Large-scale Speaker Retrieval on Random Speaker Variability Subspace
This paper describes a fast speaker search system to retrieve segments of the same voice identity in the large-scale data. A recent study shows that Locality Sensitive Hashing (LSH) enables quick retrieval of a relevant voice in the large-scale data …
Authors: Suwon Shon, Younggun Lee, Taesu Kim
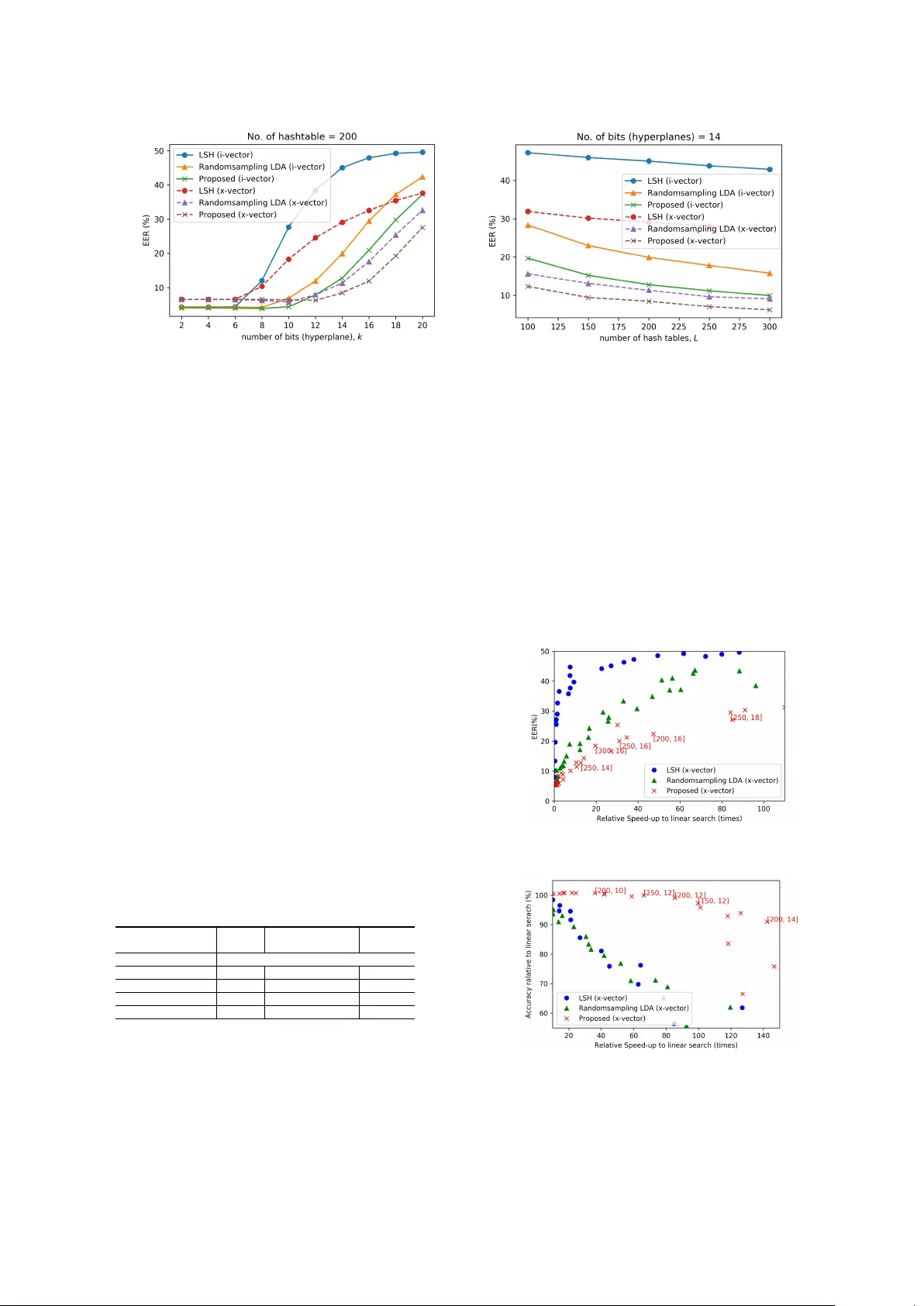
Large-scale Speak er Retriev al on Random Speaker V ariability Subspace Suwon Shon 1 , Y ounggun Lee 2 , T aesu Kim 2 Massachusetts Institute of T echnology , Cambridge, MA, USA 1 Neosapience, Inc., Seoul, South K orea 2 swshon@csail.mit.edu { yg,taesu } @neosapience.com Abstract This paper describes a fast speaker search system to retrie v e segments of the same voice identity in the large-scale data. A recent study shows that Locality Sensitiv e Hashing (LSH) en- ables quick retriev al of a relev ant voice in the large-scale data in conjunction with i-vector while maintaining accuracy . In this paper , we proposed Random Speaker-v ariability Subspace (RSS) projection to map a data into LSH based hash tables. W e hypothesized that rather than projecting on completely random subspace without considering data, projecting on randomly gen- erated speaker v ariability space would gi ve more chance to put the same speaker representation into the same hash bins, so we can use less number of hash tables. Multiple RSS can be gen- erated by randomly selecting a subset of speakers from a lar ge speaker cohort. From the e xperimental result, the proposed ap- proach sho ws 100 times and 7 times faster than the linear search and LSH, respectiv ely . Index T erms : speaker retrie v al, speaker search, hashing, speaker v ariability subspace 1. Introduction T oday , so to speak, we are living in the flood of online videos and social media. It is known that hundreds of hours of video are uploaded e very minute on Y outube. Since most of the on- line videos include speech segments, collecting and abusing someones v oice becomes much easier than ev er before. More- ov er , recent significant advances in speech synthesis technology made it easier to clone v oice identity and it becomes harder to distinguish between original speech and synthesized one [1, 2]. In the area of multimedia retriev al, music and video search tech- nology ha ve been de veloped to protect the cop yright of the con- tents. Howe v er , it is yet dif ficult to search someones v oice iden- tity from a large amount of multimedia data. V oice identity search would play an important role to prevent illegal cloning and ab using. One might apply con v entional speak er identifica- tion or verification algorithms for such purpose. It could be done by training the speaker model and inferring the model score for e very speech segment a v ailable online. But, it is prac- tically not doable because of the large search space. Thus, it is inevitable to develop faster algorithms without performance degradation to prompt to a user as quickly as possible [3]. After audio segment can be represented in a single low- dimensional latent vector such as i-v ector [4], hashing approach was proposed on the speaker search problem to maximize the speed of retriev al while minimizing the performance degrada- tion [5, 6, 7, 8]. Locality Sensitiv e Hashing (LSH) [9] is a po w- erful tool to approximate the nearest neighbor search in high dimension and successfully adopted on top of the i-vector for a large-scale f ast speaker identification. For a large scale application, long hash bits are needed to reduce the size of each hash bin and to speed up a retriev al time. Ho we ver , since the LSH is data-independent unsuper- vised hashing method rely on the random projection, it suffers from the redundancy of the hash bits. Also, long hash bits de- crease the collision probability between similar samples. Con- sequently , we are encouraged to use a lot of multiple hash tables and this increases the query time and storage consumption. T o reduce this redundancy , a supervised hashing method can be considered. A spectral hashing [10] is a representativ e method in a supervised hashing method. It produces a very efficient hash code by learning a hash function from the training data. Ideally , all the true neighbor of an arbitrary query can be found in the specific hash bucket. Howe ver , this is not feasible using only a single hash table for a practical situation such as large- scale data lies on the high-dimensional space. In this study , we propose a Random Speaker -variability Subspace (RSS) projection approach based on the Linear Dis- criminant Analysis (LD A) to give maximum efficiency on the hash table of LSH. Providing weak supervision by selecting random subset speakers in the training dataset when we gen- erate random projection matrix for LSH, we observed it could dramatically save the hash bits (hyperplanes) and hash tables by removing the redundancy . W e also re-define the speaker search task into more detail sub-task as speaker identification task and speak er retriev al task considering the query and search space. Experiments were conducted using both i-vector and neural network based speaker embedding, x-vector [11]. W e used V oxceleb 1 and 2 dataset [12, 13] and prepared a various combination of dataset categories to measure the performance of speaker search sub-tasks. 2. Speaker sear ch in the wild Speaker search can be di vided into two sub-categories as speaker identification and speaker retriev al. The main dif fer- ence between two sub-tasks is whether the query is from arbi- trary speech segment or tar get speaker segment. 2.1. Speaker Identification For speaker identification, the query x is a latent vector from an arbitrary speech se gment and its class (speak er index) is C x . Search space is D = { ω 1 , ω 2 , ...ω S } where S is total num- ber of Speaker and ω s is a latent vector from a speak er speech segment, s . y s is the score between x and ω s . For closed- set speaker identification which query speech is assumed to be spoken by one of the speakers in the search space, the system forced the input query to match the best matching speaker in the search space as C x = C y ∗ where y ∗ = max s =1 ...S y s . Previous study on lar ge-scale speak er identification mostly supposed this closed-set identification to measure the performance [5, 6]. Howe ver , in practical situation, the system needs to con- sider that the speech query may not be spoken by the speaker in the search space. This can be represented as open-set speaker identification. Open-set speaker identification is also kno wn as multi-target detection, so we can borrow the top-1 stack detec- tor performance measurement term in [14] about miss and f alse alarm probability . 2.2. Speaker Retriev al For speaker retrieval, the query ω is a latent variable from a speech segment of the target speaker we are interest in and its class is C ω . The search space is D = { x 1 , x 2 , ...x N } where N is the total number of segments to search and x n is a la- tent vector from an arbitrary speech segment from an unknown speaker . Compared to the speaker identification task, the query and search space are changed each other . The aim of this task is to retrie ve all relev ant documents. Thus, speaker retrieval is 1 to N verification task. The performance measurement is the same as the 1 to 1 verification task which is a general speaker veri- fication task. Howe ver , the trials to measure the performance need to be prepared by full combination between the query and search space. For instance, if we hav e 10 target speakers for an input query , the number of trials is 10 × N . 3. Speaker Dataset T o make up speaker search en vironment, we used V oxceleb 1 and 2 dataset [12, 13]. The V oxceleb dataset is composed of automatically collected audio and video data for large scale speaker identification. The collecting pipeline includes face de- tection and active speaker verification to verify all video clips hav e detected faces with synchronized speaking voice by the conservati ve threshold to maximize the precision. These pro- cesses are reasonable pre-processing to our speaker search sce- nario, so we used the audio part of the V oxceleb dataset without modification. V oxceleb 1 and 2 have more than 1,281,352 ut- terances from 7,365 speakers. Utterances were extracted from a video clip and each clip has roughly 10 to 50 utterances. W e used V oxceleb 1 development set (147,935 utterances from 1,211 speakers) for training on both identification and retriev al task. For the test, we combined the utterances in a dif ferent way for each task. Speaker identification task : For search space in the speaker identification task, we used the utterances from first 3 video clips in V oxceleb 1 test set, plus entire utterances from V ox- celeb 2 development set. W e will use all utterances from the same speaker at once for speaker representation, so each en- tity of search space represent a unique speak er and include total 6,034 speak ers. For the query , we used the rest utterances in the V oxceleb1 test set. Since we already pick ed the utterances from first 3 clips for search space, all the query must hav e the same identity in search space and this means closed-set identification task as previous studies [5, 6]. Speaker retrie val task : For search space, we used 100,000 ut- terances from V oxceleb 2 de velopment set and 3,776 utterances from the first 3 clips in V oxceleb 1 test set. W e randomly se- lected 100,000 utterances in the V oxceleb 2 development set from 1,092,009 utterances, so total 103,776 utterances became the search space. For the query , we used utterances from first 3 clips in V oxceleb 1 test set (total 40 speakers, a target class which has relev ant utterance in search space) and V oxceleb 2 test set (total 120 speakers, a non-target class which does not T able 1: Speaker verification performance by speaker r epr esen- tation method on V oxceleb1 test set Speaker EER representation i-vector (cosine) 8.1 i-vector (PLD A) 5.4 x-vector (cosine) 9.9 x-vector (PLD A) 6.0 hav e relev ant utterances in search space). Thus, 160 speaker representations were used as query . W e mainly focused on the speaker retrieval task, but we also conducted an experiment on speak er identification task as the previous study reported [6]. 4. F ast large-scale speak er retrie val 4.1. Speaker r ecognition system For performance comparison, we considered two speaker rep- resentation, i-vector [4] and x-vector [11]. T o train i-vector and x-vector , we used the voxceleb 1 development set as de- picted in the section 3. W e follo wed other training detail same as [15]. T able 1 sho ws the speaker verification performance of i-vector and x-vector using Equal Error Rate (EER) measure- ment. W e used the same system as reported in [15]. Note that since the V oxceleb 1 contains only 1,211 speakers which is a small number to training DNN, x-vector shows slightly worse performance than i-vector . 4.2. LSH The goal of our study is that to retrie ve similar speaker ef fi- ciently with minimum performance loss. In the pre vious study , LSH was adopted for this task and showed v ery promising per- formance on the lar ge-scale speaker identification task combin- ing with i-vector . LSH projects the i-vector into random hyperplane. This hash operation maps close vectors into the same bins(i.e. buck- ets) with high probability [16]. Suppose r is d -dimension ran- dom projection vector drawn from a standard normal distribu- tion, d is dimension of original i-vector w . The hash function maps i-vector w as : w r = h r ( w ) = sgn ( w T r ) = ( 1 if w T r ≥ 0 0 if w T r < 0 (1) W e can concatenate se veral hash functions and use multiple, in- dependent hash functions to boost performance, by using d × k dimensional random projection matrix R l where k is the num- ber of hyperplane per hash table, d is dimension of original speaker representation, l , 1 ≤ l ≤ L , is the hash tables in- dex and L is the total number of hash tables. Thus, the param- eter k and L need to be chosen carefully since the parameter decides the trade-off between performance and computational efficienc y . In this study , we basically follow the same i-v ector retriev al with LSH algorithm in [6] and also used cosine distance which guarantees its performance in conjunction with LSH. W e mea- sured the baseline performance of closed-set speaker identifica- tion and speaker retriev al tasks using i-vector and x-vector as shown in table 2. Redu ndan t projection withou t consi derin g data distribution Spk1 Spk2 Spk3 (a) Random pr ojection Always guaran tee maximum inter-spea ker variabili ty for randoml y sel ected speakers Spk1 Spk2 Spk3 (b) RSS pr ojection (No. of random speaker=2) Figure 1: Example of projections for 3 speakers. Same color r epresents dif fer ent utterances for same speaker . T able 2: Speaker searc h performance using i-vector and x- vector Speaker Speaker Speaker Representation retriev al, EER(%) identification, Acc.(%) i-vector 4.36 79.23 x-vector 5.60 76.74 4.3. Random Speaker -variability Subspace (RSS) Projec- tion Since LSH is an unsupervised hashing method that uses ran- dom projection matrix drawn from a d -dimensional standard normal distribution, it suffers from redundancy of the hyper- planes (hash bits) as represented in figure 1. Thus, lots of hash tables are needed to access enough points for the satisfactory recall. In this situation, we can give a weak supervision to gen- erate the random subspace projection matrix using speaker la- bels to make the same speaker’ s voice mapped into the same bin more efficiently . W e generate Linear Discriminant Anal- ysis (LD A) transformation matrix directly by using utterances from the random subset of the speakers and use this matrix for projection matrix R l . Suppose S l is a randomly selected speaker subset from training dataset where the number of speaker is N s . Using the speaker representation in the subset S l , we can obtain the between-class scatter matrix and the within-class scatter matrix. Then, we can calculate LDA matrix which maximizes the ratio of the two scatter matrices. This LD A matrix project speaker representation into RSS and we can generate it L times ran- domly to substitute the random projection matrix R l in LSH. For hyperparameter N s , if we choose too man y speak ers, it will generate a similar LD A matrix which have many redundancy between projection matrices. Also we have to choose N s more than the length of hash bits k to project into k dimension. T o balance the size of each hash bin, we modified the hash func- tion as h r ( w ) = sgn ( w T r + b ) where b is the mean of projected data, i.e, b = − 1 N P N i =1 w T i r Similar work w as reported in the f ace recognition study [17] that uses random sampling LDA. They generated multiple pro- jection matrix by selecting eigen vectors randomly . Then LD A was applied on each projected subspace. Since they ha ve only d eigen vectors to be selected randomly , the redundancy between the projected subspaces would be increased if we increase the number of hash tables. This approach is not actually designed for hashing. Ho wev er, projecting samples onto random sub- space to enforce weak classifiers is similar scheme to our ap- proach, so we also use this random sampling LD A to generate projection matrix R l and compare it with other approaches. Figure 2: A verag e Hamming distance of same identities divided by the distance of differ ent identities. Lower is better . In the projected subspace, hamming distance approximates the cosine distance as the number of random hyperplanes k is increases [18]: cos ( w i , w j ) ≈ cos ( H ( h r ( w i ) , h r ( w j )) k π ) (2) where H ( · ) is a hamming distance. Thus, if the projection ma- trix effecti vely approximates the original distance, the speaker representation from the same identity has high possibility to be in the same or near bucket and we can use less number of hash functions to approximate the original distance. It means that the hamming distance of speaker representation from the same identity would be closer than others. T aking this into consid- eration, the approximation capability of a new projection ma- trix can be measured by the av eraged hamming distance of the same identities and different identities. W e checked this av- eraged hamming distance using LSH, random sampling LD A, and the proposed method. As shown in figure 2, the proposed method shows that the distance between the same speakers is close, but the different speakers result in far distance. From this observation we can e xpect the proposed method would gi ve significant efficienc y than others. 5. Experimental results W e conducted two tasks of experiments, speaker identification and speaker retrieval, and the experimental environments were fully described in the section 3. For speaker retriev al, EER was used for performance measurement, for the speaker iden- tification task (closed-set), accuracy was used for as described in section 2. I-vector and x-vector were extracted in 600 and 512 dimensions respectiv ely , then reduced into 150 dimensions using LD A. W e measured the retrie val time to return candidates for a given query and excluded the time to extract i-vector and x-vector . For the baseline, we generate L random projection matrix which drawn from d -dimensional standard normal dis- tribution. For RSS projection, the optimal operating N s is var- ied by the number of hyperplanes. Rather than optimizing, we set to d , equals to i-vector or x-vector dimension, so the subset has more than d samples at least to avoid within-class scatter matrix become singular by small sample size problem [19]. W e repeated L times to generate RSS projection matrix by select- ing random speakers for each matrix. For the random sampling LD A [17], we used randomly 100 eigen vectors from PCA for random subspace, then repeat L times to generate random sam- pling LD A matrix. W e used these three projection matrix R l for LSH. Figure 3 (a) and (b) shows the result on various number (a) V arying number of hyperplane, k (b) V arying number of hash table, L Figure 3: EER measurement on speak er retrieval task. of hyperplanes and hash tables. The proposed RSS projec- tion sho ws significant efficienc y compared to others in the EER measurement. Meanwhile, it is interesting that the x-vectors mapped into hash bins very efficiently than i-vectors in all methods. W e surmise that this phenomenon is because the x- vector extracting DNN was trained discriminatively with one hot speak er label while the i-v ector frame work assumes that the i-vector distributed in Gaussian distribution. Thus, the distance between the same speaker x-vectors is more likely to become close than the i-vector . W e believed that any speaker embed- dings extracted from DNN would take this advantage, not only x-vector . Figure 4 (a) and (b) shows trade-off plot between retriev al speed and performance. W e conducted the experi- ments by varying the parameter k and L and scattered in speed and performance axis. On both speaker retrieval and identifi- cation task, the proposed approach shows remarkable perfor- mance improv ement. For e xample, to speed up while maintain- ing abov e 95% speaker identification performance relative to linear search, the proposed approach has 100 times faster than linear search and 7 times faster than LSH as shown in table 3. Note that the EER in figure 3 and figure 4 (a) is absolute value, not relati ve v alue to linear search. T o gi ve an intuition on the pa- rameters, we specified pairs of parameters on the plot in [ L, k ] format by varying a parameter while the other was fixed. As shown in the figure, k is more sensitiv e to performance than L . Thus, L can be used for fine-tune to satisfy required perfor- mance. T able 3: P erformance summary of hashing methods on speaker identification Hashing LSH Random-sampling LD A Proposed Baseline Accuracy 76.74 % Hashing Accuracy 74.10% 74.14% 74.65% Relativ e speed 14 × 7 × 100 × No. of Hyperplanes 10 6 12 No. of Hash tables 300 150 150 6. Conclusion W e hav e proposed a RSS based hash algorithm to search and retriev e someone’ s voice identity , which is applicable to a large scale speech dataset. Previous studies hav e focused on the speaker identification, b ut we hav e redefined the search problem both in the speaker identification and retriev al. The proposed approach has shown significant efficienc y to save retrie val time and storage consumption compared to “v anilla” LSH that uses random projection. W e hav e also observed that the speak er em- bedding is more advantageous to be mapped into a hash table compared to traditional i-vector . T o the best of our knowledge, this is the first study to use the class supervision on hashing for acoustic information retriev al. For future work, we would ex- plore speaker retrieval methods further in many other domains as well as real-world applications. It would be also interesting to inv estigate ho w the system works in the presence of cloned voice by recent speech synthesis algorithms. (a) Speaker r etrieval task. Y -axis r epr esent EER(%) value. (b) Speaker identification task. Y -axis r epr esent accu- racy r elative to linear searc h accuracy . Figure 4: Speedup vs. performance trade-off. The number of k varied fr om 2 to 20 in step of 2 and L fr om 100 to 300 in steps of 50. A pair of numbers on the plot r epresent [ L, k ] as examples. 7. References [1] Y . W ang, R. Skerry-Ryan, D. Stanton, Y . Wu, R. J. W eiss, N. Jaitly , Z. Y ang, Y . Xiao, Z. Chen, S. Bengio, Q. Le, Y . Agiomyrgiannakis, R. Clark, and R. A. Saurous, “T acotron: T owards End-to-end Speech Synthesis, ” ArXiv e- prints arXiv:1703.10135 , 2017. [2] Y . Jia, Y . Zhang, R. J. W eiss, Q. W ang, J. Shen, F . Ren, Z. Chen, P . Nguyen, R. Pang, I. L. Moreno, and Y . W u, “T ransfer Learning from Speaker V erification to Multispeaker T ext-T o-Speech Syn- thesis, ” ArXiv e-prints , 2018. [3] H. Aronowitz and D. Burstein, “Efficient Speaker Identification and Retriev al, ” in Interspeech , 2005, pp. 2433–2436. [4] N. Dehak, P . J. Kenny , R. Dehak, P . Dumouchel, and P . Ouel- let, “Front-End Factor Analysis for Speaker V erification, ” IEEE T rans. on Audio, Speech, and Lang. Process. , vol. 19, no. 4, pp. 788–798, may 2011. [5] W . Jeon and Y .-M. Cheng, “Efficient Speaker Search ov er Large Populations using Kernelized Locality-sensitive Hashing, ” in ICASSP , 2012, pp. 4261–4264. [6] L. Schmidt, M. Sharifi, and I. L. Moreno, “Large-scale Speaker Identification, ” in ICASSP , 2014, pp. 1669–1673. [7] R. Leary and W . Andrews, “Random projections for large-scale speaker search, ” pp. 66–70, 2014. [8] D. Sturim and W . M. Campbell, “Speak er linking and applications using non-parametric hashing methodsy, ” in Interspeech , 2016, pp. 2170–2174. [9] P . Indyk and R. Motwani, “ Approximate Nearest Neighbors: T o- wards Removing the Curse of Dimensionality , ” Pr oceedings of the 30th Annual ACM Symposium on Theory of Computing , pp. 604–613, 1998. [10] Y . W eiss, A. T orralba, and R. Fergus, “Spectral Hashing, ” Nips ’08 , no. 1, pp. 1–8, 2008. [11] David Snyder , P . Ghahremani, D. Povey , D. Garcia-Romero, and Y . Carmiel, “Deep Neural Network Embeddings for T ext- Independent Speak er V erification, ” in Interspeech , 2017, pp. 999– 1003. [12] A. Nagrani, J. S. Chung, and A. Zisserman, “V oxCeleb: A large- scale speaker identification dataset, ” in Interspeech , 2017, pp. 2616–2620. [13] J. S. Chung, A. Nagrani, and A. Zisserman, “V oxCeleb2: Deep Speaker Recognition, ” in Interspeech , 2018, pp. 1086–1090. [14] E. Singer and D. Re ynolds, “Analysis of Multitarget Detection for Speaker and Language Recognition, ” in ODYSSEY The Speaker and Language Recognition W orkshop , no. 4, 2004, pp. 301–308. [15] S. Shon, H. T ang, and J. Glass, “Frame-lev el Speaker Embeddings for T ext-independent Speaker Recognition and Analysis of End- to-end Model, ” in IEEE Spoken Language T echnology W orkshop (SLT) , 2018. [16] A. Gionis, P . Indyk, and R. Motwani, “Similarity Search in High Dimensions via Hashing, ” VLDB ’99 Pr oceedings of the 25th International Confer ence on V ery Lar ge Data Bases(VLDB) , vol. 99, no. 1, pp. 518–529, 1999. [17] X. W . X. W ang and X. T . X. T ang, “Random sampling LD A for face recognition, ” Proceedings of the 2004 IEEE Computer So- ciety Conference on Computer V ision and P attern Recognition, 2004. CVPR 2004. , vol. 2, pp. 259–265, 2004. [18] A. Jansen and B. V an Durme, “Indexing Raw Acoustic Features for Scalable Zero Resource Search, ” Conference of the Interna- tional Speech Communication Association , v ol. 4, pp. 2466–2469, 2012. [19] R. Huang, Q. Liu, H. Lu, and S. Ma, “Solving the small sam- ple size problem of LDA, ” in International Confer ence on P attern Recognition , vol. 3, 2002, pp. 29–32.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment