Decoupling Hierarchical Recurrent Neural Networks With Locally Computable Losses
Learning long-term dependencies is a key long-standing challenge of recurrent neural networks (RNNs). Hierarchical recurrent neural networks (HRNNs) have been considered a promising approach as long-term dependencies are resolved through shortcuts up…
Authors: Asier Mujika, Felix Weissenberger, Angelika Steger
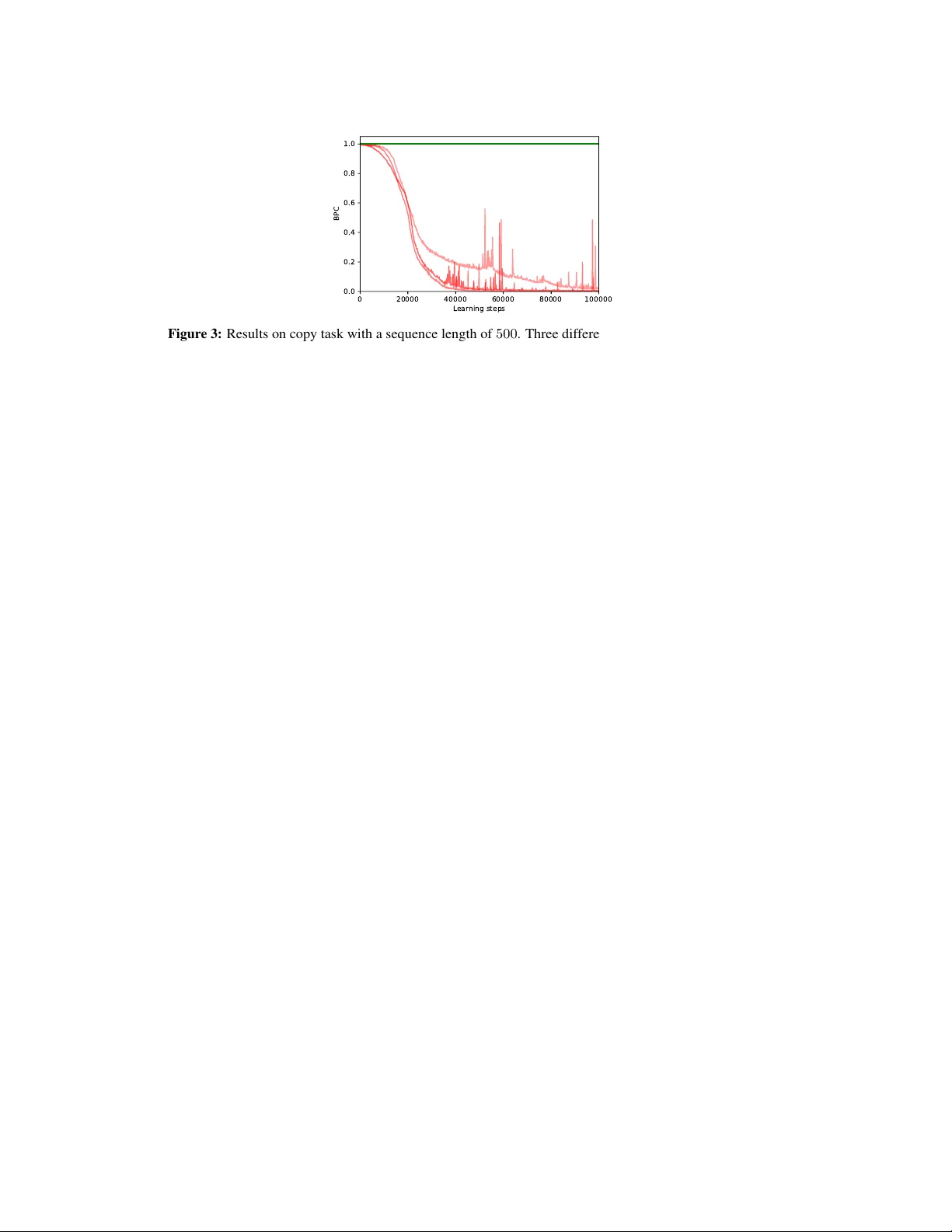
Decoupling Hierar chical Recurr ent Neural Networks W ith Locally Computable Losses Asier Mujika ∗ † Department of Computer Science ETH Zürich, Switzerland asierm@inf.ethz.ch Felix W eissenberger † Department of Computer Science ETH Zürich, Switzerland felix.weissenberger@gmail.com Angelika Steger Department of Computer Science ETH Zürich, Switzerland steger@inf.ethz.ch Abstract Learning long-term dependencies is a ke y long-standing challenge of recurrent neu- ral networks (RNNs). Hierarchical recurrent neural networks (HRNNs) ha ve been considered a promising approach as long-term dependencies are resolved through shortcuts up and do wn the hierarchy . Y et, the memory requirements of T runcated Backpropagation Through T ime (TBPTT) still pre vent training them on v ery long sequences. In this paper , we empirically show that in (deep) HRNNs, propag ating gradients back from higher to lower le v els can be replaced by locally computable losses, without harming the learning capability of the network, o ver a wide range of tasks. This decoupling by local losses reduces the memory requirements of training by a f actor exponential in the depth of the hierarchy in comparison to standard TBPTT . 1 Introduction Recurrent neural networks (RNNs) model sequential data by observing one sequence element at a time and updating their internal (hidden) state tow ards being useful for making future predictions. RNNs are theoretically appealing due to their T uring-completeness [ 28 ], and, crucially , hav e been tremendously successful in comple x real-world tasks, including machine translation [ 5 , 30 ], language modelling [23], and reinforcement learning [24]. Still, training RNNs in practice is one of the main open problems in deep learning, as the following issues prev ail. (1) Learning long-term dependencies is extremely difficult because it requires that the gradients (i.e. the error signal) hav e to be propagated ov er many steps, which easily causes them to vanish or explode [13, 2, 14]. (2) T runcated Backpropagation Through T ime (TBPTT) [ 33 ], the standard training algorithm for RNNs, requires memory that gro ws linearly in the length of the sequences on which the network is trained. This is because all past hidden states must be stored. Therefore, the memory requir ements of training RNNs with large hidden states on long sequences become prohibiti vely large. ∗ Author was supported by grant no. CRSII5_173721 of the Swiss National Science Foundation. † Equal contribution. Preprint. Under revie w . (3) In TBPTT , parameters cannot be updated until the full forw ard and backward passes ha ve been completed. This phenomenon is known as the parameter update lock [ 16 ]. As a consequence, the frequency at which parameters can be updated is in versely proportional to the length of the time-dependencies that can be learned, which makes learning exceedingly slo w for long sequences. The problem of vanishing/e xploding gradients has been alleviated by a plethora of approaches ranging from specific RNN architectures [ 15 , 5 ] to optimization techniques aiming at easing gradient flow [ 21 , 26 ]. A candidate for effecti vely resolving the vanishing/exploding gradient problem is hierarchical RNNs (HRNNs) [ 27 , 8 , 18 , 29 , 6 ]. In HRNNs, the network itself is split into a hierarchy of lev els, which are updated at decreasing frequencies. As higher lev els of the hierarchy are updated less frequently , these architectures hav e short (potentially logarithmic) gradient paths that greatly reduce the vanishing/e xploding gradients issue. In this paper , we show that in HRNNs, the lower lev els of the hierarchy can be decoupled from the higher lev els, in the sense that the gradient flo w from higher to lower le vels can effecti vely be replaced by locally computable losses. Also, we demonstrate that in consequence, the decoupled HRNNs admit training with memory decreased by a factor e xponentially in the depth of the hierarchy compared to HRNNs with standard TBPTT . The local losses stem from decoder networks which are trained to decode past inputs to each level from the hidden state that is sent up the hierarchy , thereby forcing this hidden state to contain all relev ant information. W e experimentally sho w that in a div erse set of tasks which rely on long-term dependencies and include deep hierarchies, the performance of the decoupled HRNN with local losses is indistinguishable from the standard HRNN. In summary , we introduce a RNN architecture with short gradient paths that can be trained memory- efficiently , thereby addressing issues (1) and (2). In the bigger picture, we believ e that our approach of replacing gradient flo w in HRNNs by locally computable losses may e ventually help to attempt solving issue (3) as well. 2 Related W ork Se veral techniques ha ve been proposed to deal with the memory issues of TBPTT [ 4 , 12 ]. Specifically , they trade memory for computation by storing only certain hidden states and recomputing the missing ones on demand. This is orthogonal to our ideas and thus, both can potentially be combined. The memory problem and the update lock have been tackled by online optimization algorithms such as Real Time Recurrent Learning (R TRL) [ 34 ] and its recent approximations [ 32 , 25 , 3 , 7 ]. Online algorithms are promising, as the parameters can be updated in e very step while the memory requirements do not grow with the sequence length. Y et, large computation costs and noise in the approximations make these algorithms impractical so far . Another way to deal with the parameter update lock and the memory requirements are Decoupled Neural Interfaces, introduced by by Jaderberg et al. in [ 16 ]. Here, a neural network is trained to predict incoming gradients, which are then used instead of the true gradients. HRNNs hav e been widely studied ov er the last decades. One early example by Schmidhuber in [ 27 ] proposes updating the upper hierarchy only if the lo wer one makes a prediction error . El Hihi and Bengio showed that HRNNs with fixed b ut different frequencies per lev el are superior in learning long-term dependencies [ 8 ]. More recently , Koutník et al. introduced the Clockwork RNN [ 18 ], here the RNN is divided into se veral modules that are updated at exponentially decreasing frequencies. Many approaches hav e also been proposed that are explicitly provided with the hierarchical structure of the data [ 29 , 19 , 31 ], for example character-le vel language models with w ord boundary information. Interestingly , Chung et al. [ 6 ] present an architecture where this hierarchical structure is extracted by the network itself. As our model utilizes fixed or gi ven hierarchical structure, yet does not learn it, models that can learn useful hierarchies may improv e the performance of our approach. Auxiliary losses in RNNs ha ve been used to impro ve generalization or the length of the sequences that can be learnt. In [ 27 ], Schmidhuber presented an approach, where a RNN should not only predict a target output to solve the task, but also its next input as an auxiliary task. More recently , Goyal et al. showed that in a variational inference setting, training of the latent variables can be eased by an auxiliary loss which forces the latent variables to reconstruct the state of a recurrent network running backwards [ 10 ]. Subsequently , T rinh et al. demonstrated that introducing auxiliary losses at random anchors in time which aim to reconstruct or predict previous or subsequent input 2 subsequences significantly improve optimization and generalization of LSTMs [ 15 ] and helps to learn time dependencies beyond the truncation horizon of TBPTT . The main difference to our approach is that they use auxiliary losses to incentivize an RNN to keep information in memory . This extends the sequences that can be solved by an additi ve factor through an echo-state netw ork-like ef fect. On the contrary , we use auxiliary losses to replace gradient paths in hierarchical models. This, together with the right memorization scheme, allows us to discard all hidden states of the lower hierarchical le vels when doing TBPTT , which reduces the memory requirements by a multiplicative f actor . 3 Methodology In this section we describe our approach in detail. W e start by defining a standard HRNN, then explain ho w cutting its gradient flo w sav es memory during training, and conclude by introducing an auxiliary loss, that can be computed locally , which prev ents a performance drop despite the restricted gradient flow (as sho wn in Section 4 below). 3.1 Hierarchical Recurr ent Neural Networks The basis of our architecture is a simple HRNN with two hierarchical levels (deeper HRNNs are considered belo w). W e describe it in terms of general RNNs. Such a RNN X is simply a parameterized and differentiable function f X which maps a hidden state h and an input x to a new hidden state h 0 = f X ( h, x ) . The HRNN consists of the lower RNN (indicated by superscript L ) and the upper RNN (superscript U ). The lower RNN recei ves the input x t and generates the output y t in addition to the next hidden state h t at e very time-step. Every k steps, the upper RNN recei ves the hidden state of the lo wer RNN, updates its o wn hidden state and sends its hidden state to the lo wer RNN. Then, the hidden state of the lower RNN is reset to all zeros. The update rules are summarized in Equation (1) for the lo wer and Equation (2) for the upper RNN. The unrolled computation graph is depicted in Figure 1. h L t = f L (0 , [ x t , h U t ]) if t mo d k = 0 , f L ( h L t − 1 , [ x t , 0]) else. (1) h U t = f U ( h U t − 1 , h L t − 1 ) if t mo d k = 0 , h U t − 1 else. (2) While we hav e outlined the case for two hierarchical le vels, this model naturally e xtends to deeper hierarchies by applying it recursively (see Section 4.4). This leads to lev els that are updated exponen- tially less frequently . Moreover , the update frequencies can also be fle xible in case the hierarchical structure of the input is explicitly pro vided (see Section 4.3). x t x t + k − 1 x t + k x t +2 k − 1 y t y t + k − 1 y t + k y t +2 k − 1 h L t h L t + k − 1 h L t + k h L t +2 k − 1 h U t h U t + k . . . . . . Figure 1: Unrolled computation graph of a HRNN with two hierarchical le vels. 3 3.2 Restricted Gradient Flow In TBPTT , the network is first unrolled for T steps in the forw ard pass, see Figure 1, while the hidden states are stored in memory . Thereafter, the gradients of the loss with respect to the parameters are computed using the stored hidden states in the backward pass, see Figure 2 (a). T o sav e memory during gradient computation, we simply ignore the edges from higher to lo wer lev els in the computation graph of the backward pass, see Figure 2. Importantly , the resulting gradients are not the true gradients and we term them r estricted gradients as they are computed under restricted gradient flo w . W e will refer to the r estricted gradients with the ˜ ∂ symbol.Thus, ˜ ∂ h U t ˜ ∂ h L t − 1 = 0 if t is a time-step when the upper RNN ticks (i.e. t mo d k = 0 ) and it is equal to the true partial deriv atives ev erywhere else. W e call the HRNN that is trained using these restricted gradients the gradient restricted HRNN ( gr -HRNN ). h L t h L t + k − 1 h L t + k h L t +2 k − 1 h U t h U t + k . . . . . . (a) Gradient flow in the unrolled HRNN h L t h L t + k − 1 h L t + k h L t +2 k − 1 h U t h U t + k . . . . . . (b) Gradient flow in the unrolled gr -HRNN Figure 2: Gradient flo w in the unrestricted and gradient restricted HRNN. Before we address the issue of compensating for the restricted gradients in the next section, we first analyze how much memory is needed to compute the restricted gradients. In the following, let t be a time-step when the upper RNN ticks (i.e. t mo d k = 0 ). A direct consequence of the restricted gradients is that P T i = t ˜ ∂ L i ˜ ∂ h L t − 1 = 0 , where L i is the loss at time-step i and we consider the network unrolled for time-steps 1 , . . . , T . Therefore, right before the upper RNN updates, ˜ ∂ L i ˜ ∂ θ L , where θ are the parameters of the network, can be computed for the previous k time-steps using just the previous k hidden states, h L t − k , . . . , h L t − 1 , of the lo wer RNN. W e further need these hidden states to compute P k i =1 ˜ ∂ L t − i ˜ ∂ h U t − k . Howe ver , we will not need the hidden states h L t − k , . . . , h L t − 1 for any other step of the backward pass and thus, we do not need to keep them in memory . Therefore, the restricted gradients can be computed using memory proportional to k for the hidden states h L t − k , . . . , h L t − 1 of the lower RNN and proportional to 2 T /k for both the T /k hidden states of the upper RNN and the T /k accumulated restricted gradients of the loss with respect to the hidden states of the upper RNN. Standard TBPTT requires memory proportional to T in order to compute the true gradients. Here, we showed that the restricted gradients can be computed using memory proportional to k + 2 T /k , thus improving by a factor of 2 /k . For (deep) HRNNs with l lev els, the abov e argument can be applied recursi vely , which yields memory requirements of ( l − 1) k for the hidden states of the lower RNNs and 2 T /k l − 1 for the uppermost RNN. 4 3.3 Locally Computable A uxiliary Losses In the gr -HRNN, the lo wer RNN is not incenti vized to provide a useful representation as input for the upper RNN. Howe ver , it is clear that if this hidden state which is sent upwards contains all information about the last k inputs, then the upper RNN has access to all information about the input, and thus the gr-HRNN should be able to learn as effecti vely as the HRNN without gradient restrictions. Hence, we introduce an auxiliary loss term to force this hidden state to contain all information about the last k inputs. This auxiliary loss comes from a simple feed-forward decoder network, which gi ven this hidden state and a randomly sampled inde x i ∈ { 1 , . . . , k } (in one-hot encoding) must output the i -th previous input. Then, the combined loss of the HRNN is the sum of the loss defined by the task and the auxiliary decoder loss multiplied by a hyper -parameter β . For hierarchies with l lev els, we add l − 1 decoder networks with respecti vely weighted losses. Crucially , the auxiliary loss can be computed locally in time. Thus, the memory requirements for training increase only by an additiv e term in the size of the decoder network. 4 Experiments In this section, we experimentally test replacing the gradient flow from higher to lower lev els by adding the local auxiliary losses. Therefore, we ev aluate the gr-HRNN with auxiliary loss (simply termed ’ours’ from here on) on four different tasks: Copy task, pixel MNIST classification, permuted pixel MNIST classification, and character -level language modeling. All these tasks require that the model effecti vely learns long-term dependencies to achie ve good performance. Additionally , to our model, we also ev aluate several ablations/augmentations of it to fully understand the importance and effects of its indi vidual components. These other models are: • HRNN : This model is identical to ours, except that all gradients from higher to lower le vels are propagated. The weight of the auxiliary loss is a hyper-parameter which is set using a grid-search (as the auxiliary loss may improv e the performance, we keep it here to make a fair comparison with our model). While this model has a much larger memory cost for training, it provides an upper bound on the performance we can e xpect from our model. • gr-HRNN : This model is equiv alent to our model, except that the weight of the auxiliary loss is set to zero. Thereby , it permits studying if using the auxiliary loss function (and the corresponding decoder network) is really necessary when the gradients are stopped. • mr-HRNN : This model is identical to the HRNN , except that it is trained using only as much memory as our model requires for training. That is, it is unrolled for a much smaller number of steps than the other models. In consequence, it admits a fair performance comparison (in terms of memory) to our model. If not mentioned otherwise belo w , the parameters are as follo ws. All RNNs are LSTMs with a hidden state of 256 units. The network for the auxiliary loss is a two layer network with 256 units, a ReLU [ 9 ] non-linearity and uses either the cross-entropy loss for discrete v alues or the mean squared loss for continuous ones. For each model we pick the optimal β from [10 − 3 , 10 − 2 , 10 − 1 , 0 , 10 0 , 10 1 , 10 2 ] , except for the gr -HRNN for which β = 0 . The models are trained using a batch size of 100 and the Adam optimizer [ 17 ] with the default T ensorflo w [ 1 ] parameters: learning rate of 0 . 001 , β 1 = 0 . 9 and β 2 = 0 . 999 . 4.1 Copy T ask In the copy task, the network is presented with a binary string and should afterwards output the presented string in the same order (an example for a sequence of length 5 is: input 01101***** with target output *****01101 ). W e refer to the maximum sequence length that a model can solve (i.e. achiev es loss less than 0 . 15 bits / char ) as L max . T able 1 summarizes the results for a sequence of length 100 . The copy task requires exact storage of the input sequence over many steps. Since the length of the sequence and therefore the dependencies are a controllable parameter in this task, it permits to explicitly assess ho w long dependencies a model can capture. 5 T able 1: Results for the copy task (3 repetitions). Memory refers to the number of vectors of the same size as the hidden state that need to be stored for each algorithm and batch element. Model Gradients Aux. loss Memory L max (longest solved sequences) ours 7 X 50 108 ± 0 gr-HRNN 7 7 50 21 ± 13 HRNN X X 200 107.7 ± 0.47 mr-HRNN X X 50 48.3 ± 0.94 Both our model and the model using all gradients ( HRNN ) achiev e very similar performance, which is limited by the number of steps for which the network is unrolled in training. Moreov er , the auxiliary loss is necessary , as the model without it ( gr -HRNN ) performs poorly . Moreov er , our model drastically outperforms the model with all gradients, when giv en the same memory budget, as the memory restricted HRNN ( mr -HRNN ) also performs poorly . Notably , our model is remarkably robust to the choice of the auxiliary loss weight β , as for all v alues except 0 it learns sequences of length at least 100 . Finally , the HRNN actually uses the capacity of the decoder network, as the grid-search yields a nonzero β . All models, except the mr -HRNN , are unrolled for T = 200 steps and the upper RNN ticks ev ery k = 10 steps of the lower one. T o equate memory budgets, the mr -HRNN is unrolled for 2 T /k + k = 50 steps. Hence, for sequence lengths at most 100 , gradients are propagated through the whole sequence. The model parameters are only updated once per batch. 4.2 (Permuted) Pixel MNIST Classification T able 2: Results for the pixel MNIST tasks (3 repetitions). Memory refers to the number of vectors of the same size as the hidden state that need to be stored for each algorithm and batch element. Model Gradients Aux. loss Memory Accuracy Accurac y (permuted) ours 7 X 166 0.9886 ± 0.0002 0.9680 ± 0.0008 gr-HRNN 7 7 166 0.2109 ± 0.0743 0.9368 ± 0.0049 HRNN X X 784 0.9885 ± 0.0003 0.9681 ± 0.0008 mr-HRNN X X 166 0.8939 ± 0.0041 0.9553 ± 0.0015 In the pixel MNIST classification task, the pix els of MNIST digits are presented sequentially . After observing the whole sequence the network must predict the class label of the presented digit. The permuted pixel MNIST task is exactly the same, but the pix els are presented in a fixed random order . T able 2 summarizes the accuracy of the dif ferent models on the two tasks. Both pixel MNIST classification tasks require learning long-term dependencies, especially when using the default permutation, as the most informati ve pix els are around the center of the image (i.e. in the middle of the input sequence) and the class prediction is only made at the end. Additionally , unlike in the copy task, the input has to be processed in a more complex manner in order to make a class prediction. The results on both tasks are in line with the copy task. Our model performs on par with the model using the true gradient ( HRNN ). Again, the auxiliary loss is necessary , as the accuracy of the gr - HRNN is significantly worse. Giv en the same memory b udget, our model outperforms the HRNN with all gradients. All models are unrolled for T = 784 steps (the number of pixels of an MNIST image) except for the memory restricted model which is unrolled for 166 steps. The upper RNN ticks ev ery k = 10 steps of the lower one. The same permutation is used for all runs of the permuted task. 6 4.3 Character -level Language Modeling T able 3: Results for the character-le vel language modeling task on the Penn T reeBank corpus (3 repetitions). Model Gradients Aux. loss V alidation bits / char T est bits / char ours 7 X 1.4519 ± 0.0014 1.4027 ± 0.0003 gr-HRNN 7 7 1.4545 ± 0.0016 1.4074 ± 0.0011 HRNN X X 1.4480 ± 0.0011 1.3974 ± 0.0021 In the character-le vel language modeling task, a text is presented character by character and at each step, the network must predict the next character . The results for this task on the Penn TreeBank corpus [20] are summarized in T able 3. In contrast to the previous tasks, character -level language modeling contains a comple x mix of both short- and long-term dependencies, where short-term dependencies typically dominate long-term dependencies. Thus, one may expect that replacing the true gradients by the local loss is the most harmful here. The performance of all 3 models is very close in this task, ev en for the gr -HRNN , which has neither gradients nor the auxiliary loss to capture long-term dependencies. W e believ e that this is due to the dominance of short-term dependencies in character-le vel language modeling. It has been widely reported that the length of the unrolling, and thus long-term dependencies, have a minimal ef fect on the final performance of character-lev el language models [ 16 ], particularly for small RNNs, as in our experiments. Still, we observe the best performance when using the true gradients ( HRNN ), a slight degradation when replacing gradients by the auxiliary loss (our), which slightly improv es on not using the auxiliary loss ( gr -HRNN ). Here, we explicitly pro vide the hierarchical structure of the data to the model by updating the upper RNN once per word, while the lower RNN ticks once per character . As discussed in Section 2, there are models that can extract the hierarchical structure, which is a separate goal from ours. W e refrain from comparing with a memory restricted model and displaying memory budgets because the dynamic memory requirements depending on the input sequence prohibit a fair comparison. Howe ver , as stated earlier , the unroll length usually has a minimal effect on the performance of character-le vel language modeling. W e unroll the models for 50 characters and use an upper RNN with 512 units to deal with the extra comple xity of the task. 4.4 Deeper Hierarchies In deeper hierarchies, the output modalities of the individual decoder networks are different: whereas the decoder network in the lo west lev el has to predict elements of the input sequence (e.g. bits in the copy task), the decoder netw orks in higher lev els hav e to predict hidden states of the lo wer lev el’ s RNNs. Here, we confirm that our approach generalizes to deeper hierarchies. In particular , we use the copy task with sequence length 500 (and truncation horizon 1000) to test this. W e consider a HRNN with 3 lev els, where the lowest RNN is updated in e very step, the middle RNN ev ery 5 steps and the upper RNN ev ery 25 steps, where no gradients from higher to lower RNNs are propagated. W e compare using the auxiliary loss only on the lowest le vel with using it in the lowest and the middle layer . Thereby , we check whether applying the auxiliary loss in the middle RNN (i.e. ov er hidden states rather than raw inputs) is necessary to solving the task. The RNNs hav e 64 , 256 and 1024 units (from lo wer to higher lev els). The β for the lo west le vel is 0 . 1 and 1 for the middle le vel. All other experimental details are kept as in Section 4.1. W e run sev eral repetitions which are sho wn in Figure 3. W ithout the auxiliary loss in the middle layer , the network cannot solve the task (in f act, not ev en close as performance is close to chance level). Howe ver , when the auxiliary loss is added also to the middle layer , the model can solve the task perfectly on e very run. 7 0 20000 40000 60000 80000 100000 Learning steps 0.0 0.2 0.4 0.6 0.8 1.0 BPC Figure 3: Results on copy task with a sequence length of 500 . Three different runs of deep HRNNs with the auxiliary loss in both lev els (red) and with the auxiliary loss only in the lower lev el (green). 5 Conclusion In this paper , we hav e shown that in hierarchical RNNs the gradient flow from higher to lo wer le vels can be effectiv ely replaced by locally computable losses. This allows memory savings up to an exponential factor in the depth of the hierarchy . In particular , we first explained ho w not propagating gradients from higher to lo wer lev els permits these memory savings. Then, we introduced auxiliary losses that encourage information to flow up the hierarchy . Finally , we demonstrated experimentally that the memory-efficient HRNNs with our auxiliary loss perform on par with the memory-heavy HRNNs and strongly outperform HRNNs gi ven the same memory b udget on a wide range of tasks, including deeper hierarchies. High capacity RNNs, like Dif ferentiable Plasticity [ 22 ], or Neural T uring Machines [ 11 ] hav e been sho wn to be useful and ev en achieve state-of-the-art in many tasks. Howe ver , due to the memory cost of TBPTT , training such models is often impractical for long sequences. W e think that combining these models with our techniques in future work could open the possibility for using high capacity RNNs for tasks in volving long-term dependencies that hav e been out of reach so far . Still, the problem of the parameter update lock remains. While this is the most under-explored of the three big problems when training RNNs (v anishing/exploding gradients and memory requirements being the other two), resolving it is just as important in order to be able to learn long-term depen- dencies. W e believ e that the techniques laid out in this w ork (i.e. replacing gradients in HRNNs by locally computable losses) can be a stepping stone to wards solving the parameter update lock. W e leav e this for future work. References [1] M. Abadi, A. Agarwal, P . Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. De vin, S. Ghemawat, I. Goodfello w , A. Harp, G. Irving, M. Isard, Y . Jia, R. Joze- fowicz, L. Kaiser , M. Kudlur , J. Le venber g, D. Mané, R. Monga, S. Moore, D. Murray , C. Olah, M. Schuster , J. Shlens, B. Steiner , I. Sutske ver , K. T alwar , P . T ucker , V . V anhoucke, V . V asudev an, F . V iégas, O. V inyals, P . W arden, M. W attenberg, M. W icke, Y . Y u, and X. Zheng. T ensorFlow: Large-scale machine learning on heterogeneous systems, 2015. URL https://www.tensorflow.org/ . Software a v ailable from tensorflow .org. [2] Y . Bengio, P . Simard, P . Frasconi, et al. Learning long-term dependencies with gradient descent is difficult. IEEE transactions on neur al networks , 5(2):157–166, 1994. [3] F . Benzing, M. M. Gauy , A. Mujika, A. Martinsson, and A. Steger . Optimal kronecker-sum approximation of real time recurrent learning. arXiv pr eprint arXiv:1902.03993 , 2019. [4] T . Chen, B. Xu, C. Zhang, and C. Guestrin. T raining deep nets with sublinear memory cost. arXiv pr eprint arXiv:1604.06174 , 2016. [5] K. Cho, B. V an Merriënboer , C. Gulcehre, D. Bahdanau, F . Bougares, H. Schwenk, and Y . Bengio. Learning phrase representations using rnn encoder -decoder for statistical machine translation. arXiv pr eprint arXiv:1406.1078 , 2014. 8 [6] J. Chung, S. Ahn, and Y . Bengio. Hierarchical multiscale recurrent neural networks. arXiv pr eprint arXiv:1609.01704 , 2016. [7] T . Cooijmans and J. Martens. On the variance of unbiased online recurrent optimization. arXiv pr eprint arXiv:1902.02405 , 2019. [8] S. El Hihi and Y . Bengio. Hierarchical recurrent neural networks for long-term dependencies. In Advances in neural information pr ocessing systems , pages 493–499, 1996. [9] X. Glorot, A. Bordes, and Y . Bengio. Deep sparse rectifier neural networks. In Proceedings of the fourteenth international confer ence on artificial intelligence and statistics , pages 315–323, 2011. [10] A. G. A. P . Goyal, A. Sordoni, M.-A. Côté, N. R. Ke, and Y . Bengio. Z-forcing: T raining stochastic recurrent networks. In Advances in neural information pr ocessing systems , pages 6713–6723, 2017. [11] A. Grav es, G. W ayne, and I. Danihelka. Neural turing machines. arXiv pr eprint arXiv:1410.5401 , 2014. [12] A. Gruslys, R. Munos, I. Danihelka, M. Lanctot, and A. Graves. Memory-efficient backpropa- gation through time. In Advances in Neural Information Pr ocessing Systems , pages 4125–4133, 2016. [13] S. Hochreiter . Untersuchungen zu dynamischen neuronalen netzen. Diploma, T echnische Universität München , 91(1), 1991. [14] S. Hochreiter . The vanishing gradient problem during learning recurrent neural nets and problem solutions. International Journal of Uncertainty , Fuzziness and Knowledge-Based Systems , 6 (02):107–116, 1998. [15] S. Hochreiter and J. Schmidhuber . Long short-term memory . Neural computation , 9(8): 1735–1780, 1997. [16] M. Jaderberg, W . M. Czarnecki, S. Osindero, O. V inyals, A. Grav es, D. Silver , and K. Kavukcuoglu. Decoupled neural interfaces using synthetic gradients. In Proceedings of the 34th International Conference on Machine Learning-V olume 70 , pages 1627–1635. JMLR. org, 2017. [17] D. P . Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv pr eprint arXiv:1412.6980 , 2014. [18] J. Koutnik, K. Greff, F . Gomez, and J. Schmidhuber . A clockwork rnn. In International Confer ence on Machine Learning , pages 1863–1871, 2014. [19] W . Ling, I. T rancoso, C. Dyer , and A. W . Black. Character -based neural machine translation. arXiv pr eprint arXiv:1511.04586 , 2015. [20] M. P . Marcus and M. A. Marcinkiewicz. Building a large annotated corpus of english: The penn treebank. Computational Linguistics , 19(2), 1993. [21] J. Martens and I. Sutskev er . Learning recurrent neural networks with hessian-free optimization. In Pr oceedings of the 28th International Confer ence on Machine Learning (ICML-11) , pages 1033–1040. Citeseer , 2011. [22] T . Miconi, J. Clune, and K. O. Stanle y . Differentiable plasticity: training plastic neural networks with backpropagation. arXiv preprint , 2018. [23] T . Mikolov , M. Karafiát, L. Burget, J. ˇ Cernock ` y, and S. Khudanpur . Recurrent neural network based language model. In Eleventh annual confer ence of the international speech communica- tion association , 2010. [24] V . Mnih, A. P . Badia, M. Mirza, A. Graves, T . Lillicrap, T . Harley , D. Silver , and K. Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In International conference on machine learning , pages 1928–1937, 2016. [25] A. Mujika, F . Meier , and A. Steger . Approximating real-time recurrent learning with random kronecker factors. In Advances in Neural Information Pr ocessing Systems , pages 6594–6603, 2018. [26] R. Pascanu, T . Mikolov , and Y . Bengio. On the dif ficulty of training recurrent neural networks. In International confer ence on machine learning , pages 1310–1318, 2013. 9 [27] J. Schmidhuber . Learning complex, extended sequences using the principle of history compres- sion. Neural Computation , 4(2):234–242, 1992. [28] H. T . Siegelmann and E. D. Sontag. On the computational power of neural nets. Journal of computer and system sciences , 50(1):132–150, 1995. [29] A. Sordoni, Y . Bengio, H. V ahabi, C. Lioma, J. Grue Simonsen, and J.-Y . Nie. A hierarchical recurrent encoder-decoder for generati ve context-a ware query suggestion. In Pr oceedings of the 24th ACM International on Confer ence on Information and Knowledge Management , pages 553–562. A CM, 2015. [30] I. Sutske ver , O. V inyals, and Q. V . Le. Sequence to sequence learning with neural networks. In Advances in neural information pr ocessing systems , pages 3104–3112, 2014. [31] K. S. T ai, R. Socher, and C. D. Manning. Impro ved semantic representations from tree-structured long short-term memory networks. arXiv preprint , 2015. [32] C. T allec and Y . Olli vier . Unbiased online recurrent optimization. arXiv preprint arXiv:1702.05043 , 2017. [33] R. J. W illiams and J. Peng. An ef ficient gradient-based algorithm for on-line training of recurrent network trajectories. Neural computation , 2(4):490–501, 1990. [34] R. J. Williams and D. Zipser . A learning algorithm for continually running fully recurrent neural networks. Neural computation , 1(2):270–280, 1989. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment