오디오와 비주얼을 맞추는 통합 모델 AlignNet
AlignNet은 비균일하고 불규칙한 시간 왜곡을 가진 영상과 오디오를 엔드‑투‑엔드 방식으로 정밀하게 정렬한다. 키포인트 기반 영상 특징과 로그‑멜 스펙트로그램을 이용해 공간·시간 어텐션, 피라미드 특징 추출, 시간 워핑, 유사도 매핑을 순차적으로 수행하고, 다중 스케일에서 밀집 대응을 예측한다. 새로 만든 Dance50 데이터셋에서 기존 SyncNet·DTW 기반 방법보다 평균 프레임 오차와 정렬 정확도 모두 크게 개선되었다.
저자: Jianren Wang, Zhaoyuan Fang, Hang Zhao
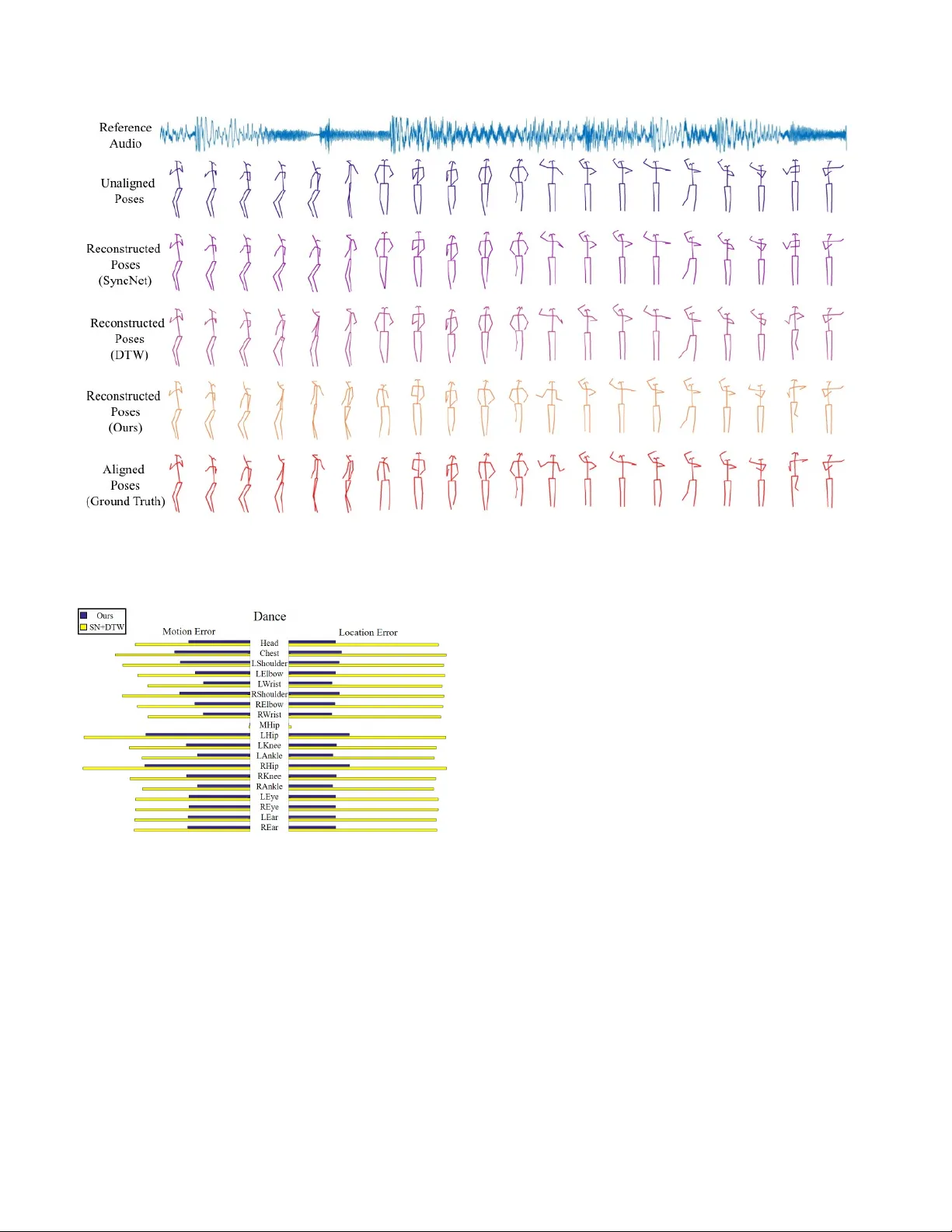
본 논문은 비균일하고 불규칙한 시간 왜곡을 가진 영상과 오디오를 정밀하게 동기화하는 새로운 모델 AlignNet을 제안한다. 기존 연구들은 주로 전역적인 시간 오프셋을 보정하거나, 비트 수준의 정렬에 머물러 비정형적인 미세 변형을 다루지 못했다. AlignNet은 이러한 한계를 극복하기 위해 엔드‑투‑엔드 방식으로 밀집 시간 대응(dense correspondence)을 직접 예측한다.
입력으로는 영상의 2‑D 키포인트(또는 입술 키포인트)와 로그‑멜 스펙트로그램을 사용한다. 키포인트는 OpenPose BODY 25 모델을 통해 추출하고, 속도·가속도 정보를 함께 제공함으로써 움직임의 동적 특성을 강조한다. 오디오는 128 차원의 로그‑멜 스펙트로그램으로 정규화한다.
모델 구조는 크게 다섯 부분으로 나뉜다. 첫 번째는 공간 어텐션과 시간 어텐션이다. 공간 어텐션은 각 키포인트에 가중치를 부여해 움직임이 큰 관절을 강조하고, 대칭 키포인트에 동일 가중치를 강제한다. 시간 어텐션은 오디오 시퀀스에 자체‑어텐션을 적용해 순간적인 비트 강도를 반영한다. 두 어텐션은 별도로 학습되며, 파라미터 효율성을 유지한다.
두 번째는 멀티스케일 피라미드 특징 추출이다. 영상과 오디오 각각에 4‑레벨 1‑D 컨볼루션 피라미드를 적용해 시간 해상도를 점진적으로 낮춘다(채널 128→64→32→16, 다운스케일 1/3, 1/2, 1/2, 1/2). 각 레벨에서 추출된 특징은 이후 단계에서 사용된다.
세 번째는 시간 워핑 레이어이다. 현재 레벨 l 에서 예측된 변위 dₗ₊₁를 상위 레벨의 오디오 특징에 역보간(up‑sampling)하여 정렬된 형태로 변환한다. 이 과정은 초기 거친 정렬을 점진적으로 정밀화하는 “잔여 오류 보정” 메커니즘으로 작동한다.
네 번째는 어피니티 매핑이다. 정규화된 영상·오디오 임베딩 사이의 내적을 계산해 유사도 행렬 A(j,i) = ⟨Fₗᵃⱼ, Fₗᵥᵢ⟩ 를 만든다. 이 행렬은 2‑D 컨볼루션을 거쳐 밀집 대응 d̂ₗ을 예측하는 입력으로 사용된다.
다섯 번째는 손실 설계이다. 각 레벨별 L1 회귀 손실 L_fₛ 은 예측 변위와 실제 변위 사이의 절대 차이를 최소화한다. 추가로 단조성 손실 L_mono 은 변위가 시간에 따라 비감소(또는 비증가)하도록 강제한다. 전체 손실은 loss = L_fₛ + μ L_mono 이며, μ는 단조성 제약의 가중치이다.
데이터 측면에서 저자들은 50시간 분량, 10 000개 이상의 12초 클립을 포함하는 Dance50 데이터셋을 구축했다. 키포인트는 OpenPose BODY 25 모델로 추출하고, 발 부분 6개는 노이즈가 많아 제외하였다. 학습 시에는 랜덤 속도 변형(가속·감속)과 선형 보간을 적용해 비균일 왜곡을 시뮬레이션하고, 영상은 좌우 대칭 플립, 오디오는 SpecAugment 기반 마스킹을 적용해 일반화 능력을 강화했다.
실험에서는 두 가지 과제(댄스‑음악 정렬, 입술‑음성 정렬)에서 AlignNet을 평가했다. 베이스라인으로는 원 논문 구현 SyncNet과 SyncNet+DTW를 사용했으며, 입력을 키포인트와 로그‑멜 스펙트로그램으로 교체해 동일 조건에서 비교했다. 정량적 평가는 방송 산업에서 정의한 인간이 감지할 수 없는 비동기 범위(−45 ms ~ +125 ms) 내 정렬 비율과 평균 프레임 오차(AFE)로 측정했다.
Dance50 테스트에서 AlignNet은 AFE를 0.94 프레임으로 낮추고, 정렬 정확도를 89.60 %까지 끌어올렸다. 이는 SyncNet(6.58 AFE, 25.88 % 정확도)과 SyncNet+DTW(4.27 AFE, 38.29 % 정확도) 대비 각각 5배 이상 개선된 수치다. 정성적 시각화에서도 AlignNet은 키포인트 궤적을 원본에 가깝게 복원했으며, 특히 비균일 가속·감속 구간에서 다른 방법이 크게 흐트러지는 반면 안정적인 정렬을 유지한다.
추가 실험으로는 정렬된 영상을 원본 음악에 맞춰 재생하는 리타게팅 실험과, 사용자 설문을 통한 주관적 평가를 수행했다. 사용자들은 AlignNet이 생성한 결과를 가장 자연스럽고 동기화가 잘 이루어졌다고 평가했다.
결론적으로 AlignNet은 어텐션, 피라미드, 워핑, 어피니티라는 네 가지 기본 원칙을 결합해 비디오·오디오 정렬 문제를 새로운 관점에서 해결한다. 비균일하고 불규칙한 시간 왜곡을 다루는 능력이 뛰어나며, 키포인트 기반 입력 덕분에 조명·배경·의상 변화에 강인하다. 향후 악기 연주와 영상, 손동작과 음성 등 다양한 멀티모달 정렬 과제에 적용 가능성이 크다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기