완전 병렬 텍스트음성 변환 시스템 FPETS
FPETS는 자동회귀 구조를 배제하고 UFANS 기반의 완전 병렬 인코더‑디코더와 학습 가능한 위치 인코딩을 결합한 새로운 TTS 모델이다. 두 단계 학습 전략을 통해 정렬 품질을 향상시키고, 실험 결과 Tacotron2 대비 600배, DCTTS 대비 50배, Deep Voice 3 대비 10배 빠른 추론 속도를 달성하면서도 MOS와 오류 발생률 면에서 기존 최첨단 모델과 동등하거나 우수한 성능을 보였다.
저자: Dabiao Ma, Zhiba Su, Wenxuan Wang
**1. 서론 및 배경**
텍스트‑음성 변환(TTS)은 입력 텍스트를 자연스러운 음성으로 변환하는 기술로, 최근 엔드‑투‑엔드 방식이 주목받고 있다. Tacotron, Tacotron2, Deep Voice 3, DCTTS 등은 인코더‑디코더 구조와 어텐션 메커니즘을 활용해 텍스트와 오디오 프레임 사이의 정렬을 학습한다. 그러나 이들 모델은 대부분 자동회귀(autoregressive) 디코더를 사용해 프레임을 순차적으로 생성하므로 추론 시 높은 지연(latency)이 발생한다. 또한 어텐션 오류(반복, 오발음, 누락)도 빈번히 보고된다.
**2. 연구 목표**
본 논문은 자동회귀 구조를 완전히 배제하고, 완전 병렬 방식으로 텍스트‑음성 변환을 수행하면서도 정렬 품질과 음질을 유지하거나 향상시키는 모델을 제안한다. 이를 위해 (i) UFANS라는 U‑shape 컨볼루션 구조를 디코더와 정렬 모듈에 적용하고, (ii) 학습 가능한 위치 인코딩을 설계하며, (iii) 두 단계 학습 전략을 도입한다.
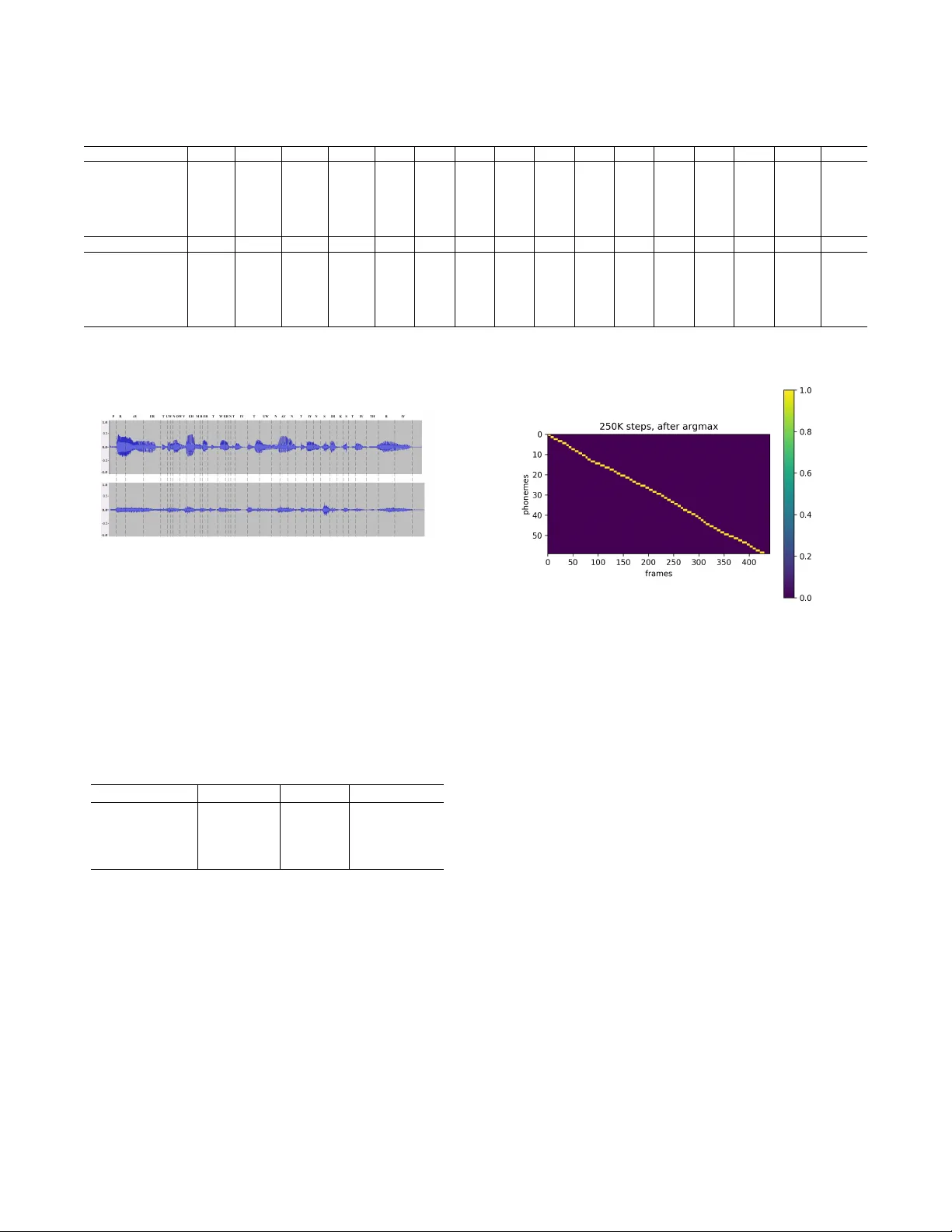
**3. 모델 아키텍처**
- **인코더**: 입력 phoneme을 임베딩 후 3개의 1‑D 컨볼루션과 전결합(dense) 레이어를 거쳐 은닉 표현 H를 만든다. self‑attention을 실험했지만 성능 차이가 없었다.
- **정렬 모듈**: UFANS(4개의 인코더‑디코더 블록, 각 블록은 풀링·업샘플링, 스킵 연결)으로 구성된다. UFANS는 정렬 폭 rᵢ(각 phoneme이 차지할 프레임 수)를 직접 예측한다.
- **위치 인코딩**: 기존 사인·코사인 절대 인코딩 대신, 로그 균등으로 샘플링한 주파수 집합 {fₖ}를 사용한다. 각 phoneme i에 대해 절대 정렬 위치 sᵢ = Σ_{k=0}^{i‑1} r_k + ½ r_i 를 정의하고, vₚᵢ =
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기