Meeting Transcription Using Virtual Microphone Arrays
We describe a system that generates speaker-annotated transcripts of meetings by using a virtual microphone array, a set of spatially distributed asynchronous recording devices such as laptops and mobile phones. The system is composed of continuous a…
Authors: Takuya Yoshioka, Zhuo Chen, Dimitrios Dimitriadis
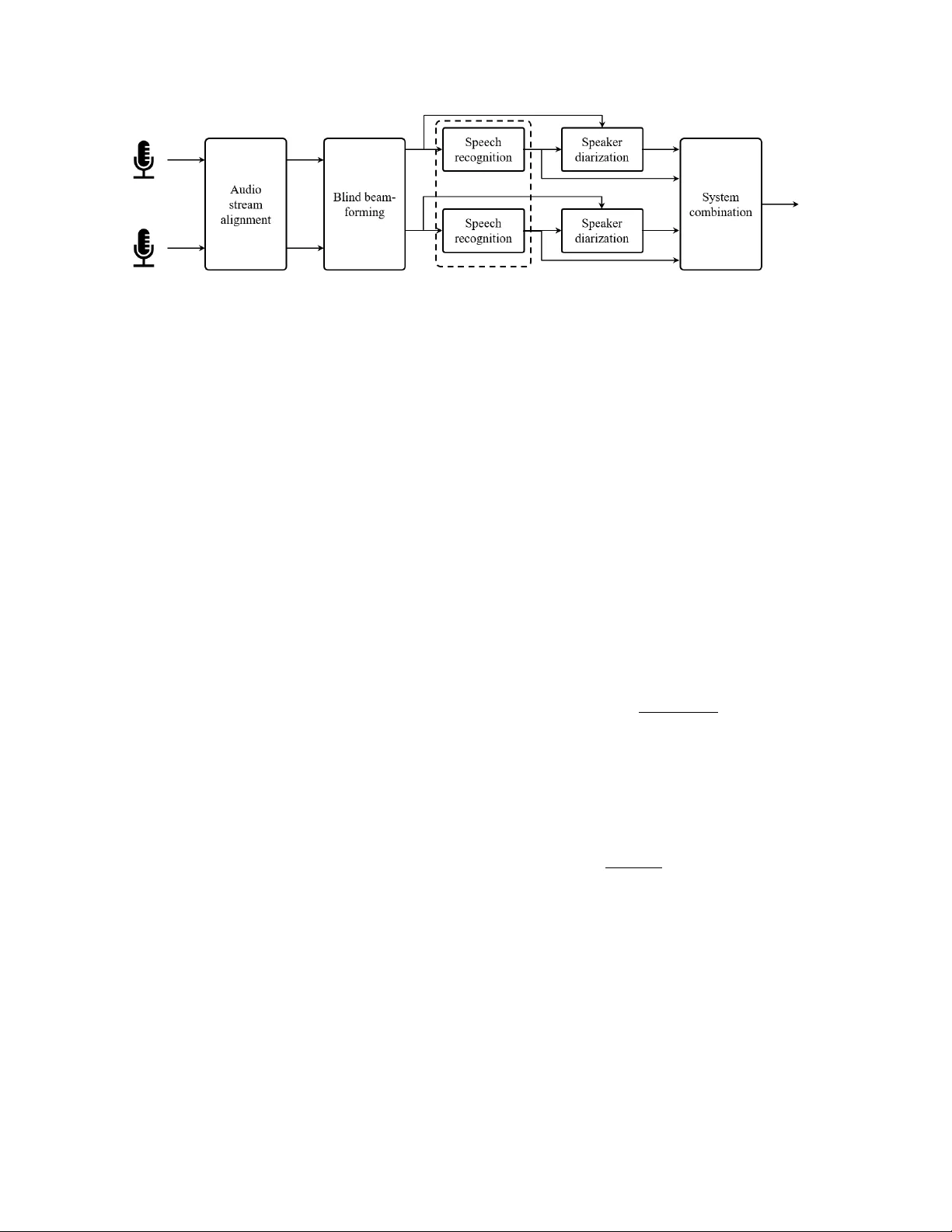
Meeting T ranscription Using V irtual Micr ophone Arrays T akuya Y oshioka, Zhuo Chen, Dimitrios Dimitriadis, W illiam Hinthorn, Xuedong Huang Andr eas Stolck e, Mic hael Zeng Microsoft T echnical Report MSR-TR-2019-11 Re vised July 2019 { tayoshio,zhuc,didimit,wihintho,xdh,anstolck,nzeng } @microsoft.com Abstract W e describe a system that generates speaker -annotated tran- scripts of meetings by using a virtual microphone array , a set of spatially distributed asynchronous recording devices such as laptops and mobile phones. The system is composed of continu- ous audio stream alignment, blind beamforming, speech recog- nition, speaker diarization using prior speaker information, and system combination. When utilizing se ven input audio streams, our system achieves a word error rate (WER) of 22.3% and comes within 3% of the close-talking microphone WER on the non-ov erlapping speech segments. The speak er-attributed WER (SA WER) is 26.7%. The relativ e gains in SA WER over the single-device system are 14.8%, 20.3%, and 22.4% for three, fiv e, and sev en microphones, respectiv ely . The presented sys- tem achieves a 13.6% diarization error rate when 10% of the speech duration contains more than one speaker . The contrib u- tion of each component to the overall performance is also in- vestigated, and we validate the system with experiments on the NIST R T -07 conference meeting test set. Index T erms : meeting transcription, asynchronous distributed microphones, distant speech recognition, speaker diarization, system combination, blind beamforming 1. Introduction Speaker -attributed automatic speech recognition (SA-ASR) of natural meetings has been one of the very challenging tasks since the early 2000s, when the NIST Rich Transcription Eval- uation series [2] started. Systems developed in the early days yielded high error rates, especially when distant microphones were used as input. Howe ver , with the rapid progress in con- versational speech transcription [3, 4]j, f ar-field speech recogni- tion [5–8], and speak er identification and diarization [9, 10], re- alizing accurate meeting transcription from a distance seems to be within reach, especially when employing microphone arrays. In addition to the microphone array setups, single-microphone systems hav e also been evaluated. The use of multiple unsynchronized audio streams, such as from mobile devices, adds comple xity to the meeting setup and processing. In return, we gain potentially better spatial cover - age since the de vices will tend to be distributed around the room and relativ ely near the speakers. Also, in many use cases it will be natural for meeting participants to bring, and then repurpose their personal devices, in the service of better transcription qual- ity . On the other hand, while there are sev eral pioneering stud- ies [11], it is unclear what the best strategies are for consoli- dating multiple asynchronous audio streams and to what extent they work for natural meetings in online and of fline setups. This report is an expanded version of a conference paper [1] with added results on NIST -R T data. In this paper , we inv estigate a meeting transcription archi- tecture based on asynchronous distant microphones by combin- ing both front-end and back-end techniques. The resulting sys- tem performance is inv estigated on real-world meeting record- ings. Our proposed system is designed to generate word recog- nition results in real time and then provide improved speaker- attributed transcriptions with limited latenc y . In addition to the end-to-end system analysis, we make the following specific contrib utions: we examine the idea of “lea ve- one-out beamforming” in the asynchronous multi-microphone setup. This method was proposed to benefit from both beam- forming and system combination approaches but tested only with synchronized signals [12]. The computational cost re- quired for calculating multiple beamformers can be reduced by taking advantage of the properties of spatial cov ariance matri- ces. W e inv estigate a similar div ersity-preserving strategy for acoustic model fusion. Further , we describe three different sys- tem combination schemes that take account of both word recog- nition and speaker attribution. Finally , we show results based on incremental RO VER that processes the ASR and diarization outputs with low latenc y . The rest of the paper is organized as follows. Section 2 de- scribes the meeting transcription task that we consider in this paper and an overall architecture of our proposed system. Sec- tion 3 elaborates on indi vidual system components with empha- sis on unique aspects of our work. Section 4 reports e xperimen- tal results, followed by concluding remarks in Section 5. 2. T ask and System Overview W e record a meeting with M audio capturing devices, such as cell phones, tablets, and laptops. The devices can be randomly placed in a conference room. The acoustic signal picked up by each device is transmitted to a common server . The server then generates a speaker-attrib uted transcription of the meeting con versation in real time as it receiv es the signals from the de- vices. In this paper , we assume that all meeting attendees have enrolled in the system and hav e provided their voice-prints for speaker identification. Figure 1 shows the processing flow of the proposed sys- tem. The input signals receiv ed by the server are misaligned for various reasons such as clock drift on each recording de- vice, differences in on-de vice signal processing, packet gen- eration, and signal transmission channels. As in Fig. 1, the audio stream alignment module constantly corrects the inter- channel signal misalignments. This is followed by a beamform- ing module, which receiv es the M time-aligned audio signals and yields N enhanced signals. In this paper , we deal with the case where M = N while this is not a requirement. Each en- hanced signal is fed to a speech recognition module to produce a real-time transcription as well as n-best recognition hypothe- Figure 1: Processing flow diagram of proposed meeting transcription system with asynchr onous multi-micr ophone input. ASR may be performed jointly acr oss channels as implied by the dotted box. ses with word-le vel time marks. The diarization module then generates a speak er label sequence for each of the segments de- tected by the ASR decoder by utilizing both word-lev el time marks and speaker embeddings e xtracted from the enhanced au- dio. Ev entually , the speaker labels and word hypotheses are processed in the system combination module to yield a final speaker -attributed w ord transcription. W e have settled on this architecture based on sev eral con- siderations: it supports both beamforming and later-stage sys- tem combination approaches, which are found to be beneficial together [12]. Also, we perform diarization after speech recog- nition, unlike in many previous systems. Since diarization typ- ically has a longer algorithmic delay this allows preliminary recognition results to be displayed in real time. Finally , sys- tem combination, coming last, is designed to merge and benefit both word recognition and speaker attrib ution. 3. System Components 3.1. A udio Stream Alignment The audio stream alignment module picks one of the input streams as a reference and aligns each of the other signals to the reference signal. When aligning a signal to the reference, the time lag between the two signals is first detected and then the non-reference signal is adjusted accordingly . For this pur- pose, we hav e two variable-length first-in-first-out buf fers for each stream: one for time lag detection, one for output gener- ation. After a few seconds (2 s in our experiments), we extract as many samples from the output buf fer as those pushed to the buf fer . These samples are given to the do wnstream modules. At T -second intervals ( T = 30 s in our experiments), we calculate the cross-correlation coefficients between the two sig- nals stored in the time-lag detection buf fer and pick the sample lag L that maximizes the cross-correlation value. W e decimate the samples in the non-reference stream output buf fer by | L | if L > 0. Otherwise, we increase the number of samples by | L | by resampling. The time-lag detection buf fer is then refreshed. T wo sources of misalignment between the signals can be distinguished, the “global” and the “local” ones. The global lag is due to the beginning of the recordings and it appears fixed. The local lag is due to clock drifting, channel delays, windows, etc. The local lag is variable and time-varying, thus requires continuous synchronization. At the beginning of the alignment processing, we may calculate the cross-correlation more fre- quently (e.g., every 1 s) until we find a significant peak in the cross-correlation sequence. This ‘global’ time lag can also be used to adjust the output wait time. In an online client-server setting, the global time lag is small. When we apply the system to offline independent recordings, the global time lag can be in the order of minutes. In this case, we may use a sliding window to first obtain an approximate estimate of the global time lag and then fine-tune the local estimates by using the sample-le vel cross-correlation as described abov e. 3.2. Blind beamforming For beamforming, we adopt a mask-based blind processing ap- proach [13, 14]. This approach was shown to perform as well as carefully designed beamformers that utilize array geometry information [15]. Mask-based blind beamforming. Assuming M microphones to be av ailable, an enhanced short time Fourier transform (STFT) coef ficients can be computed as the inner product of M - dimensional beamformer coef ficient vector w f and input multi- channel STFT coefficient vector y f t , where subscripts f and t denote frequency bin and time frame indices, respectiv ely . In one formulation, the beamformer coefficients are estimated with a minimum variance distortionless response (MVDR) principle as w f = Φ − 1 N , f Φ S , f r tr Φ − 1 N , f Φ S , f , (1) where Φ i is the spatial cov ariance matrix ( i = S for speech; i = N for noise) where r a one-hot unit vector with 1 at the position of the reference microphones, which may be chosen based on a maximum signal-to-noise ratio (SNR) principle [16]. The speech and noise spatial cov ariance matrices are estimated using spectral masks, i.e., Φ i = 1 ∑ t ∈ T M i , f t ∑ t ∈ T M i , f t y f t y H f t , (2) where T is a segment over which the beamformer is estimated, and M i , f t is the spectral mask for time-frequency point ( f , t ) . In our experiments, a neural network trained to minimize the mean squared error between clean and enhanced log-Mel features was used [15]. The spectral masks were estimated for ev ery 1 s-batch. The beamformer coefficients are also updated accordingly . Strategies for generating multiple differ ent outputs. System combination relies on errors being partly uncorrelated among inputs. For this reason, [12] suggested manipulating early- fusion approaches to keep the outputs as decorrelated as pos- sible, specifically using a lea ve-one-out approach to beamform- ing. T wo such schemes are in vestigated in this work. In the first scheme, called the all-channel approach, we ro- tate the 1’ s position in unit vector r from the first element to the last to create dif ferent beamformer coef ficient vectors based on Eqn. (1). A potential drawback of this approach is that the beamformer outputs might not retain enough diversity among different channels because they are still based on the same in- put signals. The second, “leav e-one-out” (LOO) scheme forms an acoustic beam by using M − 1 channels while varying the left- out microphone in a round-robin manner . This scheme requires M dif ferent ( M − 1 ) -dimensional noise spatial covariance matri- ces to be inv erted in order to calculate M beamformers based on Eqn. (1). It can be shown that all the M inv erse spatial covari- ance matrices of size M − 1 can be deriv ed from a shared M - dimensional inv erse spatial covariance matrix by utilizing the matrix in version properties of block and permutation matrices. Therefore, both two schemes can be run with similar computa- tional cost. 3.3. Speech recognition The speech recognition module con verts an incoming audio sig- nal to an n-best list with word-le vel time marks. In the ex- periments reported later , we used a conv entional hybrid ASR system, consisting of a latency-controlled bidirectional long short-term memory (LSTM) acoustic model (AM) [17] and a weighted finite state transducer decoder . Our AM was trained on 33K hours of in-house audio data, including close-talking, distant-microphone, and artificially noise-corrupted speech. Decoding was performed with a trigram language model (LM). Whenev er a silence segment longer than 300 ms was detected, the decoder generated an n-best list, which was rescored with both a 5-gram trained on 100B words and an LSTM-LM. The latter used two 2048-unit recurrent layers and was trained on 2B words. 3.4. Speaker diarization with prior information Giv en a speech region detected by the speech recognition mod- ule, speaker diarization assigns a person label to each word in the top recognition hypothesis. W e adopt an approach con- sisting of three steps: d-vector generation, segmentation, and speaker identification. W ith our decoder configuration, each in- coming speech region typically contains up to 20 words. The d-vector generation step calculates speaker embed- dings [18] for every fixed time interval (320 ms in our system). W e trained a ResNet-style embedding extraction network [19] on the V oxCeleb corpus [20] to generate 128-dimensional d- vectors. The speaker segmentation step decomposes the receiv ed word sequence into speaker-homogeneous subsegments. This is performed with an agglomerative clustering approach [21, 22] by using the d-v ectors as observed samples. Initially , ev ery sin- gle word comprises a unique subsegment. For ev ery neighbor- ing subsegment pair, the degree of proximity between the two subsegments is estimated in the embedding space. The closest pair is then merged to form a new subsegment. The proximity is defined as the cosine similarity between the mean d-vectors. This process is repeated until the cosine similarity drops below a threshold (0.15 in our experiments). Finally , a speaker label is assigned to each subsegment. In this paper , we assume that a list of meeting attendees is avail- able. For each subsegment, a segment-le vel embedding is com- puted by av eraging the d-vectors over the subsegment. Like- wise, the embedding of each speaker is pre-computed from enrollment audio samples, which were around 30 s long. The speaker label that gi ves the highest cosine similarity to the sub- segment embedding is selected. 3.5. System combination System combination consolidates the multiple speaker- attributed ASR results to produce a final transcription result. R O VER [23] and confusion network combination (CNC) [24, 25] are two popular system combination approaches. The goal of this step is to combine e vidence from all channels, after beamforming, for both word and speaker recognition. As dis- cussed in Section 3.4, a speaker label is assigned to ev ery word based on the acoustics of the av ailable audio streams. For pur- poses of RO VER, the speaker identities are encoded as au- dio channel numbers. Then, they are submitted to the NIST R O VER algorithm [23] along with the word hypotheses, which combines them by aligning words based on dynamic program- ming and their time marks and extracting the words with the highest vote count. W e have modified the interface to the R O VER algorithm in such a way that this process can be in- vok ed online, as new speaker-attrib uted word hypotheses be- come av ailable from the diarization module, by using a sliding window shared across streams. Due to misalignment between different decoder outputs, some words may appear twice. W e run a simple filter removing the duplicates. For CNC-based system combination, we devised an alter- nativ e algorithm that currently operates in batch mode. On each channel, for each speech segment, the decoder generates n-best lists, which are aligned into confusion networks (CNs). The speaker recognition output from each channel is also en- coded as a CN, using special tags for the speaker identities, in- terspersed with 1-best word hypotheses. W e modified the CN algorithms in SRILM [26] to support aligning word and speak er CNs, and augmented the usual minimal edit distance objective function with a time-misalignment penalty . The end result of the modified CNC is that n-best w ord hypotheses from all chan- nels are merged with the speaker information, and the speakers and words with highest combined posteriors can be decoded jointly . 3.6. Acoustic model combination In addition to the channel-fusion approaches described abov e, i.e., beamforming and system combination, it is also possible to combine frame-lev el senone posterior probabilities from multi- ple streams before ASR decoding [27]. While this approach is not integrated into the end-to-end system yet, we have in vesti- gated the effectiv eness of senone-level AM fusion, with strate- gies aimed at increasing the diversity of the output results for later processing with R O VER or CNC. The baseline results (first row) in T able 1 use senone pos- teriors from a single channel, produced by the AM and used as input to the decoder . Next, the sum and max of senone pos- teriors across channels are in vestigated. This results in a single word hypothesis stream, with R OVER/CNC combining speaker hypotheses only . Similar to the leave-one-out strategy for beam- forming, we can preserve div ersity by sampling from the chan- nels, followed by hypothesis combination. In the last two rows of T able 1, we present results with 6-out-7 senone fusion (result- ing in 7 different senone subsets), and 3-out-7 with 35 outputs. In the latter case, we sample 7 of the 35 possible outputs to re- duce computation. Either way , the 7 resulting decoding outputs are routed to system combination as before. T able 1: AM combination. Results for one particular meeting. Numbers should not be compar ed with those of other tables. R O VER CNC %WER %SA WER %WER %SA WER Baseline 25.9 28.2 25.9 28.2 Sum 25.4 28.4 24.7 28.2 Max 22.5 27.5 22.5 27.2 Max 6 of 7 23.8 27.2 22.1 26.7 Max 3 of 7 24.2 26.8 22.3 26.9 T able 2: WERs and SA WERs using seven micr ophones. Sys. Comb . Beamforming %WER %SA WER None None 27.0 34.4 (real time) All channels 24.8 30.8 Leav e one out 24.9 30.9 R O VER None 25.3 28.5 (online) All channels 24.2 27.4 Leav e one out 24.2 27.2 CNC None 22.8 27.7 (offline) All channels 22.5 26.9 Leav e one out 22.3 26.7 IHM + reference diarization 14.4 14.4 4. Experiments and Results 4.1. Data and metrics W e conducted a series of experiments to analyze the perfor- mance of the system described so far . W e recorded fiv e internal meetings; three meetings were recorded with sev en independent consumer devices, four of which were iOS devices and three based on Android. All devices were different products. The other two meetings were recorded with a seven-channel circu- lar microphone array . For these meetings, we did not make use of the fact that the signals were synchronous and let the signals through the entire pipeline including the audio stream align- ment module. Those meetings took place in several different rooms and lasted for 30 minutes to one hour each, with three to eleven participants per meeting. The meetings were neither scripted nor staged; the participants conducted normal work dis- cussions and were familiar with each other . Partly as a result, about 10% of all speech occurred in overlap with at least one other speaker . Reference transcriptions were created by pro- fessional transcribers based on both close-talking and far-field recordings. T o test for generalization to different recording conditions, we also ran our system on meeting recordings from the NIST 2007 Rich Transcription (R T -07) ev aluation [2]. This R T -07 “conference meeting” test set consists of 8 meetings from four different recording sites, of varying lengths and with the num- ber of microphones ranging from 3 to 16. Each meeting has from four to six participants, with 31 distinct speakers in to- tal. Transcription accuracy is ev aluated on a 22-minute excerpt from each meeting. The system outputs were scored with NIST’ s scoring toolkit [28] to calculate both standard, speaker-agnostic word error rates (WERs) and speaker-attrib uted WERs (SA WERs). For the latter , a word is counted as correct only if both the word label and its speaker are identified correctly . Note that these metrics count ov erlapped speech as any other . Since our sys- tem, at present, does not attempt to separate o verlapping speech we thus have a floor on the error rate of about 10% (on the in- ternal meeting data). T able 3: Impact of number of micr ophones for system based on leave-one-out beamforming and CNC. No. of microphones 1 3 5 7 %WER 27.0 24.0 22.7 22.3 %SA WER 34.4 29.3 27.4 26.7 T able 4: Speaker-independent WERs for non-overlapped se g- ments. SDM: single distant micr ophone. BF: beamforming System SDM BF BF + CNC IHM %WER 20.6 18.1 16.2 13.2 4.2. Speech transcription accuracy on internal meetings T able 2 shows the results for various system configuration, on the meetings we recorded internally . For the systems that do not perform any form of system combination, seven different results were obtained, each corresponding to a different one of the microphones, and the averages are reported in the table. As a best case condition, and to calibrate the difficulty of the distant- microphone task, the final table row giv es results for individual head-mounted microphones (IHM), with reference speak er se g- mentation. The best system, combining beamforming and CNC, achiev ed substantial improvement over the single microphone system. The WER and SA WER relative gains were 17.4% and 22.4%, respectively . Relative to the IHM scenario as a floor , WER and SA WER were reduced by 37% and 39%, respectively . W e can see that both beamforming and system combina- tion (either with R O VER or CNC) contributed to the final per- formance, e ven though both steps combined information across channels. CNC provided the largest performance gain. While beamforming yielded a smaller gain, it is more easily used for real-time applications. The leave-one-out scheme provided slightly larger gains than the all-channel beamforming when combined with system combination, especially CNC, confirm- ing our rationale in Section 3.2. T able 3 shows the WERs and SA WERs for different num- bers of microphones. There is a clear correlation between the number of microphones and the amount of improvement over the single channel system. Even with only three microphones, our system yielded relativ e gains of 11.1% and 14.8% in WER and SA WER, respectiv ely . T o assess the speech recognition accuracy when a single person is speaking, we scored the results only against se gments that did not contain any forms of overlap. 1 Note that this dis- carded 58% of the words. The results are shown in T able 4. By comparing the numbers with the results of T able 2, we can see that the system produced around 25% more accurate transcrip- tions for the non-overlapped segments. For the full system, the WER on non-overlapped speech is only 3.0% worse than with close-talking microphones. Considering that the overlaps make up about 10% of the speech duration, this result shows that segments including overlaps are more affected by the speaker- microphone distance. 4.3. Speech transcription accuracy on RT -07 meetings While these meeting recordings in the NIST R T -07 set are already synchronized, we ran the front-end processing un- changed, and simply removed the word deduplication step in the final hypothesis processing. W e ev aluated the system in all three 1 This was done by using NIST’ s asclite with the “-overlap-limit 1” option. T able 5: W or d error rate on NIST RT -07 meetings. The three MDM versions use no beamforming, beamforming on all mi- cr ophones, and the leave-one-one appr oach, r espectively . Evaluation condition No overlap Overlap ≤ 4 SDM 16.7 28.2 MDM: CNC 15.5 26.2 MDM: All-mic-BF + CNC 14.8 26.3 MDM: LOO-BF + CNC 14.6 26.0 IHM 12.3 15.9 NIST ev aluation conditions: single distant microphone (SDM), multiple distance microphones (MDM), and close-talking mi- crophones (IHM). SDM uses a single microphone designated by NIST , supposedly centrally located. SDM and MDM used automatic speech detection, whereas IHM was run using the reference segmentation, since this task otherwise requires cross- talk suppression and we did not want to confound the results. 2 Another ev aluation variable is the degree of overlap allowed in the scored segments. Here we scored the outputs both on the non-ov erlapped se gments and those with up to four overlapping speakers. 3 T able 5 summarizes the results. First, note that IHM er- ror rates are very similar to those on our internal meetings (12-13% for non-overlapping speech), showing that the intrin- sic speech recognition dif ficulty is similar . The SDM WER (28.2%) is also similar to the average single-microphone WER in the earlier tests (27.0%). Howe ver , the relative WER reduc- tion from multi-microphone processing (using both CNC and LOO-beamforming), is only 7.8%. This is much less than the 17.4% reduction for the internal meeting set (comparing the first line in T able 2 with the next-to-last line). One reason could be that the microphones in most meetings of this test set were located so closely that the extra microphones yield less additional information, compared with with the distributed, multiple-device setup used in our internal meetings. Although the performance gains from the MDM process- ing were smaller, the algorithms used in our system still each giv e substantial gains, especially on non-overlapped speech seg- ments. Beamforming in conjunction with CNC is 4.5% bet- ter than CNC alone, and leave-one-out processing improves the relativ e gain to 5.8%. Overall, the WER for non-overlapped speech that is achieved with multiple microphones is 12.6% relativ e lower than for SDM, and only 2.3% higher than with close-talking microphones. This gap between MDM and IHM is again similar to the 3.0% g ap found for the internal meetings. For a further e xamination of the effect of number of micro- phones on the different system versions, we chose the 5 (out of 8) R T -07 meetings with six or more microphones. W e then ran recognition with subsets of 1, 2, . . . , 6 microphones, taking care to always include the SDM channel, and making sure that the subsets were nested (i.e., nev er removing any microphones). Figure 2 plots the WERs on non-overlapping segments of the 5-meeting subset, for CNC without beamforming (No BF), 2 T eams participating in the original R T -07 ev aluation typically found that automatic IHM segmentation g av e WERs about 1-3% higher than with reference segments [29]. Note that error rates reported here are much lower than in the original ev aluation, reflecting general ad- vances in speech recognition. Also, the training data for the original ev aluation was limited to shared, publicly available corpora, while our system had no such restriction. 3 W e stopped at four because the run-time for scoring grows expo- nentially with the allo wed degree of overlap. With this limit, only 2.3% of all transcribed words are excluded. Figure 2: Effect of varying number of micr ophones for differ ent pr ocessing strate gies (WERs on NIST RT -06 5-meeting subset) T able 6: Diarization err or on speaker-attributed ASR output. The percenta ge of overlapped speech is 10.0%, and accounts for most of the missed speech. Misses F Alarms SpkrErr DER A vg. by channel 10.5 3.3 1.8 15.6 CNC output 10.2 2.4 1.0 13.6 all-microphone beamforming, and leav e-one-out beamforming. The right-most datapoint (“7+”) on each line refers to process- ing with all av ailable microphones (up to 16 for some meet- ings). The IHM error rate is shown as a single datapoint (at lower right). A few observations are noteworthy . First, without beam- forming (CNC only) we see a degradation going from one to two microphones. This is not surprising if the second micro- phone has much worse recognition than the first (SDM) one, since CNC does not work reliably if the input systems are of very different quality (unless that fact is known in advance and the systems can be weighted appropriately). Beamforming has the effect of creating audio streams of similar quality , thereby av oiding this problem for CNC. Second, the lea ve-one-out strategy is not advantageous with four or fewer microphones. This can be understood from the fact that removing a microphone from the beam in itself will make the results worse, and is only a win because the effec- tiv eness of CNC is improved. If very few microphones are av ailable to begin with, the degradation due to the first effect can be larger than the gain from the second. Therefore, when used in conjunction with system combination, the beamforming strategy should be chosen depending on the number of av ailable microphones. 4.4. Speaker diarization accuracy Since the speaker attribution algorithm at present relies on speaker enrollment, we ev aluated its accuracy on internal meet- ings only . W e took the speaker-attributed recognition output, added 0.5 s of extra duration at the margins of contiguous out- put from the same speaker , and e valuated the result according to the NIST “Who spoke when” task [22]. Note that our task is not speaker -agnostic diarization, but recognizing the known speak- ers. Also, we are not trying to recognize ov erlapping speakers, so about 10% of speech is missed, thus putting a floor on the missed speech and ov erall diarization error rate (DER). T able 6 gives the speaker diarization error of the system, by channel and for the combined output. The false alarm rate is quite low since the recognizer acts as a very conservativ e speech detection engine. Similar to word recognition, CNC reduces the speaker error (44% relative) by pooling speaker label posterior probabilities across all channels. 5. Conclusion W e studied a meeting transcription architecture for asyn- chronous distant microphones, combining front-end and back- end techniques, and ev aluated it on real meeting recordings. W e found that both front-end (blind beamforming) and back-end (model or system combination) algorithms improve word er- ror , speaker-attrib uted word error , and diarization error metrics. Both beamforming and senone posterior fusion can be made more effecti ve in conjunction with system combination by us- ing leave-one-out techniques. System combination was gener- alized such that it benefits both word and speaker hypotheses. On non-overlapped speech, the error rate is only 3.0% absolute worse than with close-talking microphones. W e found broadly consistent results on NIST meeting ev aluation data, with 2.3% absolute WER dif ference between distant and close-talking mi- crophones, for non-overlapped speech. In summary , our study shows the effecti veness of multiple asynchronous microphones for meeting transcription in real-world scenarios. A major re- maining challenge is recognition of ov erlapped speech [30]. 6. References [1] T . Y oshioka, D. Dimitriadis, A. Stolck e, W . Hinthorn, Z. Chen, M. Zeng, and X. Huang, “Meeting tran- scription using asynchronous distant microphones, ” in Pr oc. Interspeech , Graz, Sep. 2019. [Online]. A vail- able: https://www .microsoft.com/en- us/research/publication/ meeting- transcription- using- asynchronous- distant- microphones/ [2] J. G. Fiscus, J. Ajot, and J. S. Garofolo, “The Rich Transcription 2007 meeting recognition evaluation, ” in Multimodal T echnolo- gies for P erception of Humans. International Evaluation W ork- shops CLEAR 2007 and RT 2007 , ser . Lecture Notes in Computer Science, R. Stiefelhagen, R. Bowers, and J. Fiscus, Eds. Berlin: Springer , 2008, vol. 4625, pp. 373–389. [3] G. Saon, G. Kurata, T . Sercu, K. Audhkhasi, S. Thomas, D. Dimitriadis, X. Cui, B. Ramabhadran, M. Picheny , L. Lim, B. Roomi, and P . Hall, “English con versational telephone speech recognition by humans and machines, ” in Proc. Interspeech , Aug. 2017, pp. 132–136. [Online]. A vailable: https://arxiv .org/abs/1703.02136 [4] W . Xiong, L. W u, F . Allev a, J. Droppo, X. Huang, and A. Stolck e, “The Microsoft 2017 con versational speech recognition system, ” in Pr oc. IEEE ICASSP , Apr. 2018, pp. 5934–5938. [Online]. A vailable: https://arxiv .org/abs/1708.06073 [5] T . Y oshioka, N. Ito, M. Delcroix, A. Ogaw a, K. Kinoshita, M. Fu- jimoto, C. Y u, W . J. Fabian, M. Espi, T . Higuchi, S. Araki, and T . Nakatani, “The NTT CHiME-3 system: advances in speech enhancement and recognition for mobile multi-microphone de- vices, ” in Proc. IEEE ASR U , 2015, pp. 436–443. [6] J. Du, Y . Tu, L. Sun, F . Ma, H. W ang, J. Pan, C. Liu, J. Chen, and C. Lee, “The USTC-iFlytek system for CHiME-4 challenge, ” in Pr oc. CHiME-4 W orksh. , 2016, pp. 36–38. [7] B. Li, T . N. Sainath, A. Narayanan, J. Caroselli, M. Bacchiani, A. Misra, I. Shafran, H. Sak, G. Punduk, K. Chin, K. C. Sim, R. J. W eiss, K. W . Wilson, E. V ariani, C. Kim, O. Siohan, M. W ein- traub, E. McDermott, R. Rose, and M. Shannon, “ Acoustic mod- eling for Google Home, ” in Proc. Interspeec h , 2017. [8] J. Li, R. Zhao, Z. Chen, C. Liu, X. Xiao, G. Y e, and Y . Gong, “De- veloping f ar-field speaker system via teacher-student learning, ” in Pr oc. ICASSP , 2018, pp. 5699–5703. [9] A. Zhang, Q. W an, Z. Zhu, J. Paisle y , and C. W ang, “Fully supervised speaker diarization, ” in Pr oc. IEEE ICASSP , May 2019, pp. 6301–6305. [Online]. A vailable: https://ai.google/ research/pubs/pub47549 [10] G. Sell, D. Snyder, A. McCree, D. Garcia-Romero, J. V illalba, M. Maciejewski, V . Manohar, N. Dehak, D. Povey , S. W atanabe, and S. Khudanpur, “Diarization is hard: some experiences and lessons learned for the JHU team in the inaugural DIHARD chal- lenge, ” in Proc. Interspeec h , 2018, pp. 2808–2812. [11] S. Araki, N. Ono, K. Kinoshita, and M. Delcroix, “Meeting recognition with asynchronous distributed microphone array us- ing block-wise refinement of mask-based MVDR beamformer, ” in Pr oc. IEEE ICASSP , 2018, pp. 5694–5698. [12] A. Stolcke, “Making the most from multiple microphones in meet- ing recordings, ” in Proc. IEEE ICASSP , 2011, pp. 4992–4995. [13] J. Heymann, L. Drude, and R. Haeb-Umbach, “Neural network based spectral mask estimation for acoustic beamforming, ” in Pr oc. IEEE ICASSP , 2016, pp. 196–200. [14] T . Higuchi, T . Y oshioka, N. Ito, and T . Nakatani, “Robust MVDR beamforming using time-frequency masks for online/offline ASR in noise, ” in Proc. IEEE ICASSP , 2016, pp. 5210–5214. [15] C. Boeddeker , H. Erdogan, T . Y oshioka, and R. Haeb-Umbach, “Exploring practical aspects of neural mask-based beamforming for far-field speech recognition, ” in Proc. IEEE ICASSP , 2018, pp. 6697–6701. [16] H. Erdogan, J. R. Hershey , S. W atanabe, M. Mandel, and J. Le Roux, “Improved MVDR beamforming using single-channel mask prediction netw orks, ” in Pr oc. Interspeech , 2016, pp. 1981– 1985. [17] S. Xue and Z. Y an, “Improving latency-controlled BLSTM acous- tic models for online speech recognition, ” in Pr oc. IEEE ICASSP , 2017, pp. 5340–5344. [18] E. V ariani, X. Lei, E. McDermott, I. L. Moreno, and J. Gonzalez- Dominguez, “Deep neural networks for small footprint text- dependent speak er verification, ” in Proc. IEEE ICASSP , 2014, pp. 4052–4056. [19] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in IEEE Conf. Computer V ision, P attern Recognition , June 2016, pp. 770–778. [20] A. Nagrani, J. S. Chung, and A. Zisserman, “V oxCeleb: a large-scale speaker identification dataset, ” in Pr oc. Interspeech , Aug. 2017, pp. 2616–2620. [Online]. A vailable: http://arxiv .org/ abs/1706.08612 [21] J. Gauvain, L. Lamel, and G. Adda, “P artitioning and transcription of broadcast news data, ” in Pr oc. ICSLP , 1998, pp. 1335–1338. [22] S. E. Tranter and D. A. Reynolds, “ An overvie w of automatic speaker diarization systems, ” IEEE T rans. Audio, Speech, Lan- guage Pr ocess. , vol. 14, no. 5, pp. 1557–1565, Sep. 2006. [23] J. G. Fiscus, “ A post-processing system to yield reduced word error rates: Recognizer output voting error reduction (RO VER), ” in Pr oc. IEEE ASRU , 1997, pp. 347–354. [24] A. Stolcke, H. Bratt, J. Butzberger , H. Franco, V . R. Rao Gadde, M. Plauch ´ e, C. Richey , E. Shriberg, K. S ¨ onmez, F . W eng, and J. Zheng, “The SRI March 2000 Hub-5 conversational speech transcription system, ” in Pr oc. NIST Speech T ranscription W ork- shop , College Park, MD, May 2000. [25] G. Evermann and P . W oodland, “Posterior probability decoding, confidence estimation, and system combination, ” in Proc. NIST Speech T ranscription W orkshop , College Park, MD, May 2000. [26] A. Stolcke, “SRILM—an extensible language modeling toolkit, ” in Pr oc. ICSLP , J. H. L. Hansen and B. Pellom, Eds., vol. 2, Den- ver , Sep. 2002, pp. 901–904. [27] S. Tibre wala and H. Hermansky , “Sub-band based recognition of noisy speech, ” in Proc. IEEE ICASSP , 1997, pp. 1255–1258. [28] J. G. Fiscus, J. Ajot, N. Raddle, and C. Laprum, “Multiple di- mension Levenshtein edit distance calculations for ev aluating au- tomatic speech recognition systems during simulaneous speech, ” in Pr oc. Int. Conf. Language Resources, Evaluation , 2006, pp. 803–808. [29] A. Stolcke, K. Boakye, ¨ Ozg ¨ ur C ¸ etin, A. Janin, M. Magimai-Doss, C. W ooters, and J. Zheng, “The SRI-ICSI Spring 2007 meeting and lecture recognition system, ” in Multimodal T echnologies for P erception of Humans. International Evaluation W orkshops CLEAR 2007 and RT 2007 , ser . Lecture Notes in Computer Science, R. Stiefelhagen, R. Bowers, and J. Fiscus, Eds., vol. 4625. Berlin: Springer , 2008, pp. 450–463. [Online]. A vailable: http://www .icsi.berkeley .edu/pubs/speech/sri- icsi- rt07- paper .pdf [30] T . Y oshioka, H. Erdogan, Z. Chen, X. Xiao, and F . Allev a, “Rec- ognizing overlapped speech in meetings: A multichannel separa- tion approach using neural networks, ” in Pr oc. Interspeech , 2018, pp. 3038–3042. [31] R. Stiefelhagen, R. Bowers, and J. Fiscus, Eds., Multimodal T echnologies for P erception of Humans. International Evaluation W orkshops CLEAR 2007 and RT 2007 , ser . Lecture Notes in Com- puter Science, vol. 4625. Berlin: Springer , 2008.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment