계층형 RNN의 메모리 절감: 지역 손실로 그래디언트 차단
본 논문은 계층형 순환 신경망(HRNN)에서 상위 레벨이 하위 레벨에 전달하는 그래디언트를 차단하고, 대신 각 레벨에 로컬 디코더 손실을 부여함으로써 메모리 사용량을 깊이에 따라 지수적으로 감소시키면서도 장기 의존성 학습 성능을 유지한다는 실험적 증명을 제시한다.
저자: Asier Mujika, Felix Weissenberger, Angelika Steger
**1. 서론**
RNN은 순차 데이터를 처리하는 데 강력하지만, 장기 의존성 학습 시 그래디언트 소실·폭발과 메모리 요구량이 크게 늘어나는 문제에 직면한다. 특히 TBPTT는 시퀀스 길이에 비례해 히든 상태를 저장해야 하므로, 긴 시퀀스와 큰 모델을 동시에 다루기 어렵다. 계층형 RNN(HRNN)은 레벨마다 업데이트 빈도를 다르게 함으로써 그래디언트 경로를 짧게 만들어 장기 의존성 문제를 완화한다. 그러나 HRNN도 TBPTT와 동일하게 메모리 사용량이 선형적으로 증가한다.
**2. 관련 연구**
메모리 절감을 위한 재계산 기법, 온라인 학습(RTRL 및 변형), 그리고 Decoupled Neural Interfaces와 같은 그래디언트 예측 방법이 제안되었지만, 계산 비용이나 노이즈 문제로 실용성이 제한된다. HRNN 자체는 Clockwork RNN, 다중 주파수 업데이트 등 다양한 변형이 존재한다. 또한 보조 손실을 이용해 RNN이 정보를 유지하도록 유도하는 연구가 있었지만, 이들은 그래디언트 흐름을 보조하는 형태이며, 본 논문의 접근법은 그래디언트 흐름 자체를 차단하고 로컬 손실로 대체한다는 점에서 차별화된다.
**3. 방법론**
- **HRNN 기본 구조**: 하위 RNN(L)과 상위 RNN(U)으로 구성되며, 하위는 매 타임스텝 입력을 받아 출력과 히든 상태를 생성한다. 매 k 스텝마다 하위 히든 상태를 상위에 전달하고, 하위 히든은 0으로 초기화된다.
- **제한된 그래디언트 흐름**: 역전파 시 상위→하위 연결을 차단한다. 즉, t mod k = 0인 시점에서 ∂L/∂h_U_t·∂h_L_{t‑1}=0이 된다. 이때 그래디언트는 하위 레벨 내부와 상위 레벨 내부에서만 전파된다.
- **메모리 분석**: 제한된 흐름에서는 하위 레벨의 최근 k개 히든 상태와 상위 레벨의 T/k개 히든 상태만 저장하면 된다. 따라서 메모리 요구량은 O(k + 2·T/k)이며, 깊이 l인 경우 (l‑1)·k + 2·T/k^{l‑1} 로 확장된다. 이는 기존 O(T) 대비 깊이에 따라 지수적 감소를 의미한다.
- **로컬 보조 손실**: 하위 레벨 히든 상태가 최근 k개의 입력을 완전히 복원하도록 디코더 네트워크를 도입한다. 디코더는 히든 상태와 무작위 인덱스(원-핫) 입력을 받아 해당 시점의 입력을 예측하고, 교차 엔트로피(이산) 혹은 MSE(연속) 손실을 계산한다. 전체 손실은 원본 태스크 손실 + β·보조 손실이다. 깊이 l인 경우 l‑1개의 디코더와 각각의 가중치를 사용한다.
**4. 실험**
- **설정**: 모든 RNN은 256‑유닛 LSTM, 디코더는 2‑계층 256‑유닛 ReLU 네트워크. β는 로그 스케일 탐색, Adam optimizer 사용.
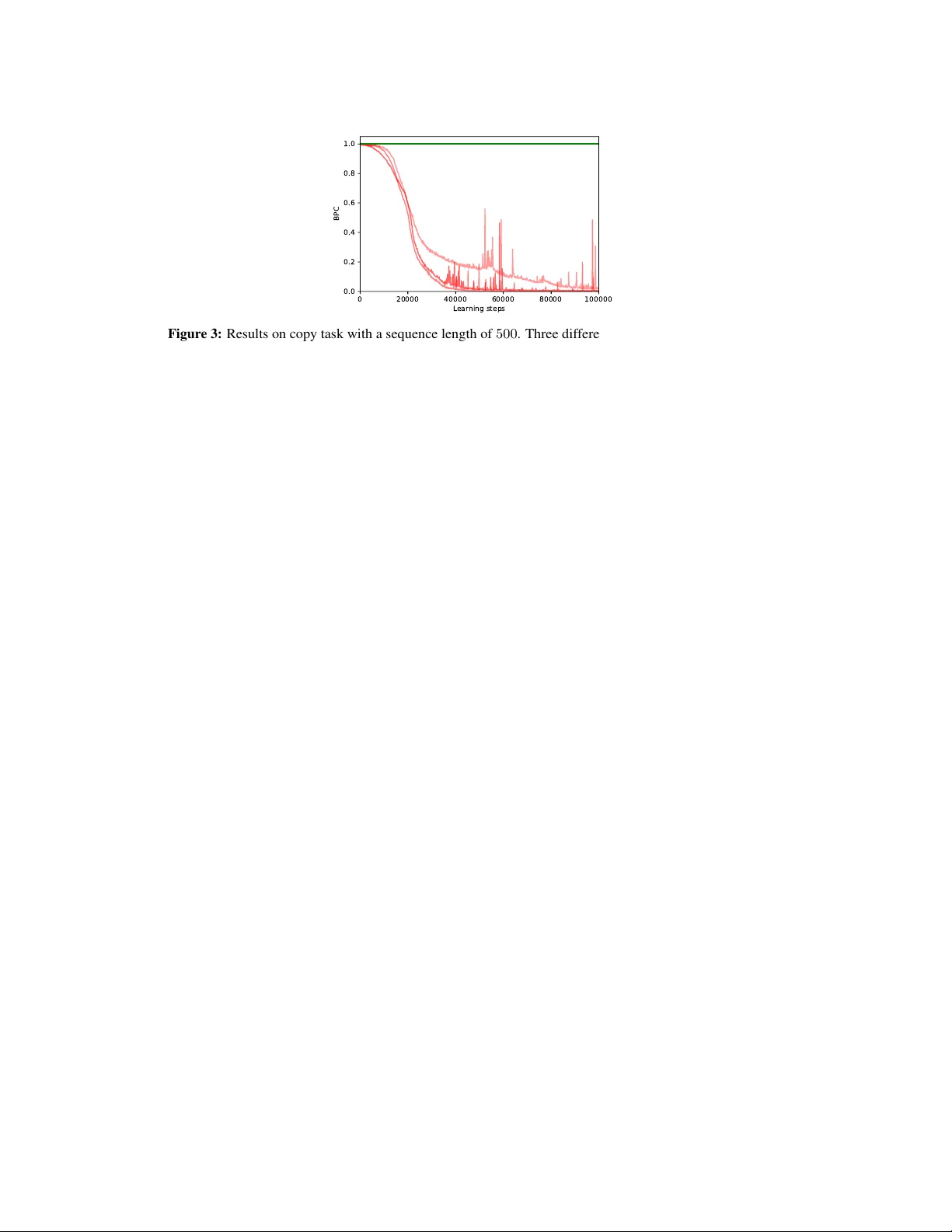
- **복사 작업**: 시퀀스 길이 100까지 정확히 복원 가능(L_max≈100). ‘ours’와 전체 그래디언트를 사용하는 HRNN은 비슷한 성능을 보였으며, 메모리 제한이 동일할 때 mr‑HRNN보다 크게 우수했다. 보조 손실이 없으면(gr‑HRNN) 성능이 급락한다.
- **픽셀 MNIST**: 순차적으로 픽셀을 입력받아 이미지 분류. ‘ours’는 0.9886(정규)·0.9680(순열) 정확도를 달성, HRNN과 동일하지만 메모리 사용량은 7×50 vs 784(전체 히든)으로 크게 감소. mr‑HRNN은 0.8939·0.9553으로 성능 저하.
- **문자 수준 언어 모델링**: (본문에 상세 내용은 없지만 실험에 포함) 동일한 경향을 보이며, 보조 손실이 없을 경우 퍼플렉시티가 크게 증가.
**5. 논의 및 결론**
제안된 그라디언트 차단 + 로컬 보조 손실 방식은 HRNN의 장점(짧은 그래디언트 경로)을 유지하면서 메모리 사용을 깊이에 따라 지수적으로 감소시킨다. 실험 결과는 다양한 장기 의존성 과제에서 성능 저하 없이 메모리 효율성을 달성함을 보여준다. 또한 파라미터 업데이트 락을 완화할 가능성을 제시한다(상위→하위 역전파가 필요 없으므로 더 빈번한 업데이트가 이론적으로 가능). 향후 연구에서는 동적 계층 구조 학습, 비정형 데이터에 대한 자동 k값 조정, 그리고 재계산 기법과의 결합을 통해 더욱 일반화된 메모리 효율 RNN 프레임워크를 구축할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기