FPETS : Fully Parallel End-to-End Text-to-Speech System
End-to-end Text-to-speech (TTS) system can greatly improve the quality of synthesised speech. But it usually suffers form high time latency due to its auto-regressive structure. And the synthesised speech may also suffer from some error modes, e.g. r…
Authors: Dabiao Ma, Zhiba Su, Wenxuan Wang
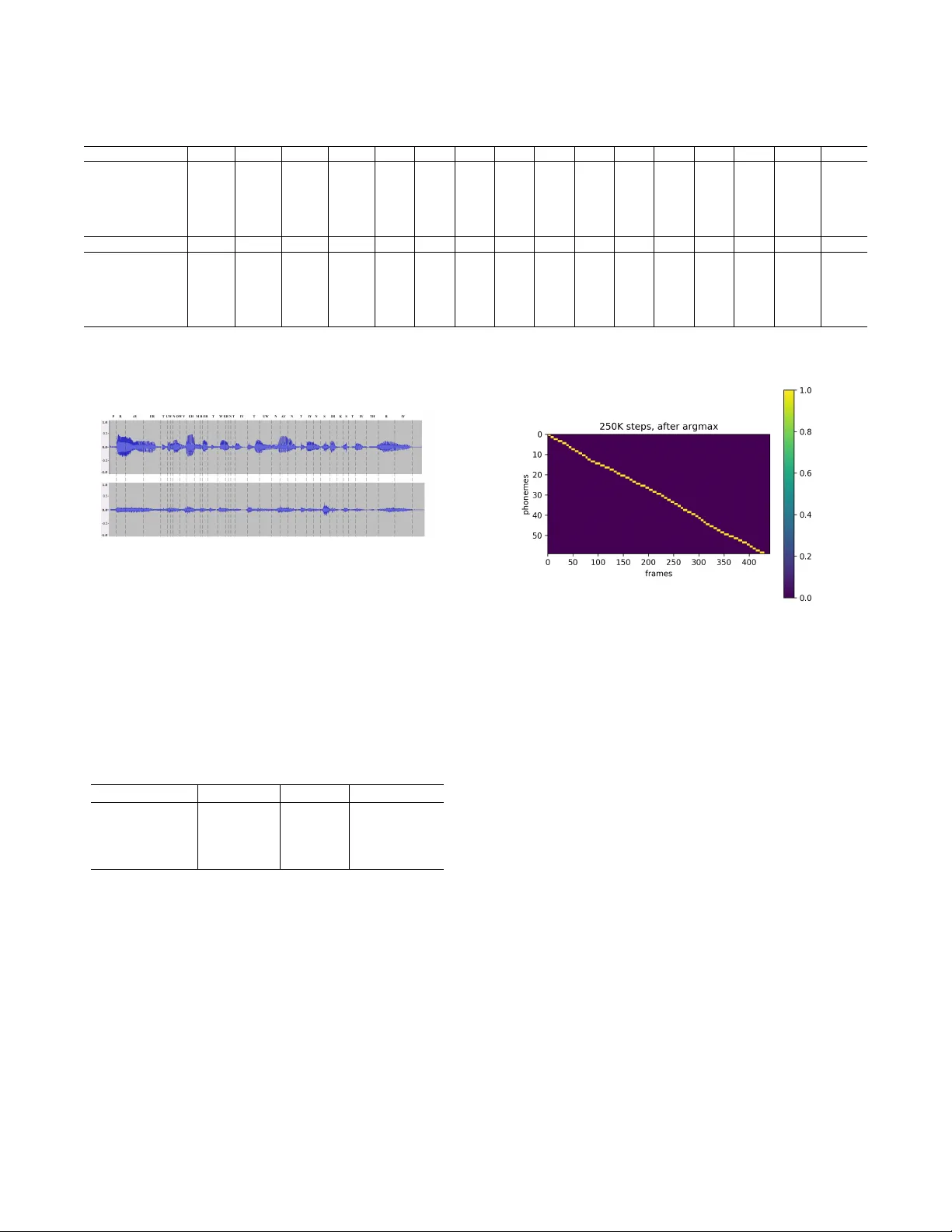
FPETS : Fully Parallel End-to-End T ext-to-Speech System Dabiao Ma ∗ 1 , Zhiba Su ∗ 1 , W enxuan W ang ∗ 2 , Y uhao Lu † 1 1 T uring Robot Co.,Ltd. Beijing, China { madabiao, suzhiba, luyuhao } @uzoo.cn 2 The Chinese Univ ersity of Hong K ong, Shenzhen. Guangdong, China wenxuanwang1@link.cuhk.edu.cn Abstract End-to-end T ext-to-speech (TTS) system can greatly improv e the quality of synthesised speech. But it usually suffers form high time latency due to its auto-regressi ve structure. And the synthesised speech may also suffer from some error modes, e.g. repeated words, mispronunciations, and skipped words. In this paper, we propose a novel non-autoregressi ve, fully parallel end-to-end TTS system (FPETS). It utilizes a ne w alignment model and the recently proposed U-shape con- volutional structure, UF ANS. Different from RNN, UF ANS can capture long term information in a fully parallel man- ner . Trainable position encoding and two-step training strat- egy are used for learning better alignments. Experimental re- sults show FPETS utilizes the power of parallel computa- tion and reaches a significant speed up of inference compared with state-of-the-art end-to-end TTS systems. More specifi- cally , FPETS is 600X faster than T acotron2, 50X faster than DCTTS and 10X faster than Deep V oice3. And FPETS can generates audios with equal or better quality and fewer errors comparing with other system. As far as we know , FPETS is the first end-to-end TTS system which is fully parallel. Introduction TTS systems aim to generate human-like speeches from texts. End-to-end TTS system is a type of system that can be trained on (text,audio) pairs without phoneme duration annotation(W ang et al. 2017). It usually contains 2 compo- nents, an acoustic model and a vocoder . Acoustic model pre- dicts acoustic intermediate features from texts. And vocoder , e.g. Griffin-Lim (Griffin et al. 1984), WORLD (MORISE, Y OKOMORI, and OZA W A 2016), W aveNet (v an den Oord et al. 2016b), synthesizes speeches with generated acoustic features. The advantages of end-to-end TTS system are threefold: 1) reducing manual annotation cost and being able to uti- lize raw data, 2) prev enting the error propagation between Copyright c 2020, Association for the Advancement of Artificial Intelligence (www .aaai.org). All rights reserved. 1 Dabiao Ma, Zhiba Su and W enxuan W ang hav e equal contri- butions. Y uhao Lu is the corresponding author . 2 Codes and demos will be released at https://github .com/ suzhiba/Full- parallel 100x real time End2EndTTS different components, 3) reducing the need of feature engi- neering. Howe ver , without the annotation of duration infor- mation, end-to-end TTS systems ha ve to learn the alignment between text and audio frame. Most competitiv e end-to-end TTS systems hav e an encoder-decoder structure with attention mechanism, which is significantly helpful for alignment learning. T acotron (W ang et al. 2017) uses an autoregressiv e attention (Bah- danau, Cho, and Bengio 2014) structure to predict align- ment, and uses CNNs and GR U (Cho et al. 2014) as encoder and decoder, respectively . T acotron2(Shen et al. 2018), which is a combination of the modified T acotron system and W av eNet, also use an autoregressi ve attention. Howe ver , the autoregressi ve structure greatly limits the inference speed in the context of parallel computation. Deep voice 3 (Ping et al. 2018) replaces RNNs with CNNs to speed up training and inference. DCTTS (T achibana, Uenoyama, and Aihara 2017) greatly speeds up the training of attention module by introducing guided attention. But Deep V oice 3 and DCTTS still have autoregressi ve structure. And those models also suffer from serious error modes e.g. repeated words, mis- pronunciations, or skipped words (Ping et al. 2018). Low time latency is required in real world application. Autoregressi ve structures, ho wever , greatly limit the infer- ence speed in the context of parallel computation. (Ping et al. 2018) claims that it is hard to learn alignment without a autoregressi ve structure. So the question is how to design a non-autoregressiv e structure that can perfectly determine alignment? In this paper , we propose a nov el fully parallel end- to-end TTS system (FPETS). Given input phonemes, our model can predict all acoustic frames simultaneously rather than autore gressiv ely . Specifically , we follow the commonly used encoder-decoder structure with attention mechanism for alignment. But we replace autoregressiv e structures with a recent proposed U-shaped conv olutional structure (UF ANS)(Ma et al. 2018), which can be fully parallel and has stronger representation ability . Our fully parallel align- ment structure inference alignment relationship between all phonemes and audio frames at once. Our novel trainable position encoding method can utilize position information better and two-step training strategy improves the alignment Figure 1: Model architecture. The light blue blocks are in- put/output flow . quality . Experimental results sho w FPETS utilizes the power of parallel computation and reaches a significant speed up of inference compared with state-of-the-art end-to-end TTS systems. More specifically , FPETS is 600X faster than T acotron2, 50X faster than DCTTS and 10X faster than Deep V oice3. And FPETS can generates audios with equal or better quality and fewer errors comparing with other sys- tem. As far as we know , FPETS is the first end-to-end TTS system which is fully parallel. Model Architectur e Most competiti ve end-to-end TTS systems ha ve an encoder- decoder structure with attention mechanism(W ang et al. 2017) (Ping et al. 2018). F ollowing this ov erall architecture, our model consists of three parts, shown in Fig.1. The en- coder conv erts phonemes into hidden states that are sent to decoder; The alignment module determines the alignment width of each phoneme, from which the number of frames that attend on that phoneme can be induced; The decoder re- ceiv es alignment information and conv erts the encoder hid- den states into acoustic features. Encoder The encoder encodes phonemes into hidden states. It con- sists of 1 embedding layer , 1 dense layer , 3 con volutional layers, and a final dense layer . Some of TTS systems(Li et al. 2018) use self attention network as encoder . But we find that it dose not make significant dif ference, both in loss value and MOS. Alignment module determines the mapping from phonemes to acoustic features. W e discard autoregres- siv e structure, which is widely used in other alignment modules(Ping et al. 2018)(W ang et al. 2017)(Shen et al. 2018), for time latency issue. Our novel alignment module consists of 1 embedding layer , 1 UF ANS (Ma et al. 2018) structure, trainable position encoding and se veral matrix multiplications, as depicted in Fig.1. Fully parallel UF ANS structure UF ANS is a modified version of U-Net for TTS task aiming to speed up infer- ence. The structure is sho wn in Fig.2.In alignment structure, UF ANS is used to predict alignment width, which is similar to phoneme duration.Those pooling and up-sampling opera- tion along the spatial dimension make the receptiv e field in- creases exponentially and high way connection enables the combination of different scales features. For each phoneme i , we define the ’Alignment Width’ r i which represents its relationship with frame numbers. Sup- pose the number of phonemes in an utterance is N , and UF ANS outputs a sequence of N scalars : [ r 0 , r 1 , ..., r N − 1 ] ; Then we relate the alignment width r i to the acoustic frame index j . The intuition is that the acoustic frame with index j = P i − 1 k =0 r k + 1 2 r i should be the one that attends most on i -th phoneme. And we need a structure that satisfies the intuition. Position Encoding Function Position encoding (Gehring et al. 2017) is a method to embed a sequence of absolute positions into a sequence of vectors. Sine and cosine posi- tion encoding has two very important properties that make it suitable for position encoding. In brief, function g ( x ) = P f cos ( x − s f ) has a heavy tail that enables one acoustic frame to receiv e phoneme information very far aw ay; The gradient function | ˙ g ( s ) | = | P f sin ( x − s f ) | is insensitive to the term x − s . W e giv e a more detailed illustration in Ap- pendix. T rainable Position Encoding Some end-to-end TTS system, like deep v oice 3 and T acotron2, use sine and cosine functions of different frequencies and add those position encoding vectors to input embedding. But they both take position encoding as a supplement to help the training of attention module and the position encoding vectors remain constant. W e propose a trainable position encoding, which is better than absolute position encoding in getting position information. W e define the absolute alignment position s i of i -th phoneme as : s i = i − 1 X k =0 r k + 1 2 r i , i = 0 , ..., T p − 1 , r − 1 = 0 (1) Figure 2: UF ANS Model Architecture Now choose L float numbers log uniformly from range [1 . 0 , 10000 . 0] and get a sequence of frequencies [ f 0 , ..., f L − 1 ] . For i -th phoneme, the position encoding vec- tor v p i of this phoneme is defined as : v p i = [ v p i,sin , vp i,cos ] , [ v p i,sin ] k = sin ( s i f k ) , [ v p i,cos ] k = cos ( s i f k ) , k = 0 , ..., L − 1 (2) Concatenating v p i , i = 0 , ..., T p − 1 together, we get a matrix P that represents position information of all the phonemes, denoted as ’Ke y’, see Fig.1 : P = [ v p T 0 , ..., v p T T p − 1 ] (3) And similarly , for the j -th frame of the acoustic feature, the position encoding vector va j is defined as : v a j = [ v a j,sin , va j,cos ] , [ v a j,sin ] k = sin ( j f k ) , [ v a i,cos ] k = cos ( j f k ) , k = 0 , ..., L − 1 (4) Concatenating all the vectors, we get the matrix F that rep- resents position information of all the acoustic frames, de- noted as ’Query’, see Fig.1: F = [ v a T 0 , ..., v a T T a − 1 ] (5) And now define the attention matrix A as : A = F P T , A j i = v p i v a T j , i = 0 , ..., T p − 1 , j = 0 , ..., T a − 1 (6) That is, the attention of j -th frame on i -th phoneme is pro- portional to the inner product of their encoding vectors. This inner product can be rewritten as : v p i v a T j = X f ( cos ( s i f ) cos ( j f ) + sin ( s i f ) sin ( j f )) = X f cos ( s i f − j f ) (7) It is clear when j = s i , the j -th frame is the one that attends most on i -th phoneme. The normalized attention matrix ˆ A is : ˆ A, ˆ A j i = A j i P i A j i (8) Now ˆ A j i represents ho w much j -th frame attends on i -th phoneme. Then we use argmax to b uild new attention matrix e A : e A j i = 1 if i = argmax k ∈ [0 ,...,T p − 1] A j k 0 otherwise (9) Now define the number of frames that attend more on i -th phoneme than any other phoneme to be its attention width w i . From the definition of attention width, e A is actually a matrix representing attention width w i . The alignment width r i and w i are different b ut related. For two adjacent absolute alignment positions s i and s i +1 , consider the two functions: g 1 ( x ) = X f cos ( x − s i f ) , g 2 ( x ) = X f cos ( x − s i +1 f ) The values of the two functions only depend on the rel- ativ e position of x to s i and s i +1 . It is known function g 1 decreases when x moves a way from s i (locally , but it is suf- ficient here). So we hav e: Figure 3: UF ANS Decoder g 1 ( x ) > g 2 ( x ) when x ∈ [ s i , 1 2 ( s i + s i +1 )) g 1 ( x ) < g 2 ( x ) when x ∈ ( 1 2 ( s i + s i +1 ) , s i +1 ] Thus x = 1 2 ( s i + s i +1 ) is the right attention boundary of phoneme i , similarly the left attention boundary is x = 1 2 ( s i − 1 + s i ) . It can be deduced that : w i = 1 2 ( s i + s i +1 ) − 1 2 ( s i − 1 + s i ) (10) = 1 4 ( r i − 1 + r i +1 + 2 r i ) (11) i = 0 , ..., T p − 1 , r − 1 = r 0 , r T p = r T P − 1 (12) which means attention width and alignment width can be linearly transformed to each other . And it is further deduced that : T p − 1 X k =0 r k = T p − 1 X k =0 w k = T a (13) UF ANS Decoder The decoder receiv es alignment information and con verts the encoded phonemes information to acoustic features, see Figure 3. Relativ e position is the distance between the phoneme and previous phoneme. Our model use it to en- hance position relationship. Follo wing (Ma et al. 2018), we use UF ANS as our decoder . The huge recepti ve field enables to capture long-time information dependency and the high- way skip connection structure enables the combination of different level of features. It generates good quality acoustic features in a fully parallel manner . T raining Strategy W e use Acoustic Loss, denoted as LO S S acou , to ev aluate the quality of generated acoustic features, which is L 2 norm between predicted acoustic features and ground truth fea- tures. In order to train a better alignment model, we propose a two-stage training strategy . Our model focus more on align- ment learning in stage 1. In stage 2 we fix the alignment module and train the whole system. Stage 1 :Alignment Learning In order to enhance the quality of alignment learning, we use con volutional decoder and design an alignment loss. Con volutional Decoder: UF ANS has stronger representation ability than vanilla CNN. But the learning of alignment will be greatly disturbed if using UF ANS as decoder . The e xperi- mental e vidences and analysis are sho wn in the next section. So we replace UF ANS decoder with a conv olutional de- coder . The con volutional decoder consists of se veral con- volution layers with gated activ ation (van den Oord et al. 2016a), sev eral Dropout (Sriv astav a et al. 2014) operations and one dense layer . Alignment Loss: W e define an Alignment Loss, denoted as LO S S alig n , based on the fact that the summation of align- ment width should be equal or close to the frame length of acoustic features. W e relax this restriction by using a thresh- old γ : LO S S alig n = γ , if | P T p − 1 k =0 r k − T a | < γ | P T p − 1 k =0 r k − T a | , otherwise (14) The final loss LO S S is a weighted sum of LO S S acou and LO S S alig n : LO S S = LO S S acou + σ LOS S alig n (15) W e choose 0 . 02 as alignment loss weight based on grid search from 0 . 005 to 0 . 3 . Stage 2 : Overall T raining In stage 2, we fix the well- trained alignment module and use UF ANS as decoder to train the overall end-to-end system. Only Acoustic Loss is used as objectiv e function in this stage. Experiments and Results Dataset LJ speech(Ito 2017) is a public speech dataset consisting of 13100 pairs of text and 22050 HZ audio clips. The clips vary from 1 to 10 seconds and the total length is about 24 hours. Phoneme-based textual features are gi ven. T wo kinds of acoustic features are extracted. One is based on WORLD vocoder that uses mel-frequency cepstral coef- ficients(MFCCs). The other is linear-scale log magnitude spectrograms and mel-band spectrograms that can be feed into Griffin-Lim algorithm or a trained W av eNet vocoder . The WORLD v ocoder uses 60 dimensional mel- frequency cepstral coefficients, 2 dimensional band aperi- odicity , 1 dimensional logarithmic fundamental frequency , T able 1: Hyper-P arameter Structure value Encoder/DNN Layers 1 Encoder/CNN Layers 3 Encoder/CNN Kernel 3 Encoder/CNN Filter Size 1024 Encoder/Final DNN Layers 1 Alignment/UF ANS layers 4 Alignment/UF ANS hidden 512 Alignment/UF ANS Kernel 3 Alignment/UF ANS Filter Size 1024 CNN Decoder/CNN Layers 3 CNN Decoder/CNN Kernel 3 CNN Decoder/CNN Filter Size 1024 UF ANS Decoder/UF ANS layers 6 UF ANS Decoder/UF ANS hidden 512 UF ANS Decoder/UF ANS Kernel 3 UF ANS Decoder/UF ANS Filter Size 1024 Droupout 0.15 their delta, delta-delta dynamic features and 1 dimensional voice/un voiced feature. It is 190 dimensions in total. The WORLD vocoder based feature uses FFT window size 2048 and has a frame time 5 ms. The spectrograms are obtained with FFT size 2048 and hop size 275. The dimensions of linear-scale log magnitude spectrograms and mel-band spectrograms are 1025 and 80. Implementation Details Hyperparameters of our model are showed in T able 1. T acotron2, DCTTS and Deep V oice3 are used as baseline . The model configurations are shown in Appendix. Adam are used as optimizer with β 1 = 0 . 9 , β 2 = 0 . 98 , = 1 e − 4 . Each model is trained 300k steps. All the experiments are done on 4 GTX 1080Ti GPUs, with batch size of 32 sentences on each GPU. Main Results W e aim to design a TTS system that can synthesis speech quickly , high quality and with fewer errors. So we compare our FPUTS with baseline on inference speed, MOS and error modes. Inference Speed The inference speed evaluates time la- tency of synthesizing a one-second speech, which includes data transfer from main memory to GPU global memory , GPU calculations and data transfer back to main memory . As is shown in T able 2, our FPETS model is able to greatly take advantage of parallel computations and is significantly faster than other systems. MOS Harv ard Sentences List 1 and List 2 are used to ev al- uate the mean opinion score (MOS) of a system. The syn- thesized audios are ev aluated on Amazon Mechanical T urk using crowdMOS method (Protasio Ribeiro et al. 2011). The score ranges from 1 (Bad) to 5 (Excellent). As is shown in T able 2: Inference speed comparison Method Autoregressi ve Inference speed (ms) T acotron2 Y es 6157.3 DCTTS Y es 494.3 Deep V oice 3 Y es 105.4 FPETS No 9.9 T able 3: MOS results comparison Method V ocoder MOS T acotron2 Griffin Lim 3 . 51 ± 0 . 070 DCTTS Grif fin Lim 3 . 55 ± 0 . 107 Deep V oice 3 Griffin Lim 2 . 79 ± 0 . 096 FPETS Griffin Lim 3 . 65 ± 0 . 082 T acotron2 W av eNet 3 . 04 ± 0 . 103 DCTTS W av eNet 3 . 43 ± 0 . 109 FPETS W av eNet 3 . 27 ± 0 . 108 FPETS WORLD 3 . 81 ± 0 . 122 T able 4: Robustness Comparison Repeats Mispronunciation Skip T acotron2 2 5 4 DCTTS 2 10 1 Deep V oice 3 1 5 3 FPETS 1 2 1 T able 3, Our FPETS is no worse than other end-to-end sys- tem. The MOS of W aveNet-based audios are lo wer than ex- pected since background noise exists in these audios. Robustness Analysis Attention-based neural TTS sys- tems may run into several error modes that can reduce synthesis quality . For example, repetition means repeated pronunciation of one or more phonemes, mispronunciation means wrong pronunciation of one or more phonemes and skip word means one or more phonemes are skipped. In order to track the occurrence of attention errors, 100 sentences are randomly selected from Los Angeles Times, W ashington Post and some fairy tales. As is shown in T a- ble 4, Our FPETS system is more rob ust than other systems. Alignment Learning Analysis Alignment learning is essential for end-to-end TTS system which greatly affects the quality of generated audios. So we further discuss the factors that can affect the alignment qual- ity . 100 audios are randomly selected from training data, de- noted as origin audios. Their utterances are fed to our sys- tem to generate audios, denoted as re-synthesized audios. The method to ev aluate the alignment quality is objectiv ely computing the difference of the phoneme duration between origin audios and their corresponding re-synthesized audios. The phoneme durations are obtained by hand. Figure 4 is the labeled phonemes of audio ’LJ048-0033’. Here only re- sults with mel-band spectrograms using Griffin-Lim algo- rithm are shown. F or MFCCs, results are similar . W e compare alignment quality between different align- ment model configurations. T able 6 shows the o verall results T able 5: A case study about phoneme-lev el comparison of alignment quality . Real duration and the predicted duration by our alignment method, using Gaussian as position encoding function, using fixed position encoding, using UF ANS as decoder are shown. P R A Y ER T UW N OW V EH M B ER T W EH real 5.35 7.28 15.48 13.43 4.96 3.44 3.36 5.44 4.72 7.20 4.56 1.92 7.12 5.36 3.36 3.84 resynth 3.55 7.97 13.28 11.37 4.88 4.00 6.19 5.27 5.46 6.39 3.56 2.08 6.13 5.69 4.34 3.03 resynth-Gauss 6.31 6.03 5.78 6.11 6.59 6.73 6.74 6.76 6.75 6.75 6.77 6.80 6.84 6.82 6.79 6.78 resynth-fixenc 7.41 7.35 11.40 10.46 4.04 4.60 2.95 6.41 4.30 7.86 5.26 2.45 9.21 6.77 3.90 2.85 resynth-UF ANS 4.08 8.09 9.41 8.45 6.90 5.70 5.21 5.71 5.98 5.29 4.87 5.20 5.43 5.14 5.10 5.37 IY T UW N A Y N T IY N S IH K S T IY TH real 10.80 9.76 9.76 6.80 6.08 6.16 7.28 5.28 5.36 6.56 6.16 4.08 3.52 6.32 9.36 9.76 resynth 10.89 11.26 9.69 7.72 5.33 6.55 7.30 5.90 5.81 5.43 5.11 4.33 3.57 6.81 10.57 11.54 resynth-Gauss 6.78 6.79 6.77 6.75 6.76 6.74 6.72 6.74 6.76 6.80 6.84 6.82 6.79 6.78 6.77 6.81 resynth-fixenc 12.05 9.21 8.26 5.76 6.90 7.63 6.47 3.20 4.74 4.11 5.85 2.97 4.01 5.29 11.26 10.60 resynth-UF ANS 7.14 7.38 8.96 8.20 5.39 5.54 7.31 6.34 5.56 6.42 5.84 4.76 5.62 7.61 8.26 8.17 on 100 audios. T able 5 is a case study which shows how phoneme-lev el duration is affected by dif ferent model. Figure 4: The upper is real audio of ’LJ048-0033’, the lo wer is the re-synthesized audio from alignment learning model. text : prior to No vember twenty two nineteen sixty three phoneme : P R A Y ER T UW N O W V EH M B ER T W EH N T IY T UW N A Y N T IY N S IH K S T IY TH R IY T able 6: Comparison of alignment quality between dif ferent configurations. Sine-Cosine or Gaussian encoding function, trainable or fixed position encoding and CNN or UF ANS decoder are ev aluated based on their average difference be- tween their duration prediction and real duration length on 100 audios. Encoding func T rainable? Decoder A verage-diff Gaussian T rainable CNN 2.58 Sin-Cos Fixed CNN 1.96 Sin-Cos T rainable UF ANS 1.80 Sin-Cos T rainable CNN 0.85 Position Encoding Function and Alignment Quality W e replace the Sine and Cosine position encoding function with Gaussian function. As T able 6 shows, the experimental re- sults show that the model can not learn correct alignment with Gaussian function. W e giv e a theoretical analysis in Appendix. T rainable Position Encoding and Alignment Quality W e replace the trainable position encoding with a fixed posi- tion encoding. The experimental results sho w that the model can learn better alignment with trainable position encoding. Figure 5: Attention plot of text : This is the destination for all things related to dev elopment at stack overflo w . Phoneme : DH IH S IH Z DH AH D EH S T AH N EY SH AH N F A O R A O L TH IH NG Z R IH L EY T IH D T UW D IH V EH L AH P M AH N T AE T S T AE K OW V ER F L O W . Decoder and Alignment Quality In order to identify the relationship between decoder and alignment quality in stage 1, we replace simple con volutional decoder by UF ANS with 6 down-sampling layers. Experiments show the computed attention width is much w orse than that with the simple con- volutional decoder . And the synthesized audios also suffer from error modes like repeated words and skipped words. The results show the simple decoder may be better in align- ment learning stage. More details are shown in T able 6. W ith UF ANS decoder, our model can get comparable loss no mat- ter that the alignment is accurate or not. Therefore, align- ment isn’ t well trained with UF ANS decoder . Human is sen- sitiv e to phoneme speed, so speech will be terrible if dura- tion in inaccurate. T o solve the problem, we train the align- ment with simple CNNs, then fix the alignment structure. W ith the fixed alignment and UF ANS decoder, our model can generate high quality audio in a parallel way . Related W orks FastSpeech (Ren et al. 2019),which is proposed in same period, can also generate acoustic features in a parallel way . Specifically , it extract attention alignments from an auto-regressi ve encoder-decoder based teacher model for phoneme duration prediction, which is used by a length reg- ulator to expand the source phoneme sequence to match the length of the target mel-spectrogram sequence for parallel mel-spectrogram generation. Using the phoneme duration extracted from an teacher model is a creative work to solve the problem that model can’ t inference in a parallel way . Howe ver , it’ s speed is still not fast enough to satisfy indus- trial application, especially it can’ t speed up when batch size is increased. Our FPETS has lo wer time latency and faster than Fast- Speech. On average FPETS generates 10ms per sentence under GTX 1080ti GPU and FastsSpeech is 25ms per sen- tence under T esla V100 GPU, which is known faster than GTX 1080ti. And FPETS can also automatically specify the phoneme duration by trainable position encoding. Conclusion In this paper , a new non-autoregressiv e, fully parallel end- to-end TTS system, FPETS, is proposed. Gi ven input phonemes, FPETS can predict all acoustic frames simul- taneously rather than autoregressi vely . Specifically FPETS utilize a recent proposed U-shaped conv olutional structure, which can be fully parallel and has stronger representa- tion ability . The fully parallel alignment structure infer- ence alignment relationship between all phonemes and au- dio frames at once. The novel trainable position encoding method can utilize position information better and two-step training strategy impro ves the alignment quality . FPETS can utilize the power of parallel computation and reach a significant speed up of inference compared with state-of-the-art end-to-end TTS systems. More specif- ically , FPETS is 600X faster than T acotron2, 50X faster than DCTTS and 10X faster than Deep V oice3. And FPETS can generates audios with equal or better quality and fewer errors comparing with other system. As far as we know , FPETS is the first end-to-end TTS system which is fully par- allel. References Bahdanau, D.; Cho, K.; and Bengio, Y . 2014. Neural ma- chine translation by jointly learning to align and translate. arXiv e-prints abs/1409.0473. Cho, K.; van Merri ¨ enboer , B.; G ¨ ulc ¸ ehre, C ¸ .; Bahdanau, D.; Bougares, F .; Schwenk, H.; and Bengio, Y . 2014. Learning phrase representations using rnn encoder–decoder for statis- tical machine translation. In Proceedings of the 2014 Con- fer ence on Empirical Methods in Natural Language Pr o- cessing (EMNLP) , 1724–1734. Doha, Qatar: Association for Computational Linguistics. Gehring, J.; Auli, M.; Grangier , D.; Y arats, D.; and Dauphin, Y . 2017. Con volutional sequence to sequence learning. In ICML . Griffin, D. W .; Jae; Lim, S.; and Member, S. 1984. Sig- nal estimation from modified short-time fourier transform. IEEE T rans. Acoustics, Speech and Sig. Pr oc 236–243. Ito, K. 2017. The lj speech dataset. https://keithito.com/LJ- Speech- Dataset/. Li, N.; Liu, S.; Liu, Y .; Zhao, S.; Liu, M.; and Zhou, M. 2018. Close to human quality tts with transformer . ArXiv abs/1809.08895. Ma, D.; Su, Z.; Lu, Y .; W ang, W .; and Li, Z. 2018. Ufans: U- shaped fully-parallel acoustic neural structure for statistical parametric speech synthesis with 20x faster . arXiv pr eprint arXiv:1811.12208 . MORISE, M.; Y OKOMORI, F .; and OZA W A, K. 2016. W orld: A vocoder-based high-quality speech synthesis sys- tem for real-time applications. IEICE T ransactions on Infor- mation and Systems E99.D(7):1877–1884. Ping, W .; Peng, K.; Gibiansky , A.; Arik, S. O.; Kannan, A.; Narang, S.; Raiman, J.; and Miller, J. 2018. Deep voice 3: 2000-speaker neural text-to-speech. In International Con- fer ence on Learning Representations . Protasio Ribeiro, F .; Florencio, D.; Zhang, C.; and Seltzer , M. 2011. Crowdmos: An approach for cro wdsourcing mean opinion score studies. In ICASSP . IEEE. Ren, Y .; Ruan, Y .; T an, X.; Qin, T .; Zhao, S.; Zhao, Z.; and Liu, T . 2019. Fastspeech: Fast, robust and controllable text to speech. CoRR abs/1905.09263. Shen, J.; Pang, R.; W eiss, R. J.; Schuster, M.; Jaitly , N.; Y ang, Z.; Chen, Z.; Zhang, Y .; W ang, Y .; Skerrv-Ryan, R.; et al. 2018. Natural tts synthesis by conditioning wa venet on mel spectrogram predictions. In 2018 IEEE Interna- tional Confer ence on Acoustics, Speech and Signal Pr ocess- ing (ICASSP) , 4779–4783. IEEE. Sriv astav a, N.; Hinton, G.; Krizhe vsky , A.; Sutske ver , I.; and Salakhutdinov , R. 2014. Dropout: A simple way to pre- vent neural networks from overfitting. Journal of Machine Learning Resear ch 15:1929–1958. T achibana, H.; Uenoyama, K.; and Aihara, S. 2017. Ef- ficiently trainable text-to-speech system based on deep con volutional networks with guided attention. CoRR abs/1710.08969. van den Oord, A.; Kalchbrenner , N.; Espeholt, L.; kavukcuoglu, k.; V inyals, O.; and Graves, A. 2016a. Con- ditional image generation with pixelcnn decoders. In Lee, D. D.; Sugiyama, M.; Luxbur g, U. V .; Guyon, I.; and Gar - nett, R., eds., Advances in Neural Information Pr ocessing Systems 29 . Curran Associates, Inc. 4790–4798. van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; V inyals, O.; Grav es, A.; Kalchbrenner, N.; Senior , A. W .; and Kavukcuoglu, K. 2016b . W av enet: A generative model for raw audio. CoRR abs/1609.03499. W ang, Y .; Skerry-Ryan, R. J.; Stanton, D.; W u, Y .; W eiss, R. J.; Jaitly , N.; Y ang, Z.; Xiao, Y .; Chen, Z.; Bengio, S.; Le, Q. V .; Agiomyrgiannakis, Y .; Clark, R.; and Saurous, R. A. 2017. T acotron: A fully end-to-end text-to-speech synthesis model. CoRR abs/1703.10135.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment