Data Generation for Neural Programming by Example
Programming by example is the problem of synthesizing a program from a small set of input / output pairs. Recent works applying machine learning methods to this task show promise, but are typically reliant on generating synthetic examples for trainin…
Authors: Judith Clymo, Haik Manukian, Nathana"el Fijalkow
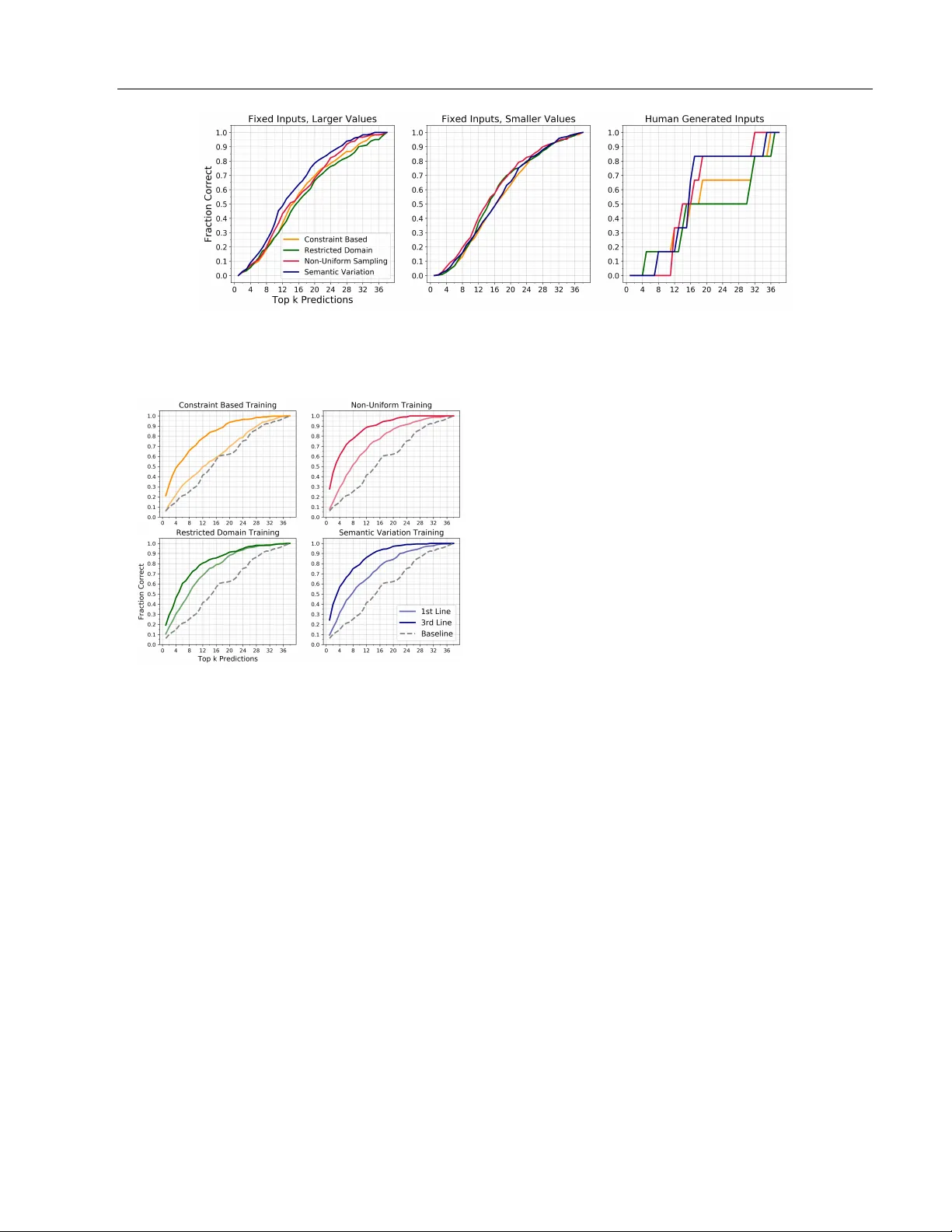
Data Generation for Neural Programming b y Example Judith Clymo ∗ Haik Man ukian ∗ Nathana¨ el Fijalk ow Adri` a Gasc´ on Bro oks P aige Univ ersity of Leeds scjc@leeds.ac.uk Univ ersity of California at San Diego hman ukia@ucsd.edu CNRS, LaBRI Alan T uring Institute nathanael.fijalk ow@labri.fr Go ogle adriagascon@gmail.com UCL Alan T uring Institute bpaige@turing.ac.uk ∗ equal contribution Abstract Pr o gr amming by example is the problem of syn thesizing a program from a small set of input / output pairs. Recen t works applying mac hine learning metho ds to this task show promise, but are t ypically reliant on generat- ing syn thetic examples for training. A par- ticular challenge lies in generating meaning- ful sets of inputs and outputs, whic h well- c haracterize a giv en program and accurately demonstrate its behavior. Where examples used for testing are generated by the same metho d as training data then the p erfor- mance of a model may b e partly reliant on this similarity . In this pap er we in tro duce a no vel approac h using an SMT solver to syn- thesize inputs which cov er a diverse set of b eha viors for a giv en program. W e carry out a case study comparing this method to exist- ing synthetic data generation procedures in the literature, and find that data generated using our approac h improv es b oth the dis- criminatory p ow er of example sets and the abilit y of trained mac hine learning models to generalize to unfamiliar data. 1 In tro duction The machine learning comm unit y has b ecome increas- ingly interested in tac kling the problem of program- ming b y example (PBE), where the goal is to find a short computer program which is consistent with a set of input and output (I/O) pairs. Methods ha ve b een dev elop ed that use neural netw orks either to gener- ate source co de directly (Devlin et al., 2017; Parisotto T ec hnical rep ort. et al., 2016; Bunel et al., 2018) or to aid existing searc h algorithms (Balog et al., 2017). These pap ers re- p ort impressiv e empirical performance. How ever, deep learning metho ds are data-hungry , and programming b y example is not a data-ric h regime. Man y neural program synthesis methods are developed targeting domain-sp ecific languages (DSLs), suc h as the FlashFill en vironment (Gulwani et al., 2012; De- vlin et al., 2017), a custom list pro cessing language (Balog et al., 2017; F eng et al., 2018), or the Karel the Rob ot environmen t (Bunel et al., 2018). These lan- guages do not hav e a large b o dy of human-generated co de, nor do they hav e canonical examples of I/O pairs whic h corresp ond to usage in a real-w orld scenario. As a result, neural program synthesis has turned to gen- erating synthetic data, typically b y sampling random programs from some predefined distribution, sampling random inputs, and then ev aluating the programs on these inputs to obtain I/O pairs. The syn thetic data is t ypically used as both the train- ing set for fitting the mo del, and the testing set for ev aluating the mo del, which is problematic if there is a mismatch b etw een these random examples and p oten tial real-world usage. In the absence of any ground truth this problem of ov er-fitting is often ig- nored. In addition, I/O pairs pro duced by random generation may not be examples that particularly w ell- c haracterise a given program. This can affect exp eri- men tal results through pr o gr am aliasing , where man y differen t possible programs are consisten t with the I/O examples (Bunel et al., 2018). Nearly all existing approaches are based on an implicit assumption that programs and I/O examples used for training should b e c hosen in a wa y that is as uniform as p ossible o ver the space, despite the fact that man y I/O examples are uninformativ e or redundan t, as is well kno wn in the automated soft ware testing comm unity (see e.g. Go defroid et al. (2005)). Con tributions. In this pap er we consider ho w to generate sets of I/O examples for training a neural T ec hnical rep ort PBE system. In particular we are concerned with the generalizabilit y of neural netw orks trained for PBE on syn thetic data. W e present four approaches to data generation in this con text, including a no vel constrain t based method. W e sho w how these different metho ds can b e applied in a case study of the DeepCoder DSL from Balog et al. (2017), an expressiv e language for manipulating lists of integers. The DeepCoder DSL has sev eral features that mak e it an in teresting and c hallenging setting for generating synthetic training data: it is capable of displa ying complex b ehavior in- cluding branching and lo oping; the set of v alid inputs for a given program can b e difficult to define and/or restricted; and the most informative examples are dis- tributed unevenly throughout the space. W e train neu- ral net works designed for program generation and as- sisting a program search using examples pro duced by the four outlined methods, then use cross-comparison to quantify the robustness of these netw orks. W e also ev aluate the degree to which different synthetic data sets uniquely c haracterise a program, imp ortant for addressing the program aliasing problem. 2 Related w ork Most approaches to generating I/O examples are based on random sampling schemes, with either a rejection step or initial constrain ts. Balog et al. (2017) construct a database of programs in the DeepCo der DSL by en umerating programs up to a fixed length and pruning those with obvious problems suc h as unused in termediate v alues. They pro duce I/O examples for each program by restricting the domain of inputs to a small, program-dependent subset which is guaran teed to yield v alid outputs and then sampling uniformly from this set. F eng et al. (2018) targets the same DSL but example pairs are generated by sam- pling random inputs and seeing whether they ev aluate to a v alid output. If a sufficien t num b er of v alid pairs are not found within a fixed amount of time, the pro- gram is discarded. The pap er do es not state what distribution is used to sample inputs. In both of these pap ers, this syn thetic data is used for both training the mo del and for ev aluating its p erformance. Bunel et al. (2018) considers the Karel the Robot do- main, and creates a dataset of programs by random sampling from the production rules of the DSL, prun- ing out programs whic h represent the identit y func- tion or contain trivial redundancies. I/O examples are constructed by sampling and ev aluating random input grids. No men tion is made of what sampling distri- bution is used for either the programs or the input grids; the syn thetic data is used for b oth training and testing. P arisotto et al. (2016) generates synthetic data for the FlashFill domain (Gulwani et al., 2012) by sampling random programs up to a maxim um of 13 expressions. The reported performance suggest a v ery large gap be- t ween the syn thetic examples (97% accuracy) and the real-w orld data (38% accuracy). Devlin et al. (2017) is more cautious: p erformance is ev aluated only on the real-w orld examples, with synthetic data used only for training. The training data is produced b y sim ulat- ing random programs up to a maximum of 10 expres- sions, and then constructing I/O pairs by sampling random inputs and testing to see whether executing the program raises an exception. Neither paper ex- plicitly sp ecifies any of the sampling distributions. The pap ers ab ov e all primarily fo cus on adv ancing searc h algorithms or impro ving heuristics, with little atten tion to data generation; the only exception w e are a ware of is Shin et al. (2019), whic h specifically pro- p oses a metho d for improving syn thetic example gen- eration. Their approach requires first defining a set of “salien t v ariables” for the domain: these tak e the form of a mapping from a syn thetic training example to a discrete v alue. They then define a sampling strategy for examples whic h aims to maximize their entrop y , b y generating a training dataset which is o verall approx- imately uniform ov er all the combinations of the dif- feren t discrete salien t v ariables. Particular atten tion is paid to the Karel the Rob ot domain, and the gen- eration of synthetic data for the algorithms in Bunel et al. (2018). When there are man y salient v ariables the discrete do- main can be large. Ho wev er, the n umber of I/O exam- ples needed for eac h program is typically quite small. In the Karel the Robot domain the input space is not constrained by the programs so it is natural to enforce uniformit y across salien t v ariables ov er the whole set of inputs. Where the program can significan tly affect the v alid input space the approac h is not appropriate. The con tributions w e mak e to this task are comple- men tary to those of Shin et al. (2019), which in this domain could still b e b eneficially applied in selecting a set of synthetic programs, but would b e difficult to adapt to generating meaningful inputs. 3 ML-aided Programming b y Example Figure 1 outlines the general approach to programming b y example we tak e in this pap er, providing a frame- w ork which can b e used to understand metho ds and settings employ ed in recent work. The problem is de- fined in terms of a concrete DSL that takes as input a set of examples ( x 1 , y 1 ) , . . . , ( x k , y k ), and syn thesizes a program mapping inputs x i to the corresp onding out- T ec hnical rep ort Learning Model M Examples ( x 1 , y 1 ) , . . . , ( x k , y k ) Synthetic T raining Dataset DSL-specific Da t a Genera tion G Prioritised Search T ree Ranking heuristic Figure 1: ML-aided programming by example puts y i . At the core of the approach is a search algo- rithm that explores the space of all programs up to a certain predefined length according to a ranking func- tion. This heuristic ranking function is deriv ed from the output of an ML mo del M that insp ects the input ( x 1 , y 1 ) , . . . , ( x k , y k ). Crucial in this approach is the training dataset of M . This dataset is obtained using a DSL-sp ecific generation pro cedure G that generates (a) programs and (b) a small set of inputs for those programs. Hence, to instan tiate a concrete approach to ML-aided programming by example one needs to define (i) the DSL, (ii) the data generation pro cedure G , and (iii) the ML model M and corresp onding search pro cedure. As mentioned ab ov e, previous work focuses primarily on (iii). Here w e instead focus on (ii), the training data generation step, and in vestigate its effect in concrete instances of the complete pip eline. 3.1 Domain sp ecific language The DeepCoder DSL (Balog et al., 2017), which we will use as our running example, consists of high-level functions manipulating list of in tegers; a program is a sequence of functions which tak e as input any of the inputs or previously computed v alues. The DSL con tains the first-order functions Head , Last , T ake , Drop , Access , Minimum , Maximum , Reverse , Sor t , Sum , and the higher-order functions Map , Fil- ter , Count , ZipWith , Scanl1 . The higher-order function Map can be com bined with (+1) , (-1) , (*2) , (/2) , (*(-1)) , (**2) , (*3) , (/3) , (*4) , (/4) . The t wo higher-order functions Fil ter and Count use predicates (>0) , (<0) , (%2==0) , (%2==1) . Finally , ZipWith and Scanl1 are paired with (+) , (-) , (*) , Min , Max . The lists in a program are of a predefined length (20 in the exp eriments of Balog et al. (2017)) with v alues in [ − 255 , 256] ∪ {⊥} , with ⊥ denoting an undefine d v alue. The seman tics of the DSL assume some form of b ound chec king, as indexing a list out of its b ounds returns ⊥ , and ov er(under)-flow c hecking, as v alues outside of the range [ − 255 , 256] ev aluate to ⊥ . As we will see, this impacts data generation b y constraining the domain of v alid inputs. This DSL is remark ably expressive: it can express non-linear func- tions via rep eated integer m ultiplication, control flow (if-then-else statements can b e enco ded by means of Fil ter ), and lo ops o ver lists (b y means of the higher- order functions). Moreo ver, the higher-order functions lik e Reverse , Sor t , ZipWith and Scanl1 allow to enco de surprisingly complex pro cedures in just a few lines, suc h as the four-line example sho wn in Figure 2. 4 Data Generation Methods W e propose three new approaches for the data genera- tion step. The first is based on a probabilistic sampling of the input space, while the other tw o treat data gen- eration as a constrain t satisfaction problem. W e de- v elop a general framework for this approach and show ho w additional constraints can be used to imp ose v ari- ation in the I/O pairs pro duced. 4.1 Sampling-based approac hes W e use the approach from Balog et al. (2017) as a baseline. Programs are ev aluated in reverse to derive a ‘safe’ range for input v alues that is guaranteed to pro duce outputs in a target range. V alues are then sampled uniformly from the safe input range to create the input(s), and the output is calculated b y ev aluat- ing the program. If the safe range for some input is empt y or a singleton, then the program is discarded. In rep orting results of our exp erimen ts, w e refer to this metho d of data generation as “Restricted Domain”. The purpose of the rev erse propagation of b ounds is to exclude all non-v alid inputs from the sampling. How- ev er, some v alid inputs are also excluded. Instead, inputs can b e sampled from an o ver-appro ximation of the set of v alid inputs or b y using a probability distri- bution that prioritises parts of the input space where v alid inputs are kno wn to be common. Inputs are then rejected if they are unsuitable for the program b eing considered. W e observe that in the DeepCoder DSL, when the out- put range is b ounded, small input v alues are compat- ible with more programs than large v alues. Sampling with a bias tow ards small v alues means that suitable inputs are found with high probability for all programs within a fixed n umber of attempts n . If suitable in- puts for a program remain common outside of the safe range iden tified by back propagation of b ounds then the gain from allowing these to b e included could be significan t. T o pro duce a sample, we first fix a random length of the input (uniformly at random) and generate a v alue r from an exp onential distribution i.e. with probabil- T ec hnical rep ort a ← [int] b ← Sor t a c ← Fil ter (>0) b d ← Head c e ← Drop d b An input-output example: Input : [-17, -3, 3, 11, 0, -5, -9, 13, 6, 6, -8, 11] Output : [-5, -3, 0, 3, 6, 6, 11, 11, 13] Figure 2: An example program in the DSL that tak es a single integer arra y as its input. Program P ( X, Y ) Logic L φ ( X, Y ) = encode L ( P ) ψ i ( X, Y ) = SynCons L ( P, { x i , y i } i ) ρ i ( X, Y ) = SemCons L ( P, { x i , y i } i ) L - Sol ver Constraint Controller V i ψ i ∧ ρ i ∧ φ ( X 7→ x i , Y 7→ y i ) Figure 3: Our constraint-solving based approac hes are instances of the ab o ve mo del. A constraint controller adaptiv ely pro duces problems for the solv er, whose so- lutions corresp ond to new input-output pairs to b e added to the training dataset it y P ( r ) ∼ Exp( r, λ ) = λe − λr . The input v alues are selected uniformly at random (with replacemen t) from the range [ − r , r ], then ev aluated on the program. If the output of the program is within the desired range the pair is accepted, otherwise a new v alue of r is sam- pled and the process rep eated. V arying the choice of λ modifies the strength of the bias, affecting both the num b er of attempts that must b e allow ed and also the similarity of examples gener- ated. In our case, we chose λ = 0 . 001 and n = 500. This method will b e referred to as “Non-Uniform Sam- pling” in the experiments section. 4.2 Constrain t-solving based approaches Sampling metho ds are not w ell suited to navigating v alid input space s that are sparse or irregular, and in a language capable of displa ying complex b ehavior the most informativ e examples ma y also be rare. A constrain t solver is able to find suitable inputs in parts of the input space that are almost alwa ys excluded in the sampling metho ds. In this section we present a metho dology to syn thesize a set of examples that relies on constraint solving. The general pro cedure is presented in Figure 3 and consists of a feedback lo op b etw een a constraint con- troller and a solver. The former adaptiv ely pro duces problems for the solver, whose solutions correspond to new I/O pairs to b e added to the training dataset. The approach is parametrised by a c hoice of a logic L , and assumes a solver, denoted L -Solver, that can decide L , i.e. find v alues for the v ariables in any for- m ula φ from L for φ to ev aluate to true, or rep ort “unsatisfiable” if such v alues don’t exist. W e require enco ding and deco ding pro cedures encode L , decode L suc h that encode L tak es a program P with input v ari- ables X and output v ariables Y , and pro duces a for- m ula whose satisfying assignments can b e translated b y decode into concrete input-output pairs of the pro- gram P . F or simplicity , we assume that the domain of the v ariables in φ L and P is the same in Figure 3 and omit the deco ding step. The simplest data syn thesis pro cedure consists of the con troller simply calling the solver iteratively to collect a sequence of input output pairs ( x 1 , y 1 ) , . . . , ( x n , y n ) for P . Note that for DSLs lik e the one presented ab ov e, a complete decision procedure migh t be to o muc h to ask, but for our purp oses soundness is sufficient. More concretely , encode L should b e constructed so that, for eac h program P in the DSL the follo wing holds: ∀ X Y : encode L ( P ) ⇒ P ( X ) = Y This pro cedure, as describ ed so far, is not very help- ful, as nothing preven ts the solv er from returning the same pair ( x, y ) at ev ery iteration. This can be easily a voided by the controller imp osing the additional con- strain t X 6 = x i ∨ Y 6 = y i after ev ery iteration. This is the most basic form of additional constrain t that w e consider. More generally , our approach considers t wo additional sets of constraints, which w e call syntac- tic c onstr aints , denoted SynCons L and semantic c on- str aints , denoted SemCons L . While b oth of this con- strain ts are conditions on I/O pairs – either for each line of the program or the whole program – the former consist of simple equality and inequality chec ks suc h as “input and output should be differen t”. In con trast, seman tic constraints are more pow erful – and costly to enforce – as they enforce predicates on input output pairs such as “the maximum v alue of the input should b e smaller than the maximum v alue of the output”. The next t wo concrete approaches to data generation are instances of the ab ov e scheme, and th us correspond to concrete c hoices for L , encode , decode , SynCons L , T echnical rep ort T able 1: Constraints and predicates used in Syn tac- tic and Semantic constraints used in our constraint- based input generation algorithms. Constraints and predicates are depicted as conditions on the I/O pairs ( x 1 , y 1 ) , . . . , ( x 5 , y 5 ) generated b y the constrain t-based approac hes. F or programs taking more than one input all constraints are applied to each of the inputs. x l i is the intermediate program output of line l given input x i . SynCons L for “Constrain t Based” and “Seman tic V ariation” c 1 := ∀ i : x i 6 = y i Output do es not match input. c 2 := ∀ i : x i 6 = [ ] All inputs ar e not empty. c 3 := ∀ i 6 = j : x i 6 = x j No duplic ate inputs in a set. c 4 := ∀ i 6 = j : y i 6 = y j No duplic ate outputs in a set. c 5 := ∀ i : | x i | > B Input length lar ger than r andom b ound B . Predicates in SemCons L for “Seman tic V ariation” p 1 := max( y i ) > max( y i − 1 ) Incr e ase maximum. p 2 := min( y i ) < min( y i − 1 ) De cr e ase minimum. p 3 := | x i | > C Input length larger than C . p l, 4 := head ( x l i ) 6 = head ( y l − 1 i ) Change in head. p l, 5 := last ( x l i ) 6 = last ( y l − 1 i ) Change in last. p l, 6 := | x l i | 6 = | y l − 1 i | Change in length. p l, 7 := max ( x l i ) 6 = max ( y l − 1 i ) Change in maximum. p l, 8 := min ( x l i ) 6 = min ( y l − 1 i ) Change in minimum. and SemCons L , and the corresponding v ariations in the b eha vior of the constrain t con troller. In our implemen- tation we use Z3 (de Moura and Bjørner, 2008) as a bac k-end solver. Z3 implemen ts incremental solving, whic h allows to push and p op constraints in to an ex- isting formula while preserving intermediate states, a crucial aspect of the implementation of a con troller. As per L , w e exp erimen ted with the theory of non- linear arithmetic, for which Z3 implements incomplete pro cedures, and the theory of bitvectors. 4.2.1 Simple constrain t solving Our third data generation method uses a constrain t solv er to pro duce v alid examples with only minimal ex- tra guidance. Hence, in this case SemCons L ( P , S ) = ∅ . SynCons L are given in T able 1 by means of a list of con- strain ts c 1 , . . . , c 5 . At the i th iteration the pair ( x i , y i ) is obtained from the solv er as a satisfying assignmen t of the constraints V i ψ i ∧ φ (as shown in Figure 3), where ψ i = V 5 i =1 c i . This guarantees that syn thesized examples will satisfy these conditions if possible. 4.2.2 Constrain t solving to generate v aried examples Our fourth metho d is inspired b y program verifica- tion approaches such as predicate abstraction and Coun terExample-Guided Abstraction Refinemen t loop (CEGAR) (Clarke et al., 2003). This method uses con- strain ts more aggressively , and in particular semantic constrain ts, by implemen ting an adaptive constrain t con troller. The syntactic constrain ts used in this case are as in the previous metho d, so we fo cus on de- scribing the semantic constraints, and the adaptive b eha viour of the controller. The con troller first uses sampling to generate a small set of examples, and then keeps trac k of the ev aluation of predicates p 1 , . . . , p 3 for the output of the program and p 4 , . . . , p 8 , for every line of the pr o gr am (see T a- ble 1) for eac h of the inputs found so far. F or example, for 5-line programs this corresp onds to storing a 5 × 5 Bo olean matrix M k for each input x k so far. The con- troller also main tains a record of constraint com bina- tions that result in unsatisfiable problems so these can b e av oided in subsequen t calls. The high-lev el idea is as follows: firstly , by monitoring any bunc hing of in previous examples the con troller can recognise pro- grams with v alid examples tending to bunch in one part of the I/O space (in this DSL, bunching is alwa ys to wards zero, so monitoring maxim um and minimum is a goo d pro xy) and force the constraint solv er to seek out examples in parts of the space where v alid exam- ples are relativ ely rare; secondly b y monitoring which of the predefined behaviours p 4 , . . . , p 8 are satisfied for eac h program line, by each of the inputs x i collected so far, the controller can detect sets inputs that do not sufficiently exercise internal lines of the program, and hence send a w eak signal regarding the presence of the function at that line to the output. Besides recording which behaviors are exhibited by each line, the controller can imp ose a given b ehavior b y assert- ing a sp ecific predicate (or its negation) as part of the seman tic constrain ts for that iteration. More sp ecifi- cally , the con troller defines the semantic constrain t of iteration i as SemCons L ( X, Y ) := ( ∀ k < i : ∃ n, m : ( p n,m ( X, Y ) 6 = M k n,m )), where p n,m is a Boolean for- m ula enco ding that the n th line of the program sat- isfies the m th predicate on input X . This constrain t enforces that in any v alid assignment X 7→ x i , Y 7→ y i obtained by the solver, input x i will induce a b ehav- ior that differs with eac h com bination of behaviors in- duced by inputs found so far in at least one line of the program. This makes the intuitiv e goal of finding “a v aried set of inputs” precise. Cho osing predicates. The choice of features to monitor is sp ecific to the DSL and based on abstrac- tions of the actions of its constituen t functions. In this DSL we are working with lists of in tegers defined by their length, the set of v alues contained, and the order in which those v alues app ear. The functions of the DSL can change all of these features. Our aim is that if the program is capable of changing the v alues that T echnical rep ort Figure 4: Histograms of the input v alues found in training sets generated with the four data generation metho ds considered. Note the large v ariation in y- axes. app ear in the output compared to the input then there should b e an I/O example that demonstrates this, if it is capable of reordering the elements this should also b e shown, and so on. The maximum, minimum, first, and last elemen ts of a list act as simplified indicators for changes in the v alues and order of the list and are the same features used in F eng et al. (2018) to assist the search procedure for this DSL. W e hav e referred to this data generation method as “Seman tic V ariation” in the exp eriments. 5 Exp erimen ts W e consider t wo c hoices of ranking heuristics; one ex- actly following Balog et al. (2017), and the other a nat- ural extension based on recurren t neural net works, fol- lo wing a sequential generation paradigm (Devlin et al., 2017; Bunel et al., 2018). The four synthetic data generation metho ds discussed ab o ve are compared in eac h of these settings. In par- ticular, we inv estigate how neural netw orks trained with data from one method p erform at test time on data generated by another. F or a fair comparison of the data generation metho ds, we use the same split of programs in to training and testing examples. Fig- ure 4 shows how input v alues are distributed in data generated by eac h metho d. The DeepCo der heuristic. The ranking function used in Balog et al. (2017) estimates, for each of the 38 functions in the DSL, the conditional probability that the function ever app ears in the program. The Figure 5: Each netw ork predicts the functions in a giv en test set program. W e rep ort the fraction of pro- grams for whic h all constituent functions are contained in the top- k predictions. The net works are trained on one mo de of generation and tested on all the others. Eac h line represen ts the performance of a training set, defined in the legend. F rom the p erformance gaps, w e see that the netw ork trained on Semantic V ariation data app ears more robust to a change in test data generation metho d. predicted probabilities provide a ranking for a depth- first search. The recurren t neural netw ork heuristic. In ad- dition, we consider an extension to DeepCo der which is lo osely inspired by the recurren t neural netw ork ar- c hitectures used for program generation in other DSLs (Devlin et al., 2017; Bunel et al., 2018). Instead of training the netw ork to output a single set of prob- abilities, we train a net work to output a sequence of probabilities, conditioned on the current line of the program. W e do this by mo deling the sequence of lines with a long short-term memory (LSTM) netw ork (Ho chreiter and Schmidh ub er, 1997). T o ease comparison, we leav e the ma jorit y of the netw ork architecture unc hanged; the only modification is the penultimate la yer is re- placed by an LSTM. The result is a netw ork which tak es as arguments not just the I/O examples, but also a target “num b er of lines”, and then returns estimates of probabilities that a function occurs on a per-line ba- sis, rather than program-wide. Complete arc hitectural details for b oth net works are in the app endix. T echnical rep ort T able 2: T otal area under top- k curves, across all ap- proac hes to test data generation. Metho d T otal A UC Seman tic V ariation 126.11 Non-uniform Sampling 123.14 Constrain t Based 118.24 Restricted Domain 114.21 T able 3: Errors due to program aliasing. Err or cor- resp onds to programs which are correct on the test data, but differ from the original generating program; the predicted programs tend to b e shorter , and often strictly c ontaine d within the target program. Method % Error % Shorter % Con tained Semantic V ariation 4 2 2 Constraint Based 6 4 3 Non-uniform Sampling 6 5 4 Restricted Domain 15 12 9 5.1 Cross-generalization of differen t metho ds The plots in Figure 5 sho w the prop ortion of programs for which ev ery line is included within the top k pre- dictions giv en b y a neural net work. If functions ac- tually presen t in the program are ranked highly b y the netw ork, this will accelerate the runtime of an y corresp onding guided search. The baseline is given b y a fixed ordering reflecting the relative frequency of eac h function in the set of programs used for train- ing. All netw orks p erformed b etter than the base- line on all test sets, showing that the netw ork is able to generalise beyond its training setting. T est data is alwa ys most accurately interpreted b y the net work trained on data generated through the same process; in fact, the four netw orks p erformed almost iden tically to each other when tested on their own data. How- ev er, the abilit y of each net work to transfer to foreign data, from a differen t generation pro cess, v aried sig- nifican tly . The t wo sampling metho ds (Restricted Do- main, Non-Uniform Sampling) in particular found the data generated by an SMT solver difficult, while the loss from the constraint-based metho ds to the sam- pling data was smaller, though still mark ed. The sum of the area under the curv es indicates the robustness of the netw orks, with the Semantic V aria- tion metho d having the largest area; v alues shown in T able 2. 5.2 Program A liasing W e measure ho w w ell the generated example sets char- acterise their target program by taking a sample of programs and I/O sets generated b y each method, and searc hing for programs no longer than the intended program which matc hed the given examples. If an alternativ e program of the same length w as recorded across all test sets then this could b e due to logical equiv alence, and these examples were excluded. The Restricted Domain metho d had the highest rate of ambiguous example sets with 15% of the sets tested able to b e satisfied b y an alternative (not equiv alent) program, compared to a 4% error rate on examples generated by the Semantic V ariation method. Some errors w ere very subtle, confusing programs that were logically different only on inputs with a sp ecific form. Others were due to difficulty distinguishing the func- tions that output in tegers: in a set of only fiv e ex- amples it is relatively common that the maximum of ev ery list is also at the same p osition, for example. The results are summarised in T able 3 whic h shows the percentage of example sets where an alternative program was found and also indicates whether this alternativ e program w as strictly shorter and strictly con tained within the target program (i.e. the target program included some function had no discernible ef- fect for any of the pro vided inputs). 5.3 P erformance on Indep endent T est Sets W e sough t to test the four net works on data that is not generated by a machine and created a small hand- crafted test set of examples on programs of length tw o to five. The p erformance of the neural netw orks is sho wn in Figure 6, in the right-most plot. The test set is clearly to o small to dra w any serious conclusions, but the go o d performance of constrain t based approaches is encouraging. As an alternative to this, we fixed five inputs and ran a set of programs on these same five inputs, keep- ing those for whic h the resulting example set could not b e satisfied by another program of the same or smaller length. Because some functions require mainly small v alues in the inputs we made one test set by this metho d whic h had almost all input v alues b et ween − 10 and 10, and a second set with many more large v alues. This approach ensures the inputs alone are relatively uninformativ e, forcing the netw orks to derive their pre- dictions from the relationship b etw een the inputs and outputs. The results of this exp erimen t are also sho wn in Figure 6 (left and centre), again giving the prop or- tion of example sets for which the whole program was con tained in the top k predictions. The netw orks all p erformed better than random, sho w- ing their predictions are not purely relian t on learning something ab out how the examples are generated. W e also observ e a difference in p erformance dep ending on whether the examples con tain mostly small or mostly T echnical rep ort Figure 6: The fraction of programs contained in the top-k predictions of trained net works on hand-crafted examples. Left and middle figures show p erformance on problems sets with fixed inputs with large and small a verage v alues respectively . Right figure sho ws p erformance on a small set of human generated examples. Figure 7: First and last line predictive accuracy of the recurren t arc hitecture on our test set with fixed inputs. large v alues. Separately , we ev aluate the p erformance of the recur- ren t neural net work arc hitecture, detailed in the ap- p endix, ov er this difficult set of examples. The same RNN mo del was trained o ver sets generated with the four different metho ds, as for the feed-forward net- w orks. W e plot the fraction of times the RNN w as correct ab out the line app earing in the top- k predic- tions for that line in Figure 7. W e see that the last line is easier to predict than the first, for all data gen- eration metho ds, matc hing the intuition that as more functions are applied to the data, more information is lost ab out lines that o ccurred earlier in the program. Ov erall, when compared to baseline, some sets strug- gle more than others, but muc h like the feed-forward case, there is no strategy that has a commanding edge o ver the others. Ho wev er, in longer programs than considered in this pap er, we imagine that the RNN architecture could more substantially assist a search than the feed- forw ard net works. The netw ork considered here pro- vides an ordering for all lines at the start of the searc h. A more adv anced approac h could up date its prediction for the next line given the evolving state of a partial program; we lea ve this to future w ork as it requires careful consideration of run time costs: Rep eated re- ev aluation of an RNN inside the inner lo op of the searc h algorithm could be inefficien t relativ e to sim- ply running more iterations with a cheaper heuristic, whereas the p er-line ranking used here has identical searc h-time cost as the DeepCo der heuristic. 6 Discussion All the metho ds of generating data that we ha ve con- sidered w ere useful in training the neural netw ork, and eac h of the four trained net works display ed the ability to generalise to unfamiliar testing data. Conv ersely , all net works display ed a preference for testing sets gen- erated in the same wa y as the data used for train- ing, demonstrating ov er-fitting to the data generation metho d to some degree. Constrain t solving prov ed an effective w ay of discov er- ing examples that w ere out of reac h to sampling meth- o ds, and simple lo cal features were useful in creating example sets that c haracterise the target program w ell and reduce the o ccurrence of ambiguous examples. W e also sa w that the more informative training data in the Seman tic V ariation method increased the resilience of the neural netw ork against unfamiliar test scenarios. Ac kno wledgments W ork started when J. C and H.M were at the The Alan T uring Institute for the Summer 2018 In ternship Pro- gramme, N. F and A. G. were at the The Alan T uring In- stitute and W arwic k Universit y , and B. P at the The Alan T uring Institute and UCL. All were supp orted by The Alan T uring Institute under the EPSRC grant EP/N510129/1, T echnical rep ort and the UK Gov ernment’s Defence & Security Programme in supp ort of the Alan T uring Institute. References Balog, M., Gaunt, A. L., Brocksc hmidt, M., Now ozin, S., and T arlo w, D. (2017). Deepco der: Learning to write programs. In International Confer enc e on L e arning R epr esentations . Bunel, R., Hausknech t, M. J., Devlin, J., Singh, R., and Kohli, P . (2018). Leveraging grammar and re- inforcemen t learning for neural program synthesis. CoRR , abs/1805.04276. Clark e, E. M., Grumberg, O., Jha, S., Lu, Y., and V eith, H. (2003). Counterexample-guided abstrac- tion refinement for symbolic model chec king. Jour- nal of the ACM , 50(5):752–794. de Moura, L. M. and Bjørner, N. (2008). Z3: an efficien t SMT solv er. In International Confer enc e on T o ols and A lgorithms for the Construction and A nalysis of Systems , v olume 4963 of L e ctur e Notes in Computer Scienc e , pages 337–340. Springer. Devlin, J., Uesato, J., Bh upatira ju, S., Singh, R., Mo- hamed, A., and Kohli, P . (2017). Robustfill: Neural program learning under noisy i/o. In International Confer enc e on Machine L e arning , pages 990–998. F eng, Y., Martins, R., Bastani, O., and Dillig, I. (2018). Program synthesis using conflict-driven learning. In Confer enc e on Pr o gr amming L anguage Design and Implementation , pages 420–435. Go defroid, P ., Klarlund, N., and Sen, K. (2005). Dart: directed automated random testing. In ACM Sig- plan Notic es , v olume 40, pages 213–223. ACM. Gulw ani, S., Harris, W. R., and Singh, R. (2012). Spreadsheet data manipulation using examples. Communic ations of the ACM , 55(8):97–105. Ho c hreiter, S. and Schmidh ub er, J. (1997). Long short-term memory . Neur al c omputation , 9(8):1735– 1780. P arisotto, E., Mohamed, A., Singh, R., Li, L., Zhou, D., and Kohli, P . (2016). Neuro-symbolic program syn thesis. In International Confer enc e on L e arning R epr esentations . Shin, R., Kan t, N., Gupta, K., Bender, C., T rabucco, B., Singh, R., and Song, D. (2019). Syn thetic datasets for neural program syn thesis. In Interna- tional Confer enc e on L e arning R epr esentations . T echnical rep ort Figure 8: Here we v ary the total num b er of unique programs in training sets and compare the resulting net work p erformance on a fixed, seman tically disjoin t, test set. All sets were generated on length ` = 3 pro- grams with the non-uniform sampling metho d. A App endix Sp ecifics of neural net work architectures considered The original DeepCo der netw ork, summarized in de- tail in the supplemental material of (Balog et al., 2017), takes as input 5 I/O pairs, padded to a fixed length. Eac h integer in the netw ork inputs is sent through a trainable em b edding la yer, represen ted as 20-dimensional real-v alued vectors; these embeddings are then concatenated together and passed through three fully-connected lay ers of size 256. This yields 5 representations, one for eac h of the input/output pairs input into the net work; these are then a veraged, and passed as input into a final sigmoidal activ ation la yer, which outputs the predicted probabilities of the 34 comp onen ts app earing in the program. Note that the branching factor for a searc h tree (e.g. depth-first searc h) is larger than 34, since the lines which contain higher-order functions also require selection of one of the predicate functions; for lines which hav e t wo func- tions, the ranking order is determined by the smaller probabilit y . In the recurrent neural netw ork, a long short-term memory (LSTM) netw ork is added to pro duce a p er- line heuristic. Most of the architecture is unc hanged: as in the original DeepCoder mo del, the inputs and outputs are sent through an embedding lay er, con- catenated, passed through three fully-connected la y- ers, and then av eraged across the fiv e examples. How- ev er, instead of predicting the probabilities of inclusion for each function directly , this represen tation is instead pro vided as an input into the LSTM, which outputs a new represen tation for each line of the program. As b efore, a final sigmoidal output lay er emits probabili- ties for each of the 34 functions, but now it is applied across eac h line. The embedding lay er in this netw ork is 50-dimensional, and the b oth the fully connected la yers and the LSTM hav e 200 hidden units. The re- sult is a net work which takes as argumen ts not just the input / output examples, but also a target “num b er of lines”, and then returns estimates of probabilities that a function occurs on a p er-line basis, rather than program-wide. Influence of the size of the training set W e inv estigated the effect of training on 90%, 20%, 10% and 1% of the p ossible programs. All the exp eri- men ts here were done on programs of length ` = 3, us- ing non-uniform sampling to generate the training and test sets. Although we decrease the num b er of total unique programs in the training sets, the total num b er of examples remain fixed for eac h set at n = 300000. Although the later sets see less programs, they con tain more examples p er program. W e observe in Figure 8 that the p erformance on top-k prediction of the test set programs is not very sensitive to the amount of programs in the test set. In light of this fact, w e c ho ose to train with sets containing 10% of the p ossible programs. This is go o d news, since in most settings, v alid input-output pairs would b e c heap er to generate than v alid programs. Details of Restricted Domain data generation metho d A v alue range for acceptable outputs is sp ecified (ini- tially [ − 255 , 256]), as well as the maximum length of the output if it is a list (the length is chosen uniformly at random from one to ten). The program is ev aluated bac kwards, computing for each intermediate v ariable a ‘safe’ range for its v alue that guarantees to ha ve out- puts in the target range. By applying this backw ard propagation of b ounds to the whole program w e find a suitable input range. V al- ues are then sampled uniformly from this range to cre- ate the input(s), and the output is calculated b y ev al- uating the program. If the resulting v alid range for some input is empty or a singleton, then the program is discarded. The short program describ ed in Figure 9 illustrates the approach and a key limitation of it. The function ScanL1 (*) on list A outputs a list whose v alue at p o- sition k is the pro duct Π k i =0 A [ i ]. F or lists of length 5 the input range for ScanL1 (*) that guarantees out- puts b etw een − 256 and 256 is [ − 3 , 3]. Pushing this range back through Map (+1) gives a range for b of [ − 4 , 2], which is unc hanged b y Fil ter (%2==1) . In T echnical rep ort Example program: a ← [int] b ← Fil ter (%2==1) a c ← Map (+1) b d ← ScanL1 (*) c Example input, and incremental output: a = [-200, 144, 25, 66, -7, 38, -1, 14, 80, 81, 155] b = [25, -7, -1, 81, 155] c = [26, -6, 0, 82, 156] d = [26, -156, 0, 0, 0] Figure 9: A program with complex restrictions on inputs that will remain in the target range Figure 10: Marginal distribution ov er prop osed in teger v alues in the non-uniform sampling. fact any even num b er could b e accepted as part of the input, and if the input contains − 1 at some p oin t then an y v alue app earing subsequen tly in list can b e large. Non-uniform Sampling The marginal distribution ov er sampled integer v alues is shown in Figure 10. A note ab out empt y outputs Some programs in the DSL output either null or the empty list on a large num b er of outputs. While these are informative to some extent, they dominated the examples gener- ated for certain programs. The process of propagating b ounds through the program is fo cussed on the v alue ranges and do es not naturally exclude empty outputs. F or example, it is not p ossible to sp ecify a r ange (other than one containin g only a single eleme n t) for inputs to Fil ter(%2==0) that guaran tees a non-empty out- put. T o ensure that empt y outputs could not domi- nate we included p ost pro cessing for b oth sampling metho ds which rejects empty outputs until 90% of the p ermitted attempts hav e b een made. Details of Simple Constrain t Based Data Generation Our training data was made up of 25 sets of 5 exam- ples for each program. Due to the random choice of minim um input length there are 6 v ersions of the ini- Figure 11: Relative improv ement to a search pro cedure assisted by neural netw ork predictions. The netw ork w as trained on the Semantic V ariation data, w e see ho w the loss in predictiv e p erformance is reflected in increased search effort tial SMT problem. Subsequen t SMT problems depend on the previous examples pro duced but because subse- quen t calls to the solver v ary only slightly the examples generated can b e v ery similar. W e exp erimen ted with randomly adding weak constrain ts such as setting the first elemen t of an input to b e o dd or even or p ositive or negative in order to modify the problem slightly for eac h call to the solver, ho wev er for the exp eriments re- p orted here the data was pro duced without any suc h random constraints and a few examples are indeed re- p eated across different sets. The Effect of Neural Net work Performance on Searc h Since the inten tion of training the neural netw ork is to use it to aid a search pro cedure, we ran a depth first searc h based on the predictions made by eac h net work. The cumulativ e time taken to complete the search by eac h netw ork is shown in Figure 11, sho wing the effect of reduced prediction accuracy on the time tak en to find suitable programs. The net work trained on simi- lar data sav ed around one quarter of the total search time across the test set o ver the worst performing net- w ork. This sho ws ho w the b enefits of mac hine learning to programming b y example may b e ov erstated when only ev aluated on “friendly” artificial data.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment