Generalized Methods and Solvers for Noise Removal from Piecewise Constant Signals
Removing noise from piecewise constant (PWC) signals, is a challenging signal processing problem arising in many practical contexts. For example, in exploration geosciences, noisy drill hole records need separating into stratigraphic zones, and in bi…
Authors: Max A. Little, Nick S. Jones
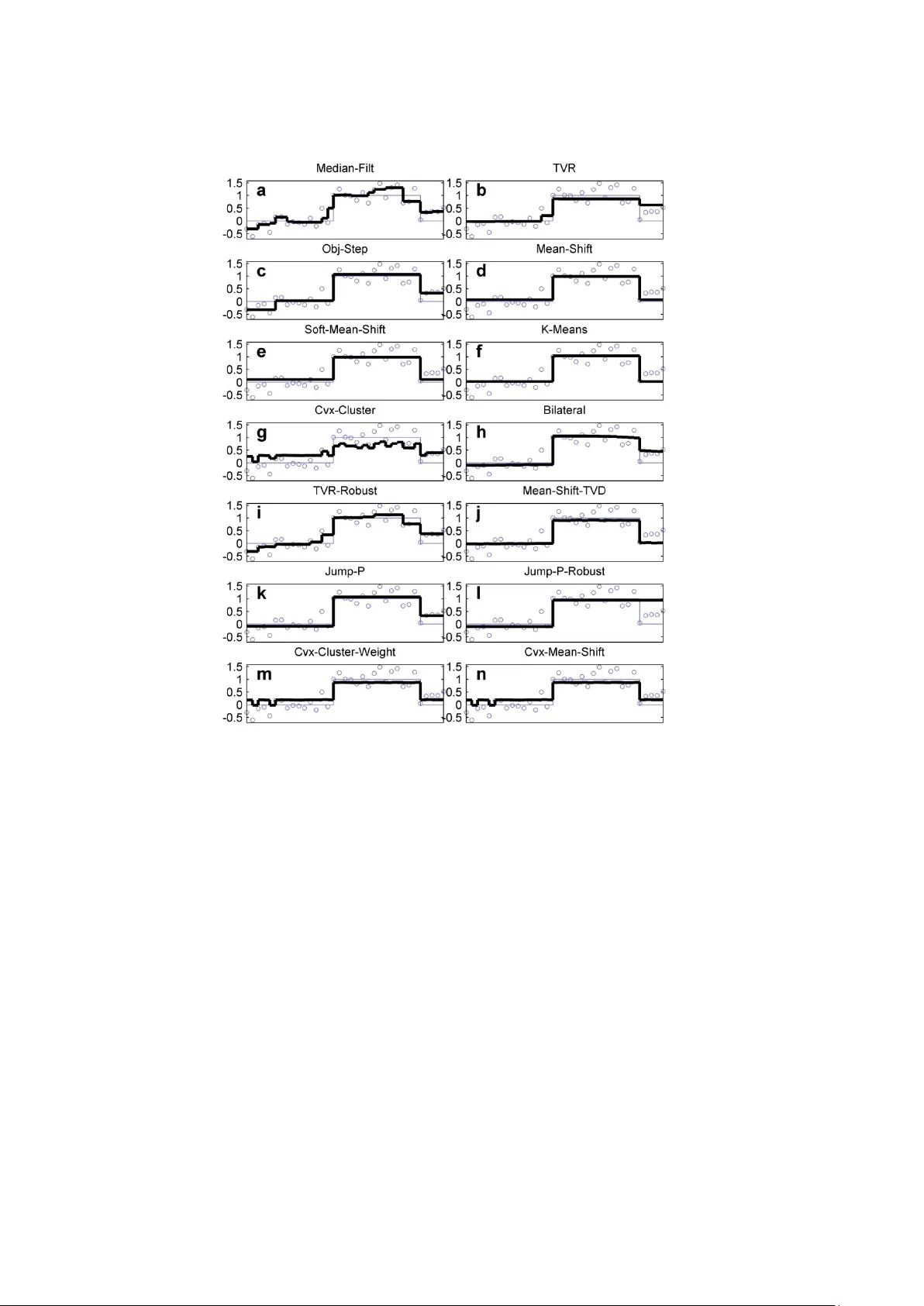
Generali zed Methods and Solvers for Noise Removal from Piecewise Constant Signals Max A . Litt le (max.li tt l e@physics.ox.ac.uk) , Nick S. Jone s (nick.jones@physics.ox.ac.uk) Departmen t of Physi cs and O xf ord Centre f or I ntegrativ e Systems Bi ology, University o f Oxf ord, UK 22 Decembe r 2010 Abstract Rem oving nois e f ro m signals which ar e piecewise cons tant (PWC) is a challenging signal processing proble m that aris es in many pract ical sc ien t ifi c and enginee ring co ntexts. For example, in e xpl orat i on geo sciences, nois y dr il l hole reco rds m ust b e separated in to const ant strati graphic zones, and in biophysics, the j umps bet ween states and dw ells o f a molecular struct ure need to be det er mi ned fro m noisy fluorescence mi croscop y s i gna ls . This pro blem is one f or w hich conve nti ona l linear s ignal pr ocessing methods are f un d amenta lly unsui ted. A wide ra nge of PWC deno i sing methods exis ts, including t ot al variation regularization, mean shift cl uster in g, stepwise j ump placement, running m edian fil ter ing, co nvex clustering shrin kage, bilateral fil ter ing, wav elet sh rinkage a nd hidden Markov models. T his pape r builds on results f ro m t he image pro cessing co mmuni t y t o sh ow t hat t he majorit y o f these algo ri thms, a nd mo re pro posed in the w ider literature, are each asso cia ted w i th a special ca se o f a ge neralized funct i onal, t hat, when minimized, so lv es t he P WC de noisi ng pro blem . We s how how t he minimizer can be o btained by a ra nge o f co mputational so lver algor ithms, including st epwise jump plac ement, quadratic o r linear pr ogrammi ng, fi nit e dif fe rences wi th a nd w i t hout adap tiv e st ep s ize , i terated running medians, least angle regression, p iecewise- li near r egularizat i on path f o ll ow ing, o r coordinate descent. Usin g t his generalized functional , w e in tro duce se ve ral novel P WC deno isin g methods, which, f or exam ple, combine t he g l o bal beha vi our o f mean shift cluster in g w i t h t he l ocal s m oo thin g o f t ot al variat i on d iffusi o n, a nd sh ow example so lver algor ithms for these new met hods. Head - to - hea d co m parisons between these methods are perf or m ed on synthet i c data, rev ealing that our new m ethods h ave a useful ro l e to pl ay. Fi nally , o verl ap s between t he generalized methods o f t hi s paper and ot hers such as wa velet sh rinkage, hidden Marko v models, and piece wise smoot h fi l t er in g are touched on. Key words: piecewis e c onstant signal , filtering , noise r emoval , shif t , edge , step , change , change point , singularity , level , s egmentation . 1. Introduction Piecew ise constant (PWC) signals e xhibi t flat reg i ons w i t h a finite number o f a brupt j u mps that are ins tanta neous, o r eff e ctively ins ta ntaneous because t he transi t i o ns o ccur in between sampling intervals . These si gna ls occur in many contexts, includin g bioinformat i cs (Snijders et al . , 2001) , as trophysics (OLoughlin , 1997) , geophysics (Mehta et al . , 1990) , m o l ecular bi osciences (S owa et al ., 2005) and digi ta l imagery (Chan a nd S hen, 2005). Figure 1 shows examp les o f signals t hat could fi t this de script i o n t hat are apparently co ntaminated b y si gnificant noise. O ften, we are in terest ed in recovering the P WC signal fro m this no i se, u s ing some k in d o f digi t a l f il t er in g t echni que. Because such s ignals arise in a gr eat m any scient if ic and e ngineering d isciplines, this no ise fil t er ing pro blem tur ns o ut to be o f enduring interest . However, it goes under a confusing array o f names. An a brup t jump ca n be call ed a shift , edge , step , change , change point , o r l e ss co mm o nly, s ingularity or trans ition ( som et im es combine d, e.g. step change ), and to em phasise t hat t hi s j ump is instantaneous, i t can o ccasi o nally a lso be sharp , fast or abrupt . The co nstan t r egi ons are o ften a ls o called level s . Bearing in mind t ha t finding t he l o cat i on o f the jumps usually allows est im at i o n o f t he level o f t he flat r egions, t he fil t er ing pro cess i t self (usually smoothing ) can al so b e ca lled detection or appr oximation , and l ess co mm o nly classification , segmentation, findi ng or localization . Statis t i cians have l o ng been interest ed in this and related pro bl e ms. Some o f t he ear liest att em pts to solve t he related change point detection probl em aro se in t he 1950’s f or statistical proces s control in m anufacturing (Page, 1955) , which began a series of st atistical co ntrib ut i ons t hat continues to this day, s ee f or ex a m p le (Pawlak et al., 2004). T he running median f ilter was introduced in t he 1970’s (T ukey , 1977) as a pr oposed improvement to running mean filtering , brin ging robust statistical e stimation t heor y t o bea r o n t his pr oblem. Foll ow ing this, ro bus t stati st i cs features heavily in a diverse range o f approaches repo rted in the st atisti cs ( Fr ied, 2007), si g nal processin g (E la d, 2002; Do ng et al ., 2007) and appli ed mathemat i cs li t eratur e (Gather et al . , 2006) . The P W C w i t h nois e m ode l is a ls o important for d i gital images, because edge s, co r respondin g t o abrupt ima ge in t e nsi t y jumps in a scan line, are highly salient features ( Marr and H il dreth, 1980) . Theref ore, noise re m ova l f ro m P WC s ignals is o f critical import ance to digital image processing , and a very r ich so urce o f contributions to t he PWC filter in g pro blem have been devised in t he image signal pro cessing co mmuni t y, such a s mathematical morphology ( Serra, 1982) , nonlinear diff usion f iltering (Perona and Malik, 1990) , total variation denoising (Rudin et a l ., 1992) a nd r elated appro ach es, de vel oped t hrough t he 1970 ’s to t hi s da y . T hese e ff ort s establishe d str ong connec t i ons with, and assimilat ed som e o f t he ear lie r wo rk o n, robust fil t ering (E lad, 2002; Mrazek et a l ., 2006). T he fact t hat piecew ise Lipschitz f unctions are goo d models f or P WC s ignals implies t ha t they have a pars im o ni o u s represe ntation in a wavelet basis (Mallat, 2009) , and wavelets for PWC de noisi ng were in t roduced in the 1990’s (Ma llat and Hwan g, 1992) . In apparent is o l at i on f r o m t he image pro cessing and stat i st ics co mmuni t ies, ot her disciplines have described alternative algo rithms. Beg inning in the 1970 ’s, explorat i on geophys icis ts de vis ed a number o f no vel PWC denoisin g algor i t hms, including step w i se jump pl acement (G ill , 1970) – apparent ly re invented a lmos t 40 ye ars later by bi o p hysi cists ( Ke rssemakers et al., 2006) . In the 1980’s hidden M arkov models (Go dfrey et al., 1980 ) were in t ro duced by geophysicis ts, wit h bi op hysics f o ll o wing this t rend i n t he 1990’ s (C hung et al., 1990) . Neuroscientists descr ib ed novel nonlinear fil t ers that att em pt to ci rcumvent t he edge smoot hin g limitat i ons o f running me an filtering aro und the sam e time (C hung and K enned y , 1991) . Superfi cially, t his pro bl em do es not appear to be particularly d ifficult, and so i t i s reasona ble to ask why it st ill deserves at t enti o n. To answe r t his f ro m a si gnal processing perspect iv e, abrupt j umps po se a fundamenta l challen ge for conventional li near method s , e.g. fi nite impu lse response, infini te impulse response o r fast Four ier tr an sform -based fil ter ing. I n the Four ie r basis, P WC signals conv erge slo wly : t ha t is, t he m ag ni tud es o f Fourier coefficients decrease much sl ower wit h increas ing frequen cy t han t he co effic ients f or cont inuous f u nct i o ns (Malla t, 2009) . Signal recovery requ i res removing the no i se, a nd convent i o nal linear m et hods t ypic ally ac hieve this by low-pass f iltering , t hat is , by re m o val o f t he high frequency det ail in t he s ignal . This is effective if t he si gna l t o be recovered i s sufficiently s m o ot h. But PWC s i gna ls are not smooth, and l ow -pass fil t er in g o f P WC si gna ls t y pically in tro duces large, spur i ous o scillations nea r t he j u mps k n o wn as Gibb’ s phenomena ( Mall at, 2009). The no i s e and t he P WC s ignal overlap sub stantially in the Fourier basis and so cannot be separated by any basic appro ach that r educes t he magni t ude of so m e Four i er co efficien ts, which is how convent i onal low - pass no i s e re m oval wor ks. This t ypical inadequacy o f convent i onal linear fil ter ing is ill ustr ated in Fi gure 2. Theref ore, we usually need t o inv oke nonlinear o r non-Gaussian t echniques (t hat is, w here t he variables in t he pro bl e m are not assumed t o be normally distributed) in o rder to achieve effective perfor m ance in this digita l fil t er ing t ask. The nonlinearity or non-Gaussiani t y o f t hese techniques makes them harder to underst and t han linear t echniques , and, as suc h, t here is st ill much to di scove r about the PWC deno ising pro bl e m , and it rem ains a to pi c o f theoreti cal interest. The li terat ure o n t his t opic is f r ag mented across statist i cs, app lied mathematics, s ignal a nd image processing, inf or m at i on theor y and spe cialist scient ifi c a nd enginee ring do mains . Whil st re l at i onships between many o f algorithms d iscussed here hav e bee n e stablished in t he image pro cessin g a nd st atist i cs co mm u nities – suc h as the connections between nonli ne ar d iffusi o n, ro bust fil t ering, tot al variation denoising, mean shift clust erin g and wav elets (Candes and Guo , 2002; Elad, 2002; Steidl et al., 2004; Chan and S hen, 2005; Mrazek et al., 2006; Arias -Cast ro and Donoho, 2009) – here we identify so m e broader pri nci ples at work: 1. The pr oblem o f P WC deno i sing is f r uitfu lly under stood as either pie cewise con stant smoothing , or as level-set recovery o wing t o t he f act that t y pically, t here will be ei t her o nly a few iso lated j umps in the si gna l , or j ust a few, isolated levels . The p iecewi s e constant vi e w natura lly sugge sts methods t hat fi t 0- degree (constant) splines t o t he noisy signal a nd which t y pical find t he jump locations t hat det erm ine the lev els. By co ntrast, t he level-se t view suggests clustering methods t hat attempt to fi nd the levels and thus determi ne the l o cat ion o f the j u mps, 2. Building o n wo rk f ro m t he image pro cessing literat ure, a ll t he methods w e study here are a ssociated with sp ecial cases of a generalized, f u nctional e quation, with t he cho i ce o f t er m s in this funct i o nal determining t he specifics of each P W C method. A few, general “co mponen t” f unct i ons are assembled in t o the term s t hat go to m ake up t his f u nct i o nal. We show he re that this funct i onal is bro ad ly applicabl e to a wi de set o f m et hods proposed acro s s the dis ciplines, 3. All t hese methods f unct i on, e i t her explicitly by t he act i o n of the so lv er, o r im plicitly by nature o f t he gene ralized funct i onal , by app licat i o n o f a sample distance reduction principle : to mi nimize t he sum in the functional, the abso l ut e differences bet ween some samples in the input si gna l has to reduce sufficiently t o pr o duce sol ut i ons that h a ve what we ca ll t he PWC property . A s o l ut i on wi t h t his property has a par sim o nious represent ation as a con stant spli ne o r l e vel-set, 4. All the P WC methods we st udy here at tempt to minimize t he genera li zed fu nctional obta in ed u sing some k in d o f solver . Although, as prese nted in t he li ter ature, these so lve rs are all seemingly ver y diffe rent, we show t hat t he se are in fact special cases o f a ha ndful o f very general co ncepts, and we identify the conditions under which each type of solver can be applied m o re gen erically. These findings pr ovide u s wit h so me str uc tur al in si ghts a bout existing methods a nd t hei r re lati o nships t ha t we expl o re in t his paper, and allow us t o develop a number o f novel P WC deno isin g t echniques, and so me new solvers, that bl end t he re lative m erits of e xisting methods in useful w ays. The det a il ed nature o f the extensive gro und work at t he st art o f t his paper i s necessar y to make i t clear how t he novel methods we pro pose in later sections are b ot h rel e vant, usef ul and so lvabl e in pract i ce. A summary o f t he paper is a s fo ll ow s. S ecti on 2 m ot iv at es and f or mali zes t he sp line a nd level -s et models for discrete-time P WC signals. Sect i on 3 in tro duces the ge neralize d fu nc t i onal t hat connects all t he methods in t his paper, and descr ib e s how thi s func t i onal ca n be built f ro m component f unct i ons. It in tr oduces t he sample dis tance reduct ion pr inciple . It shows how exis t ing PWC de noisi ng algor i thms are a ssociated w i th s pecial case s of t his functional. Sect i o n 4 d isc usses ge neral c lasses o f solvers t ha t minimi ze t he ge neralized funct i onal, and some new observat i o ns about exi st in g P WC deno i sing metho ds t hat ari s e whe n considering the p ro per ties of these so lvers. S yn t hesising the k nowle dge fro m t hese ear lier se ctions, Sect i o n 5 t hen goes o n t o mot iva te an d devise new P WC de noising methods and so lvers. S ecti on 6 co m pares t he numerical r esul t s o f t wo cha llenging PWC deno i sing tasks, and discusses t he accuracy of me thods and ef fi c ien cy of different so lv er s. Finally , Sect ion 7 summar is es t he findings o f t he paper a nd connect s to ot her approaches, including wavelets, HMMs, p ie cewise sm oot h fil t ers and nonli ne ar d iff u s i o n PDEs, and ment i ons possible d i r ect i ons for future research. 2. Piece w ise constant signals as splines and leve l -sets In t hi s paper, we wish to reco ver an sam p le PWC si gnal , for . W e assume t hat t he discrete-time signal is obtained by sa mpling of the co ntin uo us -t im e signal , (note that t he use of “time” here sim ply stands in f or the fac t that the sign al is j ust a set o f va lues or dered by t he index o r , and we will o f ten suppress t he index f or not ati o na l cla ri t y ). The observed signal is cor rupted by an ad ditive n o i se random process , i .e. . PWC s ignals co nsist o f two fun d a mental pieces o f inf o r m at i o n: the levels ( the values o f t he samples in co nstant regions ), a nd t he boundaries o f t hose regions ( the locat i o ns o f t he jumps). A co mm o n t heme in this paper is t he dis t in ct i on between (a) PWC si gna ls descr ib ed by t he l o cations o f t he ju mps , which in t urn det er min e t he levels according t o t he specifics o f the no i se re m o val method, and (b) signals described by the values of t he l evels, which then determi ne the l o cat i o n of the jumps thro ugh the propert i es o f the m ethod. By wa y o f mot iv at in g t he jump in terpret at i o n, we consider St e i d l et al. (2006) show in g t hat t he widely u sed total variation regularization P WC de noisi ng me thod has, as so luti o ns, a set of d iscrete -t im e, constant 0-degree splines , where t he location o f t he sp li ne knot s is det ermi ned by t he regu l ar izat i o n para m eter and t he in put data . This r esu l t pro vi des the first in t u i tive model for PWC signals as co ns truct ed f rom co nstant splines, and P WC denoisin g as a spline interpolation problem . The sp li ne model is usua lly a co m pact one because it is genera lly the case t ha t the PWC s ignal t o be recovered has o nly a s mall number o f d iscontinui t i es re lativ e t o t he length o f the signal, that i s, o nly a few jumps o ccurrin g between indices and where . T he jumps in the si gna l o ccur at t he spline knots w i t h l ocat ions (to gethe r with t he “boundary k not s” and f or co m pleteness). The PWC s i g nal is reco ns tructed from the values o f the constant l evels and the knot l ocat i o ns, e. g. f or , where . Al t er natively , o ne can view t he pro bl e m o f P WC deno i s ing as a clustering problem , classically so lved using techni ques such a s mean shift or K - means clustering (Cheng, 1995) . In this context, it is natural t o apply t he level-set m ode l , and indeed, this may so me t ime s be m o re useful (a nd m ore co m pact ) t han t he sp line descri pt i o n (Chan and S hen, 2005). The level -set for t he value ( refers t o the set of all u ni qu e va l ues in the PWC si gna l ) , i s t he set o f indic es co rrespondin g to , The co m plete l evel-set o ver all values o f the PWC signal is f or med f rom the uni o n of t he se level-set s, whi c h also makes up the co m plete index set, . The l eve l -set s form a par tition of t he index set, so t hat for all where . A succinct r epresen tat i o n o f each level-set can be co nstr ucted using o nly t he left and r i g ht boundary in d ices o f ea ch co ntiguously numbered range o f indices that m ake up each level -set . The sp line and level-set descriptions are, o f course, readi ly in terchangeable using appro pri ate tr an sformati ons. Since this paper is concerned with d is crete -time signal s only, t he defini t ion of a P W C signal used in t hi s paper is that t hey have a simple representation as either 0 - degree splines o r as level-sets. B y s imple, we mean t hat the number of jumps is smal l co m par ed to t he n umber of samples , , or, t hat the numbe r o f unique levels is small co m pared t o t he numb er o f samples . If a signal sat isfi e s either condition we say t hat i t has t he PWC proper ty . 3. A gener alized function al for PWC denoising As discussed in the in tro ducti on, a ll t he P WC de no i s ing methods inves t i gated in t his paper are associa ted with special cases o f the foll o w in g general f u nct i o nal equat i on: (3.1) Here is t he in put si gnal o f l e ngth , and i s t he out put of t he no i se re m oval algor i thm, o f l e ngth . T his functional co mbines diff erence functions into kernels , and lo sses . S ee T ables 1 and 2 and t he next sect i on f or details . In pract ice , usefu l kernel and loss f unct i o ns f or PWC denoisi ng are t y pically o f t he f orm descr ib ed in the tables. A la rge number o f e xis t in g methods can be ex pressed a s special ca ses o f the r esul t ing f unct i onal assemble d fro m t hese funct i onal co m po nents (Tabl e 1). Var i ous solvers can be u sed to minimize t his functiona l to obtain t he o utput , these are l is ted in Tabl e 3. 3.1 Diffe rences, kernels and losses As descr ibed in Ta ble 1, the basi s o f t he u nification o f t hes e methods in to a s in gle funct i onal equa t i o n, is t he quantification of t he differences between all pairs o f input and output sa m p les , and t hei r in dices (Table 1a). In the st atist i cal l i t erat ure, t he ge neralized functional (3. 1) would t y pically be d er iv ed f ro m specificat ion o f likelihood and prior d istr ib ut ions, where t he li kelihood wo ul d involve t erms in and t he pr i or inv olve functions o f . A minimizer for t he funct i o nal wou ld be a regularized ma ximum likelihood o r maximum a-posteriori estimator . In t his paper, we w ill t herefore descr ibe ter m s in as likelihood ter m s, a nd terms in as regularization terms. Usin g t hese d ifferenc es, loss functions (Table 1c) and kernels (T able 1 b) are constructed. By kerne ls , here we sim ply mean non- negative f unct i o ns o f abso lute diffe rence ( we ca ll this distance ), which are usua lly symmetr i c. The l oss fu nctions are non- negat iv e funct i o ns o f d i stances. W e de fine two diff er ent k in ds o f losses: simpl e l o sses t hat increase with d istance, a nd composite losses t hat ar e o nly increasi ng w i t h distance over a certa in range o f t he d istance . T he der ivativ e o f t he loss f u nction: the inf luence f unction (a t erm b orro we d f rom t he ro bus t statistics literatur e) pl a ys an impo rtant rol e in so m e i terat iv e a lgori thms for mi n imizing the functional ( in particular, see Sect i o n 4. 5, o n fini t e d iffe rences below). Wi t h co mposite loss f u nct i o ns, t he influenc e function is seen t o be a pro duct o f an a ssoc i at ed kernel t er m t hat represents t he magnitude o f t he grad ient o f t he l oss, and a term that represents t he direction o f t he grad ient o f t he loss. I n t his p aper, we w ill focus on s imple s ymmetric dis tance functions. The t hree cases we will f ocu s o n the non-zero count defining , whi c h is zero if is zero , and o ne ot herwis e. The case co rrespon ds to t he absolute dis tance, and corresponds to the square distanc e . We dist in gu ish between differences in t he values o f in put and o utput sa m p les, , and , and the d ifferenc e between t he sequence o f samples . T hus , a kernel based on d ifferences between pa i rs o f variables we call a value kernel , t o di stinguish i t f rom a kernel based o n which we ca ll a sequen ce kernel . W e ma ke f ur ther d istincti o ns between hard and soft kernels . Hard kernel s are non-zero for some range of dis tances, and o ut si d e t his ra nge, t hey are zero . Sof t kernels t ake non -zero values for all va l ues o f the d istance. We a ls o describe the t rivial ker nel t hat is 1 for a ll values of distance as t he global kernel . When us ed as a sequence k ernel t he g l o ba l ker nel mea ns that all pa i r wise t erms e nter in to t he su m , a nd w hen used as a value kernel it implies t hat all d ifferences in va l ue are weighted equally . All o t her kernel s are therefore local kernels . The s pecial local sequence kernels and is o l ate only adjacent terms in the generalized functional sum, and t erm s that are aligned to t he sam e in de x value, respectively ( where is an indic ato r function whi ch takes a value of 1 if is tr ue and zero otherwis e). The loss fu nctions are asse mbl ed into t he f unc t i o n in (3.1) t hat quantifi es t he loss incurred by e ver y diff erence. Summation o f o ver a ll pairs o f in d ices in the input and o utput si g nals leads to the f unct i o nal to be minimized wi t h respect to the output . 3.2 The sample distance reduction principle The generalized pr esentat i on of the P W C de noisin g me thods i n t his paper allows us t o see t hat the basic operation o f t hese methods is t o reduce the distance between samples in t he in put s i g na l . In t his sect ion we give a non-r i go ro us explanati on for t his behavi our. As t he s im p lest example, co nside r ; for this leads to a c onvex funct i onal t hat has the optimum , constant solution (t his c an b e shown b y diff erent i at in g with respect to each and sett in g each equat i o n to zero). Throughout t he paper we us e t he notation to denote the output si g nal o btaine d at i t erat ion o f a so lv er ( we thus ha ve a mi xed not ati o n in which t he co ntext defines the in terpr etati on o f m : it can e i t her be the unknown P WC signal w e ar e t rying t o estim ate or represents o ur curren t best estim ate). Our solv ers wo uld typically be ini t ialised with and then successive att em pts at solutions , , are condi t ional o n past attempts We e xpect good iterative so lv ers ini t ialized w i t h to reduce the d i stance be tween in put sam p les in successive i t erat i o ns, the natura l terminati on o f t his pro cess being the co nstant so luti on . Thi s o ccurs with t he s im ple l o ss that increases w i th increasing d iffe rence, a nd minimizing t he tot al su m o f l osses requ ires that t he differences mus t be reduced in abso l ut e value. Of co urse, t his t rivi al co nstan t so l ut i on is no use in pract ice . One way in which this t r ivial so l ut i on is avo i ded is by regularization : for the purpo se of illustration, co nsi d er t he f u nct i o nal arising f r o m f o r (see Tabl e 2). Th e resul t in g f u nct i o nal has t he property that wh en t he regularization param eter the optim al so l ut ion is ; but as , the second term dominates, f orc ing the samples in t he o utput s i gnal to collapse onto a s ingle co ns tant. A use ful P WC output co nsi sting o f severa l diff erent level s might li e between these two extremes. The trivial constant so lut i o n is also a voided by t he in tro ducti on of ke r nels . Cons i der, for example, t he sof t - m ea n shif t f unct i ona l for (See Table 2), and an iterat iv e so lver ini t ialized with . Wi t h this m od ifi c ation to the sim p le l os s function ( Table 1c), the l o ss attached to dis tances between sa mples do es not i nc rease strongly with i ncreasing d iff erences: beyond a certa in dista nce, t he l o ss remains e ffectively u nchanged. T hus , in minimizing t he t ot al sum o f losses in t he fu nc t i onal, so me pa irs o f samples are forced c l oser t o gether, whereas o thers are free to bec ome further apart . T hose that are constrain ed even tua lly co ll apse o nto a f ew level s. T herefore, a mi n imum o f t he funct i o nal is o f ten a use f ul P WC so lution. Note t hat the t rivial constant so l ut i on is a minimizer, but because t he fun ct i onal is not convex , a non-t rivial PWC so l ut i on is usually reached fi rst by a grad i ent descent solve r. Sequence kernels all o w t he d i st anc e reduct i on to becom e localised in index. For t he diffusion filter wi th and , o nly s amples t hat are adjac ent to e ach ot her m ust become closer to each ot her unde r minimi zat ion o f t he functional (see Sect ion 4.3). T he d ifference bet ween s amples that are not adj acent i s irrelevant. Locally constant r uns o f s imilar values c an t heref o re em erg e t o produce a PWC output. Note t hat here, for the case , t he only possible P WC o utput is t he t rivial const an t o utput because the diffusi o n is then li near. Ke r nel s app lied to differences o f t he input samp les al o ne can a ls o prevent t he out put from colla p sing do wn onto a single co ns tant. Fo r exam p le, by modifying t he simple loss (Table 1c) w i t h t he hard kerne l (T able 1b) applied to the input dif ferences, as in , , wi th so lver ini t ializat i o n , o nly t hose samples in the output si gnal t hat have the same index as sam ples in the input si gnal that are close in value, end up m ak ing a co ntribution to t he su m in t he functi ona l . Because o f t his, mi nimizing t he functional r equires only t hat t he d is tance between t hose samp les in t he output signal must be reduc ed, t he rest are unc onstra in ed. T heref ore, t he outputs t hat mi nimize t his (convex) functional ca n in c lude o nes t hat consi st o f m o re t han o ne level . 3.3 Existing methods in the generalized fu nctional form Diffusion filtering-type methods These methods, w i t h , can be u nderstood as combining seque ntially aligned likelih oo d terms w i t h ad jacent regulari zat i o n terms (see Sect i o n 3.1), using sim ple l o sses, w i th the regularizati on parameter . We ment i on the case for comple teness: t his can be so lv ed using a (cyclic) running w eighted me an f ilter o r usin g Four ier filtering (see Sec tion 4.3). It i s, howev er, o f no pract i cal use in P WC de no i s ing because it is pure ly quadrat ic , a nd he nce has a linear fil ter ing operation as solve r, a si t uation disc ussed in t he in t ro ducti on. Of m ore val u e is t he case where and : this is total variation regularization (Rudi n e t al., 1992). Where and , we o btain m a ny ju mp placement methods that hav e been pro posed in t he sc ientifi c and engineering literature ( Gill , 1970 ; Ke rssemakers et al., 2006 ; Ka lafut and Visscher, 2008) . The co rresponding d iffusi o n filtering metho ds, t hat are not cons trained by t he input s i g nal ( but t hat t ypically have t he signal as t he ini t ial condit i o n o f an i t erat ive solver: ), are o btain ed when the li k elih oo d ter m is rem o ved, e.g. wi th . Convex cluste ring shrinkage This c lustering method has , and co mbine s aligned d iff erences in t he li k e li hoo d t erm w i th a g l o bal regu larizatio n t erm w i th regu l arizat i on para meter . It uses only simple l o sses. The likelih oo d t erm uses the square l o s s, wh ereas the regularization term has abso lute v alue l os s (Pelckmans et al ., 2005) . Mean shift cluster ing-type metho ds This c lass o f methods uses g l o bal li ke li hoo ds or regu l ar izers, wh ere the losses (T able 1c) are assoc i ated w i t h hard, local value kernels ( Table 1b). F or coupled with an adapt iv e st ep-s i ze fini t e diff erence solver, we h ave mean shift cluster ing , and wi t h we o btain a cl u stering method t hat has im port ant simil ar ities to K-means clustering , we w ill call t his likelihood mean shift (Fukunaga and Host etl er , 1975 ; Cheng, 1995) , also see Sect ion 4.6. S ince these methods u se co m posite l o sses as de fined in Table 1c, differences between s amples h ave t o be s mall in or der to m ake a d ifference to t he va l ue o f t he functional . He nce, samples that start off c l ose under some iterat iv e so lve r ini t ialised w i t h , w ill become closer u nder i terat i on o f the so lver, t his induces t he “clus ter in g ” e ffec t o f these methods (see S ect i o n 4. 6 for further details ). Bilateral fil tering -type methods These me thods ex p loit s oft v a lue kernels, a nd hard sequence kern els i n the regularization term , and have . One way of descr ibing t hese methods is that t hey are s imilar to m ean shift c lustering w i t h so ft value kernels, but combined w i t h sequentially local, hard kernels (Mrazek et al., 2006) . They t heref ore inh erit so m e o f the cluster in g effect o f mean shift cluster in g, but also the e ffect o f clusterin g due to sequenc e locality. 4. Solvers for th e generalized fun ctional and some new observ ation s for existing methods We d istinguish t wo broad cl asses o f so lv ers f or t he generalized fu nctional: (a) t hose that di rectly minimize t he functional , and (b) t hose t hat so lve t he de scent ordinary dif f erential equations (ODEs) obta in ed b y diff erent i at in g t he func t i onal w i t h respect to . In category (a) we find gre edy m et hods t hat attempt to fi t a 0- degree sp line t o t he no i s y signal , conve x o pt im izat i on methods including linear a nd quad ratic pro gramming , coordinate desce nt , subgradient and many o thers. In category ( b) we find a very large number of techniques that can be ident ifi ed as nume rical methods for the (simul ta neous) initial value problem we o btain by d iff erent i at ing the functional w i t h respect to t he o utput si g nal . The go al o f t his sect i on is to dis cuss t hese so lv e rs in t he context of important PWC den o i sing methods that have f ou nd frequent use in pract ic e. Here we expand upon t he descent ODEs in a spec ial case t ha t i s import ant for t hose solve rs in cat ego ry (b). A minimum o f t he generalized functional is o btain e d at for each (which par allels t he fi rst -order o ptimali t y co ndi t i o n in variat i onal calcu l us). It wil l not be po ssibl e in ge neral t o solv e this result ing set of equat i ons a naly t ically , so o ne appr oach is t o start with a “guess ” solution and t o evolv e t his tria l so l ut i on in t he direction that l owers the value o f the m ost , until t he so l ut i on sto ps chan ging at a minimum o f the f u nct i onal . T his is t he idea behind the (st eepest) descen t ODEs defined a s , w i th t he ini t ial co ndi t i o ns . T he sol ut i on depends on the solver parame ter . Ma ny o f t he algori thms we describe in t his paper can be wr i tt en in t he form where are loss functions, are any s equence kerne ls , and is t he regul ar izat i on para meter, and t he steepest descen t ODEs are then : (4.1) Here the dependence o f t he out puts o n the solver parame ter has b een made e xplici t, b ut we will usual l y suppress this f or clarit y . T y pically , i t is arranged such that, when , , and is o ften used as the ini t ia l condition f or t hes e ODEs. As t he ODE s are evolved forward in , t he o utput beco m es c l o ser to having t he PWC pro perty on each i t erat i o n. 4.1 Stepwise jump placement A conceptua lly simple a nd co mm o nly proposed al go rithm f o r di rectly minimizing i s stepwise jump placement t hat start s with a spline w i t h no knot s as a t ri al so lution a nd t hen intro duces t hem t o t he sp line one at a time (G ill , 1970 ; Kerssemakers et al . , 200 6; Ka lafut and V i s scher, 2008). The locati on of ea ch new knot is determined by g reedy se arch , that i s, by a sys te matic scan t hrough all l o cat ions , fin ding the l o cat ion that reduces the funct i onal t he most at each i terat ion. If t he i terat i o n st o ps after a few knot s, t hi s ensur es that t he sol ut i ons satisfy t he PWC pro perty. At i t erati on we denote the sp li ne k not l o cations as . Then t he values of t he constant levels are determine d t hat minimize t he gen eralized funct i onal g iven these fixed kn ot indice s. St epwis e jump placement methods ty pically de fine a f unct i onal of the for m : (4.2) whe re are stri ct ly increas ing f u nct i ons – and since they a re increasing, this funct i onal has the same minimi zer as the f u nct i o nal o bta in ed from , wi th a regularization param eter t hat is deter mine d by either t he propertie s of the input si gnal or t he ch o i ce o f t he number of jumps. In part icular, t he method o f Kal afut and V isscher (2008) has and . Sin ce t he number of jumps is fixed at each iteration, the o ptim um levels in the spline fi t ar e just the mean o f t he samples f or each lev el: (4.3) f or . Only t he likelih oo d t erm must be e valuated to perform t he greed y sca n for t he in de x o f each new k not at i teration . Giv en t he func tional above, i t can be t hat no new knot index can be found that reduces bel o w t he previ ou s iteration; t his is used as a cr i t er i a t o t erm inate t he p l acement o f new knot s (Gill , 1970; Kalafut and V is scher, 2008) . Stoppin g a f ter a predetermined number o f jumps have been p laced (Gill , 1970), or de t ermi ning a pe ak in the ratio o f the likelih oo d t erm to the li ke lih oo d evaluated us i ng a “c o unter- fi t” ( Kerssemakers et al., 2006), simil ar in spirit to t he F-ratio statistic in analysis of variance , are tw o other suggested terminati o n criter i a. 4.2 Linear and quadratic programmin g For purel y convex problems (t hat is, probl e ms where t he l oss f unct i ons are all co nvex i n ), t h e unique minimi zer f or can be found us ing standard t echniques fro m co nvex o ptimi zat i o n (Boy d and Van denberghe, 2004). In part i cular, bot h total variat i o n regularization (Rud in et a l ., 1992) and convex clustering sh rinkage (Pe l ckmans et al., 2005) can be t ransf o r med in t o a quadrat i c pro gra m (quadrat ic pro blem w i th linear inequali t y constra in ts), which ca n be so lv ed by int erior-point t echni ques. Fast , speciali zed p rimal-dual interior- point me thods f or tot al variati o n regu lari zat i o n hav e been de veloped r e cent ly ( Kim et al., 2009) . The scope f or linear programs is very wide, i t applies t o l o ss functions such as the l o ss based on t he abso l ute d istance, but a lso f or asymm etr ic quantile loss f unct i o ns su ch as , where is the appropriate quant ile . Quant il es are minimizers f or t hes e as ymm etr i c losses, t he median being the special, symmet ric ca se (Koenke r, 2005), and t he se l osses wo uld be us eful if i t is e xpected t hat t he noise d istr ib ut i on has asymme tr ic outliers. 4.3 Analytic solutions to the descent ODEs In ge neral , all u seful PWC methods have functionals t hat cann o t be mi n imized a naly t ically; i t is inf o r m at iv e for the fl ow o f this paper, however, to s tudy a functional that ca n be so lv ed a naly t ically , eve n t hough i t i s not a usef ul in pract ice. For t he special case o f s imple square l o ss functions, minimi zat i o n o f t he funct i o nal ca n be carried out directly using matr ix arithmet i c . We start by considering linear diff usion filtering : (4.4) The ass oc iated ini t ial va l u e descent ODE s are: (4.5) with , t he boundary cases de fine d by f or and . We can wri t e t his in ma trix f or m as where is t he system matrix w i th o n t he m a in d iagonal, and o n t he di ago nals above and bel o w t he main d iagonal. This ca n be understood as a semi-discr ete heat equation , wi t h t he r ight han d side be ing a discrete appro xima t i on to the Laplaci an. This set of homogeneous, li near, constant co effi c ient ODEs can be solve d exact ly by finding t he ei ge nvalues and eigenve cto rs of the sys te m matr ix which are: (4.6) The m at r ix o f e i ge nvectors i s orthogonal, and can be m ade o rthonormal without l oss o f generali t y . This matrix is then uni tar y so , and the sol ut i on is wr i t t en explicitly in t erms of t he eigenvecto rs: (4.7) The constants of integrat i o n are determi ned by t he ini t ial condition , by calculat in g . This matrix o perati o n ca n, in f act, be seen t o be t he discrete sine Fou rier transf orm o f t he input sign a l, so the constants are Fourier coefficien ts o f the ex pansion o f t he solution in t he sine ba sis, and t he so l ution is merely t he invers e d iscrete sine t ransf o r m of t he discrete sine Fo urier domain representat i o n o f the input signal , where eac h f reque ncy co m ponent is scaled by . Since the eigenvalues are always negat iv e, the contr ib ut i on of these frequency co mponents in t he so lut i o n decay with increasing , t endin g to zero as . T his co nfi rms, by a d iff erent route, t hat t he solution ca n only be ent i rely co nstant when all samples are zero . Addi t i onally, for all so t hat hi g h f r equency co m ponents decay m o re qu i ckly w i t h increasing t han l o wer freque ncy co mponen ts. Therefore, high f requency fluct uation s du e t o noise are qu ickly s m o ot hed awa y, and sl o wly- varyi ng f r eque ncy co m pone nts rem a in. We w ill now m ake a connect i on to t he we ighted running mean f ilter , a ubi qui to us line ar smoot hing t echni que. The linearity and translation inv ariance with respect to o f th i s syste m allows the so l ut i on to be wri t t e n in t erms of a (c i rcular) convo lution with t he Gree n’s fu nction ( impulse response i n the signal pro cessi ng li t erature) . Usin g t he special initial condi t i o n f or an d ot herwise , t he Green ’s fu nct i on is : (4.8) f or a particular (here denotes t he entry wise pro duc t). Becaus e mul t iplication o f t he frequenc y componen ts i s equivalent to c onvolution in t he dom ain , we can n ow wr i t e t he sol ut i on as: (4.9) whe re in dicates circular convo l ution. The Green’s f unct i on is o f t he form o f a Gaussian “pulse” c entred in the mi ddle of t he signal . Iteratin g the convolution -times, , gi ve s t he so l ut i on a t m u l t i ples of , i .e. . For s m a ll , t he Gaussi an pu lse has small e ff ec tive w i dt h and so t he Green ’s f unct i on, cen tered aro und t he Gaussian pu lse, ca n be tr unca ted to produce an ( i t erat ed) w eighted running mean f ilter with sh ort window l ength : (4.10) with and the we i ghts, obtain ed by cen ter ing an d truncatin g the Green’s f unct i o n, are normalized . At t he boundaries we de fine for and . T he s m o ot hin g behaviour of t hi s linear fil t er is useful f or no is e re m o val , but, as d i scu sse d in the intro ducti o n, sin ce jumps in P WC signals also have si gnificant f r equency contr ib ut ions at the scale of nois e fluctuat i ons, these are sm o ot hed a wa y sim ultaneously. Thus, t he sm oot hin g functional o btaine d by t he square regu l arizat i on l oss is o f li t tle practica l value in P WC deno isi ng applicat i ons, despite t he t antali zing availability o f a n e xact analy t ic minimizer a nd its practical im p lementat i o n as a s im p le r unning weighted mean fil t er. 4.4 Iterated runn ing median filter While i t was seen above that t he iterated running (wei ghted) me an fil ter is o f n o esse nti al value in noise removal f ro m P WC si gna ls due t o its lineari t y , t he nonlinear iterated running median f ilter has been pro pose d ins tead. This finds t he median (rat he r than the mean) o f t he sa mples in a window o f length that s li des over t he si gna l : (4.11) with , .and t he boundaries are defined t hrough for and . The above minimizat i o n expresses t he idea t hat t he median is the constant that mi nimizes t he tot al abso l ut e deviations from o f t he samples in each w indow. This contrasts w i th the ( eq ual weighted) running mean filter which mi nimizes t he tot al squared de viations instead. I t i s well- known that the runni ng median f il ter do es not smooth away edges a s dramatically as t he running mean f il ter u nder condi t i o ns o f low no i se spread (Justusson, 1981; Arias-Castro and Donoho, 2009), and t heref ore thi s filter h a s v a lue as a me thod f or PWC de no i s ing i n a limi t ed ran ge o f applic at i ons. It e rated median fil ter ing has so m e value a s a met hod f o r PWC den o ising, so i t is in t erest ing to ask how i t is related to ot her methods in t his paper. We o bserve here a co nnect i on between total variation dif f usion filtering and the i terat ed m edian fil t er. We pro ve in t he appendix that applyi ng t he me dian fil t er w i th w indow si ze to a si g nal cannot in cr ease t he total variation o f t he signal, e.g. , wh ere . I f we consider a num erical so lv er f o r t he tot al var i at i on diffusi o n ODEs obtained f ro m t he generalized f u nct ional w i t h : (4.12) with the ini t ial co ndi t i o n , t his so lv er m ust also reduce t he tot al varia t i on o n each iteration (because i t is an integrator that lowers t he tot al variation f unc tional at each i terat i on). The window length 3 iterated me dian fil t er differs f ro m suc h an integrator becaus e every iterat ed m edian filter co nv er ges o n a root signal that depends on , t hat is , a si gnal t hat is fixed under the iteration of t he filter (Arce, 2005) . Theref ore, unlike the so l ut i on to the tot al v ariat i on d iffusi o n ODEs (t hat ev en tua lly leads t o a constant si gnal with zero total variat i on) this i t erat ed median fil t er cann ot r em o ve a ll jumps for all signals , and so i t does not nec essa r ily reduce t he tot al variation to zer o. De t ermining t he kn ot s in t he spline r epresentation i s not a sim p le ma tt er for t he i t erated median filter. After convergence, whether the so l ut i ons have the PWC propert y depe nds upon t he ini t ia l conditions , a nd the n umber o f iterat i o ns to r each convergenc e. 4.5 Finite differences Few ot her solvers have such w ides pread app licabili t y as nu merical methods for t he descent ODEs (4.1). For exam ple, in Sect ion 4.6 we w ill see that m a ny import ant PWC cluster in g a lgor i t hms can be der ived as specia l cases o f such nume r i c al methods. Init ial value problems such as ( 4.1) can be appro xim at e ly in tegrat e d us in g an y of a wide range o f numerical methods, including E uler (f orward) finite differences (Mrazek et al., 2006): (4.13) whe re i s the step s i ze, together w i t h ini t ial conditio n , a set of constants. This is accurate to first or der i n the st ep size. Higher order accurate integrators could be used instead if required. In t he special case where all t he l o ss f unct i ons are co nvex a nd different i a ble, t his method must converge o n t he unique minimizer fo r . If any one o f t he loss functi o ns is not diffe rentiable ever y w here, t hen convergence is not guaranteed, but achieving a goo d approximation t o t he minimizer may st ill be po ssibl e, part i cularly if t he l o ss f unct i o n is non-d if ferent i a ble at o nly a smal l set of isola ted po in t s. If t he loss funct i ons are not convex but are d iff er ent i able, t hen co nvergence to a minimizer for t he f unct i o na l is guara nteed; but t his may not be t he minimi zer t ha t le ads t o t he smallest pos sible value for t he functional . Wi t hout diff erent i a bility, t hen conv ergence cannot be guara nteed e i ther. For non - conv ex l o sses, o ne useful heur isti c t o gain co nfidence t hat a pro posed soluti on found using finite d ifferences is the minimizer asso cia ted w i th t he s mallest po ssibl e value f or the f unct i onal is to res t art the i t erat i o n several t ime s fro m ran do mi zed st artin g condi t i ons and i t erate until conv ergence (o r a pproxim ate co nv erge nce). One can then take the solut i o n with t he smallest val ue o f t he functional fro m t hese (approximately ) converged so l ut i ons. 4.6 Finite differences with adaptive step sizes In t his sect ion we w ill obta in many st andard clustering algo ri t hms as spec ial cases of t he fini t e d if ferenc e s in t ro duced above. Fo r t he Eu l er forward fi nite d ifference so lver, the fixed st ep s i ze can be rep laced w i t h a n adaptiv e step size. This t ri ck ca n be used t o deriv e mean shift , and the soft versi on of t his m et hod, as well a s the bilateral f ilter (Mrazek et al . , 2006), but it can be used m ore generally. We not e here t hat the po pular K-means method i s concept ually e xtremely similar al though not a di rect speci al case o f t he fu nct i o nal (3 .1) . In t his section, we s how how to deriv e a method we call likelihood mean shift (see T able 2) t hat is a re levant specia l case of t he f unct i onal (3.1) . As d i s cussed ear li er, if t he l o ss f unct i o n is composi te (Table 1c), then the influenc e function is t he pro duct o f a kernel a nd a di rect i on term (Cheng, 1995) . In part i cu lar, f or t he l ocal, hard l oss functions and , the inf luence func t i ons are and , so i n the l a tter case, the kernel is t he hard w in dow of size , and the direc tion ter m is jus t the diff ere nce . Wi t h co mposi te square l os s f u nct i o ns, such as , an d by (4.13), t he Euler fi nite diff erence f or m ula can be: (4.14) whe re is any seque nc e kernel (here, for sim plici t y, we have shown t he case where the for m o f t he kernels used in t he likelihood and regu la r iza t i on t er m s ar e t he same, but t hey need not be in ge neral). Now, we set a n appropriate adaptive step size : (4.15) ensurin g st eps beco m e larger in flatt er reg i o ns. Classical mean shift (Sect i o n 3.3 and Ta ble 2) u ses t he hard l o cal, square l oss f unct i o n; t he sequence ker nel is g lobal , so t he fi ni te difference formula becomes : (4.16) Replacing the st ep s i ze w i t h t he adaptive quant i t y , af ter some algebra we get: (4.17) which is the cl assica l mean s hif t a l go r i thm t hat repl aces eac h o utput sam ple value with the me an o f all t hose within a d istance . Wh at we are calling likelihood mean shift (Secti on 3.3 and Table 2) , has, simil ar to m ea n shif t t he adaptiv e step- size, l ead ing to t he i t eration: (4.18) that r epl aces each cluster cen tro i d with t he mean o f all t he input samples within a distance . Soft versi ons o f b o t h al gorithms are obtained by using the sof t kernel instead o f t he hard kernel. Up until now i t has been assu med t hat t hat for ea ch sample value at , , t here is a co rrespondin g est im ate for the PWC signal ; in t his case i s act in g as a n in dex for “t ime ” for bot h input and output si g nals . For our par t ic ular d iscussi o n o f K -m ea ns below i t i s necessary to all o w t hat t he index of need not be a pro xy for time but instead in dexes each d istinct level in t he PWC out put si g na l : t here might be distinct level s in t he PWC o ut put si g nal a nd i t is po ssibl e t hat Der ivi ng t he classical K-means algorithm – requires t he constructi on of the value ker nel : (4.19) which is t he in d icat or functi o n o f whether t he c l ust er centroid i s the c l o sest to t he input sample . Then t he i t erat ion: (4.20) can be seen t o repla ce t he clust er centro i ds wit h t he mea n o f a ll sa mples t hat are closer to i t t ha n t o any o ther cen tro id. Ch eng (1995) sh ows t hat can be o btain ed as t he limi t ing case of the sm oo t h f u nction: (4.21) when . Indeed, f or fi nite , t hi s yields the soft K -means algor i t hm. Howe ver, as we d i scussed a bove (Section 3.3), there are two reasons why the classical K -means a l go r i thm departs from the generali ze d f unct i onal (3.1) in t his paper. The fi r st i s because t he number o f d i stinct o utpu t sam p les in t he K - m ea ns a lgorithm i s , for . However, if t he re are m any less t han lev els in a PWC sig nal , t he K -means so lve r typically merges t he input samples do wn onto t hi s small number of u nique o utput values. T he second departure is t hat t he kernel cannot be o btain ed directly f ro m t he part i cu lar form o f t he generalized func t i onal (3. 1), because eac h t erm must t hen be a funct i on o f differences o f all sam ples in and , not jus t d iff erences o f samples in d exed by t he pair . However, K -means is an import ant PWC method an d i t i s co nceptually ver y simila r to me an shif t. In fact, the really cr i t ical diffe rence is that t he K - m ea ns algor i thm iterat es on the likelih o o d dif ference , whereas m ean shift iterates o n t he regulari zat i o n d iffe rence ( com pare (4.18) wi th (4.20)) Thi s i s our reason f or calli ng the cl u stering m ethod based o n the li kelih oo d t he likelih o o d m ea n shif t method. The bilateral f ilter (Secti o n 3.3 and Ta ble 2 ) combines the hard local sequence kernel and t he soft l oss t erm and this leads to t he f o ll o wing fi ni t e diff erence update: (4.22) Inse rt ing t he adapt iv e st ep size o btains t he bilat eral fil t er f or mula (Mrazek et al ., 2006): (4.23) See also E l ad (2002) for a very ins truct iv e a l t er native der ivat i on inv o lvi ng Jaco bi solvers f or t he equ iv a lent matrix al gebra for m ulat i on. This sect ion has s hown how adapt in g t he st ep- si ze of t he Euler integrator leads to a number o f we ll-know n clusterin g algor i thms for appro pri ate combinations o f l o ss funct i ons. T he d ynamics o f t he e vo lvi ng s olution can be u nderstood in t erm s o f t he level-set m o del. For m ean shif t c lustering, ini t ially , , an d (as sumi ng noise), each will t y pically ha ve a unique va lue, so every level-set contains o ne e ntry (which is just the index f or each sample), . As t he i t erat i ons pr oceed, Chen g (1995) sh ows that if is sufficient ly large t hat the suppo rt o f t he hard value kerne l covers m ore than o ne samp le o f the ini t ial signal, these samples w i t hin t he support wil l be dr awn to gether until t hey merge onto a sin gle value after a fini t e numbe r of i t erations. After merging, t hey alwa ys t ake o n the same value u nder f urther iterations. Therefore, after merging, t here w ill be a decreased number o f u nique values in , and fewe r unique level-sets, that will cons is t o f a n in creased numb er of indices. Gro ups o f merged samples will themselves merge into l arger gro ups under subsequent i terat i ons, until a fi xed point is r eached at whi ch no m o re changes to o ccur under subsequent i t erat i ons. Therefore, after convergenc e, depe nding o n t he ini t ial signal and t he widt h o f t he ker nel, t here w ill t y pically o nly be a few level-s ets t hat will consist o f a l arge number o f indices each, and the l evel -set descri pt i on will be very compact. In t he case of K -means c l ustering, t here ar e values in the P W C s i gnal o ut put and at each step, every lev el- set at i t erat i on is obtained by evaluat in g t he in dicato r kernel f or every : . Note t hat it is po ssibl e f or t wo o f t he l evels to merge with eac h ot her, in whic h case t he associated l evel-set s are als o me rged. Af t er a fe w iterations , K -means converges on a fi xed po in t where there are no m ore chan ges to (Cheng, 1995). Soft kernel versi o ns of K -means a nd me an shif t have simil ar merging behavi o ur u nde r i t erat i o n, except t he or der of t he merging (t hat is w hich sets o f indices are merged together at each i ter ation) will depend in a more complex way upon t he ini t ial signal and t he kern el par ame ter . Bila tera l fil ter ing ca n be seen a s so f t m ean s hif t, but with t he addition o f a hard sequential windo w. Therefore i t inheri ts s imilar mergin g a nd convergence behaviour under iteration. However, for samples t o merge, t hey must both be c l o se in va l ue and t em po ra lly separat ed by at m o st samples (whereas for mean s hif t, t hey need o nl y be c l o se in va l u e). The add i t i onal const rain t of t empora l locality implies t hat eac h merge do es not necessarily assimilate large groups of indices, and the level-set description is n ot t y p ically as co m pact as w i t h mean shift. 4.7 Piecewise linear path following For nearly a ll use f ul fu nctionals of t he for m (3.1), analy t ical so lutions ar e unobtainable . Ho wever, i t turns out that t here ar e so m e impo rtant special cases w hich f or which a minimizer ca n be obta in ed with a lgor i thms that might be descr ib ed as semi-analyt ic , and we d escr ib e t hem in this section. Fo r useful PWC de no i s ing, i t is comm o n t hat t he r i g ht hand side o f t he desce nt ODE sy stem is d iscontinuous, which po ses a cha ll e nge for conv ent i onal numerical t echniques such a s fini te d iff erences. Ho wever, i t has been s hown that if t he likelih oo d term is convex and piecewise quadratic (t hat is , construct ed of piecewise po ly no mials o f or der at m o st t wo), and the regulari zat i o n ter m has convex l os s functions that are piecew i se linear , t hen the so l ut i on to t he descent ODEs is cont in uous and co ns truct ed o f p iecewise linear segments (Ro sset and Zhu, 2007). Formally, t here i s a set o f r egularization points an d a c orr espondi ng set of -e l ement gradient vec to rs , in terms o f w hich t he f u ll regularizatio n path , that is , t he set o f a ll so l ut i ons o btain ed by varying a regularization param eter , can b e expressed. We can write t hi s a s: (4.24) f or all . P W C denoising algorithms t hat hav e this piecewise li near regularization pat h pr operty include total variation regulari zation and convex clustering shrinkage (P elc kmans et al ., 2005) . The values o f the regulari zat i on po in ts and t he grad i e nt vecto rs can be found using a general so lve r pro posed by Ro sset and Zhu ( 2007) , but specialized a lgori thms exist for total variation regu larization; o ne finding t he pat h in “f o rward” sequence o f increasing (Hofling, 2009) , and t he ot her, by expressing the co nv e x f unct i onal in t er m s of t he convex dual variables (Boy d and Va ndenberghe, 2004), obtains the sam e pa th i n r ev erse f o r decreasing (Tibshi rani and Ta yl or , 2010) . Tot al variati on regu larizat i o n has been the subject o f in te nsive stu d y since i ts intro duction (Rud in et a l ., 1992) . Strong and Chan (2003) show t hat a step o f height and w idth in a n o t herwi se z ero si g nal is decr eased in height by , and is “flatt ene d” when . Fundamentally , t hese findings ca n be explained by t he sample reduct ion principle: t he for m o f t he regu l ar i zat i o n t er m acts to linea rly decrease t he abso lute d ifference in v alue between adjacent sa m p les and as increases (a process known as shrinkage in t he statistics li t eratur e), and o nce adja cent sam ples eventually coincide f or o ne of t he regulariza t i on po ints , they share t he same value for all . T hus , pairs o f sa mples can be viewed as me rg ing to gethe r (a process known as fusing ) to form a new part i t i on of the index set , consisting of subsets o f indices in consecut iv e sequences wi t h no gaps. We will see illust rati ons o f this behavi our later when we e xamine the iteration pat hs of o ther solvers as well. Ini t ially , at , t his part iti o n is t he t ri vial o ne where each subset of t he in dex set contains a s ingle in de x. Subs ets o f indices in t he current part i tion assimilate t hei r neighb our ing subset s a s increa ses, unt il t he part i tion consists of j ust one subset containing a ll t he indices at , and t hi s is also where . T hus , tot al variation regul arizat i on recru i t s samples into c onstan t “runs” of increasing length as increases . This offers another intuitive explanat i o n f or why c onstant splines a ff o rd a co mpact understanding o f t he output of t ot al variat i o n regularizat i on. For t he backward path foll o w ing so lv er (T ib shirani and T ayl o r, 2010) t hat begins at the r egula rizat i on po in t , t he spli ne co nsists o f no jumps , and only the boundary k not s , and one level . As t he path is fo ll o wed backward to t he next regul arizat i on po in t , t he spli ne is sp li t w i t h a new k not at locati on and one new level is added, so t hat t he sp li ne is de scribed by t he set o f knots and l e vels . The so lv er cont inue s add in g knots at each regularization po in t until t here are lev els a nd knot s. The forward path fo ll ow ing a l gorithm star ts at this condition and m erges levels by delet in g knots at ea ch regu lari zation po in t. Piece wise linear pat h foll o w ing requires t he co mputation of t he r egula rizat i on po in t s , and i t i s p ossible to directly co mpute the maximum useful value o f t he regu larization p arameter where all the out put samples are fuse d t ogether (Kim et al., 2009): (4.25) whe re i s the elementw i se vector maximum, and is the fi r st dif ference matr ix : (4.26) Furtherm or e, knowing that a step o f height and uni t w i dth i s fl att ened when , all ows us to suggest an estim ate for t he minimum useful value t hat is jus t la rger than the no i se spread: if t he noise is Gaussian w i t h standard deviation , t he n sett ing will r emove 99% o f t he noise. T heref ore, t he use f ul range o f t he regularization param eter for P W C denoising can be estim ated a s . 4.8 Other solvers The desce nt ODEs define an init ial val ue problem that is a st an dard to pic in the numerical a nalysis o f nonlinear diff erent i al equat i o ns, and there exists a substant i al li terat ure on n umerical in tegrat i on o f these equati ons (Iserles , 2009). These incl ud e the fini te d ifference m ethods discussed a bove, but a l so predictor-corrector a nd higher o rder m et hods such as Runge-Kutta , multi step in t egrat ors, and collocation . The co st o f higher accura c y with high or der in tegrators is t ha t an in creased number o f evaluat i ons o f t he r i ght hand si de o f the descent ODEs are requ i red per step. Ho wev er, t he m a in depart ure o f t his pro blem f ro m classical ini t ial value pro blems is t he exis te nce o f d iscontinui t ies in t he r i g ht hand s ide o f the desce nt ODE system t ha t arise when t he l o ss f unct i ons are not differentiable e ve r ywh ere, a nd most o f t he useful l o ss functions for P WC de no isi ng methods are non - diff erent i able. As a so l ution, f lux and slope-limiters hav e be en applied t o total variati o n regular iza t i on in the past (Rudin et a l . , 1992). We a lso m ent ion here t he ver y interest in g matrix algebra in terpr etat i o n o f P WC deno ising methods t hat o pens up t he possib ili t y o f using s olvers designed f o r numerical matrix algebra inc l uding the Jacobi and Gauss -Seidel a lgori thms, and var i a nts such as suc cessive over-relaxation (Elad, 2002). 5. Ne w methods and solver s for PWC denoising Having introduced t he co mponents, the generalized f unct i o na l and so lv er a lgor i th ms for e xis t in g methods, in this sect i on we invest i g at e how so m e o f t hese exist in g concepts can be ge neralized. T here is m ore t han one potential starting po in t for t his. One appro ach is to ask about t he range o f validi t y o f t heir asso ciated so lv ers: wha t pr operties must t he fu nc t i onal sat isfy to a ll o w t his so lv er t o be app lied? Anot her appro ach is to att em pt to syn thesise new functi ona ls that are “hybr ids” o f exist in g methods, le ading to new methods t hat have t hei r o wn meri t as PWC deno isi ng methods. We will start by seeing how t he very simplest st epwis e jump p l acement solvers can be ge neralized ( Sect i on 5.1). We t hen discuss t he connect i on bet ween tot al variation r egula rizat i on and regression splines , and in do in g so m ot iv ate a n ovel c oordinate de scent method in (Section 5. 2). By considerin g a generalizat i on o f tot al v ar iati on r egu l arizat i o n, we will g ive a novel co nvex m etho d t hat can han dle stat isti c al outliers in t he noise, a nd c an be so lve d using o ff-t he-shelf linear pro grammi ng a l gor i thms (S ecti on 5.3). Next, in addressing an im po rt ant limi tat ion o f convex clust erin g s hrin kage (see Sectio n 3.3 and Table 2), we will mot iva te a weighting trick th at not only impro ves the usefulness of convex cluster ing sh rinkage, but also leads to a novel vers i o n of me an shif t c lustering that pro vi des a fu ndamen ta lly new clusterin g method and assoc i ated so lv er algorithm (S ection 5.4). Fin ally , by e xposin g so me of t he limitat i ons o f total variati on d iffusi o n and mean shift c lus ter in g, we deve l o p a hybrid method w i th im pr o ved performance , a nd derive a ne w so lv er algor i t hm for it (S ecti on 5.5). 5.1 Jump penalization and robust jump pe nalization Stepwise j u mp p la ce ment m et hods c an ensure th at the so l ut i ons have the P W C pr operty, w hich m ake s i t in t erest ing t o ask whether the i dea c an be ge neralized. T he co nceptua l sim plicity o f the stepw i s e jump plac ement solver a l go rithm is frustrat ed if t he r egula rizat i on t erm depends on t he knot locat i ons, as in t he case of t ot al variation regu lari zat i on where the reg ula r iza t i on t erm involv es t he abso l ute value of adjacent diff erences, o r where mi nim izing the likelih oo d term given the fi xed knot confi gur at i on is not straightf orward or requires co nsi derable co mputational e ff o rt . Thus, t he gr eatest appeal o f stepw ise j ump p lac ement algor i t hms is as a minimi z er for f uncti ona ls t hat combi ne the non-zero c ount regul ar ization t erm w i t h ad jac ent sequen c e kernel , , but, more generally , l ikelihood t erm s s uch as , whe re . We can therefore suggest novel jump penalization methods: (5.1) f or and f reely chose n regu l ar izat i on para m eter . For , t he mean f ormula (4. 3) appli es whe n cal culat in g t he l evels o f t he sp li ne fi t , whereas for t he median formula is requ i red to calcula te t he levels ins tead: (5.2) (Recall that i s the time index of the th knot o f t he sp li ne) . Fro m a statistical point o f vi ew, this jump penali zat i on method w i t h is va l u a ble where the no i se distribut i o n is symmetric and heavy- ta il ed, because in t his s i t uat ion t he m e an will b e hea vily influen ced by o utliers, b ut the m edian is ro bus t to thes e l arge devia t i ons. T he f unct i onal is non-co nvex a nd non-different i a ble, and t hus not am enable to me thods such as linear o r quadra tic pro gramming, and will po se n on- convergence c hallenges f o r numerical methods f o r t he associ ated i nit i a l va lue pro blem . Howev er, t he greedy search used in s tepw ise jump p lacemen t r equi res reconstructin g t he sp line fit for each putat iv e new jump locat i o n and t his is not nec essarily co mputati onall y effi cient. In the re levant li t erature ( Gill , 1970; Kerssemakers et al . , 2006; Ka laf ut and V isscher, 2008) , we have o nly f ou nd the ide a t hat stepw i se ju m p p lacem ent pro ceeds w i t h in tro ducin g new k nots until a t ermi nat i on cr i ter i a is reach ed. Ho wever, t hi s stepw is e jump placement strategy has t he d i sadvantage t hat t he minimizer that l eads t o the smallest possible value o f t he fu nctional might only be achievable by st epwis e removal of jumps. Theref ore i t may be necessary to place a jum p at every l o c at i on, a nd perfor m i t erat iv e jump removal t o attempt to lower the f u nct i o nal . S imil arly, because t he non-zero coun t l o ss is non-co nvex, the fu nc t i onal is not conv ex e i ther, a nd there m ay be a nother so luti o n that l o wers t he fu nctional further. Therefore, in so me c ircumstances, a l ternat in g between i terat iv e k not pl acement and iterative k not rem o val may s uc ceed in find ing a better solution than either plac ement o r rem oval alone. In fact, minimizing the functional is a co mbi nato rial o ptimi z at i o n pro blem , because the number o f knots is a n in teger quant i t y . Theref ore, it ca n be addressed by t he w ide arr ay o f t echniques that hav e be en devel oped for such problems ( Papadimit riou and Stei g li tz, 1998) . The j u mp pe naliz at i on methods in t ro duced ab o ve have a nother use f ul in t erpret ati on w here t he PWC signal represen ts a d iscrete -tim e sto chas t i c pro cess t hat can ha ve both po sitive and negat ive jumps of any height. The count numb er o f a Poisson proce ss is a n impo rtan t special case o f this w here t he jumps are a ll of t he same height and pos i t ive o nly : t hen t he time interval betwee n j umps is e xponen t i ally d istr ib ut ed. In t hat case, t he pro ba bili t y o f o bta ini ng a jump i n a ny o ne d is cret e -tim e sampling interval is just , wh ere is t he sampli ng interval and is t he m ean t im e bet ween jum ps. I n t he cor resp onding discrete -t ime sett in g, the number of j u mps is a random variable that is Bernou ll i d i str ib uted with para m et er . Then t he appro pri ate choic e o f regularization para m et er i s . At o ne extr em e, w hen , t hat i s, a j ump is exact ly as likely as no jump in any o ne sampling in t erval, this factor is zero , so t he number o f jump s p lays no r ole in t he minimi zer of t he functional, which is just t he input si gna l . At t he other extreme , when , t he m ean time between j u mps becomes infi nite, so a j ump in a ny in ter val becomes im probable, and . This f orces t he number of j umps to zero when minimizing the functional. 5.2 Regression splines and coordinate descent In this sect i on we demonst rate t he in t im ate co nnection between total va riation regularization , w hich is o f maj or importance in P WC de no isi ng app lications and spli ne regression , and how a sim p le new solver can be applied to find t he so l ut i on. For t he special c ase o f tot al va r iation regu l arizat i o n, f or whi c h , the f unct i onal beco m e s: (5.3) whe re is t he (e ntry wise) vector 1 -norm, and is the first d if ference matrix as de fi ned in (4.26). This is shown to be equivalen t to the f o ll o wing f unct i o nal (Kim et al . , 2009) : (5.4) whe re is t he (entrywi se) vector - norm , to be minimized over the new variables (t hes e new variables are spline co effici ents related to t he original variables , see bel ow). The ma tr ix has t he f or m : (5.5) which conta in s a discrete, 0-degree (co ns tant) s p li ne in each r ow, wi th a knot pl ac ed at posi t i ons respectively . T his d em onst rat es that tot al variation denoising is also a LA SSO regression pro bl e m using a set o f constant spline s a s basis functions, and t he aim is to pr oduce a sparse app roximation with as few non-zero knot coefficients as possible ( Steidl et al., 2006; Kim et a l ., 2009) . The ge neral LASSO regressi o n pr oblem has bee n st udied e xtensively in t he stat istics and machine learning li t erat ure, and t here are a l arge number o f so lve rs t ha t can be used t o find t he only minimu m o f t he functiona l abov e. These include subgradient t echni qu es such as Gauss-Seidel a nd grafting (Schmidt et al., 2007) , but a l so methods t hat use a sm oot hed appro xim at i on t o t he 1 -norm including E psL1 , log-barrier , SmoothL1 , and expectation-maximization (Schmidt et al., 2007). Refor m u lat i o n as a co nstrain ed least -squares pro blem leads to interior-point , sequential quadratic programming and variants (Schmidt et a l ., 2007). However, com putat i ona l savings mi ght be m ad e by exploiting the special structure of thi s tot al var i at i o n regularization problem . Minimizi ng t he generalized funct i onal with re spect to varia t i on in o ne o f t he var i a bles alone (when the others ar e held fixed), can so m et im es be conducted analy t ically, o r is simple to compute approximately. T his observ at i on has lead to a number of ver y simp l e coordinate de scent so lvers f or regularization pro blems (Frie dman et a l ., 2007; Schmidt et al ., 2007) . It h as been shown that such co ordin ate descent so lvers ar e minimi zers f or f unct i o nals o f the form: (5.6) whe re t he li kelihood func t i onal t erm on the left is conv ex a nd diffe rent i able, and the regularization functions are convex. The regu larization t er m displayed here is separable : but t he f unct i onals in t his pap er do not have separable regu l arizat i o n t erms. Speci al adapt at i o ns are t he refore requi red in o rder to apply coor dinate descent to the total variat i on regularizat ion pro blem , for e xam ple see Friedman et al. (2007). This inv o lves ident ifyi ng the conditions under which groups of variables need to be merged a nd varied to gether. However, w e make t he observ at i on here t hat t he LASSO sp li ne regressio n problem o btained f ro m the tot al variation regu l ar izat i o n method is separabl e, and t ha t t he spline regressi on matrix above has a particularly s imple f orm. T his all o w s us to devel op a s imple coo rdinate descent solver for tot al vari at i on regu larization t ha t avo i ds t he co mplexi t y o f detectin g and gro upin g var i a bles altoget her. In particular, not e t hat t he o ri ginal variables ar e o btaine d using where are t he sp li ne coe fficien ts, so that each elemen t is j u st t he cum ulative sum o f the spli ne coefficients: (5.7) Simil arly, go ing the other way , t he spline coe ffici ents can be o btaine d fro m the ori g inal v ar iabl es using successive differenc es: (5.8) with . Also, note that at , t he original variables are equa l to t he i n put si gna l , t heref o re the descent algor i t hm can be usefully ini t iali sed w i t h t he successive differences of t h e input s i gnal. It is usefu l t o unders tand t his descent al go r i thm as a t wo-step process, (1) an update step : (5.9) f o ll o wed by (2) t he shrinkage step : (5.10) with ini t ial conditions , , and , where . Normalization o f t he sp li ne m atrix is requ i r ed t o preven t i t erat es from diverging. T hese steps (1), (2) are repeated until converge nce. The o ri ginal variables at co nv erge nce can be recovered us ing . We c an understand (5. 9) foll owed by (5.10) as the regres si on c oeffi cient obtain ed by regressing t he error in ( 5.9) onto t he -th variable (Friedman et al . , 2007). The shrinka ge t erm (5.10) i s j ust t he sol ut i o n to the absolute penali zed l east -squares regressi o n ( 5.4) if we fi x all the variables except the va r iable . Usin g t he o bs ervat i ons about t he m atrix above, the update step can be sim p lified considerably: (5.11) The expanded form of t he expressi o n o n the r i g ht shows t hat t he term in can be pre-computed, whi ch ca n l ead to further com putat i onal sa vings . Alt hough simple, t his co ordina te descent a l gor i thm requ i r es a large number of i t erat ions to reach conv ergence, parti cularly f o r s mall , becaus e o n each iteration, the vari able do es n ot chan ge very much. Therefore, the speed o f conv ergence i s part ly depe ndent upon the s i ze o f . Furtherm ore, t he i t erat es bef ore reachin g convergence do not represent t he sol ution at sm aller values o f , because is fixed dur in g t he i terat i o n. Thus, i t erat ion o f t his algor i t hm does not o btain the regula rization path auto m atically, as it does for t he piecewise linear r egularization pat h f ollow er f or t he same pro blem (Ho fling, 2009). F or some applic at i ons, where we want the who l e set o f so l ut ions when varying , this co ul d be a drawback. We note here t hat a r el at ed approach to PWC den o ising was proposed in dependent ly in t he geo scien ces li t erat ure (Mehta et al ., 1990). 5.3 Robust total variation regularization an d linear programming Tot al va r iation regu lari zat i o n is a useful t echnique if t he no i se d istr ib ut i on is Gaussian. If t here are o utli ers in the nois e, t hen we c an adapt t he tec hni que t o increas e it s robustness by replacing t he square likelihood loss with the abs o l ute loss in stead. The ro bust total variati o n funct i o nal beco m e s: (5.12) which can be cas t as a least absolute regres sion pro bl em: (5.13) whe re is t he identity matr ix, is t he zero matrix , is t he vecto r 1-norm , and is t he fi rst differenc e m atr ix as in (4. 26), but wi t h t he last row all zero . This is in t he f orm o f a linear program (a linear pro bl em w i t h linear inequa li t y co nstr ain t s), which is so lvable using, for e xample, simplex or interior- point m ethods (Bo y d a nd Va ndenberghe, 2004; Ko enke r, 2005) . To o ur know l edge t hough, specialized f ast o r regularization pat h-foll o w ing methods for t his r obust tot al var i at i on r egularizat i on pr oblem do not exi st, as the y do for non-robus t tot al var i at i on regu lari zat i o n ( but see Koenker et al . (1994) for related i deas, and Darbon and Sigelle (2006) f or an appro ach in the ca se w here t he signals are integer r ather than rea l , and a ls o references therein). 5.4 Weighted convex clustering shrin kage Convex c lustering shrinka ge has an ad vantage o ver m ean shif t and ot her c l ust erin g methods, t ha t the function a l is co nvex, so t here exists a unique so l ut ion t hat minimizes t he funct i onal and i t can be f ou nd by fast quadratic pro gram ming a lgor i t hms su ch as t he in t er i or point t echni que. However, t he me thod can be highly sensi t ive t o the ch oice o f regularizati on par a meter : t he re i s t ypi cally o nly a s m a ll r ange o ver which the so l ution t ransi t ions f ro m e ver y sample bel o nging t o its o wn cluster, to t he eme rgence of a s ingle cluster f or a ll sa mples. To reduce this se nsi t ivit y and expand t he u seful range of t he regu l ar ization para meter, a simple pro posal is t o f ocus the clusterin g only o n t hose samples in t ha t are ini t ia lly close to each ot he r. Sam p les that are far apart ini t ially cann ot t herefore become clustered to gether. Thi s l eads t o t he foll ow ing adapt ation t o t he co nv e x c l u stering sh rinkage functional : (5.14) This method ret ain s t he convexi t y pro perti es o f t he o riginal , because t he we ights are based o n t he input sign a l which is fixed. It is t heref ore a m e nable t o quadratic pro gramming. The parameter controls t he exten t o f t he value kerne l , t hat is , how c l o se t he input sa mples need to be to be subject to sam ple d istance re duction. As bef o re, a small regularizat i on parameter c onstrains the sol ut i on to be sim ilar t o the in put s i g nal. 5.5 Convex mean shift clustering The use o f input- si gnal d ependent weights for enhanci ng t he usefulness o f a P WC method presented above is a tr i ck t hat can be applied m ore w idely . Fo r examp l e, mean shif t c lus ter in g is not c onvex , b ut it is po ssible t o pro duce a sim p le adaptat i o n that is convex: (5.15) f or which t he associa ted infl ue nce function i s . This shou ld be co ntrasted with the infl ue nce f unct i on f or mean s hif t c lustering w i t h abso l ute ( rather t han square) loss w hich is . To see why t hi s new m ethod can be considered a convex versi o n o f mean shif t c l ust er in g, consider t hat a solver f or t he descent ODE s for this method would be ini t ialized wit h , such t hat, t he infl ue nce function for t he first iteration of t his so lv er is , and this co inci d es exactly w i t h the influen ce funct i o n for (absol ut e) mean s hif t. The adapt ive Eu le r so lvers for t he abso l ut e mean shif t a nd conv ex mean shift are, respectiv ely: (5.16) (5.17) (Not e: wi th t he square l os s in classical mean s hif t in (4. 16), t he adapt iv e so lv er s implifies t o t he i t erat ed mean, as s hown ear lie r). O ne w ay of understanding t he r e l at i o nship to conv ent i o nal mean shift is that t he val ue kerne l f or co nv ex mea n shif t do es not chan g e dur in g iterations , w herea s for m ea n shif t t he ker nel weights are re - computed on each i terat i on. 5.6 Soft mean shift total variation diffusion and predictor -corrector integration We have s een a bove (S ection 4.6) t hat cl ust ering methods have the P WC pro perty in t erms o f leve l-sets, and total variati o n r egularizat i on in t erms o f splines. These d iffe rent methods have cert ain d is adva ntages. T he l e vel - set representation is descr ibed in t er ms of levels , and this de ter mines t he l o cat ions o f the jumps. A co nse quence of this is t hat rapid changes in the mean o f the no ise can cause rapid, spur i o us t ransitions between levels . O n the other hand, t he spline r epresentation sets t he locat ion of the jumps, which in tur n deter mi nes t he const ant l eve ls . Theref ore, t he spline m ode l is vulnerable t o gradual , systemat i c c hanges in t he level o f co ns tant regi o ns due t o chan ges in the mean o f t he noise, for ex ample. Clust erin g methods such as mean s hif t pro vide constraints on t he levels of co nstant reg i ons a nd t hese co uld be u sed to all eviate t he weaknesses o f t ot al va r ia t i on a lgor i t hms, b y contrast, t he t em po ra l co ns tra in ts buil t in t o tot al var i at i o n a lgor i t hms cou l d he lp pre ven t spur i o us transitions o f clusterin g methods tha t are in sens i t iv e to t em po ra l seque nc e. Here we show t hat i t i s po ssible to synthesi se the two represen tat i ons u sin g a novel P WC method t hat combi ne s the g l o bal be havi o ur of mean shif t c l u ster ing with t he sequ entially l o cal behavi o ur o f t otal var i at i o n regularization, using the foll o w ing func t i onal: (5.18) Here, is a kernel para meter t hat determi nes the e ff ect iv e “precisi o n” o f t he mean s hif t: if i s large, then t he sol ut i on ca n different i ate small pe aks in t he a m plit ude di st r ib uti on, if small, t hen o nly large peak s ar e det ected. Because o f t he for m o f ( 5.18), we ca ll t his method sof t mean shift total variation diff usion . The regu l arizat i o n parameter determines t he r ela tive inf luence of the tot al variat i on regu l ar izat i o n t erm : if s mall , t hen l o cally sequential r uns of close values have li tt le influence o ver t he solution; if large, t hen m o des in t he a m plitude dis tr ibution can be broken up in order to find sequential cons tant runs instead. Al t hough not neces sarily t he best or m o st effici ent so lver, f or t he purpo ses of ill ust rati on we pro pose a t wo - s tep, midpoint predictor-corrector integrator for the resul t in g descent ODEs (I serl es, 2009) : (5.19) (5.20) with ini t ial co ndi t i on . Usin g this integrator, we obtain the foll o wing so lv er for t hi s new P WC denoising algorithm : (5.21) (5.22) At t he boundaries we have for and for t he tot al variat i on part o f t he expression a bove. Al t hough t he r egularizat i on term is not dif ferentiable e verywhe re, t his fini t e difference solver is r easonably stable f or sm all , and experience shows t hat conv e rgence to a useful , approximate so l ut i on is possible w i thin a few hun dred i t erat i ons. 6. Numerica l results and d iscussion In t his sect i on we d iscuss t he results o f applying t he e xis t in g a nd new me thods and solvers o f t his paper t o typical PWC de noisi ng pro bl e ms. First, we focus on accurat e recovery . We applied eac h method to a synthetic, uni t st ep signal, corr upted by additive Gaussian noise. Method parameters were o ptimi zed by han d to achieve the o utput t hat is c l o sest to t he known step signal. We first test ed the ability o f t he methods to r ec ove r the step whils t i gnor in g t wo is o l ated “out liers” that co ul d be incor rectly ident ifi e d as level t ransi t i o ns, t he resu l t s are sh ow n in Fi gure 3. In the case o f outliers, the new j u mp pena li z at i o n and mean shift tot al variat ion diffusi o n methods (3k,l,j ) appear to produce t he m ost accurate r esul ts. Me an shift and bilater al fil ter ing are able to r ecover t he step ( 3d,h), but ar e unable to i gnore t he o utli ers. K - means can ignore t he out li er s (3 f), but exhibits an incorrect tr ansi t io n near t he lea ding step edge, because a sample near the edg e i s c l o ser in value t o t he height o f t he st ep. Tota l variat i on regularization and the ro bus t tot al variat i on regu la rization (3b, i ) cor rectly ignore the o utli ers, but t end to identify many small, spur i ous edges ; this is tr ue als o of i terat ed median fil ter in g (3a). Alt hou gh t hes e spur i ous jumps in total variation methods ca n be remo ve d by furt her in creasing the regular iz at i on parameter, t his will be at t he expense o f intro ducin g very s ignifi cant bias in t o t he estimate of t he level o f the constant regi ons ( essentially, this is a consequence o f the piecewise lineari t y o f t he regu l arizat i o n pat h). There is, however, no co rrespondin g parametric control over the i terat ed l e ngth 3 median fil t er, a nd clearly convergence on a root si g nal t ha t has many spurious jumps. Soft m ean s hift, co nv ex mean shift a nd weighted convex cluster in g s hrinkage (3e,n,m ) fail to ignore t he o utliers and also show so me spurious t ransi t i o ns bet ween leve ls. The o bjec t iv e st ep -fi tt in g (see Table 2) method (3c) also places jumps at t he o utli ers, and i n ot her, spuri ous l o cat i ons. Co nvex cluster in g sh rinkage fails to i dent if y the step at all and is also influen ced by t he outli ers (3g). Up unt il now, we have assumed that t he no is e is stat i stically independent, but in practice, i t may have some kind of cor relation. We t heref ore devised a not he r c hallenging t est: reco ver a u ni t step s i g na l w i t h linear dr if t in t he mean o f t he noise as a co nf ou nding facto r, see Figur e 4. No w, we can see t hat mean s hif t , so ft mean shif t, K - means a nd mean s hif t t ot al variat i on d iffusion (4d,e,f,j) are able to recover t he st ep an d ign ore t he dr if t ver y effectively . T hese methods are success f ul in t his case because t hey are largely insensi t ive t o t he sequent ial or de rin g o f the i nput sa m p les (wi t h t he exception of mean shif t tot al v ariat ion dif fusi o n); t hey are simp ly conv erging o n pe aks in t he d istr ib ut i on o f t he input sample t hat t urn o ut to be la rgely u naff ect ed by t he dr if t . Jum p pe nalization, o bjective step -fi t t ing, and bilateral m ethods (4k,l ,c,h) are unable to i g nore t he drif t , but pro duce the smoothest so l ut ions. Weighted convex cluster in g shrinkage and co nvex mean shif t (4m,n) are not confus ed by t he dr if t , but have so m e spur i o us edges. T otal variation regu larization is a lso adversely a ffected b y the dr if t a nd in t ro duces a sm all, incorrect j ump, but i s apprec iably bett er t han ro bus t total variation regularization (4b,i ). Arguably the wor st perf or min g methods are i t erat ed m edian filter in g and convex cluster in g sh rinkage (4a,g). Nex t, in o rder to understand t he efficiency o f d if ferent m et hods and so lv ers, we app ly a representat ive select i o n of i terat iv e so lvers to the ba sic t ask of noise r emoval fro m a s hort, unit syn thet i c st ep corr upted by Gau ssian noise. Figure 5 shows the resu l t ing out put si gnal, and the ite ration path o f t he so lver: t hat is , t he cur ve s tr aced out by t he samples in the so l ut i on as t he i t erat ions pr oceed. This i s a p l ot of the i terat i o n number o n the horizontal axis , against t he val ues o f the sa mples o n t he vertical a xis. T he d istance reduct i on pr in ciple i s apparen t in the out put as the so lv er iterates to wards convergence to a minimum o f the associated f u nct i onal. It is also possible to discrimina te me thods t hat use onl y value kern els such as mean shift and K - means, f ro m method s that use l ocal sequence ker nels ( for example, t ot al variati on regularizat i on and bila tera l filter in g) . The for m er can o nly merge t o gether sa mples t ha t are close in value, t herefore, t he iterati o n p at hs do not in tersect . On the other hand, t he l att er can constrain those t hat are se que ntially cl o se t o m er ge together, and t he i terat ion paths can in t ersect. In t erms o f t he number of i terat i ons, the f o rward stepwise jump p lacement algori thm for jump penalization methods are t he m o st effective, co nvergin g o n a so l ut i on in t wo st eps (5f ). Ne xt, we fi nd kernel adapt iv e step - size E ule r in t egrato rs f or mean shif t , K - m eans and bilatera l fil ter ing t aking at m o st fiv e st eps (5b,c,d). The f orward linea r regu larizat i o n path f o ll o w in g so lver for tot al va riat ion regu lari zat i o n is next, t akin g 10 steps to reach the u nique opt im u m sol ut i on ( 5a). W eighted conv ex c lustering shrin kage w i t h n on - adapt ive step-s i ze Euler in t egrat i on t akes so me 300 steps t o conv erge (5g). Lastly, t he t wo -step m id-poin t predictor- c orr ec tor in t egrat or for mean shif t t ot al variatio n regul arizat ion conv erges to a s olution af ter ab out 500 i terations (5e). Analy t ic minimizers f or t he generalized fu nctional (3. 1) are o nly available in the ca se o f pur ely li near systems (simple quadrat ic loss funct i o ns). Therefore, numerical algor i t hms ar e requ i red generally . T he solvers descr ibed in t his paper are not nece ssarily t he most effici ent t hat coul d be applied t o each method. Co m paring solvers is complica ted a nd a fu lly r igor ous appro ach is beyo nd t he sco pe of t his paper. Ho wev er, t here are so me so me gene ral o bs ervat i ons that can be made. When t he l o ss funct i o ns are co nvex and co mbined in co nvex co mbi nati on t his ca n be adva ntageous because then i t is k nown t hat t here i s o ne unique minimizer for t he func t i onal, g iven f ixed para meters. T his avoids t he unce rta in t y inhe rent to n o n-co nv e x m et hods, wh ere we do n ot know whether the s ol ut i on obtain ed is t he minimi zer asso cia ted w i th t he s mallest possible va l ue o f the functional or not: t he re m a y be a be tter sol ut i on obtaine d by start in g the so lv er f r o m d ifferent ini t ial c onditions. Thi s m ay requ i re us to run t he solver to conv ergence many t imes t o gain conf idenc e t hat t he r esul t is t he best po ssibl e. Ha ving s aid t his, whe ther it matters t hat t he so luti o n is o ptim al depends o n pr act i c al c ircumstances. For m a ny P WC de noisi ng methods t he functionals are convex, and in t er m s o f co m putational co m p lexi t y , in t er i or po in t a l gorithms are very e ffi cient (Boyd and Van d e nberghe, 2004). If t here are o nly a f ew j u mps t hen forward stepwise jump p lac ement, as descr ibed in Se ct ion 4.1, i s ver y effi cient. Ho weve r, we ca nnot know whether a se quen ce of jum p s placed by t his f orward -o nly a lgor i t hm is t he best because the ju mp penaliza t i on functional is non -convex. Theref ore, t he same issues a bout uncertain t y in t he optimali t y o f t he resu l t s occur as w i th any no n-convex fu nc t i onal . The scope f or stepwise j ump placement algorithms is qu i t e na rro w, becaus e it requ i r es a n eas ily so lvable likelih o o d functi on given t he fixe d spline knots. Al t hough having the w ides t scope o f a ll , we have s een t hat fini t e d ifference methods for t he descent ODEs can take hun dreds o f st eps to co nv erge, and are t heref ore rel at iv e ly ineffi cient. However, the simple measure o f adaptin g t he st ep-size can cut t he number of iterations requ i r ed to reach co nvergence e nor m ously, as we have seen f o r the m ea n shif t and other c lus ter ing meth ods. Sim p le fini t e differences are o nly pract ical t hen if m o d ifi ed w i th adapt iv e step -siz es o r som e other appro ach to speed in g up convergence . The scope for ( f o rward) piecewis e linear r egu lariza t i on path f o ll o wers f o r PWC deno i s ing turns out to be reasonably wi d e (Rosset and Zhu, 2007), and i f path li near i t y can be dro pped, ev en w ider (Rosset, 2004) . Theref ore, if t he full regu larization p ath o f so l ut i ons is requ ired, pat h f o ll o wing methods can be e ffic i ent, as we hav e seen for total va r iation regularization. To o ur knowle dge, backwa rds pat h fo ll o w in g h a s only bee n investi gat ed for total variat i o n regularization. Coordinate descent i s probably the least eff ici ent in terms of n umber of iterations and requi res separabil i t y o f the regularization ter m, which do es not apply in g enera l t o t he P WC deno ising funct i onals in this paper . However, the update o n each i terat ion is very simple and t his may yet t urn out to be co mpe t i tive wit h other so lvers appli e d whe re separability can be show n to hol d. 7. Summary , related and fu ture idea s In t his paper, by present in g an extensively ge neralized mathema t i cal framewor k f or perf o rming PWC n o i s e removal , s everal new PWC deno ising methods and as soc i at ed so lv er a lgori thms are pro posed t hat at tempt to combine the advantages of e xisting methods in new and u sef ul ways. Numerical test s on syn t het i c dat a co m pare the reco very accuracy and e fficiency o f t hese e xisting and novel methods head - to - he ad, fi nding t hat t he new mean s hif t tot al variat ion deno ising me thod is e ffectiv e u nder c hall e ng ing condit i o ns where exist ing methods sh ow s i gnificant deficiencies. In o rder to devis e t hese new P WC deno isi ng methods, this study h as pr esented a g eneralized a pproach to unders tanding a nd per for mi ng no i s e re m o val f ro m piecew is e co ns tant s ignals . It i s based o n ge ne ralizing a substantial number o f e xisting methods, found t hrough a w i de arr ay o f d isciplines, unde r a gen era lized functional , w here ea ch method is asso ci ated w i t h a special case o f t his functional. T he g e ne ralized funct i ona l is constructed fro m all possible differences o f sam ples in t he input and out put si gnals a nd thei r indices, over whic h sim ple a nd co mposite l o ss functions are placed. PWC o ut puts are obtained by seek in g an o ut put s i g nal t ha t minimi zes t he funct i o nal, whic h is a summat i o n o f t hes e ker nel loss funct i ons. T he t ask o f PWC deno isi ng is then for m a lized as t he problem o f recovering e i ther a co mpa ct co ns tant spline or level- set descr ipti o n o f t he PWC s ignal obscured by n o i se. Minimi z ing the f unct i onal i s seen as c o ns tr aining the diff ere nce be tween appropriate sa mples in t he input s i gna l . A r ange o f so lve r a lgor i thms for minimizing t he fu nc t i onal ar e investi gat ed, through whi ch we were able to provi de som e novel observat i ons on exis t in g methods. Whils t the st ructure o f t his paper has e ncouraged us to m ake as inclusive investigation a s po ssibl e o f PWC denoisin g methods, there are many o t her m etho ds that ca nnot b e ass oc i at ed with s pecial cases of t his gene ralized f unct i ona l . Below, for co m p leteness, we d iscuss the co ncept ual o verlaps and re lati o nships between some of these other me thods that get si g nificant use in practica l PWC deno i s ing appli cat ions . 7.1 Wavelets Wavelet techniques are u biqui to us, generic m ethods for s i g nal analysis, and t heir use in ge neral no ise r emoval has been co mprehensi vely explored ( Mallat a nd Hwang, 1992 ; Ma llat a nd Zhong, 1992; Catt ani , 2004; Ma llat, 2009). Co nn ect ions between wavelet t echnique s and so m e o f t he smoot hing methods de scribed in t his paper, in particular tot al variation regu la r i z ation (St ei dl e t al ., 2004), have bee n established. Wav elet methods ar e powerful for many reasons, here we j u st m e nt i o n a f ew o f t he basics: including (a) t he exis tence o f an algorithm with com put at i o nal co mplexi t y for t he forward and reverse wavelet t ransf o r m s in t he d i screte-t im e sett ing (Malla t, 2009); (b) t he statis t i ca l theory o f wavelet shrinkage t hat expl o i t s o rthonorm ality o f the wa ve l et basis to perf or m noise re m o val us ing very simp le, coefficie nt -by-coe ffi c ient ( separable ) nonlinear tr ansf o r mations o f the wavelet co effi c ients ( Candes, 2006); a nd (c) many signals, in t he wa velet basis are sparse , t hat is, a large pro por t ion of t he coefficients are effect iv ely zero making the wavelet r epresen tati on ve ry co m pa ct. Wavelet methods requi re t he c hoice o f basis, a nd f or PWC denoising, t he Haar basis , itself co m po sed o f PWC functions, has been suggested m a ny t im es in t he w ider li t erature (Cattani, 2004; Taylor et al . , 2010) , a l though it is not t he only bas is t hat has been propo sed. Removing no i s e t ypically requi res re m o val o f the small - scale deta il in t he s ignal . The r esul t of re m oving t his det ail is t hat t he t ime- localisation o f t he re maining la rge scale P WC basis f unct i ons is po or, s o t ha t t he j umps in t he PWC signal cannot be accurately l ocat ed and t end to become misali gned t o the l ocat i o ns o f the jumps in P WC bases instead. Furt herm o re, shrinka ge cau ses “oscillations” nea r jumps that are not ali g ned with t he j u mps in t he basis; oscillations th at are s imi la r in character to t he Gibb ’s phenomen a observed using linear l ow -pass fil t e ring. Thes e issues a re an unavo i da ble consequence o f t he Heisenberg un cert ain t y inherent to tim e - f reque ncy analys is (Ma llat, 2009). The P WC deno i sing methods described in t his pap er are not bas ed o n t im e - f requency analysis. Per haps because of t his, histo ri ca lly , wavelet -based appro aches, and t he k in d o f methods d i s cussed in this paper, have developed quite separately (Candes and Guo, 2002). T he re are, however, some po in ts o f co ntact t hat hav e addr esse d how to prev ent wav elet o scill at i o ns n ear jumps, yet retain so me of the des i r able co nceptual and computat i ona l pro pe rti es o f wavelet methods. The li t erat ure o n this topic is ver y extensive and we r estr i ct o urselv e s to a f ew o f the o ve rlappin g concepts t hat are of direct re l evance to the PWC methods an d solvers discussed in this paper. If we are prepared to drop o rthogonali t y, then we lose separabi lity, but t his do es not m ea n that we l ose t he appeali ng concept of coeffi c ient sh rinkage: in fa ct, in the r egressi o n s pline approach to total va riat ion regularization d is cussed a bove , t he use o f t he absolute f unct i on app lied as a regu larizer o ver t he co nst ant sp li n e coefficients can be see n as non-separable shrinkage in the spline basis . T he so lv er is m ore com p lex tha n separable s hrin kage (we now have to so l ve a L ASSO pr oblem), but t he j umps ( spline knot s) are no l onger restricted by H eisenberg u ncertainty and can be placed precisely at t he j umps in t he P WC signal (Ma ll at, 2009) . Al t er natively , Ca ndes and Guo (2002) and others (Chan and Shen, 2005) disc uss how the wavelet reconstruction with absolute l oss o n the wa velet co eff icien ts can be aug mented w i th t he tot al vari at i o n o f the wavelet reconstructi on to attem pt to mi n imize the o scillati ons near d iscont in u ities. T he s o l ut i on can n o l onger be obtained u sing separable shrinkage, b ut t he o rthogonali t y a nd pot ential sparsity o f t he wavelet tr ansf o r m is retained. A f inal e xample is that o f ite rated tran slation invariant wavelet shrinkage (St eidl et a l . , 2 004), which has bee n shown to hav e s imilar perfo rmance to total variati on r egularizat i o n, but t he co nn ect ion is somewhat less di rect. 7.2 Hidden Markov m odels ( HMM s) Hidden Markov models (HMMs) p lay an import an t role in pract i cal PWC de noisi ng applicat i ons (Go dfrey et al., 1980; Chung et al . , 1990 ; Jong- Kae and Djuric, 1996; McKinney et a l . , 2006) . It i s im po rt ant therefore t o unders tand t he re lationships between t he ge ne ralized methods pro posed in t his paper and HMMs. T he li t erat ure on the very many var i ants o f H MMs is extens ive ( Blimes , 2006), but we focus here on one o f t he most popu l ar HMM v ar iants that h a s s een r epeated us e in PWC deno i s ing – the dis crete-state HMM w i t h continuous, Gaussian emission probabilities . This confi gurat i on has deep similari t i es to the (hard o r soft) K -m ea ns clusterin g a lgor i t hms d is cussed in t his paper. T he similari t y e merges from t he r elati ons hip between K - means clusterin g and (Gaussian) mixture density modellin g . In this HMM var ian t, t here are dis t in ct states to the u nderlying Markov chain , each asso ciated w i t h a s ingle Gaussian distribution, parameteris ed by means and var i ances. If t he underlying cha in is in stat e at index , t he n t he o utput sam ple fro m the no i s y signal i s dr awn from a Gauss ian w i th mean and vari ance . T he Markov chain is para meterise d by addi t i onal t ransition density and initial probability variables , t he t ransi t i on densi t y det ermi ning t he stati st i ca l dependence of upon and earli er states if necessary (B limes , 2006) . The go a l o f f i t t ing the H MM t o t he noisy signa l is to find t hese t ransi t i o n and ini t ial pr obabili t ies, a nd the parameters o f t he Gaussian s as soc i at ed wi th each st ate. If, however, is inde pende nt o f , t he n t his HMM variant collapses to a Gaussi an mix ture de nsi t y mode l (Rowe is an d Gha hram ani, 1999) , where t he goal o f fi t t ing is t o determine t he para meters o f t he Gau ssians alo ne. This is t y pically so lved us ing e xpectation-maximization (EM) method ( Hasti e et al., 2001) . There are t wo st eps t o t his method, the E-step : in w hich t he as signment of each index to each st ate is deter mined, and the M-step w here the Gauss ian parameters are re -est imated using the assignments. In this paper, t he adaptiv e st ep- si ze Eu le r in tegrat or applied to t he K -means algorithms can be seen as a concatenation o f t hes e t wo steps, in t he special case where t he variances o f t he Gaussians are fixed. T his aris es because EM is equivalent to iterative, weighted mean a nd variance rep lac ement, t he we i g hts det ermine d by the stat e assi g nment. For so f t K -me ans, t he weigh ts are the pro babili t ies o f assignment to each state given the means and v ar iances f ro m t he pre vi ous i terat i on; for (hard) K -means, most probable a ssignments are u sed ins tead o f probabili t ies , so t he wei g hts are eit her zero or one. EM is has been adapted to the HMM case of mix tur e modelling, where depen ds o n . T he E-st ep bec omes m o re co m plex be cause ca lculating t he stat e assignment pro babi lit ies requ i res “trac in g” thro ugh all po ssible states up un t il index . Fortunately , conditional indepen dence o f t he Markov chain makes a considerable algeb raic s implifi cat i on o f t his assignment po ssible, in t he pro ba bilistic as signment case t he resulting me thod is known as t he Baum-Welch a lgor i t hm, t he m o st probabl e varia nt o f which is Viterbi o r seque ntial K-means training (Blim es, 2006) . The means o f t he Gau ssian asso ciated w i t h each st ate are anal o gous t o t he levels in t he P WC leve l-set model, and t his variant o f HMM w i t h continuous emissi o n pr obabili t ies has t he P WC pr operty if the number of states because t here will be many indices assigned sequent i ally to t he same level. This explains w hy discret e - state HMMs wi th cont in uous e mi s sion pro babili t ies are useful f o r gene ral P WC deno isi ng pro bl e ms. 7.3 Piecewise constant (PWC) ver sus piecewise s mooth (PWS )? The fact t ha t PWC signals are also piecewise sm ooth im plies t hat m et hods for no i se re m o val f rom piecewise sm oot h (PWS) signals can, in pr inciple , be applied to t he PWC denoising pro bl e m. Here, by P WS, we m ean a si gna l that has a f ini t e isolated set of d iscon t in uities ( j umps), and everywhere e lse t he funct i on has o ne o r many continuous der iv at iv es. The P WS no i se re m o val p ro bl e m has at tracted co nsi dera ble att ention , in p articular fro m those app lyi ng wave let analys is in the signal a nd image pro cessing co mmuni t ies ( Chaisin t hop and Drago tti, 2009; Mallat, 2009). For PWS signals, t he leve l- set model is no l o nger pars im o ni ous ( but see the stack or threshold decompo sition r epresentation t hat is o f cen tr al impo rtance t o morphol og i cal s ignal pro cessin g ( Arce, 2005)). The extensi o n o f t he 0 -degree sp li ne mode l t o higher degrees r equires piecew ise ( fi rst, second etc.) diff erent i ability, w here the s ignal to be recovered is continuous everywhere, howeve r, t h e PWC s ignals we r efer to i n t his paper are d iscontinuous at t he jump locati o ns. T he refore, the higher degree spline mo del is not compa ct for PWS signals e i t her. Here we d iscuss a s mall se le ct i on o f P WS methods t hat are notabl e for t heir inf or m at iv e overlap w i th the algor i t hms in this paper. Since no i se removal fro m s ignals t hat ar e smooth eve rywhere is a pr oblem for which the ru nning mean filter is well sui ted, adapt in g t he r unning linear filter to the existe nce o f a few isolated jumps is a natural sol ut i o n in many co ntexts. T his requires so me t echni que f or (e i t her implicitly o r e xpli c i t ly) d etect in g t he e xist en ce o f a jump. Many a lgor i thms t ha t pro vi de jump capabilit y to runni ng fil t ers ( not jus t t he running mean fil ter) expl o i t the concept o f data-adaptive w eighting , t hat is, some meas ure o f t he dis tance assoc i ated w i t h sa mples inside (o r outsi de) t he l ocal fil ter ing w indow i s u sed t o provide a measure of whether a d iscontin uity e xists w i t hin t he window. This measure the n c han ges t he l o cal we ight in g t o mi t igate t he edge sm oo t hi ng e ffect of filt erin g o ver the j ump. I n t his paper, those techniques t hat pl ac e a kernel o ver the t erm are usin g such dat a-adaptive wei ght in g. In t hi s co ntext, i t is inf or mat iv e to note t hat in t he limit when in t he bilateral fil t er formula , we obtain t he i t erat ed, runni ng m e a n fil ter of width , and wi th a sof t (Gaussian) sequen ce kernel, we o btain t he iterated running weighted m ean fil t er. Theref ore, o ne i teration o f the bilatera l f il t er can be viewed a s a ru nning we ighted mean f il t er, where t he we i g hts are chosen to fi lter onl y t hose sa mples that are c l ose i n v alue (Elad, 2002) . Simil ar ideas hav e been pr opo sed independe ntly i n many dif ferent dis ciplines. C hung and Kennedy (1991) describe a we ighted running mean fil ter with a w eigh t in g scheme t hat i s co ns tant but d iff erent in t he left a nd r i g ht si de o f t he w in do w around each sa m ple. T he we i g hts are inversely pro portional to a posi t iv e p ower of t he magni t ude o f t he difference between the mean o f t he lef t or ri ght sides o f t he w indow, and t he sample in t he middle o f the window. The weights ca n be co mputed ba sed o n sa mples o ut si de t he fil t er ing w in do w, and t he final out put o f the filter ca n be a summat i o n o ver running means o f differing lengths ( Chung and Ke nnedy, 1991). Runni ng fil t ers based on a variet y o f linear co mbi nat i o ns o f ra nk o rdered samples in t he w indow, such as the trimmed mean f ilter or t he double w indo w mo dif ied trimmed mean f ilter are conceptually similar and ver y usef ul f or PWS n o i se rem o val ( Gather et al . , 2006). The PWC den o ising al gor i thms in this paper are t heref o re closely related to some PWS algorithms, but the PWC denoisin g pro blem is dist inct. In part i cular, we present evidenc e here t hat t he PWC denoising problem is one for which inf or mat i o n acro ss t he who l e s ignal can be efficient ly exploited by co ns truct in g a co mpact l e vel -set represen tat i on, f or exam ple u sing t he fu ll pa i rwis e d if ferences in sample values in t he mean s hif t o r wei g hted conv ex cluster in g s hrinkage a l gor ithms . This ap pro ach wo ul d not be effici ent for PWS signals, because in between the jumps, a P WS s ignal is not gene rally co ns tant, and so do es n ot necessarily have a co m p act level -set descri pt i on. 7.4 Continuum approaches and nonlinear partial differential equations (PDEs) The ge neralized functional (3. 1) in t his paper is based on a pure ly d iscrete -time sett in g. Most real s ignals ar e continuous in tim e, but desp i t e continuous time b eing co m putat i onally inac cess ibl e (it usually is), t here are som e mathema t i cal ad vantages t o goi ng to a contin uous t im e m ode l o f the signal, e ven if t his has to be dis cret i sed later for co m putat i o nal reasons. The largest s ingle c lass o f co nt in uous-t im e P WC deno isi ng methods are t hose based o n nonlinear partial dif f erential equations (P DEs), and ha ve nearly all b een de vel o ped in t he image pro cessi ng literature (Chan and Shen, 2005) . I n t he limi t of infini te simal t ime increments , t he d iscrete-time, gene ralized functional becomes a do uble i n tegra l funct i onal instead. T hen, t he variational deriv ative o f t he functional w i t h resp ect to t he co ntin uo us -t im e o utput si g nal is a n Euler-Lagrange PDE, a nd i t w ill be nonlinear if it is useful for PWC deno i sing. So, i t is fairly easy to show that many , if not most, of the me thods in t his paper hav e an equivalent PDE f or m . Nu m er ical so lvers for this PDE wo ul d be very simila r t o num erical so lv ers for t he descent ODEs der iv ed ear li er . Pass ing t o t he cont in uu m also invi te s applicat i on o f Sethian’s co mputational level-set algorithm s that, in t he 1D s ignal case, wo ul d co rrespo nd t o techni ques f or e volving t he jump l ocat ions between the dis t in ct level-set s that com pr ise the PWC solution, as opposed to the levels (C han and Shen, 2005) . 7.5 Future directions The new methods a nd so lvers pr esented in t his pa per represent j ust a ha ndf ul o f directions t hat the generalized functional a nd so lv er descri pt i on suggests. C l ear ly, there are a ve ry lar ge number o f o t her possible methods t hat can be construct ed f ro m t he funct i onal co mponents we describe in t his paper, t hat are as yet u nexplored, t hat might be o f value in P WC de noisin g. Ho wever, det ermi n ing w hich o f t hese methods would have min imize r(s) with t he P WC pro perty, and in add i t i o n, admi t e fficient and re liabl e so lvers, w ill requ i re additional wo rk. We imagine one appro ach : a f o r m al axi o mati c s ys te m leading to t he scale-space equation has been d evelo ped to t he design o f nonlinear PDEs f o r im age a nalysis, t hat cons tr ains t hei r for m t o hav e u niversally use f u l pro per ties (Chan and S hen, 2005). It i s qu ite possible t hat s uch axio ms might be modified for PWC de noising purposes. The co ns equences o f suc h axioms co u l d be expl ored wi t h resp e ct to t he f unct i onal co m ponent s and t hei r in t eract ions w i t h t he so lv ers presented in t his paper , with a view t o asking what combinations lead to soluti o ns with the PW C pro perty . A ppendix To prove t hat t he 3 -poin t i terated me dian filter cannot raise the to t al var ia t i on o f t he signal , we examine t wo adja ce nt win do ws and apply a simple co mbi natorial argu m e nt o ve r t he in put si gnal , so t hat the t wo input win do ws have the val ue s , and t he t wo output windows have t he val ues and . Now, label as “inn er” values, and t he other two as “outer” values. The non - increasin g t otal variat i on co ndi t i on is t hat . Sin ce t he median operation se lec ts one o f t he values in t he input set, t here are f our diff er e nt cases to consi der. First, co nsi d er whe n bot h windows select t he same in put, i.e. , t hei r diffe rence is zero and t he co ndi t i on is sat isfi e d t ri vially . S imil arly t rivi al is t he case when t he two inne r va l ues are swapped, i.e. and , t he condition is sat i sfied at equa li t y. Thi rdly, if o ne of the windows selects o ne o f the inner values, a nd the ot her one o f the out er val ues, t hen it must be that the selected o uter val ue lies in between t he t wo inner values, and so is closer to eithe r o f the inner values than the inn er values are to t hemselves , sat isfyi ng t he condi t i on. T he final ca se i s w hen bot h o uter val ues are selected, but in t hat case t hey bot h lie in bet ween the inner values a nd so t he co ndi t i o n is aga in sat isfi ed. This pro ves that implying t hat t he m edian o peration appli e d to t hese t wo win do ws cannot increase t he t ot al var iation. T he final step in t he proof is to extend t hi s to t he e nt i r e signal: t he t otal variat i on over every pair o f ad jacent values cannot increase, so t he tot al variat i o n o ver t he enti re signal cannot increa se eithe r. Thus, 3 -po in t m edian fil t er ing can only either leave t he t otal variation o f a signal u nchan ged o r reduce i t after each i terat i on. References Arce GR (2005) Nonli near s i g nal processing: a st a tis t i cal approach. Ho boken, N.J.: Wi ley-I ntersc i e nce. Arias -Cast ro E , Donoho DL (2009) Do es Median Fil ter ing Tr uly Preserve Edges Bet ter T ha n L inear Filter in g ? Annal s o f Stati st i c s 37:1172 -1206. Blimes JA (2006) Wh at HMMs can do. IEICE Tra n sact ions on Infor m at i o n and S y st ems E89 -D:869-891. Bl oo m H J (2009) Nex t gene rat i on Geo stat i onary Operat i onal Enviro nmental Sate lli t e: GOES - R, the Uni ted States' ad vanced weather sent in e l . In: Re m o t e Sensing S ystem E ngineering II, 1 Ed iti o n, pp 7458 02 - 745809. San Diego, CA, USA: SPIE. Boy d SP, Vandenberghe L (2004) Co nvex o ptimiza t i on. Cambridge, U K ; New Yo rk: Cambridge Universit y Press. Candes EJ (2006) Modern statistic al est im ati on via oracle in equalities. Acta Numerica 15:257- 326. Candes EJ, Guo F (2002) New mul t iscale tr ansf o r m s, mi nimum t ot al var iati o n s yn t hesis: applicat i ons to edge - preserving im age reco nstructi o n. S i gnal Pro cessing 82:1519 -1543. Cattani C ( 2004) Haar wavelet -bas ed t echnique for sharp ju mps c lassificat i o n. Mathemat i ca l a nd Co m puter Mode ll ing 39:255- 278. Chaisin t hop V, Dragotti PL (2009) Semi-param etr i c co mpres si o n o f p iece wise- sm oo t h f unct i o ns. In: Proceedings o f the European Conf erence on Signal Processing (EUSIPCO). Glas go w, UK. Chan TF, S hen J (2005) I m age pro cessi ng a nd analysis : variat i o nal, PDE , wavelet, and sto chastic methods. Philadelphia: Soci et y for I ndus trial and Applied Mathem at i c s. Cheng YZ (1995) Mean S hif t , Mo de Seeking, an d Clust erin g. IEE E Tran sactions on Pa tt ern Analysis and Machine In te lli gence 17:790-799. Ch ung SH, Kenn edy RA (1991) Forward- Backward No nli near Filter in g Technique f o r Extracting S mall Bi o l og i cal Signals fro m Noise. Journal of Neurosci ence Methods 40:71 -86. Ch ung SH, Moo re JB, Xia L, Pr emkumar LS, Gage P W (1990) C haracterization of S ingle Cha nnel Currents Usin g Digital S ignal-Pro cessi ng T echniques Based on H idden M arkov -Models. Philoso phical Transac t i ons o f the Roy a l Soc i et y of London Series B- Biologic al Sciences 329:265 -285. Darbon J, S igelle M (2006) I m age r est orati o n with d iscrete co nstrain ed tot al va riat ion - Part I: Fast and exact optimization. Journal of Mathematical Imaging and Visi o n 26:261 -276. Dong YQ, Chan RH, Xu SF (2007) A det ecti o n s t a tis t i c f o r random- valued impulse noise. IEEE Transactions on Ima ge Pro cessing 16:1112-1120. Elad M (2002) On t he o rigin o f the bil at era l fil t er a nd wa ys to improve i t. IEEE T rans act i o ns o n Image Processing 11:1141-1151. Fried R (2007) O n the ro bust detection o f edges i n t ime s eries filtering. Co m putat ional Stat is tics & Data Analysis 52:1063-1074. Friedman J, Hast i e T, Hofling H, Tibshi ra ni R ( 2007) Pathwis e Co ordinate Opt im izati on. Annals of Applied Statis t i cs 1:302 -332. Fukunaga K, Host etl er L (1975) T he es timation of t he gradient of a densi t y functio n, w i th applicat i ons in patt ern recognition. IEEE Transac tions on Infor m at i o n Theo ry 21:32 -40. Gather U, Fri ed R, Lanius V (2006) Robus t detai l-preser ving signal extracti on. I n: Ha ndbook o f t im e ser ies analy s is (Schel ter B, Win ter halder M, Timme r J, eds), pp 131-153: Wiley - VCH. Gill D (1970) Appli cat ion of a St atistical Zonat i on Met hod to Reserv oir Evaluat i on and Digit ize d - Log Analysis. American Association of Pet rol eum Geo l o gists Bulletin 54:719 - &. Godfrey R, Muir F, Rocca F (1980) Mo deli ng Seismic I mpedance w i t h Marko v-Chains. Geo physics 45:1351 - 1372. Hast i e T, Tibshi r ani R, Frie dman JH (2001) The e l e ments of st atis t i cal learning : dat a mi ning, inf eren ce, and prediction : with 200 f ull-co lor ill ustr ations . New Yo rk: Sprin ger. Hofling H (2009) A path algorithm for the fus ed lasso sign al appro xim at o r. In : arX i V. Iserles A (2009) A first cour se in t he numerical analysi s o f d iff erent i al equat i ons, 2nd Edition. Cambr i dge ; New York: Cambri dge University Press. Jong-Kae F, D juric PM (1996) Auto m at i c segmentat i on o f piecewise co nstant s i gnal b y hidden Mark ov m ode ls . In: St at i st i ca l S ignal and Arra y Pro cessin g, 1996. Proceedings., 8t h IEEE Si g nal Pr ocessing Works hop on (Cat. No.96TB10004, pp 283-286. Justusson BI ( 1981) Median fil t ering: stat i stical pro perti e s. In: T wo-Dimensi o nal Digital Signal Pr cessing II: Transf or m s and Median Filters (Huang TS, ed), pp 161 -196: Springer. Kalafut B, Vis scher K (2008) An o bjec t iv e, model- independent method f o r det ecti o n o f non-u nif o r m steps in noisy signals. Co m puter Phy s ics Co mm u nications 179:716-723. Ke rssemakers J WJ , Munteanu EL, Laan L, No e tzel TL, Janson ME, Do gterom M (2006) Assembly dynamics of microt ubul es at m o l ecular reso l ut i on. Nat ure 442:7 09- 712. Kim S J, Koh K , Bo yd S, Gorin evsky D (2009) L1 Trend Fil t er in g. SIAM Review 51:339-360. Koen ker R (2005) Quantil e regression. Cambridge ; New Yo rk: Cam bridge Universi t y Press. Koen ker R, Ng P, Portnoy S (1994) Quantile S m o othing Splines. Biome tr i ka 81:673 -680. Mall at S, Hwang WL (1992) Sin gularit y De tect i o n and Processin g wi t h Wavelets. IEEE Tran sactions o n Inf or ma t i on Theor y 38:617- 643. Mall at S, Zhong S ( 1992) Characterizat i o n of S ign a ls fro m Mu l t iscal e Edges. IEEE T ransa ct i ons o n Pattern Analysis and Machine Inte lli ge nce 14:710 -732. Mall at SG ( 2009) A wavelet to ur o f signal p ro cessing : t he sp arse way, 3rd Ed ition. Amsterdam ; Bosto n: Elsevie r/ Ac ademic Press. Marr D, Hildreth E (1980) T heory o f Edge -Det ecti on. Pr oceedings of t he Ro yal So ciety o f Lo ndon Ser ies B - Bi o l og i cal Sciences 207:187- 217. McKinney SA , Joo C, Ha T (2006) An alysis of si ngle- m o l ecu le FR ET traje cto ri es using hidden Marko v m o de ling. Bi ophysical Jour nal 91:1941- 1951. Mehta CH, Radh akrishnan S , Srikan th G (1990) Segm e ntation of Well L ogs by Maxim um - Likelih o o d- Estimation. Mathem at i ca l Geo l o g y 22:853- 869. Mrazek P, Weickert J, Bruhn A (2006) On Ro bust E s timation a nd Smoot hing w i t h Spat i al a nd T ona l Kernels . In: Geometric Propertie s f or Incomplete Data (Kl ett e R, Kozera R, N oakes L, W eickert J, ed s): Sprin ger. OLoughli n KF (1997) SPIDR on t he Web: Space physics in ter act ive dat a r es ource on-line a nalysis too l. Radi o Scien ce 32:2021-2026. Page ES (1955) A Test for a Chan ge in a Parameter Occurrin g at an Un known Point. Biometrika 42:523 -527. Papadimi t r i ou CH, St eigli t z K (1998) Co mbinatorial o ptimization : a lgor i thms and co mplexi t y. Mineol a, N.Y.: Dover Publi cat i ons. Pawla k M, Rafajl o wicz E, Stelan d A ( 2004) On det ectin g jumps in t ime ser ies: No nparametric sett in g. Jo urnal of Nonparam etr i c St a tistics 16:329-347. Pelckmans K, de Bra banter J, Su y kens J AK, d e Moor B (2005) C o nv ex Cluster in g S hrinkage. I n: PASCAL Worksh op on Stati st i c s and Opt imi zat i o n of Clustering. Perona P, Ma lik J (1990) Sca le-Space a nd Edge- Detection Us ing Anisotro pi c D iff usi o n. IE EE Tr a nsactions o n Pattern An alysis and Machine Intelligence 12:629 -639. Pi lizota T , Brown MT, Leake MC, Bra nch RW, Ber ry RM, Armi t ag e JP (2009) A m o lecular brake, not a cl utch, stops t he Rhodo bac ter sphaeroides flagellar m o t or. Proceed in gs o f t he Nat i o nal Academy o f Sc iences of the Uni t ed St ates of Ameri c a 106:11582 -11587. Rosset S (2004) Trackin g cur ved regularizat i o n opt imiz at i on so l ut i on paths. I n: Advances in Neural Infor m at i o n Processing: MIT Press. Rosset S, Zhu J (2007) Pi ecewise linear regu l ar ized so l ut i on paths. Annals o f St atis t i cs 35:1012 -1030. Roweis S, Ghahramani Z (1999) A unifying review of line ar gaussian models. Neural Computation 11:305 -345. Rudin LI, Osh er S, Fate mi E (1992) No nline ar Tot al Var iat i o n Based No ise Removal Algor i thms. Physic a D 60:259-268. Ry der RT, Crangl e RD, Tr ippi MH, Swezey CS, L en tz E E, Rowan LR, Ho pe RS (2009) Geol ogic Cross Sect i o n D –D’ T hro ugh t he Appalachian Basin from t he Findlay Arch, S andusky Count y , Ohio, to t he Vall e y and R idge Pro vince, Hardy Count y , West V i r ginia. I n: U. S. Geo l o g i cal Survey S c ientific Inves t i gat i ons, p 52: U.S. Geologic al Survey. Schmidt M, Fu ng G, Rosales R ( 2007) Fast o pti mizat i on methods for L1 regu lari zat i o n: A co m parat iv e stud y and two new approaches. Machine Learning: ECML 2007, Proceedin gs 4701:286- 297 809. Serra JP (1982) Im age analysis and mathematical m o rp ho l og y . London ; New Yor k: Academ ic Press. Snijders AM, Nowak N, Segraves R, Bl ackwo od S, Brown N, Conroy J, Ha mil to n G, Hindle AK, Hue y B, Kimura K, Law S, M y a mb o K, Pa lm er J, Y ls tr a B, Yue JP, Gray JW, Ja in AN, P in kel D, Albertson DG (2001) Ass embly o f microarra y s f or geno me-wide me asure men t of DNA cop y number. Nature Gen et i cs 29:263- 264. Sowa Y, Rowe AD, Leake MC, Yakushi T, Homma M, Ishijima A, Berry RM (2005) Di rect o bs erva t i on o f steps in rot ation of the b acter i a l flagellar motor. Nature 437:916 -919. Steidl G, Didas S, Neu mann J (2006) Spli ne s in hi g her order TV regul ar ization. I nternati ona l Journal o f Com puter Visi o n 70:241-255. Steidl G, Weickert J, Bro x T, Mrazek P, W elk M (2004) On t he equivalence o f so ft wavelet shrinka ge, tot a l variation diff u sio n, tot al variat ion r egula rizat i on, and SIDEs. Si am Journal o n Numerical An a lysis 42:686-713. Strong D, C h an T (2003 ) Edge -preservin g and scale-dependent pr o perties o f total variation reg ula r iz at i on. Inverse Pro bl ems 19:S165-S187. Tayl o r JN, Makaro v DE , Landes C F (2010) Denoising S ingle-Mo l ecule FRET T rajectori e s w i t h Wavelets a nd Bayesian Inference. Biophysical j ourna l 98:164 -17 3. Tibshi r a ni RJ, T ayl o r J (2010) Regu larization paths for least squares pro blems w i t h generalized L1 penal t ies. In: arXiV. Tukey JW (1977) Exploratory data an alysis. Reading, Mass.: Addison- Wesl ey Pub. Co . Table 1:”Components” for PWC denoising methods. All the methods in this paper can be construct ed using all pairwise differences between input samples, output samples, and sequence indices. These differences are then used to define kernel and loss functions. Loss functions and kernels are combined to make the generali zed functional to be minimized with respect to the out put signal . Function is the indicat or fu nction such that if the condition is true, and otherwise. (a) Difference Description Input-output value difference; used in likelihood t erms Output-output value difference; used in regularization t erms Input-input value difference; used in both likelihood and regularization terms Sequence difference; used in both lik elihood and regularization terms (b) Kernel fun ction Description Global Hard (local in either value or sequence) Soft (semi-l ocal in either value or sequence) Isolates only sequentiall y adjacent terms when used as sequence kernel Isolates only terms that have the same index when used as sequence kernel (c) Loss function Influence fun ction (derivative of loss function) Composition Simple Composite Composite Table 2: A generalized functional for noise removal from piecew ise constant (PWC) signals. The functional combi nes differences, loss es and kernel functions described in Table 1 int o a function to be minimized over all samples, pairwise . Various solver algorithms are used to minimize this functi onal with respect to the solution , these are described in Table 3. Gener alized functional fo r piecewise constant noise removal Existing methods Fun ction Notes Linear diffusion Solved by weighted mean filtering; cannot produce PWC solutions; not PWC Step-fitti ng (Gill, 1970; Kerssema kers et al., 2006) Termination criteria based on number of jumps; PWC Objective step-fitting (Kalafut and Visscher, 2008) Likelihood term the same upto log transformation; regularization parameter fixed by data; PWC Total variat ion regularization (Rudin et al., 1992) Convex; fused LASSO signal approximator is the same; PWC Total variat ion diffusion Convex; partially minimized by iterated 3-point median filter; PWC Mean shift clustering Non-convex; PWC Likelihood mean shift clustering Non-convex; K -means is simil ar but not a direct special case (see text); PWC Soft mean shift clustering Non-convex; PWC Soft l ikelihood mean shift clustering Non-convex; soft-K-means is s imil ar but not a direct special case (see text); PWC Convex clustering shrinkage (Pelckmans et al., 20 05) Convex; PWC Bilateral f ilter (Mrazek et al., 2006) Non-convex New methods proposed in this paper Jump penalization Non-convex; PWC Robust jump penalization Non-convex; PWC Robust total v ariation regularization Convex; PWC Soft mean shift total va riation diffusion Non-convex; PWC Weighted convex clustering shrinkage Convex; PWC Convex mean shift clustering Convex; PWC Table 3: Solvers for finding a mi nimizer of the generalized piecew ise constant (PWC) noise removal functional i n Table 2. The first column is the solver algorithm, the sec ond is the different PWC methods to which the technique can be a pplied in theory. Solver Can apply to Notes Analytic conv olution Linear diffusion Problems with only square loss functions are analytical in a similar way Linear programming (Boyd and Vandenberghe, 2004) Robust total v ariation regularization Direct minimizer of functional; also all piecewise linear convex problems Quadratic programming (Boyd and Vandenberghe, 2004) Total variat ion regularization Convex clustering shrinkage Direct minimizer of functional; also all problems that combine square likelihood with absolute regularization loss Stepwise jump placement (Gill, 1970; Kerssemakers et al., 20 06; Kalafut and Visscher, 2008 ) Step-fitti ng Objective step-fitting Jump penalization Robust jump penalization Greedy spline fit minimizer of functional Finite differencing (Mrazek et al., 2006) Total variat ion regularization Total variat ion diffusion Convex clustering shrinkage Mean shift clustering Likelihood mean shift clustering Soft mean shift clustering Soft K -means clusteri ng Robust total v ariation regularization Soft mean shift total va riation diffusion Finite differences are not guaran teed to converge for non -diff erentiable loss functions Coordinate descent (Friedman et al., 2007) Total variat ion regularization Robust total v ariation regularization Iterated mean repla cement (Cheng, 1995 ) Mean shift clustering Likelihood mean shift clustering Obtainable as adaptive step- size forward Euler differencing Weighted iterated mean replacement (Cheng, 1995) Soft mean shift clustering So ft likelihood mean shift clustering Obtainable as adaptive step- size forward Euler differencing Piecewise linear regularization path foll ower (Rosset and Zhu, 2007; Hofl ing, 2009) Total variat ion regularization Convex clustering shrinkage Least-angle regression path follower (Tibshirani and Taylor, 2010) Total variat ion regularization Reverse of piecewise linea r regularization path follower Figure 1: Examples of signals that could be modeled as piecewise constant (PW C) signals obscured by noise. (a) Log normalized DNA copy-number ratios against genome order from a microarray-based comparative g enomic hybridization study (Snijders et al., 2001); (b) Cosmic ray intensity against time recorded by neutron monitor (OLoughlin, 1997); (c) rotation speed against time of R. Sphaeroides flagellum (Pilizota et al., 2009), (d) pixel re d intensity value against horizontal pixel pos ition for a single s can line from a digi tal image, (e) short -wavelength solar X-ray flux agai nst time recorded by GO ES -15 space weather satellite (Bl oom, 2009), and (f) gamma ray intensity agai nst depth from USGS wireline geological survey well log (Ryder et al., 2009). Figure 2: N oise removal from PWC s ignals is a task for which no linear filter is efficien t, because, for independent noise, t he noise and the PWC s ignal both have infinite bandw idth , e.g. there is no maximum frequency above which the Fourier components of either have zero magnitude. (a) A smooth signal (blue) with added noise (grey), constructed from a few sinusoidal component s of random frequency and amplitude; (b) a PWC signal (blue) with added noise (grey), constructed from “s quare - wave” components of the same frequency and amplitude as the s mooth signal. (c) (Discrete) Fourier analysis of the noisy s mooth signal shows a few large magni tude, low -frequency components, and the background noise level that occupies the w hole frequency range. (d) Four ier analysis of the noisy PW C signa l in (b), s howing the same low -frequency, large magnitude components, but also many other large magnitude components across the entire frequency range (which are harmonics of the square wave components). The black, dotted line in (c) and (d) shows the frequency respons e (magnitude not to scale) of a low-pass f ilter used to perform noise removal; this is applied to the noisy, smoo th signal in (e) and the n oisy PW C signal in ( f). It can be s een that w hilst the smooth signal is recovered effectively and there is little noticeable distortion, although noise is removed from the PW C signal, the jumps are also smoothed away or cause spurious oscillations (Gibb’s pheno mena). Figure 3: Response of PWC denoising methods to a step o f unit height with additive Gaussian noise ( ) and two extreme outliers. The methods are (a) i terated med ian filter for to tal variation diffusion, (b) total variation regulariza tion ( ), (c) obj ective s tep-fitti ng, (d) mean shift ( ), (e) soft mean shift ( ), (f) K -means ( ), (g) convex cl ustering s hrinkage ( ), (h) bilateral f ilter ( ), (i) robust total variation regularization ( ), (j) soft mean shift total variation diffusion ( ), (k) jump penalization ( ), (l) robust jump penalization ( ), (m) weighted convex clustering shrinkage ( ), and (n) convex mean shift ( ). Figure 4: Response of PWC denoising methods to a step o f unit height with additive Gaussian noise ( ) and linear mean drift. The methods and parameters are as described in Figure 3. Figure 5: Iterat ion pa ths for solvers appli ed t o a representative sample of PWC denoising methods. The noise Is Gaussian ( ). The left column shows the final, converged ou tputs of each method, the r ight column the associated iteration path taken towards convergence. T he vertical axes are the va lues of the inpu t (b lue circles) and output (black line) s amples, an d the known PWC signal (thin blue l ine). T he methods and solver al gorithms are (a) total variation regularization by piecew ise line ar forward regularization path follower, (b) mean shift with adap tive step-size Euler integration, (c) K -means with adaptive step-size Euler integration, (d) bi lateral filtering with adapt ive step -size E uler integration (e) mean shift t otal variation dif fusion with predictor-corrector two-step integrat ion, (f) jump penal ization with f orward stepwise jump placement, (g) weighted co nvex clustering shrinkage with Euler integrati on. Method parameters are chosen to give good PWC recovery results.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment