Noise Adaptive Speech Enhancement using Domain Adversarial Training
In this study, we propose a novel noise adaptive speech enhancement (SE) system, which employs a domain adversarial training (DAT) approach to tackle the issue of a noise type mismatch between the training and testing conditions. Such a mismatch is a…
Authors: Chien-Feng Liao, Yu Tsao, Hung-Yi Lee
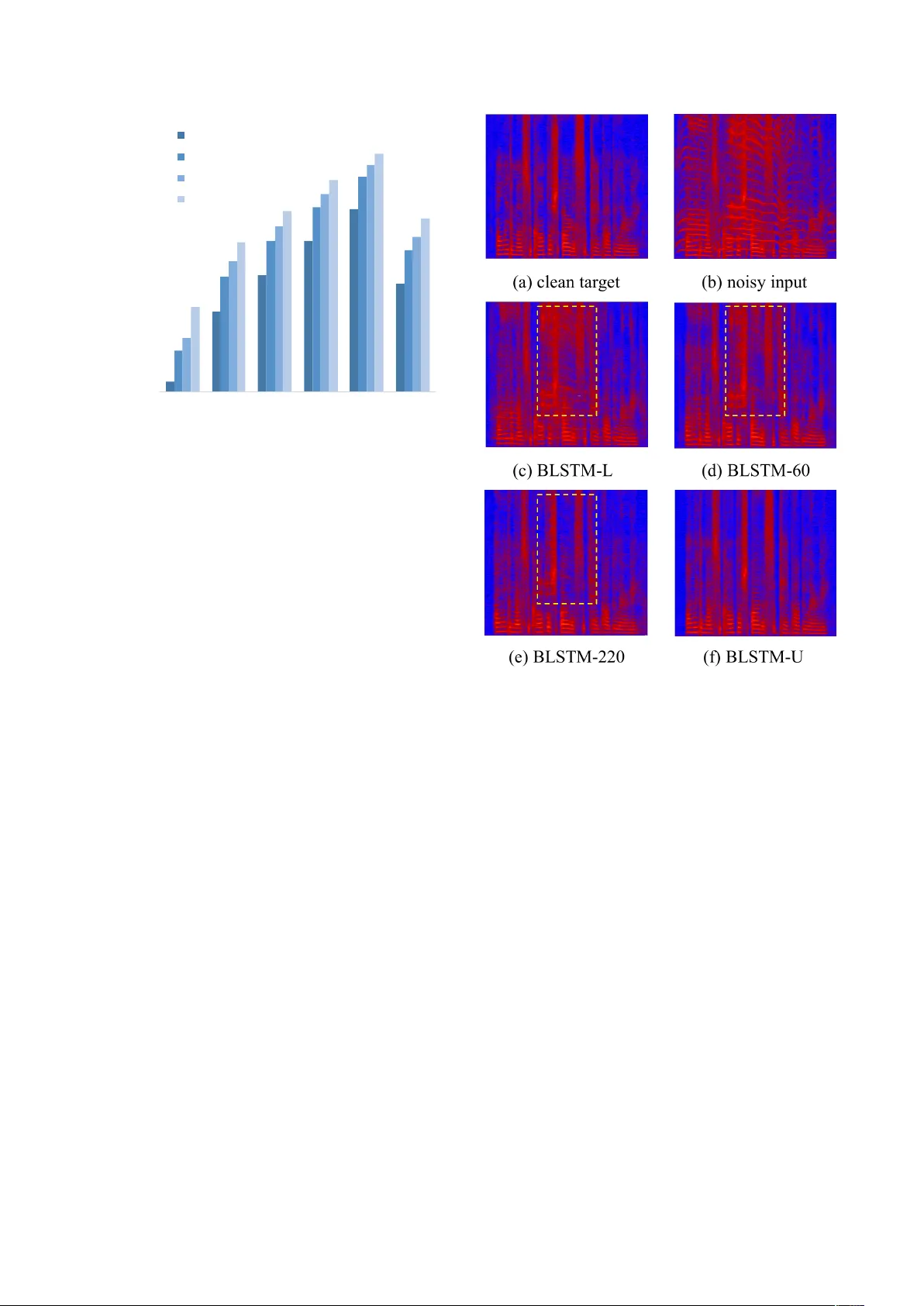
Noise Adaptiv e Speech Enhancement using Domain Adversarial T raining Chien-F eng Liao 1 , Y u Tsao 1 , Hung-Y i Lee 3 , Hsin-Min W ang 2 1 Research Center for Information T echnology Innov ation, Academia Sinica, T aiwan 2 Institute of Information Science, Academia Sinica, T aiwan 3 Graduate Institute of Electrical Engineering, National T aiwan Univ ersity , T aiwan { r06946002,hungyilee } @ntu.edu.tw, yu.tsao@citi.sinica.edu.tw, whm@iis.sinica.edu.tw Abstract In this study , we propose a novel noise adaptiv e speech en- hancement (SE) system, which employs a domain adversarial training (D A T) approach to tackle the issue of a noise type mis- match between the training and testing conditions. Such a mis- match is a critical problem in deep-learning-based SE systems. A large mismatch may cause a serious performance degradation to the SE performance. Because we generally use a well-trained SE system to handle v arious unseen noise types, a noise type mismatch commonly occurs in real-world scenarios. The pro- posed noise adaptiv e SE system contains an encoder-decoder - based enhancement model and a domain discriminator model. During adaptation, the D A T approach encourages the encoder to produce noise-in variant features based on the information from the discriminator model and consequentially increases the robustness of the enhancement model to unseen noise types. Herein, we regard stationary noises as the source domain (with the ground truth of clean speech) and non-stationary noises as the target domain (without the ground truth). W e ev aluated the proposed system on TIMIT sentences. The experiment re- sults sho w that the proposed noise adaptive SE system suc- cessfully provides significant improv ements in PESQ (19.0%), SSNR (39.3%), and STOI (27.0%) over the SE system without an adaptation. Index T erms :Speech enhancement, domain adversarial train- ing, domain adaptation, deep neural networks 1. Introduction Speech enhancement (SE) has been widely used as a pre- processor in speech-related applications, such as speech cod- ing, hearing aids [1], automatic speech recognition (ASR), and cochlear implants [2]. In the past, various SE approaches hav e been developed. Notable examples include spectral subtrac- tion [3], minimum-mean-square-error (MMSE)-based spectral amplitude estimator [4], W iener filtering [5], and non-negati ve matrix factorization (NMF) [6]. Recently , deep denoising au- toencoder (DD AE) and deep neural network (DNN)-based SE models ha ve also been proposed and extensiv ely in vestigated [7–10]. Howe ver , one of the critical problems in data-driven SE is the mismatch between the training and testing en vironments. In real-world scenarios, the acoustic en vironment where we deploy our enhancement model can be vastly dif ferent from our training examples, and unseen noises can seriously degrade the quality of processed signal. One way to overcome this problem is to collect as many types of noises as possible to increase the generalization [8], but it is not practical to cov er potentially in- finite noise types that may occur in real scenarios. W e propose to come in from the domain adaptation perspecti ve. Although not commonly seen in SE studies, this is of great interest in the field of computer vision and has been shown to be success- ful [11–13]. The goal of domain adaptation is to utilize the unla- belled tar get domain data to transfer the model learned from the source domain data to a rob ust model in the tar get domain. One way is to extract domain in variant features in the use of domain adversarial training (DA T) [14]. The key idea is to jointly train a discriminator, which can classify whether the input is from the source domain or the target domain gi ven the e xtracted features, and a feature extractor , which tries to confuse the discriminator . As a result, the downstream task will not take domain infor- mation into consideration, and thus will be robust to a domain mismatch. In our scenario, noisy utterances corrupted by stationary noises are defined as the source domain, and non-stationary noises without corresponding clean utterances are the target do- main. W ith the help of D A T , we achieved significant improv e- ments in objectiv e measures including perceptual evaluation of speech quality (PESQ) [15], segmental signal-to-noise ra- tio (SSNR), and short-time objecti ve intelligibility (STOI) [16]. W e compare our D A T with an upper-bound model and a lower- bound model. The upper -bound model is trained in a fully- supervised fashion where the clean speech references for the target domain data are available, and the lower -bound model is trained using the source domain data only , without any do- main adaptation techniques. Experiments sho w that the pro- posed noise adaptiv e model successfully provides significant improv ements ov er the lower -bound model. The rest of the paper is org anized as follows. W e revie w some works focused on domain adaptation for speech-related tasks in Section 2. In Section 3, we provide a detailed expla- nation of our approach, including the objectiv e functions. The experiment settings and results are presented in Section 4. Fi- nally , we provide some concluding remarks in Section 5. 2. Related work Generativ e Adversarial Netw ork (GAN) [17] has recently at- tracted great attention in the deep learning community . Adver- sarial training is capable of modeling a complex data distribu- tion by employing an alternative mini-max training scheme be- tween a generator network and a discriminator network. One of its applications is to serve as a new objective function for a regression task. Instead of explicitly minimizing the L1 \ L2 losses, which can cause ov er-smoothing results, the discrimina- tor provides a high-le vel abstract measurement of the “realness” of the generated images. This idea has been used in SE tasks with parallel [18–23] or nonparallel corpora [24, 25]. Another important application of adversarial training is domain adaptation. In a data-driven-based pattern classification \ regression task, the mismatch between the train- ing and testing conditions is also kno wn as the domain shift problem, which can cause a serious performance degradation. Encoder Decoder Discriminator @ L reg ress @✓ dec enhanced clean noisy fe a t u r e s domain l abel Forward-pass Backward-pass (gradient) @ L reg ress @✓ enc @ L DAT @✓ enc @ L DAT @✓ disc L DAT L reg ress @ L DAT @✓ disc Figure 1: The pr oposed adversarial training scheme includes an encoder , a decoder and a discriminator . During tr aining, the encoder- decoder and the discriminator ar e optimized alternatively . The discriminator tries to minimize L DAT , whereas the encoder tries to maximize it. In this way , the encoder is encourag ed to pr oduce noise-invariant featur es. One way to tackle this problem is to match the data distributions across domains. Ganin et al. [14] proposed utilizing adversarial training to produce high-dimensional features that were indis- tinguishable for a discriminati ve domain classifier . Such an idea has been deployed in various speech processing frame works for extracting domain-inv ariant features. In [26, 27], the authors matched the distributions of the clean and distorted speeches in the feature space, and confirmed that the noise-in variant fea- tures were beneficial to robust acoustic models. In [28–31], speaker -in variant and accent-in variant features were extracted in a similar fashion for speaker recognition and speech recog- nition. In [32], Domain Separation Network with three net- work components was used to extract the features. The com- ponent shared by both domains was optimized with the classifi- cation loss and DA T . T o further increase the degree of domain- in variance, two priv ate components were separately trained to be orthogonal to the shared component. Although D A T has frequently been utilized in noise-robust speech recognition, all uses have been in classification tasks. In this study , we con- firmed that D A T can be deployed on an SE system as well. 3. Domain adversarial speech enhancement W e assume a scenario in which only a small amount of noisy ut- terances that match the testing condition (i.e., the non-stationary noise en vironment) are av ailable, and there is no corresponding clean speech at all. W e denote the speech dataset under sta- tionary noises as S = { x i , y i , c i } N i =1 , where x i and y i are the noisy signal and its corresponding clean signal, c i ∈ { 1 , ..., C } indicates the noise type of the i -th data, and C denotes the number of noise classes. The unlabelled speech dataset under non-stationary noises is denoted as T = { x j , c j } M j =1 , where M << N . The goal is to utilize these unlabelled data to mini- mize the domain mismatch. 3.1. Domain adversarial training Our network consists of three components: the encoder net- work E ( x ; θ enc ) whose input is noisy speech x and output is the extracted feature vector f , the decoder network D ( f ; θ dec ) that estimates clean acoustic feature y given input f , and the discriminator netw ork Disc ( f ; θ disc ) that outputs a probability distribution over the domains. Here, θ enc , θ dec and θ disc are the parameters of the network; for simplicity , we drop the θ no- tation in the equations below . The overall workflow is shown in Figure 1. Unlik e the discriminator in [14], which is a binary classifier that predicts the source \ target domain, in this study it giv es a probability distribution ov er multiple noise types. The discriminator tries to correctly predict the noise types, whereas the encoder tries to maximize the prediction error . As a result, the encoder tends to produce noise-inv ariant features, thereby reducing the mismatch problem. 3.2. Objective functions W e take the regression approach as our SE objectiv e function, which minimizes mean-absolute-error between the ground truth of the clean speech and the output of the decoder network: L reg ress = 1 N N X i =1 | D ( f i ) − y i | (1) where N is the total number of training samples from the source domain, x i and y i are the i -th paired noisy and clean speeches. The discriminator is optimized by minimizing the categorical cross-entropy loss, denoted as L DAT : L DAT = − 1 M + N M + N X i =1 C X k =1 c ik log P ( c i = k | f i ) (2) where P ( c i = k | f i ) is the discriminator output after softmax, and c ik denotes the k -th value in one-hot expression of label c i . W e attempted two methods to realize adversarial training. First, follo wing [14], a gradient re versal layer (GRL) is inserted between the discriminator and the encoder . In the forward- pass, the GRL acts as an identity layer that leaves the input unchanged, b ut re verses the gradient passing through it by mul- T able 1: The aver age PESQ, SSNR, and STOI scores for e valuating BLSTM-L, BLSTM-60, and BLSTM-U on the test set at five differ ent SNR levels and the average scor es across all SNRs. BabyCry is the adapted target domain noise type, while Cafeteria is the unseen noise type. The adaptive model (BLSTM-60) is superior to the baseline (BLSTM-L) across all SNRs for thr ee metrics. The highest scor es per metric ar e highlighted with bold text, excluding the BLSTM-U . BLSTM-L (Baseline) BLSTM-60 BLSTM-U (Oracle) SNR(dB) PESQ SSNR STOI PESQ SSNR STOI PESQ SSNR STOI BabyCry -3 1.803 -3.995 0.775 1.971 -0.916 0.802 2.901 4.981 0.901 3 2.181 -0.609 0.844 2.369 2.098 0.865 3.208 6.549 0.929 6 2.373 1.007 0.871 2.559 3.478 0.890 3.325 7.195 0.938 9 2.557 2.399 0.894 2.739 4.696 0.911 3.419 7.732 0.945 12 2.730 3.808 0.910 2.903 5.879 0.925 3.509 8.314 0.951 A vg. 2.329 0.522 0.859 2.508 3.047 0.879 3.272 6.954 0.933 Cafeteria -3 1.609 -8.485 0.574 1.654 -7.587 0.603 1.595 -8.703 0.584 3 2.021 -4.951 0.729 2.099 -3.595 0.759 2.031 -4.801 0.745 6 2.219 -2.987 0.796 2.312 -1.476 0.820 2.246 -2.574 0.812 9 2.418 -1.065 0.849 2.520 0.570 0.867 2.462 -0.395 0.866 12 2.612 0.715 0.887 2.720 2.476 0.902 2.669 1.647 0.905 A vg. 2.176 -3.355 0.767 2.261 -1.922 0.790 2.201 -2.965 0.782 tiplying it by a negati ve scalar λ in the backward-pass. Another way is to optimize the encoder and the discriminator alterna- tiv ely , as in [17]. The choice of GRL instead of alternating min- imization can be viewed as different approximations of mini- max [33], and the second scheme stabilized the training and produced better results in our preliminary e xperiments. Finally , the network parameters are updated via gradient descent, and the ov erall update rules are as follows: θ enc ← θ enc − α ( ∂ L reg ress ∂ θ enc − λ ∂ L DAT θ enc ) (3) θ dec ← θ dec − α ∂ L reg ress θ dec (4) θ disc ← θ disc − α ∂ L DAT θ disc (5) where α is the learning rate, and the hyperparameter λ is the importance weight between two objecti ves. 4. Experiments The TIMIT database [34] was used to prepare the training and test sets. For the training set, 500 utterances were randomly selected from the TIMIT training set and corrupted with fiv e stationary noise types (the source domain) at six SNR levels (-5 dB, 0 dB, 5 dB, 10 dB, 15 dB, and 20 dB) to form 15,000 source domain training data. Another 220 utterances were mixed with the non-stationary noise type (the target domain) to form the adaptation dataset. In this paper , the stationary noise types include car noise, engine noise, soft wind noise, strong wind noise, and pink noise, and the non-stationary noise type is a baby-cry noise. Hence, the total number of noise classes C was six in the following experiments. For the test set, to ev al- uate the adaptation performance, 192 utterances from the core test set of TIMIT database were corrupted with the same non- stationary noise type (baby-cry) of the target domain. Unseen non-stationary noise type cafeteria babble was also used to e val- uate the generalization ability of the adapted SE model. 4.1. Implementation W e used a BLSTM [35, 36] model as building block for the SE network. The encoder and the decoder each contains a bidirec- tional LSTM layer with 512 nodes, and the decoder contains a fully connected layer with 257 linear nodes at the output for spectrogram estimation. The discriminator herein was a unidi- rectional LSTM with 1,024 nodes, and a fully connected layer with 6 nodes followed by a softmax layer to predict the noise type. The Adam algorithm [37] was used for training, with a learning rate of 0.0001 and 0.0005 for the SE model and the dis- criminator , respectively . The batch size is set to 16. W e found that models are robust to the choice of λ as long as it is below 0.1, and λ = 0.05 was chosen through out all adaptation models. The sampling rate of our speech data is 16 kHz. W e extracted the time-frequenc y (T -F) features using a 512-point short time Fourier transform (STFT) with a hamming window size of 32 ms and a hop size of 16 ms, resulting in feature vectors consisting of 257-point STFT log-po wer spectra (LPS). For the SE model, we split each training utterance into mul- tiple segments of 32 frames, and thus the input and output of our encoder-decoder will be a matrix of 257x32. Finally , mul- tiple decoder outputs were concatenated and synthesized back to the w av eform signal via the inv erse Fourier transform and an ov erlap-add method. W e used the phases of the noisy signals for the inv erse Fourier transform. Further details and the demo may be found at https://github.com/jerrygood0703/ noise_adaptive_DAT_SE . In the following experiments, we will e valuate our SE al- gorithm from three aspects: speech quality , noise reduction, and speech intelligibility . Therefore, PESQ, SSNR (in dB), and STOI will be used to ev aluate the enhanced speech, respectively . For all three, a higher score indicates better results. 4.2. Results For a fair comparison, we used the same model architecture, weight initialization, and training scheme for all models com- pared during the experiments. The baseline is denoted as BLSTM-L , with λ set to zero, meaning that only the source domain data were used to train the model parameters. First, we 1.75 1.95 2.15 2.35 2.55 2.75 2.95 3.15 -3 3 6 9 12 A vg. PES Q SNR(dB ) BLSTM -L BLSTM -60 BLSTM -140 BLSTM -220 Figure 2: Comparison of the baseline and the pr oposed models in PESQ at differ ent SNR levels. W e denote BLSTM-60 (-140 and -220) as the pr oposed models, where the number r epre- sents the amount of targ et domain noisy speech data seen dur- ing training. The PESQ scor es for the unprocessed speech ar e 1.506, 1.882, 2.075, 2.261, and 2.456 at -3 dB, 3 dB, 6 dB, 9 dB, and 12 dB, r espectively , with the averag e of 2.036. intend to in vestigate the correlation of the amount of adaptation data to the achie vable performance. Thus, we prepared three sets of adaptation data. For the first set, 60 out of 220 noisy utterances were mixed with the target noise type at 0 dB SNR, which yielded 60 target domain noisy utterances that could be used in DA T . Another 80 utterances were added to formed a 140-utterances subset, while the third subset contained all of 220 utterances. The models unsupervisedly adapted with dif- ferent numbers of target domain noisy utterances are dubbed as BLSTM-60 , BLSTM-140 and BLSTM-220 . W e also con- ducted a fully supervised experiment to be our upper-bound model, denoted as BLSTM-U . In this case, the 220 noisy train- ing utterances of the target domain were paired with the corre- sponding clean utterances during training, and thus the model was optimized using fully supervised mean-absolute-error and the domain adversarial objecti ve was not in volved. T able 1 shows the results of the av erage PESQ, SSNR, and STOI scores on the test set for the BLSTM-L , BLSTM-60 , and BLSTM-U . For the baby-cry noise set, we can see that with only 60 noisy utterances for adaptation, the proposed model outperformed the baseline at ev ery SNR lev els by a large mar- gin. It cov ers 19.0%, 39.3%, and 27.0% of the gap between the baseline and upper-bound model, with respect to the aver - age PESQ, SSNR, and STOI. F or the cafeteria babble noise set, we tested the SE performance using the model adapted with the baby-cry noise. The results show that the proposed model does not ov erfit to the adapted noise, and even attains slightly bet- ter scores. W e hypothesize that DA T learns more generalized features by explicitly constraining the encoder to be noise in- variant, thus making the decoder noise independent. Research into the generalization ability will be left for future studies. In Figure 2, we sho w the effecti veness of DA T on differ - ent amounts of target domain adaptation data. W e can see that Figure 3: Spectr ograms of a TIMIT utterance in the teset set: (a) clean tar get, (b) noisy speech (baby-cry at 3 dB), (c) baseline model BLSTM-L, (d) and (e) adaptive model BLSTM-(60, 220), (f) upper-bound model BLSTM-U . PESQ gradually increases when there are more target domain noisy speech data in volv ed in training. Since unlabelled noisy speech data are easily acquired, the benefit from noise adap- tiv e training is promising. Finally , examples of enhanced spec- trograms of the baseline model, proposed methods, and upper- bound are sho wn in Figure 3. It is clearly shown that noises are more suppressed for the models using D A T than the baseline. In summary , the models equipped with noise adaptation achieved higher scores than the models without adaptation. 5. Conclusions and Future work In this paper, we studied the problem of noise mismatch in SE systems. W e propose tackling the problem using a DA T algo- rithm on a BLSTM model. Utilizing unlabelled target domain noisy speech, we aimed at extracting noise-inv ariant features. Experimental results sho w that the proposed model achiev es significant improv ements over the baseline model using only a fe w noisy data. T o the best of our kno wledge, this is the first study adopting D A T to adapt an SE model to unseen noise types with an improv ed performance. In the future, we plan to study the generalization ability of SE systems with respect to unseen noise types. 6. References [1] H. Le vitt, “Noise reduction in hearing aids: A revie w , ” Journal of r ehabilitation resear ch and development , vol. 38, no. 1, pp. 111– 122, 2001. [2] Y .-H. Lai, F . Chen, S.-S. W ang, X. Lu, Y . Tsao, and C.-H. Lee, “ A deep denoising autoencoder approach to impro ving the intelli- gibility of vocoded speech in cochlear implant simulation, ” IEEE T ransactions on Biomedical Engineering , vol. 64, no. 7, pp. 1568– 1578, 2016. [3] S. Boll, “Suppression of acoustic noise in speech using spectral subtraction, ” IEEE T ransactions on acoustics, speech, and signal pr ocessing , vol. 27, no. 2, pp. 113–120, 1979. [4] Y . Ephraim and D. Malah, “Speech enhancement using a minimum-mean square error short-time spectral amplitude esti- mator , ” IEEE T ransactions on acoustics, speech, and signal pr o- cessing , vol. 32, no. 6, pp. 1109–1121, 1984. [5] P . Scalart and J. V . Filho, “Speech enhancement based on a priori signal to noise estimation, ” in Acoustics, Speech, and Signal Pro- cessing, 1996. ICASSP-96. Conference Pr oceedings., 1996 IEEE International Confer ence on , vol. 2. IEEE, 1996, pp. 629–632. [6] K. W . Wilson, B. Raj, P . Smaragdis, and A. Div akaran, “Speech denoising using nonnegati ve matrix factorization with priors, ” in Acoustics, Speec h and Signal Processing , 2008. ICASSP 2008. IEEE International Conference on . IEEE, 2008, pp. 4029–4032. [7] X. Lu, Y . Tsao, S. Matsuda, and C. Hori, “Speech enhancement based on deep denoising autoencoder. ” in Interspeech , 2013, pp. 436–440. [8] Y . Xu, J. Du, L.-R. Dai, and C.-H. Lee, “ A regression ap- proach to speech enhancement based on deep neural networks, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr o- cessing , vol. 23, no. 1, pp. 7–19, 2015. [9] M. Kolbk, Z.-H. T an, J. Jensen, M. Kolbk, Z.-H. T an, and J. Jensen, “Speech intelligibility potential of general and special- ized deep neural network based speech enhancement systems, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr o- cessing , vol. 25, no. 1, pp. 153–167, 2017. [10] D. W ang and J. Chen, “Supervised speech separation based on deep learning: An overvie w , ” IEEE/ACM T ransactions on Audio, Speech, and Languag e Pr ocessing , 2018. [11] M. Long, H. Zhu, J. W ang, and M. I. Jordan, “Unsupervised do- main adaptation with residual transfer networks, ” in Advances in Neural Information Pr ocessing Systems , 2016, pp. 136–144. [12] E. Tzeng, J. Hoffman, K. Saenko, and T . Darrell, “ Adversarial dis- criminativ e domain adaptation, ” in Computer V ision and P attern Recognition (CVPR) , vol. 1, no. 2, 2017, p. 4. [13] R. Shu, H. H. Bui, H. Narui, and S. Ermon, “ A dirt-t ap- proach to unsupervised domain adaptation, ” arXiv pr eprint arXiv:1802.08735 , 2018. [14] Y . Ganin, E. Ustinova, H. Ajakan, P . Germain, H. Larochelle, F . Laviolette, M. Marchand, and V . Lempitsky , “Domain- adversarial training of neural networks, ” The Journal of Machine Learning Resear ch , v ol. 17, no. 1, pp. 2096–2030, 2016. [15] I.-T . Recommendation, “Perceptual evaluation of speech quality (pesq): An objective method for end-to-end speech quality as- sessment of narrow-band telephone networks and speech codecs, ” Rec. ITU-T P . 862 , 2001. [16] C. H. T aal, R. C. Hendriks, R. Heusdens, and J. Jensen, “ An al- gorithm for intelligibility prediction of time–frequency weighted noisy speech, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 19, no. 7, pp. 2125–2136, 2011. [17] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde- Farley , S. Ozair , A. Courville, and Y . Bengio, “Generative adver - sarial nets, ” in Advances in neural information pr ocessing sys- tems , 2014, pp. 2672–2680. [18] S. Pascual, A. Bonafonte, and J. Serra, “Segan: Speech enhancement generative adversarial network, ” arXiv preprint arXiv:1703.09452 , 2017. [19] D. Michelsanti and Z.-H. T an, “Conditional generative adversarial networks for speech enhancement and noise-robust speaker veri- fication, ” arXiv pr eprint arXiv:1709.01703 , 2017. [20] C. Donahue, B. Li, and R. Prabhavalkar , “Exploring speech en- hancement with generativ e adv ersarial networks for robust speech recognition, ” arXiv pr eprint arXiv:1711.05747 , 2017. [21] Z. Meng, J. Li, Y . Gong et al. , “ Adversarial feature-mapping for speech enhancement, ” arXiv pr eprint arXiv:1809.02251 , 2018. [22] A. Pandey and D. W ang, “On adversarial training and loss func- tions for speech enhancement, ” in 2018 IEEE International Con- fer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 5414–5418. [23] S.-W . Fu, C.-F . Liao, Y . Tsao, and S.-D. Lin, “Metricgan: Genera- tiv e adversarial networks based black-box metric scores optimiza- tion for speech enhancement, ” arXiv preprint , 2019. [24] M. Mimura, S. Sakai, and T . Kawahara, “Cross-domain speech recognition using nonparallel corpora with cycle-consistent ad- versarial networks, ” in Automatic Speech Recognition and Un- derstanding W orkshop (ASR U), 2017 IEEE . IEEE, 2017, pp. 134–140. [25] Z. Meng, J. Li, Y . Gong et al. , “Cycle-consistent speech enhance- ment, ” arXiv pr eprint arXiv:1809.02253 , 2018. [26] Y . Shinohara, “ Adversarial multi-task learning of deep neural net- works for robust speech recognition. ” in INTERSPEECH , 2016, pp. 2369–2372. [27] S. Sun, B. Zhang, L. Xie, and Y . Zhang, “ An unsupervised deep domain adaptation approach for robust speech recognition, ” Neu- r ocomputing , vol. 257, pp. 79–87, 2017. [28] T . Tsuchiya, N. T awara, T . Ogawa, and T . Kobayashi, “Speaker in variant feature extraction for zero-resource languages with ad- versarial learning, ” in 2018 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , 2018, pp. 2381–2385. [29] Z. Meng, J. Li, Z. Chen, Y . Zhao, V . Mazalov , Y . Gong et al. , “Speaker-in variant training via adversarial learning, ” arXiv pr eprint arXiv:1804.00732 , 2018. [30] Q. W ang, W . Rao, S. Sun, L. Xie, E. S. Chng, and H. Li, “Un- supervised domain adaptation via domain adversarial training for speaker recognition, ” in 2018 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 4889–4893. [31] S. Sun, C.-F . Y eh, M.-Y . Hwang, M. Ostendorf, and L. Xie, “Do- main adversarial training for accented speech recognition, ” arXiv pr eprint arXiv:1806.02786 , 2018. [32] Z. Meng, Z. Chen, V . Mazalov , J. Li, and Y . Gong, “Unsupervised adaptation with domain separation networks for robust speech recognition, ” in Automatic Speech Recognition and Understand- ing W orkshop (ASRU), 2017 IEEE . IEEE, 2017, pp. 214–221. [33] W . Fedus, M. Rosca, B. Lakshminarayanan, A. M. Dai, S. Mo- hamed, and I. Goodfellow , “Many paths to equilibrium: Gans do not need to decrease adiv ergence at every step, ” arXiv preprint arXiv:1710.08446 , 2017. [34] J. S. Garofolo, “Timit acoustic phonetic continuous speech cor- pus, ” Linguistic Data Consortium, 1993 , 1993. [35] F . W eninger , H. Erdogan, S. W atanabe, E. V incent, J. Le Roux, J. R. Hershey , and B. Schuller, “Speech enhancement with lstm recurrent neural networks and its application to noise-robust asr, ” in International Conference on Latent V ariable Analysis and Sig- nal Separation . Springer , 2015, pp. 91–99. [36] L. Sun, J. Du, L.-R. Dai, and C.-H. Lee, “Multiple-target deep learning for lstm-rnn based speech enhancement, ” in 2017 Hands- fr ee Speech Communications and Microphone Arrays (HSCMA) . IEEE, 2017, pp. 136–140. [37] D. P . Kingma and J. Ba, “ Adam: A method for stochastic opti- mization, ” arXiv pr eprint arXiv:1412.6980 , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment