도메인 적대적 훈련으로 만나는 깨끗한 목소리: 노이즈 적응형 음성 향상 기술
본 연구는 훈련과 테스트 환경 간의 노이즈 유형 불일치라는 음성 향상(SE) 시스템의 핵심 문제를 해결하기 위해 도메인 적대적 훈련(DAT)을 도입한 새로운 적응형 시스템을 제안합니다. 정지 노이즈가 포함된 소스 도메인 데이터와 레이블이 없는 비정지 노이즈 타겟 도메인 데이터를 활용해, 인코더가 노이즈에 불변하는 특징을 추출하도록 유도함으로써 보이지 않는 노이즈에 대한 모델 강건성을 크게 향상시켰습니다. TIMIT 데이터셋 실험에서 PESQ 1…
저자: Chien-Feng Liao, Yu Tsao, Hung-Yi Lee
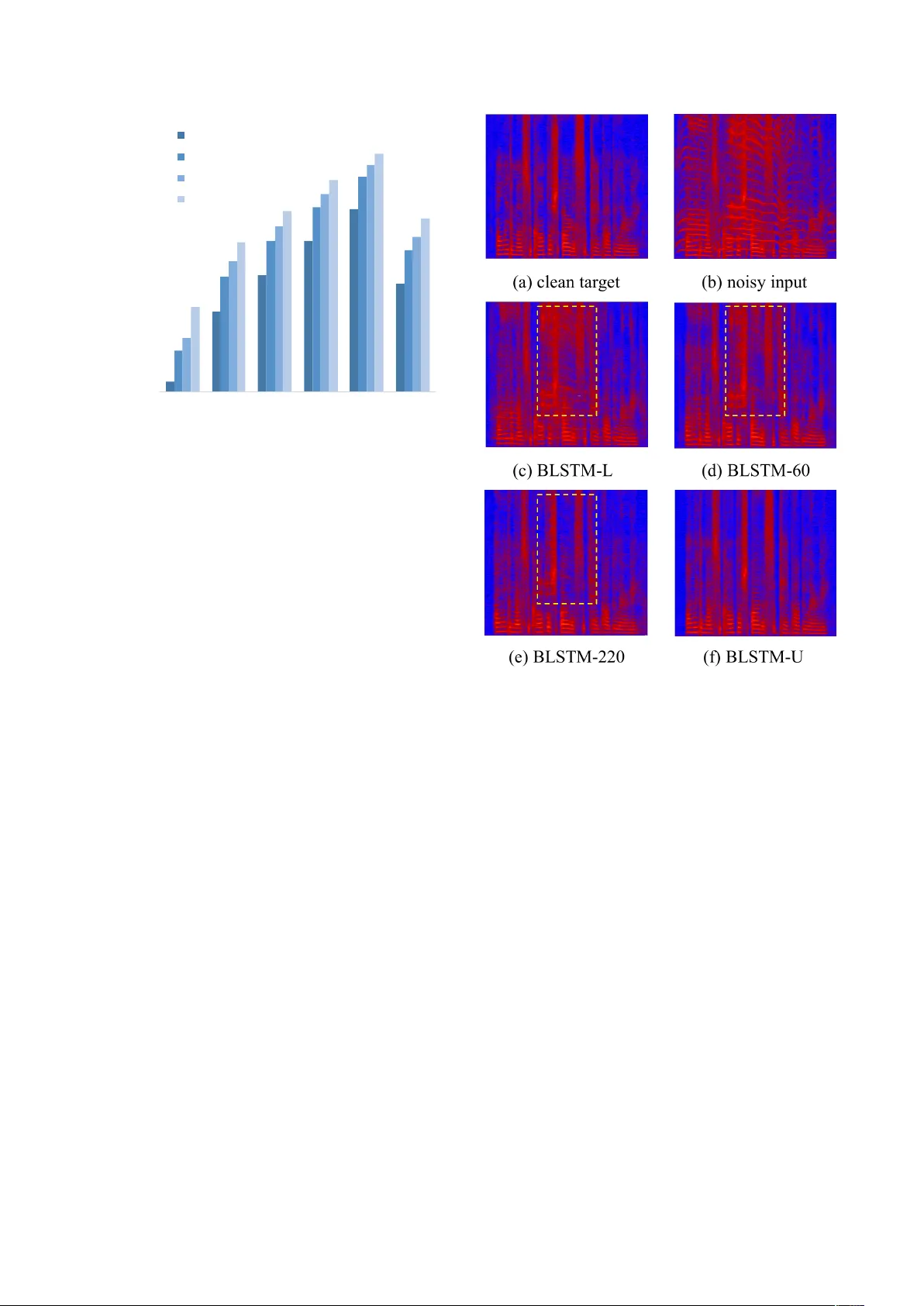
이 논문은 딥러닝 기반 음성 향상 시스템이 직면한 가장 큰 난제 중 하나인 '훈련-테스트 노이즈 불일치' 문제를 해결하기 위한 노이즈 적응형 프레임워크를 제시합니다. 실제 환경은 무한히 다양한 잡음이 존재하므로, 모든 잡음 유형을 훈련 데이터에 포함시키는 것은 불가능합니다. 이에 저자들은 도메인 적응의 관점에서 문제를 접근하였습니다.
먼저, 정지 노이즈(자동차 소음, 엔진 소음 등)로 오염된 음성과 그에 대응하는 깨끗한 음성 쌍을 '소스 도메인'으로 정의합니다. 반면, 적응 대상이 되는 비정지 노이즈(아이 울음소리)로 오염된 음성은 깨끗한 레이블이 없는 '타겟 도메인'으로 설정합니다. 시스템은 크게 세 가지 구성 요소로 이루어집니다: 1) 잡음 음성의 로그 파워 스펙트럼(LPS)을 입력받아 특징을 추출하는 BLSTM 기반 인코더, 2) 추출된 특징으로부터 깨끗한 음성의 LPS를 복원하는 BLSTM 기반 디코더, 3) 인코더의 출력 특징이 어느 도메인(노이즈 유형)에서 왔는지 분류하는 LSTM 기반 도메인 판별자.
훈련은 두 가지 손실 함수를 통해 진행됩니다. 첫째, 소스 도메인 데이터에 대해서만 적용되는 회귀 손실(L_regress)로, 디코더 출력과 실제 깨끗한 음성 스펙트럼 간의 평균 절대 오차를 최소화합니다. 둘째, 도메인 적대적 손실(L_DAT)로, 판별자가 노이즈 유형을 정확히 분류하도록 하면서 동시에 인코더는 이 판별자를 속이도록(판별자의 분류 오류를 최대화하도록) 적대적으로 훈련됩니다. 이때 안정적인 훈련을 위해 생성적 적대 신경망(GAN)처럼 인코더/판별자를 번갈아 가며 최적화하는 방식을 채택했습니다.
실험은 TIMIT 데이터베이스를 기반으로 진행되었습니다. 소스 도메인 훈련 데이터는 5종류의 정지 노이즈를 -5dB~20dB SNR로 혼합하여 생성했으며, 타겟 도메인 적응 데이터는 비정지 노이즈(아이 울음소리)를 사용했습니다. 평가는 적응된 노이즈(아이 울음소리)와 보지 못한 새로운 노이즈(카페테리아 잡음) 모두에 대해 수행되었습니다. 결과는 명확했습니다. 타겟 도메인의 무레이블 잡음 음성 60개만으로 적응한 모델(BLSTM-60)도, 소스 도메인 데이터만으로 훈련한 기준 모델(BLSTM-L)을 모든 SNR과 평가 지표(PESQ, SSNR, STOI)에서 크게 앞섰습니다. 특히 평균 PESQ는 2.329에서 2.508으로 상승했으며, 이는 완전 지도 학습 상한선 모델(BLSTM-U) 성능까지의 격차 중 19.0%를 메꾼 수치입니다. 더 많은 적응 데이터를 사용할수록 성능은 점진적으로 향상되었습니다. 가장 의미 있는 것은 적응에 사용한 특정 노이즈가 아닌 완전히 새로운 카페테리아 잡음에 대해서도 제안 모델의 성능이 기준 모델보다 우수했다는 점으로, 이 방법이 특정 노이즈에 과적합하지 않고 일반화된 노이즈 불변 특징을 학습함을 입증합니다.
결론적으로, 이 연구는 음성 향상 분야에 도메인 적대적 훈련을 효과적으로 도입하여, 적은 양의 무레이블 타겟 환경 데이터만으로도 기존 모델의 강건성을 획기적으로 높일 수 있는 가능성을 보여주었습니다. 이는 실제 배포 환경에서 마주할 수 있는 무수히 많은 보이지 않는 노이즈에 대응하는 실용적인 음성 향상 시스템 개발에 중요한 방향을 제시합니다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기