TentacleNet: A Pseudo-Ensemble Template for Accurate Binary Convolutional Neural Networks
Binarization is an attractive strategy for implementing lightweight Deep Convolutional Neural Networks (CNNs). Despite the unquestionable savings offered, memory footprint above all, it may induce an excessive accuracy loss that prevents a widespread…
Authors: Luca Mocerino, Andrea Calimera
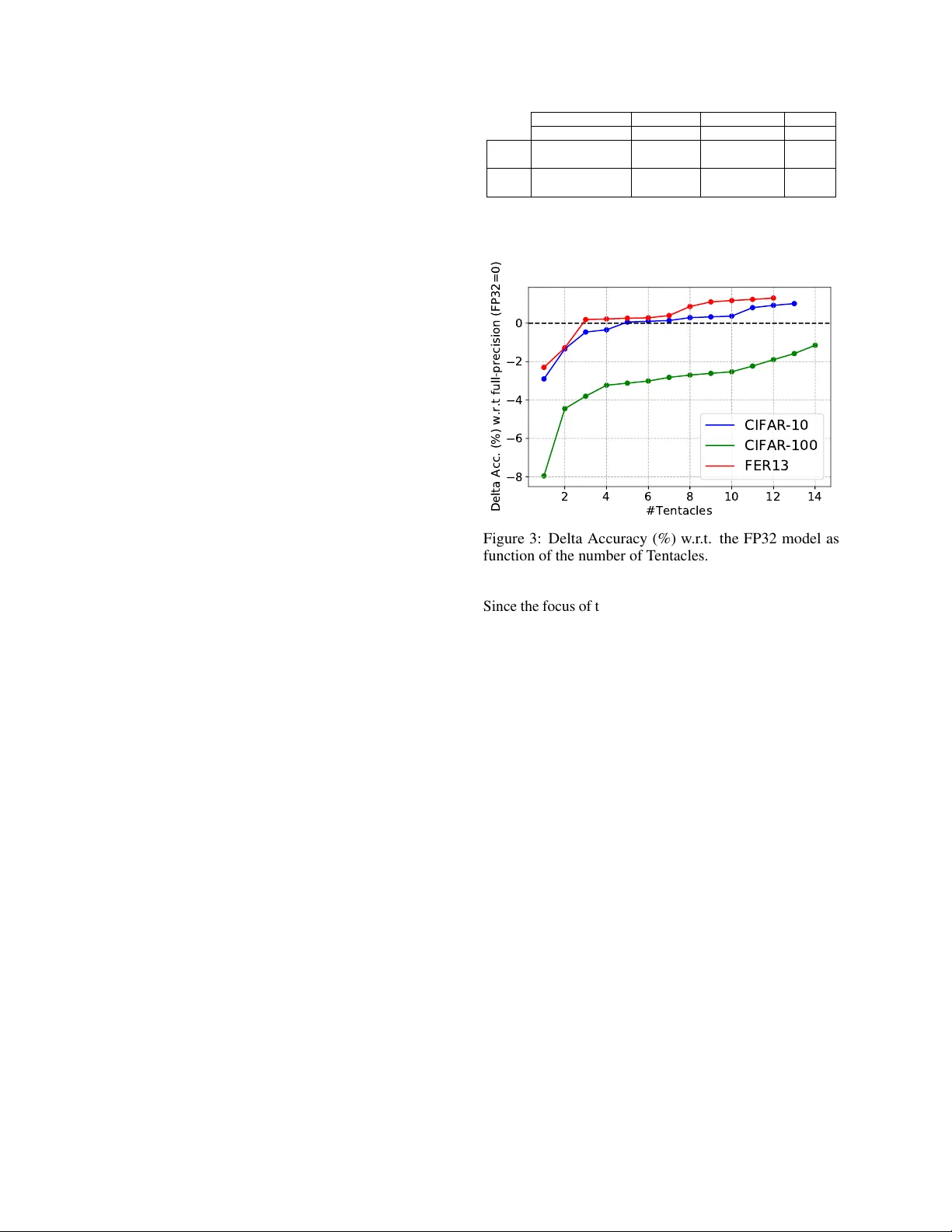
T E N T A C L E N E T : A P S E U D O - E N S E M B L E T E M P L A T E F O R A C C U R A T E B I N A RY C O N VO L U T I O N A L N E U R A L N E T W O R K S Luca Mocerino, Andrea Calimera Politecnico di T orino, 10129 T orino, Italy A B S T R AC T Binarization is an attractiv e strategy for implementing lightweight Deep Con volutional Neural Networks (CNNs). Despite the unquestionable sa vings offered, memory footprint abo ve all, it may induce an excessi ve accuracy loss that prev ents a widespread use. This work elaborates on this aspect introducing T entacleNet, a new template designed to improv e the predictiv e performance of binarized CNNs via parallelization. Inspired by the ensemble learning theory , it consists of a compact topology that is end-to-end trainable and or ganized to minimize memory utilization. Experimental results collected ov er three realistic benchmarks sho w T entacleNet fills the gap left by classical binary models, ensuring substantial memory savings w .r .t. state-of-the-art binary ensemble methods. K eywords Deep Learning · Machine Learning · Binary Neural Network · Optimization This is a Preprint . Accepted to be Published in Proceedings of © 2020 IEEE International Conference on Artificial Intelligence Circuits and Systems, March 23-25 2020, Genov a, Italy . IEEE Copyright Notice. © 2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collecti ve works, for resale or redistrib ution to servers or lists, or reuse of any copyrighted component of this work in other works. 1 Introduction Con volutional Neural Netw orks (CNNs) are known to be highly redundant, a positi ve characteristic for the training because it helps to achiev e higher accuracy , but highly undesired during inference, when extra-functional met- rics, like latency , energy and memory footprint, are just as important. No matter if the tar get is a cloud application hosted on a serv er queried by millions of users, or a mobile application run on low-po wer cores with limited resources, an efficient use of CNNs calls for effecti ve optimization strategies. There is plenty of compression or approximation tech- niques that serve this purpose operating at dif ferent lev els of abstraction which lev erage different knobs [1 – 3]. At the bit-le vel, binarization is a v ery attractive option. The pioneering idea, firstly introduced in [4] and then elabo- rated in [5] and [6], is to project weights and/or acti vations into a binary space. Moving from multi-bit representations (either floating-point or fixed-point) to single-bit has clear advantages, such as the lo wering of the memory footprint and a better use of the available bandwidth since operands can be packed in a single line and accessed in parallel. Moreov er, it allows the replacement of real and integer arithmetic with bit-wise operators, e.g. parallel Boolean XNOR and pop-counting [6], which are faster and less resource demanding. This latter aspect is ho wev er influ- enced by the type of hardware av ailable. General purpose architectures grew to support mainstream applications op- erating on single-precision floating-point, therefore, less frequent instructions and unusual data representations, like those deployed in binary CNNs, ha ve been dropped for the sake of area efficiency . T o fill this gap, software macros can be used to unpack data and properly feed the ex ecu- tion units. This may introduce substantial performance ov erhead [7]. Dedicated hardware accelerators, like those introduced in [8 – 11], may be a better option as they can push binary CNNs tow ard impressiv e speed-up. In spite of the potential savings brought, the use of binary CNNs is still quite limited, sometimes prohibiti ve, because of the poor predictiv e quality . For instance, compared to full-precision (32-bit floating-point), the accuracy drop may range from 2% to 10%, but ev en more depending on the complexity of the task [6]. The objective of this work is to address this limitation introducing a new model template named T entacleNet . The basic working principle is inspired by the ensemble learning theory , well known in machine and deep learning [12], that is, the assembly of many weak classifiers enables a str ong predictor with higher accuracy . Howe ver , T entacleNet shows distincti ve features that hav e been specifically designed to leverage the power of binary BNNs and to optimize resource usage. Moreov er, it is end-to-end trainable and can be applied to any generic CNN model using the training procedures av ailable in common deep learning framew orks. Due to its parallel topology , T entacleNet is ready for the forthcoming Accepted to be Published in Pr oceedings of ©2020 IEEE International Conference on Artificial Intelligence Cir cuits and Systems, Mar ch 23-25 2020, Genova, Italy . generation of parallel architectures with heterogeneous accelerators [13]. Experimental results collected ov er three computer vision tasks, i.e. image classification on CIF AR-10 and CIF AR- 100 [14] and facial expression recognition on the FER13 data-set [15], re veal T entacleNet can reach the accuracy of full-precision models, yet ensuring much lower mem- ory footprint compared to state-of-the-art binary ensemble methods [16]. 2 Background and Pr evious W orks 2.1 Binarized Neural Networks The recent literature shows se veral binarization methods for CNNs. In [4], Courbariaux et al. introduced the concept of CNNs with binary weights in the range {-1, 1}, leav- ing the activ ations in full-precision (floating-point 32-bit). In [5], the same authors presented a full-binary CNN where also the activ ations get projected in a binary space using a sign acti vation function. That is the first example of a full-binary CNNs processed with bit-wise XNOR and pop- counting, with no floating-point arithmetic. As side ef fect, the prediction accuracy suf fered substantial degradation ( ≥ 10%) . Later , M. Rastegari et. al. presented XNOR- Net [6], an alternati ve architecture to mitigate the accurac y drop by re-scaling the binary output of each conv olutional layer through a full-precision normalization layer . The improv ement over [5] was remarkable: up to 16.3% on ImageNet [17]. The XNOR-Net represents still today the state-of-the-art for binary CNNs and therefore we bor- rowed the same architecture in this w ork (simply referred as BNN hereafter). Howe ver , our strategy can be extended to any type of binarized network. 2.2 Featur e Extraction in a BNN Giv en x ∈ R ch × w in × h in as the input feature and w ∈ R ch × kw × kh as the weight tensor, their con volution is ap- proximated as follows: x ∗ w ≈ popcount ( X xnor W ) · K · α (1) where K and α are the scaling factors. While weights ( W ) are binarized off-line, the binary acti v ation function is fused with the batch normalization and hence run on- line. Given the parameters of the batch normalization, i.e. variance σ 2 , mean µ , scale γ , shift factor β , a coefficient for numerical stability , a generic feature map x is binarized as follows: X = B inAC T 0 , 1 ( x ) = 1 x ≥ c 0 x < c (2) with c = µ − β /γ √ σ 2 + . As additional details, we do not use K , that is the activ ations scaling factor , in order to speed-up the training stage; c and α are represented as 32-bit floating point numbers. It is worth to notice that within a BNN, the first and the last layers are kept and processed to full-precision (floating- point 32-bit) in order to mitigate the accuracy drop induced by the binarization of the inner layers. This is a rele vant characteristic exploited by T entacleNet. The efficient processing of a BNN requires an effecti ve implementation of parallel bit-wise XNOR, pop-counting, and bit-2-word packing/unpacking (e.g. from 1 to 32-bit and vice-versa). While ne w specialized cores hav e an ex- tended instruction-set coupled with dedicated hardware units, e.g. [8], for many general-purpose cores the only viable option is to make custom software macros. The performance gap between hardware acceleration and soft- ware implementation is lar ge, with the latter being much slower [7]. For instance, in [18] Moss et al. showed that a custom FPGA-based inference engine gets 8.5 × faster and 20 × more energy ef ficient. T entacleNet is orthogonal to the kind of hardware, but it would benefit most from custom accelerators. 2.3 Ensembles Learning Ensemble methods are well-kno wn tools in statistics and machine learning; the y are commonly used to improve resilience against under -/over -fitting [12]. The basic prin- ciple is simple, yet effecti ve: use multiple weak estimators to build up with a single str ong classifier . Random forests are practical examples, where the weak classifiers consist of decision trees [19]. Existing ensemble strategies mainly dif fer on ( i ) the train- ing procedure adopted and ( ii ) how the outcome of the weak estimators are grouped and ev aluated. The taxonomy is as follows: Bagging [20]. The training dataset D is randomly parti- tioned into N sub-sets d i ( i ∈ [1 , N ] ), with N the number of weak estimators. Each weak estimator is trained using d i as the training set. During inference, the outputs of the N estimators are a veraged or e valuated with a voting mechanism. Boosting [21, 22]. Each weak estimator is trained (sep- arately) ov er the full dataset D . The outputs of the N estimators are then fused using a linear transformation whose coef ficients are learned at training time, for instance using AdaBoost algorithm [23]. Stacking [24, 25]. The N weak estimators are trained on the original data D . Then, their outputs are used as training-set for an additional meta-estimator , which is run in sequence during inference. The ke y feature is that the stack is built upon heterogeneous estimators. There exist different w orks that proposed the use of ensem- ble methods for deep neural networks. Remarkable results are reported in [26], where the authors adopted a boosting strategy on image classification, b ut also in CoopNet [27] which combines multiple precision models to improv e ac- curacy and inference latency . Even more interesting, the concept of ensemble learning can be found in the internal architecture of the most recent CNN models. For instance ResNet [28], DenseNet [29] and Inception series [30] have layers which combine branches produced by the previous 2 Accepted to be Published in Pr oceedings of ©2020 IEEE International Conference on Artificial Intelligence Cir cuits and Systems, Mar ch 23-25 2020, Genova, Italy . layers to improv e performance. This resembles an ensem- ble learning structure indeed. All the abov e methods were thought to improv e accuracy , with no particular attention to the complexity of the weak classifiers. The result is a dramatic increase in the model size. When extra-functional metrics (e.g. memory and la- tency) enter the cost function, the selection of the weak es- timators should be resource-oriented and not just accuracy- driv en. In this regard, binary CNNs are good candidates: they are weak, fast and small. Some recent w orks explored this option. For instance, in [16] the authors adapted the classical ensemble methods to binary CNNs, bagging and boosting in particular . The collected results re vealed that a large number of BNNs is needed to get close to the ac- curacy of the full-precision model, thus resulting in large memory space. T entacleNet takes a step forward, showing that binary ensembles can reach high accuracy with fe wer resources. 3 T entacleNet 3.1 Architectur e T entacleNet is a parallel template embedding lightweights BNNs in a pseudo-ensemble structure. It serves an y kind of feed-forward CNN, namely , any full-precision CNN can be translated follo wing the T entacleNet template and exploit the binary computation. A high-lev el view is depicted in Fig. 1. The inner core consists of n parallel branches, the tentacles , which play as the weak estimators. Each tentacle (labeled as BNN i ) is a replica of the binarized floating-point model, except for the first and last layer which are shared among all the tentacles, these are the Con volutional Bloc k and the Fully-Connected Block in Fig. 1. The former (grey box) is in charge of producing a common activ ation map fed as input to all the tentacles. It contains three sub-layers, con volution (CONV), normalization (Norm) and acti vation (A CT). The latter (blue box) implements the actual classification of the binary features extracted along the tentacles. It is worth emphasizing that all the tentacles operate full binary operations [-1,1], while the Con volutional Block and the Fully-Connected Block are taken to full-precision [FP], i.e. floating-point 32-bit. This design choice is inherited from state-of-the-art BNN models [4 – 6], which suggest leaving the first and last layer to full-precision gets higher accuracy . Another important aspect is that the sharing of the two blocks, the most memory demanding due to high arithmetic precision, contributes to sa ve memory space. The shape of the shared Fully-Connected Block differs depending on the topology of the original full-precision model. If the original model does produce the C logits through global pooling (where C is the number of classes), namely , without any fully-connected layer (Fig. 2-a), the logits are simply concatenated as a 1-D vector of cardinal- ity N × C and then fed as input to the Fully-Connected Block , which is a dense layer of shape N × C inputs and BinCONV m-1 Convolutional Block BNN 1 BNN 2 BNN n Fully- Connected Block 1,2 ... C CONV Norm ACT Conv . Block Baseline BNN BinCONV 2 BinCONV 3 [FP] [FP] [-1,1] Figure 1: T entacleNet architecture. CONV refers to con- volutional layers, Norm to normalization layer , A CT to activ ation layers. The prefix Bin stands for binary . (b) (a) 1,2 ... C 1,2 ... C 1,2 ... C BNN 1 BNN 2 BNN n N x C FC BNN x BNN 2 BNN n 1 ,2 ... C 1,2 ... K 1,2 ... K 1,2 ... K N x K Figure 2: Composition of the Fully-Connected Block N × C 2 weights. Otherwise, if the original model has its own fully-connected layer to produce the logits (Fig. 2-b), we drop it out and concatenate the feature maps as a 1-D vector of cardinality N × K , with K the number of features of each weak estimator; in such case the Fully- Connected Block is a dense layer of shape N × K inputs and N × K × C weights. 3.2 Building and T raining Methodology T entacleNet can be seen as a pseudo-ensemble that imple- ments some mixed features belonging to the stacking and boosting methods, in particular: the stack is composed of heterogeneous learners with dif ferent data-representation; the outputs of the weak estimators are e valuated through a linear transformation; all the layers, including the first and last block, are trained within a single procedure using the same data-set. The result is an end-to-end trainable model whose parameters can be learned through classical back-propagation. The assembling of T entacleNet encompasses few stages. The entry le vel is a pre-trained floating-point CNN model binarized following the topology described in [6], namely , first and last layers as floating-point and the inner m − 2 layers as binary . The sequence of such m − 2 binary layers (from BinCONV 2 to BinCONV m − 1 as reported in the left diagram of Fig.1) builds a tentacle. n replicas of the same 3 Accepted to be Published in Pr oceedings of ©2020 IEEE International Conference on Artificial Intelligence Cir cuits and Systems, Mar ch 23-25 2020, Genova, Italy . tentacle are placed in parallel (from BNN 1 to BNN n in Fig. 1) and then tied to the top and the bottom with the first con volutional block and the last fully connected block as described in the section 3.1. Once the T entacleNet is assembled, the training procedure described in [6] is deployed to learn the weights of the binary tentacles and the weights of the shared layers. In order to guarantee enough expressiv e power and reduce the risk of under -/over -fitting, the tentacles are initialized with dif ferent seeds. Sax e et al. [31] demonstrated that weights initialized with orthonormal or orthogonal bases achiev e better performance. In the binary domain, the ma- trices that satisfy these conditions are called Hadamard matrices . They are square matrices of order 1, 2, or 4 n , with n ∈ N ; the entries are -1 and 1 and can be generated using Sylvester’ s method. In order to adapt the Hadamard matrices to the dimensions of the binary kernels within the tentacles, the rows are randomly removed (to reduce the rank) or replicated (to increase the rank). The result- ing pseudo -Hadamard matrices are sub-optimal but still a fa vorable initialization [5]. 4 Experimental results 4.1 Benchmarks and Data-sets T entacleNet has been ev aluated on the following tasks. Image Classification (CIF AR-10/100) - the standard im- age classification problem; the data-set contains 60k 32x32 RGB labeled images and can be configured for 10- or 100- class recognition [14]. Facial Expression Recognition (FER13) - emotion recognition from facial expression; the data-set collects 36k 48x48 gray-scale facial images labeled with se ven different f acial expressions [15]. Each of the abov e tasks is implemented through a special- ized CNN model as reported in T able 1; the same models work as baseline to b uild the T entacleNet. The table col- lects the classification accuracy (%) and the model size (kB) of the three networks trained in full-precision 32- bit (ro w FP32) and after binarization (row BNN); here the BNN models refer to XNOR-Net [6]. As expected, BNNs reach remarkable memory reduction (e.g. 24.2 × for ResNet9 on CIF AR-100) at the cost of significant accurac y loss (8.05% as the worst-case). 4.2 T raining and Inference Set-Up For each task a dedicated T entacleNet is built starting from the BNN model. The training of T entacleNet iterates for 300 epochs using an adaptiv e learning rate ( lr ) schedule: lr updated with step 0.1 ev ery 15 consecutiv e epochs in which the validation loss does not change. Both training and inference stages are implemented using PyT orch (version 1.1.0) and made run on a serv er po wered with 40-core Intel Xeon CPUs and accelerated with the NVIDIA Titan Xp GPU (CUD A v10.0). Dataset CIF AR-10 CIF AR-100 FER13 Baseline Model NiN [32] ResNet9 [28] FerNet FP32 Accuracy (%) 88.11 68.25 65.16 Model Size (kB) 3778 19984 1880 BNN Accuracy (%) 85.20 60.20 62.86 Model Size (kB) 181 826 64 T able 1: Benchmarks: Datasets and CNNs 2 4 6 8 10 12 14 #Tentacles 8 6 4 2 0 Delta Acc. (%) w.r.t full-precision (FP32=0) CIFAR-10 CIFAR-100 FER13 Figure 3: Delta Accuracy (%) w .r .t. the FP32 model as function of the number of T entacles. Since the focus of this paper is on the accurac y-vs-memory tradeoff of binary ensembles, the assessment of hardware- dependent extra-functional metrics, like latency and ener gy , is left aside as part of future works. 4.3 Perf ormance assessment The objectiv e of this section is twofold: ( i ) prov e that T entacleNet can push binary CNNs towards full-precision accuracy; ( ii ) show that T entacleNet outperforms existing binary-ensemble methods, both in terms of accurac y and memory . Concerning the first issue, Fig. 3 reports a parametric anal- ysis of the classification accuracy achiev ed by T entacleNet on the three benchmarks. The line plot shows the delta accuracy , which is the difference between T entacleNet and the FP32 model; the break-e ven point is centered on zero (horizontal dotted line). Deploying just one tentacle, T en- tacleNet collapses to the original BNN model, namely , the accuracy drop is the same reported in T able 1. As a general trend, the distance to FP32 gets smaller with the number of tentacles. For NiN ov er CIF AR-10 and FerNet ov er FER13 T entacleNet reaches the break-ev en with 3 and 5 tentacles respectiv ely , and it goes even abo ve tow ards positiv e values, +1.00% with 13 tentacles for CIF AR-10 and +1.31% with 12 tentacles for FER13, meaning that it outperforms FP32 models with much less weight memory: 645kB vs 3778kB for CIF AR-10 (83% savings), 188kB vs 1880kB for FER13 (90% savings). The behavior for ResNet ov er the more comple x CIF AR-100 data-set is less 4 Accepted to be Published in Pr oceedings of ©2020 IEEE International Conference on Artificial Intelligence Cir cuits and Systems, Mar ch 23-25 2020, Genova, Italy . performing compared to the other two benchmarks, yet re- markable. With 14 tentacles, the delta accuracy impro ves from -8.05% to -1.15%, very close to FP32, still ensur- ing low memory footprint, 11465 kB vs 19984 (42.6% less). For all the three benchmarks, additional experiments rev ealed the accuracy of T entacleNet saturates, namely , there is no further improvement by increasing the num- ber of tentacles; the top right points of the three lines in the plot of Fig. 3 show the highest accuracy that can be reached. For what concerns the second issue, we provide Benchmark T emplate ∆ (%) #Ensemble/ T entacle M. Size (kB) CIF AR-10 (NiN) [16] Bagging 0 12 2167 Boosting 0 8 1445 T entacleNet 0 5 645 (55.3%) CIF AR-100 (ResNet9) [16] Bagging -4.82 30 24755 Boosting -4.77 25 20629 T entacleNet -1.15 14 11465 (44.4%) FER13 (FerNet) [16] Bagging -0.35 11 697 Boosting -0.67 26 1648 T entacleNet 0 3 188 (73.0%) T able 2: T entacleNet vs BENN [16] a quantitative comparison against BENN [16], which is state-of-the-art for binary ensembles. The BENN strategy is to apply standard ensemble methods to BNNs, bagging and boosting in particular . T o ensure a fair comparison we implemented and applied the two BENN methods on the benchmarks under analysis. The main results are collected in T able 2, which reports the delta accuracy w .r .t. the FP32 model (as in Fig.3), the number of ensembles (for BENN) or tentacles (for T entacleNet), and the memory footprint (the percentage reported in brackets refers to the memory savings of T entacleNet w .r .t. the smallest BENN model). When possible, the comparison is done at the break-e ven point with the FP32 model (i.e. ∆ =0), otherwise at the highest achiev able accuracy . T entacleNet is more accurate and more compact than BENN over the three benchmarks. For instance, considering the NiN model o ver CIF AR-10, both BENN and T entacleNet achiev e the accuracy of the FP32 model, b ut T entacleNet needs less memory to store the weights (55.3% less w .r .t. boosting). Larger savings hav e been observed for FerNet over the FER13 bench- mark, where BENN and T entacleNet are almost equi valent in terms of accuracy (T entacleNet +0.35% more accurate than BENN bagging), but with a large memory spread (T en- tacleNet is 73% smaller than BENN bagging). Also for the most complex netw ork, namely ResNet over CIF AR-100, T entacleNet reaches higher accurac y (+3.62% w .r .t. BENN boosting) with large memory savings (44.4%). T o be noted that the memory footprint of the smallest BENN (20629 kB) gets bigger than the original FP32 model (19984 kB). Overall, T entacleNet is more accurate and much smaller than other binary ensemble methods. 5 Conclusions References [1] V . Sze et al. , “Efficient processing of deep neural networks: A tutorial and survey , ” Pr oceedings of the IEEE , vol. 105, no. 12, pp. 2295–2329, 2017. [2] S. Han et al. , “Eie: efficient inference engine on com- pressed deep neural network, ” in 2016 ACM/IEEE 43r d Annual International Symposium on Computer Ar chitectur e (ISCA) . IEEE, 2016, pp. 243–254. [3] L. Mocerino et al. , “Energy-ef ficient con volutional neural networks via recurrent data reuse, ” in 2019 Design, Automation & T est in Eur ope Confer ence & Exhibition (D A TE) . IEEE, 2019, pp. 848–853. [4] M. Courbariaux et al. , “Binaryconnect: T raining deep neural networks with binary weights during propagations, ” in Advances in neural information pr ocessing systems , 2015, pp. 3123–3131. [5] ——, “Binarized neural netw orks: Training deep neu- ral networks with weights and acti vations constrained to+ 1 or-1, ” arXiv pr eprint arXiv:1602.02830 , 2016. [6] M. Rastegari et al. , “Xnor -net: Imagenet classifica- tion using binary con volutional neural networks, ” in Eur opean Confer ence on Computer V ision . Springer , 2016, pp. 525–542. [7] Y . Hu et al. , “Bitflo w: Exploiting vector parallelism for binary neural networks on cpu, ” in 2018 IEEE International P arallel and Distributed Pr ocessing Symposium (IPDPS) , May 2018, pp. 244–253. [8] Y . Umuroglu et al. , “Finn: A framew ork for fast, scalable binarized neural network inference, ” in Pro- ceedings of the 2017 A CM/SIGDA International Sym- posium on F ield-Pr ogrammable Gate Arr ays . A CM, 2017, pp. 65–74. [9] A. Al Bahou et al. , “Xnorbin: A 95 top/s/w hardware accelerator for binary conv olutional neural networks, ” in 2018 IEEE Symposium in Low-P ower and High- Speed Chips (COOL CHIPS) . IEEE, 2018, pp. 1–3. [10] Y . Li et al. , “ A 7.663-tops 8.2-w energy-ef ficient fpg a accelerator for binary conv olutional neural networks, ” in FPGA , 2017, pp. 290–291. [11] R. Andri et al. , “Y odann: An ultra-low po wer con vo- lutional neural network accelerator based on binary weights, ” in 2016 IEEE Computer Society Annual Symposium on VLSI (ISVLSI) . IEEE, 2016, pp. 236– 241. [12] T . G. Dietterich, “Ensemble methods in machine learning, ” in Pr oceedings of the Fir st International W orkshop on Multiple Classifier Systems , ser . MCS ’00. London, UK, UK: Springer -V erlag, 2000, pp. 1–15. [13] A. Garofalo et al. , “Pulp-nn: Accelerating quantized neural networks on parallel ultra-low-po wer risc-v processors, ” arXiv preprint , 2019. 5 Accepted to be Published in Pr oceedings of ©2020 IEEE International Conference on Artificial Intelligence Cir cuits and Systems, Mar ch 23-25 2020, Genova, Italy . [14] A. Krizhevsk y , “Learning multiple layers of features from tiny images, ” T ech. Rep., 2009. [15] I. J. Goodfello w et al. , “Challenges in representa- tion learning: A report on three machine learning contests, ” Neural Networks , vol. 64, pp. 59–63, 2015. [16] S. Zhu et al. , “Binary ensemble neural network: More bits per network or more networks per bit?” in Pr o- ceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , 2019, pp. 4923–4932. [17] J. Deng et al. , “Imagenet: A large-scale hierarchical image database, ” in 2009 IEEE confer ence on com- puter vision and pattern r ecognition . Ieee, 2009, pp. 248–255. [18] D. J. M. Moss et al. , “High performance binary neural networks on the x eon+fpga ™ platform, ” in 2017 27th International Confer ence on F ield Pr ogrammable Logic and Applications (FPL) , Sep. 2017, pp. 1–4. [19] L. Breiman, “Random forests, ” Machine learning , vol. 45, no. 1, pp. 5–32, 2001. [20] ——, “Bagging predictors, ” Machine Learning , vol. 24, no. 2, pp. 123–140, Aug 1996. [21] R. E. Schapire, “The strength of weak learnability , ” Machine Learning , vol. 5, no. 2, pp. 197–227, Jun 1990. [22] ——, “The boosting approach to machine learning: An overvie w , ” in Nonlinear estimation and classifi- cation . Springer , 2003, pp. 149–171. [23] Y . Freund et al. , “ A short introduction to boosting, ” Journal-J apanese Society F or Artificial Intelligence , vol. 14, no. 771-780, p. 1612, 1999. [24] D. W olpert et al. , “Combining stacking with bagging to improv e a learning algorithm, ” Santa F e Institute, T echnical Report , 1996. [25] L. Breiman, “Stacked re gressions, ” Machine Learn- ing , vol. 24, pp. 49–64, 1996. [26] M. Moghimi et al. , “Boosted conv olutional neural networks. ” in BMVC , 2016, pp. 24–1. [27] L. Mocerino et al. , “Coopnet: Cooperati ve con volu- tional neural network for low-po wer mcus, ” arXiv pr eprint arXiv:1911.08606 , 2019. [28] K. He et al. , “Deep residual learning for image recog- nition, ” in Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , 2016, pp. 770–778. [29] G. Huang et al. , “Densely connected conv olutional networks, ” in Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , 2017, pp. 4700–4708. [30] C. Szegedy et al. , “Going deeper with con volutions, ” in Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , 2015, pp. 1–9. [31] A. M. Saxe et al. , “Dynamics of learning in deep linear neural networks, ” in NIPS W orkshop on Deep Learning , 2013. [32] M. Lin et al. , “Network in netw ork, ” arXiv pr eprint arXiv:1312.4400 , 2013. 6
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment