Learning Neural Activations
An artificial neuron is modelled as a weighted summation followed by an activation function which determines its output. A wide variety of activation functions such as rectified linear units (ReLU), leaky-ReLU, Swish, MISH, etc. have been explored in…
Authors: Fayyaz ul Amir Afsar Minhas, Amina Asif
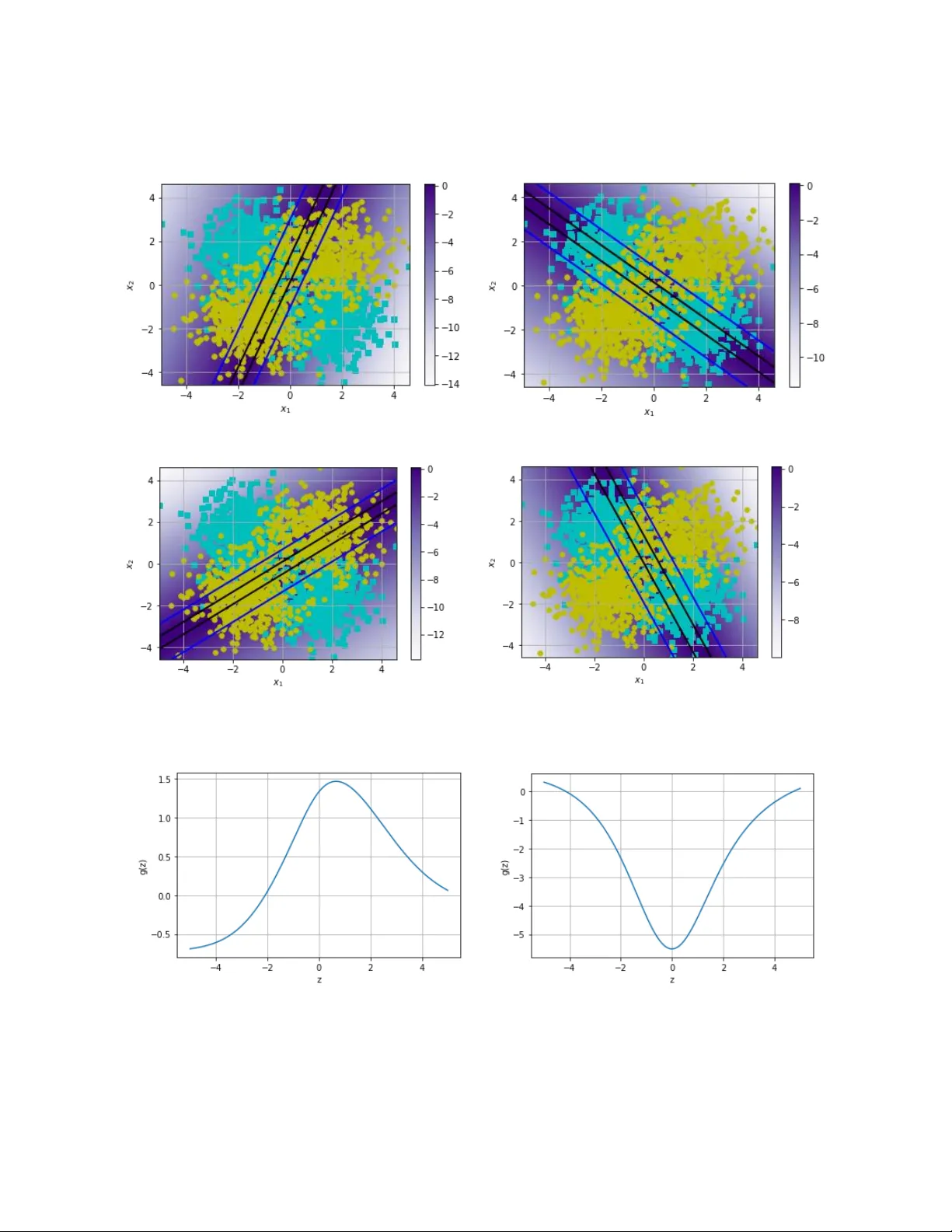
L e a r n i n g N e u r a l A c t i v a t i o n s Fayyaz ul Amir Afsar Minhas 1, * and Amina Asif 2, 3 1 Department of Co mputer Science, University o f Warwick, Coven try CV4 7AL, UK 2 Department of Computer and Information Sciences, Pakistan Institute o f Eng ineering and Applied Scien ces (PIEAS), PO Nilore, Islamaba d, Pakistan. 3 Department of Computer Science, National University o f Computer a nd Emerging Sciences FAST‐NU, Islamabad, Pakistan * corresponding author email: fayyaz.minhas@warwick.ac. uk ; Abstract An artificial neuron is modelled as a weighted summation followed by an activation function which determines its out put. A wide v ariety of activation functions such as rectified linear units (ReLU), leaky-ReLU, S wish, M I SH, et c. have be en explored in the li terature. In this short paper, we explore what happens when the activation function of each neuron in an artificial neural network is learned natively fr om data alone. This is ac hieved b y modelling the ac ti vation function of each neuron as a small neural network whos e w eights are shared by all neurons in the original network. We list our pri mary findings in the conclusions section. The code for our analysis is available at: https://github.com/amina01/Lea rning-Neural-Activations . 1. Introduction “What is the optimal activation function in a neural network?” is a question that is still being researched after more than 70 years since the first reported use of a binary activation function in the McColluch-Pitts perc eptron model [ 1]. A number of r esearchers have attempted to answer this question by proposing dif ferent t ypes of activation func tions whose desi gn i s mostly motivated b y some desirable criteria such as monotonicit y, diffe rentiability, non-saturation, bounded-support, etc. [2] – [6]. The question we pose in this paper is “Can we learn the activation function of a neural network while training the neural network ? and if y es, th en what are the characteristics of such learned activation function ?” . Early work on this question has been carried out by Fausett [7] who devised a method to learn the slope of si gmoidal activation functions. Ho wever, this analysis was limited to changes in the slope of the activation onl y. A more generic approach was recentl y proposed b y Ramachandran et al. which us ed an automatic search techniq ue to discover S WISH activations [4] . Other approac hes that involve searching for an activation function throug h error minimization include [8], [ 9]. Similar to these methods, we have analy z ed what type of activation functions can be learned using empirical risk minimization while learning the overall neural network for a given probl em. In contrast to previous work, our proposed approach is not motivated by the desi gn of better activation functions that ma y give improved accuracy or reduced computational complexity . Rather, we simpl y w ant to a nal y z e what activation functions are learned naturall y i f the only objective is empirical e rror reduction. Our approach is b ased on updating the activation function ever y time the prediction neural network is updated. In conclusion, we also give pointers o n how the problem of learning a ctivation functions from data can be formulated as a meta-learning problem. Table 1- Some commonly used activation functions. Name and Reference Formula for Linear Rectified Linear (ReLU) Leaky-ReLU Sigmoid (or logistic) Hyperbolic Tangent (tanh) Swish [4] MISH [6] 2. Methods 2.1 Structural and Mathematical Formulation Mathematically, fo r a given d -dimensional input , a sin gle n euron with we ights can be modelled as a weighted summation followed by an activation function as follows: . The activation function is t y picall y s et a priori by the designer of the neural n etwork. Examples of some activation functions are given in Table 1. A predictive neural network model can be ex pressed as a mathematical function with all learnable weight parameters of all its constituent ne urons lumped into . In case of supe rvised learning, the ne uron network is lea rned using struc tural or empirical risk minimi zation which involve minimizing a loss function that measures the extent of the error between the output of the neural network for a given input and its associated target. (a) (b) Figure 1- (a) Illustration of a neuron wit h a pre -defined activa tion functio n. (b) Concept diagra m of a neuron using learnable AFU for activatio n. In this work, we want to anal yze what happens when the activation function of each neuron or a group of neurons in a neural network model is para metrized b y a small neu ral network, henceforth referred to as an Activation Function Unit (AFU). Mathematicall y, the out put of an AFU ca n be represented by . Here represents the neural architecture of the AFU and are its learnable parameters. In this work, we have primaril y explored singl e hidden layer neural networks as AFUs, i. e., functions of the parameterized form given b y : (see Fi gure 1 ). Here is a base a ctivation function and can be set to any o f the canonical activation functions listed in Table 1 and is the number of hidden units in . The weights and bias of the i th neuron in j th la ye r in the AFU are denoted b y and , respectively. The overall learning prob lem can now be framed a s: . Note that AFU parameters can either be shared by all neurons in the neural network , i.e., all neurons in the network apply the same AFU or ea ch la y er (and possibly e ach individ ual neuron) in can have their own A FU (see Figure 1). Since the AFUs are shared b y multiple neurons in , the increase in the overall number of lea rnable p arameters is quite small: 3N+1 for the sin gle hidden layer AFU with N neurons in the hidden lay e r given above. 2.2 Experimental Analysis 2.2.1 Toy Problem We have first solved a simple two-dimensional two-class XOR-st yle classification problem with the proposed approach. The data comprises of a total of 2000 p artiall y overlapping points drawn from four Gaussian distributions (500 points each, two per class) centered at ( -1, -1), (+1, +1) (positive class) and (-1, +1), (+1, -1) (negative cl ass). The pr ediction neural network comprises four hidden layer neurons sharing an AFU with a si ngle output layer neuron with linear activation. Hinge loss function is used together with adaptive moment estimation (Adam) [10] for gradient based optimization. W e have ex perimented with different number of neurons (8,128) in the AFU hidden la yer as well as dif ferent ba se activation functions (ReLU, Sigmoid). In terms of performance analysis, we show the classification boundary learned for the problem together with the activation function and activation outputs of individual neurons. 2.2.2 Smoothness Analysis In order to analyze the smoothness characteristics of the AFU learned for the toy problem above, we have compared the prediction landscape for a randomly initialized neural network (5 la yers with 10 neurons in each layer) using ReL U vs. AFU activations. 2.2.3 MNIST For a more practical analysis, we h ave us ed the MN IST dataset [11] (60K training and 10K t est examples). Here, the prediction neural n etwork consists of two c onvolut ional la yers (32 3 ×3 filters with a 25% training drop -out in the first and 64 3×3 filters in the second) followed by two full y connected layers (128 ne urons in the hidden lay er wit h 50% training drop-out and 10 outpu t l ay e r neurons corresponding to the ten classes). Negative log likelihood is used as the loss function in this problem. An adaptive learning r ate method (ADADelta) is used together with a step -wise learning r ate sch eduler which decreases the learni ng rate b y 0.7 in each epoch starting from a base learning rate of 1.0. Here, we did two experiments: 1) same AFU across all neurons in all layers and 2) different AFU for different la yers. The learned A FUs for these experiment s together with the prediction accurac y using the widel y used ReLU a ctivation and AFU a re compare d for a fix ed number of training epochs (10). We have also p lotted the loss function across epochs for the proposed approach with ReLU activation. 2.2.4 CIFAR-10 We have also anal yzed the proposed approach ov er the CIFAR -10 [12] benchmark dataset whic h comprises of 10 classes (a ir plane, dog, automobile, bird, cat, deer, frog, horse, ship, truck) each with 6000 32×32 image s. W e have us ed the MobileNetv2 [13] in this experiment. The neural network is trained ov er 50,000 training ex amples for 100 epochs usin g a batch size of 100 with Adam optimizer (learning rate of 0.001). Test performance is evaluated over 10,000 examples and the accuracy of the network with the same AFU across all l ayers is compared to using M ISH [6] activation which gives ~86% accuracy. (a) Learned decision bo undary (black solid line) (b) AFU before traini ng (c) AFU after training Figure 2- Learnt decision boundary a nd AFUs for the to y problem. 3. Results and Discussion 3.1 Toy Problem For the XOR toy problem, the boundary produced by the prediction network is shown in Figure 2. The AFU fo r the neural network is plotted before and after training in the figure as well. It is interesting to see that the learned AFU is very different from the initial AFU which uses R eLU activations in its design. Furthermore, the AFU loosel y resembles a radial basis function centered at zero. There was no improvement in acc urac y using thi s AFU over and above native ReLU, sigmoid or h yperbolic tangent activation functions. The activations of individual neurons in the neural network are plotte d in Figure 3. The learned AFU for this problem with using a si gmoid base activation function with 8 and 128 hidden la yer neurons are shown in Figure 4 (a) and (b) respectively. It is inte resting to obs erve the over all similarity of the learned AFU with si gmoidal base activations to the on e obtained using Re LU a ctivations. It is also interesting to note that the learned activation functions do not saturate and do not produce zeros which can result in a large number of “dead” neurons. (a) Activation of 1 st neuron (b) Activation of 2 nd neuron (c) Activation of 3 rd neuron (d) Activation of 4 th neuron Figure 3- Activation plots for 4 neuro ns in hidden layer o f the neural netwo rk for toy problem. (a) AFU with 8 hidden neurons in G (sig moid initialization) (b) AFU with 128 hidden neurons in G Figure 4- AFUs learnt using 8 and 1 28 neurons in hidden la yer with sig m oid as base a ctivation . (a) Prediction scor es for a randomly initialized 5 - layer network with Re LU (b) Predictio n scores for a randomly initialized 5 - layer network with the lear ned AFU over the toy problem Figure 5- Comparison of smoot hness between ReLU and AF U learnt using the proposed sche me. 3.2 Smoothness Analysis We have anal y z ed the s moothness of the learned AFU relative to Re LU over a 5 -hidden la yer randomly initialized network with 10 n eurons in each la yer in Figure 5. The results show th at the learned AFU results in smoother transitions in comparison to the canonical ReLU network which indicates a possible and unproven regularization impact of learning activation functions. (a) Shared AFU across all la yers for MN IST (b) Independent AFU for first layer (c) Independent AFU for 2 nd layer (d) Independent AFU for 3 rd layer Figure 6- Learnt AFUs for M NIST experiment. Figure 7- Learnt AFU for CIFAR-10 experiment. 3.3 MNIST For the MNIST p roblem, we have obt ained no significant improvement in prediction performance when using learned AFU over and above c anonical activation functions such as ReLU and hyperbolic tangents ar e used (Accuracy of 99.2% was obtained for all) . However, the re is a significant dif ference between the learned AFU when the same A FU is shared across all la yers and when different layers us ed different AFUs (see Figure 6 ). The same AFU learned for all la y ers resembles a leak y-ReLU. I n contrast, wh en the AFUs are allowed to be different for different layers in the network, the resulting activation functions are indeed very different from each other. A V-shaped ac tivation function similar to the one obtained for the to y p roblem is produ ced for the first layer whereas an inverted Leak y-ReLU like activation is produced for the second layer. A mostly linear activation is learned for the full y connected la yer. This seems to indicate that learning activation functions can have a se l f-re gularizing effe ct (unproven). 3.4 CIFAR-10 Similar to the MNIST an alysis, no performance improvement is observed for the CIFAR10 dataset when using learned AFUs vs. ca nonical AFUs (e. g., MI S H): Using MISH gives top -1 accuracy o f 86.3% whereas AFU results in 85.1% (for the same mobile net v 2 with 1 00 epochs). However, it is interesting to see that the resulting learned AFU is simil ar in structure to MI S H ( Figure 7). 4. Conclusions and Future Work In conclusion we have found that: Learned activation functi ons do not degrade p erformance and can possibl y lead to minor performance gains. This has also been shown in the independent work by[9]. Learning activation functions typically result in smooth non-saturating functions. The use of learned activation functions in dee p neural network can produce smooth fitness landscapes possibly due to the over-parameterization of the optimization problem. Learned activation functions can have a possible regularization effect on learning. However, this effect needs to investigated f urther. Natively learned activation function can be ver y similar to well-known activation functions (such as Leaky-ReLU or MISH). Learned a ctivation functions produce a V (or inve rted V) type pattern whi ch needs t o be explored further. Different layers can learn vastly differe nt activation functions. In our experience, mor e linear-like activations are learned towards the final layers of a deep neural network. As a consequence, it may be advisable to have fixed initial linear activation functions in the final la yers when initializing the neural network and gradually makin g them more and more non-linear similar to ideas underly ing curriculum learning [14] . Based on analysis of the structure activation functions learned by our approach we conclude that M ISH activation can possibl y be fu rther im proved slightl y b y a ddition of a parameter that controls its slop for in the nega tive quadrants (z<0). Activation functions learned in our independent work are ver y similar in structure to the ones produced by [9] despite our proposed scheme being relatively naïve in comparison. It would be definitely interesting to explore what t ypes of pe rformance gains are obtained for a machine learning pr oblem when using ac tivation functions learned over diffe rent but related classification problem. Learning b etter activation functions can be mod elled as met a-learning problem sim ilar to the work [15] , [16] . Here, the change in the loss function of a neural net work in a fixed number of steps using a given AFU can be used as a meta -loss function to optimize the AFU resulting in activation functions that g uarantee faster convergence. References [1] W. S. McCulloch and W. Pit ts, “A log ical calculus of the ideas immanent in nervous activit y,” Bull. Math. Biophys. , vol. 5, no. 4, pp. 115 – 133, 1943. [2] R. Hecht- Nielsen, “Th eory of the ba ckpropagation neural network,” in Neural networks for perception , Elsevier, 1992, pp. 65 – 93. [3] N. Tepedelenlioglu, A. R ezgui, R. Scalero, and R. Rosario, “Fast algor ithms for trainin g multilayer perceptrons,” Neural Intell. Syst. Integr. , pp. 107 – 133, 1991. [4] P. R amachandra n, B. Zoph, and Q. V. Le, “Swish: a self - gated activation function,” ArXiv Prepr. ArXiv171005941 , vol. 7, 2017. [5] V. Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” in Proceedings of the 27th i nternational conference on machine learning (ICML-10) , 2010, pp. 807 – 814. [6] D. Misra, “Mish: A Self Re gularized Non - Monotoni c Neural Activation Function,” ArXiv Prepr. ArXiv190808681 , 2019. [7] L. Fausett, Fundamentals of neural networks: ar chitectures, algorithms, and appli cations . Prentice-Hall, Inc., 1994. [8] L. R. Sütfeld, F. Brieger, H. Finger, S. Füllhase, and G. Pipa, “Adaptive blending units: Trainable activation functions for deep neural n etworks,” ArXi v Prepr. ArXiv180610064 , 2018. [9] A. Apicella, F. Isgrò, a nd R. Prevete, “A simple and e fficient archite cture for trainable activation functions,” ArXiv Prepr. ArXiv190203306 , 2019. [10] D. P. Kingma and J . Ba, “Adam: A method for stochastic optimiz ation,” ArXiv Prepr. ArXiv14126980 , 2014. [11] Y. LeCun, C. Cortes, and C. J. Burge s, “The MNIST database o f ha ndwritten digits.” 1998. [12] A. Krizhevsky and G. Hinton, “Convolutional deep belief networks on cifar - 10,” Unpubl. Manuscr. , vol. 40, no. 7, pp. 1 – 9, 2010. [13] M. Sandler, A. H oward, M. Zhu, A. Zhmoginov, and L. - C. Chen, “Mob ilenetv2: Inverted residuals and linear bott lenecks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2018, pp. 4510 – 4520. [14] Y. Bengio, J. Louradour, R. Collobert, and J. Weston, “Curriculum learning,” in Proceedings of the 26th annual international conference on machine learning , 2009, pp. 41 – 48. [15] M. Andry c howicz et al. , “Learning to learn by gradient descent by gra di ent descent,” in Advances in neural information processing systems , 2016, pp. 3981 – 3989. [16] Y. C hen et al. , “L e arning to learn without gradient descent b y gradient descent,” in Proceedings of the 34th International Conferenc e on Machine Learning -Volume 70 , 2017, pp. 748 – 756.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment