On the Utility of Learning about Humans for Human-AI Coordination
While we would like agents that can coordinate with humans, current algorithms such as self-play and population-based training create agents that can coordinate with themselves. Agents that assume their partner to be optimal or similar to them can co…
Authors: Micah Carroll, Rohin Shah, Mark K. Ho
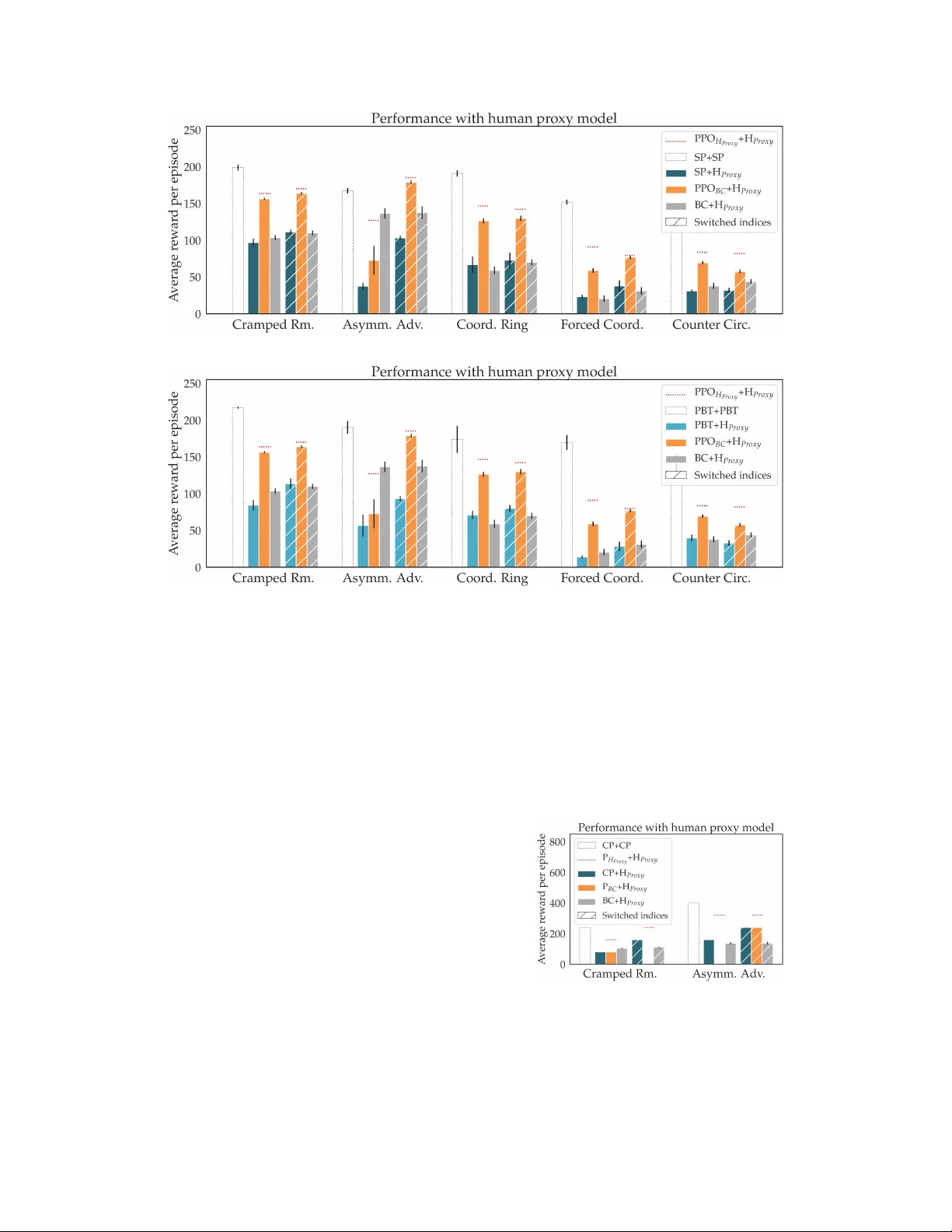
On the Utility of Lear ning about Humans f or Human-AI Coordination Micah Carroll UC Berkeley mdc@berkeley.edu Rohin Shah UC Berkeley rohinmshah@berkeley.edu Mark K. Ho Princeton Univ ersity mho@princeton.edu Thomas L. Griffiths Princeton Univ ersity Sanjit A. Seshia UC Berkeley Pieter Abbeel UC Berkeley Anca Dragan UC Berkeley Abstract While we would lik e agents that can coordinate with humans, current algorithms such as self-play and population-based training create agents that can coordinate with themselves . Agents that assume their partner to be optimal or similar to them can con v erge to coordination protocols that fail to understand and be understood by humans. T o demonstrate this, we introduce a simple en vironment that requires challenging coordination, based on the popular game Over cooked , and learn a simple model that mimics human play . W e e valuate the performance of agents trained via self-play and population-based training. These agents perform very well when paired with themselv es, but when paired with our human model, they are significantly worse than agents designed to play with the human model. An experiment with a planning algorithm yields the same conclusion, though only when the human-aw are planner is giv en the exact human model that it is playing with. A user study with real humans sho ws this pattern as well, though less strongly . Qualitativ ely , we find that the gains come from having the agent adapt to the human’ s gameplay . Giv en this result, we suggest sev eral approaches for designing agents that learn about humans in order to better coordinate with them. Code is av ailable at https://github.com/HumanCompatibleAI/overcooked_ai . 1 Introduction An increasingly effecti ve way to tackle two-player games is to train an agent to play with a set of other AI agents, often past versions of itself. This po werful approach has resulted in impressive performance against human experts in games like Go [ 33 ], Quake [ 20 ], Dota [ 29 ], and Starcraft [ 34 ]. Since the AI agents nev er encounter humans during training, when ev aluated against human experts, they are under going a distributional shift. Why doesn’t this cause the agents to f ail? W e hypothesize that it is because of the competitive nature of these games. Consider the canonical case of a two-player zero-sum game, as shown in Figure 1 (left). When humans play the minimizer role but take a branch in the search tree that is suboptimal, this only incr eases the maximizer’ s score. Howe ver , not all settings are competiti ve. Arguably , one of the main goals of AI is to generate agents that collaborate , rather than compete, with humans. W e would like agents that help people with the tasks they want to achiev e, augmenting their capabilities [ 10 , 6 ]. Looking at recent results, it is tempting to think that self-play-like methods extend nicely to collaboration: AI-human teams performed well in Dota [ 28 ] and Capture the Flag [ 20 ]. Ho we ver , in these games, the advantage may come from the AI system’ s individual ability , rather than from coordination with humans. W e claim that in general, collaboration is fundamentally dif ferent from competition, and will require us to go beyond self-play to e xplicitly account for human behavior . 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), V ancouv er , Canada. Figure 1: The impact of incorrect expectations of optimality . Left: In a competitiv e game, the agent plans for the worst case. AI expects that if it goes left, H will go left. So, it goes right where it e xpects to get 3 reward (since H would go left). When H suboptimally goes right, AI gets 7 re ward: mor e than it expected. Right: In a collaborativ e game, AI expects H to coordinate with it to choose the best option, and so it goes left to obtain the 8 rew ard. Howev er, when H suboptimally goes left, AI only gets 1 reward: the worst possible outcome! Consider the canonical case of a common-payoff game, sho wn in Figure 1 (right): since both agents are maximizers, a mistake on the human’ s side is no longer an advantage, but an actual problem, especially if the agent did not anticipate it. Further , agents that are allowed to co-train might con ver ge onto opaque coordination strategies. For instance, agents trained to play the collaborati ve game Hanabi learned to use the hint “red” or “yello w” to indicate that the ne west card is playable, which no human would immediately understand [ 12 ]. When such an agent is paired with a human, it will ex ecute the opaque policy , which may fail spectacularly when the human doesn’ t play their part. W e thus hypothesize that in true collaborati ve scenarios agents trained to play well with other AI agents will perform much more poorly when paired with humans. W e further hypothesize that incorporating human data or models into the training process will lead to significant improv ements. T o test this hypothesis, we introduce a simple en vironment based on the popular game Over cooked [ 13 ], which is specifically designed to be challenging for humans to coordinate in (Figure 2).W e use this en vironment to compare agents trained with themselves to agents trained with a learned human model. For the former , we consider self-play [ 33 ], population-based training [ 19 ], and coupled planning with replanning. For the latter , we collect human-human data and train a behavior cloning human model; we then train a reinforcement learning and a planning agent to collaborate well with this model. W e ev aluate how well these agents collaborate with a held-out “simulated” human model (henceforth the “proxy human”), trained on a different data set, as well as in a user study . Figure 2: Our Overcooked environment. The goal is to place three onions in a pot (dark grey), take out the resulting soup on a plate (white) and deliv er it (light grey), as many times as possible within the time limit. H , the human, is close to a dish dispenser and a cooked soup, and AI , the agent, is facing a pot that is not yet full. The optimal strategy is for H to put an onion in the partially full pot, and for AI to put the e xisting soup in a dish and deliv er it. This is due to the layout structure, that makes H hav e an advantage in placing onions in pots, and AI hav e an advantage in deli vering soups. Howe ver , we can guess that H plans to pick up a plate to deliv er the soup. If AI nonetheless expects H to be optimal, it will expect H to turn around to get the onion, and will continue moving to wards its own dish dispenser , leading to a coor dination failure . 2 W e find that the agents which did not leverage human data in training perform very well with themselves, and drastically worse when paired with the proxy human. This is not explained only by human suboptimality , because the agent also significantly underperforms a “gold standard” agent that has access to the proxy human. The agent trained with the behavior -cloned human model is drastically better , showing the benefit of having a relati vely good human model. W e found the same trends e ven when we paired these agents with real humans, for whom our model has much poorer predictiv e power b ut nonetheless helps the agent be a better collaborator . W e also experimented with using beha vior cloning directly for the agent’ s policy , and found that it also outperforms self-play-like methods, but still underperforms relati ve to methods that that le verage planning (with respect to the actual human model) or reinforcement learning with a proxy human model. Overall, we learned a fe w important lessons in this work. First, our results showcase the importance of accounting for real human behavior during training: e ven using a behavior cloning model prone to failures of distributional shift seems better than treating the human as if they were optimal or similar to the agent. Second, leveraging planning or reinforcement learning to maximize the collaborati ve rew ard, again ev en when using such a simple human model, seems to already be better than v anilla imitation. These results are a cautionary tale against relying on self-play or vanilla imitation for collaboration, and adv ocate for methods that le verage models of human beha vior, acti vely improv e them, or ev en use them as part of a population to be trained with. 2 Related W ork Human-robot interaction (HRI). The field of human robot interaction has already embraced our main point that we shouldn’t model the human as optimal. Much work focuses on achieving collaboration by planning and learning with (non-optimal) models of human beha vior [ 26 , 21 , 31 ], as well as on specific properties of robot beha vior that aid collaboration [ 2 , 14 , 9 ]. Ho wever , to our knowledge, ours is the first work to analyze the optimal human assumption in the context of deep reinforcement learning, and to test potential solutions such as population-based training (PBT). Choudhury et al. [7] is particularly related to our work. It ev aluates whether it is useful to learn a human model using deep learning, compared to a more structured “theory of mind” human model. W e are instead ev aluating how useful it is to ha ve a human model at all . Multiagent reinf orcement learning . Deep reinforcement learning has also been applied to multia- gent settings, in which multiple agents take actions in a potentially non-competiti ve game [ 24 , 15 ]. Some work tries to teach agents collaborati ve behaviors [ 22 , 18 ] in en vironments where rewards are not shared across agents. The Bayesian Action Decoder [ 12 ] learns communicati ve policies that allo w two agents to collaborate, and has been applied to the cooperativ e card game Hanabi. Ho we ver , most multiagent RL research focuses on AI-AI interaction, rather than the human-AI setting. Lerer and Peysakho vich [23] starts from the same observ ation that self-play will perform badly in general-sum games, and aims to do better gi ven some data from agents that will be ev aluated on at test time (analogous to our human data). Howe ver , they assume that the test time agents have settled into an equilibrium that their agent only needs to replicate, and so they train their agent with Observ ational Self-Play (OSP): a combination of imitation learning and MARL. In contrast, we allo w for the case where humans do not play an equilibrium strategy (because they are suboptimal), and so we only use imitation learning to create human models, and train our agent using pure RL. Imitation lear ning. Imitation learning [ 1 , 16 ] aims to train agents that mimic the policies of a demonstrator . In our work, we use beha vior cloning [ 30 ] to imitate demonstrations collected from humans, in order to learn human models to collaborate with. Howe ver , the main focus of our work is in the design of agents that can collaborate with these models, and not the models themselves. 3 Preliminaries Multi-agent MDP . A multiagent Markov decision process [ 5 ] is defined by a tuple h S, α, { A i ∈ α } , T , R i . S is a finite set of states, and R : S → R is a real-valued re ward function. α is a finite set of agents; A i is the finite set of actions av ailable to agent i . T : S × A 1 ×· · · × A n × S → [0 , 1] is a transition function that determines the next state gi ven all of the agents’ actions. 3 Figure 3: Experiment layouts. From left to right: Cramped Room presents low-le vel coordination challenges: in this shared, confined space it is very easy for the agents to collide. Asymmetric Advantages tests whether players can choose high-le vel strategies that play to their strengths , as illustrated in Figure 2. In Coor dination Ring , players must coordinate to trav el between the bottom left and top right corners of the layout. F or ced Coor dination instead removes collision coordination problems, and forces players to de velop a high-level joint strategy , since neither player can serve a dish by themselves. Counter Circuit inv olves a non-obvious coordination strategy , where onions are passed over the counter to the pot, rather than being carried around. Behavior cloning. One of the simplest approaches to imitation learning is gi ven by beha vior cloning, which learns a policy from e xpert demonstrations by directly learning a mapping from observations to actions with standard supervised learning methods [ 4 ]. Since we hav e a discrete action space, this is a traditional classification task. Our model takes an encoding of the state as input, and outputs a probability distribution o ver actions, and is trained using the standard cross-entropy loss function. Population Based T raining. Population Based Training (PBT) [ 19 ] is an online evolutionary algorithm which periodically adapts training hyperparameters and performs model selection. In multiagent RL, PBT maintains a population of agents, whose policies are parameterized by neural networks, and trained with a DRL algorithm. In our case, we use Proximal Policy Optimization (PPO) [ 32 ]. During each PBT iteration, pairs of agents are dra wn from the population, trained for a number of timesteps, and have their performance recorded. At the end of each PBT iteration, the worst performing agents are replaced with copies of the best agents with mutated hyperparameters. 4 En vironment and Agents 4.1 Over cooked T o test our hypotheses, we would lik e an environment in which coordination is challenging, and where deep RL algorithms work well. Existing environments ha ve not been designed to be challenging for coordination, and so we build a ne w one based on the popular video game Over cooked [ 13 ], in which players control chefs in a kitchen to cook and serve dishes. Each dish takes se veral high-lev el actions to deliv er, making strate gy coordination dif ficult, in addition to the challenge of motion coordination. W e implement a simplified version of the en vironment, in which the only objects are onions, dishes, and soups (Figure 2). Players place 3 onions in a pot, leav e them to cook for 20 timesteps, put the resulting soup in a dish, and serve it, giving all players a rew ard of 20. The six possible actions are: up, do wn, left, right, noop, and "interact", which does something based on the tile the player is facing, e.g. placing an onion on a counter . Each layout has one or more onion dispensers and dish dispensers, which provide an unlimited supply of onions and dishes respectiv ely . Most of our layouts (Figure 3) were designed to lead to either low-le vel motion coordination challenges or high-level strategy challenges. Agents should learn ho w to navig ate the map, interact with objects, drop the objects of f in the right locations, and finally serve completed dishes to the serving area. All the while, agents should be aware of what their partner is doing and coordinate with them ef fectiv ely . 4.2 Human models W e created a web interface for the game, from which we were able to collect trajectories of humans playing with other humans for the layouts in Figure 3. In preliminary experiments we found that human models learned through behavior cloning performed better than ones learned with Generativ e Adversarial Imitation Learning (GAIL) [ 16 ], so decided to use the former throughout our experiments. T o incentivize generalization in spite of the scarcity of human data, we perform behavior cloning ov er a manually designed featurization of the underlying game state. 4 For each layout we gathered ~16 human-human trajectories (for a total of 18k environment timesteps). W e partition the joint trajectories into two subsets, and split each trajectory into two single-agent trajectories. For each layout and each subset, we learn a human model through behavior cloning. W e treat one model, BC, as a human model we hav e access to, while the second model H P roxy is treated as the ground truth human proxy to ev aluate against at test time. On the first three layouts, when paired with themselves, most of these models perform similarly to an a verage human. Performance is significantly lower for the last tw o layouts (Forced Coordination and Counter Circuit). The learned models sometimes got “stuck”: they would perform the same action over and over again (such as walking into each other), without changing the state. W e added a simple rule-based mechanism to get the agents unstuck by taking a random action. For more details see Appendix A. 4.3 Agents designed for self-play W e consider two DRL algorithms that train agents designed for self-play , and one planning algorithm. DRL algorithms. For DRL we consider PPO trained in self-play (SP) and PBT . Since PBT in volves training agents to perform well with a population of other agents, we might expect them to be more robust to potential partners compared to agents trained via self-play , and so PBT might coordinate better with humans. For PBT , all of the agents in the population used the same network architecture. Planning algorithm. W orking in the simplified Ov ercooked en vironment enables us to also compute near-optimal plans for the joint planning problem of deli vering dishes. This establishes a baseline for performance and coordination, and is used to perform coupled planning with r e-planning . W ith coupled planning, we compute the optimal joint plan for both agents. Howe ver , rather than executing the full plan, we only execute the first action of the plan, and then replan the entire optimal joint plan after we see our partner’ s action (since it may not be the same as the action we computed for them). T o achiev e this, we pre-compute optimal joint motion plans for e very possible starting and desired goal locations for each agent. W e then create high-lev el actions such as “get an onion”, “serv e the dish”, etc. and use the motion plans to compute the cost of each action. W e use A ∗ search to find the optimal joint plan in this high-level action space. This planner does make some simplifying assumptions, detailed in Appendix E, making it near-optimal instead of optimal. 4.4 Agents designed for humans W e seek the simplest possible solution to having an agent that actually takes advantage of the human model. W e embed our learned human model BC in the environment, treating it’ s choice of action as part of the dynamics. W e then directly train a policy on this single-agent en vironment with PPO. W e found empirically that the policies achiev ed best performance by initially training them in self-play , and then linearly annealing to training with the human model (see Appendix C). For planning, we implemented a model-based planner that uses hierarchical A ∗ search to act near - optimally , assuming access to the policy of the other player (see Appendix F). In order to preserve near- optimality we make our training and test human models deterministic, as dealing with stochasticity would be too computationally expensi ve. 5 Experiments in Simulation W e pair each agent with the proxy human model and ev aluate the team performance. Independent variables. W e vary the type of agent used. W e hav e agents trained with themselves: self-play (SP), population-based training (PBT), coupled planning (CP); agents trained with the human model BC: reinforcement learning based (PPO B C ), and planning-based P B C ; and the imitation agent BC itself. Each agent is paired with H P roxy in each of the layouts in Figure 3. Dependent measures. As good coordination between teammates is essential to achiev e high returns in this environment, we use cumulati ve re wards ov er a horizon of 400 timesteps for our agents as a proxy for coordination ability . For all DRL experiments, we report av erage rewards across 100 rollouts and standard errors across 5 dif ferent seeds. T o aid in interpreting these measures, we also compute a "gold standard" performance by training the PPO and planning agents not with BC, b ut with H P roxy itself, essentially giving them access to the ground truth human they will be paired with. 5 (a) Comparison with agents trained in self-play . (b) Comparison with agents trained via PBT . Figure 4: Rew ards over trajectories of 400 timesteps for the dif ferent agents (agents trained with themselves – SP or PBT – in teal, agents trained with the human model – PPO B C – in orange, and imitation agents – BC – in gray), with standard error over 5 different seeds, paired with the proxy human H P r oxy . The white bars correspond to what the agents trained with themselves expect to achiev e, i.e. their performance when paired with itself (SP+SP and PBT+PBT). First, these agents perform much worse with the proxy human than with themselves. Second, the PPO agent that trains with human data performs much better , as hypothesized. Third, imitation tends to perform somewhere in between the two other agents. The red dotted lines show the "gold standard" performance achiev ed by a PPO agent with direct access to the proxy model itself – the difference in performance between this agent and PPO B C stems from the innacuracy of the BC human model with respect to the actual H P r oxy . The hashed bars show results with the starting position of the agents switched. This most makes a dif ference for asymmetric layouts such as Asymmetric Advantages or Forced Coordination. Figure 5: Comparison across planning methods. W e see a similar trend: cou- pled planning (CP) performs well with itself (CP+CP) and worse with the proxy human (CP+H P r oxy ). Having the correct model of the human (the dotted line) helps, b ut a bad model (P B C +H P r oxy ) can be much worse because agents get stuck (see Appendix G). Analysis. W e present quantitati ve results for DRL in Fig- ure 4. Even though SP and PBT achie ve excellent per- formance in self-play , when paired with a human model they struggle to even meet the performance of the imi- tation agent. There is a large gap between the imitation agent and gold standard performance. Note that the gold standard rew ard is lo wer than self-play methods paired with themselves, due to human suboptimality af fecting the highest possible reward the agent can get. W e then see that PPO B C outperforms the agents trained with themselves, getting closer to the gold standard. This supports our hy- pothesis that 1) self-play-like agents perform drastically worse when paired with humans, and 2) it is possible to improv e performance significantly by taking the human into account. W e sho w this holds (for these layouts) even when using an unsophisticated, beha vior-cloning based model of the human. 6 Figure 6: A verage rewards o ver 400 timesteps of agents paired with real humans, with standard error across study participants. In most layouts, the PPO agent that trains with human data (PPO B C , orange) performs better than agents that don’ t model the human (SP and PBT , teal), and in some layouts significantly so. W e also include the performance of humans when playing with other humans (gray) for information. Note that for human-human performance, we took long trajectories and e valuated the re ward obtained at 400 timesteps. In theory , humans could have performed better by optimizing for short-term reward near the end of the 400 timesteps, but we expect that this ef fect is small. Due to computational complexity , model-based planning was only feasible on two layouts. Figure 5 shows the results on these layouts, demonstrating a similar trend. As expected, coupled planning achiev es better self-play performance than reinforcement learning. But when pairing it with the human proxy , performance drastically drops, f ar belo w the gold standard. Qualitati vely , we notice that a lot of this drop seems to happen because the agent expects optimal motion, whereas actual human play is much slower . Giving the planner access to the true human model and planning with respect to it is suf ficient to improve performance (the dotted line abov e P B C ). Ho wever , when planning with BC but e valuating with H proxy , the agent gets stuck in loops (see Appendix G). Overall, these results sho wcase the benefit of getting access to a good human model – BC is in all likelihood closer to H P roxy than to a real human. Next, we study to what e xtent the benefit is still there with a poorer model, i.e. when still using BC, b ut this time testing on real users. 6 User Study Design. W e varied the AI agent (SP vs. PBT vs. PPO B C ) and measured the av erage reward per episode when the agent was paired with a human user . W e recruited 60 users (38 male, 19 female, 3 other , ages 20-59) on Amazon Mechanical T urk and used a between-subjects design, meaning each user w as only paired with a single AI agent. Each user played all 5 task layouts, in the same order that was used when collecting human-human data for training. See Appendix H for more information. Analysis. W e present results in Figure 6. PPO B C outperforms the self-play methods in three of the layouts, and is roughly on par with the best one of them in the other two. While the effect is not as strong as in simulation, it follows the same trend, where PPO B C is ov erall preferable. An ANO V A with agent type as a factor and layout and player inde x as cov ariates showed a significant main effect for agent type on reward ( F (2 , 224) = 6 . 49 , p < . 01 ), and the post-hoc analysis with T ukey HSD corrections confirmed that PPO B C performed significantly better than SP ( p = . 01) and PBT ( p < . 01 ). This supports our hypothesis. In some cases, PPO B C also significantly outperforms human-human performance. Since imitation learning typically cannot exceed the performance of the demonstrator it is trained on, this suggests that in these cases PPO B C would also outperform imitation learning. W e speculate that the differences across layouts are due to dif ferences in the quality of BC and DRL algorithms across layouts. In Cramped Room, Coordination Ring, and the second setting of Asymmetric Adv antages, we have both a good BC model as well as good DRL training, and so PPO B C outperforms both self-play methods and human-human performance. In the first setting of Asymmetric Advantages, the DRL training does not work v ery well, and the resulting policy lets the human model do most of the hard work. (In fact, in the second setting of Asymmetric Advantages in 7 Figure 7: Cross-entropy loss incurred when using various models as a predictiv e model of the human in the human-AI data collected, with standard error over 5 different seeds. Unsurprisingly , SP and PBT are poor models of the human, while BC and H P r oxy are good models. See Appendix H for prediction accuracy . Figure 4a, the human-AI team beats the AI-AI team, suggesting that the role played by the human is hard to learn using DRL.) In F orced Coordination and Counter Circuit, BC is a very poor human model, and so PPO B C still has an incorrect expectation, and doesn’ t perform as well. W e also guess that the effects are not as strong in simulation because humans are able to adapt to agent policies and figure out how to get the agent to perform well, a feat that our simple H P roxy is unable to do. This primarily benefits self-play based methods, since they typically hav e opaque coordination policies, and doesn’t help PPO B C as much, since there is less need to adapt to PPO B C . W e describe some particular scenarios in Section 7. Figure 7 shows ho w well each model performs as a predictiv e model of the human, averaged across all human-AI data, and unsurprisingly finds that SP and PBT are poor models, while BC and H P roxy are decent. Since SP and PBT expect the other player to be like themselv es, they are ef fectiv ely using a bad model of the human, explaining their poor performance with real humans. PPO B C instead expects the other player to be BC, a much better model, e xplaining its superior performance. 7 Qualitative Findings Here, we speculate on some qualitativ e behaviors that we observ ed. W e found similar behaviors between simulation and real users, and SP and PBT had similar types of failures, though the specific failures were dif ferent. Adaptivity to the human. W e observed that o ver the course of training the SP agents became v ery specialized, and so suf fered greatly from distributional shift when paired with human models and real humans. For e xample, in Asymmetric Advantages, the SP agents only use the top pot, and ignore the bottom one. Howev er, humans use both pots. The SP agent ends up waiting unproducti vely for the human to deli ver a soup from the top pot, while the human has instead decided to fill up the bottom pot. In contrast, PPO B C learns to use both pots, depending on the context. Leader/follo wer behavior . In Coordination Ring, SP and PBT agents tend to be very headstrong: for any specific portion of the task, they usually expect either clockwise or counterclockwise motion, but not both. Humans have no such preference, and so the SP and PBT agents often collide with them, and keep colliding until the human gi ves way . The PPO B C agent instead can take on both leader and follower roles. If it is carrying a plate to get a soup from the pot, it will insist on following the shorter path, ev en if a human is in the way . On the other hand, when picking which route to carry onions to the pots, it tends to adapt to the human’ s choice of route. Adaptive humans. Real humans learn throughout the episode to anticipate and work with the agent’ s particular coordination protocols. F or example, in Cramped Room, after picking up a soup, SP and PBT insist upon deli vering the soup via right-do wn-interact instead of do wn-right-do wn-interact – ev en when a human is in the top right corner, blocking the way . Humans can figure this out and make sure that the y are not in the way . Notably , PPO B C cannot learn and take advantage of human adaptivity , because the BC model is not adapti ve. 8 8 Discussion Summary . While agents trained via general DRL algorithms in collaborativ e environments are v ery good at coordinating with themselves, they are not able to handle human partners well, since they hav e nev er seen humans during training. W e introduced a simple environment based on the game Overcook ed that is particularly well-suited for studying coordination, and demonstrated quantitativ ely the poor performance of such agents when paired with a learned human model, and with actual humans. Agents that were explicitly designed to work well with a human model, ev en in a very naiv e way , achiev ed significantly better performance. Qualitati vely , we observed that agents that learned about humans were significantly more adaptive and able to take on both leader and follower r oles than agents that expected their partners to be optimal (or like them). Limitations and future w ork. An alternati ve hypothesis for our results is that training against BC simply forces the trained agent to be rob ust to a wider v ariety of states, since BC is more stochastic than an agent trained via self-play , but it doesn’ t matter whether BC models real humans or not. W e do not find this likely a priori, and we did try to check this: PBT is supposed to be more robust than self-play , but still has the same issue, and planning agents are automatically robust to states, but still showed the same broad trend. Nonetheless, it is possible that DRL applied to a sufficiently wide set of states could recoup most of the lost performance. One particular experiment we would like to run is to rain a single agent that works on arbitrary layouts. Since agents would be trained on a much wider v ariety of states, it could be that such agents require more general coordination protocols, and self-play-like methods will be more viable since they are forced to learn the same protocols that humans would use. In contrast, in this work, we trained separate agents for each of the layouts in Figure 3. W e limited the scope of each agent because of our choice to train the simplest human model, in order to showcase the importance of human data: if a naiv e model is already better , then more sophisticated ones will be too. Our findings open the door to exploring such models and algorithms: Better human models: Using imitation learning for the human model is prone to distrib utional shift that reinforcement learning will exploit. One method to alleviate this would be to add inducti ve bias to the human model that makes it more likely to generalize out of distrib ution, for example by using theory of mind [ 7 ] or shared planning [ 17 ]. Ho wever , we could also use the standard data aggre gation approach, where we periodically query humans for a new human-AI dataset with the current version of the agent, and retrain the human model to correct any errors caused by distrib ution shift. Biasing population-based training towards humans: Agents trained via PBT should be able to coordinate well with any of the agents that were present in the population during training. So, we could train multiple human models using variants of imitation learning or theory of mind, and inject these human models as agents in the population. The human models need not e ven be accurate, as long as in aggregate they cover the range of possible human behavior . This becomes a v ariant of domain randomization [3] applied to interaction with humans. Adapting to the human at test time: So far we have been assuming that we must deploy a static agent at test time, but we could have our agent adapt online. One approach would be to learn multiple human models (corresponding to different humans in the dataset). At test time, we can select the most likely human model [ 27 ], and choose actions using a model-based algorithm such as model predictiv e control [ 25 ]. W e could also use a meta-learning algorithm such as MAML [ 11 ] to learn a policy that can quickly adapt to ne w humans at test time. Humans who learn: W e modeled the human policy as stationary , preserving the Markov assumption. Howe ver , in reality humans will be learning and adapting as they play the game, which we would ideally model. W e could take this into account by using recurrent architectures, or by using a more explicit model of ho w humans learn. Acknowledgments W e thank the researchers at the Center for Human Compatible AI and the Interact lab for v aluable feedback. This work was supported by the Open Philanthropy Project, NSF CAREER, the NSF V eHICaL project (CNS-1545126), and National Science Foundation Graduate Research Fellowship Grant No. DGE 1752814. 9 References [1] Pieter Abbeel and Andre w Y Ng. Apprenticeship learning via in verse reinforcement learning. In Pr oceedings of the twenty-first international conference on Mac hine learning , page 1. A CM, 2004. [2] Rachid Alami, Aurélie Clodic, V incent Montreuil, Emrah Akin Sisbot, and Raja Chatila. T ow ard human-aw are robot task planning. In AAAI spring symposium: to boldly go wher e no human-r obot team has gone befor e , pages 39–46, 2006. [3] Marcin Andrychowicz, Bo wen Baker , Maciek Chociej, Rafal Jozefo wicz, Bob McGrew , Jakub Pachocki, Arthur Petron, Matthias Plappert, Glenn Powell, Ale x Ray , et al. Learning dexterous in-hand manipulation. arXiv pr eprint arXiv:1808.00177 , 2018. [4] Michael Bain and Claude Sammut. A framework for behavioural cloning. In Machine Intelligence 15, Intelligent Agents [St. Catherine’ s Colleg e, Oxfor d, J uly 1995] , pages 103–129, Oxford, UK, UK, 1999. Oxford University . ISBN 0-19-853867-7. URL http: //dl.acm.org/citation.cfm?id=647636.733043 . [5] Craig Boutilier . Planning, learning and coordination in multiagent decision processes. In Pr oceedings of the 6th confer ence on Theor etical aspects of rationality and knowledge , pages 195–210. Morgan Kaufmann Publishers Inc., 1996. [6] Shan Carter and Michael Nielsen. Using artificial intelligence to augment human intelligence. Distill , 2017. doi: 10.23915/distill.00009. https://distill.pub/2017/aia . [7] Rohan Choudhury , Gokul Swamy , Dylan Hadfield-Menell, and Anca Dragan. On the utility of model learning in HRI. 01 2019. [8] Prafulla Dhariwal, Christopher Hesse, Oleg Klimov , Alex Nichol, Matthias Plappert, Alec Radford, John Schulman, Szymon Sidor , Y uhuai W u, and Peter Zhokhov . OpenAI baselines. https://github.com/openai/baselines , 2017. [9] Anca D Dragan, K enton CT Lee, and Siddhartha S Srini vasa. Le gibility and predictability of robot motion. In Pr oceedings of the 8th ACM/IEEE international confer ence on Human-r obot interaction , pages 301–308. IEEE Press, 2013. [10] Douglas C Engelbart. Augmenting human intellect: A conceptual framework. Menlo P ark, CA , 1962. [11] Chelsea Finn, Pieter Abbeel, and Serge y Levine. Model-agnostic meta-learning for fast adap- tation of deep networks. In Pr oceedings of the 34th International Confer ence on Machine Learning-V olume 70 , pages 1126–1135. JMLR. org, 2017. [12] Jakob N Foerster , Francis Song, Edward Hughes, Neil Burch, Iain Dunning, Shimon Whiteson, Matthew Botvinick, and Michael Bo wling. Bayesian action decoder for deep multi-agent reinforcement learning. arXiv pr eprint arXiv:1811.01458 , 2018. [13] Ghost T o wn Games. Overcooked, 2016. https://store.steampowered.com/app/ 448510/Overcooked/ . [14] Michael J Gielniak and Andrea L Thomaz. Generating anticipation in robot motion. In 2011 R O-MAN , pages 449–454. IEEE, 2011. [15] Jayesh K Gupta, Maxim Egorov , and Mykel Kochenderfer . Cooperativ e multi-agent control using deep reinforcement learning. In International Confer ence on Autonomous Agents and Multiagent Systems , pages 66–83. Springer , 2017. [16] Jonathan Ho and Stefano Ermon. Generati ve adversarial imitation learning. In Advances in Neural Information Pr ocessing Systems , pages 4565–4573, 2016. [17] M. K. Ho, J. MacGlashan, A. Greenwald, M. L. Littman, E. M. Hilliard, C. T rimbach, S. Brawner , J. B. T enenbaum, M. Kleiman-W einer , and J. L. Austerweil. Feature-based joint planning and norm learning in collaborative games. In A. Papafragou, D. Grodner , D. Mirman, and J.C. Trueswell, editors, Pr oceedings of the 38th Annual Confer ence of the Cognitive Science Society , pages 1158–1163, Austin, TX, 2016. Cognitiv e Science Society . 10 [18] Edward Hughes, Joel Z Leibo, Matthew Phillips, Karl T uyls, Edgar Dueñez-Guzman, Anto- nio García Castañeda, Iain Dunning, T ina Zhu, Ke vin McKee, Raphael K oster , et al. Inequity av ersion improves cooperation in intertemporal social dilemmas. In Advances in Neural Infor - mation Pr ocessing Systems , pages 3326–3336, 2018. [19] Max Jaderberg, V alentin Dalibard, Simon Osindero, W ojciech M Czarnecki, Jeff Donahue, Ali Razavi, Oriol V inyals, Tim Green, Iain Dunning, Karen Simonyan, et al. Population based training of neural networks. arXiv pr eprint arXiv:1711.09846 , 2017. [20] Max Jaderber g, W ojciech M. Czarnecki, Iain Dunning, Luke Marris, Guy Le ver , Antonio Garcia Castañeda, Charles Beattie, Neil C. Rabino witz, Ari S. Morcos, A vraham Ruderman, Nicolas Sonnerat, Tim Green, Louise Deason, Joel Z. Leibo, David Silver , Demis Hassabis, K oray Kavukcuoglu, and Thore Graepel. Human-level performance in 3d multiplayer games with population-based reinforcement learning. Science , 364(6443):859–865, 2019. ISSN 0036-8075. doi: 10.1126/science.aau6249. URL https://science.sciencemag.org/content/364/ 6443/859 . [21] Shervin Ja vdani, Siddhartha S Srini vasa, and J Andre w Bagnell. Shared autonomy via hindsight optimization. Robotics science and systems: online pr oceedings , 2015. [22] Joel Z Leibo, V inicius Zambaldi, Marc Lanctot, Janusz Marecki, and Thore Graepel. Multi-agent reinforcement learning in sequential social dilemmas. In Pr oceedings of the 16th Confer ence on Autonomous Agents and MultiAgent Systems , pages 464–473. International F oundation for Autonomous Agents and Multiagent Systems, 2017. [23] Adam Lerer and Ale xander Peysakhovich. Learning existing social con ventions via observ a- tionally augmented self-play . AAAI / A CM conference on Artificial Intelligence, Ethics, and Society , 2019. [24] Ryan Lowe, Y i W u, A viv T amar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mix ed cooperati ve-competiti ve en vironments. In Advances in Neur al Information Pr ocessing Systems , pages 6379–6390, 2017. [25] Anusha Nagabandi, Gregory Kahn, Ronald S Fearing, and Serge y Levine. Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning. In 2018 IEEE International Confer ence on Robotics and Automation (ICRA) , pages 7559–7566. IEEE, 2018. [26] Stefanos Nikolaidis and Julie Shah. Human-robot cross-training: computational formulation, modeling and e valuation of a human team training strate gy . In Pr oceedings of the 8th A CM/IEEE international confer ence on Human-r obot interaction , pages 33–40. IEEE Press, 2013. [27] Eshed Ohn-Bar , Kris M. Kitani, and Chieko Asakawa. Personalized dynamics models for adaptiv e assistiv e navig ation interfaces. CoRR , abs/1804.04118, 2018. [28] OpenAI. How to train your OpenAI Five. 2019. https://openai.com/blog/ how- to- train- your- openai- five/ . [29] OpenAI. OpenAI Five finals. 2019. https://openai.com/blog/openai- five- finals/ . [30] Dean A Pomerleau. Efficient training of artificial neural netw orks for autonomous navigation. Neural Computation , 3(1):88–97, 1991. [31] Dorsa Sadigh, Shankar Sastry , Sanjit A Seshia, and Anca D Dragan. Planning for autonomous cars that lev erage effects on human actions. In Robotics: Science and Systems , volume 2. Ann Arbor , MI, USA, 2016. [32] John Schulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov . Proximal policy optimization algorithms. arXiv pr eprint arXiv:1707.06347 , 2017. [33] David Silv er, Thomas Hubert, Julian Schrittwieser , Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv pr eprint arXiv:1712.01815 , 2017. 11 [34] Oriol V inyals, Igor Babuschkin, Junyoung Chung, Michael Mathieu, Max Jaderberg, W o- jciech M. Czarnecki, Andrew Dudzik, Aja Huang, Petko Georgie v , Richard Po well, T imo Ewalds, Dan Horgan, Manuel Kroiss, Ivo Danihelka, John Agapiou, Junhyuk Oh, V alentin Dalibard, David Choi, Laurent Sifre, Y ury Sulsky , Sasha V ezhnev ets, James Molloy , Tre vor Cai, David Budden, T om Paine, Caglar Gulcehre, Ziyu W ang, T obias Pfaff , T oby Pohlen, Y uhuai W u, Dani Y ogatama, Julia Cohen, Katrina McKinney , Oli ver Smith, T om Schaul, T imothy Lillicrap, Chris Apps, K oray Ka vukcuoglu, Demis Hassabis, and Da vid Silver . AlphaS- tar: Mastering the Real-Time Strategy Game StarCraft II. https://deepmind.com/blog/ alphastar- mastering- real- time- strategy- game- starcraft- ii/ , 2019. 12 A Beha vior cloning W e collected trajectories from Amazon Mechanical T urk. W e removed trajectories that fell short of the intended human-human trajectory length of T ≈ 1200 and very suboptimal ones (with re ward roughly below to what could be achiev ed by one human on their own – i.e. less than 220 for Cramped Room, 280 for Asymmetric Adv antages Ring, 150 for Coordination Ring, 160 for Forced Coordination, and 180 for Counter Circuit). After remo val , we had 16 joint human-human trajectories for Cramped Room en vironment, 17 for Asymmetric Advantages, 16 for Coordination Ring, 12 for Forced Coordination, and 15 for Counter Circuit. W e di vide the joint trajectories into two groups randomly , and split each joint tra- jectory (( s 0 , ( a 1 0 , a 2 0 ) , r 0 ) , . . . , ( s T , ( a 1 T , a 2 T ) , r T )) into two single agent trajectories: (( s 0 , a 1 0 , r 0 ) , . . . , ( s T , a 1 T , r T )) and (( s 0 , a 2 0 , r 0 ) , . . . , ( s T , a 2 T , r T )) . At the end of this pro- cess we have twice as many single-agent trajectories than the joint human-human trajectories we started with, for a total of approximately 36k en vironment timesteps for each layout. W e then use the two sets of single-agent human trajectories to train two human models, BC and H P roxy , for each of the fi ve layouts. W e e valuate these trained beha vior cloning models by pairing them with themselves a veraging out rew ard across 100 rollouts with horizon T = 400 . In each subgroup, we used 85% of the data for training the behavior cloning model, and 15% for validation. T o learn the policy , we used a feed-forward fully-connected neural network with 2 layers of hidden size 64. W e report the hyperparameters used in T able 1. W e run each experiment with 5 different seeds, leading to 5 BC and 5 H P roxy models for each layout. W e then manually choose one BC and one H P roxy model based on the heuristic that the H P roxy model should achiev e slightly higher rew ard than the BC model – to make our usage of H P roxy as a human proxy more realistic (as we would expect BC to underperform compared to the e xpert demonstrator). Behavior cloning, unlike all other methods in this paper , is trained on a manually designed 64 - dimensional featurization the state to incenti vize learning policies that generalize well in spite of the limited amount of human-human data. Such featurization contains the relati ve positions to each player of: the other player, the closest onion, dish, soup, onion dispenser, dish dispenser , serving location, and pot (one for each pot state: empty , 1 onion, 2 onions, cooking, and ready). It also contains boolean v alues encoding the agent orientation and indicating whether the agent is adjacent to empty counters. W e also include the agent’ s own absolute position in the layout. T o correct for a tendency of the learnt models to sometimes get stuck when performing low level action tasks, we added a hardcoded the beha vior cloning model to take a random action if stuck in the same position for 3 or more consecuti ve timesteps. As far as we could tell, this does not significantly affect the beha vior of the human models except in the intended way . Behavior cloning hyperparameters Parameter Cramped Rm. Asym. Adv . Coord. Ring Forced Co- ord. Counter Circ. Learning Rate 1e-3 1e-3 1e-3 1e-3 1e-3 # Epochs 100 120 120 90 110 Adam epsilon 1e-8 1e-8 1e-8 1e-8 1e-8 T able 1: Hyperparameters for behavior cloning across the 5 layouts. Adam epsilon is the choice of the for the Adam optimizer used in these experiments. B Self-play PPO Unlike beha vior cloning, PPO and other DRL methods were trained with a lossless state encoding consisting of 20 masks, each a matrix of size corresponding to the en vironment terrain grid size. Each mask contains information about a specific aspect of the state: the player’ s own position, the player’ s own orientation, location of dispensers of v arious types, location of objects on counters, etc. In order to speed up training, we shaped the rew ard function to gi ve agents some re ward when placing an onion into the pot, when picking up a dish while a soup is cooking, and when picking up a soup 13 with a dish. The amount of reward shaping is reduced to 0 o ver the course of training with a linear schedule. W e parameterize the policy with a con volutional neural network with 3 con volutional layers (of sizes 5 × 5 , 3 × 3 , and 3 × 3 respectiv ely), each of which has 25 filters, followed by 3 fully-connected layers with hidden size 32. Hyperparameters used and training curves are reported respecti vely in T able 2 and Figures 8. W e use 5 seeds for our experiments, with respect to which we report all our standard errors. PPO S P hyperparameters Parameter Cramped Rm. Asym. Adv . Coord. Ring Forced Co- ord. Counter Circ. Learning Rate 1e-3 1e-3 6e-4 8e-4 8e-4 VF coefficient 0.5 0.5 0.5 0.5 0.5 Rew . shaping horizon 2.5e6 2.5e6 3.5e6 2.5e6 2.5e6 # Minibatches 6 6 6 6 6 Minibatch size 2000 2000 2000 2000 2000 T able 2: Hyperparameters for PPO trained purely in self-play , across the 5 layouts. For simulation, we used 30 parallel en vironments. Similarly to the embedded human model case, parameters common to all layouts are: entropy coef ficient (= 0 . 1) , gamma (= 0 . 99) , lambda (= 0 . 98) , clipping (= 0 . 05) , maximum gradient norm ( = 0 . 1 ), and gradient steps per minibatch per PPO step (= 8) . For a description of the parameters, see T able 3. (a) Cramped Room (b) Asymmetric Advantages (c) Coordination Ring (d) Forced Coordination (e) Counter Circuit Figure 8: PPO S P self-play av erage episode rewards on each layout during training. C PPO with embedded-agent en vironment T o train PPO with an embedded human model we use the same network structure as in the PPO S P case in Appendix B and similar hyperparameters, reported in T able 3. As in the PPO S P case, we use rew ard shaping and anneal it linearly throughout training. Empirically , we found that – for most layouts – agents trained directly with competent human models to settle in local optima, ne ver de veloping good game-play skills and letting the human models collect re ward alone. Therefore, on all layouts except F orced Coordination, we initially train in pure self-play , and then anneal the amount of self-play linearly to zero, finally continuing training purely with the human model. W e found this to improve the trained agents’ performance. In Forced Coordination, both players need to learn g ame-playing skills in order to achie ve an y reward, so this problem doesn’t occur . 14 T raining curves for the training (BC) and test (H P roxy ) models are reported respectively in Figures 9 and 10. PPO B C and PPO H P r oxy hyperparameters Parameter Cramped Rm. Asym. Adv . Coord. Ring Forced Co- ord. Counter Circ. Learning Rate 1e-3 1e-3 1e-3 1.5e-3 1.5e-3 LR annealing factor 3 3 1.5 2 3 VF coefficient 0.5 0.5 0.5 0.1 0.1 Rew . shaping horizon 1e6 6e6 5e6 4e6 4e6 Self-play annealing [5e5, 3e6] [1e6, 7e6] [2e6, 6e6] N/A [1e6, 4e6] # Minibatches 10 12 15 15 15 Minibatch size 1200 1000 800 800 800 T able 3: Hyperparameters for PPO trained on an embedded human model en vironment, across the 5 layouts. LR annealing factor corresponds to what factor the learning rate was annealed by linearly o ver the course of the training (i.e. ending at LR 0 /LR f actor ). VF coefficient is the weight to assign to the v alue function portion of the loss. Rewar d shaping horizon corresponds to the environment timestep in which rew ard shaping reaches zero, after being annealed lineraly . Of the two numbers reported for self-play annealing , the former refers to the en vironment timestep we begin to anneal from pure self-play to embedded human model training, and the latter to the timestep in which we reach pure human model embedding training. N/A indicates that no self-play was used during training. # Minibatches refers to the number of minibatches used at each PPO step, each of size minibatch size . For simulation, we used 30 parallel en vironments. Further parameters common for all layouts are: entropy coefficient (= 0 . 1) , gamma (= 0 . 99) , lambda (= 0 . 98) , clipping (= 0 . 05) , maximum gradient norm ( = 0 . 1 ), and gradient steps per minibatch per PPO step (= 8) . For further information, see the OpenAI baselines PPO documentation [8]. (a) Cramped Room (b) Asymmetric Advantages (c) Coordination Ring (d) Forced Coordination (e) Counter Circuit Figure 9: PPO B C av erage episode rewards on each layout during training over 400 horizon timesteps, when pairing the agent with itself or with BC in proportion to the current self-play annealing. D Population Based T raining W e trained population based training using a population of 3 agents, each of which is parameterized by a neural network trained with PPO, with the same structure as in C. During each PBT iteration, all possible pairings of the 3 agents are trained using PPO, with each agent training on a embedded single-agent MDP with the other PPO agent fixed. PBT selection was conducted by replacing the worst performing agent with a mutated version of the h yperparameters. The parameters that could be mutated are lambda (initialized = 0 . 98 ), clipping (initialized = 0 . 05 ), learning rate (initialized = 5 e − 3 ), gradient steps per minibatch per PPO update (initialized = 8 ), 15 (a) Cramped Room (b) Asymmetric Advantages (c) Coordination Ring (d) Forced Coordination (e) Counter Circuit Figure 10: PPO H P r oxy av erage episode rewards on each layout during training over 400 horizon timesteps, when pairing the agent with itself or with H P r oxy in proportion to the current self-play annealing. entropy coefficient (initialized = 0 . 5 ), and value function coef ficient (initialized = 0 . 1 ). At each PBT step, each parameter had a 33% chance of being mutated by either a factor of 0 . 75 or 1 . 25 (and clipped to the closest inte ger if necessary). For the lambda parameter , we mutate by ± 2 where is the distance to the closest of 0 or 1 , to ensure that it will not go out of bounds. As for the other DRL algorithms, we use re ward shaping and anneal it linearly throughout training, and e v aluate PBT reporting means and standard errors o ver 5 seeds. Hyperparameters and training rew ard curves are reported respectiv ely in T able 4 and Figure 11. PBT hyperparameters Parameter Cramped Rm. Asym. Adv . Coord. Ring Forced Co- ord. Counter Circ. Learning Rate 2e-3 8e-4 8e-4 3e-3 1e-3 Rew . shaping horizon 3e6 5e6 4e6 7e6 4e6 En v . steps per agent 8e6 1.1e7 5e6 8e6 6e6 # Minibatches 10 10 10 10 10 Minibatch size 2000 2000 2000 2000 2000 PPO iter . timesteps 40000 40000 40000 40000 40000 T able 4: Hyperparameters for PBT , across the 5 layouts. PPO iteration timesteps refers to the length in en vironment timesteps for each agent pairing training. For simulation, we used 50 parallel en vironments. The mutation parameters were equal across all layouts. For further description of the parameters, see T able 3. E Near -optimal joint planner As mentioned in 4.3, to perform optimal planning we pre-compute optimal joint motion plans for ev ery possible starting and desired goal location for each agent. This enables us to quickly query the cost of each motion plan when performing A ∗ search. W e then define the high-lev el actions: “get an onion”, “serve the dish”, etc, and map each joint high-lev el action onto specific joint motion plans. W e then use A ∗ search to find the optimal joint plan in this high-lev el action space. This planner does make some assumptions for computational reasons, making it near-optimal instead of optimal. In order to reduce the number of required joint motion plans by a factor of 16, we only consider position-states for the players, and not their orientations. This adds the possibility of wasting one timestep when executing certain motion plans, in order to get into the correct orientation. W e 16 (a) Cramped Room (b) Asymmetric Advantages (c) Coordination Ring (d) Forced Coordination (e) Counter Circuit Figure 11: A verage episode rew ards on each layout during training for PBT agents when paired with each other, av eraged across all agents in the population. hav e added a set of additional conditions to check for such a case and reduce the impact of such an approximation, but the y are not general. Another limitation of the planning logic is that counters are not considered when selecting high lev el action, as it would increase the runtime of A ∗ by a large amount (since the number of actions av ailable when holding an item would greatly increase). This is not of large importance in the two layouts we run planning experiments on. The use of counters in such scenarios is also minimal in human gameplay . Another approximation made by the planner is only considering a 3 dish deli very look-ahead. Analyzing the rollouts, we would expect that increasing the horizon to 4 would not significantly impact the rew ard for the two layouts used in Section 5. F Near -optimal model-based planner Giv en a fixed partner model, we implement a near -optimal model-based planner that plays with the fixed partner . The planner uses a two-layered A ∗ search in which: 1) on a low le vel we use A ∗ in the game state space with edges being basic player joint actions (one of which is obtained by querying the partner model). T o reduce the complexity of such search, we remov e stochasticity from the partner model by taking the argmax probability action. 2) on a higher lev el we use A ∗ search in the state space in which edges are high le vel actions, similarly to those of the near -optimal joint planner described in Appendix E. Unlike in that case, it is unfeasible to pre-compute all lo w-lev el motion plans, as each motion plan does not only depend on the beginning positions and orientations of the agents, but also on other features of the state (since they could influence the actions returned by the partner model). G Planning experiments Due to computational constrains, when ev aluating planning methods (such as in Figure 5), we ev aluated on a horizon of 100 timesteps, and then multiplied by 4 to make the en vironment horizon comparable to all other experiments. This is another source of possible suboptimality in the planning experiments. When observing Figure 5, we see that P B C +H P roxy performs much worse than the red dotted line (representing planning with respect to the actual test model H P roxy ). This is due to the fact that in the planning experiments all agents are set to choose actions deterministically (in order reduce the 17 planning complexity – as mentioned in appendix F), leading the agents to get often stuck in loops that last the whole remaining part of the trajectory , leading to little or no reward. H Human-AI experiments Figure 12: The results are mostly similar to those in Figure 6, with the exception of larger standard errors introduced by the non-cooperati ve trajectories. The reported standard errors are across the human participants for each agent type. Figure 13: Accuracy of various models when used to predict human beha vior in all of the human-AI trajectories. The standard errors for DRL are across the 5 training seeds, while for the human models we only use 1 seed. For each seed, we perform 100 ev aluation runs. The human-AI trajectories were collected with a horizon of 400 timesteps. The agents used in this experiment were trained with slightly different hyperparameters than those in the pre vious appendices: after we had results in simulation and from this user study , we improved the h yperparameters and updated the simulation results, but did not rerun the user study . After manually inspecting the collected human-AI data, we remov ed all broken trajectories (human not performing any actions, and trajectories shorted than intended horizon). W e also noticed that in a large amount of trajectories, humans were extremely non-cooperative, not trying to perform the task well, and mainly just observing the AI agent and interacting with it (e.g. getting in its way). Our hypothesis was that these participants were trying to "push the boundaries" of the AI agents and test where the y would break – as they were told that the y would be paired with AI agents. W e also remov ed these non-cooperativ e trajectories before obtaining our results. Cumulativ ely across all layouts, we remov ed 15, 11, and 15 trajectories of humans paired with PBT , PPO S P , and PPO B C agents respectiv ely . In Figure 12 we report human-AI performance without these trajectories remo ved. Performing an ANO V A on all the data with agent type as a factor and layout and player index as a co variates showed a significant main effect for agent type on re ward ( F (2 , 250) = 4 . 10 , p < . 01 ), and the post-hoc analysis with T ukey HSD corrections confirmed that PPO B C performed significantly better than for PBT ( p < . 01 ), while fell just short of statistical significance for SP ( p = . 06) . 18 W e also report the results of using v arious agents as predictiv e models of human beha vior in Figure 13. This is the same setup as in Figure 7, except we are reporting accuracies here instead of cross-entrop y losses. Another thing to note is that in order to obtain Figure 7, to prev ent numerical overflo ws in the calculation of cross-entropy for the PBT and PPO S P models, we lower -bounded the probability outputted by all models for the correct action to = 1 × 10 − 3 . This reduces the loss of all models, but empirically af fects PBT and PPO S P the most, as they are the models that are most commonly confidently-incorrect in predicting the human’ s action. W e chose this as it is about 1 order of magnitude smaller than the smallest predictions assigned to the correct actions by the human models (i.e. the worst mistak es of the human models). 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment