Machine Learning for high speed channel optimization
Design of printed circuit board (PCB) stack-up requires the consideration of characteristic impedance, insertion loss and crosstalk. As there are many parameters in a PCB stack-up design, the optimization of these parameters needs to be efficient and…
Authors: Jiayi He, Aravind Sampath Kumar, Arun Chada
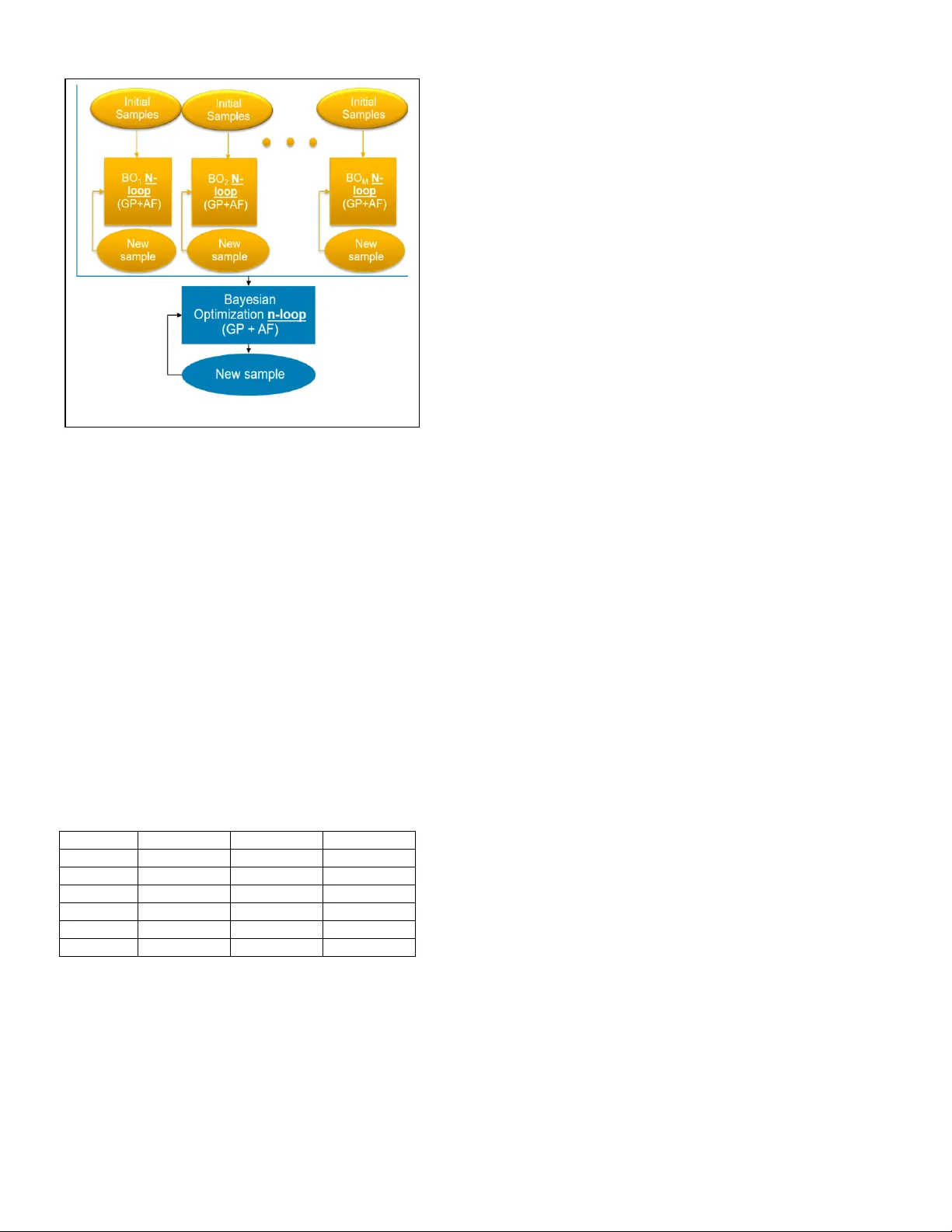
Parallel and Intelligent Ba yesian Optimization for PCB Stack-up Design Jiayi He #1 , Ar avind Samp ath Kumar $2 , Arun Chada *3 , Bhyrav Mutnury *4 , Jame s Drewni ak #5 # EMC Labor atory, D epartm ent of Electri cal and Computer E ngi neering , Mis souri Univ ersit y of Scien ce and Technology, Rolla, M o, USA 1 hejiay@m st.edu, 5 drewni ak@mst .edu * Dell, Enterprise Product Gr oup, One Dell Wa y, MS RR5 -31, Round Rock, Texas, USA 3 arun_chada@dell.com , 4 bhyrav_mutnury@dell.com $ Department of Electrical and Computer E ngineering , No rth Carolina State University, Raleigh, NC , USA 2 asampat2@ ncsu.edu Abstract — Design of printed circuit board (PCB) stack -up requires the consideration of characteristic impedance, insertion loss and crosstalk. As there are many parameters in a PCB stack - up design, the optimization of these parameters needs to be efficient and accurate. A less optimal stack- up would lead to expensive PCB material choices in high speed designs. In this paper, an efficient global optimization method using parallel and intelligent Bayesian optimization is proposed for the stripline design . Keywords — Sta ck - up , stripline, Bayesian optimization I. I NTRODUCTION In high speed s yste m design, opti mizing print ed c ircu it board (P CB) stack-up is play ing a mor e an d mor e import ant role in design stage. Sin ce P CB stack-u p d efinition is one of the first thi ngs to be locked during the design ph ase, a less than optim um PCB stack-up can result in the selecti on of expensiv e lamin ate ma t erials. The cost of a sy stem can be signifi cantly red uced wit h an optimum stack-up d esign. The desi gn of PCB st ack -u p usu ally con siders the tr ansmis sion lin e e lectr ical propert ies, s uch a s imped ance matching, in sertion loss minimiz ation and crosst alk minimiz ation. There are many tools availa ble for de signers to ge t th ese tr ansmis sion line properti es by inputti ng t he stack-up par amet ers. Howe ver, optimi zing th ese para meter s is not e asy as there are many param eters at play. For a differenti al strip line shown in Figure 1 , the inp ut para meters include t he trace widt h ( W), trace spacing (S), trace thicknes s (T), core height (H 1 ), total diel ectric height (H), dielectric c onst ant f or c ore and prepreg (ε r ). D esigner should also consider other paramet ers like loss tang ent, s urfa ce roughne ss and et ching fa ctor to name a few. There are 6-16 parameter s that n eed to be opt imized depe nding on t he engineer’ s req uir ement. Optimiz ation of the stack- up need s runni ng the transmi ssion line solver and brut e-forc e, ful l-factori al search of the design space c an take weeks and month s of simulation time as the number of combinati ons would run into 100s of thousand s. A sma rter met hod is needed to reduce the search space from 100s of thous ands to few hundred s. In thi s p aper, Baye sian o ptimization ( BO) i s us ed to pe rform the global optimiz ation in or der to red uce t he number of o bjective f uncti on evalu ation s . Howe ver, cla ssic BO also has its limit ation in convergen ce speed when the dimension of the objectiv e function or the numb er of observatio ns gets large. In this paper, a parallel and intellig ent BO i s propo sed for the PCB stack -up optimiz ation. The paper is org anized as foll ows: Section II descri bes Bayesian optimizati on. The limitation s of Bayesian optimiz ation are discusse d in Section III. Secti on I V discussed the paral lel intellige nt Bayesian optim ization along with th e simulatio n result s. Sect ion V summari zes the paper. II. B AYES IAN OPTIMIZATION WITH G AUSSIAN P ROCESS Bayes ian Optimization consist of two main components: a Bayesian statistics model for modeling the objective function and an acquisition function for determining which point to sample next. Usually Gauss ian process (GP) regression is used as th e Bayesian statistical model. For G P priors, a joint Gaussian distribution is created with the entire s et of available observation points. T he objective function “ f ” is de fined as a GP pr ior with a mean function “ μ ” and a covariance functi on “ k .” Based on prior observation points, the prior distribution on [ f (x 1 ) , …, f(x N ) ] is: f (x 1: N ) ~ N( μ (x 1: N ), K ) (1 ) where x 1 : N represent the “ N ” observation points, μ( x 1 : N ) is the mean vector at the c orre sponding observation points a nd k is the corresponding covariance matrix: ( 2) Fig. 1 A s ample c ross-s ection of a PCB Where the kernel function k is de fined by: ( 3 ) ( 4) where θ is a hyperparameter for effective length scaling. To infer the value of f ( x ) at the next data point, x N+1 , we can compute the conditional distribution of f( x ) given these observations using Bayes’ theorem. (5) (6) (7 ) ( 8 ) Where K is the cova rianc e matrix and k is the kernel function. T hen the poste rior distribution of any ne w data point is given by the above equations. The next point to be evaluated is chos en by maximizing or minimizing th e acquisition function. There are three widely used acquisition function: probability of improvement (PI), expected improvement (E I) and upper/lower confidence bound (UCB/LCB). T he goal of acquisition function is to find the point that potentially improves the current best or worst value. In this paper, PI is used to minim ize the objective function. T he next sample is given by: (9) Where and are the posterior distribution calculated from (6) and (7), τ is a hyperparameter that determines the ratio of exploration and exploitation. Larger τ leads to more exploration than exploitation. A typical flow chart of BO is shown in Figure 2: 1) Choose N initial samples and evaluate the objective function. 2) Train the GP regressor from the observed points and calculate the pos t erior distribution. 3) Add a new sample ba sed on the acquisition function and evaluate this sample. 4) Repeat step 2 and 3 until th e stopping crit eria is met. In BO process , s ince the acquisition function is only determined by previous observations, a new sample is selected without computing the objective function in advance and only the selected sample point wil l be evaluated. Thus , the number of s amples that are evaluated is minim ized in BO. A s evaluating th e objective function at one sample means r unning th e transmission li ne solver once, the computation time can be significantly reduced by minimizing the number of computation samples. III. C HALL ENGES OF BAYESIAN OPTI MIZATION The main c hall enges of B ayesian optim izat ion are it s feasibility t o s cale to higher dimension s and it s effici ency at large number of obs ervations . When the number of observatio ns gets larger, the size of the covari ance matrix also gets larger, re sulting in a s i gnificant in crease in computati on time . Higher dime nsion al problems force BO to have a larger init ial s ampl ing or runni ng for m ore iteratio ns, both will cau se BO ta ke long er tim e to co nverge. Another challeng e i s the opt imized result m ay be affect ed by the initi al sampl es. Since th e GP po sterior i s determin ed by previ ous observ ations, the in itial ra ndom sample s and its s ize will pl ay a rol e in it. The o ptimized result and the number of iteration needed may vary from run to run. This phenome non is more obvious when the dimension of the prob lem gets larger, as BO force s to have a larger initi al sample size a t high er dimen sions. The c hoi ce of covaria nce fu nction and acqui sition function w ill also influ ence the eff icien cy of BO. There are many differ ent covarian ce function s s uch as the s quared exponenti al fun ction, the Matern functio n, t he rational quadratic fu nction, etc . T he choic e of covarian ce function may a ffe ct the convergen ce speed of BO. In this paper, we used th e Mat ern cov arian ce functi on. In LCB acq uisition function , the hyp erparamet er, τ , repr esent s the fa ctor between explorati on and e xploit ation, so the value of τ needs to be t uned to a chieve t he glob al opt imum with fe wer iteratio ns . IV. P ARALL EL AND INTELLIGENT BAYESI AN OPTIMIZATION To resol ve the challenges in cla ss i c BO, a paralle l and intellig ent Bayesian optimi zation metho d is propo sed. The flow chart of this metho d is shown in Figur e 3 . In first s tep of this algorit hm, mul tiple small BOs are run in para llel with different r andom initia l samples. Each BO follows the procedur e of classical B ayesian optimizati on a s des cribed in Section II I . After “N” iteratio ns, the da t a c ollected by all individu al BO s a re combine d to a bigger data set. Then in second step, another large BO is perform ed on th e combined dataset for “n” more it eratio ns and re ports th e optimiz ed result. In the prop osed metho d, m ultipl e indep endent small BOs a re runnin g parall elly. The size of i nitial samp les is relativ e small, so the computati on s pee d at this step is fast. When the data set gets combined, the calculatio n speed will be slower as the number of o bservati ons gets large, bu t we can limit the number of iterati ons for this BO as previou s steps alr eady give re sults v ery close to t he global opti mum. So the computat ion time challenge at larger datas et gets resolved. Fig. 2. F low cha rt of typical B O This m ethod al so mitiga tes th e effect of random initi al sample s. By running multipl e B Os w ith differ ent init ial sample s and combini ng the data from each BO, the randomn ess in initi al data is unlikely to pl ay a role in this procedur e any l onger . This feature m akes the alg orithm more robu st. Considerin g the fact that the choice of hyperp arameter s will affect the efficien cy of almost every machi ne learning algorithm, it i s accept able that the c ov ariance funct ion and hyperp arameters in the acquisiti on function still play a role in the pr oposed m ethod. Sin ce our method i s more effici ent and not sensitiv e to the randomne ss, tuning the hyperp arameters would b e faster and ea sier. To validat e our proposed PIBO method, it is applie d to a different ial striplin e design probl em. In this preliminary study, the number of parameter s are equal to 6 for simpli city. The parameter s to be optimize d included t he trace width ( W), tra ce spacing (S) , trace thi cknes s (T), core height ( H 1 ) , total h eight ( H 2 ) and th e di ele ctric c onstant (ε r ). The r ange and st ep of ea ch inpu t variable s i s li sted in T able. 1. The t otal number of co mbina tions ar e roughly 10 0K. TABLE I. R ANGE AND STEP OF EACH PARAMETER Parameter Min Max Step W (mil) 3 8 0.25 S (mil) 3 8 0.25 T (mil) 3 5 0.5 H 1 (mil) 8 10 0.5 H 2 (mil) 1.1 1.3 0.1 ε r 3.6 3.8 0.1 The goa l of this o ptimiz ation is to minimiz e th e in sertion loss while the c har acteri stic impeda nce matche s the target impedanc e, whi ch i s 85Ω. The chara cteristi c impe dance and the insertion loss are calcu lated fr om a 2D cross-section al solver. The obje ctive fun ction i s defin ed as: (10) Where Z c and loss are the charact erist ic imped ance and the loss of the tra nsmission line, Z T i s the tar get imp edanc e. The goal i s to mi nimiz e thi s objecti ve f unctio n. The n umber 100 is a factor to adjust the weig ht of the se two terms , which i s tuned by some e xper iments. If the designer aims to maximize th e lo ss whil e mat ching the target impedan ce , t he loss term can be repl aced by the inver se of the loss and the factor n eeds t o be tun ed again a s shown below: (1 1) Using the propose d method, the optimum desig n i s obtained as: 7.25mil s for tra ce width, 7.75mil s for trace spacing, 5mil s for core height , 10mil s for total he i ght, 1.3mils for trace thi ckness a n d 3.6 for diel ectric const ant. The whole optimiz ation proce ss only runs 260 simulation s and th e computatio n time is 15 minute s on a 12 core machine. Ru nning al l 100K si mulati ons on a 200 core server in parall el will take 14 hour s. Compar ed to running all t he com binations , our propos ed met hod is v ery efficient. The e xp eriment is repeat ed mult iple time s a nd th e gl obal optima converges around 250 t o 270 simulati ons using the proposed appro ach V. C ONCLUSION In this paper, a parall el a nd intellig ent Bayesian optimiz ation method is propo sed. B y running BO in parall el, the comput ation time gets reduc ed and the repeatabilit y is improv ed. This m ethod is succes sfully applied to PCB stack-up desig n to minimi ze the loss of transmi ssion lin e and m atch th e targ et imped ance. In the future, this method will be a ppl ied to more complex problem s with higher dim ension an d mor e out puts (li ke crosstal k). An a pproa ch t o find optimu m initi al sample s and hyperp arameters will al so be studied. R EFE R ENCES ( To be added later ) [1] G. Eason, B. Noble, and I . N. Sneddon, “ On certain inte grals of Lipsc hitz- Hankel type involving products of Bessel functions,” Phil. Trans. R oy. Soc. London, vol. A247, pp. 529 – 551, April 1955. (refere nces) [2] J . Clerk Maxwell, A Treatise on Electricity and Ma gnetism, 3rd ed., vol. 2. Oxford: Clarendon, 1892, pp.68 – 73. [3] I . S. Jacobs and C. P. Be an, “Fine particles, thin films and exc hange anisotro py,” in Magnetis m, vol. I II, G. T . Rado and H. Suhl, Eds. New York: Academic, 1963, pp. 271 – 350. [4] K. E lissa, “ Title of paper if known,” unpublished. [5] R. Nicole, “Title of paper with only firs t word capitalized,” J. Name Stand. Abbrev., in press. [6] Y. Yor ozu, M . Hir ano, K. Oka, and Y. Tagawa, “Electron spectrosc opy studies on magneto-optical me di a a nd plas tic substrate interface,” IEEE Transl. J. Ma gn. Japan, vol. 2, pp. 740– 741, A ugust 1987 [Digests 9th Annual C onf. Magnetics Japan, p. 301, 1982 ]. [7] M. Young, The T echnical Writer ’ s Handbook. Mill Valle y, CA: University Science, 1989. Fig. 3. F low cha rt of PIBO
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment