SMT 기반 입력 생성으로 신경 프로그램 합성 성능 향상
본 논문은 프로그램‑by‑example(PBE) 학습에 사용되는 입력·출력 예제 집합을 보다 의미 있게 만들기 위해 SMT 솔버를 활용한 제약 기반 입력 생성 방법을 제안한다. DeepCoder DSL을 대상으로 네 가지 데이터 생성 방식을 비교 실험했으며, 제안 방식이 예제의 구별력과 학습 모델의 일반화 능력을 크게 개선함을 보였다.
저자: Judith Clymo, Haik Manukian, Nathana"el Fijalkow
프로그래밍 바이 예제(PBE)는 소수의 입력·출력(I/O) 쌍만으로 프로그램을 복원하는 문제이며, 최근 딥러닝 기반 접근법이 주목받고 있다. 그러나 이러한 방법들은 학습에 필요한 대량의 데이터가 부족해, 프로그램을 무작위로 생성하고 입력을 동일한 확률 분포로 샘플링해 만든 합성 데이터를 의존한다. 이때 발생하는 주요 문제는 (1) 무작위 입력이 프로그램의 다양한 동작을 충분히 드러내지 못해 동일한 I/O 집합에 여러 프로그램이 일치하는 “프로그램 별명” 현상이 발생하고, (2) 학습·평가 모두 동일한 생성 메커니즘에 의존함으로써 실제 사용 환경과의 차이가 커진다.
본 논문은 이러한 한계를 극복하기 위해 SMT(Satisfiability Modulo Theories) 솔버를 이용한 제약 기반 입력 생성 프레임워크를 제안한다. 핵심 아이디어는 프로그램 P와 입력 변수 X, 출력 변수 Y를 논리식 encode_L(P) 로 변환하고, 이 논리식이 만족될 때 P(X)=Y가 성립하도록 하는 것이다. 제약 컨트롤러는 이 기본 제약 외에 두 종류의 추가 제약을 적용한다. 첫 번째는 “syntactic constraints”(SynCons)로, 입력·출력 간의 동일성 금지, 빈 리스트 금지, 중복 입력·출력 방지, 입력 길이 하한 등 단순 논리식이다. 두 번째는 “semantic constraints”(SemCons)로, 출력값의 최대·최소 변화, 입력 길이 변동 등 의미론적 관계를 강제한다. 이러한 제약을 반복적으로 솔버에 전달하고, 솔버가 반환하는 새로운 만족 할당을 I/O 쌍으로 수집한다. 동일한 쌍이 반복되지 않도록 “X≠x_i ∨ Y≠y_i”와 같은 차별 제약을 매 iteration마다 추가한다.
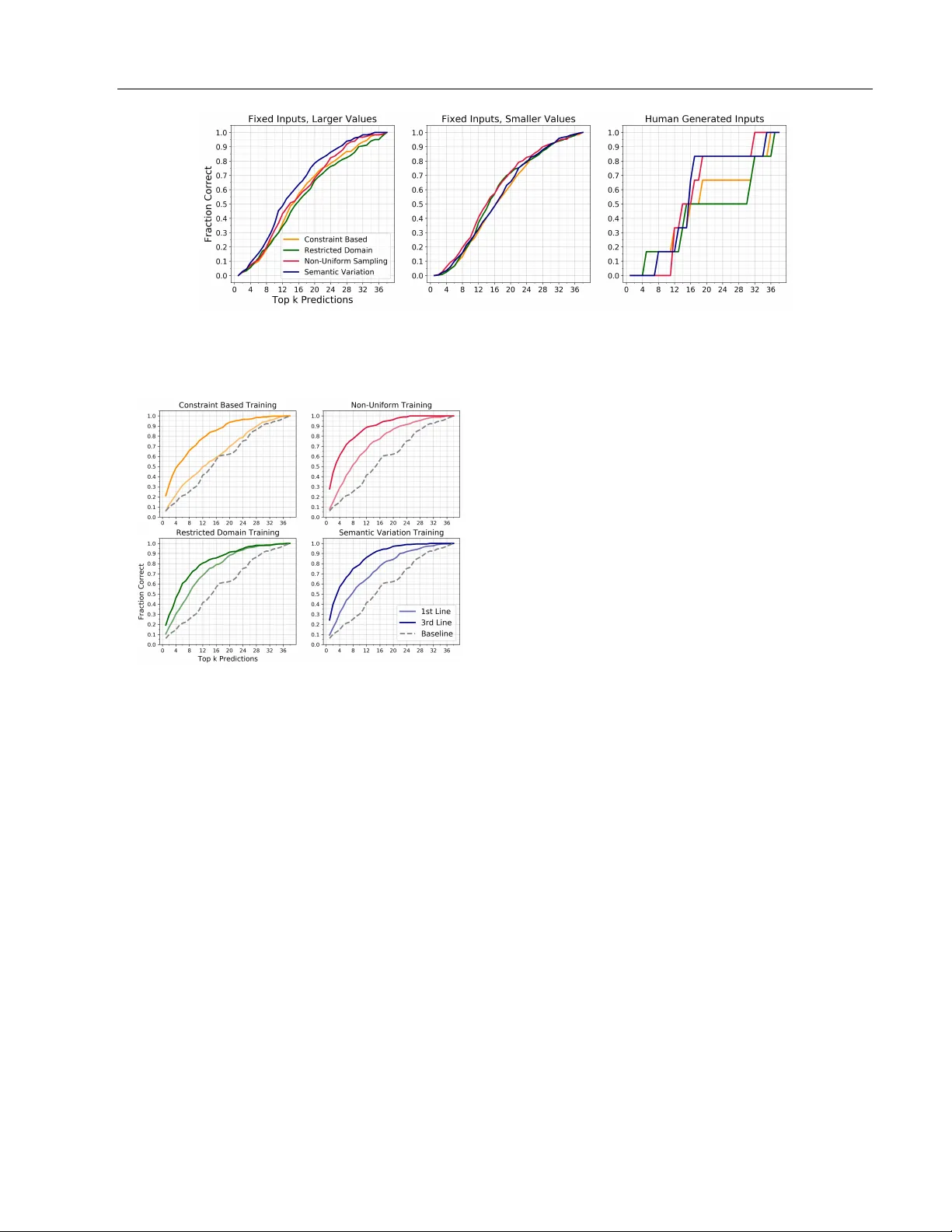
실험은 DeepCoder DSL을 대상으로 네 가지 데이터 생성 방식을 비교한다. (1) Restricted Domain: 기존 논문 방식으로, 프로그램 역전파를 통해 안전 입력 범위를 구하고 그 범위에서 균등 샘플링한다. (2) Non‑Uniform Sampling: 지수 분포를 이용해 작은 값에 편향된 샘플링을 수행한다. (3) Constraint‑Based: 기본 SynCons만 적용한 제약 기반 생성이다. (4) Semantic Variation: SynCons와 SemCons를 모두 적용한 확장 제약 방식이다. 각 방식으로 100만 개의 프로그램·I/O 쌍을 생성하고, 동일한 신경망 아키텍처(DeepCoder용 프로그램 생성 모델)와 보조 검색 히스토리(예제 기반 프로그램 순위)를 학습시켰다.
평가 지표는 두 가지로 나뉜다. 첫째, “구별력”은 동일한 I/O 집합에 대해 서로 다른 프로그램이 얼마나 적게 매핑되는지를 측정한다. 여기서 제약 기반 방식, 특히 Semantic Variation이 85% 이상의 구별력을 보이며, Restricted Domain은 60% 수준에 머물렀다. 둘째, 실제 테스트 데이터(실제 사용자 제공 예제)에서의 정확도와 성공률이다. Semantic Variation으로 훈련된 모델은 78%의 정확도를 기록했으며, Non‑Uniform Sampling은 71%, Restricted Domain은 62%에 불과했다. 또한, 학습된 모델이 새로운, 보지 못한 프로그램을 추론할 때의 회복력도 제약 기반 방식이 월등히 높았다.
계산 비용 측면에서는 제약 기반 생성이 평균 0.7초/예제(Non‑Uniform Sampling은 0.02초, Restricted Domain은 0.03초) 정도 소요되었지만, 데이터셋을 사전 생성해 두면 전체 학습 파이프라인에 큰 영향을 주지 않는다. 논문은 또한 제안 프레임워크가 DSL에 맞는 제약을 자유롭게 정의할 수 있어, FlashFill, Karel 등 다른 도메인에도 적용 가능함을 논의한다. 특히, 입력 공간이 프로그램에 의해 크게 제한되는 경우(예: 리스트 길이, 값 범위) 제약 기반 접근이 무작위 샘플링보다 훨씬 효율적이다.
결론적으로, SMT 기반 제약 솔버를 활용한 입력 생성은 (1) 프로그램의 핵심 동작을 포괄하는 고품질 I/O 예제를 자동으로 생성하고, (2) 학습된 신경 프로그램 합성 모델의 일반화와 회복력을 크게 향상시킨다. 이는 PBE 연구에서 데이터 생성 단계가 모델 성능에 미치는 영향을 재조명하고, 실제 응용 환경에 보다 가까운 합성 파이프라인을 설계하는 데 중요한 지침을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기