Learned imaging with constraints and uncertainty quantification
We outline new approaches to incorporate ideas from deep learning into wave-based least-squares imaging. The aim, and main contribution of this work, is the combination of handcrafted constraints with deep convolutional neural networks, as a way to h…
Authors: Felix J. Herrmann, Ali Siahkoohi, Gabrio Rizzuti
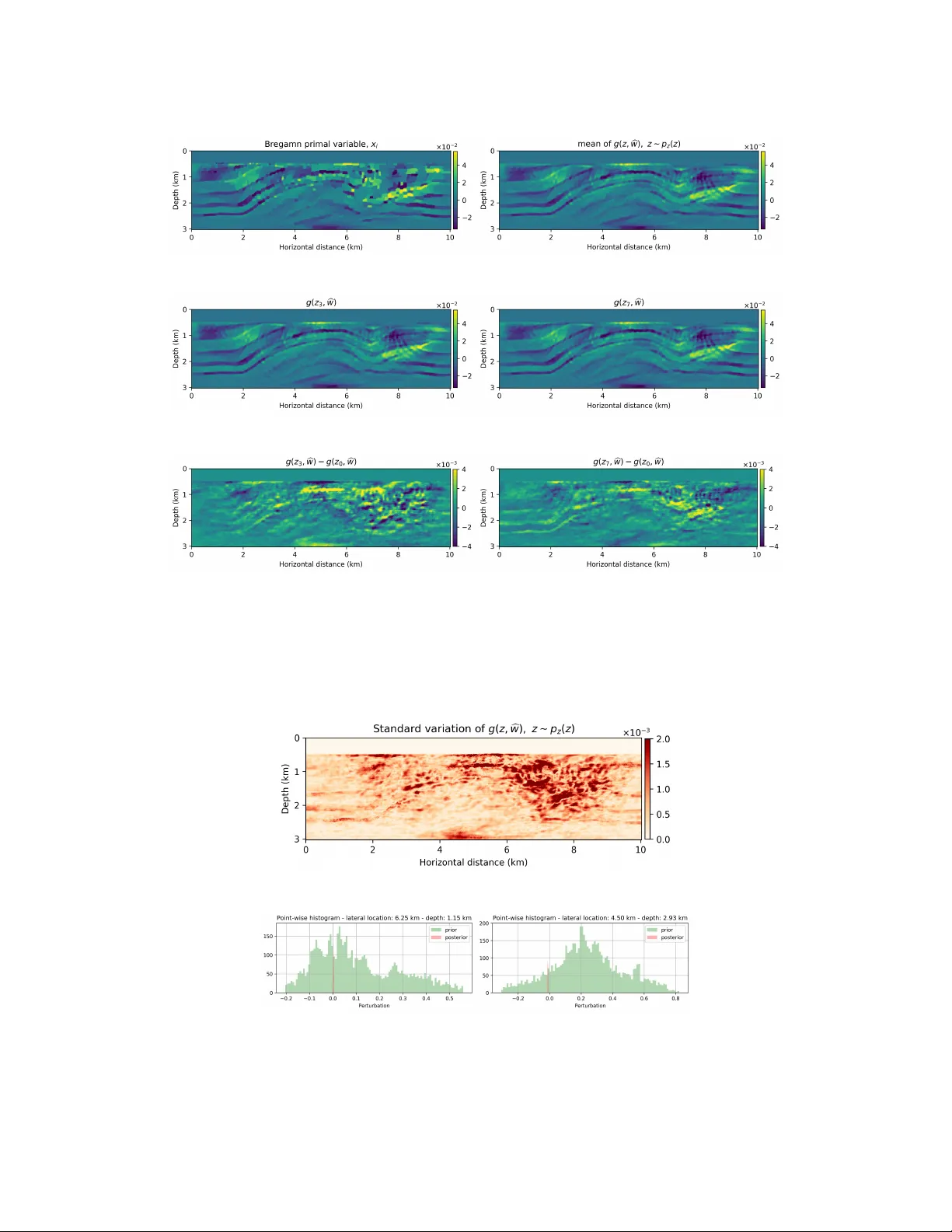
Lear ned imaging with constraints and uncertainty quantification Felix J . Herrmann, Ali Siahk oohi, and Gabrio Rizzuti School of Computational Science and Engineering Georgia Institute of T echnology {felix.herrmann, alisk, rizzuti.gabrio}@gatech.edu Abstract W e outline ne w approaches to incorporate ideas from deep learning into wave-based least-squares imaging. The aim, and main contribution of this w ork, is the combina- tion of handcrafted constraints with deep con v olutional neural networks, as a way to harness their remarkable ease of generating natural images. The mathematical basis underlying our method is the e xpectation-maximization frame work, where data are divided in batches and coupled to additional “latent” unknowns. These unkno wns are pairs of elements from the original unkno wn space (b ut no w coupled to a specific data batch) and network inputs. In this setting, the neural network controls the similarity between these additional parameters, acting as a “center” variable. The resulting problem amounts to a maximum-likelihood estimation of the network parameters when the augmented data model is marginalized ov er the latent variables. 1 The seismic imaging problem In least-squares imaging, we are interested in in v erting the following inconsistent ill-conditioned linear in v erse problem: minimize x 1 2 N X i =1 k y i − A i x k 2 2 . (1) In this e xpression, the unkno wn v ector x represents the image, y i , i = 1 , . . . , N the observed data from N source experiments and A i the discretized linearized forward operator for the i th source experiment. Despite being overdetermined, the abo v e least-squares imaging problem is challenging. The linear systems A i are large, e xpensi v e to e v aluate, and inconsistent because of noise and/or linearization errors. As in many in v erse problems, solutions of problem 1 benefit from adding prior information in the form of penalties or preferentially in the form of constraints, yielding minimize x 1 2 N X i =1 k y i − A i x k 2 2 subject to x ∈ C (2) with C representing a single or multiple (conv ex) constraint set(s). This approach offers the flexibility to include multiple handcrafted constraints. Sev eral key issues remain, namely; (i) we can not afford to w ork with all N experiments when computing gradients for the abov e data-misfit objectiv e; (ii) constrained optimization problems con v erge slowly; (iii) handcrafted priors may not capture complexities of natural images; (iv) it is non-tri vial to obtain uncertainty quantification information. 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), V ancouv er , Canada. 2 Stochastic linearized Bregman T o meet the computational challenges that come with solving problem 2 for non-differentiable structure promoting constraints, such as the ` 1 -norm, we solve problem 2 with Bregman iterations for a batch size of one. The k th iteration reads ˜ x ← ˜ x − t k A > k ( A k x − y k ) x ← P C ( ˜ x ) (3) with A > k the adjoint of A k , where A k ∈ { A i } N i =1 , and P C ( ˜ x ) = argmin x 1 2 k x − ˜ x k 2 2 subject to x ∈ C (4) being the projection onto the (con v e x) set and t k = k A k x − y k k 2 2 / k A > k ( A k x − y k ) k 2 2 the dynamic steplength. Contrary to the Iterative Shrinkage Thresholding Algorithm (IST A), we iterate on the dual variable ˜ x . Moreo ver , to handle more general situations and to ensure we are for every iteration feasible (= in the constraint set) we replace sparsity-promoting thresholding with projections that ensure that each model iterate remains in the constraint set. As reported in W itte et al. [1] , iterations 3 are known to conv erge fast for pairs { y k , A k } that are randomly drawn, with replacement, from iteration to iteration. As such, Equation 3 can be interpreted as stochastic gradient descent on the dual variable. 3 Deep prior with constraints Handcrafted priors, encoded in the constraint set C , in combination with stochastic optimization, where we randomly draw a dif ferent source experiment for each iteration of Equation 3, allow us to create high-fidelity images by only w orking with random subsets of the data. While encouraging, this approach relies on handcrafted priors encoded in the constraint set C . Moti vated by recent successes in machine learning and deep conv olutional networks (CNNs) in particular, we follo w V an V een et al. [2] , Dittmer et al. [3] and W u and McMechan [4] and propose to incorporate CNNs as deep priors on the model. Compared to handcrafted priors, deep priors defined by CNNs are less biased since they only require the model to be in the range of the CNN, which includes natural images and e xcludes images with unnatural noise. In its most basic form, this in volves solving problems of the follo wing type [2]: minimize w 1 2 k y − Ag ( z , w ) k 2 2 . (5) In this expression, g ( z, w ) is a deep CNN parameterized by unknown weights w and z ∼ N(0 , 1) is a fixed random vector in the latent space. In this formulation, we replaced the unknown model by a neural net. This makes this formulation suitable for situations where we do not ha ve access to data-image training pairs but where we are looking for natural images that are in the range of the CNN. In recent work by V an V een et al. [2] , it is shown that solving problem 5 can lead to good estimates for x via the CNN g ( z, b w ) where b w is the minimizer of problem 5 highly suitable for situations where we only hav e access to data. In this approach, the parameterization of the network by w for a fixed z plays the role of a non-linear redundant transform. While using neural nets as strong constraints may offer certain advantages, there are no guarantees that the model iterates remain physically feasible, which is a prerequisite if we want to solv e non-linear imaging problems that include physical parameters [ 5 , 6 ]. Unless we pre-train the network, early iterations while solving problem 5 will be unfeasible. Moreover , as mentioned by V an V een et al. [2] , results from solving inv erse problems with deep priors may benefit from additional types of regularization. W e accomplish this by combining hard handcrafted constraints with a weak constraint for the deep prior resulting in a reformulation of the problem 5 into minimize x ∈C , w 1 2 k y − Ax k 2 2 + λ 2 2 k x − g ( z , w ) k 2 2 . (6) In this expression, the deep prior appears as a penalty term weighted by the trade-of f parameter λ > 0 . In this weak formulation, x is a slack variable, which by virtue of the hard constraint will be feasible throughout the iterations. The abov e formulation offers fle xibility to impose constraints on the model that can be relax ed during the iterations as the network is gradually “trained”. W e can do this by either relaxing the constraint set (eg. by increasing the size of the TV -norm ball) or by increasing the trade-of f parameter λ . 2 4 Learned imaging via expectation maximization So far , we used the neural network to regularize in verse problems deterministically by selecting a single latent v ariable z and optimizing ov er the network weights initialized by white noise. While this approach may remove bias related to handcrafted priors, it does not fully exploit documented capabilities of generative neural nets, which are capable of generating realizations from a learned distribution. Herein lies both an opportunity and a challenge when in verse problems are concerned where the objects of interest are generally not known a priori. Basically , this leaves us with two options. Either we assume to ha ve access to an oracle, which in reality means that we ha ve a training set of images obtained from some (expensi ve) often unkno wn imaging procedure, or we make necessary assumptions on the statistics of real images. In both cases, the learned priors and inferred posteriors will be biased by our (limited) understanding of the in version process, including its regularization, or by our (limited) understanding of statistical properties of the unkno wn e.g. geostatistics [ 7 ]. The latter may lead to perhaps unreasonable simplifications of the geology while the former may suf fer from remnant imprint of the nullspace of the forward operator and/or poor choices for the handcrafted and deep priors. 4.1 T raining phase Contrary to approaches that have appeared in the literature, where the authors assume to have access to a geological oracle [ 7 ] to train a GAN as a prior , we opt to learn the posterior through in version deriving from the abo ve combination of hard handcrafted constraints and weak deep priors with the purpose to train a network to generate realizations from the posterior . Our approach is motiv ated by Han et al. [8] who use the Expectation Maximization (EM) technique to train a generativ e model on sample images. W e propose to do the same but no w for seismic data collected from one and the same Earth model. T o arriv e at this formulation, we consider each of the N source experiments with data y k as separate datasets from which images x k can in principle be in verted. In other words, contrary to problem 1, we make no assumptions that the y k come from one and the same x but rather we consider n N different batches each with their o wn x k . Using the these y k , we solve an unsupervised training problem during which • n minibatches of observed data, latent, and slack variables are paired into tuples { y i , x i , z i } n i =1 with the latent v ariables z i ’ s initialized as zero-centered white Gaussian noise, z i ∼ N (0 , I ) . The slack variables x i ’ s are computed by the numerically e xpensi ve Bregman iterations, which during each iteration work on the randomized source experiment of each minibatch. • latent variables z i ’ s are sampled from p ( z i | x i , w ) by running l iterations of Stochastic Gradient Langevin Dynamics (SGLD, W elling and T eh [9] ) (Equation 7), where w is the current estimate of network weights, and x i ’ s are computed with Bregman iterations (Equation 8). These iterations for the latent v ariables are warm-started while keeping the network weights w fixed. This corresponds to an unsupervised inference step where training pairs { x i , z i } n i =1 are created. Uncertainly in the z i ’ s is accounted for by SGLD iterations [7, 8]. • the network weights are updated using { x i , z i } n i =1 with a supervised learning procedure. During this learning step, the network weights are updated by sample averaging the gradients w .r .t. w for all z i ’ s. As stated by Han et al. [8] , we actually compute a Monte Carlo average from these samples. By following this semi-supervised learning procedure, we expose the generativ e model to uncertainties in the latent variables by drawing samples from the posterior via Langevin dynamics that in volv e the following iterations for the pairs { x i , z i } n i =1 z i ← z i − ε 2 ∇ z λ 2 k x i − g ( z i , w )) k 2 2 + k z i k 2 2 + N (0 , εI ) (7) with ε the steplength. Compared to ordinary gradient descent, 7 contains an additional noise term that under certain conditions allows us to sample from the posterior distribution, p ( z i | x i , w ) . The 3 training samples x i came from the following Bre gman iterations in the outer loop ˜ x i ← ˜ x i − t k A > k ( A k x i − y k ) + λ 2 ( x i − g ( z i , w )) x i ← P C ( ˜ x i ) . (8) After sampling the latent variables, we update the netw ork weights via for the z i ’ s fixed w ← w − η ∇ w n X i =1 k x i − g ( z i , w ) k 2 2 (9) with η steplength for network weights. Conceptually , the abov e training procedure corresponds to carrying out n dif ferent in versions for each data set y i separately . W e train the weights of the network as we con verge to the dif ferent solutions of the Bregman iterations for each dataset. As during Elastic-A veraging Stochastic Gradient Descent [ 10 , Chaudhari et al. [11] ], x i ’ s hav e room to de viate from each other when λ is not too lar ge. Our approach differs in the sense that we replaced the center v ariable by a generativ e network. 5 Example W e numerically conduct a survey where the source experiments contain se vere incoherent noise and coherent linearization errors: e = ( F k ( m + δ m ) − F k ( m ) − ∇ F k ( m ) δ m ) , where A k = ∇ F k is the Jacobian and F k ( m ) is the nonlinear forward operator with m the known smooth background model and δ m the unknown perturbation (image). The signal-to-noise ratio of the observed data is − 11 . 37 dB. The results of this experiment are included in Figure 1 from which we make the following observations. First, as expected the models generated from g ( z , b w ) are smoother than the primal Bregman v ariable. Second, there are clearly variations amongst the different g ( z , b w ) ’ s and these variations a verage out in the mean, which has fe wer imaging artifacts. Because we were able to train the g ( z , w ) as a “byproduct” of the in version, we are able to compute statistical information from the trained generativ e model that may giv e us information about the “uncertainty”. In Figure 2, we included a plot of the pointwise standard deviation , computed with 3200 random realizations of g ( z , w ) , z ∼ p z ( z ) , and two examples of sample “prior” (before training) and “posterior” distribution. As expected, the pointwise standard de viations shows a reasonable sharpening of the probabilities before and after training through in version. W e also argue that the areas of high pointwise standard de viation coincide with regions that are dif ficult to image because of the linearization error and noise. 6 Discussion and Conclusions In this work, we tested an in verse problem framework which includes hard constraints and deep priors. Hard constraints are necessary in many problems, such as seismic imaging, where the unknowns must belong to a feasible set in order to ensure the numerical stability of the forward problem. Deep priors, enforced through adherence to the range of a neural network, pro vide an additional, implicit type of regularization, as demonstrated by recent work [ 2 , Dittmer et al. [3] ], and corroborated by our numerical results. The resulting algorithm can be mathematically interpreted in light of expectation maximization methods. Furthermore, connections to elastic a veraging SGD [10] highlight potential computational benefits of a parallel (synchronous or asynchronous) implementation. On a speculati ve note, we ar gue that the presented method, which combines stochastic optimization on the dual variable with on-the-fly estimation of the generativ e model’ s weights using Langevin dynamics, reaps information on the “posterior” distrib ution lev eraging multiplicity in the data and the fact that the data is acquired ov er one and the same Earth model. Our preliminary resul ts seem consistent with a behavior to be e xpected from a “posterior” distribution. References [1] Philipp A. W itte, Mathias Louboutin, Fabio Luporini, Gerard J. Gorman, and Felix J. Herrmann. Compressiv e least-squares migration with on-the-fly fourier transforms. GEOPHYSICS , 84(5): R655–R672, 2019. doi: 10.1190/geo2018- 0490.1. URL https://doi.org/10.1190/geo2018- 0490. 1 . 4 (a) (b) (c) (d) (e) (f) Figure 1: Imaging according to the proposed method. a) a Bregman primal variable x ∗ i obtained after 350 Bregman iterations. b) the mean of g ( z , b w ) obtained by generating 3200 random realizations of z ∼ p z ( z ) and av eraging the corresponding g ( z , b w ) ’ s. c,d) two examples of generated images from g ( z , b w ) for different z ’ s. e,f) the differences between images in the middle ro w with another realization of the network. (a) (b) (c) Figure 2: Statistics of imaging according to the proposed method. a) the pointwise standard deviation among samples generated by e v aluating g ( z , b w ) ov er 3200 random realizations of g ( z , w ) , z ∼ p z ( z ) . b,c) sample “prior” (before training) and “posterior” distribution functions for two points in the model. 5 [2] Dav e V an V een, Ajil Jalal, Mahdi Soltanolkotabi, Eric Price, Sriram V ishwanath, and Ale xan- dros G. Dimakis. Compressed Sensing with Deep Image Prior and Learned Regularization. arXiv e-prints , art. arXiv:1806.06438, Jun 2018. [3] Sören Dittmer , T obias Kluth, Peter Maass, and Daniel Otero Baguer . Regularization by architecture: A deep prior approach for inv erse problems. arXiv preprint , 2018. [4] Y ulang W u and Geor ge A McMechan. Parametric con volutional neural netw ork-domain full- wa veform in version. Geophysics , 84(6):R893–R908, 2019. [5] Ernie Esser , Lluís Guasch, Tristan v an Leeuwen, Aleksandr Y . Aravkin, and Felix J. Herrmann. T otal-variation re gularization strategies in full-wa veform in version. SIAM Journal on Imaging Sciences , 11(1):376–406, 2018. doi: 10.1137/17M111328X. URL https://slim.gatech.edu/ Publications/Public/Journals/CoRR/2016/esser2016tvr/esser2016tvr .pdf . (SIAM Journal on Imaging Sciences). [6] Bas Peters, Brendan R. Smith yman, and Felix J. Herrmann. Projection methods and applications for seismic nonlinear in verse problems with multiple constraints. Geophysics , 2018. doi: 10. 1190/geo2018- 0192.1. URL https://slim.gatech.edu/Publications/Public/Journals/Geophysics/ 2018/peters2018pmf/peters2018pmf.html . (Published online in Geophysics). [7] Lukas Mosser, Olivier Dubrule, and M Blunt. Stochastic seismic waveform in version using generati ve adversarial networks as a geological prior . In F irst EA GE/PESGB W orkshop Machine Learning , 2018. [8] T ian Han, Y ang Lu, Song-Chun Zhu, and Y ing Nian W u. Alternating back-propagation for generator network. In Thirty-Fir st AAAI Conference on Artificial Intelligence , 2017. [9] Max W elling and Y ee W T eh. Bayesian learning via stochastic gradient langevin dynamics. In Proceedings of the 28th international conference on machine learning (ICML-11) , pages 681–688, 2011. [10] Sixin Zhang, Anna E Choromanska, and Y ann LeCun. Deep learning with elastic av eraging sgd. In Advances in Neural Information Pr ocessing Systems , pages 685–693, 2015. [11] Pratik Chaudhari, Anna Choromanska, Stefano Soatto, Y ann LeCun, Carlo Baldassi, Christian Borgs, Jennifer Chayes, Le vent Sagun, and Riccardo Zecchina. Entropy-sgd: Biasing gradient descent into wide valle ys. arXiv preprint , 2016. 6
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment