be seen that SyncNet-DTW captures some of the mapping be- tween video and audio very coarsely , while failing to align with more subtle changes. W e believ e that this is be- cause SyncNet-DTW uses SyncNet as its backbone net- work, which is trained with blocks of matching / non- matching pairs, assuming that the frames within each block is temporally aligned. In our application scenario, ho wev er , the video could be distorted at any moment on any tem- poral scale, so their method cannot deal with such distor- tions very well. In contrast, the prediction from our method closely matches the ground truth distortion and is able to undistort & recover the input video. W e belie ve that this is because (1) the hierarchical nature of our model helps the network extract visual and auditory features on multi- ple temporal scales; (2) the warping layer makes it easier to predict coarser trends on larger temporal scales; and (3) the af finity map helps to correlate the relationship between video features and audio features. W e also show the effec- tiv eness of each model in the ablation study later . Figure 3: Skeleton visualizations of the proposed method and comparison with the baselines on Dance50 . For better visual- ization, we ev enly sample 20 frames from the original 180 frames. Figure 4: Comparison of the performance (mean motion & location error) of our method and SyncNet + DTW (SN+DTW) on the dance-music alignment task. 4.2. Lip-speech Alignment Settings T o e valuate our model on the lip-speech align- ment task, we assemble a subset from the V oxCeleb2 dataset [5], which is an audio-visual dataset consisting of short clips of human speech extracted from Y ouT ube videos. W e select and cut 22000 video clips of length 12 seconds and with 25 fps, mounting to 73 hours in total. The dataset contains 333 different identities and a wide range of ethnicity and languages. The dataset split is as follows: the training set has 18000 clips, and the v alidation and test- ing sets each have 2000 clips. The sets are exclusi vely video-disjoint, and there is no overlap between any pair of videos from any two sets. Similar to Dance50 , to deal with the noisy frame-wise results, we first remov e the out- lier keypoints by performing median filtering and then the missing values are linearly interpolated and smoothed with a Savitzky-Golay filter . Again, we compare our method against the state-of-the-art baselines using the ev aluation metrics mentioned above, and all methods are trained with online sample generation and data augmentation, for 500 epochs, and the best performing model on the validation set is selected for testing. Results Similar to Section 4.1, we sho w the mean motion error and location error of each lip k eypoint after alignment in Figure 5. Ke ypoints labels are the same as used in Open- Pose [3]. As sho wn in the figure, for both motion and loca- tion, our proposed method outperforms the baseline method consistently by a large mar gin for all the lip keypoints. T able 2 compares the performance of our method and the two baselines on subset of V oxCeleb2 testing set. Our method significantly reduces the AFE , and achiev es a gain of 45.11% in accuracy , which achiev es 81.05%. Note that here the AFE is similar to the AFE on Dance50 , but the Figure 5: Comparison of the performance (mean motion & location error) of our method and SyncNet + DTW (SN+DTW) on the lip-speech alignment task. Methods Performance AFE Accuracy SyncNet [6] 6.33 27.41 SyncNet+DTW [14] 3.96 35.94 AlignNet (Ours) 1.03 81.05 T able 2: Performance of speech-lip alignment on V ox- Celeb2 dataset. Figure 6: Qualitative results of the ground truth distortion compared to the predicted distortions by SyncNet-DTW and our method. Left: dance-music alignment, Right: lip- speech alignment. accuracy on Dance50 is much higher . This is because the frame rates of the two datasets are different (30 fps for Dance50 and 25 fps for V oxCeleb2 ), and one frame in V ox- Celeb2 corresponds to a longer duration in ms. There- fore, these results do not suggest the relati ve dif ficulty of dance-music alignment and speech-lip alignment, but they together indicate that our proposed method for audio-video alignment works well in dif ferent application scenarios. Methods Performance AFE Accuracy Base 2.87 43.57 FP 2.45 56.88 FP+MI 1.81 67.49 FP+MI+SA 1.32 75.33 FP+MI+SA+T A 1.14 79.65 FP+MI+SA+KA 0.97 88.20 FP+MI+SA+KA+T A 0.94 89.60 T able 3: Ablation study on dance-music alignment by adding these modules sequentially: Base (base model), FP (feature pyramid), MI (motion inputs, velocity and accel- eration), SA (spectrogram augmentation), KA (keypoint at- tention) and T A (temporal attention). Similar to the dance-music alignment task, we plot an example of the ground truth distortion compared to the dis- tortion predicted by DTW and our method in the bottom part of Figure 6 (Right). This result clearly shows that our method recov er the distorted video at a very high accuracy . 4.3. Ablation Study T o sho w the effecti veness of each module in our method, we conduct an ablation study on the Dance50 dataset, where we add the modules sequentially to the pipeline and ev aluate the performance. The training setup is the same as before. W e start with a basic network, denoted as base, where direct pose keypoints are fed in as inputs and no feature pyramid is used, predicting the correspondence directly from an affin- ity map. Then, the following modules are added sequen- tially to the network: FP (feature pyramid), MI (motion in- puts, velocity and acceleration), SA (spectrogram augmen- tation from [21]), KA (ke ypoint attention) and T A (temporal attention). T able 3 shows the results of the ablation exper - iments. It is clear that both feature pyramid and motion inputs boost the performance of the network by a large mar- gin, and spectrogram augmentation further helps the net- work to learn meaningful feature e ven when some temporal and frequency information are missing and helps alleviate ov erfitting. Both ke ypoints attention and temporal attention can im- prov e the alignment performance. This means some key- points and time steps are more important for alignment. And focusing on these spatial temporal regions will signifi- cantly improv e the performance. Howe ver , temporal atten- tion is not as effecti ve as keypoints attention. One possi- ble reason is that most music pieces have fixed and simi- lar beats, which can be implicitly encoded in the network without temporal attention module. Thus, adding tempo- ral might have limited improvement. On the other hand, Figure 7: Keypoint attention visualization for the dance- music alignment task. Circle sizes and bar lengths represent the attention magnitudes on human keypoints. motion rhythms are not always as clear as music beats, i.e. dancer might dance dif ferently giv en the same music piece. Thus, focusing on specific keypoints can significantly im- prov e the performance of our proposed module. 4.4. Attention V isualizations Keypoint Attention W e visualize the learned keypoint at- tentions by our model for the dance-music alignment task in Figure 7, where a skeleton visualization is presented along- side the histogram of the attention values after softmax. A circle is drawn around each keypoint, and the radii are larger for keypoints with larger attention v alues. Results show the attention for eyes and limbs (elbows, wrists, knees, ankles) are significantly larger than the attention for the bulk of the body (chest, shoulders, hip). The network has learnt to rely more on the limbs whose movements are more rapid, and less on the bulk parts that seldom mov ed very fast. W e also note that the network assigns more attention to the eyes but very little to head or ears. A possible explanation for this is that the mov ements of head (like turns) is best represented by tracking two eyes, rather than ears that are sometimes occluded. T emporal Attention Figure 8 shows the temporal atten- tion on an example audio mel-spectrogram. As can be seen, the attention module tends to focus more on the onsets of a music piece which can be easily understood since dancers always switch motion pattern at these onsets. Thus, focus- ing more on these temporal regions can help with better alignment. 4.5. Dance and Speech Retargeting By time-warping the visual beats of existing dance footage into alignment with new music, we can change the song that a performer is dancing to, which is kno wn as danc- ing retargeting. W e generate 7 e valuation pairs for dance retargeting ev aluation. Each pair contains a dancing video directly combined with another music piece and the same Figure 8: Mel-spectrogram (top), onset env elop (middle), and temporal attention (bottom) on a sample audio. Atten- tion magnitudes agree with audio onsets. T ask Percentage Direct Combination Ours Dance Retargeting 31% 69% Speech Retargeting 22% 78% T able 4: Subjectiv e user study for dance and speech retar - geting. video retar geted according to the audio using AlignNet. W e ask 13 people for their preference of all the ev aluation pairs, and the result is shown in T able 4. Similarly , we gener- ate 7 ev aluation pairs for speech retargeting e valuation. It’ s worth noticing that in these speech pairs, both videos say the same sentence since it is not reasonable to align talking f ace with dif ferent sentences. As can be seen in T able 4, sub- jects prefer ours to direct combinations, which means that our method can generalize well to real-world data. How- ev er, our method performs slightly worse in dance retarget- ing. The main reason is most dancing musics have simi- lar beats and direct combination can achieve decent perfor- mance. Demo videos of both the retargeting task and the synthetic re-alignment task can be found in the supplemen- tary materials and on our webpage. 5. Conclusion In conclusion, we proposed AlignNet, an end-to-end model to address the problem of audio-video alignment at arbitrary temporal scale. The approach adopts the follo w- ing principles: attention, pyramidal processing, warping, and affinity function. AlignNet establishes new state-of- the-art performance on dance-music alignment and speech- lip alignment. W e hope our work can inspire more studies in video and audio synchronization under non-uniform and irregular misalignment ( e .g. dancing). A ppendix 1: Dance50 Dataset W e introduce Dance50 dataset for dance-music align- ment. The dataset contains 50 hours of dancing clips from ov er 200 dancers. There are 20,000 6-second videos in the training set, 5,000 in the v alidation set, and 5,000 in the testing set. Our training, v alidation, and testing sets contain disjoint videos, such that there is no overlap between the videos from any two sets. Dataset collection In the construction of the Dance50 dataset, we focus on dancing videos in which the visual dynamics and audio beats are closely coupled and well synchronized. Therefore, we crawled K-pop dance cover videos performed by experienced dancers from Y ouT ube and Bilibili . All videos hav e a video frame rate of 30 fps and an audio sampling rate of 44,100 Hz. The videos are then cut into 6-second clips (180 frames per clip). W e further fil- ter the video clips to include only high-quality samples sat- isfying the following requirements: (1) single-person, (2) minimal or no camera mov ement, (3) full size shots with minimal or no occlusion of body parts. These restrictions av oids the problem of person tracking / ReID and keeps the dataset clean from excessi ve external noise. Dataset annotations Similar to [13], we represent our an- notations of the dancers’ pose over time with a temporal sequence of 2D skeleton keypoints, obtained using Open- Pose [3] BOD Y 25 model. W e then discard 3 very noisy keypoints from each foot, keeping 19 k eypoints to represent poses. T o cope with the noisy frame wise results, we first re- mov e the outlier keypoints by performing median filtering, and then the missing values are linearly interpolated and smoothed with a Savitzky-Golay filter . W e provide these annotations with the videos at 30 fps. Furthermore, the quality of these annotations are checked by comparing de- tected keypoints with manually labeled keypoints on a sub- set of the training data. A ppendix 2:More Experiments Pose Attention Ke ypoint L1 error (normalized) Location V elocity Ours SN+DTW Ours SN+DTW Head 0.128 0.412 0.112 0.209 Chest 0.146 0.433 0.137 0.246 Left Shoulder 0.139 0.426 0.127 0.232 Left Elbow 0.128 0.429 0.099 0.205 Left Wrist 0.119 0.422 0.085 0.186 Right Shoulder 0.139 0.427 0.128 0.233 Right Elbow 0.127 0.424 0.101 0.205 Right Wrist 0.118 0.418 0.086 0.186 Mid Hip 0 0 0 0 Left Hip 0.166 0.432 0.189 0.302 Left Knee 0.131 0.406 0.116 0.220 Left Ankle 0.121 0.400 0.096 0.197 Right Hip 0.167 0.434 0.191 0.305 Right Knee 0.131 0.405 0.116 0.219 Right Ankle 0.121 0.398 0.096 0.196 Left Eye 0.128 0.411 0.112 0.209 Right Eye 0.128 0.411 0.112 0.209 Left Ear 0.128 0.407 0.113 0.210 Right Ear 0.129 0.408 0.113 0.211 T able 5: Pose Attention. Lip Attention Figure 9: Lip attention V isualization Ke ypoint L1 error (normalized) Location V elocity Ours SN+DTW Ours SN+DTW 48 0.265 0.441 0.188 0.295 49 0.306 0.471 0.235 0.355 50 0.326 0.482 0.262 0.388 51 0.318 0.468 0.258 0.380 52 0.324 0.479 0.260 0.386 53 0.305 0.470 0.236 0.355 54 0.266 0.441 0.189 0.296 55 0.292 0.456 0.225 0.339 56 0.318 0.478 0.252 0.376 57 0.312 0.463 0.251 0.371 58 0.318 0.475 0.253 0.375 59 0.290 0.453 0.224 0.335 60 0.272 0.444 0.199 0.306 61 0.343 0.502 0.280 0.409 62 0.318 0.466 0.255 0.379 63 0.340 0.498 0.276 0.405 64 0.272 0.444 0.200 0.308 65 0.339 0.497 0.278 0.406 66 0.318 0.466 0.255 0.379 67 0.340 0.498 0.280 0.408 T able 6: Lip Attention References [1] D. P . Bertsekas, D. P . Bertsekas, D. P . Bertsekas, and D. P . Bertsekas. Dynamic pro gramming and optimal control , vol- ume 1. Athena scientific Belmont, MA, 1995. [2] H. Bredin and G. Chollet. Audiovisual speech synchrony measure: application to biometrics. EURASIP Journal on Applied Signal Pr ocessing , 2007(1):179–179, 2007. [3] Z. Cao, G. Hidalgo, T . Simon, S.-E. W ei, and Y . Sheikh. OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields. In arXiv preprint , 2018. [4] H.-K. Chiu, E. Adeli, B. W ang, D.-A. Huang, and J. C. Niebles. Action-agnostic human pose forecasting. 2019 IEEE W inter Confer ence on Applications of Computer V ision (W ACV) , pages 1423–1432, 2018. [5] J. S. Chung, A. Nagrani, and A. Zisserman. V oxceleb2: Deep speaker recognition. In INTERSPEECH , 2018. [6] J. S. Chung and A. Zisserman. Out of time: automated lip sync in the wild. In Asian conference on computer vision , pages 251–263. Springer , 2016. [7] S.-W . Chung, J. S. Chung, and H.-G. Kang. Perfect match: Improv ed cross-modal embeddings for audio-visual syn- chronisation. ICASSP 2019 - 2019 IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , pages 3965–3969, 2018. [8] A. Davis and M. Agrawala. V isual rhythm and beat. ACM T ransactions on Graphics (T OG) , 37(4):122, 2018. [9] F . De la T orre. A least-squares frame work for component analysis. IEEE T ransactions on P attern Analysis and Ma- chine Intelligence , 34(6):1041–1055, 2012. [10] A. Ephrat, I. Mosseri, O. Lang, T . Dekel, K. Wilson, A. Hassidim, W . T . Freeman, and M. Rubinstein. Look- ing to listen at the cocktail party: A speaker-independent audio-visual model for speech separation. arXiv pr eprint arXiv:1804.03619 , 2018. [11] S. Furukawa, T . Kato, P . Savkin, and S. Morishima. V ideo reshuffling: Automatic video dubbing without prior knowl- edge. In ACM SIGGRAPH 2016 P osters , SIGGRAPH ’16, pages 19:1–19:2, New Y ork, NY , USA, 2016. A CM. [12] R. Gao and K. Grauman. 2.5 d visual sound. In Pr oceed- ings of the IEEE Conference on Computer V ision and P attern Recognition , pages 324–333, 2019. [13] S. Ginosar , A. Bar , G. K ohavi, C. Chan, A. Owens, and J. Malik. Learning individual styles of con versational ges- ture. In Computer V ision and P attern Recognition (CVPR) . IEEE, June 2019. [14] T . Halperin, A. Ephrat, and S. Peleg. Dynamic temporal alignment of speech to lips. In ICASSP 2019-2019 IEEE International Confer ence on Acoustics, Speec h and Signal Pr ocessing (ICASSP) , pages 3980–3984. IEEE, 2019. [15] B. King, P . Smaragdis, and G. J. Mysore. Noise-robust dy- namic time warping using plca features. In 2012 IEEE Inter - national Confer ence on Acoustics, Speech and Signal Pro- cessing (ICASSP) , pages 1973–1976. IEEE, 2012. [16] J. Lewis. Automated lip-sync: Background and tech- niques. The Journal of V isualization and Computer Anima- tion , 2(4):118–122, 1991. [17] B. LUCAS. An iterative image registratio technique with an application to stereo vision. In Proceedings of 7th In- ternational J oint Confer ence on Artificial Intelligence , 1981 , pages 674–679, 1981. [18] Y .-J. Luo, M.-T . Chen, T .-S. Chi, and L. Su. Singing voice correction using canonical time warping. In 2018 IEEE In- ternational Confer ence on Acoustics, Speec h and Signal Pr o- cessing (ICASSP) , pages 156–160. IEEE, 2018. [19] A. Nagrani, J. S. Chung, and A. Zisserman. V oxceleb: a large-scale speaker identification dataset. T elephony , 3:33– 039, 2017. [20] A. Owens and A. A. Efros. Audio-visual scene analysis with self-supervised multisensory features. In Pr oceedings of the Eur opean Confer ence on Computer V ision (ECCV) , pages 631–648, 2018. [21] D. S. Park, W . Chan, Y . Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V . Le. Specaugment: A simple data aug- mentation method for automatic speech recognition. ArXiv , abs/1904.08779, 2019. [22] L. R. Rabiner and B.-H. Juang. Fundamentals of speech r ecognition . Prentice Hall, 1993. [23] M. E. Sargin, Y . Y emez, E. Erzin, and A. M. T ekalp. Audio- visual synchronization and fusion using canonical correla- tion analysis. IEEE T ransactions on Multimedia , 9(7):1396– 1403, 2007. [24] D. Sun, X. Y ang, M.-Y . Liu, and J. Kautz. PWC-Net: CNNs for optical flo w using pyramid, warping, and cost volume. In Computer V ision and P attern Recognition (CVPR) , 2018. [25] G. T rigeorgis, M. A. Nicolaou, B. W . Schuller, and S. Zafeiriou. Deep canonical time warping for simultaneous alignment and representation learning of sequences. IEEE transactions on pattern analysis and machine intelligence , 40(5):1128–1138, 2017. [26] G. Trigeor gis, M. A. Nicolaou, S. Zafeiriou, and B. W . Schuller . Deep canonical time warping. In Pr oceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 5110–5118, 2016. [27] D. v . Vloed, J. Bouten, and D. A. van Leeuwen. Nfi-frits: A forensic speaker recognition database and some first experi- ments. [Sl]: ISCA Speaker and Language Characterization special inter est gr oup , 2014. [28] R. H. W oo, A. Park, and T . J. Hazen. The mit mobile device speaker verification corpus: data collection and preliminary experiments. In 2006 IEEE Odyssey-The Speaker and Lan- guage Reco gnition W orkshop , pages 1–6. IEEE, 2006. [29] H. Zhao, C. Gan, W .-C. Ma, and A. T orralba. The sound of motions. arXiv preprint , 2019. [30] H. Zhao, C. Gan, A. Rouditchenko, C. V ondrick, J. McDer- mott, and A. T orralba. The sound of pix els. In The Eur opean Confer ence on Computer V ision (ECCV) , September 2018. [31] F . Zhou and F . T orre. Canonical time warping for alignment of human beha vior . In Advances in neural information pro- cessing systems , pages 2286–2294, 2009.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment