인간을 이해하는 AI 협업: Overcooked에서의 학습 전략 비교
본 논문은 인간과 협업이 요구되는 환경에서 자기‑플레이와 인구 기반 학습이 만든 에이전트가 인간 파트너와는 크게 성능 차이를 보인다는 점을 실험적으로 입증한다. Overcooked 기반 시뮬레이션에서 인간 행동을 모방한 모델을 학습하고, 이를 활용한 강화학습·플래닝 에이전트를 비교했을 때, 인간 모델을 이용한 에이전트가 인간 파트너와의 협업에서 현저히 우수함을 확인한다. 또한 실제 인간 사용자 실험에서도 동일한 경향이 관찰되었다.
저자: Micah Carroll, Rohin Shah, Mark K. Ho
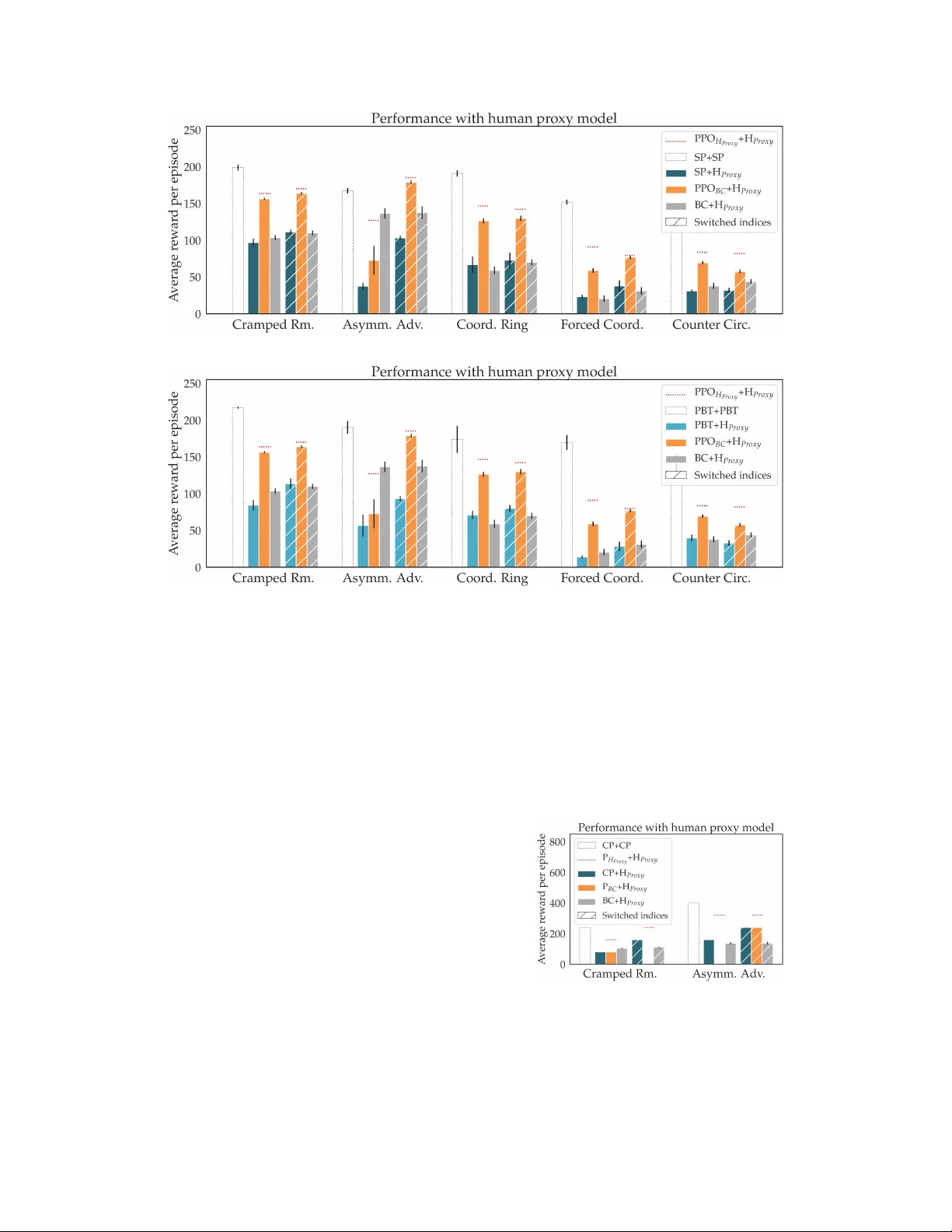
본 논문은 인간과의 협업이 핵심인 다중 에이전트 환경에서 기존의 자기‑플레이(self‑play)와 인구 기반 훈련(Population Based Training, PBT) 방식이 인간 파트너와의 협업에 한계가 있음을 실험적으로 입증한다. 연구진은 먼저 Overcooked 게임을 단순화한 시뮬레이션 환경을 설계하였다. 이 환경은 양파, 접시, 냄비 등 제한된 객체와 6가지 기본 행동(상·하·좌·우·대기·상호작용)만을 제공하면서도, 레이아웃에 따라 저수준 움직임 조정부터 고수준 전략 선택까지 다양한 협업 난이도를 만든다. ‘Cramped Room’, ‘Asymmetric Advantages’, ‘Coordination Ring’, ‘Forced Coordination’, ‘Counter Circuit’ 등 5가지 레이아웃을 통해 충돌 회피, 역할 분담, 물체 전달 등 복합적인 협업 과제를 제공한다.
인간 데이터는 웹 인터페이스를 통해 수집했으며, 각 레이아웃당 약 16개의 인간‑인간 플레이 트래젝터리를 확보해 총 18,000 타임스텝을 확보하였다. 저자들은 행동 복제(Behavior Cloning, BC)를 사용해 인간 모델을 학습했으며, 두 개의 모델을 교차 검증용으로 나누었다. 하나는 훈련에 사용되는 BC 모델, 다른 하나는 테스트 시 “프록시 인간”(H_Proxy)으로 활용돼 실제 인간 행동을 근사한다.
에이전트 설계는 크게 두 축으로 나뉜다. 첫 번째는 자기‑플레이 기반 에이전트로, PPO 기반 자기‑플레이(SP), PBT, 그리고 공동 플래닝(Coupled Planning, CP) 세 가지를 구현했다. 특히 PBT는 에이전트 풀 내에서 서로 다른 파트너와 주기적으로 학습하면서 하이퍼파라미터를 진화시켜 일반화 능력을 높이려는 시도이다. 두 번째는 인간 모델을 활용한 에이전트로, BC 모델을 환경에 내장하고 PPO로 재학습한 PPO_BC와, 인간 모델을 동적 파트너로 가정한 계층적 A* 플래너인 P_BC를 제시한다. 플래너는 고수준 행동(양파 획득, 요리 서빙 등)과 저수준 이동 비용을 결합해 근접 최적 계획을 생성한다.
실험에서는 각 에이전트를 H_Proxy와 짝지어 400 타임스텝 동안의 누적 보상을 측정하였다. 자기‑플레이(SP), PBT, CP 에이전트는 자신과 짝을 이룰 때는 높은 보상을 기록했지만, H_Proxy와 짝을 이룰 경우 급격히 성능이 저하되었다. 이는 인간이 비최적·비정형적인 행동을 보일 때 에이전트가 “최적 파트너” 가정에 기반한 정책을 고수해 협업 실패가 발생함을 의미한다. 반면, 인간 모델을 활용한 PPO_BC와 P_BC는 H_Proxy와의 협업에서 현저히 높은 보상을 달성했다. 특히 플래너 기반 P_BC는 인간 모델이 정확히 제공될 때 거의 최적에 가까운 성능을 보이며, 행동 복제만을 이용한 BC 자체보다도 우수했다.
실제 인간을 대상으로 한 사용자 연구에서도 동일한 패턴이 관찰되었다. 인간 파트너와의 평균 보상은 인간 모델을 사용한 에이전트가 가장 높았으며, 자기‑플레이 에이전트는 상대적으로 낮았다. 다만 인간 모델의 예측 정확도가 제한적이었음에도 불구하고, 인간 모델을 활용한 접근법이 여전히 이점을 제공한다는 점이 흥미롭다.
논문은 이러한 결과를 바탕으로 몇 가지 설계 원칙을 제시한다. 첫째, 인간을 최적 파트너로 가정하지 말고, 실제 인간 행동을 모델링해야 한다. 둘째, 비록 행동 복제 모델이 불완전하더라도, 이를 활용한 강화학습이나 플래닝은 인간과의 협업에 큰 도움이 된다. 셋째, 인간 모델을 플래너에 직접 통합하거나, 인간 모델을 사용해 정책을 사전 학습한 뒤 재학습하는 방식이 효과적이다.
마지막으로 저자들은 향후 연구 방향으로 (1) 인간 모델의 불확실성을 고려한 베이지안 플래닝, (2) 인간‑에이전트 상호작용을 통한 온라인 모델 업데이트, (3) 다양한 협업 도메인에 일반화 가능한 인간‑중심 학습 프레임워크 개발 등을 제안한다. 이 연구는 협업형 AI 설계에 있어 인간 행동 모델링의 중요성을 실증적으로 보여주며, 인간‑AI 팀워크를 향상시키기 위한 구체적인 방법론을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기