Augmented State Feedback for Improving Observability of Linear Systems with Nonlinear Measurements
This paper is concerned with the design of an augmented state feedback controller for finite-dimensional linear systems with nonlinear observation dynamics. Most of the theoretical results in the area of (optimal) feedback design are based on the ass…
Authors: Atiye Alaeddini, Kristi A. Morgansen, Mehran Mesbahi
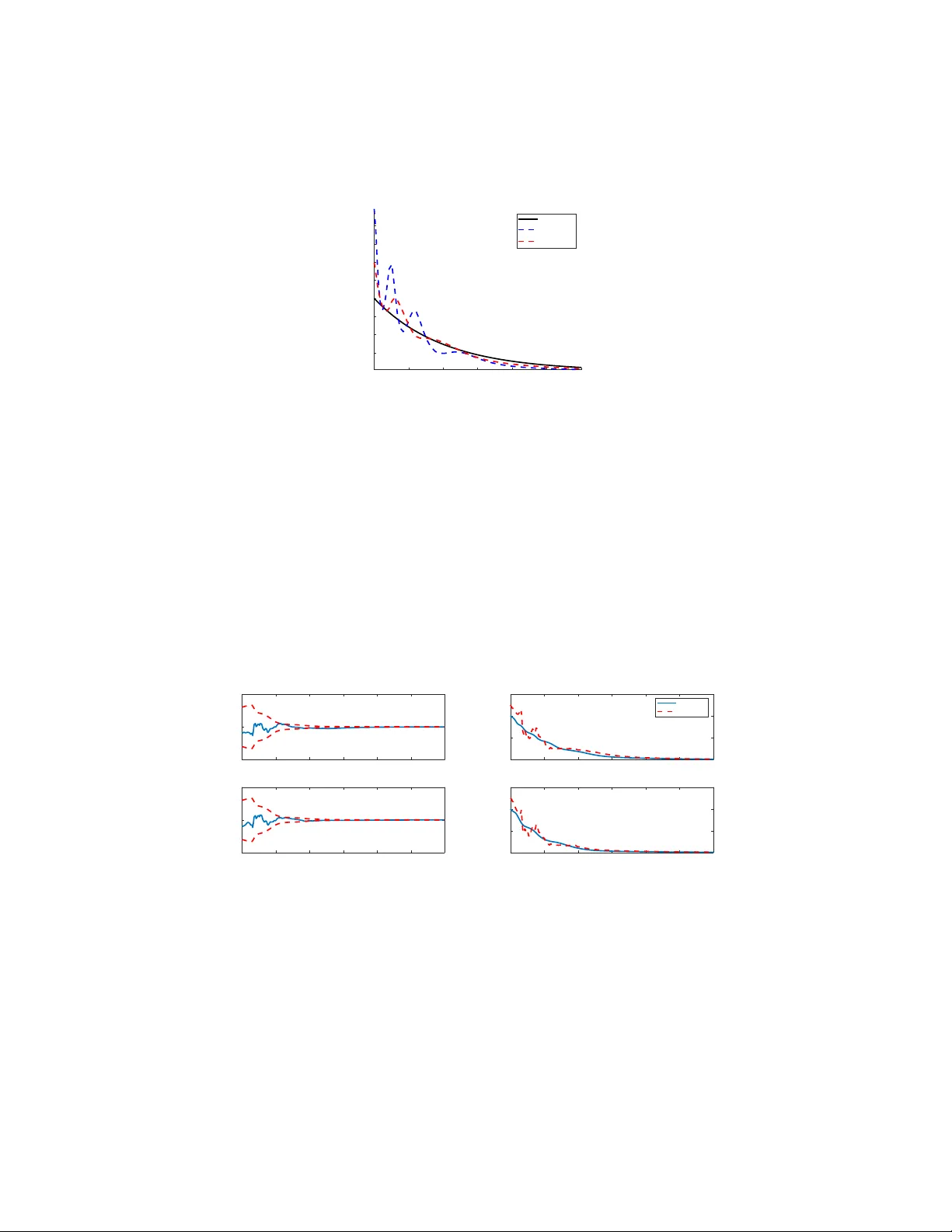
Augmented State Feedback for Improving Observ ability of Linear Systems with Nonlinear Measurements Atiye Alaeddini Institute for Disease Modeling, Bellevue , W A, 98005 Kristi A. Morgansen , Mehran Mesbahi University of W ashington, W illiam E. Boeing Department of Aer onautics and Astronautics, Seattle, W A 98195 Abstract This paper is concerned with the design of an augmented state feedback controller for finite-dimensional linear systems with nonlinear observation dynamics. Most of the theoretical results in the area of (optimal) feedback design are based on the assumption that the state is av ailable for measurement. In this paper , we focus on finding a feed- back control that avoids state trajectories with undesirable observability properties. In particular , we introduce an optimal control problem that specifically considers an inde x of observ ability in the control synthesis. The resulting cost functional is a combination of LQR-like quadratic terms and an index of observability . The main contribution of the paper is presenting a control synthesis procedure that on one hand, provides closed loop asymptotic stability , and addresses the observability of the system–as a transient performance criteria–on the other . K eywor ds: Nonlinear observations, linear state feedback, observ ability, stability 1. Introduction A primary consideration in the control synthesis procedure examined in this paper is system observability . This is motiv ated by the inherent coupling in the actuation and sensing in nonlinear systems; as such, one might be able to make a system more observable by changing the control inputs [1, 2, 3]. Here, we consider a particular type of nonlinear systems, namely , one with linear state dynamics paired with a nonlinear observation dynamics. This is motiv ated by the fact that in some practical problems, nonlinearities arise from the system measurements. An example of this type of sys- tems is a simplified particle model of a vehicle with a camera or sonar with range- only/bearing-only measurements, such as an autonomous underwater vehicle (A UV). The measurements for these vehicles are usually based on acoustic localization [4]. In this case, acoustic transducers are installed on the A UV and on a set of other bea- cons. The A UV has the exact global location of the beacons and can determine its range to one (Single Beacon Navigation [5]), three (Long-Baseline Localization [6]), Pr eprint submitted to Systems & Contr ol Letters August 30, 2019 or more separate beacons in order to determine its position. Another example of non- linear observ ation is bearing-only measurement, e.g., [7]. In this case, the vehicle only has information about its direction but not about the distance from reference points. A modeling of a vehicle with azimuth bearing, conical bearing, and depth/elev ation angle measurements can be found in [8]. For linear systems, Linear Quadratic Regulation (LQR) is a well known and com- monly used method for designing an optimal control law giv en a quadratic cost function of state and control. One potential problem may be that while the LQR problem min- imizes the cost functional, it may not result in good response when the measurement equation does not facilitate the use or reconstruction of the state for feedback. In this paper we modify the cost functional in standard LQR and suggest an augmented control in order to improve the observability of the baseline optimal controller . As such, we show that we can av oid unobserv able trajectories by augmenting decaying oscillatory terms with the LQR-induced state feedback, without ef fecting the asymptotic stability and performance of the baseline controller . Our goal in this work is proposing a synthesis procedure for efficiently choosing the inputs of a nonlinear system to improve its o verall sensing performance (measured by the observability Gramian). This task is moti v ated through problems where the re- construction of the state proves to be challenging and it becomes imperativ e to activ ely acquire, sense, and estimate it; an example of such a problem is robot localization op- erating in an unknown environment, when the robot only has access to range/bearing measurements [9]. In this context, a robot can use a path that leads to more effecti ve localization of itself or to construct a map of the en vironment [9, 10]. For example, in [10], sampling trajectories for autonomous v ehicles are selected from a finite sampling of trajectories through an exhausti ve search. On the other hand, the work [9] discusses the geometry of trajectories that achiev es maximum information for a model of the rov er robot. Y u et al. [11] have dev eloped a path planning algorithm based on dynamic programming for navigation of a micro aerial vehicle (MA V) using bearing-only mea- surements. In their proposed algorithm, at each time step, one of the three possible choices of roll command–that is more observable–is selected. The observ ability-based optimal controller design presented in this work is closely related to the analysis discussed in [12] and [13] to avoid unobserv able state/output trajectories. In both works, an index of observability is added to the cost functional. The index of observability used in both of these w orks are inspired by the observ ability matrix for linear systems. The observ ability rank condition for nonlinear systems, giv en in [14, 15], depends on the rank of the span of the observation space of the nonlinear system. In general, the observability matrix of a nonlinear system is the span of the Lie deriv ativ es of the output function in all possible directions generated from the drift and control vector fields. In this work, we introduce an index of observability that is closely related to the observability Gramian. Unlike the observability matrix which gives a yes/no answer to the observ ability question, the observability Gramian parameterizes the lev el of observability for linear/nonlinear system. In comparison with previous observability-based path planning algorithms reported in the literature, the controller obtained in this paper can be applied to a lar ger f amily of nonlinear systems (with a general form of the nonlinear observation function); more- ov er , the obtained controller ensures closed loop stability . In particular , utilizing the 2 concept of observability Gramian, and tools from linear optimal control theory , this paper dev elops a synthesis procedure for a modified version of the optimal linear state feedback with stability guarantees. The objecti ve function examined in this paper is quadratic in state and control, augmented with an observability measure. One of our contribution is presenting an observability inde x, whose optimization does not hav e adverse ef fects on the asymptotic stability properties of the system. 2. Preliminaries on Obser vability of Nonlinear Systems Consider the linear time in variant system of the form ˙ x = A x + B u y = C x , (1) for which the observability Gramian, W o , L = Z t f 0 e A T t C T Ce At d t , (2) can be computed to ev aluate the observability of a linear system (linear dynamics and linear observ ation) [16]. A linear system is (fully) observable if and only if the corre- sponding observability Gramian is full rank [17]. In the linear setting, if the observ- ability Gramian is rank deficient, certain states (or directions in the state space) cannot be reconstructed from the measurement, re gardless of the control polic y being applied. While the observability Gramian works well for determining the observ ability of lin- ear systems, analytical observability conditions for nonlinear systems quickly become intractable, necessitating simplifications for computational tractability . One such ap- proach is the ev aluation of nonlinear observability Gramian through linearization and using the corresponding Jacobian matrices for linear observability analysis; howe ver , this approach only provides an approximation of the local observ ability for a specific trajectory . One alternativ e method to ev aluate the observability of a nonlinear system is using the concept of observ ability co variance or the empirical observ ability Gramian [16]. This approach provides a more accurate description of a nonlinear system’ s ob- servability (compared with linearization), while being computationally less expensi ve to apply compared with say , Lie algebraic based methods. T o set the stage for the main contribution of the paper, let us first provide a brief overvie w of the empirical observ- ability Gramian and how it is used to e valuate the observ ability of nonlinear systems. Consider the problem of system observability for the nonlinear system, ( ˙ x = f ( x , u ) , x ∈ R n , u ∈ R p , y = h ( x ) , y ∈ R m . (3) The empirical observability Gramian for the system (3) is constructed as follows. For ε > 0, let x ± i 0 = x 0 ± ε e i be the perturbations of the initial condition and y ± i ( t ) be the corresponding output, where e i is the i th unit vector in R n . For the system (3), the empirical observability Gramian W o , is an n × n matrix, whose ( i , j ) entry is W o i j = 1 4 ε 2 Z t f 0 y + i ( t ) − y − i ( t ) T y + j ( t ) − y − j ( t ) d t . (4) 3 It can be shown that the empirical observability Gramian con verges to the local observ- ability Gramian as ε → 0 [16]. Note that the perturbation, ε , should always be chosen such that the system stays in the region of attraction of the equilibrium point of the system. The largest singular value [18], the smallest eigenv alue [16], the determinant [10, 19], and the trace of the inv erse [10] of the observability Gramian have all been used as different measures for the (nonlinear) system observ ability . By using the definition giv en in (4), the trace of the empirical observability Gramian can be written as trace ( W o ) = 1 4 ε 2 Z t f 0 n ∑ i = 1 h ( x + i ( t )) − h ( x − i ( t )) 2 d t , (5) where, x ± i ( t ) is the trajectory corresponding to the initial condition x ± i 0 = x 0 ± ε e i . 3. Problem F ormulation Consider a system with nonlinear observation, ˙ x = A x + B u , x ∈ R n , u ∈ R p , y = h ( x ) , y ∈ R m . (6) The linear-quadratic optimal control (known as LQR) aims at minimizing the cost func- tional min x , u J = Z ∞ 0 x T Q x + u T R u d t , (7) with Q = Q T 0 , R = R T 0 , (8) and the linear dynamics (6) represents the constraints. The solution of LQR is the linear state feedback u LQR = − R − 1 B T P x , (9) where P is the positiv e definite solution of the Riccati equation, Q + A T P + P A − PBR − 1 B T P = 0 . (10) The LQR control places the poles of ¯ A in a stable, suitably-damped locations in the complex plane, where ¯ A is the “ A -matrix” of the closed loop system, and in this case ¯ A = A − BR − 1 B T P . Picking the L yapunov function V ( x ) = x T P x , we hav e, V ( x ) > 0 , for all x 6 = 0 , ˙ V ( x ) = x T P ˙ x + ˙ x T P x = x T ( − Q − PBR − 1 B T P ) x < 0 , for all x 6 = 0 . (11) Hence, the optimal LQR control (9) asymptotically stabilizes the origin. One potential problem may be that while the LQR problem minimizes the above cost functional, it may not result in a good practical response, e.g., when the obtained 4 trajectory is not observable- in this case, we are not able to reconstruct the states re- quired for state feedback. In fact, since the output function is nonlinear , the lineariza- tion of the output function h ( x ) about the optimal LQR trajectory could be unobserv- able (or poorly observ able). In this section, our goal is modifying the LQR control such that we avoid unobservable trajectories, while ensuring that the closed loop system is stable. In order to preserve the asymptotic con vergence of the closed loop state trajec- tory , we consider an LQR augmented control design setup. In such a setup the control objectiv e considered is twofold: • Improv e the observ ability of the system in order to av oid unobservable trajecto- ries, and • Guarantee the con ver gence of the resulting state trajectory to the equilibrium of the linear dynamics, i.e., the origin. The suggested controller assumes the form, 1 u ( x ) = − R − 1 + S ( x ) B T P x , (12) where, S is a diagonal matrix with diagonal elements, S ii ( x ) = k 1 i e − k 2 i k x k sin 2 ( k 3 i k x k + k 4 i ) , k 1 i ≥ 0 , k 4 i ∈ [ 0 , π 2 ) , i = 1 , . . . , p , and P is the solution of the Riccati equation (10). The justification for the proposed augmentation of the state feedback obtained from LQR for enhancing observability is as follows. First, from pre vious research on under - sensed nonlinear systems, it is known that desirable trajectories for improving (non- linear) observability are sinusoidal [9, 20]. In fact, sinusoidal control inputs achiev e motions in Lie bracketing directions that are generally required for having full rank observability matrix [21, 22]. Lastly , the decaying term ensures that as we approach the origin, we recov er the baseline LQR controller . Let us first establish the stability of the proposed control scheme. Proposition 1. Given the nonlinear system with a contr ollable linear dynamics and nonlinear observation (6) , the contr ol given by (12) asymptotically stabilizes the sys- tem. Pr oof. As the linear state dynamics is controllable, the control u 0 ( x ) = − R − 1 B T P x asymptotically stabilizes the system (6). Now , consider the L yapunov function V ( x ) = x T P x with the control u ( x ) given in (12). Note that the L yapunov function is positi ve definite. Furthermore, ˙ V ( x ) = x T P ˙ x + ˙ x T P x = x T − Q − PBR − 1 B T P − 2 PBSB T P x . (13) 1 W e note that if in fact, the sole purpose enhancing observ ability is state feedback, then the proposed controller needs be implemented using the estimated state instead; see § 5 for the example. For the purpose of this paper- ho wev er, we focus on augmented control synthesis for observability enhancement assuming the av ailability of the state. 5 Since S ii ≥ 0 ( i = 1 , · · · , p ) , the matrix S is a positiv e semi-definite. Since we hav e R − 1 0, then, ˙ V < 0 for all nonzero x proving the statement of the theorem. 4. Selection of Parameters f or the A ugmented Controller W e now consider the follo wing augmented cost functional, min x , u J = Z t f 0 l 1 ( x , u ) − wl 2 ( t , x , x ± 1 , · · · , x ± n ) d t , (14) where, l 1 ( · ) = x T Q x + u T R u , l 2 ( · ) = e − α t 4 ε 2 n ∑ i = 1 h ( x + i ) − h ( x − i ) 2 , (15) and w is a scalar determining the weight of the observability term ( l 2 ). The proposed cost functional consists of two parts: • The first term, l 1 ( x , u ) , takes into account the control ener gy and the deviation from the desired steady state trajectory; in our setup we assume that Q and R are positiv e definite. • The observability index, l 2 ( t , x , x ± 1 , · · · , x ± n ) , is a discounted version of the trace of the observ ability Gramian (given in (5)), which is a transient term, and takes into account the local observability of the system. In the cost function (14), the sum of the control effort (i.e., the integral of the u T R u term) and the deviation from the desired trajectory (i.e., the inte gral of the x T Q x term) is minimized, while maximizing an observability inde x. The index l 1 ( x , u ) determines the asymptotic beha vior of the closed loop system, while l 2 ( t , x , x ± 1 , · · · , x ± n ) specifies the desired transient behavior of the system. This cost function does not directly maxi- mize observ ability . Instead, the observ ability term, l 2 ( t , x , x ± 1 , · · · , x ± n ) , tunes the cost function so that the obtained optimal control makes the system more observable. W e note that maximizing the index of observ ability in the absence of the remaining terms does not guarantee the stability of system. Although we have showed that the suggested control does not destabilize the sys- tem, howe ver , our goal is that the sum of the control effort and the states cost ( l 1 ( · ) ) is the dominant term, if possible. As mentioned earlier, the main task of the observ ability term ( wl 2 ( · ) ) is tuning the optimal trajectory . In the next theorem, we will show there always e xist the parameters ( w and α ) to achiev e this goal. Theorem 1. Given l 1 and l 2 cost functions in (15) , if the output function, h ( x ) , is Lipschitz continuous, and the closed loop system is stable, then ther e always exist w and α such that for all t and nonzero x , u , we have l 1 ( · ) − wl 2 ( · ) > 0 . Pr oof. Since the output function, h ( x ) , is Lipschitz continuous, there exists L such that h ( x + i ( t )) − h ( x − i ( t )) 2 ≤ L 2 x + i ( t ) − x − i ( t ) 2 , ∀ t . (16) 6 As ¯ A (the “ A -matrix” of the closed loop system) is stable, x ± i ( t ) = e ¯ At ( x 0 ± ε e i ) . Therefore, x + i − x − i 2 = 2 ε e ¯ At e i 2 = 4 ε 2 e ¯ At e i 2 . Using the Lipschitz condition (16), we hav e l 2 ( · ) = e − α t 4 ε 2 n ∑ i = 1 h ( x + i ) − h ( x − i ) 2 ≤ L 2 e − α t 4 ε 2 n ∑ i = 1 x + i − x − i 2 = L 2 e − α t n ∑ i = 1 e ¯ At e i 2 = L 2 e − α t e ¯ At 2 F . (17) Furthermore, e ¯ At F ≤ √ n e ¯ At 2 ; as such, we hav e l 2 ( · ) ≤ nL 2 e − α t e ¯ At 2 2 . Again by stability of ¯ A , it also follows that, ∃ K , a > 0 , e ¯ At 2 ≤ K e − at , ∀ t ≥ 0 . If we pick w such that w ≤ λ min ( Q ) k x 0 k 2 nL 2 K 2 , (18) then wl 2 ( · ) ≤ λ min ( Q ) k x 0 k 2 e − ( α + 2 a ) t . W e also know that x T Q x = x T 0 e ¯ A T t Qe ¯ At x 0 = Q 1 2 e ¯ At x 0 2 ≥ λ min ( Q ) e ¯ At x 0 2 . Thus, x T Q x − wl 2 ( · ) ≥ Q 1 2 e ¯ At x 0 2 − λ min ( Q ) k x 0 k 2 e − ( α + 2 a ) t ≥ λ min ( Q ) e ¯ At x 0 2 − k x 0 k 2 e − ( α + 2 a ) t . (19) Now we can select α to satisfy the following condition: α ≥ σ 2 max ( ¯ A ) − 2 a . (20) Then, x T Q x − wl 2 ( · ) ≥ 0 . Using (18) and (20), we now ha ve l 1 ( · ) − wl 2 ( · ) = { x T Q x − wl 2 ( · ) } + u T R u ≥ u T R u > 0 , for nonzero u , concluding the proof. 7 Note that since we do not kno w the exact v alues of ¯ A and x 0 at the beginning, we need to have an initial guess of these values and set w and α . The values of l 1 and l 2 need to be monitored, and if l 1 − wl 2 < 0, we need to update the values of w and α until they meet the condition. The optimal control u ∗ is hence obtained from solving minimize Z t f 0 l 1 ( x , u ) − wl 2 ( t , x , x ± 1 , · · · , x ± n ) d t subject to u = − R − 1 + S ( x ) B T P x . (21) By substituting u = − R − 1 + S ( x ) B T P x into (21), the cost functional can be approx- imated as, J ( k 1 , · · · , k 4 ) = Z t f 0 Γ ( t , x , x ± 1 , · · · , x ± n , k 1 , · · · , k 4 ) d t , (22) where Γ ( · ) = x T PB ( R − 1 + 2 S + S RS ) B T P + Q x − wl 2 ( t , x , x ± 1 , · · · , x ± n ) . (23) Considering the abov e nonlinear system, the following optimization problem can now be considered for control synthesis: minimize k 1 , ··· , k 4 J ( k 1 , · · · , k 4 ) = Z t f 0 Γ ( t , x , x ± 1 , · · · , x ± n , k 1 , · · · , k 4 ) d t subject to ˙ x = A − B ( R − 1 + S ) B T P x , x ( 0 ) = x 0 , ˙ x ± k = A − B ( R − 1 + S ) B T P x ± k , x ± k ( 0 ) = x 0 ± ε e k , k = 1 , · · · , n . (24) In the next section, we delve into designing an algorithm for obtaining the parameters k 1 , · · · , k 4 in order to solve (24). 4.1. Optimization Algorithm In this section, an algorithm is presented to solve (24) to determine the control policy for the control objective with an embedded observability index. Here, a recursive gradient-based algorithm is devised to find the solution to this optimization problem. Giv en (22), we first define a new v ariable, x n + 1 , as x n + 1 ( t ) = Z t 0 Γ ( τ , x ( τ ) , x ± 1 ( τ ) , · · · , x ± n ( τ ) , k 1 , · · · , k 4 ) d τ . (25) Assuming that x ( 0 ) = x 0 is given, it is clear that x n + 1 ( 0 ) = 0 and x n + 1 ( t f ) = J ( · ) . Next, define an augmented state vector as ¯ x ( t ) = x ( t ) x ± 1 ( t ) . . . x ± n ( t ) x n + 1 ( t ) . 8 Then, ˙ ¯ x = ˙ x ˙ x ± 1 . . . ˙ x ± n ˙ x n + 1 = H ( t , ¯ x , k 1 , · · · , k 4 ) ; ¯ x ( 0 ) = x 0 x 0 ± ε e 1 . . . x 0 ± ε e n 0 , (26) where, H ( t , ¯ x , k 1 , · · · , k 4 ) = A − B ( R − 1 + S ) B T P 0 0 0 . . . 0 0 0 A − B ( R − 1 + S ) B T P x x ± 1 . . . x ± n Γ ( t , x , x ± 1 , · · · , x ± n , k 1 , · · · , k 4 ) , (27) and Γ ( · ) is gi ven in (23). The optimization problem can now be formulated as: minimize k 1 , ··· , k 4 J = x n + 1 ( t f ) subject to ˙ ¯ x = H ( t , ¯ x , k 1 , · · · , k 4 ) . (28) In order to solve this optimization problem, the gradient ∂ J ∂ k j = ∂ x n + 1 ∂ k j t = t f , is required [23]. By defining ¯ X k j = ∂ ¯ x ∂ k j , and applying the chain rule, we hav e ˙ ¯ X k j = ∂ H ∂ ¯ x ∂ ¯ x ∂ k j + ∂ H ∂ k j = ∂ H ∂ ¯ x ¯ X k j + ∂ H ∂ k j , ¯ X k j ( 0 ) = 0 , j = 1 , · · · , 4 . (29) Here, ∂ H ∂ ¯ x and ∂ H ∂ k j can be computed from the giv en form of Γ ( · ) . Thereby , the matrix differential equation (29) becomes a time v arying linear ordinary dif ferential equation that should be solved along with (26) for 0 < t < t f . The last ro w of ¯ X k j , j = 1 , · · · , 4 at t = t f contains the gradient vectors which can be used for improving the parameter k j . As such, one can adopt a gradient descent algorithm for obtaining the optimal gains k ∗ j . Note that we can also use an estimate of the Hessian matrix to make sure that the optimal point is a minima of the objective (and not a saddle point), e.g., by adopting a finite difference approximation for estimating the Jacobian presented in [24, 25]. 5. Illustrative Examples In this section, we consider two examples that demonstrate the application of the results discussed in the paper . The first example pertains to a suitably constructed nonlinear system; the second example pertains to a network of linear systems over an undirected graph. 9 In the first example, the control synthesis procedure proposed in this paper is il- lustrated on a (simple) holonomic system with a nonlinear measurement. The system dynamics is giv en by ˙ x 1 = u 1 , ˙ x 2 = u 2 . (30) In this case, we hav e a linear system ˙ x = A x + B u , where, A = 0 and B = I . Since rank ( B ) = 2 the system is controllable. By choosing Q = R = I and solving the alge- braic Riccati equation A T P + P A − PBR − 1 B T P + Q = 0, we obtain P = I . Thus, the control policy u LQR = − R − 1 B T P x = − x asymptotically stabilizes (30). Utilizing this state feedback controller requires full state estimation, which necessitates an observ- able system. In the meantime, if for any portion of the trajectory the state is not ob- servable, we hav e no means of implementing the LQR-based state feedback controller . Due to this coupling between sensing and control, we can in vestigate the observability of the system after applying the controller . Assume that the position of the vehicle is continuously measured by an omni-directional camera centered at the origin (bearing measurement). Then, the output function is giv en as, 2 y = x 2 x 1 , (31) where y ∈ R is a bearing only measurement, providing information on the direction of the vehicle b ut not on the range. The observability matrix is no w giv en by d O = ∂ ∂ x y ˙ y . . . = − x 2 x 2 1 1 x 1 2 x 2 x 3 1 u 1 − 1 x 2 1 u 2 − 1 x 2 1 u 1 . . . . . . . (32) The system is locally observable if the observability matrix d O is full rank [26]. The observability matrix for the nonlinear system, howe ver , has infinite ro ws. Here, we can show that there exists a set of control inputs such that the observ ability matrix becomes full rank. Let us consider the first two ro ws of the observability matrix; then we hav e det ( d O ) = 1 x 3 1 u 2 − x 2 x 1 u 1 . Hence when u 2 6 = x 2 x 1 u 1 , the observability matrix is full rank, and as a result, the system is observable. Now , if we substitute the optimal control obtained from LQR, u LQR = − x , we hav e ˙ y = ˙ x 2 x 1 − ˙ x 1 x 2 x 2 1 = − x 1 x 2 + x 1 x 2 x 2 1 = 0 . (33) All other differential terms are zero ( ¨ y = y ( 3 ) = . . . = 0). Thereby by applying the control u LQR = − x , the observability matrix is rank deficient, and the system is not 2 W e note that the measurement function in this e xample, y , is undefined in case of x 1 = 0. Here, we ha ve assumed that x 1 6 = 0 , ∀ t . 10 observable with this choice of control. This phenomena is well kno wn in computer vision and stems from the fact that we cannot “observe” range between the camera and the vehicle from bearing measurements only . Therefore, while we have optimal controls for this type of linear system, the nonlinear measurement needs to be managed appropriately for observability . Now we augment the observ ability inde x to the optimization problem. Assume that the instantaneous “observability” inde x is given by: l 2 ( · ) = e − α t 4 ε 2 y + 1 ( t ) − y − 1 ( t ) 2 + y + 2 ( t ) − y − 2 ( t ) 2 . The modified optimal control is thus giv en by u i ( x ) = − 1 + k 1 i e − k 2 i k x k sin 2 ( k 3 i k x k + k 4 i ) ! x i , i = 1 , 2 . (34) The resulting trajectories for the initial condition ± 4 , ± 4 are depicted in Fig. 1. The optimal controller chooses a trajectory that is not necessarily the closest path to the origin. The observability-based optimal control initially keeps the system away from an unobserv able trajectory (that would hav e led to mo ving directly to wards the origin), while keeping the shortest path to the origin, and e ventually returning to the desired equilibrium. Although, the observability-based controller chooses the longer path, it guarantees the system observability in order to estimate the state information required for implementing the state feedback control. -4 -2 0 2 4 x 1 -4 -3 -2 -1 0 1 2 3 4 x 2 Figure 1: T rajectories for the system (30) and measurement (31) with observability-based optimal control. Here, we compare the optimal LQR control without the observability term and the modified optimal control giv en in (34) that considers the observability of the system. The optimal controls for these two scenarios are given in Fig. 2. As it can be seen in this figure, initially the modified optimal control deviates from the optimal LQR control, howe ver , over time, the observability term becomes less dominant, and the absolute values of the observability-based control take the lead with respect to their corresponding LQR optimal control to satisfy the asymptotic stability condition. 11 0 0.5 1 1.5 2 2.5 3 time 1 2 3 4 5 6 7 8 control u LQR u 1 modified u 2 modified Figure 2: Optimal controls for the system (30) and measurement (31) using LQR optimal state feedback control without (solid line) and with (dashed lines) observability-based optimal control. T o further demonstrate the utility of the proposed observability-based control syn- thesis procedure, an extended Kalman filter (EKF) is considered to estimate the states of this linear system with a nonlinear measurement dynamics. The EKF is implemented in MA TLAB in accordance with the presentation in [27]. Estimates are initialized to ˆ x 0 = 1 . 25 x 0 with an initial covariance matrix of P = I . Simulation results using the augmented observability-based control are shown in Fig. 3. As shown in this figure, state estimates conv erge to the true state values for the proposed augmented feedback. In contrast, results for the LQR control are shown in Fig. 4. As explained abov e, since this system is not observable with the LQR control, the corresponding estimator does not hav e desirable conv ergence property . 0 0.5 1 1.5 2 2.5 3 -5 0 5 x 1 true -x 1 estimated estimation results 0 0.5 1 1.5 2 2.5 3 t (sec) -5 0 5 x 2 true -x 2 estimated (a) 0 0.5 1 1.5 2 2.5 3 0 2 4 6 x 1 true estimated 0 0.5 1 1.5 2 2.5 3 t (sec) 0 2 4 6 x 2 (b) Figure 3: State trajectories and estimates for the augmented control. (a) States estimation errors and 3 σ bounds from the EKF estimator . (b) True and estimated states. W e note that the above example can be extended to hav e any system matrix A , leading to an unobserv able system as long as the control input remains linear . In the next example we consider the consensus problem over an undirected network of three dynamic agents on a complete graph. W e assume that there is control on all nodes of 12 0 0.5 1 1.5 2 -10 0 10 x 1 true -x 1 estimated estimation results 0 0.5 1 1.5 2 t (sec) -10 0 10 x 2 true -x 2 estimated (a) 0 0.5 1 1.5 2 0 2 4 6 x 1 true estimated 0 0.5 1 1.5 2 t (sec) 0 2 4 6 x 2 (b) Figure 4: State trajectories and estimates for the baseline LQR control. (a) States estimation errors and 3 σ bounds from the EKF estimator . (b) True and estimated states. this network. The corresponding dynamics can be written as [28], ˙ x = − 2 1 1 1 − 2 1 1 1 − 2 x + 1 1 1 u . If we solve the optimal LQR control for Q = I and R = 1, we ha ve u LQR = − 0 . 5774 x 1 − 0 . 5774 x 2 − 0 . 5774 x 3 . W e assume that the agents are equipped with a compass and a sensor which can mea- sure bearing to nearby agents. In our 3-node example, the first agent observes the relativ e value of the other nodes with respect to its own state. Thus, the observation of the first agent is giv en by , y 1 = x 2 x 1 x 3 x 1 T . It can be shown that this network with bearing only measurement becomes unobserv- able under the linear time in variant LQR control. W e can sho w that there always e xists some initial condition for which the network with bearing only measurements is unob- servable. Assume for example that x ( 0 ) = v , where v is an eigen vector of A − BK , and K = 0 . 5774 0 . 5774 0 . 5774 is the linear state feedback. Then ˙ x = λ x , where λ is the eigen value associated with eigen vector v . Thus, x ( t ) = e λ t x ( 0 ) , and x j ( t ) x k ( t ) = e λ t x j ( 0 ) e λ t x k ( 0 ) = x j ( 0 ) x k ( 0 ) = constant . Therefore, all time derivati ves of the output is zero, i.e., d i dt i x j x k = 0 for all i ≥ 1, and since the number of measurements for each node (which is equal to the number of neighbors of that node) is always less than the dimension of the system (which is equal to the number of all nodes), the observability matrix cannot be full rank and agents are not able to reconstruct the states that are required for utilizing feedback control. 13 In both cases mentioned abov e, the states can not be reconstructed using bearing measurements only . More generally , it can be shown that any system with linear dy- namics can be made to be unobserv able with arbitrary linear control inputs for some nonlinear measurement. Assume for example that we hav e a linear dynamics of the form ˙ x = A x + B u with a linear control inputs u = K x and a nonlinear observation y = h ( x ) , y ∈ R m . Now let z = h ( x ) ; if we consider the set of nonlinear observations whose time deriv ativ es can be written as ˙ y = H 1 x + H 2 z , then we hav e ˙ x ˙ z = A + BK 0 H 1 H 2 x z , y = 0 1 x z . (35) For this time-in variant system, there is a con venient observ ability test. In particular , the rank of the observability matrix, O = 0 1 H 1 H 2 H 2 H 1 + H 1 ( A + BK ) H 2 2 H 2 2 H 1 + H 2 H 1 ( A + BK ) + H 1 ( A + BK ) 2 H 3 2 . . . . . . , determines whether the system is observable [29]. W e can see that if H 1 = 0, then the system is unobservable for any linear state feedback gain K . Note that the case where H 1 = 0 is only one scenario where this unobservability phenomena occurs; we can find other combinations of the terms H 1 , H 2 that make this system unobserv able for a linear state feedback. Needless to say , the same phenomena also occurs for other classes of nonlinear measurements. As such, the synthesis procedure detailed in this paper becomes pertinent for a large class of control systems consisting of a linear state dynamics augmented with nonlinear observations. 6. Conclusion This paper is concerned with modifying the optimal control for a linear system with nonlinear measurements based on a nonlinear observability criteria. In this direction, the exponential discounted form of the empirical observ ability Gramian has been used for improving the local observability for this class of nonlinear systems. W e proposed a modified cost function that contains a term that determines asymptotic behavior of the system (similar to the con ventional LQR) in addition to a transient term responsible for maximizing a notion of nonlinear observ ability . Hence the augmented cost func- tion becomes a combination of quadratic and non-quadratic terms, motiv ated by the desire to maximize the observability of the nonlinear system. W e then considered the stability of this augmented closed loop system; in particular, we proposed an oscilla- tory feedback control to increase stability properties of the feedback system while also improving the observability of the nonlinear system. A method w as then proposed that relies on superimposing a transient time-varying oscillatory term on a stabilizing con- troller; it is sho wn that the addition of this transient term does not af fect the asymptotic stability of this class of nonlinear systems. 14 A CKNO WLEDGMENTS The authors thank Bill and Melinda Gates for their activ e support and their sponsor- ship through the Global Good Fund. The research of M. Mesbahi has been supported by ONR grant N00014-12-1-1002 and NSF grant SES-1541025. Constructi ve sugges- tions and comments by the Associate Editor and revie wers of this manuscript are also acknowledged. References References [1] A. Alaeddini, K. A. Morgansen, Autonomous state estimation using optic flow sensing, in: American Control Conference, 2013, pp. 585–590. [2] B. T . Hinson, K. A. Morgansen, Observability optimization for the nonholonomic integrator , in: American Control Conference, 2013, pp. 4257–4262. [3] A. Alaeddini, K. A. Morgansen, T rajectory design for a nonlinear system to insure observability , in: European Control Conference, IEEE, 2014, pp. 2520–2525. [4] J. D. Quenzer , K. A. Morgansen, Observability based control in range-only un- derwater vehicle localization, in: American Control Conference, 2014, pp. 4702– 4707. [5] P . Baccou, B. Jouvencel, Homing and navigation using one transponder for auv , postprocessing comparisons results with long base-line na vigation, in: Interna- tional Conference on Robotics and Automation, V ol. 4, 2002, pp. 4004–4009. [6] M. B. Larsen, Synthetic long baseline navigation of underwater vehicles, in: OCEANS 2000 MTS/IEEE Conference and Exhibition, V ol. 3, 2000, pp. 2043– 2050. [7] S. C. Nardone, V . J. Aidala, Observability criteria for bearings-only target mo- tion analysis, IEEE Transactions on Aerospace and Electronic Systems (2) (1981) 162–166. [8] S. Hammel, V . Aidala, Observ ability requirements for three-dimensional tracking via angle measurements, IEEE Transactions on Aerospace Electronic Systems 21 (1985) 200–207. [9] F . Lorussi, A. Marigo, A. Bicchi, Optimal exploratory paths for a mobile rover , in: Proceedings IEEE International Conference on Robotics and Automation, V ol. 2, 2001, pp. 2078–2083. [10] L. DeVries, S. J. Majumdar , D. A. Paley , Observability-based optimization of coordinated sampling trajectories for recursi ve estimation of a strong, spatially varying flowfield, Journal of Intelligent & Robotic Systems 70 (1-4) (2013) 527– 544. 15 [11] H. Y u, R. Sharma, R. W . Beard, C. N. T aylor , Observability-based local path planning and collision av oidance for micro air vehicles using bearing-only mea- surements, in: American Control Conference, 2011, pp. 4649–4654. [12] C. B ¨ ohm, R. Findeisen, F . Allgoe wer, A voidance of poorly observable trajecto- ries: A predictiv e control perspectiv e, IF A C Proceedings V olumes 41 (2) (2008) 1952–1957. [13] A. Alessandretti, A. P . Aguiar , C. N. Jones, A model predictive control scheme with additional performance index for transient behavior , in: Proceedings of the 52nd Conference on Decision and Control, 2013, pp. 5090–5095. [14] R. Hermann, A. J. Krener, Nonlinear controllability and observability , IEEE T ransactions on Automatic Control 22 (5) (1977) 728–740. [15] E. D. Sontag, Y . W ang, I/O equations for nonlinear systems and observation spaces, in: Proceedings of the 30th IEEE Conference on Decision and Control, 1991, pp. 720–725. [16] A. J. Krener , K. Ide, Measures of unobservability , in: Proceedings of the 48th Conference on Decision and Control, held jointly with the 2009 28th Chinese Control Conference, 2009, pp. 6401–6406. [17] P . M ¨ uller , H. W eber , Analysis and optimization of certain qualities of controlla- bility and observability for linear dynamical systems, Automatica 8 (3) (1972) 237–246. [18] A. K. Singh, J. Hahn, Determining optimal sensor locations for state and param- eter estimation for stable nonlinear systems, Industrial & Engineering Chemistry Research 44 (15) (2005) 5645–5659. [19] M. Serpas, G. Hackebeil, C. Laird, J. Hahn, Sensor location for nonlinear dy- namic systems via observability analysis and max-det optimization, Computers & Chemical Engineering 48 (2013) 105–112. [20] B. T . Hinson, M. K. Binder , K. A. Morg ansen, Path planning to optimize observ- ability in a planar uniform flow field, in: American Control Conference, 2013, pp. 1392–1399. [21] A. R. T eel, R. M. Murray , G. C. W alsh, Non-holonomic control systems: from steering to stabilization with sinusoids, International Journal of Control 62 (4) (1995) 849–870. [22] R. M. Murray , S. S. Sastry , Nonholonomic motion planning: Steering using sinu- soids, IEEE T ransactions on Automatic Control 38 (5) (1993) 700–716. [23] P . Esfahani, F . Farokhi, M. Karimi-Ghartemani, Optimal state-feedback design for non-linear feedback-linearisable systems, Control Theory & Applications, IET 5 (2) (2011) 323–333. 16 [24] J. C. Spall, Adaptiv e stochastic approximation by the simultaneous perturbation method, IEEE T ransactions on Automatic Control 45 (10) (2000) 1839–1853. [25] A. Alaeddini, D. J. Klein, Application of a second-order stochastic optimization algorithm for fitting stochastic epidemiological models, 2017 Winter Simulation Conference (WSC) (2017) 2194–2206. [26] H. Nijmeijer , A. V an der Schaft, Nonlinear dynamical control systems, Springer Science & Business Media, 1990. [27] J. L. Crassidis, J. L. Junkins, Optimal estimation of dynamic systems, CRC press, 2011. [28] M. Mesbahi, M. Egerstedt, Graph theoretic methods in multiagent networks, V ol. 33, Princeton Univ ersity Press, 2010. [29] R. W . Brockett, Finite dimensional linear systems, V ol. 74, SIAM, 2015. 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment