가상 마이크 배열을 활용한 회의 기록 시스템
본 논문은 노트북·스마트폰 등 비동기식으로 배치된 여러 휴대용 디바이스를 가상 마이크 배열로 활용해 회의의 자동 전사와 화자 라벨링을 수행하는 시스템을 제안한다. 7개의 입력 스트림을 이용했을 때 비중첩 구간에서 WER 22.3%, SA‑WER 26.7%를 달성했으며, 화자 구분 오류율은 13.6%에 불과했다.
저자: Takuya Yoshioka, Zhuo Chen, Dimitrios Dimitriadis
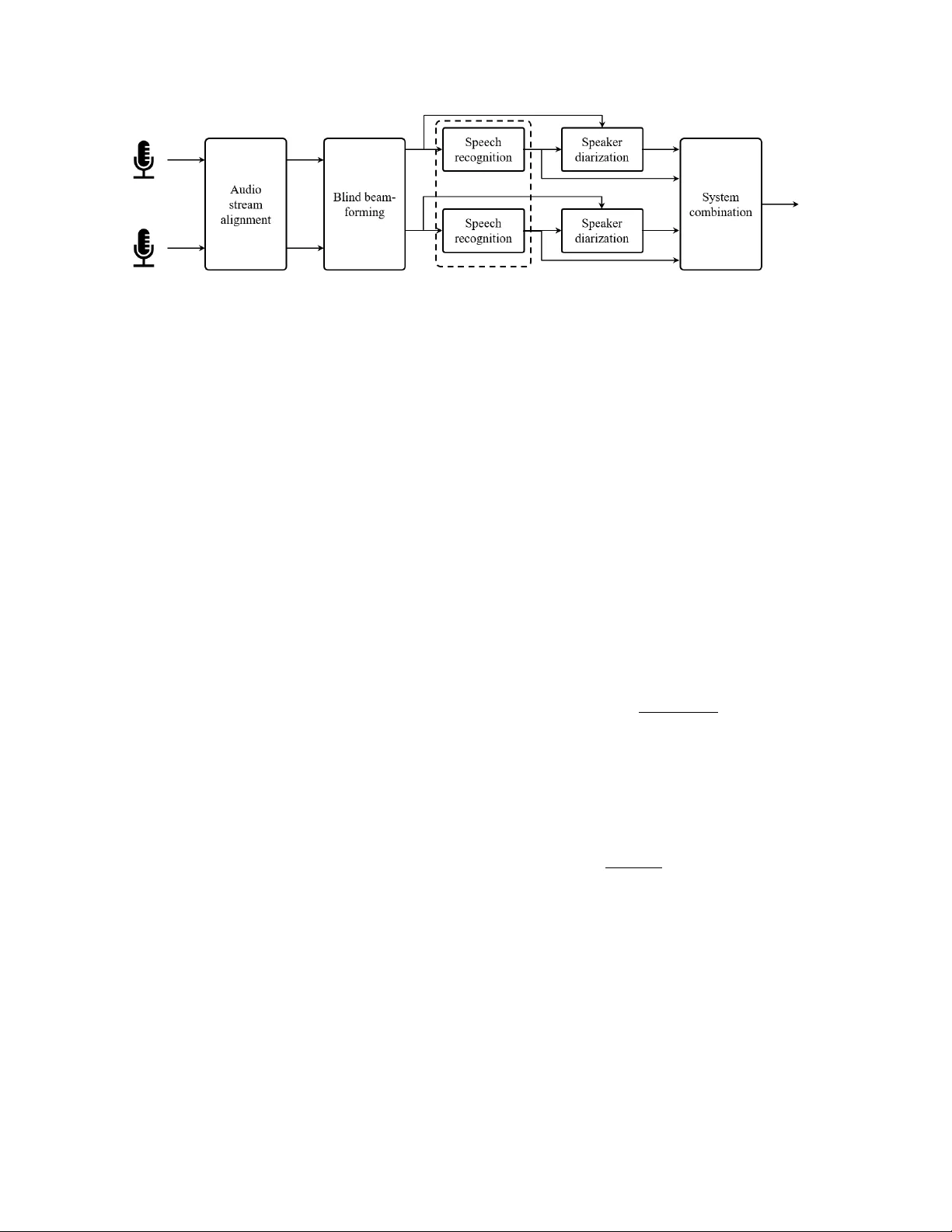
본 논문은 회의실에 배치된 여러 휴대용 디바이스(노트북, 스마트폰 등)를 가상 마이크 배열로 활용해, 회의 대화를 실시간에 가깝게 전사하고 화자를 정확히 라벨링하는 종합 시스템을 제안한다. 시스템은 크게 다섯 단계로 구성된다. 첫 번째 단계는 **오디오 스트림 정렬**이다. 각 디바이스는 서로 다른 시작 시점과 클럭 드리프트, 전송 지연 등으로 인해 비동기식으로 녹음된 오디오 스트림을 서버에 전송한다. 서버는 하나의 스트림을 기준(reference)으로 삼아, 다른 스트림과의 교차상관을 30 초마다 계산해 전역 지연을 보정하고, 1 초 간격의 샘플‑레벨 교차상관을 통해 지속적인 지역 지연을 추정·보정한다. 이 과정은 초기 전역 지연을 빠르게 파악하고, 이후에는 실시간으로 변동하는 클럭 드리프트를 최소화한다.
두 번째 단계는 **블라인드 빔포밍**이다. 논문은 마스크 기반 MVDR 방식을 채택한다. 먼저 1 초 배치 단위로 청정·노이즈 로그‑멜 특성을 최소화하도록 학습된 신경망이 스펙트럴 마스크를 생성한다. 이 마스크를 이용해 스피치와 노이즈의 공간 공분산 행렬을 추정하고, MVDR 가중치를 계산해 각 마이크 배열에 대한 빔포밍 출력을 만든다. 여기서 두 가지 빔포밍 전략을 비교한다. ‘All‑Channel’ 방식은 모든 마이크를 순차적으로 기준 마이크로 삼아 M개의 빔포머를 생성한다. ‘Leave‑One‑Out’(LOO) 방식은 매번 하나의 마이크를 제외하고 M‑1개의 마이크만 사용해 빔포머를 만들며, 이를 M번 반복한다. LOO는 채널 간 상관성을 낮추어 결과 다양성을 확보한다. 논문은 블록·퍼뮤테이션 행렬의 역행성을 이용해 M‑1 차원의 공분산 행렬을 M 차원의 공유 행렬에서 효율적으로 도출함으로써 두 방식이 동일한 연산 복잡도를 갖도록 설계하였다.
세 번째 단계는 **음성 인식**이다. 33 천시간 규모의 내부 데이터(클로즈‑톡, 원거리 마이크, 인공 노이즈 포함)로 사전 학습된 LSTM 기반 하이브리드 acoustic model과 weighted finite‑state transducer 디코더를 사용한다. 디코더는 300 ms 이상의 무음 구간을 탐지하면 n‑best 리스트를 생성하고, 5‑gram 언어 모델과 2 B 단어 규모의 LSTM‑LM으로 재점수를 매겨 정확도를 향상시킨다. 실시간 디코딩을 위해 latency‑controlled bidirectional LSTM을 채택했으며, 각 단어에 시간 마크를 부여한다.
네 번째 단계는 **화자 다이어리제이션**이다. 회의 참가자는 사전에 음성 프린트를 등록해 두며, 시스템은 320 ms 간격으로 d‑vector(128‑dim) 임베딩을 추출한다. 이 임베딩은 ResNet‑style 네트워크로 VoxCeleb 데이터셋을 이용해 학습되었다. 추출된 d‑vector를 기반으로 어그로머레이티브 클러스터링을 수행한다. 초기에는 각 단어를 개별 클러스터로 두고, 인접 클러스터 간 코사인 유사도가 0.15 이상이면 병합한다. 최종 클러스터에 대해 평균 d‑vector를 구하고, 사전에 등록된 화자 프로파일과 코사인 유사도를 비교해 가장 높은 유사도를 보이는 화자를 할당한다. 이 과정은 회의 중 10 % 정도가 겹치는 발화가 있더라도 13.6 %의 다이어리제이션 오류율(DER)을 기록한다.
다섯 번째 단계는 **시스템 결합**이다. 두 가지 결합 방법을 제시한다. 첫 번째는 RO‑VER 알고리즘을 확장한 방식으로, 화자 라벨을 채널 번호로 인코딩하고, 동적 프로그래밍 기반 워드 정렬과 투표 방식을 적용한다. 슬라이딩 윈도우를 이용해 온라인으로 새로운 화자‑주석 워드 가설이 들어올 때마다 실시간으로 업데이트한다. 두 번째는 Confusion Network Combination(CNC) 방식을 변형한 것으로, 각 채널의 n‑best 리스트를 혼동 네트워크로 변환하고, 화자 라벨을 특수 태그로 삽입한다. 시간 불일치 패널티를 추가해 워드와 화자 정보를 동시에 최적화한다. 두 방법 모두 오프라인·온라인 시나리오에서 유사한 성능을 보였으며, LOO 빔포밍과 결합했을 때 SA‑WER 26.7 %를 달성했다.
또한, 프레임‑레벨 senone posterior를 다중 스트림에서 직접 결합하는 **Acoustic Model Fusion** 실험을 수행했다. ‘Sum’, ‘Max’, ‘6‑out‑7’, ‘3‑out‑7’ 등 다양한 집계 방식을 시험했으며, ‘Max’ 방식이 22.5 % WER, 27.5 % SA‑WER로 가장 좋은 결과를 보였다. 이는 채널 간 다양성을 유지하면서도 강력한 사후 확률을 활용할 수 있음을 시사한다.
실험은 5개의 내부 회의(각 회의 30 분~1 시간, 3~11명)와 7채널 원형 마이크 배열을 사용한 2개의 회의에서 수행되었다. 비동기식 디바이스를 사용한 경우, 7개의 마이크 입력으로 비중첩 구간에서 22.3 % WER, 26.7 % SA‑WER를 달성했으며, 이는 클로즈‑톡 마이크(인-핸드 마이크)와의 차이가 3 % 수준에 불과했다. 화자 겹침이 10 %인 상황에서도 13.6 % DER을 기록, 실용적인 회의 기록 시스템으로서 충분히 경쟁력 있음을 입증한다.
요약하면, 본 연구는 **비동기식 다중 마이크 정렬 → 마스크 기반 블라인드 빔포밍 → 대규모 하이브리드 ASR → 사전 화자 정보 기반 다이어리제이션 → 다중 결합**이라는 파이프라인을 통해, 실제 회의 환경에서 실시간에 가까운 지연으로 높은 정확도의 화자‑주석 전사를 제공한다는 점에서 의미가 크다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기