학습으로 얻는 신경망 활성화 함수의 새로운 탐구
본 논문은 각 뉴런의 활성화 함수를 고정된 형태가 아니라, 모든 뉴런이 공유하는 작은 신경망(Activation Function Unit, AFU)으로 파라미터화하여 학습 과정에서 동시에 최적화한다. XOR toy 문제, MNIST, CIFAR‑10을 대상으로 실험한 결과, 학습된 활성화 함수는 기존 ReLU·Leaky‑ReLU·Mish와 유사한 형태의 부드럽고 비포화(non‑saturating) 특성을 보이며, 성능 향상은 미미하지만 레이어별…
저자: Fayyaz ul Amir Afsar Minhas, Amina Asif
본 논문은 인공 신경망에서 각 뉴런이 적용하는 활성화 함수를 사전에 정의된 고정 함수가 아니라, 학습 가능한 작은 신경망(Activation Function Unit, AFU)으로 모델링하여 네트워크와 동시에 최적화하는 방법을 제안한다. AFU는 단일 은닉층을 가진 MLP 형태이며, 은닉 유닛 수와 기본 활성화 함수(예: ReLU, Sigmoid)를 자유롭게 선택할 수 있다. AFU의 파라미터는 전체 네트워크 학습 과정에서 역전파를 통해 업데이트되며, 파라미터 공유 방식은 (i) 모든 뉴런·레이어가 동일한 AFU를 공유하거나, (ii) 레이어별·뉴런별로 별도 AFU를 할당하는 두 가지 경우로 나뉜다. 파라미터 증가량은 은닉 유닛 수에 비례하는 3N+1 정도에 불과해, 기존 네트워크에 큰 부하를 주지 않는다.
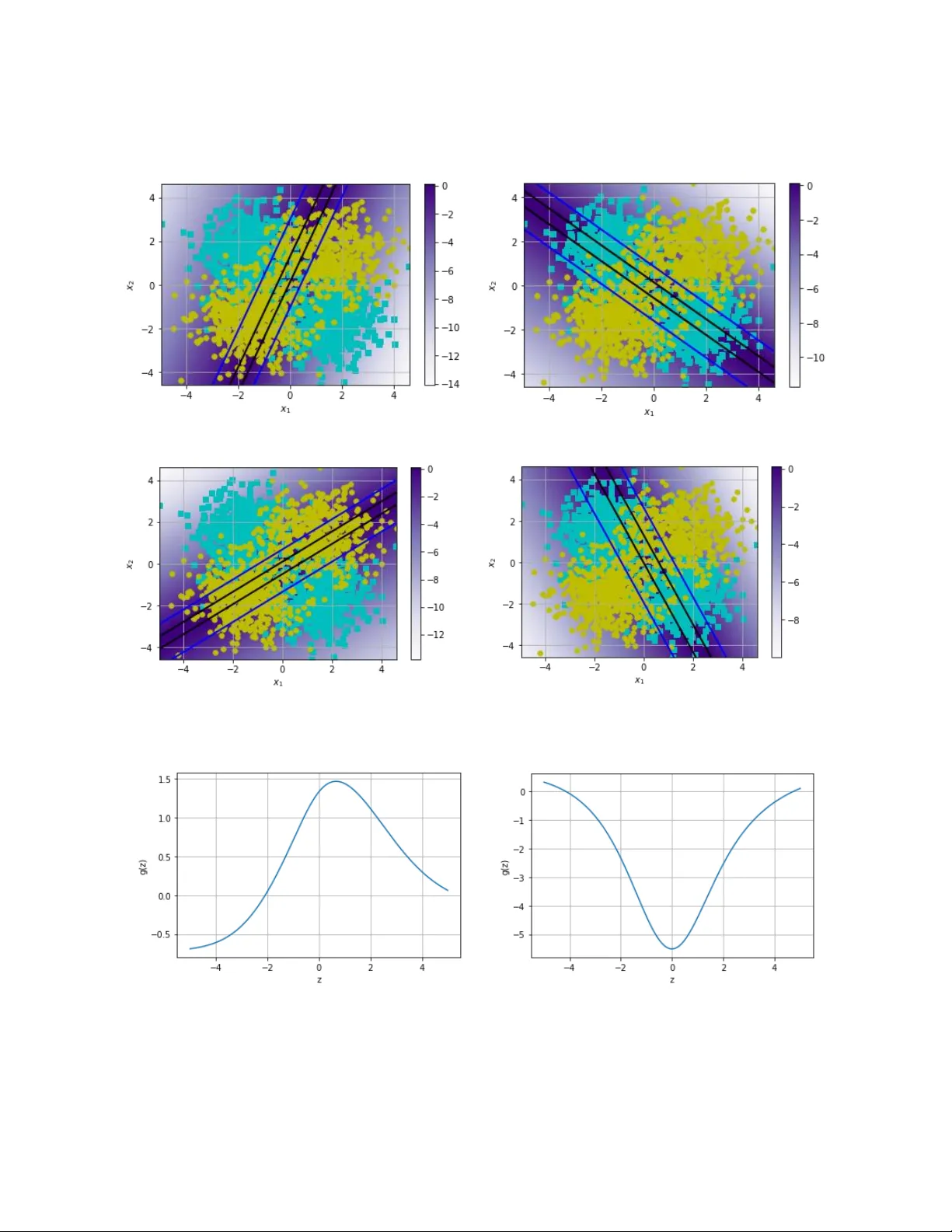
실험은 네 가지 데이터셋·구조에 대해 수행되었다. 첫 번째는 2차원 XOR 형태의 toy 문제로, 4개의 은닉 뉴런이 하나의 AFU를 공유하도록 설정하였다. 힌지 손실과 Adam 옵티마이저를 사용했으며, AFU는 초기 ReLU 기반에서 학습 후 원점에 중심을 둔 방사형 기저 함수와 유사한 형태로 변형되었다. 정확도는 기존 ReLU·Sigmoid·tanh와 차이가 없었지만, 활성화 함수가 비포화·연속적인 형태로 변함을 확인했다.
두 번째는 5‑레이어, 각 레이어 10 뉴런으로 구성된 무작위 초기화 네트워크에서 AFU와 ReLU를 비교한 “smoothness analysis”이다. 손실 표면을 시각화한 결과, AFU를 적용한 경우 전이 구간이 더 부드럽게 변해 급격한 기울기 변화가 감소했으며, 이는 활성화 함수가 연속적인 미분 가능성을 유지함에 따라 암묵적인 정규화 효과를 제공할 가능성을 시사한다.
세 번째는 MNIST 손글씨 분류 실험이다. 두 개의 합성곱 레이어와 두 개의 완전 연결 레이어를 갖는 네트워크에 대해 (i) 모든 레이어가 동일한 AFU를 공유, (ii) 레이어별로 독립적인 AFU를 사용하였다. 10 에폭 학습 후 정확도는 99.2%로 ReLU·tanh와 동일했으며, 성능 차이는 없었다. 그러나 학습된 AFU의 형태는 흥미로운 차이를 보였다. 전체 레이어에 동일 AFU를 적용했을 때는 Leaky‑ReLU와 유사한 형태가, 레이어별로 독립 AFU를 사용했을 때는 첫 번째 레이어에서 V‑shape, 두 번째 레이어에서 역 V‑shape, 마지막 완전 연결 레이어에서는 거의 선형에 가까운 형태가 학습되었다. 이는 깊은 네트워크가 층마다 다른 비선형 특성을 필요로 할 수 있음을 보여준다.
네 번째는 CIFAR‑10 이미지 분류에 MobileNetV2를 적용한 실험이다. 동일 AFU를 모든 레이어에 공유했을 때 최종 정확도는 85.1%였으며, 이는 Mish 활성화(86.3%)에 약간 못 미쳤다. 그러나 학습된 AFU는 Mish와 구조적으로 유사한 곡선을 형성했으며, 특히 음의 구간에서 부드러운 비선형성을 유지했다. 이는 AFU가 기존 설계된 활성화 함수와 비슷한 형태로 수렴할 수 있음을 의미한다.
논문의 결론에서는 다음과 같은 주요 인사이트를 도출한다. 첫째, 학습된 활성화 함수는 성능을 저하시키지 않으며, 경우에 따라 미세한 향상이 가능하다. 둘째, 학습 과정에서 비포화·연속적인 함수 형태가 자연스럽게 도출된다. 셋째, 레이어별로 서로 다른 비선형 특성이 학습될 수 있으며, 특히 깊은 네트워크의 뒤쪽 레이어는 보다 선형에 가까운 활성화를 선호한다. 넷째, 이러한 특성은 손실 표면을 부드럽게 만들어 잠재적인 정규화 효과를 제공할 수 있다. 다섯째, 기존 Mish와 유사한 형태가 자동으로 학습될 수 있음을 확인했으며, Mish에 추가 파라미터를 도입하면 성능을 약간 개선할 여지가 있다. 마지막으로, 활성화 함수 학습을 메타러닝 문제로 재구성하면, 특정 단계에서의 손실 감소량을 메타‑손실로 활용해 더 빠른 수렴을 유도할 수 있다. 전반적으로, 활성화 함수를 고정된 설계가 아닌 데이터‑주도적으로 학습하는 접근법이 이론적·실험적 가치를 가지고 있음을 입증하였다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기