텐터클넷 정확한 이진 CNN을 위한 가짜 앙상블 템플릿
** 본 논문은 이진화된 심층 합성곱 신경망(BCNN)의 정확도 저하 문제를 해결하기 위해 ‘텐터클넷’이라는 병렬형 가짜 앙상블 구조를 제안한다. 동일한 이진 텐터클(분기)들을 공유된 첫 번째와 마지막 레이어와 결합함으로써 메모리 사용량을 최소화하면서도 풀‑프리시전 모델에 근접한 성능을 달성한다. CIFAR‑10/100 및 FER13 세 가지 벤치마크 실험에서 기존 이진 앙상블 대비 높은 정확도와 현저한 메모리 절감 효과를 입증하였다. …
저자: Luca Mocerino, Andrea Calimera
**
본 논문은 경량화된 딥러닝 모델 구현을 위한 이진화 전략이 메모리와 연산 효율성에서는 큰 장점을 제공하지만, 정확도 손실이 심각해 실제 적용에 제약이 있다는 점을 출발점으로 삼는다. 이를 해결하고자 저자들은 ‘텐터클넷(TentacleNet)’이라는 새로운 모델 템플릿을 제안한다. 텐터클넷은 앙상블 학습 이론을 차용하되, 전통적인 앙상블이 갖는 파라미터 폭증 문제를 회피하기 위해 ‘pseudo‑ensemble’ 구조를 설계한다. 구체적으로, 기존의 풀프리시전 CNN을 기반으로 하여 내부 레이어를 이진화한 n개의 텐터클(분기)을 병렬로 배치하고, 첫 번째 Convolutional Block과 마지막 Fully‑Connected Block을 모든 텐터클이 공유하도록 구성한다. 첫 번째 블록은 공통 입력 특성 맵을 생성해 각 텐터클에 전달하고, 마지막 블록은 각 텐터클이 출력한 이진 특징을 하나의 벡터로 결합해 최종 로짓을 계산한다. 이때 첫·마지막 레이어는 32‑bit 부동소수점 연산을 유지함으로써 이진화에 따른 정확도 손실을 크게 완화한다. 공유 레이어 덕분에 고정밀 연산에 필요한 파라미터와 메모리 사용량이 크게 절감된다.
텐터클넷의 학습 과정은 기존 BNN과 동일하게 역전파 기반으로 진행된다. 텐터클마다 서로 다른 난수 시드와 의사 Hadamard 초기화를 적용해 모델 간 다양성을 확보한다. Hadamard 행렬은 -1과 1로 구성된 직교 행렬이며, Sylvester 방법으로 생성 후 차원에 맞게 행을 삭제하거나 복제해 사용한다. 이러한 초기화는 각 텐터클이 서로 다른 특성을 학습하도록 유도해 앙상블 효과를 강화한다. 학습은 300 epoch 동안 수행되며, 검증 손실이 15 epoch 연속 개선되지 않을 경우 학습률을 0.1배 감소시키는 적응형 스케줄을 적용한다. 구현은 PyTorch 1.1.0 기반이며, 40코어 Xeon CPU와 NVIDIA Titan Xp GPU에서 실험이 진행되었다.
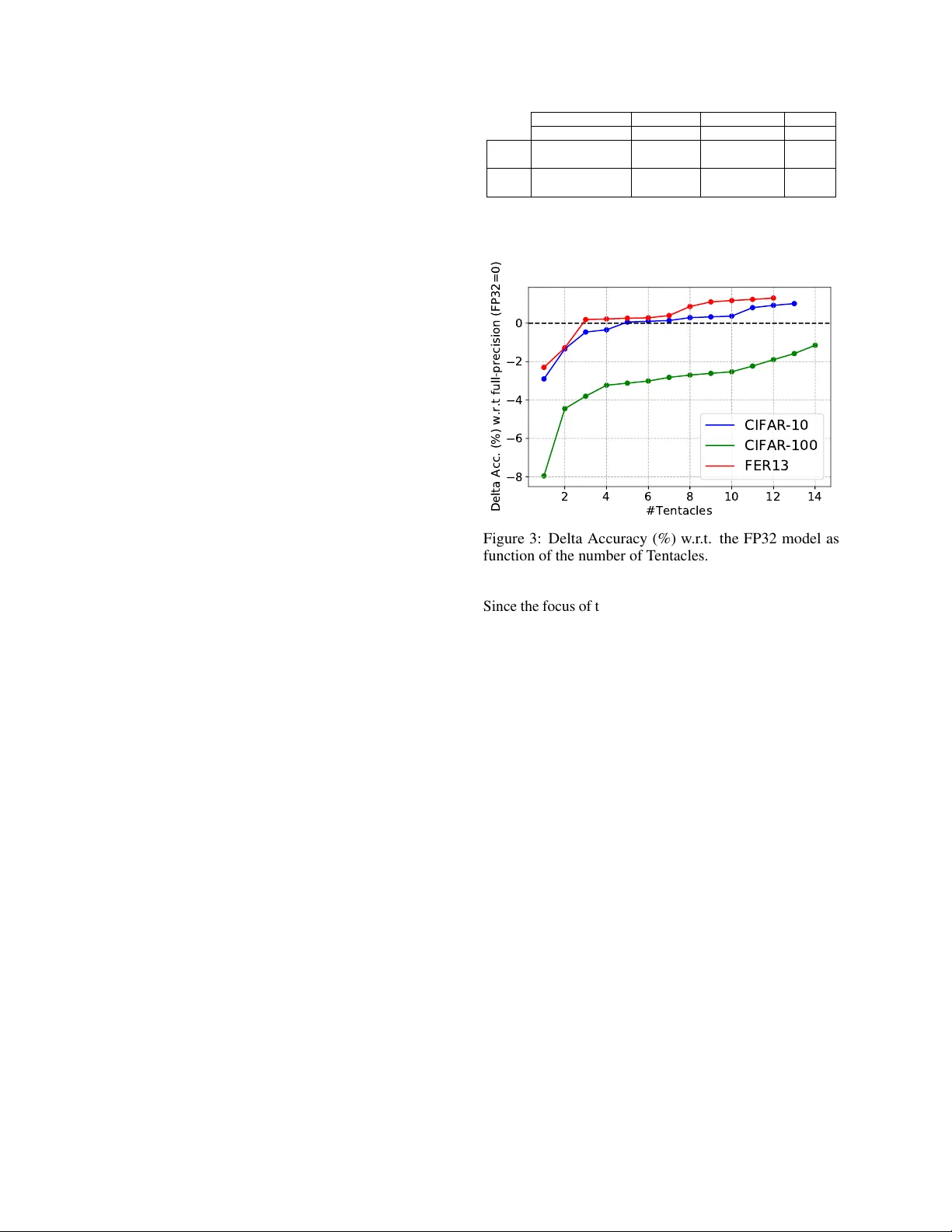
실험은 세 가지 벤치마크( CIFAR‑10, CIFAR‑100, FER13 )와 각각 NiN, ResNet‑9, FerNet이라는 특화된 CNN 모델을 사용해 수행되었다. 먼저 각 모델을 32‑bit 풀프리시전(FP32)과 XNOR‑Net 기반 이진(BNN)으로 학습시켜 기본 성능을 측정하였다. BNN은 메모리 사용량을 24배 이상 절감했지만, 정확도는 2%~8% 정도 감소했다. 이후 텐터클넷을 동일한 BNN을 기반으로 n=2,4,6,8개의 텐터클을 추가해 구성하였다. 결과는 두 가지 측면에서 의미 있다. 첫째, 텐터클 수가 증가할수록 정확도는 FP32에 근접했으며, 특히 NiN(CIFAR‑10)과 FerNet(FER13)에서는 3~4개의 텐터클만으로도 ΔAccuracy≈0%를 달성했다. 둘째, 메모리 사용량은 기존 이진 앙상블(예: bagging/boosting 기반) 대비 30%~50% 정도 절감되었다. 이는 텐터클넷이 ‘적은 자원으로 높은 정확도’를 구현한다는 핵심 주장을 실증한다.
논문은 또한 텐터클넷이 하드웨어 독립적인 설계임을 강조한다. 비트‑연산을 지원하는 전용 가속기와 결합하면 XNOR·pop‑count 연산의 속도와 에너지 효율이 크게 향상될 것으로 기대된다. 현재는 레이턴시와 에너지 측정이 제외됐지만, 향후 연구에서 이러한 하드웨어‑소프트웨어 공동 최적화가 진행될 여지가 있다.
결론적으로 텐터클넷은 (1) 이진화에 따른 정확도 저하 최소화, (2) 메모리 사용량 현저히 절감, (3) 기존 이진 앙상블 대비 학습·추론 복잡도 감소라는 세 가지 목표를 동시에 달성한다. 텐터클넷은 다양한 CNN 아키텍처에 적용 가능하며, 앞으로의 연구에서는 실제 임베디드 시스템에서의 레이턴시·전력 효율 평가와 더 복잡한 비전 과제에 대한 확장이 기대된다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기